- [第二部分]改善深层神经网络
- 训练集train,开发集Dev,测试集test
- 如何诊断高偏差和高方差吗?
- 防止过拟合: L1正则化容易使模型参数稀疏
- 防止过拟合: L2正则化又被称为权重衰减(指学习率的权重, 起到学习率衰减的效果).
- 防止过拟合: 正则化能防止过拟合呢?
- 防止过拟合: 理解Dropout
- Normalize与梯度下降的关系
- 梯度消失和梯度爆炸
- 梯度检查Grad check
- mini-batch
- 指数加权平均
- 动量梯度下降momentum
- RMSprop
- Adam (momentum和RMSprop的结合)
- 学习率衰减(实现函数有很多,下面举几个例子)
- 如何调参: 怎么对重要的超参数进行搜索.
- 批量归一化batchnorm
- batchnorm为什么奏效?
- 多分类任务与softmax激活函数
[第二部分]改善深层神经网络
训练集train,开发集Dev,测试集test
- 注意: 开发集不需要太大. 因为开发集的目的是对不同的模型进行有偏评估, 其数据集大小能起到该作用即可.
- 准则: 开发集和测试集要保证在同一数据分布上. 这是因为开发集费劲全力改善模型在开发集上的性能. 这种做法尤其在诸如网页爬虫等数据质量不是很优秀的数据集上非常好用.
- 另外, 没有测试集也是可以的. 这是因为测试集的目的是提供无偏估计来评价最终选定的网络的性能, 所以如果你不需要无偏估计的话, 可以不要测试集.
- 注: 当只有训练集和开发集时, 有些人会把此时的开发集称为测试集, 但是事实上, 开发集的用词更准确.
如何诊断高偏差和高方差吗?

上图, 用训练集和开发集的误差来诊断模型在当前训练集上是否高偏差和高方差 (注: 这里假设理想偏差或贝叶斯偏差为0%)
- 如何理解”方差与偏差”, 以及它们和”过拟合与欠拟合”之间的联系呢?
- “方差与偏差”是针对模型在训练集上的表现..
- bias=E(p(x)) - f(x) , 计算预测值与真实值之间平均差异, 即一个模型在不同训练集上的平均表现与真实值的差异, 用于衡量模型是否容易欠拟合.
- variance= E((p(x) - E(p(x)))^2) 计算预测值之间的平均差异, 即一个模型在不同训练集上的平均差异, 用于衡量模型是否容易过拟合.

- 为什么要诊断出模型在训练集上的”方差与偏差”呢?
因为诊断结果很重要. 它直接意味着模型在测试集或实际应用下是否容易发生过拟合或者欠拟合, 它强烈暗示了当前模型的泛化能力. 同时, 它还能指导我们接下来如何调整, 比如增加数据量,减化模型参数,正则化等等手段.
- 如何诊断训练集上是否高偏差或高方差呢?
| Train set error | 低 | 高 | 高 | 低 | | —- | —- | —- | —- | —- | | Dev set error | 高 | 高 | 很高 | 低 | | 此时模型的泛化性 | |
|  |
| 
 |
|  |
| 诊断结果: | 高方差 | 高偏差 | 高偏差/高方差 | |
|
| 诊断结果: | 高方差 | 高偏差 | 高偏差/高方差 | |
防止过拟合: L1正则化容易使模型参数稀疏

