Apache flink简介
Apache flink是什么
flink 框架处理流程

flink应用场景
区别:批处理本身就需要“积攒”的成本。
为什么选择flink
- 批处理和流处理
- 流数据更真实存在
- 目的
低延迟
高吞吐
结果准确性和良好的容错性
传统数据处理架构
- 联机事务处理OLTP(on-line transaction processing)
OLTP面向应用系统数据库(面向应用)
简单事务
实时
数据量
- 联机分析处理OLAP(On-Line Analytical Processing)
分区技术、并行技术
有状态的流式处理
多个架构并行时,存在数据乱序问题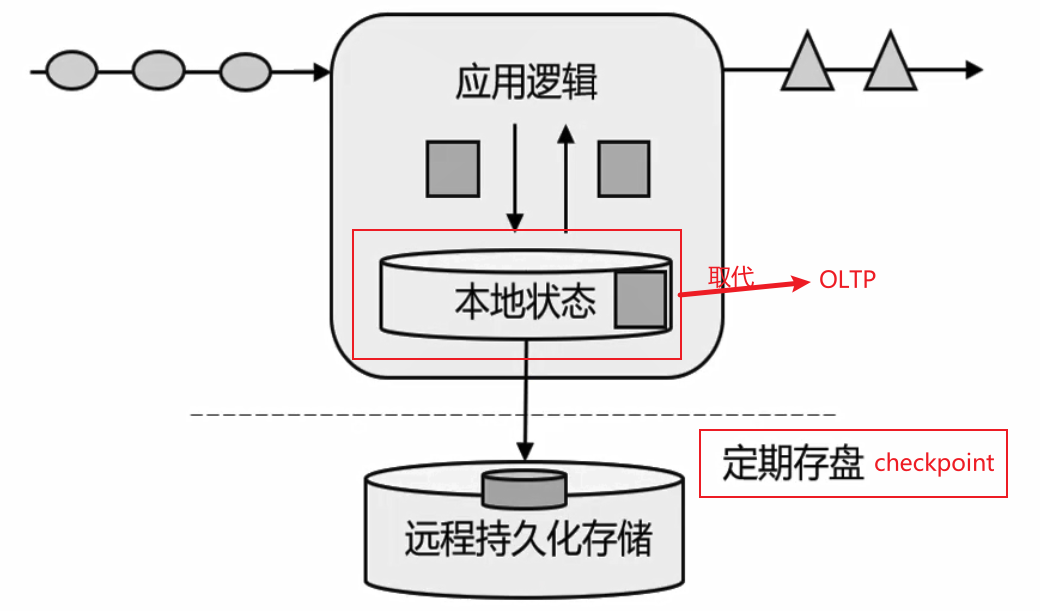
流处理演变
- lambda架构

新一代流处理—Flink
一套系统实现lambda架构的功能。
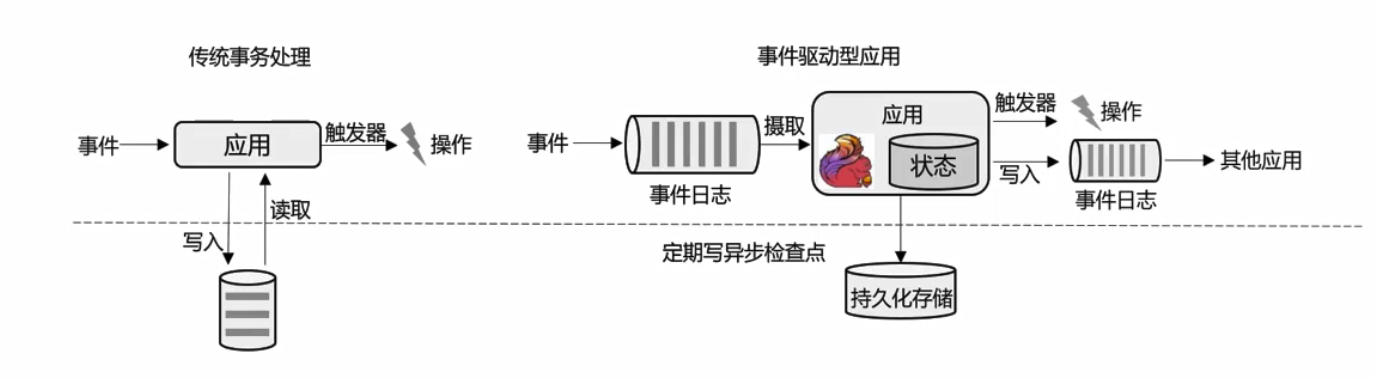
- 事件分析型应用

