- [第一部分]神经网络
- GRADED FUNCTION: forward_propagation
- GRADED FUNCTION: backward_propagation
- GRADED FUNCTION: nn_model
- [第二部分]改善深层神经网络
- 训练集train,开发集Dev,测试集test
- 如何诊断高偏差和高方差吗?
- 防止过拟合: L1正则化容易使模型参数稀疏
- 防止过拟合: L2正则化又被称为权重衰减(指学习率的权重, 起到学习率衰减的效果).
- 防止过拟合: 正则化能防止过拟合呢?
- 防止过拟合: 理解Dropout
- Normalize与梯度下降的关系
- 梯度消失和梯度爆炸
- 梯度检查Grad check
- mini-batch
- 指数加权平均
- 动量梯度下降momentum
- RMSprop
- Adam (momentum和RMSprop的结合)
- 学习率衰减(实现函数有很多,下面举几个例子)
- 如何调参: 怎么对重要的超参数进行搜索.
- 批量归一化batchnorm
- batchnorm为什么奏效?
- 多分类任务与softmax激活函数
- [第三部分]结构化机器学习项目
- [特别专栏]大佬访谈
- [第二部分]改善深层神经网络
[第一部分]神经网络
sigmoid

所谓激活函数,其实就是我们将某些数值定义为某种语义…比如在sigmoid激活函数中,我们把数值的大小定义为可能性的高低, 数值越小我们定义越为不可能, 数值越大我们定义为越可能….所以, 发现了吗?
- 通过激活函数,我们将冰冷的数值表达为了我们更方便理解的语义信息.
- 至于为什么sigmoid函数的公式是这样的吗? 无非这种公式在将冰冷数值表达为语义信息方面做得更好.
代价(损失)函数与梯度下降

如上是逻辑回归的损失函数在进行梯度下降来找到更好的模型参数…
为什么需要损失函数呢? 这是因为在前面的激活函数中,我们已经能够将冰冷的数值表达我更容易理解的语义信息, 但是仍然有个问题, 模型虽然给出了语义, 但它给出的语义并不是正确的呀 ? 所以呢: 这时候就需要机器学习起来了,让它输出的语义信息变得更准确, 甚至希望准确到, 让我们可以无条件相信它给出的答案… 但是, 怎么做呢? 于是就出现了损失函数, 损失函数的目的就是去表达模型的好坏(尽管, 这种评价可能并不完全正确), 换句话说:
- 我们让损失函数的高低与模型的每一个可学习的参数都是有联系的, 于是乎, 我们只需要通过某种方式(比如梯度下降)让损失函数变得低, 以调整模型参数, 进而让模型变得更好.
- 但是, 你逻辑回归的损失函数为什么是这样的公式吗? 第一, 该公式的确能比较好地表达模型的好坏; 第二, 该函数是“凹函数”, 在进行梯度下降时, 能更容易更快地收敛到或接近全局最优点.(注: 该特性, 也让逻辑回归的损失函数几乎适用所有初始化方式)
- 综上: 损失函数的设计尤为关键, 因为, 在训练模型的过程中, 我们不仅要依靠损失函数来表达模型的好坏, 而且还要让损失函数自身更容易收敛到全局最优点. 另外, 有时会对损失函数采用取对数等方式, 可能与加快计算或极大似然估计等有关.
计算图与梯度下降
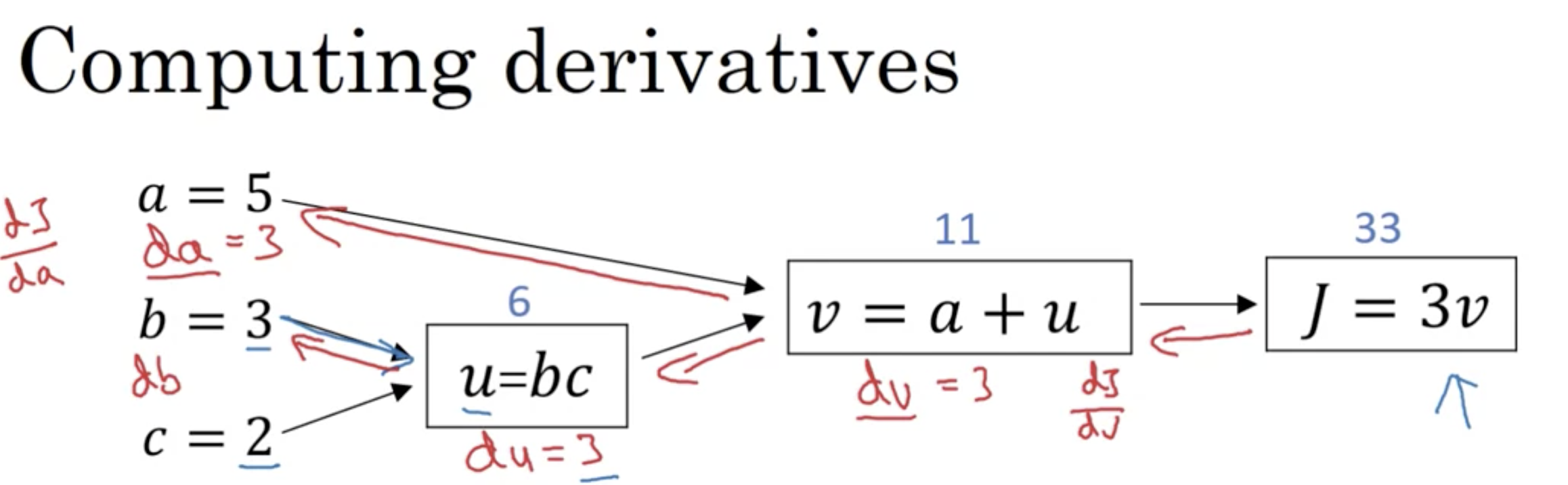
如上的计算图…
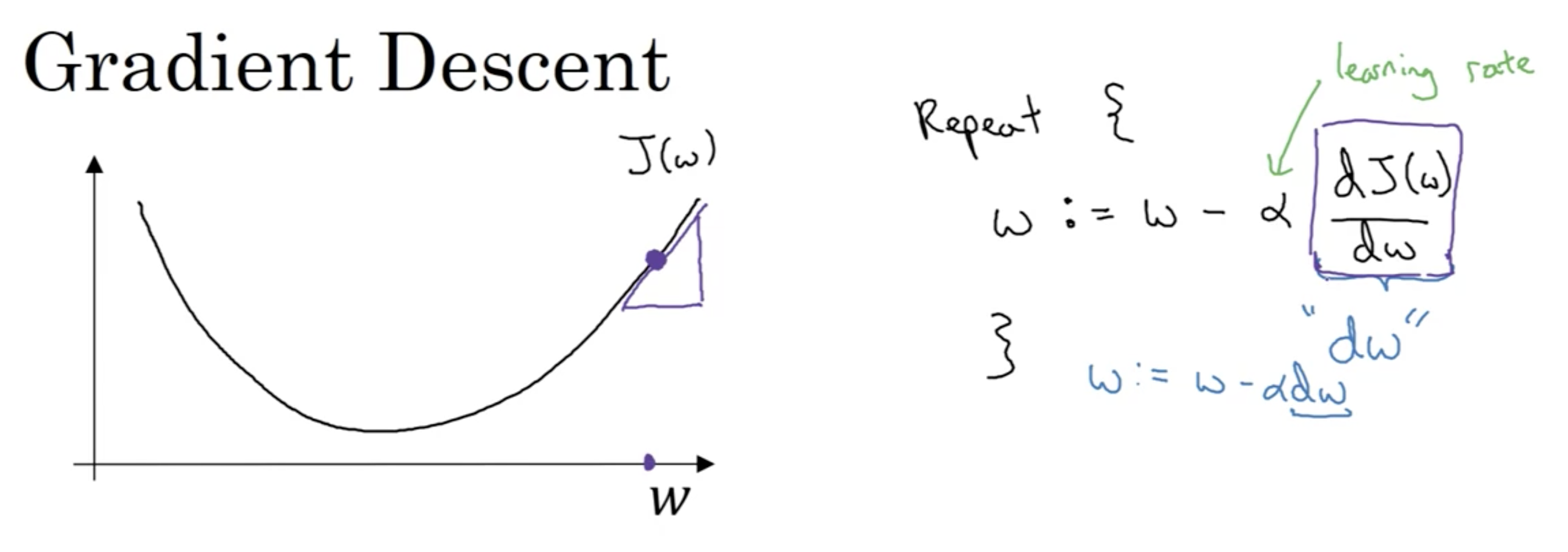
首先, 梯度是什么意思呢? 梯度下降又是什么意思呢? 梯度又是怎么得到的呢?
- 梯度的定义(最大方向导数): 一个向量,表示某一函数在该点处的方向导数沿着该方向取得最大值,即函数在该点处沿着该方向(此梯度的方向)变化最快,变化率最大. 注意梯度与偏导数的公式联系, 见下:

- 梯度下降: 顾名思义, 就是沿着梯度的方向, 以最快地下降到损失函数的底部. (为什么要到达损失函数的底部在前面已经说过了)
- 梯度计算: 根据微积分的链式求导法则, 我们能知道在每个参数在损失函数的当前点的一阶偏导数, 由这些参数的一阶偏导数构成的向量即是梯度.
- 怎么实现损失函数的梯度下降呢? 其实并不是直接用梯度去更新所有参数, 而是在损失函数构成的空间中, 每个参数都在该空间中的一个维度上, 我们只要让每一个参数都”沿着自身维度的方向和其一阶偏导数”(注: 可理解为该参数相对于自身的梯度)(以及学习率)去更新自身,全部的这些改变, 最终体现出来就是损失函数变小了.
- 如下, m个样本时的梯度下降(左右各为遍历版本和向量化的版本):

numpy向量的一点说明

如上所示, don’t use “rank 1 array”, 其既不是行向量, 也不是列向量. 所以为了避免不必要麻烦, 我们尽量使用列或行向量形式. 另外, 日常使用断言,能有效避免尺寸不匹配问题.
逻辑回归损失函数的数学解释…
图1: 
由图1, 可知到逻辑回归的损失函数L被定义为logp(y|x), 而p(y|x)又可等价表示为上图中的数学公式 , 该定义会在图2中用到.
