HDFS写数据流程
写数据的整体流程
HDFS写数据流程示意:
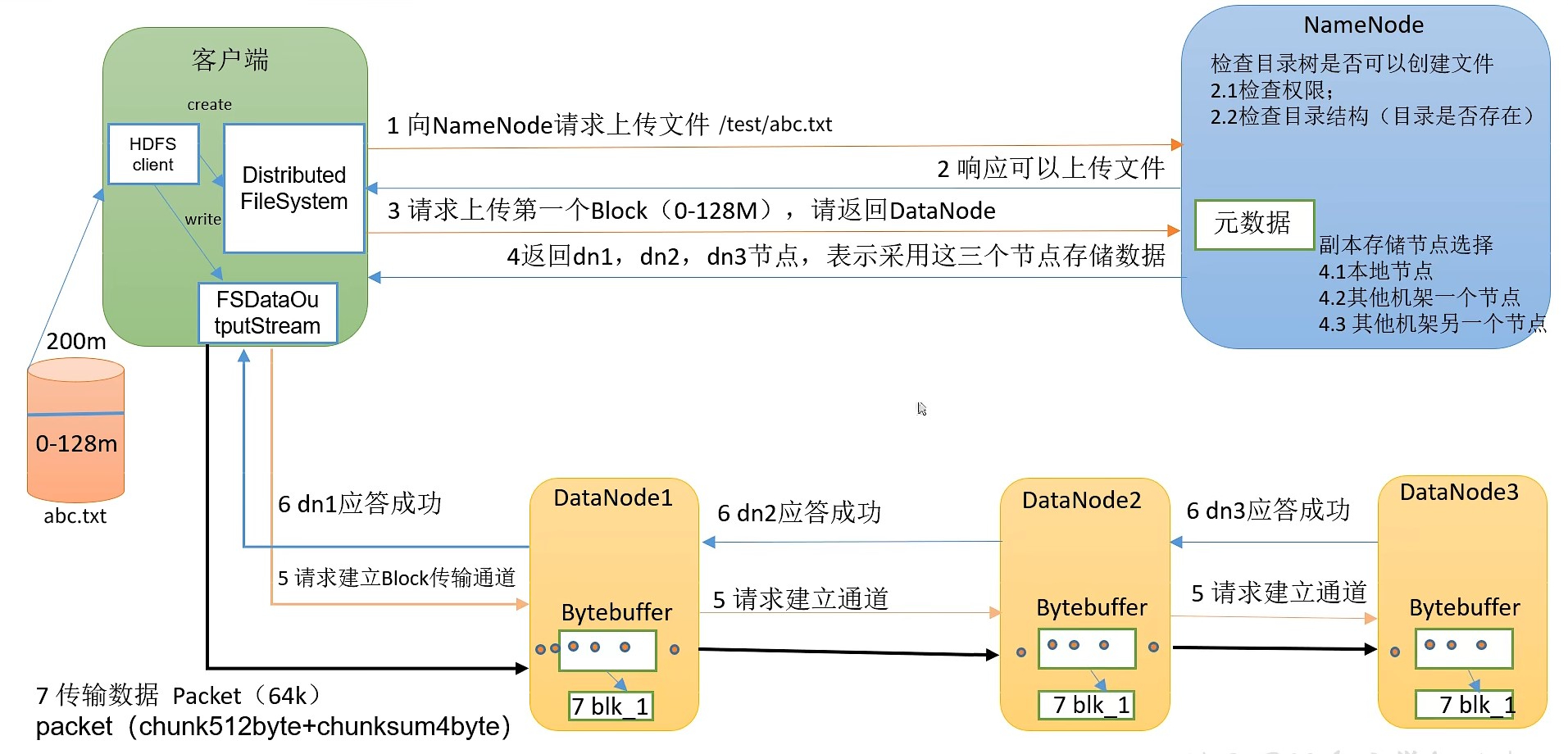
在第7步中,客户端要向DataNode写数据时,是以一种管道(pipeline)的方式,先向一个DataNode写入,然后由该DataNode继续发给下一个、下一个再发给下下个。不是客户端多线程同时写多个DataNode。
客户端向DataNode传输数据时,也不是直接串行将整个文件块写入,而是将文件块拆分成多个64k的数据包(packet),多个数据包并行的对同一个DataNode进行写入。
DataNode写数据完成后会向给自己发送数据的前一级发送应答信号。如果DataNode写数据失败,没有正确发送应答信号,它的前一级会重试重新向该DataNode传输数据。
写数据流程:
- HDFS客户端创建对象实例 DistributedFileSystem,该对象中封装了与HDFS文件系统操作的相关方法
- 调用DistributedFileSystem对象的create()方法,通过 RPC 请求 NameNode创建文件。NameNode执行各种检查判断:目标文件是否存在、父目录是否存在、客户端是否具有创建文件的权限。NameNode就会为本次请求记下一条记录,返回 FSDataOutputStream 输出流对象给客户端用于写数据。