上图: 满足正则化条件,实际上是求解蓝色区域与黄色区域的交点.
防止过拟合: L2正则化又被称为权重衰减(指学习率的权重, 起到学习率衰减的效果).
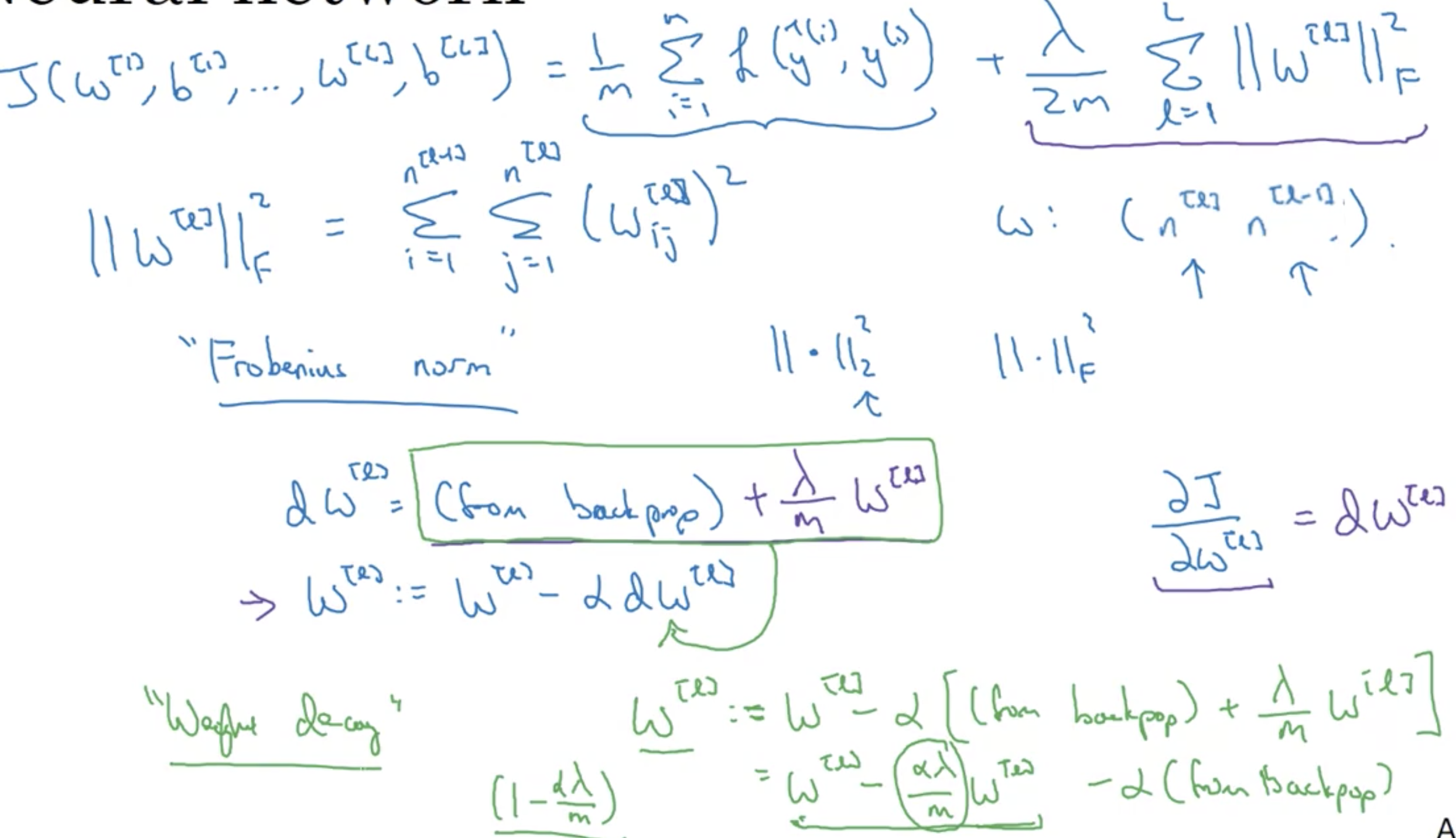
上图, 我们对代价函数进行了L2正则化,以防止过拟合. 在计算反向传播后发现, 正则项的梯度对于更新参数的方式, 无异于做学习衰减的方式.
防止过拟合: 正则化能防止过拟合呢?
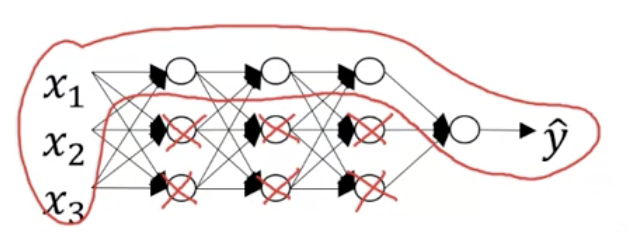