图: 2
如上,以m个样本的逻辑回归的损失函数为例
首先, 基本的数学原理是极大似然估计, 在逻辑回归的损失函数中, 具体是负对数极大似然估计. (注: 极大似然估计方法(Maximum Likelihood Estimate,MLE)也称为最大概似估计或最大似然估计,是求估计的另一种方法.我们通过已经给定的样本x1~xn(独立同分布)来估计参数, 该估计的前提背景是我们认为现有的样本当前分布中最常见的样本)
如下是似然函数的定义: ![[前三部分合集] - 图10](/uploads/projects/theta@oiog2u/6aa0dba2ad7e17c8497f1a8359a11ddf.svg)
在当前背景下, 对数似然函数为下式, 其目的是根据样本x们来估计参数y们, 本质的估计方法为极大似然估计.
在极大化似然函数时, 对其两边取对数不仅能简化运算, 而且不会影响参数y的估计. 同时, 再对上式的一边取负, 即刻, 我们便将”极大化似然函数等价为极小化对数似然函数来估计参数y”, 采用梯度下降来做这样的极小化操作. (注: 当前背景下, 需要估计参数是yhat和y)
再结合图1中损失函数的定义” L=logp(y|x) “, 得到代价函数如下: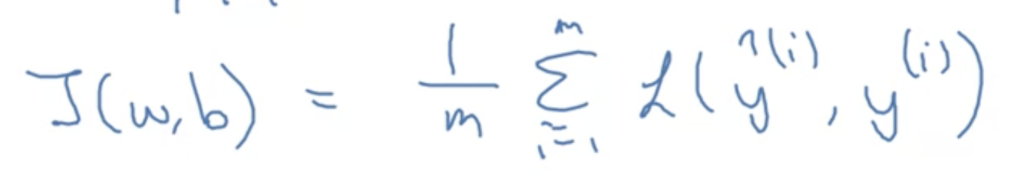 (注: 上式的1/m只是一个放缩系数而已, 是因为这里求平均损失而已, 它也可取其他值, 这不是关键)
(注: 上式的1/m只是一个放缩系数而已, 是因为这里求平均损失而已, 它也可取其他值, 这不是关键)
神经网络的运算及其向量化

理解上图中的
是不难的. 由每个WiTX都是对输入x1 ~ x3的线性组合得到一个输出Zi , 而且输出Z保持和输入X同为列向量(其元素是行向量)…可知输出的尺寸.

激活函数(详细内容见后续)
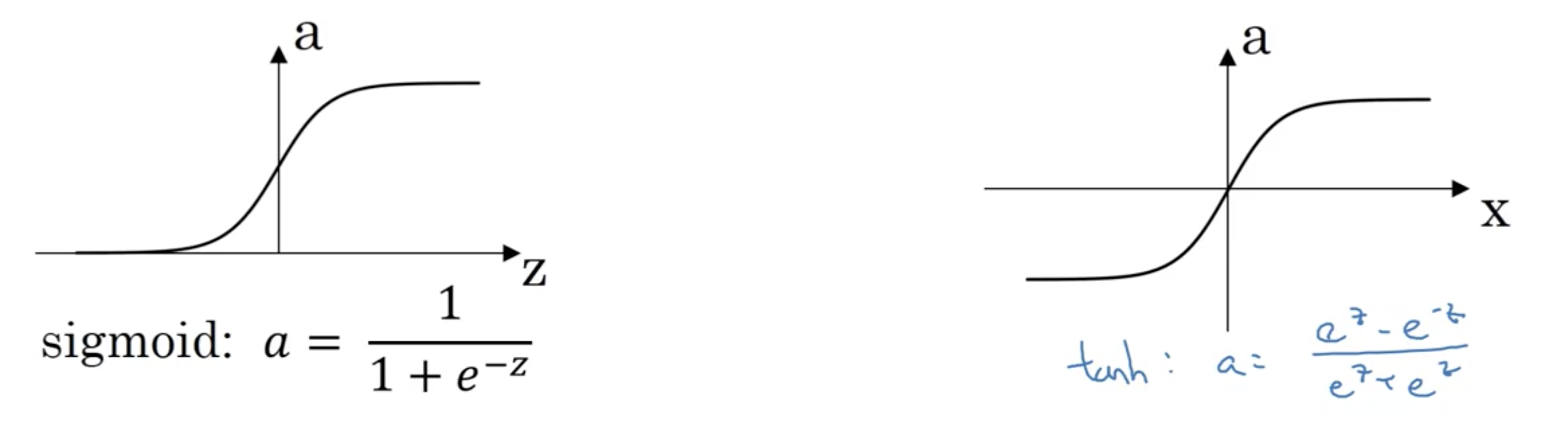
上图, sigmoid和Tanh.
从数值优化上讲, 激活函数至少要是非线性的.
对于二分类任务, 建议隐藏层使用Tanh,relu等激活函数, 仅仅在输出层上使用Sigmoid激活函数(注: 多分类任务上用softmax替代Sigmoid).
- 从数值优化上讲, Tanh总是比sigmoid更优秀, 为什么呢? 答: 因为Tanh会使得数值的均值趋于0, 这会使得下一层更容易训练…另外, tanh在特征相差明显时的效果会很好,在循环过程中会不断扩大特征效果.
- 从语义上讲, 用sigmoid表达概率值的作用是肯定的
sigmoid和TanH的共同缺点: 两边的梯度很低, 有梯度消失问题.
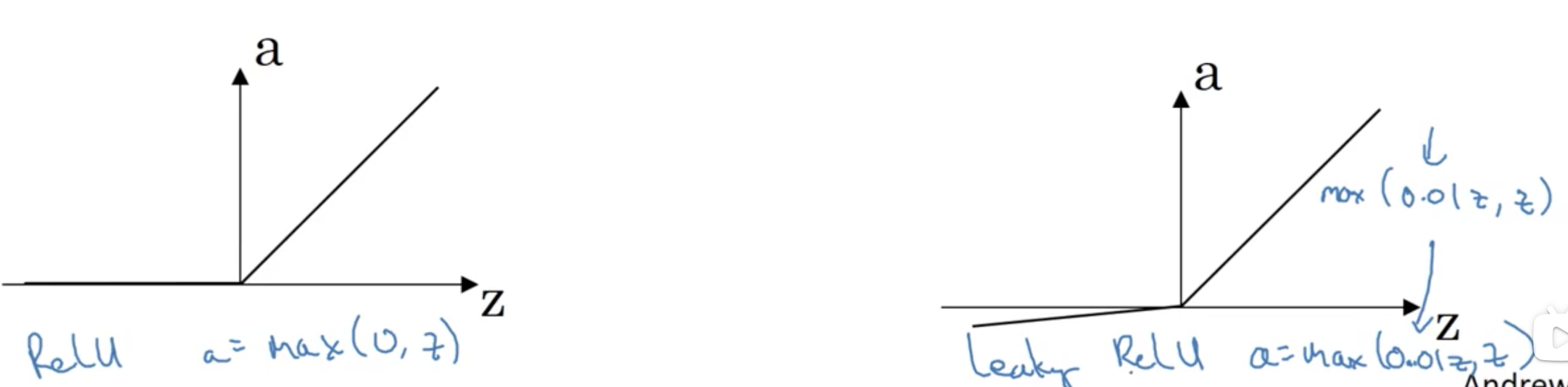
上图: relu和leakyrelu
relu和leakyrelu解决了Tanh和sigmoid的关于梯度的缺点, leakyrelu相比relu解决了z<0时的神经元死亡问题.
目前, relu和leakyrelu被主流所推荐使用.
参数随机初始化
w = np.random.randn(…) * 缩小系数. b = np.zero(…)
对于浅层网络(深层另做讨论), 缩小系数一般取0.01, 原因是我们希望该层计算出的z能接近0,以在大部分激活函数下都能确定很好的学习梯度.
解释一个误区: 权重不能被初始化为0的原因(哪怕只有一层被初始化为0), 并不是以为你输出z=0, 而是因为”对称失效问题”, 这将导致该隐层的不同神经元都肩负着相同的计算功能, 这种影响又将作用之后的神经元上, 进而导致网络学得一般. 其实, 随机初始化也是解决上述”对称失效问题”的关键
为什么网络的”深度”是有效的?