- 客户端通过 FSDataOutputStream输出流开始写入数据
- 客户端写入数据时,将数据分成一个个数据包(packeg,默认64k)。内部组件DataStreamer请求NameNode挑选出适合存储数据副本的一组DataNode地址,默认是3副本存储。DataStreamer将数据包流式传输到管道(pipeline)的第一个 DataNode,该DataNode存储数据包并将它发送到 pipeline 的第二个DataNode。同样的,第二个DataNode存储数据包并发送给第三个(也是最后一个)DataNode。
- 传输的反方向上,会通过ACK机制校验数据包传输是否成功
- 客户端完成数据写入后,在 FSDataOutputStream 输出流上调用 close() 方法关闭
- 客户端DsitributedFileSystem联系NameNode,告知NameNode文件写入完成,等待NameNode确认。因为NameNode已经知道文件由哪些块组成(DataStream请求分配数据块),因此仅需等待最小复制块即可成功返回。最小复制是由参数 dfs.namenode.replication.min 指定,默认是1。即只要有1个副本上传成功,NameNode就认为已经上传成功,如果其他DataNode有缺失的块,可以通过这个DataNode继续复制。
网络拓扑-节点距离计算
在HDFS写数据的过程中,NameNode会选择距离和待上传数据最近距离的DataNode接收数据。
节点距离的计算:两个节点到达最近的共同祖先的距离总和。
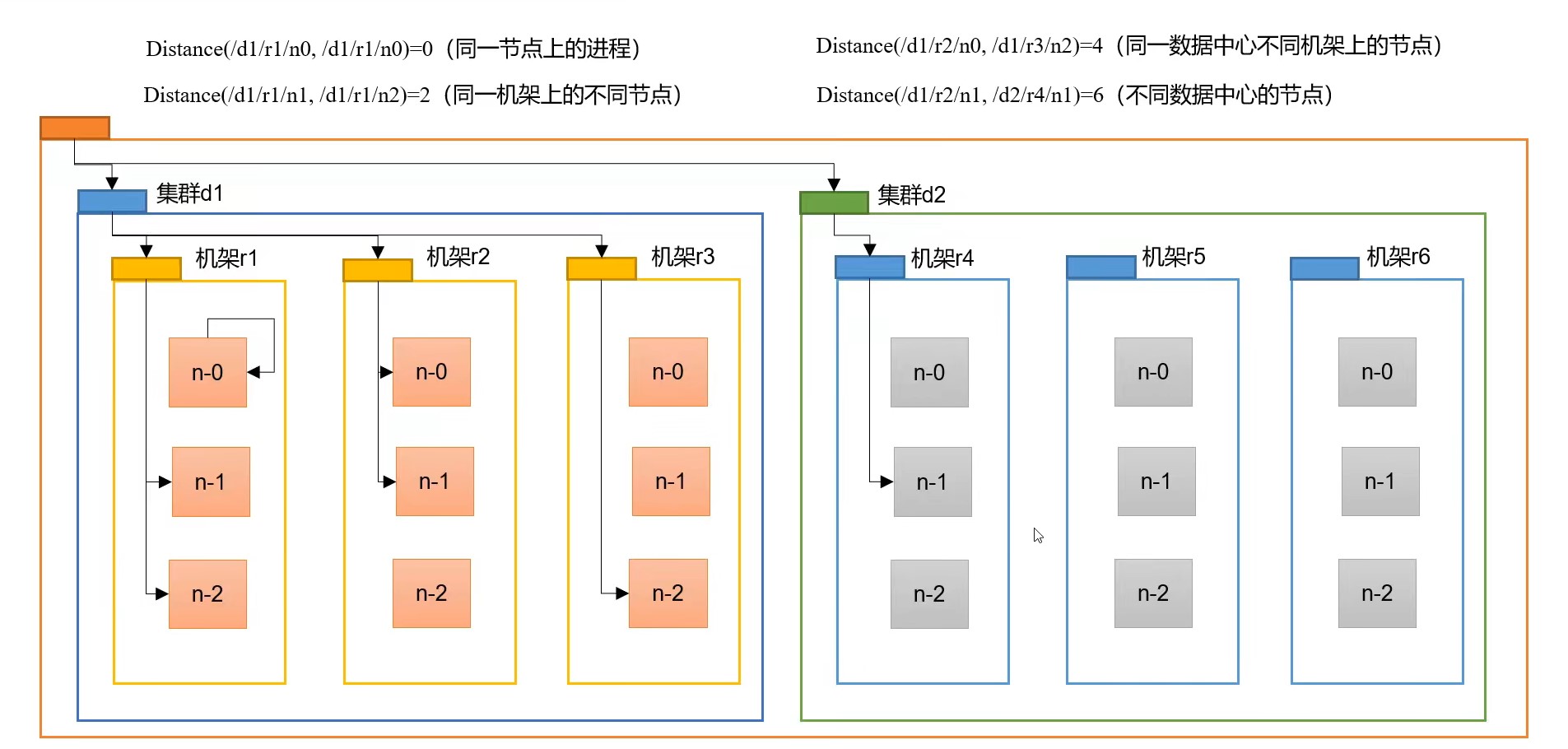
以上图为例:
- 如果两个进程都处于
d1/r1/n0( d1集群 r1 机架 n-0 节点)上,那么这两个进程之间的距离就是0 - 如果两个进程位于同一机架不同节点,一个位于
d1/r1/n1节点,一个位于d1/r1/n2节点,这两个节点之间的距离就是:(n1到r1的距离) + (r1到n2的距离) = 2 - 如果两个进程位于同一个集群的不同机架上,一个位于
d1/r2/n0,一个位于d1/r3/n2,这两个节点之间的距离就是:(no到r2+r2到d1) + (d1到r3+r3到n2) = 4 - 如果两个进程是不同集群的节点,那么距离就是6