其实质是收缩权重防止过拟合. 从神经元角度讲, 正则化会收缩模型权重参数, 甚至让部分参数等于0, 神经元的输出Z也随之同等变化. 这让神经单元的效果变差了;
从激活函数的角度上讲, 正则化会收缩模型权重参数 使得逐层的线性变换能力差了, 最终模型的拟合能力也差了.
防止过拟合: 理解Dropout
其实质仍是收缩权重来防止过拟合.
由于神经元随机失活的机制, 模型会倾向于”把鸡蛋更匀地放在不同篮子里”, 该过程通过对每个神经元使用更小的权重参数来实现, 这有利于压缩这些权重的平方范数(平方和).
Normalize与梯度下降的关系
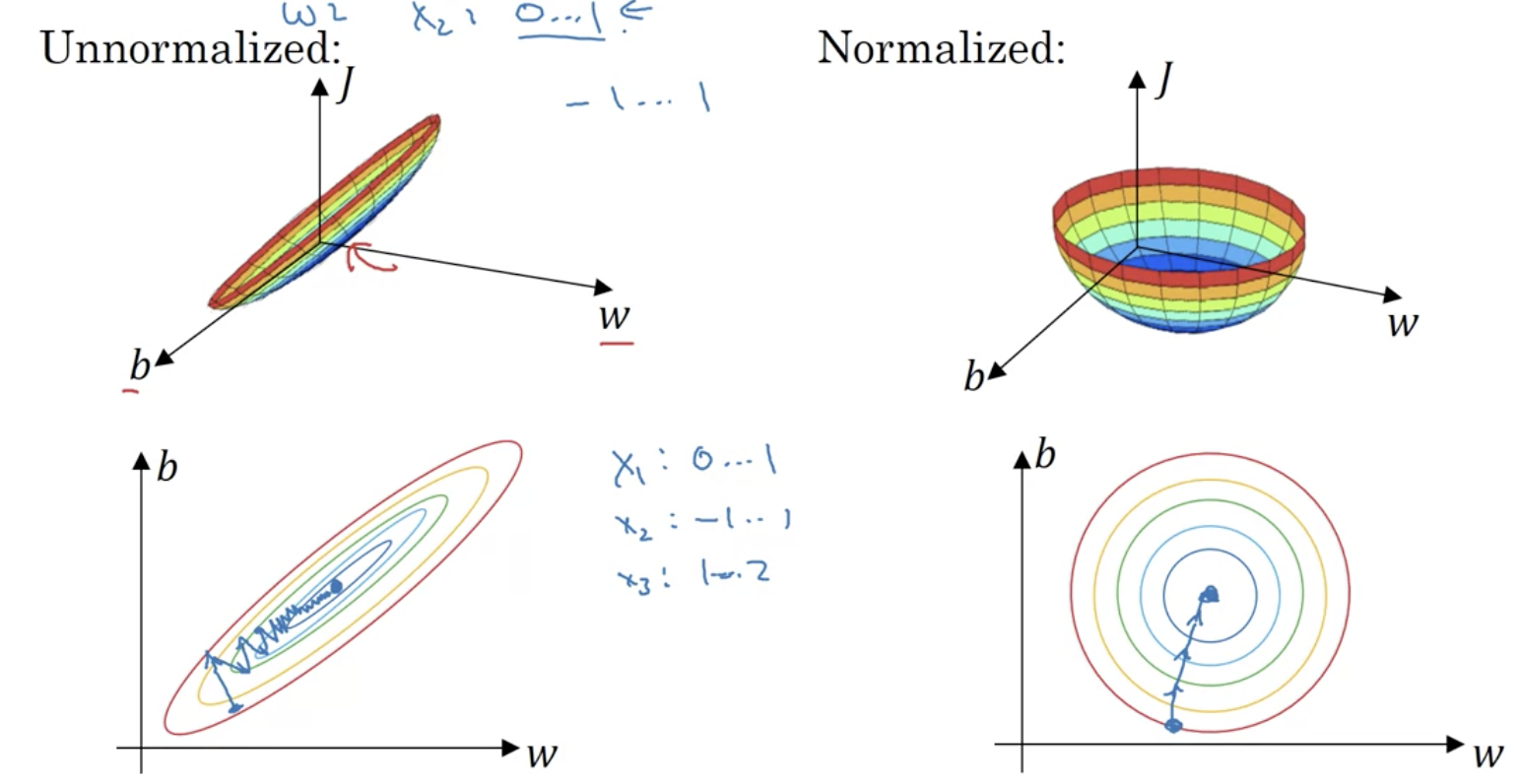
上图, 对数据进行归一化之后更利于收敛, 因为它改善了梯度的方向, 使之更稳定, 梯度下降也更快.

上图是均值和方差的计算方式. 以及归一化的计算过程. 值得注意的是: 在开发集和测试集上进行normalize, 必须使用训练集上的均值和方差.
梯度消失和梯度爆炸

上图, 如果不考虑激活函数…计算每一层的权重矩阵相乘.
梯度消失和梯度爆炸的启示是: 一定要好好初始化参数. 当初始化不正确时, 权重矩阵的相乘结果可能无限趋于0或趋于无穷, 当进行反向传播时, 体现在梯度的消失与梯度的爆炸.
- 下面看如何更好地初始化参数

上图, 根据输入一个神经元的特征数(或者说上一层的神经元个数), 和具体的激活函数, 来确定一个缩小系数. 另外, 这是默认的初始化方式, 你也可以再乘上一个超参数, 然后不断调优.
梯度检查Grad check