上图, 从提取低级信息—>到提取更高级信息的角度给出直观解释. 另外, “深度”比’宽度”更容易计算
正向与反向传播的细节
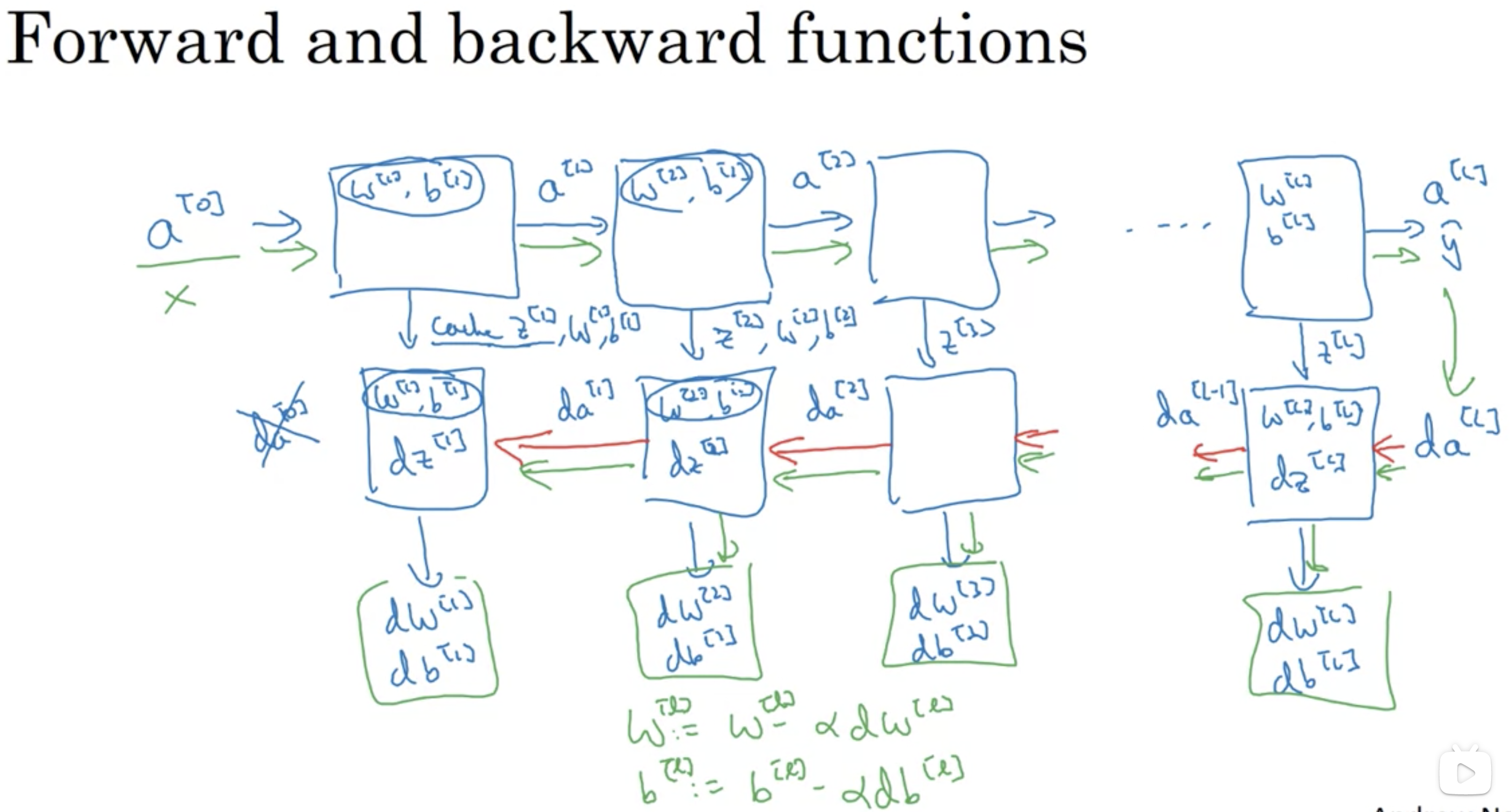
上图: 蓝色为正向传播, 红色为反向传播. 绿色代表一次梯度下降.
上方的图, 在正向传播的同时要缓存Z, 目的是后续计算反向传播. 其实很简单, 如下图, 在反向传播中, 我们求梯度的顺序. 
下面是正向传播的代码, 其返回正向传播输出A的同时, 还返回了Z的缓存
# GRADED FUNCTION: forward_propagationdef forward_propagation(X, parameters):"""Argument:X -- input data of size (n_x, m)parameters -- python dictionary containing your parameters (output of initialization function)Returns:A2 -- The sigmoid output of the second activationcache -- a dictionary containing "Z1", "A1", "Z2" and "A2""""# Retrieve each parameter from the dictionary "parameters"### START CODE HERE ### (≈ 4 lines of code)W1 = parameters["W1"]b1 = parameters["b1"]W2 = parameters["W2"]b2 = parameters["b2"]### END CODE HERE #### Implement Forward Propagation to calculate A2 (probabilities)### START CODE HERE ### (≈ 4 lines of code)Z1 = np.dot(W1,X) + b1A1 = np.tanh(Z1)Z2 = np.dot(W2,A1) + b2A2 = sigmoid(Z2)### END CODE HERE ###assert(A2.shape == (1, X.shape[1]))cache = {"Z1": Z1,"A1": A1,"Z2": Z2,"A2": A2}return A2, cache
浅层神经网络的numpy实现
随机初始化参数….返回W和b矩阵
# GRADED FUNCTION: initialize_parametersdef initialize_parameters(n_x, n_h, n_y):"""Argument:n_x -- size of the input layern_h -- size of the hidden layern_y -- size of the output layerReturns:params -- python dictionary containing your parameters:W1 -- weight matrix of shape (n_h, n_x)b1 -- bias vector of shape (n_h, 1)W2 -- weight matrix of shape (n_y, n_h)b2 -- bias vector of shape (n_y, 1)"""np.random.seed(2) # we set up a seed so that your output matches ours although the initialization is random.### START CODE HERE ### (≈ 4 lines of code)W1 = np.random.randn(n_h,n_x) * 0.01b1 = np.zeros((n_h,1))W2 = np.random.randn(n_y,n_h) * 0.01b2 = np.zeros((n_y,1))### END CODE HERE ###assert (W1.shape == (n_h, n_x))assert (b1.shape == (n_h, 1))assert (W2.shape == (n_y, n_h))assert (b2.shape == (n_y, 1))parameters = {"W1": W1,"b1": b1,"W2": W2,"b2": b2}return parameters
def forward_propagation(X, parameters): “”” Argument: X — input data of size (n_x, m) parameters — python dictionary containing your parameters (output of initialization function)
Returns:A2 -- The sigmoid output of the second activationcache -- a dictionary containing "Z1", "A1", "Z2" and "A2""""# Retrieve each parameter from the dictionary "parameters"### START CODE HERE ### (≈ 4 lines of code)W1 = parameters["W1"]b1 = parameters["b1"]W2 = parameters["W2"]b2 = parameters["b2"]### END CODE HERE #### Implement Forward Propagation to calculate A2 (probabilities)### START CODE HERE ### (≈ 4 lines of code)Z1 = np.dot(W1,X) + b1A1 = np.tanh(Z1)Z2 = np.dot(W2,A1) + b2A2 = sigmoid(Z2)### END CODE HERE ###assert(A2.shape == (1, X.shape[1]))cache = {"Z1": Z1,"A1": A1,"Z2": Z2,"A2": A2}return A2, cache
- 3. 代价函数(逻辑回归)...计算CrossEntropyLoss(predictions, labels)...返回cost
```python
# GRADED FUNCTION: compute_cost
def compute_cost(A2, Y, parameters):
"""
Computes the cross-entropy cost given in equation (13)
Arguments:
A2 -- The sigmoid output of the second activation, of shape (1, number of examples)
Y -- "true" labels vector of shape (1, number of examples)
parameters -- python dictionary containing your parameters W1, b1, W2 and b2
Returns:
cost -- cross-entropy cost given equation (13)
"""
m = Y.shape[1] # number of example
# Compute the cross-entropy cost
### START CODE HERE ### (≈ 2 lines of code)
logprobs = Y*np.log(A2) + (1-Y)* np.log(1-A2)
cost = -1/m * np.sum(logprobs)
### END CODE HERE ###
cost = np.squeeze(cost) # makes sure cost is the dimension we expect.
# E.g., turns [[17]] into 17
assert(isinstance(cost, float))
return cost
def backward_propagation(parameters, cache, X, Y): “”” Implement the backward propagation using the instructions above.
Arguments:
parameters -- python dictionary containing our parameters
cache -- a dictionary containing "Z1", "A1", "Z2" and "A2".
X -- input data of shape (2, number of examples)
Y -- "true" labels vector of shape (1, number of examples)
Returns:
grads -- python dictionary containing your gradients with respect to different parameters
"""
m = X.shape[1]
# First, retrieve W1 and W2 from the dictionary "parameters".
### START CODE HERE ### (≈ 2 lines of code)
W1 = parameters["W1"]
W2 = parameters["W2"]
### END CODE HERE ###
# Retrieve also A1 and A2 from dictionary "cache".
### START CODE HERE ### (≈ 2 lines of code)
A1 = cache["A1"]
A2 = cache["A2"]
### END CODE HERE ###
# Backward propagation: calculate dW1, db1, dW2, db2.
### START CODE HERE ### (≈ 6 lines of code, corresponding to 6 equations on slide above)
dZ2= A2 - Y
dW2 = 1 / m * np.dot(dZ2,A1.T)
db2 = 1 / m * np.sum(dZ2,axis=1,keepdims=True)
dZ1 = np.dot(W2.T,dZ2) * (1-np.power(A1,2))
dW1 = 1 / m * np.dot(dZ1,X.T)
db1 = 1 / m * np.sum(dZ1,axis=1,keepdims=True)
### END CODE HERE ###
grads = {"dW1": dW1,
"db1": db1,
"dW2": dW2,
"db2": db2}
return grads
- 5. 更新W和b参数...计算w = w - lr*dw....返回parameters
```python
# GRADED FUNCTION: update_parameters
def update_parameters(parameters, grads, learning_rate = 1.2):
"""
Updates parameters using the gradient descent update rule given above
Arguments:
parameters -- python dictionary containing your parameters
grads -- python dictionary containing your gradients
Returns:
parameters -- python dictionary containing your updated parameters
"""
# Retrieve each parameter from the dictionary "parameters"
### START CODE HERE ### (≈ 4 lines of code)
W1 = parameters["W1"]
b1 = parameters["b1"]
W2 = parameters["W2"]
b2 = parameters["b2"]
### END CODE HERE ###
# Retrieve each gradient from the dictionary "grads"
### START CODE HERE ### (≈ 4 lines of code)
dW1 = grads["dW1"]
db1 = grads["db1"]
dW2 = grads["dW2"]
db2 = grads["db2"]
## END CODE HERE ###
# Update rule for each parameter
### START CODE HERE ### (≈ 4 lines of code)
W1 = W1 - learning_rate * dW1
b1 = b1 - learning_rate * db1
W2 = W2 - learning_rate * dW2
b2 = b2 - learning_rate * db2
### END CODE HERE ###
parameters = {"W1": W1,
"b1": b1,
"W2": W2,
"b2": b2}
return parameters
def nn_model(X, Y, n_h, num_iterations = 10000, print_cost=False): “”” Arguments: X — dataset of shape (2, number of examples) Y — labels of shape (1, number of examples) n_h — size of the hidden layer num_iterations — Number of iterations in gradient descent loop print_cost — if True, print the cost every 1000 iterations
Returns:
parameters -- parameters learnt by the model. They can then be used to predict.
