[第三部分]结构化机器学习项目
如何进行实验: 调参的4个阶段(正交化调参经验)

上图, 讲述了”正交化”调参的经验, 即上图中4个阶段, 它们之间是相对独立的, 分别对应4组旋钮 (注: 不建议设置提前停止这个参数). 在前3个阶段, 我们关注代价函数的降低; 最后一个阶段, 我们关注代价函数或开发集的设计是否合理.
如何进行实验: 单一评估指标, dev\test set, train set
由于不同模型的各项指标非常复杂, 必须要设计评估模型好坏的单一评估指标, 这些指标要在train\dev\test上记录. (注: 均值, F1-score等就是单一评估指标). 另外, 这个单一评估指标可能需要反复修改, 因为还要考虑阈值,唤醒词, 用户偏好等等.

注: 关于如何用户偏好, 可以添加权重w, 比如在分类网络中, 可以将色情图片归类错误的惩罚更大.
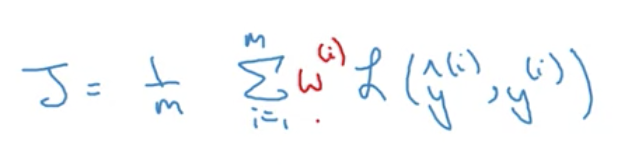
设计dev\test set….将开发集和测试集放在同一分布. 建议: 随机打乱再分开发集和测试集.

根据实际反馈, 考虑训练集是否有问题, 并再次修改1,2步骤

如何进行实验: 误差分析 (avoidabel)bias和方差如何解决?
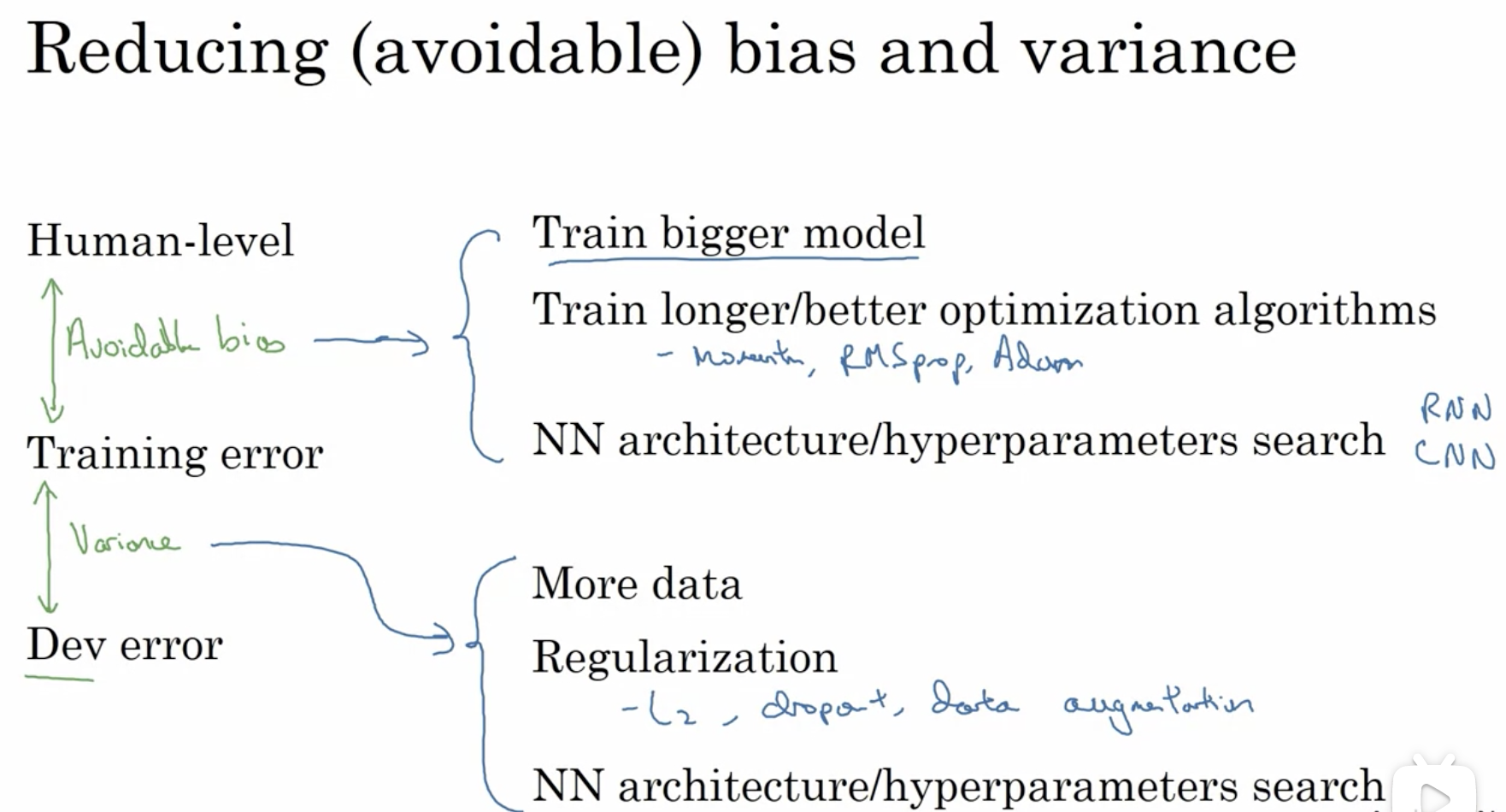
上图: 确定好human-level error(将人类的表现视为贝叶斯最优)之后, 将人类与训练集上的偏差定义为可忽略偏差. 在进行实验室时, 我们应该辨别目前应该专注降低可忽略偏差还是降低方差.
(可忽略)偏差和方差的解决方案见上图右
注: 以上是数据集之前同分布的情况, 当不同分布时可能有数据不配问题, 其解决方案见后续
如何进行实验: 快速建立系统, 不断迭代.