梯度检查的目的: 检查手写的反向传播代码是否有错误.
梯度检查的过程: 使用数值方法得到近似梯度(误差为ℇ), 然后计算该近似梯度与反向传播代码返回的梯度之间的误差ℇ’. 检查标准为: ℇ’越接近ℇ越好, 如果相差明显, 就说明反向传播代码有问题. 注: 如果你跟我一样, 用Pytorch这类自动求导的工具, 不需要关注梯度检查. 另外, 还有许多检查技巧, 由于自己基本不会涉及梯度检查, 这里不再补充.
相关代码如下:
def gradient_check_n(parameters, gradients, X, Y, epsilon=1e-7):"""检查backward_propagation_n是否正确地计算了正向传播的成本输出的梯度。Arguments:parameters --包含参数的python字典 "W1", "b1", "W2", "b2", "W3", "b3":grad -- backward_propagation_n的输出包含参数的成本梯度。x -- 输入数据点,形状(输入大小,1)y -- true "label"epsilon -- 用公式对输入进行微小位移计算近似梯度Returns:difference -- 近似梯度与反向传播梯度之间的差异。"""# Set-up variablesparameters_values, _ = dictionary_to_vector(parameters)grad = gradients_to_vector(gradients)num_parameters = parameters_values.shape[0]J_plus = np.zeros((num_parameters, 1))J_minus = np.zeros((num_parameters, 1))gradapprox = np.zeros((num_parameters, 1))# Compute gradapproxfor i in range(num_parameters):thetaplus = np.copy(parameters_values) # Step 1thetaplus[i][0] = thetaplus[i][0] + epsilon # Step 2J_plus[i], _ = forward_propagation_n(X, Y, vector_to_dictionary(thetaplus)) # Step 3thetaminus = np.copy(parameters_values) # Step 1thetaminus[i][0] = thetaminus[i][0] - epsilon # Step 2J_minus[i], _ = forward_propagation_n(X, Y, vector_to_dictionary(thetaminus)) # Step 3# Compute gradapprox[i]gradapprox[i] = (J_plus[i] - J_minus[i]) / (2 * epsilon)# 通过计算与反向传播梯度比较差异。numerator = np.linalg.norm(grad - gradapprox) # Step 1'denominator = np.linalg.norm(grad) + np.linalg.norm(gradapprox) # Step 2'difference = numerator / denominator # Step 3'if difference > 2e-7:print ("\033[93m" + "反向传播有一个错误! difference = " + str(difference) + "\033[0m")else:print ("\033[92m" + "你的反向传播效果非常好! difference = " + str(difference) + "\033[0m")return difference
mini-batch
epoch的概念: 遍历一次数据集
batch的概念: 数据集按批次的大小分为多批, 这些批次就是mini-batch, 批次的大小就是mini-batch size
mini-batch的目的: 将原本一个epoch进行一次梯度下降(batch grad descent), 变为现在每个batch都进行一次梯度下降(mini-batch grad descent).
下面这个图, 紫色,绿色,蓝色分别对应单样本梯度下降,batch梯度下降, mini-batch梯度下降.

- 超参数mini-size的建议
如果 数据量较小(<2000) , mini-batch-size = 1 (即使用Batch grad descent)
如果 数据量较大, mini-batch-size = 26 ~ 29 之间
指数加权平均
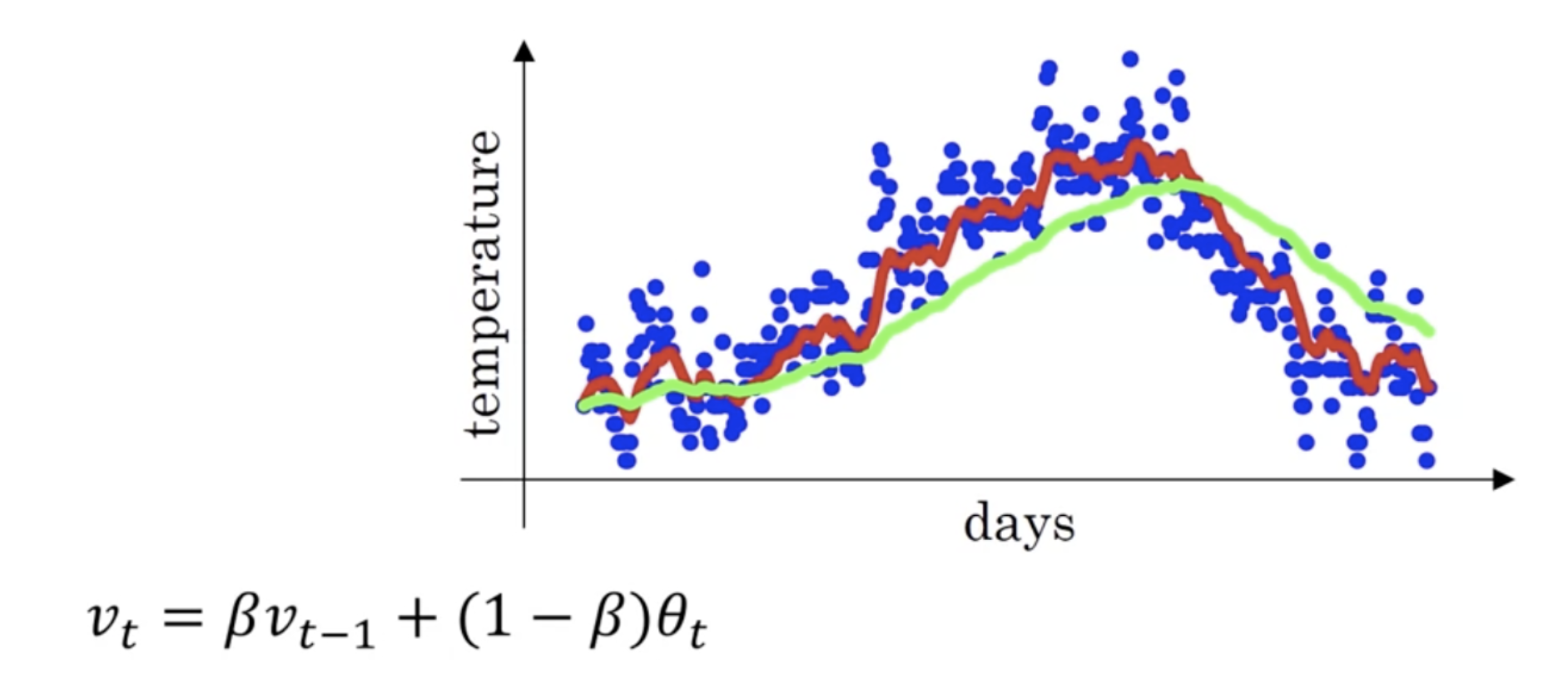
上图是每日的气温. 蓝色, 红色, 绿色分别是原始数据,指数加权后的数据, 指数加权后的数据.
公式: avg = beta avg + (1-beta) data , 含义是: 加权平均了前1/(1-beta) 次数据, beta越大, 整个数据集越平滑. 其指数的字面意思是这些加权的权重之间是指数关系
下面的代码, 来体验一下指数加权平均的beta参数.
- 无偏指数加权平均. 由上图可见, 之前的公式在刚开始有很大偏差. 修改代码如下:

动量梯度下降momentum

思想: 对参数的梯度做(无偏)指数加权平均后, 用该梯度去更新参数.
超参数: beta=0.9 比较稳健.
RMSprop

RMSprop计算了”参数的梯度的平方”的指数加权平均, 该算法希望降低垂直方向的震荡
Adam (momentum和RMSprop的结合)

- adam超参数建议.
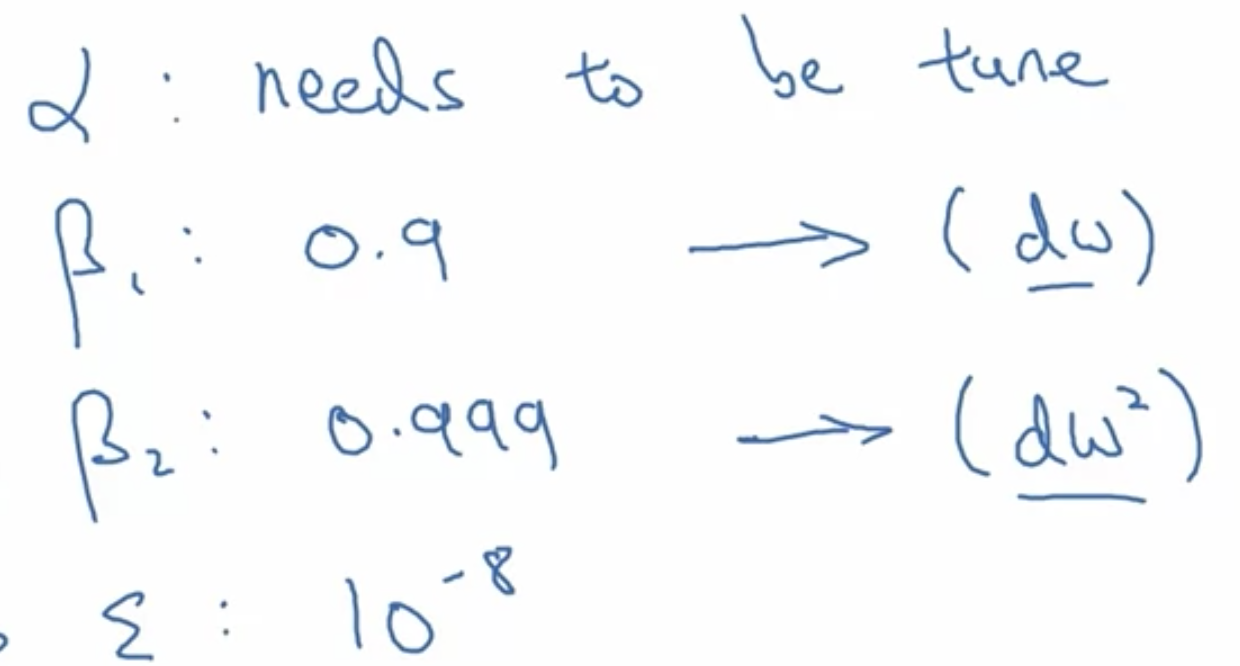
学习率衰减(实现函数有很多,下面举几个例子)