"""
np.random.seed(3)
n_x = layer_sizes(X, Y)[0]
n_y = layer_sizes(X, Y)[2]
# Initialize parameters, then retrieve W1, b1, W2, b2. Inputs: "n_x, n_h, n_y". Outputs = "W1, b1, W2, b2, parameters".
### START CODE HERE ### (≈ 5 lines of code)
parameters = initialize_parameters(n_x, n_h, n_y)
W1 = parameters["W1"]
b1 = parameters["b1"]
W2 = parameters["W2"]
b2 = parameters["b2"]
### END CODE HERE ###
# Loop (gradient descent)
for i in range(0, num_iterations):
### START CODE HERE ### (≈ 4 lines of code)
# Forward propagation. Inputs: "X, parameters". Outputs: "A2, cache".
A2, cache = forward_propagation(X, parameters)
# Cost function. Inputs: "A2, Y, parameters". Outputs: "cost".
cost = compute_cost(A2, Y, parameters)
# Backpropagation. Inputs: "parameters, cache, X, Y". Outputs: "grads".
grads = backward_propagation(parameters, cache, X, Y)
# Gradient descent parameter update. Inputs: "parameters, grads". Outputs: "parameters".
parameters = update_parameters(parameters, grads)
### END CODE HERE ###
# Print the cost every 1000 iterations
if print_cost and i % 1000 == 0:
print ("Cost after iteration %i: %f" %(i, cost))
return parameters
- 7. 进行预测...集成正向传播....输入parameters和输入X, 返回正向传播的结果(即predictions)
```python
# GRADED FUNCTION: predict
def predict(parameters, X):
"""
Using the learned parameters, predicts a class for each example in X
Arguments:
parameters -- python dictionary containing your parameters
X -- input data of size (n_x, m)
Returns
predictions -- vector of predictions of our model (red: 0 / blue: 1)
"""
# Computes probabilities using forward propagation, and classifies to 0/1 using 0.5 as the threshold.
### START CODE HERE ### (≈ 2 lines of code)
A2, cache = forward_propagation(X, parameters)
predictions = np.round(A2)
### END CODE HERE ###
return predictions
[第二部分]改善深层神经网络
训练集train,开发集Dev,测试集test
- 注意: 开发集不需要太大. 因为开发集的目的是对不同的模型进行有偏评估, 其数据集大小能起到该作用即可.
- 准则: 开发集和测试集要保证在同一数据分布上. 这是因为开发集费劲全力改善模型在开发集上的性能. 这种做法尤其在诸如网页爬虫等数据质量不是很优秀的数据集上非常好用.
- 另外, 没有测试集也是可以的. 这是因为测试集的目的是提供无偏估计来评价最终选定的网络的性能, 所以如果你不需要无偏估计的话, 可以不要测试集.
- 注: 当只有训练集和开发集时, 有些人会把此时的开发集称为测试集, 但是事实上, 开发集的用词更准确.
如何诊断高偏差和高方差吗?

上图, 用训练集和开发集的误差来诊断模型在当前训练集上是否高偏差和高方差 (注: 这里假设理想偏差或贝叶斯偏差为0%)
- 如何理解”方差与偏差”, 以及它们和”过拟合与欠拟合”之间的联系呢?
- “方差与偏差”是针对模型在训练集上的表现..
- bias=E(p(x)) - f(x) , 计算预测值与真实值之间平均差异, 即一个模型在不同训练集上的平均表现与真实值的差异, 用于衡量模型是否容易欠拟合.
- variance= E((p(x) - E(p(x)))^2) 计算预测值之间的平均差异, 即一个模型在不同训练集上的平均差异, 用于衡量模型是否容易过拟合.
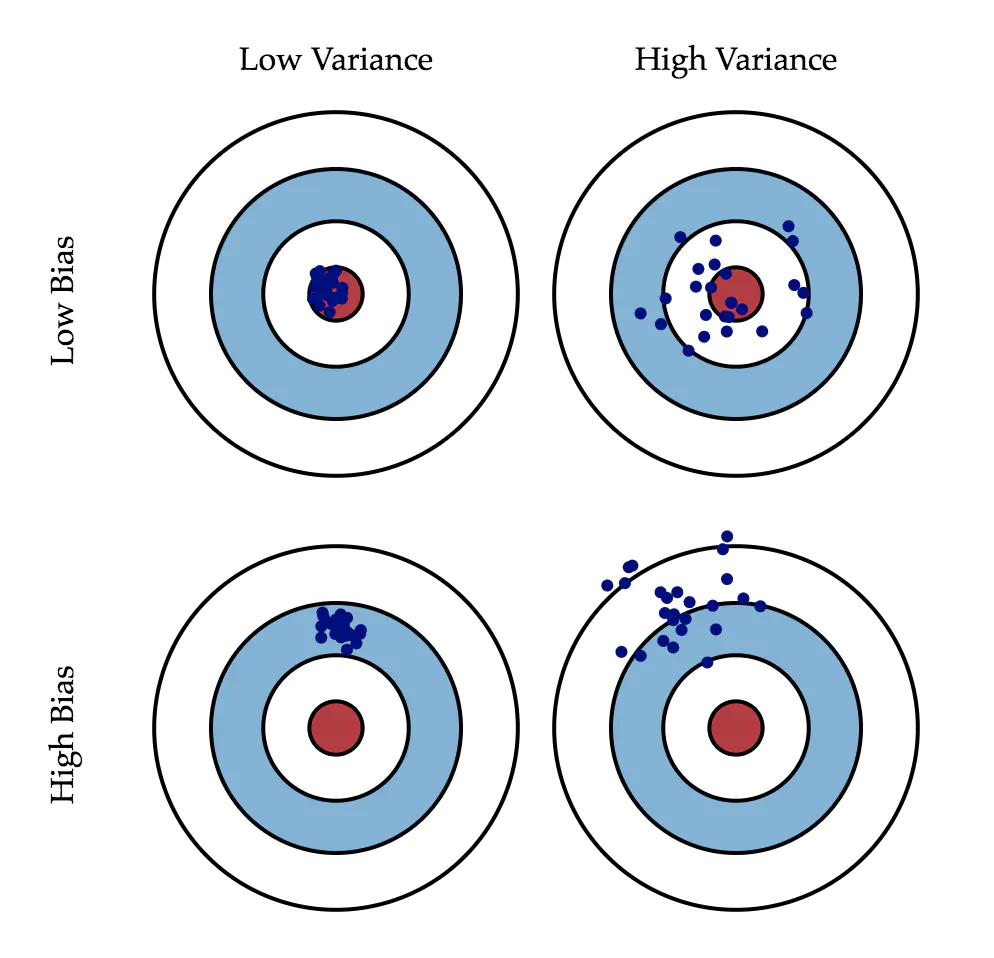
- 为什么要诊断出模型在训练集上的”方差与偏差”呢?
因为诊断结果很重要. 它直接意味着模型在测试集或实际应用下是否容易发生过拟合或者欠拟合, 它强烈暗示了当前模型的泛化能力. 同时, 它还能指导我们接下来如何调整, 比如增加数据量,减化模型参数,正则化等等手段.
- 如何诊断训练集上是否高偏差或高方差呢?
| Train set error | 低 | 高 | 高 | 低 | | —- | —- | —- | —- | —- | | Dev set error | 高 | 高 | 很高 | 低 | | 此时模型的泛化性 | |
|  |
| 
 |
|  |
| 诊断结果: | 高方差 | 高偏差 | 高偏差/高方差 | |
|
| 诊断结果: | 高方差 | 高偏差 | 高偏差/高方差 | |
防止过拟合: L1正则化容易使模型参数稀疏

上图: 满足正则化条件,实际上是求解蓝色区域与黄色区域的交点.
防止过拟合: L2正则化又被称为权重衰减(指学习率的权重, 起到学习率衰减的效果).

上图, 我们对代价函数进行了L2正则化,以防止过拟合. 在计算反向传播后发现, 正则项的梯度对于更新参数的方式, 无异于做学习衰减的方式.
防止过拟合: 正则化能防止过拟合呢?


其实质是收缩权重防止过拟合. 从神经元角度讲, 正则化会收缩模型权重参数, 甚至让部分参数等于0, 神经元的输出Z也随之同等变化. 这让神经单元的效果变差了;
从激活函数的角度上讲, 正则化会收缩模型权重参数 使得逐层的线性变换能力差了, 最终模型的拟合能力也差了.
防止过拟合: 理解Dropout
其实质仍是收缩权重来防止过拟合.
由于神经元随机失活的机制, 模型会倾向于”把鸡蛋更匀地放在不同篮子里”, 该过程通过对每个神经元使用更小的权重参数来实现, 这有利于压缩这些权重的平方范数(平方和).
Normalize与梯度下降的关系
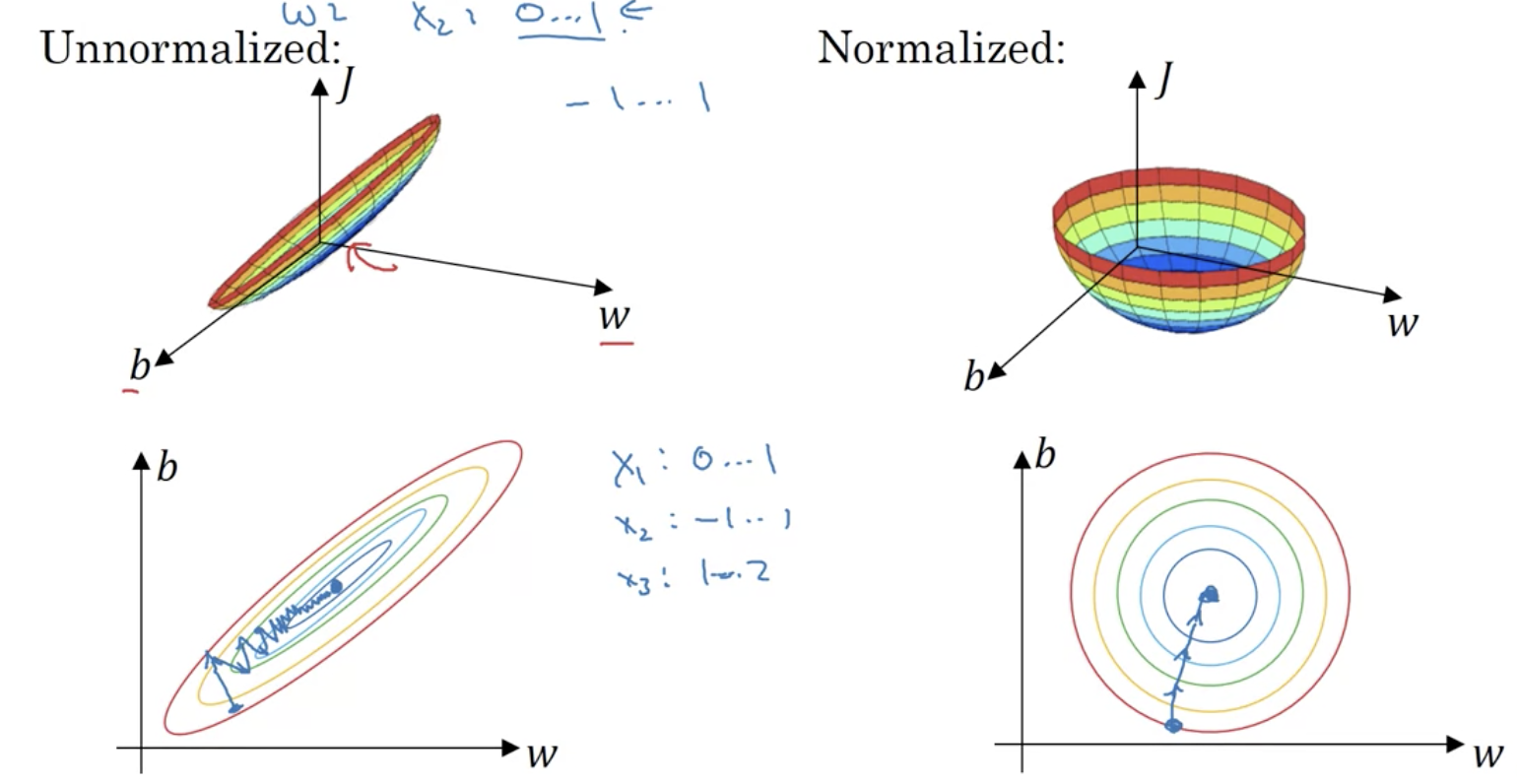
上图, 对数据进行归一化之后更利于收敛, 因为它改善了梯度的方向, 使之更稳定, 梯度下降也更快.
