简介
Kafka 是一种高吞吐、分布式、基于发布和订阅模型的消息系统
Kafka 用于离线和在线消息的消费,将消息数据按顺序保存在磁盘上,并在集群内以副
本的形式存储以防止数据丢失。Kafka 可以依赖 ZooKeeper 进行集群管理,并且受到
越来越多的分布式处理系统的青睐,比如 Storm、Spark、Flink 等都支持与 Kafka 集
成,用于实时流式计算。
消息队列
消息队列MQ(Message Queue)是一种进程间通信或者同一个进程中不同线程间的通信方式,主要解决异步处理、应用耦合、流量消峰等问题,实现高性能、高可用、可 伸缩和最终一致性架构,是大型分布式系统不可缺少的中间件。
如下图,系统 A 将消息发布到 MQ,然后系统 B 再从 MQ 取消息
消息队列有3种好处。
good.1 异步处理
生产者会将所有数据存放在 MQ 中, 消费者不需要立即处理,大大缩短了系统的响应时间。
good.2 应用解耦
消息队列可以对系统间的依赖进行解耦,降低依赖系统变更带来的影响。
在高耦合的场景中,上游应用和下游应用之间一旦某个应用出现故障或者进行维护则可能更改其他应用的代码。

应用解耦场景下,应用之间关心的数据,而非彼此的代码逻辑。
下图中,上游应用只管生产数据,下游应用只管消费数据,而不关心其他应用的可用性。
good.3 流量消峰
消息队列能够避免了流量的不规则冲击。它就像是水电站中的蓄水池,能够有效地隔离上下游,将水先存在起来,即便遇到洪水也能以更平滑的方式传给下游。
另外,Kafka 除了“蓄水池”的功能之外,还提供了消息顺序性保障、回溯消息、 持久化存储等功能。
消息队列的两种模式
消息在 MQ 中有两种传输模型,分别是点对点(point to point)和发布/订阅(publish/subscribe)模型。
点对点模型

发布/订阅模型
就像电视广播系统一样。生产者的消息被按照某个概念进行分类,每个分类都能被不同消费者所订阅。
kafka系统架构
个典型的 Kafka 系统架构会包括 Producer、broker、Consumer等角色,以及一个 ZooKeeper 集群。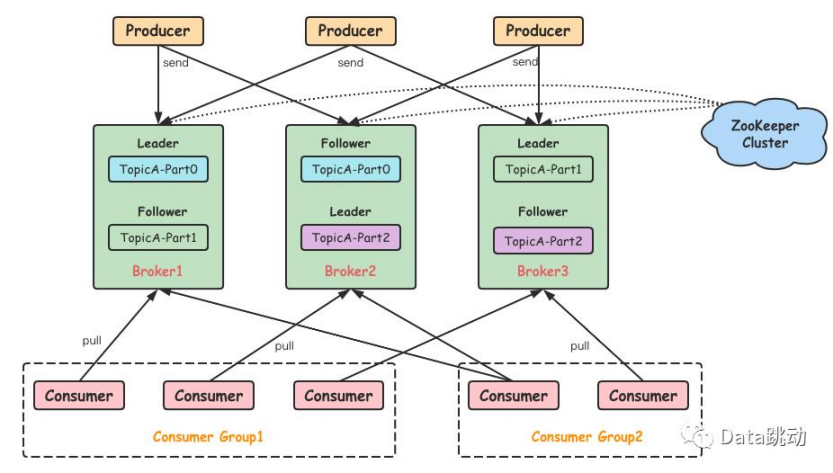
- Producer:生产者,负责将客户端生产的消息发送到 Kafka 中,可以支持消息的异
步发送和批量发送;
- broker:服务代理节点,Kafka 集群中的一台服务器就是一个 broker,可以水平无
限扩展,同一个 Topic 的消息可以分布在多个 broker 中;
- Consumer:消费者,通过连接到 Kafka 上来接收消息,用于相应的业务逻辑处理;
- ZooKeeper: 见下
- Consumer Group:消费者组,指的是多个消费者共同组成一个组来消费一个 Topic中的消息
ZooKeeper 是一个分布式协调服务,其设计的初衷是为分布式软件提供一致性服务。其本质上,就是文件系统+通知机制。提供了一个类似 Linux 文件系统的树形结构,ZooKeeper 的每个节点既可以是目录也可以是数据,并且 ZooKeeper 还提供了对每个节点的监控与通知机制
Kafka 同时支持两种消息传输模型
- 实现点对点模型的方式就是引入Consumer Group,即一个topic的消息,目的主要是让多个消费者同时消费,可以加速整个消费者端的吞吐量。
kafka的核心概念
kafka多副本机制

若有收获,就点个赞吧
0 人点赞