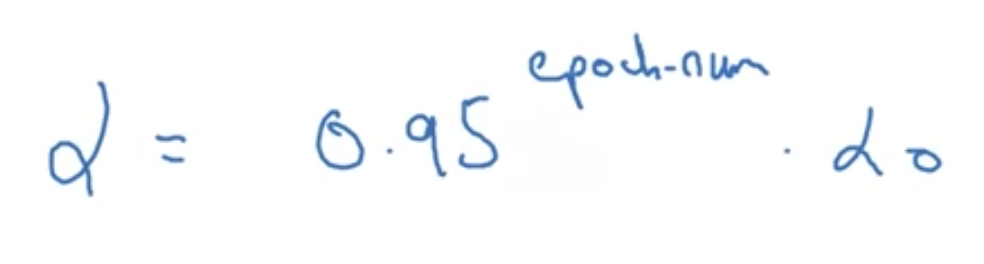

如何调参: 怎么对重要的超参数进行搜索.

见图, 重要程度: 红色 > 黄色 > 紫色.
- 超参空间中随机搜索, 且随机取样的方式要考虑数值尺度, 而不能直接线性地随机采样.
比如你认为学习率范围在 0.0001 ~ 1之间, 那么应该如下随机采样:
- 对区间取log得到: -4 ~ 0
- 在-4 ~ 0 上随机取值 (-4 + 4 * np.random.rand())
- 得到随机采样 = np.power( 10, (-4 + 4 * np.random.rand()))
- 特别地, 对指数加权平均的beta超参数进行随机采样, 尤其应该采用如上的采样方式. (因为平均了1/(1-beta)个数据, 可知beta在趋近1时, 非常敏感, 此时应该加大采样密度.)
比如你认为beta范围在 0.9 ~ 0.999之间, 那么应该如下随机采样:
- 1-beta范围在0.0001 ~ 0.1之间
- 对1-beta随机采样得到: np.power( 10, (-4 + 3 * np.random.rand()))
- 得出 beta = 1- np.power( 10, (-4 + 3 * np.random.rand()))
批量归一化batchnorm