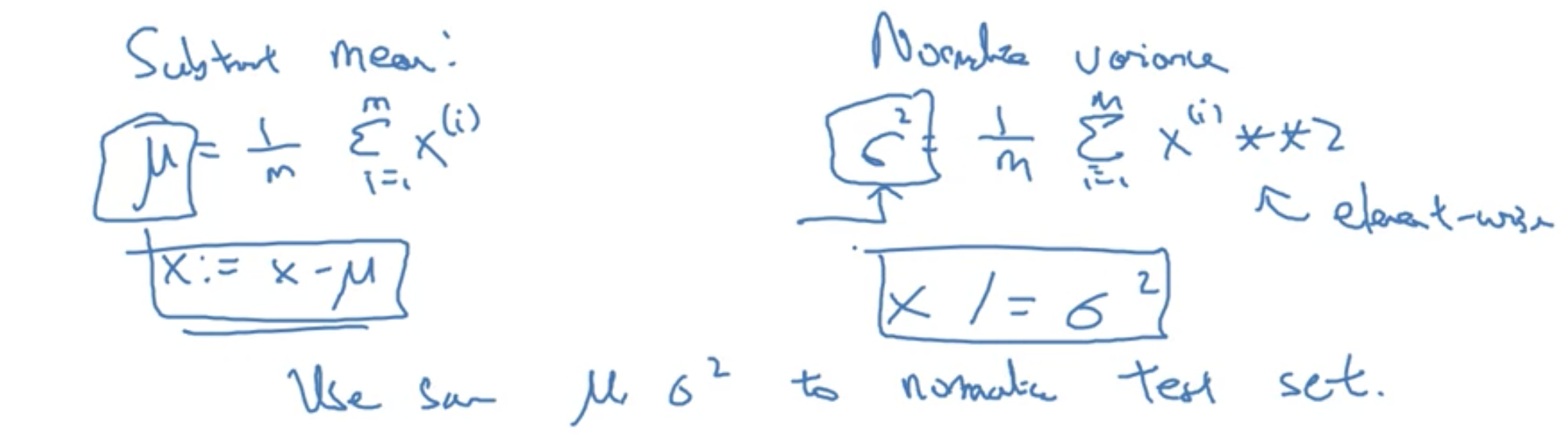
上图是均值和方差的计算方式. 以及归一化的计算过程. 值得注意的是: 在开发集和测试集上进行normalize, 必须使用训练集上的均值和方差.
梯度消失和梯度爆炸

上图, 如果不考虑激活函数…计算每一层的权重矩阵相乘.
梯度消失和梯度爆炸的启示是: 一定要好好初始化参数. 当初始化不正确时, 权重矩阵的相乘结果可能无限趋于0或趋于无穷, 当进行反向传播时, 体现在梯度的消失与梯度的爆炸.
- 下面看如何更好地初始化参数

上图, 根据输入一个神经元的特征数(或者说上一层的神经元个数), 和具体的激活函数, 来确定一个缩小系数. 另外, 这是默认的初始化方式, 你也可以再乘上一个超参数, 然后不断调优.
梯度检查Grad check


梯度检查的目的: 检查手写的反向传播代码是否有错误.
梯度检查的过程: 使用数值方法得到近似梯度(误差为ℇ), 然后计算该近似梯度与反向传播代码返回的梯度之间的误差ℇ’. 检查标准为: ℇ’越接近ℇ越好, 如果相差明显, 就说明反向传播代码有问题. 注: 如果你跟我一样, 用Pytorch这类自动求导的工具, 不需要关注梯度检查. 另外, 还有许多检查技巧, 由于自己基本不会涉及梯度检查, 这里不再补充.
相关代码如下:
def gradient_check_n(parameters, gradients, X, Y, epsilon=1e-7):
"""
检查backward_propagation_n是否正确地计算了正向传播的成本输出的梯度。
Arguments:
parameters --包含参数的python字典 "W1", "b1", "W2", "b2", "W3", "b3":
grad -- backward_propagation_n的输出包含参数的成本梯度。
x -- 输入数据点,形状(输入大小,1)
y -- true "label"
epsilon -- 用公式对输入进行微小位移计算近似梯度
Returns:
difference -- 近似梯度与反向传播梯度之间的差异。
"""
# Set-up variables
parameters_values, _ = dictionary_to_vector(parameters)
grad = gradients_to_vector(gradients)
num_parameters = parameters_values.shape[0]
J_plus = np.zeros((num_parameters, 1))
J_minus = np.zeros((num_parameters, 1))
gradapprox = np.zeros((num_parameters, 1))
# Compute gradapprox
for i in range(num_parameters):
thetaplus = np.copy(parameters_values) # Step 1
thetaplus[i][0] = thetaplus[i][0] + epsilon # Step 2
J_plus[i], _ = forward_propagation_n(X, Y, vector_to_dictionary(thetaplus)) # Step 3
thetaminus = np.copy(parameters_values) # Step 1
thetaminus[i][0] = thetaminus[i][0] - epsilon # Step 2
J_minus[i], _ = forward_propagation_n(X, Y, vector_to_dictionary(thetaminus)) # Step 3
# Compute gradapprox[i]
gradapprox[i] = (J_plus[i] - J_minus[i]) / (2 * epsilon)
# 通过计算与反向传播梯度比较差异。
numerator = np.linalg.norm(grad - gradapprox) # Step 1'
denominator = np.linalg.norm(grad) + np.linalg.norm(gradapprox) # Step 2'
difference = numerator / denominator # Step 3'
if difference > 2e-7:
print (
"\033[93m" + "反向传播有一个错误! difference = " + str(difference) + "\033[0m")
else:
print (
"\033[92m" + "你的反向传播效果非常好! difference = " + str(difference) + "\033[0m")
return difference
mini-batch
epoch的概念: 遍历一次数据集
batch的概念: 数据集按批次的大小分为多批, 这些批次就是mini-batch, 批次的大小就是mini-batch size
mini-batch的目的: 将原本一个epoch进行一次梯度下降(batch grad descent), 变为现在每个batch都进行一次梯度下降(mini-batch grad descent).
下面这个图, 紫色,绿色,蓝色分别对应单样本梯度下降,batch梯度下降, mini-batch梯度下降.

