多数据源配置 dynamic-datasource
参考:mybatis-plus 系列(苞米团队):
https://mp.baomidou.com/guide/dynamic-datasource.html
Spring boot 添加starter使用动态多数据源
https://blog.csdn.net/qq_26677157/article/details/83306717
动态数据源实现原理参考:
https://cloud.tencent.com/developer/article/1415185
介绍:
dynamic-datasource-spring-boot-starter 是一个基于springboot的快速集成多数据源的启动器。
优势:
1. 数据源分组,适用于多种场景 纯粹多库 读写分离 一主多从 混合模式。
2. 简单集成Druid数据源监控多数据源,简单集成Mybatis-Plus简化单表,简单集成P6sy格式化sql,简单集成Jndi数据源。
3. 简化Druid和HikariCp配置,提供全局参数配置。
4. 提供自定义数据源来源(默认使用yml或properties配置)。
5. 项目启动后能动态增减数据源。
6. 使用spel动态参数解析数据源,如从session,header和参数中获取数据源。(多租户架构神器)
7. 多层数据源嵌套切换。(一个业务ServiceA调用ServiceB,ServiceB调用ServiceC,每个Service都是不同的数据源)
8. 使用正则匹配或spel表达式来切换数据源(实验性功能)。
劣势
不能使用多数据源事务(同一个数据源下能使用事务),网上其他方案也都不能提供。
如果你需要使用到分布式事务,那么你的架构应该到了微服务化的时候了。
如果呼声强烈,项目达到800 star,作者考虑集成分布式事务。
约定
- 本框架只做 切换数据源 这件核心的事情,并不限制你的具体操作,切换了数据源可以做任何CRUD。
- 配置文件所有以下划线 _ 分割的数据源 首部 即为组的名称,相同组名称的数据源会放在一个组下。
- 切换数据源即可是组名,也可是具体数据源名称,切换时默认采用负载均衡机制切换。
- 默认的数据源名称为 master ,你可以通过spring.datasource.dynamic.primary修改。
- 方法上的注解优先于类上注解。
建议
强烈建议在 主从模式 下遵循普遍的规则,以便他人能更轻易理解你的代码。
主数据库 建议 只执行 INSERT UPDATE DELETE 操作。
从数据库 建议 只执行 SELECT 操作
使用步骤
注解:
使用 @DS 切换数据源。@DS 可以注解在方法上和类上,同时存在方法注解优先于类上注解。
注解在service实现或mapper接口方法上,但强烈不建议同时在service和mapper注解。 (可能会有问题)
| 注解 | 结果 |
|---|---|
| 没有@DS | 默认数据源 |
| @DS(“dsName”) | dsName可以为组名也可以为具体某个库的名称 |
1、引入maven依赖