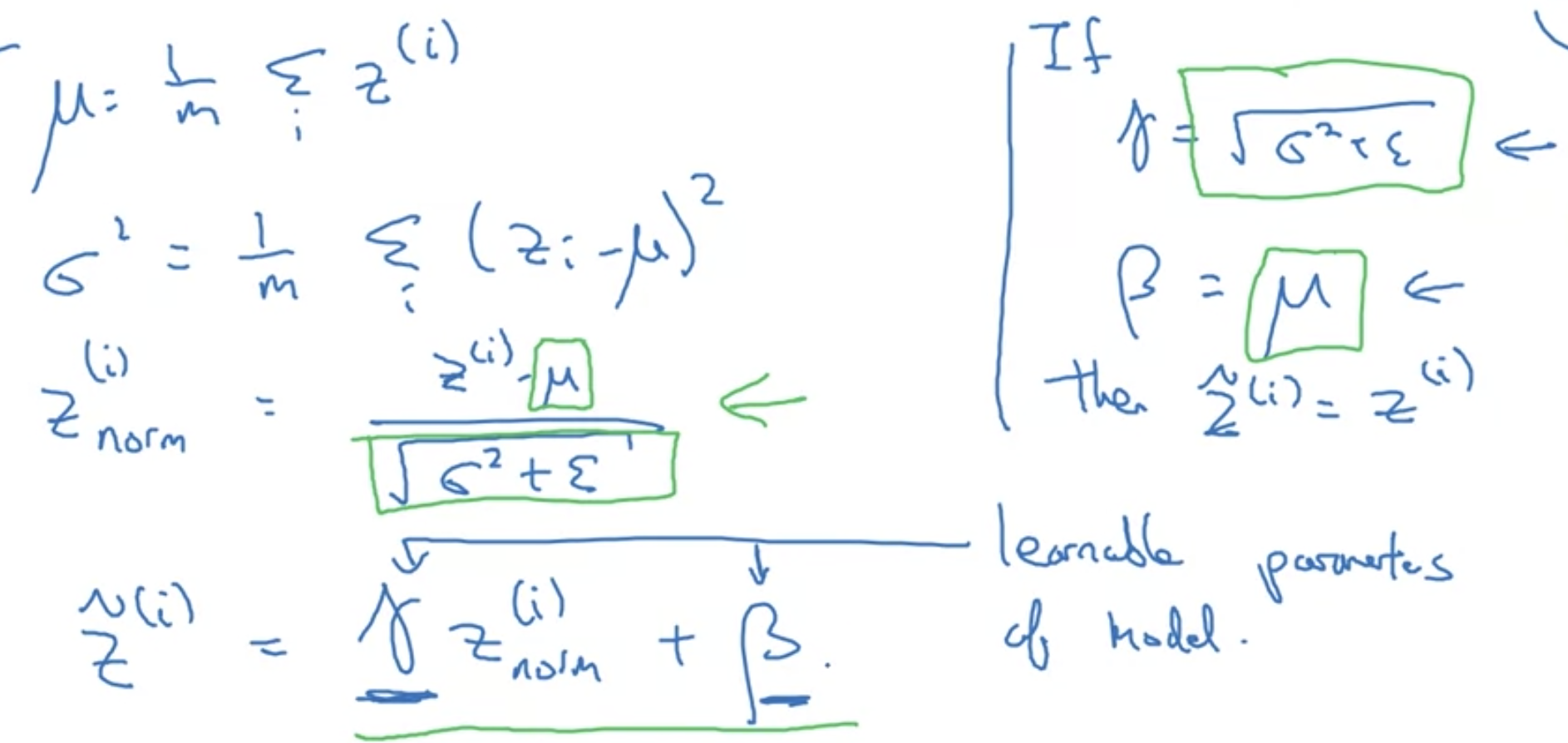
- 具有可学习参数𝛾和𝛽的batchnorm被称为仿射变换的batchnorm. 𝛾和𝛽增加了我们对均值和方差的控制和偏差修正等(比如在mini-batch场景下). 而且, 仿射变换的batchnorm因为有可学习的𝛽存在, 我们完全可以删除模型参数beta.
- 在理论上, 如果批量归一化没有用, 𝛾和𝛽甚至能通过学习来消除批量归一化的操作.(见图右侧)
- batchnorm同样也适用于momentum,RMSprop,adam优化算法, 但注意: 这些优化算法采用不同于梯度下降的其他更新方式, 于后细说.
注: 对于mini-batch来说, 一般测试集上的归一化所使用的均值或方差, 求于之前每个mini-batch的均值或方差的指数加权平均
batchnorm为什么奏效?
- 削弱了前后层之间的耦合, 限制了每一层的参数更新, 也让每一层的学习更稳固与独立.
我们知道, 学习了X到Y的映射, 但一旦X发生改变, 又要重新学习映射. 不仅如此, 模型的数据分布还随着协变量covariate的变化而变化的. 在神经网络中, 隐层的神经元作为协变量, 同时也做为后续层的输入值, 它无时无刻不在影响着其之后层的数据分布, 当然, 也影响了模型的数据分布. 