- 超参数mini-size的建议
如果 数据量较小(<2000) , mini-batch-size = 1 (即使用Batch grad descent)
如果 数据量较大, mini-batch-size = 26 ~ 29 之间
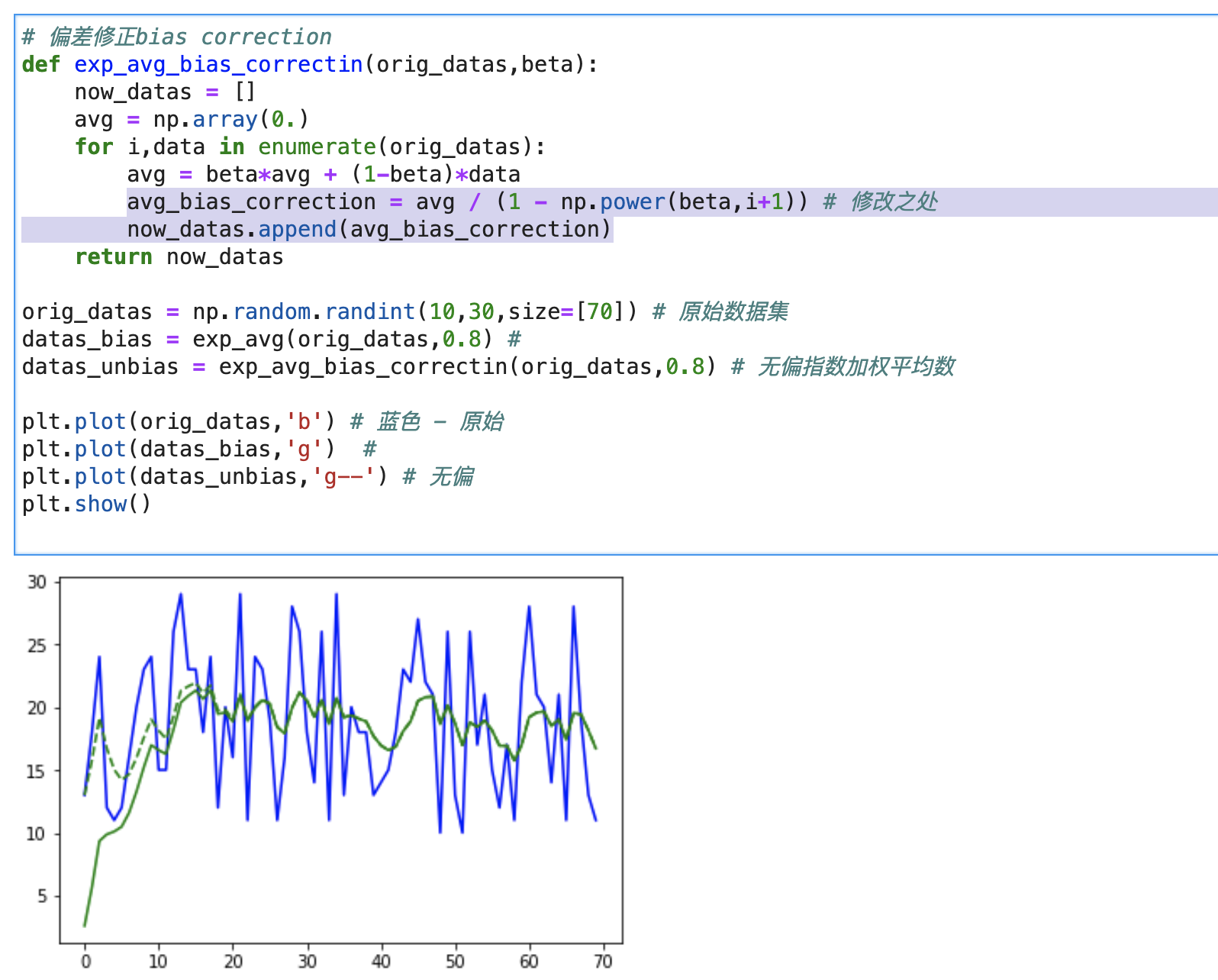
指数加权平均
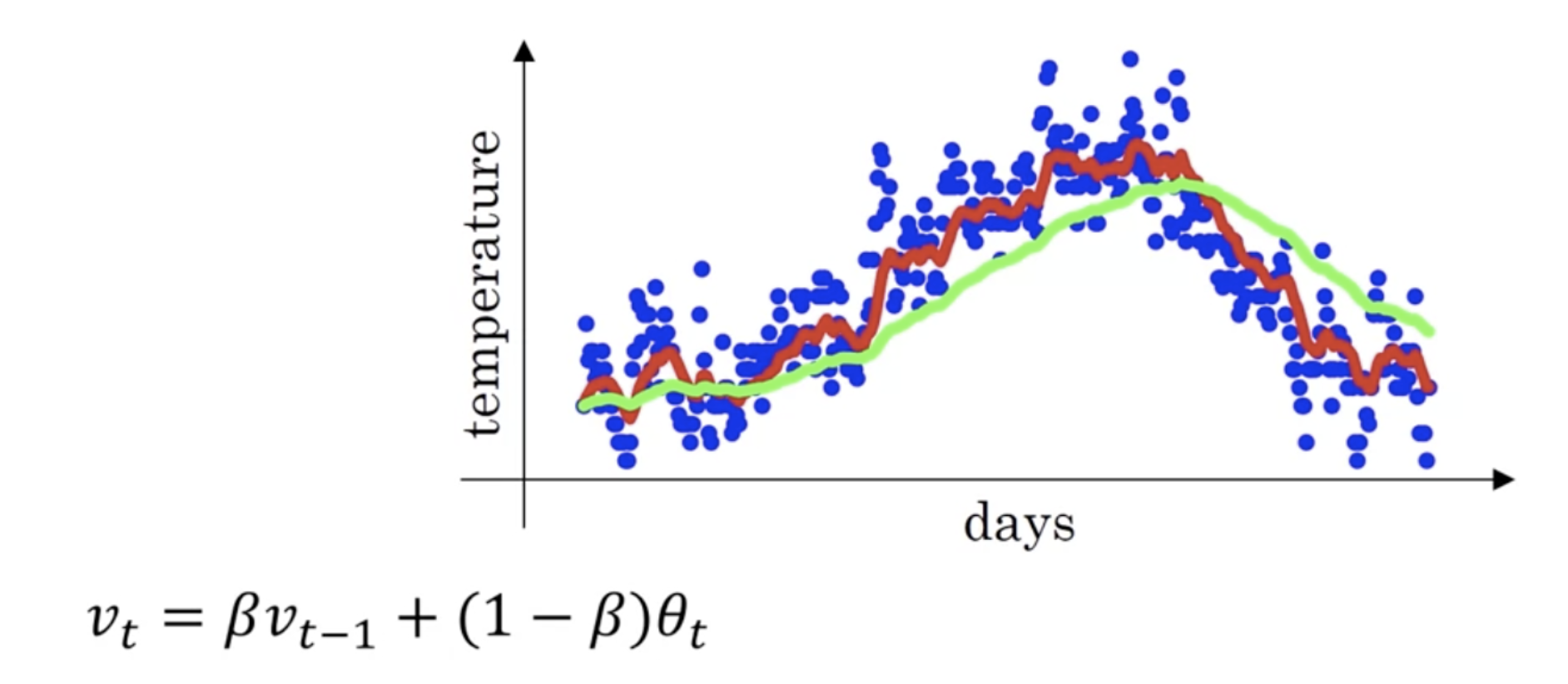
上图是每日的气温. 蓝色, 红色, 绿色分别是原始数据,指数加权后的数据, 指数加权后的数据.
公式: avg = beta avg + (1-beta) data , 含义是: 加权平均了前1/(1-beta) 次数据, beta越大, 整个数据集越平滑. 其指数的字面意思是这些加权的权重之间是指数关系
下面的代码, 来体验一下指数加权平均的beta参数.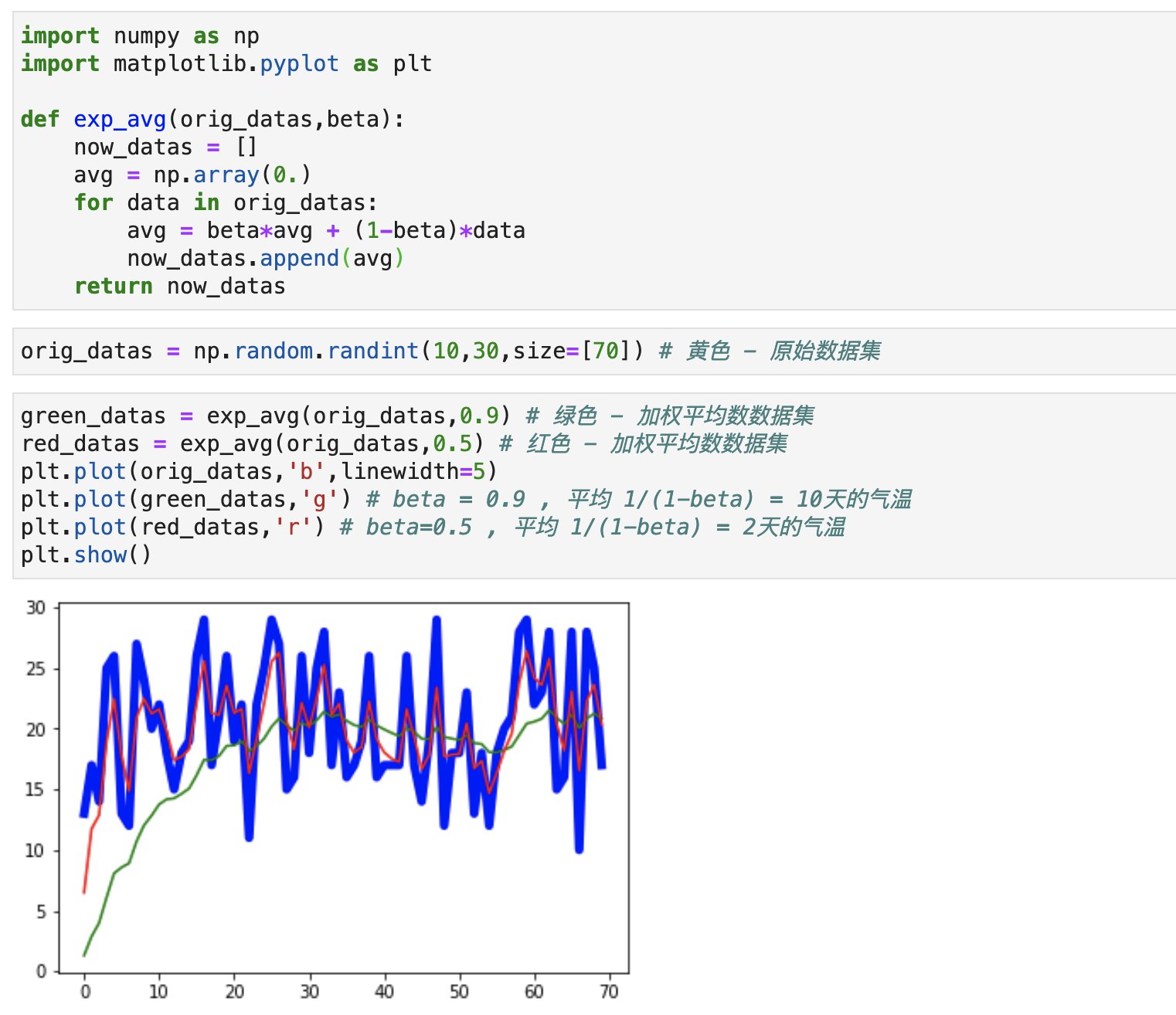
- 无偏指数加权平均. 由上图可见, 之前的公式在刚开始有很大偏差. 修改代码如下:
动量梯度下降momentum

思想: 对参数的梯度做(无偏)指数加权平均后, 用该梯度去更新参数.
超参数: beta=0.9 比较稳健.
RMSprop

RMSprop计算了”参数的梯度的平方”的指数加权平均, 该算法希望降低垂直方向的震荡
Adam (momentum和RMSprop的结合)

- adam超参数建议.