<!-- druid --><!-- https://mvnrepository.com/artifact/com.alibaba/druid-spring-boot-starter --><!--这里如果选择是 druid-spring-boot-starter 会有 webUi 监控访问地址 eg:http://localhost:7084/druid/index.html --><dependency><groupId>com.alibaba</groupId><artifactId>druid-spring-boot-starter</artifactId><version>1.1.10</version><optional>true</optional></dependency><!-- <dependency><groupId>com.alibaba</groupId><artifactId>druid-spring-boot-starter</artifactId><version>1.1.18</version></dependency>--><!--主从配置依赖--><dependency><groupId>com.baomidou</groupId><artifactId>dynamic-datasource-spring-boot-starter</artifactId><version>2.4.2</version></dependency>
2、配置数据源
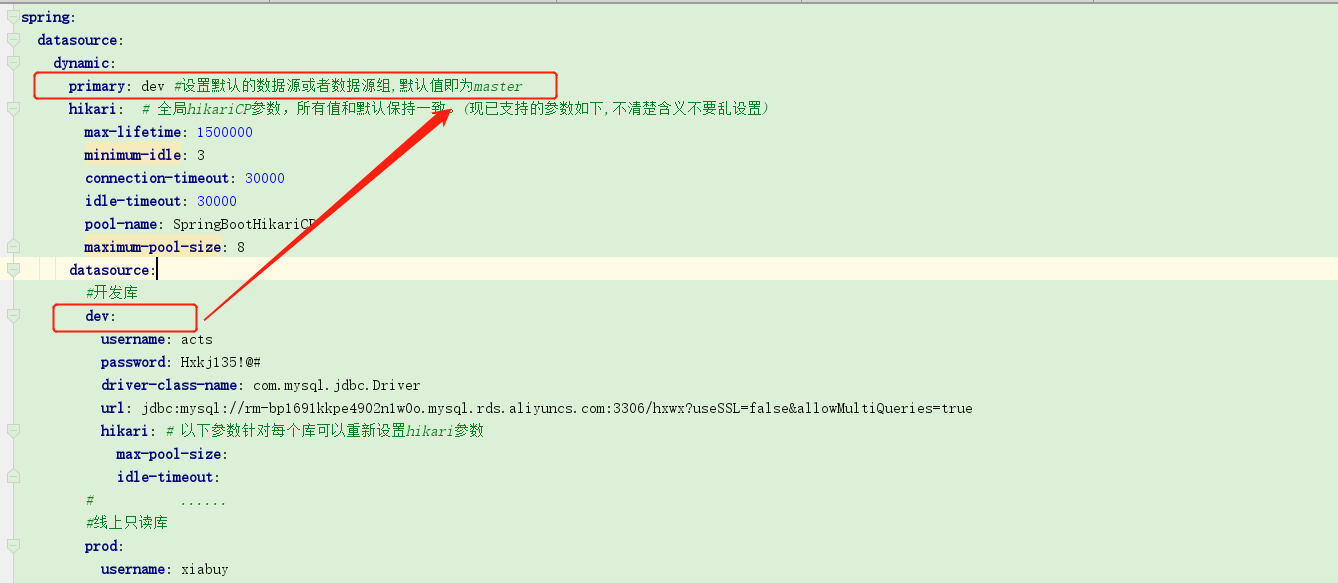
注意: 设置默认的数据源或者数据源组,默认值即为master
如果设置的名字不是 mater 需要
spring.datasource.dynamic.primary: 新名字 (这里的默认不是按下标来的,是按名字来的)
eg:
spring:
datasource:
druid:
stat-view-servlet:
loginUsername: admin
loginPassword: 123456
dynamic:
druid: #以下是全局默认值,可以全局更改
initial-size:
max-active:
min-idle:
max-wait:
datasource:
master:
username: root
password: 123456
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://47.98.253.2:3306/test1?characterEncoding=utf8&useSSL=false
druid: # 以下参数针对每个库可以重新设置druid参数
initial-size:
validation-query: select 1 FROM DUAL #比如oracle就需要重新设置这个
public-key: #(非全局参数)设置即表示启用加密,底层会自动帮你配置相关的连接参数和filter。
slave:
username: root
password: 123456
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://47.98.253.2:3306/test2?characterEncoding=utf8&useSSL=false
druid: # 以下参数针对每个库可以重新设置druid参数
initial-size:
validation-query: select 1 FROM DUAL #比如oracle就需要重新设置这个
public-key: #(非全局参数)设置即表示启用加密,底层会自动帮你配置相关的连接参数和filter。
# ......
logging:
level:
com.baomidou: debug
3、mybatis的mapper文件
@Mapper
@Repository
public interface TestMapper {
@DS("slave")
@Select({" select * from a "})
List<Map> getList();
@DS("master")
@Select({" select * from a "})
List<Map> getList2();
}
4、springBoot 启动类配置 DynamicApplication
去除默认的 Druid 数据源
原因:
DruidDataSourceAutoConfigure在DynamciDataSourceAutoConfiguration之前,其会注入一个DataSourceWrapper,会在原生的spring.datasource下找url,username,password等。而我们动态数据源的配置路径是变化的。
@SpringBootApplication(exclude = DruidDataSourceAutoConfigure.class)
5、TestController
@RestController
public class TestController {
@Autowired
private TestMapper testMapper;
@GetMapping("/test")
public void test(){
List<Map> list= testMapper.getList();
for (Map map : list) {
System.out.println(map.get("a")+""+map.get("b"));
}
System.out.println("------- " +
"List -------");
List<Map> list2= testMapper.getList2();
for (Map map : list2) {
System.out.println(map.get("a")+""+map.get("b"));
}
}
6、查看结果 console 输出

7、如果想配置 hikairCP
7.1首先配置 yml 指向
spring:
profiles:
active: druid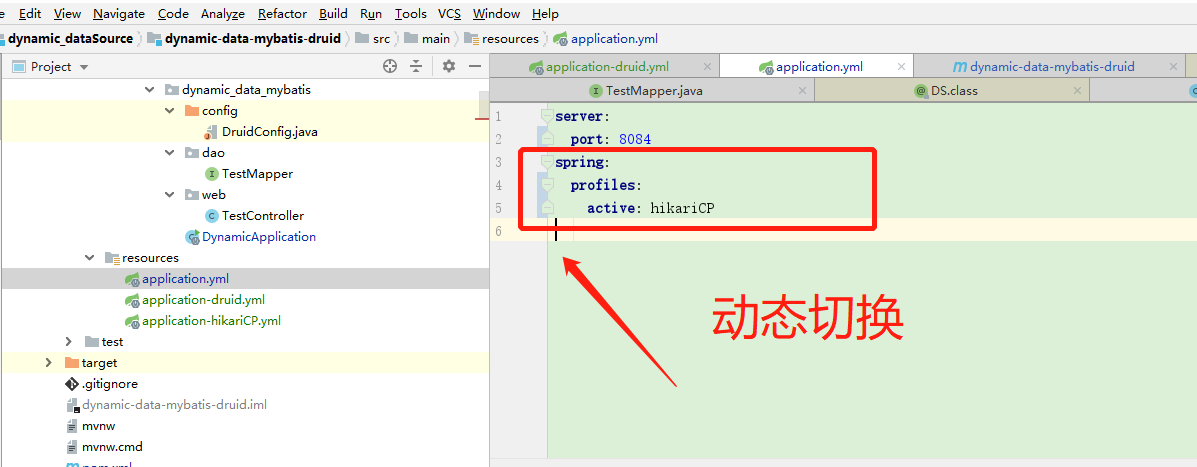
7.2去除druid依赖,和其他引用该jar相关的。
因为 苞米团队这个jar 会默认先连druid。因为国内用druid多。
如果使用hikair还保留这个jar ,启动有异常
7.3、application-hikariCP.yml 配置
spring:
datasource:
dynamic:
primary: master #设置默认的数据源或者数据源组,默认值即为master,如果不是需要重新设置新的名字
hikari: # 全局hikariCP参数,所有值和默认保持一致。(现已支持的参数如下,不清楚含义不要乱设置)
catalog:
connection-timeout:
validation-timeout:
idle-timeout:
leak-detection-threshold:
max-lifetime:
max-pool-size:
min-idle:
initialization-fail-timeout:
connection-init-sql:
connection-test-query:
dataSource-class-name:
dataSource-jndi-name:
schema:
transaction-isolation-name:
is-auto-commit:
is-read-only:
is-isolate-internal-queries:
is-register-mbeans:
is-allow-pool-suspension:
data-source-properties: #以下属性仅为演示(默认不会引入)
serverTimezone: Asia/Shanghai
characterEncoding: utf-8
useUnicode: true
useSSL: false
autoReconnect: true
cachePrepStmts: true
prepStmtCacheSize: 250
prepStmtCacheSqlLimit: 2048
useServerPrepStmts: true
useLocalSessionState: true
rewriteBatchedStatements: true
cacheResultSetMetadata: true
cacheServerConfiguration: true
elideSetAutoCommits: true
maintainTimeStats: false
allowPublicKeyRetrieval: true
health-check-properties:
datasource:
master:
username: root
password: Tlz19970905
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://47.98.253.2:3306/master?characterEncoding=utf8&useSSL=false
hikari: # 以下参数针对每个库可以重新设置hikari参数
max-pool-size:
idle-timeout:
# ......
slave:
username: root
password: Tlz19970905
url: jdbc:mysql://47.98.253.2:3306/slave?characterEncoding=utf8&useSSL=false
driver-class-name: com.mysql.cj.jdbc.Driver
druid:
initial-size: 6
7.4 启动并测试
出现 红色圈住的内容说明已经切换到 hikari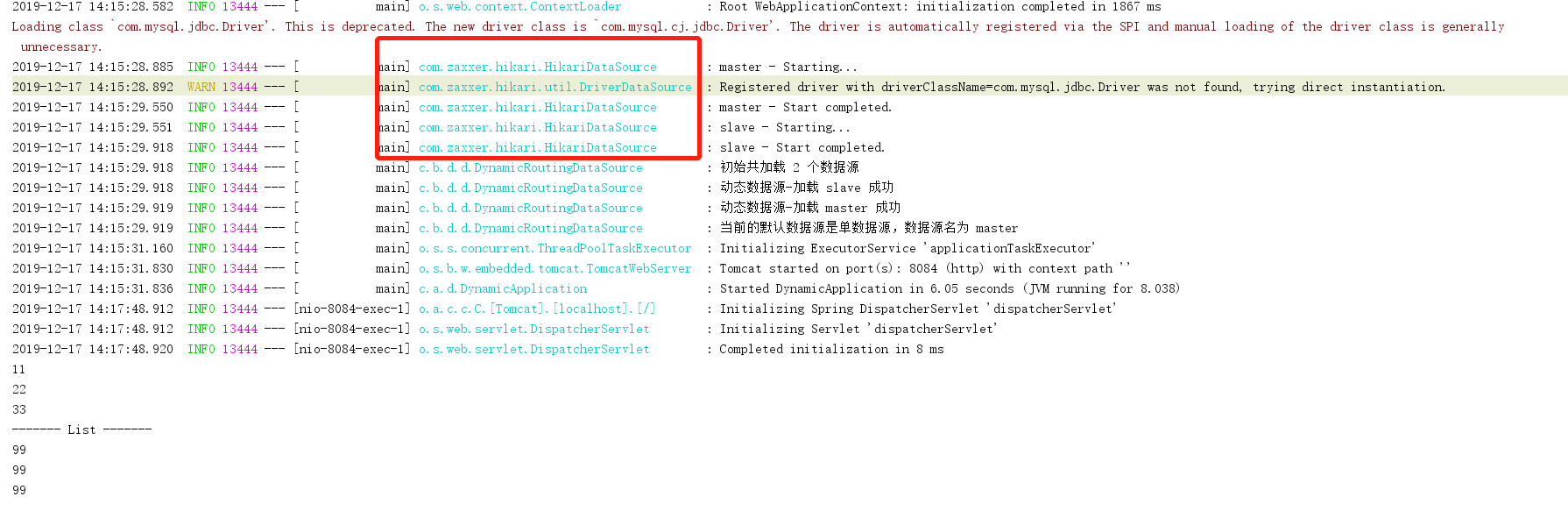
补充
补充1:hikari参数配置
补充2:druid参数设置
补充3:配置 durid 监控的账号和密码
1、代码配置 参考 https://www.cnblogs.com/feiyangbahu/p/9842363.html
这里注意如果使用了 dynamic-datasource 这个数据源,就不支持 yml 配置 访问druid的权限了
因为此时的 yml 的config 配置 指的是 dynamic-datasource 不是 druid 本身的数据源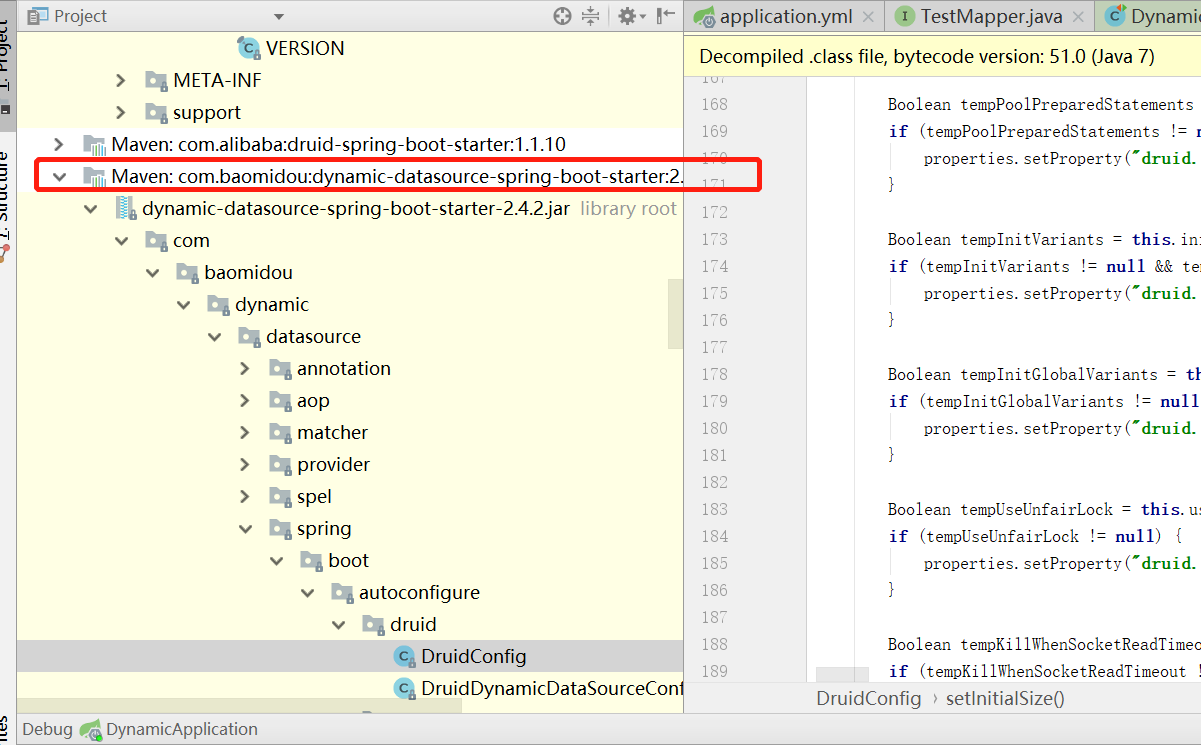
import javax.sql.DataSource;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.boot.web.servlet.FilterRegistrationBean;
import org.springframework.boot.web.servlet.ServletRegistrationBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import com.alibaba.druid.pool.DruidDataSource;
import com.alibaba.druid.support.http.StatViewServlet;
import com.alibaba.druid.support.http.WebStatFilter;
@Configuration
public class DruidConfig {
@Bean
public ServletRegistrationBean druidServlet() {// 主要实现web监控的配置处理
ServletRegistrationBean servletRegistrationBean = new ServletRegistrationBean(
new StatViewServlet(), "/druid/*");//表示进行druid监控的配置处理操作
servletRegistrationBean.addInitParameter("allow", "127.0.0.1,129.168.1.11");//白名单