那么加入BN到底起到什么效果呢? 答: 加入BN之后, 削弱了前后层之间的耦合, 使得协变量的变化对于数据分布的影响变得有限了, 也让每一层的学习更稳固与独立, 所以有效提升了模型的学习速度.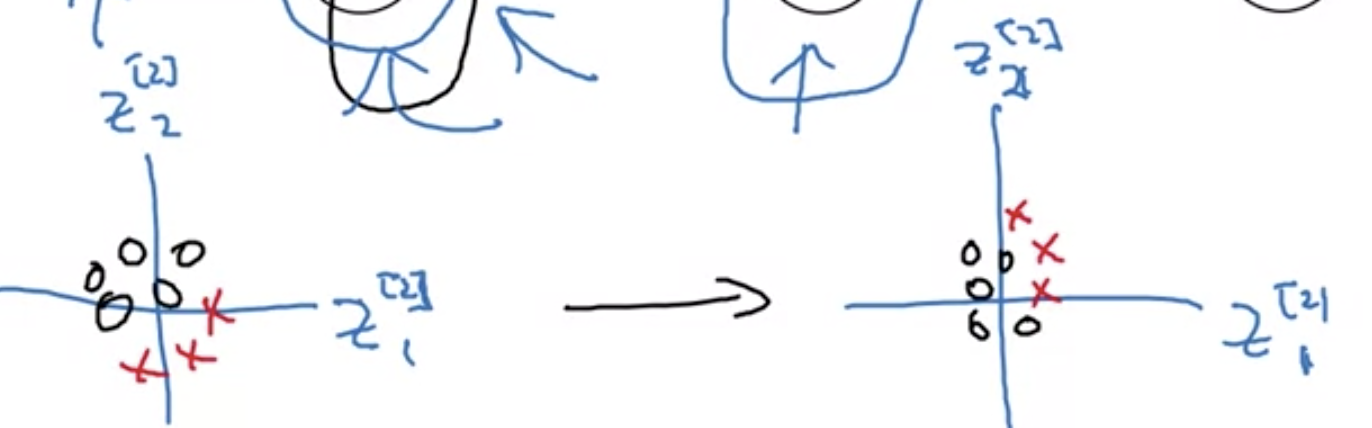
前后层的数据, 无论它们如何变化, 始终有相同的均值与方差的限制
- 轻微的正则化效果(mini-batch下)
对mini-batch求计算的均值和方差是有偏差的, 即增加了隐藏层的噪声, 所以起到了正则化的效果. 具体原因同dropout一样, 这些噪声的出现, 让后续的隐藏单元不会过度依赖其它隐藏单元, 而倾向于让参数变得更小.(注: 更大的mini-batch size 意味着更少的噪声, 正则化效果也会更差)
多分类任务与softmax激活函数
softmax激活函数的特别之处: 不同于sigmoid等, 它接受向量,需要对输出归一化, 也输出向量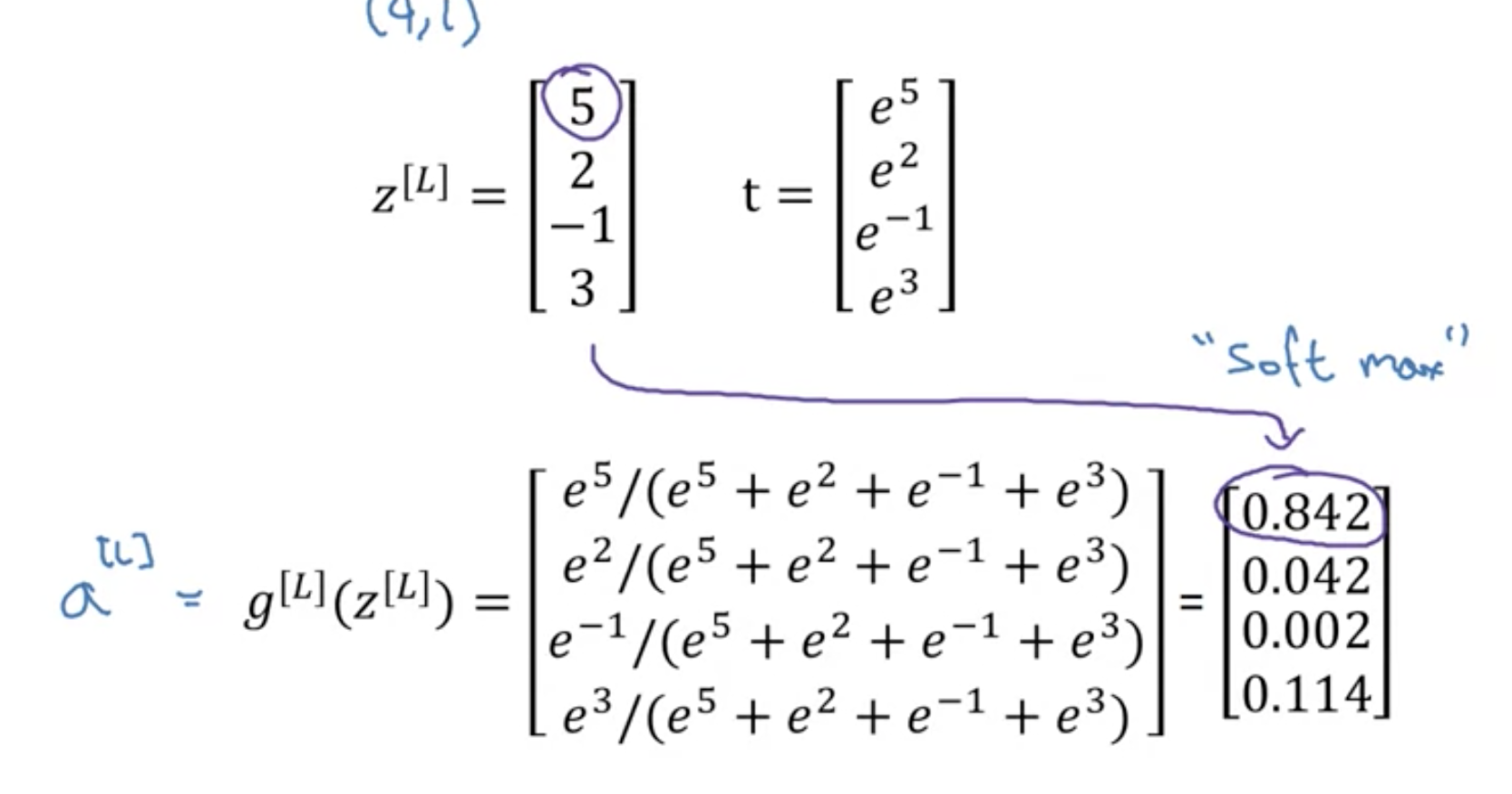
多分类网络的输出为 p(分类1 | x) , p(分类2 | x) ,…., p(分类n | x)
损失函数如下:
注: 最小化softmax的损失函数, 与用于二分类的逻辑回归的损失函数一样, 本质是某种形式的极大似然估计

若有收获,就点个赞吧
0 人点赞