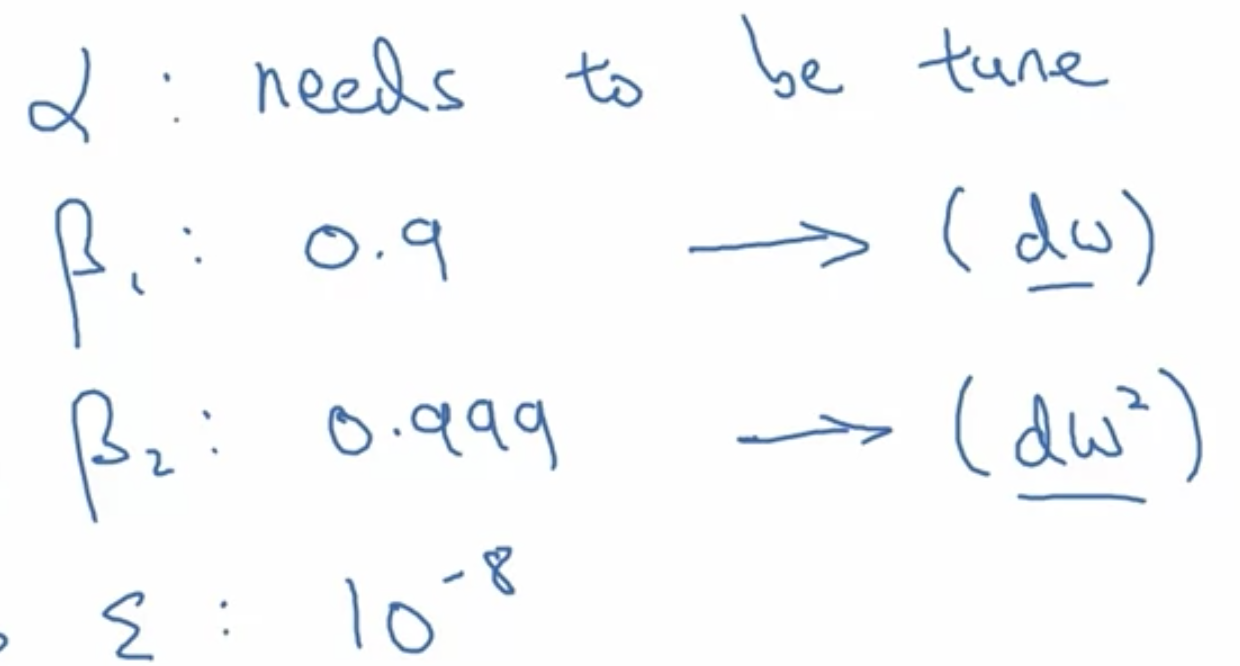
学习率衰减(实现函数有很多,下面举几个例子)

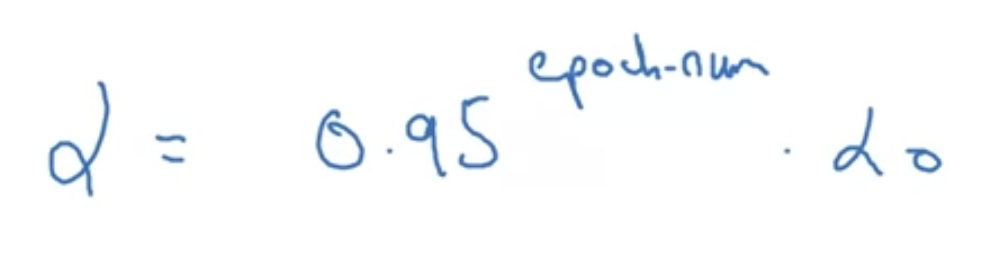

如何调参: 怎么对重要的超参数进行搜索.
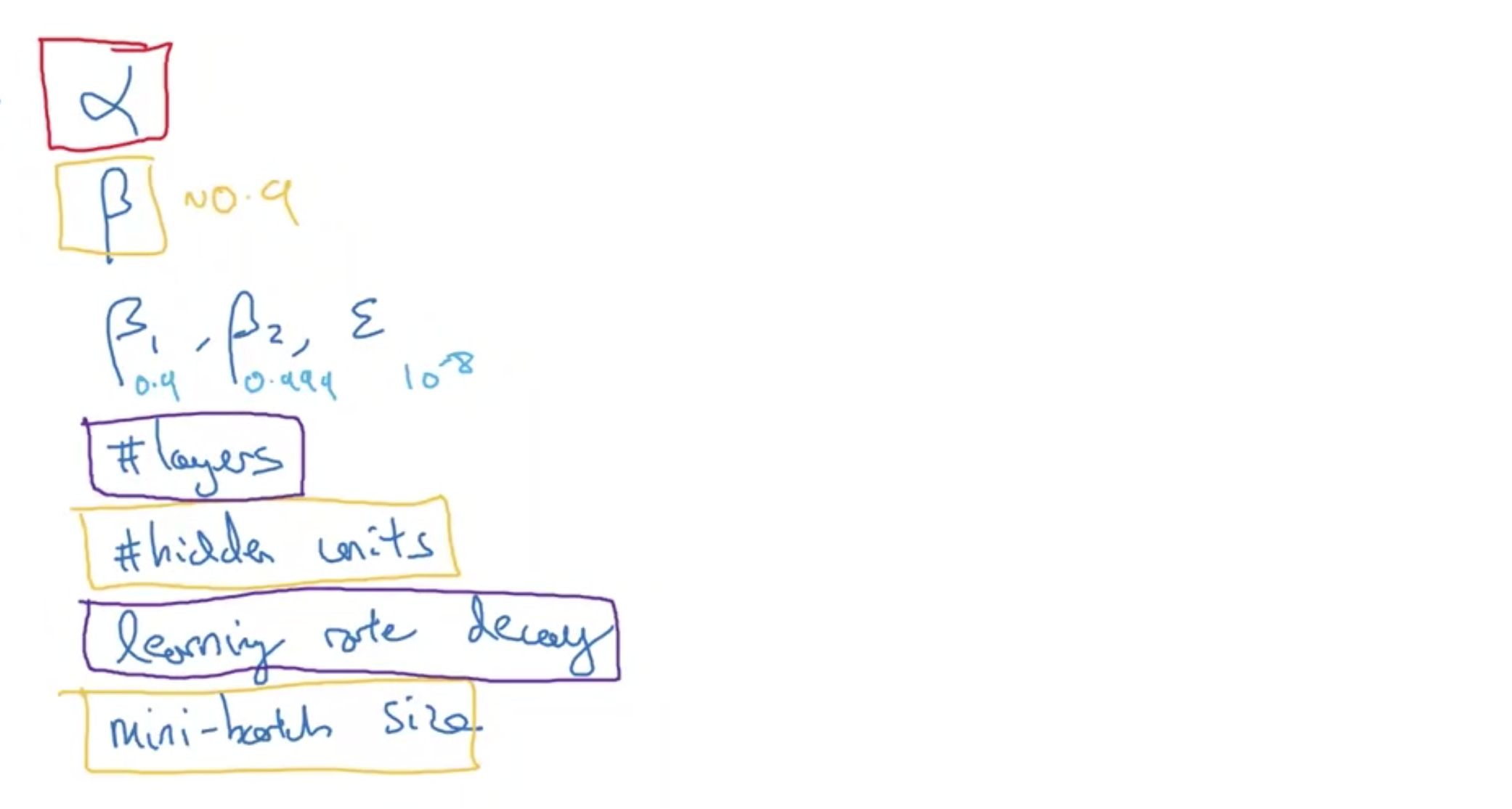
见图, 重要程度: 红色 > 黄色 > 紫色.
- 超参空间中随机搜索, 且随机取样的方式要考虑数值尺度, 而不能直接线性地随机采样.
比如你认为学习率范围在 0.0001 ~ 1之间, 那么应该如下随机采样:
- 对区间取log得到: -4 ~ 0
- 在-4 ~ 0 上随机取值 (-4 + 4 * np.random.rand())
- 得到随机采样 = np.power( 10, (-4 + 4 * np.random.rand()))
- 特别地, 对指数加权平均的beta超参数进行随机采样, 尤其应该采用如上的采样方式. (因为平均了1/(1-beta)个数据, 可知beta在趋近1时, 非常敏感, 此时应该加大采样密度.)
比如你认为beta范围在 0.9 ~ 0.999之间, 那么应该如下随机采样:
- 1-beta范围在0.0001 ~ 0.1之间
- 对1-beta随机采样得到: np.power( 10, (-4 + 3 * np.random.rand()))
- 得出 beta = 1- np.power( 10, (-4 + 3 * np.random.rand()))
批量归一化batchnorm

- 具有可学习参数𝛾和𝛽的batchnorm被称为仿射变换的batchnorm. 𝛾和𝛽增加了我们对均值和方差的控制和偏差修正等(比如在mini-batch场景下). 而且, 仿射变换的batchnorm因为有可学习的𝛽存在, 我们完全可以删除模型参数beta.
- 在理论上, 如果批量归一化没有用, 𝛾和𝛽甚至能通过学习来消除批量归一化的操作.(见图右侧)
- batchnorm同样也适用于momentum,RMSprop,adam优化算法, 但注意: 这些优化算法采用不同于梯度下降的其他更新方式, 于后细说.
注: 对于mini-batch来说, 一般测试集上的归一化所使用的均值或方差, 求于之前每个mini-batch的均值或方差的指数加权平均
batchnorm为什么奏效?
- 削弱了前后层之间的耦合, 限制了每一层的参数更新, 也让每一层的学习更稳固与独立.
我们知道, 学习了X到Y的映射, 但一旦X发生改变, 又要重新学习映射. 不仅如此, 模型的数据分布还随着协变量covariate的变化而变化的. 在神经网络中, 隐层的神经元作为协变量, 同时也做为后续层的输入值, 它无时无刻不在影响着其之后层的数据分布, 当然, 也影响了模型的数据分布. 那么加入BN到底起到什么效果呢? 答: 加入BN之后, 削弱了前后层之间的耦合, 使得协变量的变化对于数据分布的影响变得有限了, 也让每一层的学习更稳固与独立, 所以有效提升了模型的学习速度.