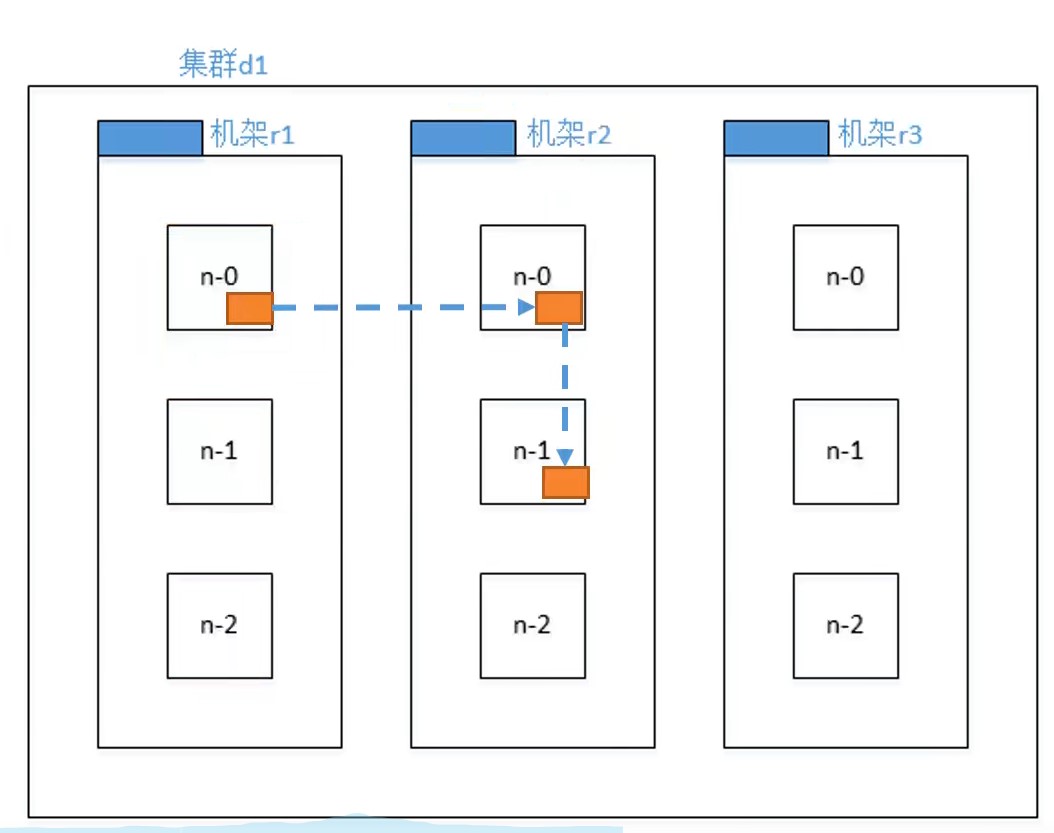
机架感知(副本存储节点的选择)
根据节点选择的官方说明,当使用的默认3个节点副本时,hdfs选择的副本存储节点为:
- 副本1存储在本机节点
one replica on the local machine - 副本2存储在另一个机架的一个节点
another replica on a node in a different (remote) rack - 副本3存储在和副本2相同机架的另一个节点
the last on a different node in the same remote rack
HDFS读数据流程
HDFS读数据的整体流程:
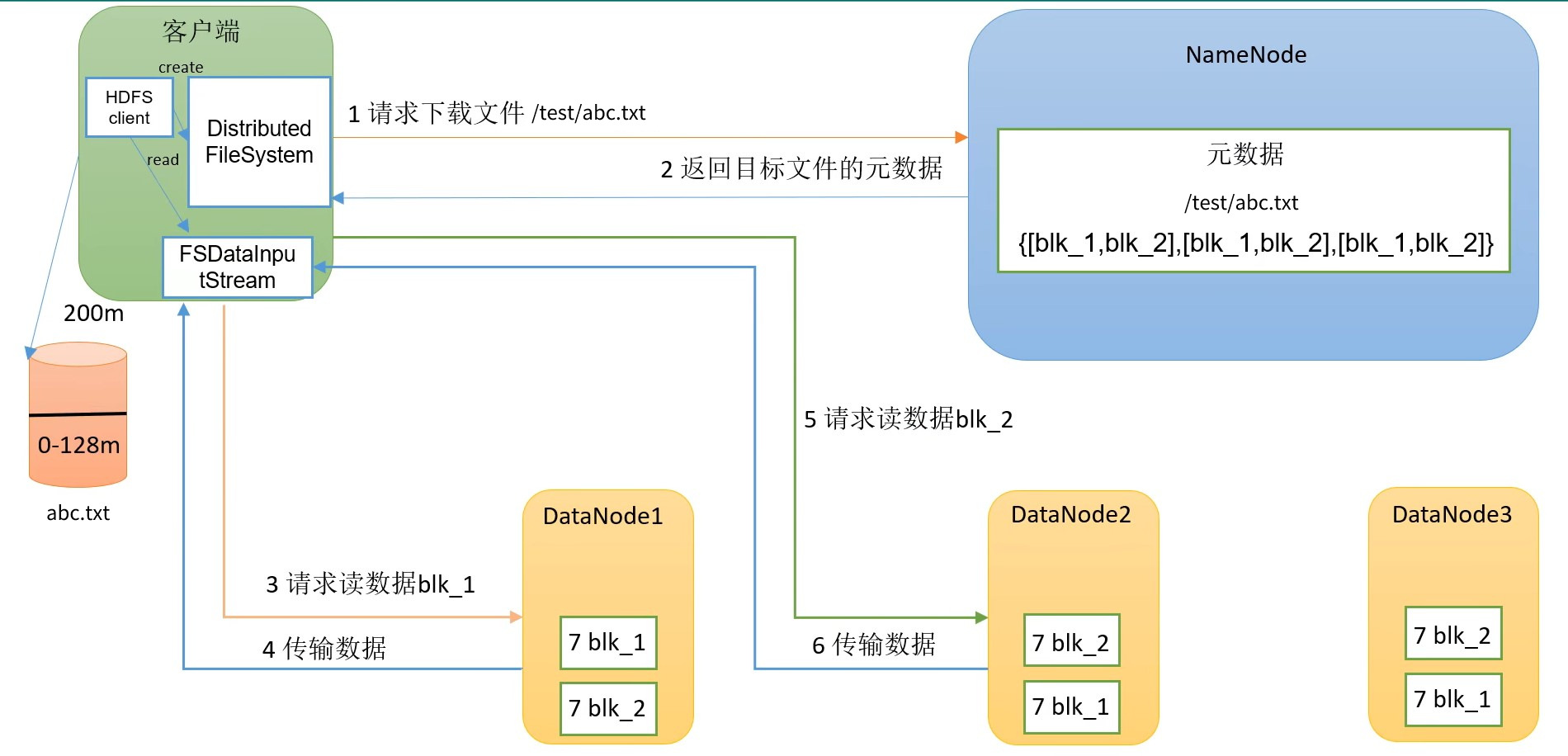
在第1步时,NameNode接到了客户端的请求,会判断客户端的用户是否有权限读,并且判断hdfs中是否有该文件,然后将元数据响应给客户端。
在第3步时,客户端要从DataNode中读取数据,而一个文件块会有多个副本,客户端会考虑哪个DataNode离自己最近,并且该DataNode的访问量负载不是很高才从这个DataNode上下载。
在第5步请求第二个文件块blk_2时,是在已经读取完成了blk_1之后才会发出该请求,是串行读,不是多线程并行。最后将读到的blk_2数据追加到blk_1末尾,就可以拼接成一个完整的文件。
所以,我们在 hadoop 服务器上的data文件夹中找到hadoop存放数据的文件夹$HADOOP_HOME/data/dfs/data/current/BP-xxxxxxx/current/finalized/subdir0/subdir0,在里面将某个文件的几个blk_xxx按顺序拼接,也能恢复出原文件:
# 需要能找到abc.txt文件拆分的文件块,以及这些文件块所在的服务器、编号# 因为我们集群只有3台服务器,且hdfs默认副本数量为3,所以每个文件块在这3台服务器上都能找到# 假设 abc.txt被拆分成的文件块为 blk_1 和 blk_2(文件块编号可以在hdfs页面上查看到,即 blk_BlockID )# 将blk_1的数据写入abc.txtcat blk_1 >> abc.txt# 将blk_2的数据追加到abc.txtcat blk_2 >> abc.txt# 此时就可以恢复出文件abc.txt

若有收获,就点个赞吧
0 人点赞