servletRegistrationBean.addInitParameter("deny", "129.168.1.12");//黑名单
servletRegistrationBean.addInitParameter("loginUsername", "root");//用户名
servletRegistrationBean.addInitParameter("loginPassword", "root");//密码
servletRegistrationBean.addInitParameter("resetEnable", "false");//是否可以重置数据源
return servletRegistrationBean;
}
@Bean //监控
public FilterRegistrationBean filterRegistrationBean(){
FilterRegistrationBean filterRegistrationBean=new FilterRegistrationBean();
filterRegistrationBean.setFilter(new WebStatFilter());
filterRegistrationBean.addUrlPatterns("/*");//所有请求进行监控处理
filterRegistrationBean.addInitParameter("exclusions", "*.js,*.gif,*.jpg,*.css,/druid/*");//排除
return filterRegistrationBean;
}
@Bean
@ConfigurationProperties(prefix = "spring.datasource")
public DataSource druidDataSource() {
return new DruidDataSource();
}
}
2、yml 配置 参考:
https://blog.csdn.net/qq_42235671/article/details/84592028
https://www.cnblogs.com/cicada-smile/p/11019708.html
开启监控是可以是 两种配置
1、yml
2、或者配置bean
条件是仅含有 druid-spring-boot-starter 单独的数据源配置
<!-- https://mvnrepository.com/artifact/com.alibaba/druid-spring-boot-starter druid 数据源 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.10</version>
</dependency>