前后层的数据, 无论它们如何变化, 始终有相同的均值与方差的限制
- 轻微的正则化效果(mini-batch下)
对mini-batch求计算的均值和方差是有偏差的, 即增加了隐藏层的噪声, 所以起到了正则化的效果. 具体原因同dropout一样, 这些噪声的出现, 让后续的隐藏单元不会过度依赖其它隐藏单元, 而倾向于让参数变得更小.(注: 更大的mini-batch size 意味着更少的噪声, 正则化效果也会更差)
多分类任务与softmax激活函数
softmax激活函数的特别之处: 不同于sigmoid等, 它接受向量,需要对输出归一化, 也输出向量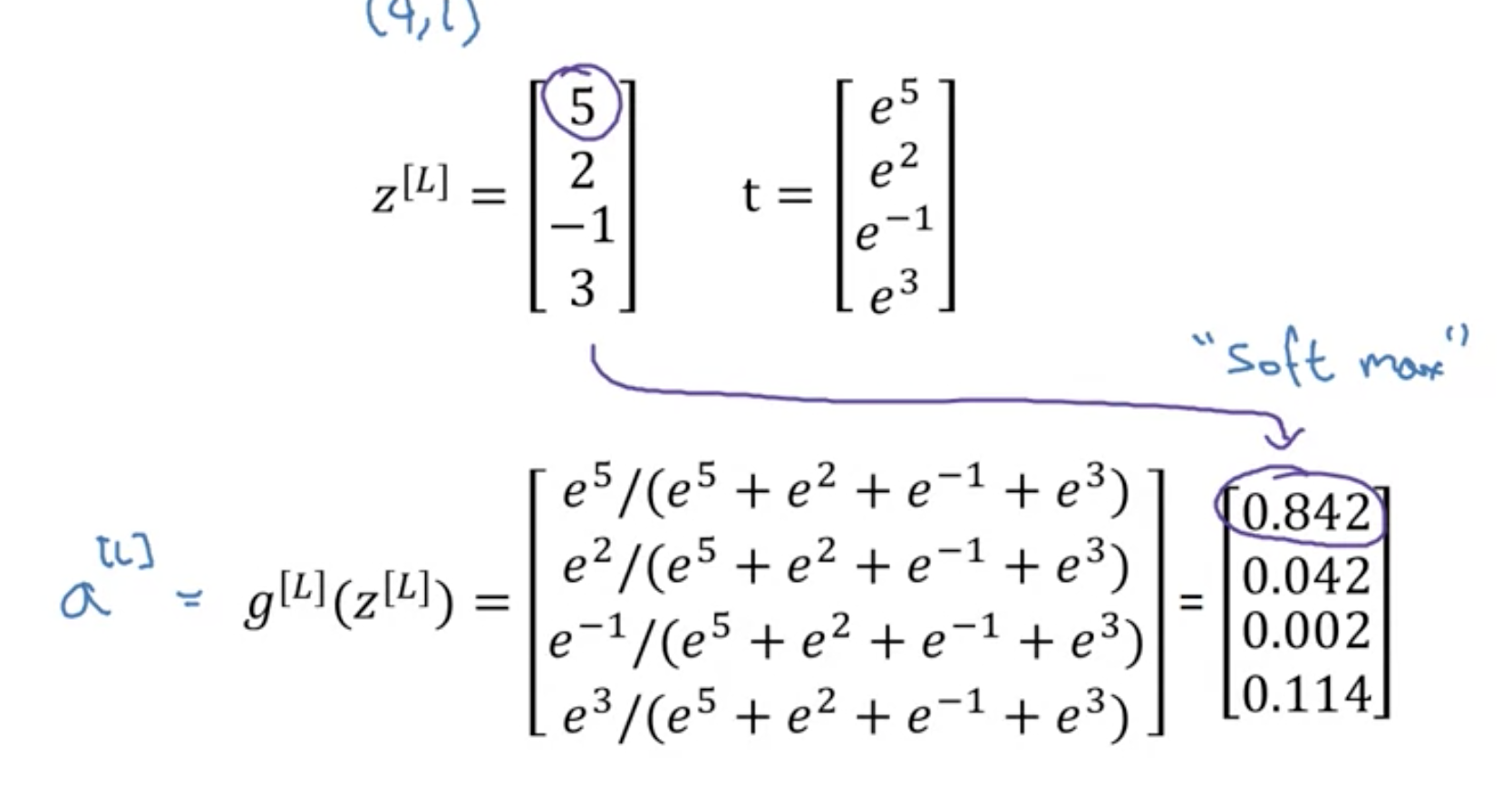
多分类网络的输出为 p(分类1 | x) , p(分类2 | x) ,…., p(分类n | x)
损失函数如下:
注: 最小化softmax的损失函数, 与用于二分类的逻辑回归的损失函数一样, 本质是某种形式的极大似然估计
[第三部分]结构化机器学习项目
如何进行实验: 调参的4个阶段(正交化调参经验)

上图, 讲述了”正交化”调参的经验, 即上图中4个阶段, 它们之间是相对独立的, 分别对应4组旋钮 (注: 不建议设置提前停止这个参数). 在前3个阶段, 我们关注代价函数的降低; 最后一个阶段, 我们关注代价函数或开发集的设计是否合理.
如何进行实验: 单一评估指标, dev\test set, train set
由于不同模型的各项指标非常复杂, 必须要设计评估模型好坏的单一评估指标, 这些指标要在train\dev\test上记录. (注: 均值, F1-score等就是单一评估指标). 另外, 这个单一评估指标可能需要反复修改, 因为还要考虑阈值,唤醒词, 用户偏好等等.

注: 关于如何用户偏好, 可以添加权重w, 比如在分类网络中, 可以将色情图片归类错误的惩罚更大.

设计dev\test set….将开发集和测试集放在同一分布. 建议: 随机打乱再分开发集和测试集.

根据实际反馈, 考虑训练集是否有问题, 并再次修改1,2步骤

如何进行实验: 误差分析 (avoidabel)bias和方差如何解决?

上图: 确定好human-level error(将人类的表现视为贝叶斯最优)之后, 将人类与训练集上的偏差定义为可忽略偏差. 在进行实验室时, 我们应该辨别目前应该专注降低可忽略偏差还是降低方差.
(可忽略)偏差和方差的解决方案见上图右
注: 以上是数据集之前同分布的情况, 当不同分布时可能有数据不配问题, 其解决方案见后续
如何进行实验: 快速建立系统, 不断迭代.

简单说: 按照左边这套步骤, 快速建立baseline, 然后不断迭代.
如何进行实验: 在train set和dev/test set上, 如何处理数据集的分布不同的情况?

如上图, 你拥有大量的高清图片, 以及不多的低清图片, 但是在实际场景下, 用户普遍使用低清图片来使用你的模型. 那么如何设置数据集呢? 答: 关键在于dev/test set应该瞄准真正的目标, 所以应该先用低清图片(真正的目标)来作为dev/test set, 剩余的全部高清和少量低清图片作为train set.
如何进行实验: 更全面的误差分析(考虑数据不匹配问题)

在解释上图之前, 先看看为什么要使用Train-dev error? 以及它是什么.
Train-dev set 是什么? 有什么用? 答: 它和训练集同分布,但是不进行训练, 充当开发集的角色. 目的是: 通过比较train error 和 train-dev error, (由于两者同分布)便可以反映方差问题(模型本身的泛化性问题). 同时, train-dev error 与 dev error 的比较, 便反映了数据不匹配问题Data missmatch(数据集之间的数据分布问题).
注: 一般情况下,human-level error、training error、training-dev error、dev error以及test error的数值是递增的,但是也会出现dev error和test error下降的情况。这主要可能是因为训练样本比验证/测试样本更加复杂,难以训练
解决方案:
- 开发集过拟合问题: 采用更大的开发集. (注, 如何判断开发集过拟合? 答: 由于开发集和测试集同分布, 如果Test error >> Dev error, 那么只能是开发集过拟合)
- 偏差和方差问题: 解决方案见上
- 数据不匹配问题(解决思想: 使开发集和训练集的数据分布尽可能相似)
- 人工合成数据, 使得开发集更相似于训练集.
合成车内音频
计算机图像学合成汽车图(左边两幅图)
迁移学习

上图: 在已训练好的语音识别模型中, 通过修改最后一层网络, 来训练语音唤醒系统.
- 迁移学习的作用: 将任务A中学到的信息迁移到任务B中, 它在少量数据的情况下, 利用已训练好的其他相似任务的模型(预训练模型), 来进行再学习.
- 迁移学习的适用: 必须在预训练模型本身已经做得很好的前提下, 这需要预训练模型有更大的数据量作为支撑.
多任务学习
用一个神经网络学习多个不同任务(这些任务共享底层的特征), 能比单独训练这些任务时更好的表现.
典型的应用: 计算机视觉的物体检测.
端到端深度学习
即输入数据, 输出结果, 中间没有独立的分段训练, 不将问题分段. (个人通俗表述)
缺点是: 需要大量数据支撑.
[特别专栏]大佬访谈
深度学习之父
- 生成对抗网络是深度学习中最新最重要的想法。
- “胶囊”的想法,比目前的神经元容纳更多的参数。
- 入门DL建议
- 多读论文,但是别太多。对于有创意的人应该少读一部分,然后发现你认为所有人都错了的东西。坚持自我的原则,如果直觉还不错就坚持。
- 不要停止编程
- 如过你找到一个想法,其他人都觉得荒谬那就太好了,可能是好想法。
- 新研究生建议
- 找到与你意见一致的导师。要是导师对你做的不感兴趣,你会得到没啥用的建议。
- 对于读博、顶尖公司
- 自动解决问题是变革。训练计算机将会和编程一样重要。
- 增强学习很有趣
- 深度学习是未来
生成对抗网络GAN之父、深度学习花书的作者
- GAN可做的有很多,处于十字路口。例如半监督学习、安全性领域。
- GAN还不够稳定,没有深度学习那样可靠。
- 给AI学习者的建议
- 现在做AI不一定要博士学位或者各种证书,在github上写好代码项目就是很好的被注意的机会。
- 初学者在github上写代码?比如,跟着花书练习,并且同时做一个项目也是重要的,这些项目最好是你感兴趣的领域。
890年代甚至没有互联网, 但那些890年的术语, 现在看来, 已经非常流行, 所以我很难想象, 他们如何在低级的硬件软件上进行实验, 以及如何渡过的神经网络的那些寒冬.

若有收获,就点个赞吧
0 人点赞