简单说: 按照左边这套步骤, 快速建立baseline, 然后不断迭代.
如何进行实验: 在train set和dev/test set上, 如何处理数据集的分布不同的情况?

如上图, 你拥有大量的高清图片, 以及不多的低清图片, 但是在实际场景下, 用户普遍使用低清图片来使用你的模型. 那么如何设置数据集呢? 答: 关键在于dev/test set应该瞄准真正的目标, 所以应该先用低清图片(真正的目标)来作为dev/test set, 剩余的全部高清和少量低清图片作为train set.
如何进行实验: 更全面的误差分析(考虑数据不匹配问题)

在解释上图之前, 先看看为什么要使用Train-dev error? 以及它是什么.
Train-dev set 是什么? 有什么用? 答: 它和训练集同分布,但是不进行训练, 充当开发集的角色. 目的是: 通过比较train error 和 train-dev error, (由于两者同分布)便可以反映方差问题(模型本身的泛化性问题). 同时, train-dev error 与 dev error 的比较, 便反映了数据不匹配问题Data missmatch(数据集之间的数据分布问题).
注: 一般情况下,human-level error、training error、training-dev error、dev error以及test error的数值是递增的,但是也会出现dev error和test error下降的情况。这主要可能是因为训练样本比验证/测试样本更加复杂,难以训练
解决方案:
- 开发集过拟合问题: 采用更大的开发集. (注, 如何判断开发集过拟合? 答: 由于开发集和测试集同分布, 如果Test error >> Dev error, 那么只能是开发集过拟合)
- 偏差和方差问题: 解决方案见上
- 数据不匹配问题(解决思想: 使开发集和训练集的数据分布尽可能相似)
- 人工合成数据, 使得开发集更相似于训练集.
合成车内音频
计算机图像学合成汽车图(左边两幅图)
迁移学习

上图: 在已训练好的语音识别模型中, 通过修改最后一层网络, 来训练语音唤醒系统.
- 迁移学习的作用: 将任务A中学到的信息迁移到任务B中, 它在少量数据的情况下, 利用已训练好的其他相似任务的模型(预训练模型), 来进行再学习.
- 迁移学习的适用: 必须在预训练模型本身已经做得很好的前提下, 这需要预训练模型有更大的数据量作为支撑.
多任务学习
用一个神经网络学习多个不同任务(这些任务共享底层的特征), 能比单独训练这些任务时更好的表现.
典型的应用: 计算机视觉的物体检测.
端到端深度学习
即输入数据, 输出结果, 中间没有独立的分段训练, 不将问题分段. (个人通俗表述)
缺点是: 需要大量数据支撑.
[特别专栏]大佬访谈
深度学习之父
- 生成对抗网络是深度学习中最新最重要的想法。
- “胶囊”的想法,比目前的神经元容纳更多的参数。
- 入门DL建议
- 多读论文,但是别太多。对于有创意的人应该少读一部分,然后发现你认为所有人都错了的东西。坚持自我的原则,如果直觉还不错就坚持。
- 不要停止编程
- 如过你找到一个想法,其他人都觉得荒谬那就太好了,可能是好想法。
- 新研究生建议
- 找到与你意见一致的导师。要是导师对你做的不感兴趣,你会得到没啥用的建议。
- 对于读博、顶尖公司
- 自动解决问题是变革。训练计算机将会和编程一样重要。
- 增强学习很有趣
- 深度学习是未来
生成对抗网络GAN之父、深度学习花书的作者
- GAN可做的有很多,处于十字路口。例如半监督学习、安全性领域。
- GAN还不够稳定,没有深度学习那样可靠。
- 给AI学习者的建议
- 现在做AI不一定要博士学位或者各种证书,在github上写好代码项目就是很好的被注意的机会。
- 初学者在github上写代码?比如,跟着花书练习,并且同时做一个项目也是重要的,这些项目最好是你感兴趣的领域。
890年代甚至没有互联网, 但那些890年的术语, 现在看来, 已经非常流行, 所以我很难想象, 他们如何在低级的硬件软件上进行实验, 以及如何渡过的神经网络的那些寒冬.

若有收获,就点个赞吧
0 人点赞