spring:
datasource:
url: jdbc:mysql://你自己的url
username: 数据库账号
password: 数据库密码
type: com.alibaba.druid.pool.DruidDataSource
druid:
# 下面为连接池的补充设置,应用到上面所有数据源中
# 初始化大小,最小,最大
initial-size: 5
min-idle: 5
max-active: 20
# 配置获取连接等待超时的时间
max-wait: 60000
# 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒
time-between-eviction-runs-millis: 60000
# 配置一个连接在池中最小生存的时间,单位是毫秒
min-evictable-idle-time-millis: 300000
validation-query: SELECT 1 FROM DUAL
test-while-idle: true
test-on-borrow: false
test-on-return: false
# 打开PSCache,并且指定每个连接上PSCache的大小
pool-prepared-statements: true
# 配置监控统计拦截的filters,去掉后监控界面sql无法统计,'wall'用于防火墙
max-pool-prepared-statement-per-connection-size: 20
filters: stat,wall
use-global-data-source-stat: true
# 通过connectProperties属性来打开mergeSql功能;慢SQL记录
connect-properties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000
# 配置监控服务器
stat-view-servlet:
enabled: true
login-username: admin
login-password: 123456
reset-enable: false
url-pattern: /druid/*
# 添加IP白名单
#allow:
# 添加IP黑名单,当白名单和黑名单重复时,黑名单优先级更高
#deny:
web-stat-filter:
# 添加过滤规则
url-pattern: /*
# 忽略过滤格式
exclusions: "*.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid/*"
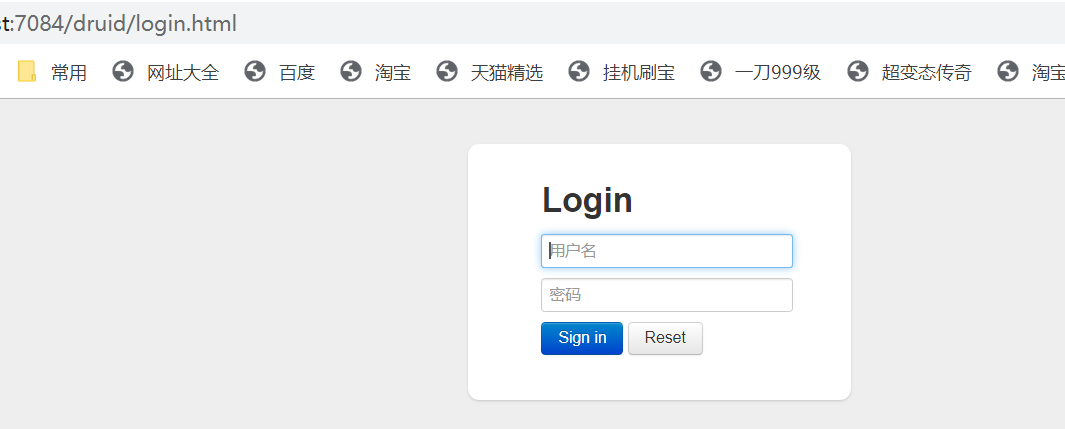
配置成功: 访问 /druid/login.html

若有收获,就点个赞吧
0 人点赞