- 数据管道型应用

Flink的分层API
- 分层API

Flink vs Spark
- 数据处理架构
spark基于批设计,流是“微批次”。
flink基于流设计,批是“有界流”。
- 数据模型
- spark 采用RDD模型(见备注),spark streaming的DStream本质是一组组小批RDD集合。
- flink 基本数据模型是数据流(datastream)、事件序列(event)
- 运行时架构
- spark 批计算,DAG划分为不同stage,一个完成计算下一个。
- flink 流计算,一个事件处理完成后发往下一个节点。
- 备注
RDD可伸缩的分布式数据集(Resilient Distributed Dataset)。
Flink 快速上手
环境准备
win10
java8
idea
maven
git
flink 1.13.0
流处理
有界流(code)
WordCount任务
import org.apache.flink.stream.api.datastream.DataStreamSourcepublic class BoundedStreamWordCount{public static main(String[] args) throws Exception{// 1. 创建流式的执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 2. 读取文件DataStreamSource<String> lineDataStreamSource = env.readTextFile("input/words.txt");// 3. 转换计算lineDataStreamSource.flatMap((String line,Collection<Tuple2<String,Long>> out)-> {String[] words = line.split(" ");for (String word : words){out.collection(Tuple2.of(word,1L));}}).returns(Types.TUPLE(Types.STRING,Types.LONG)) // 因为JAVA类型擦除,我们给flink指明类型。// 4. 分组keyedStream<Tuple2<String,Long>,String> wordAndOneKeyedStream = wordAndOneTuple.keyBy(data -> data.f0); // 输入key序列// 5. 求和SingleOutputStreamOperator<Tuple2<String,Long>> sum = wordAndOneKeyedStream.sum(1);// 6. 打印sum.print();// 7. 执行env.execute();}}
无界流(code)
- 有界流和无界流的差异代码
- 有界流读取文件
DataStreamSource<String> lineDataStreamSource = env.readTextFile("input/words.txt");
- 无界流读取文本流(监听端口)
DataStreamSource<String> lineDataStreamSource = env.socketTextStream("hadoop102",7777);
import org.apache.flink.stream.api.datastream.DataStreamSourcepublic class BoundedStreamWordCount{public static main(String[] args) throws Exception{// 1. 创建流式的执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 2. 读取文本流(监听端口)DataStreamSource<String> lineDataStreamSource = env.socketTextStream("hadoop102",7777);// 3. 转换计算lineDataStreamSource.flatMap((String line,Collection<Tuple2<String,Long>> out)-> {String[] words = line.split(" ");for (String word : words){out.collection(Tuple2.of(word,1L));}}).returns(Types.TUPLE(Types.STRING,Types.LONG)) // 因为JAVA类型擦除,我们给flink指明类型。// 4. 分组keyedStream<Tuple2<String,Long>,String> wordAndOneKeyedStream = wordAndOneTuple.keyBy(data -> data.f0); // 输入key序列// 5. 求和SingleOutputStreamOperator<Tuple2<String,Long>> sum = wordAndOneKeyedStream.sum(1);// 6. 打印sum.print();// 7. 执行env.execute();}}
// 2. 读取文本流(监听端口)ParameterTool parameterTool = ParameterTool.fromArgs(args);String hostname = parameterTool.get("host");Integer port = parameteerTool.get("port");DataStreamSource<String> lineDataStreamSource = env.socketTextStream(hostname,port);
- 补充:使用nc监听端口,来做作为俩天工具
1、
[atguigu@hadoop102 ~]$ nc -lk 7700
2、
[atguigu@hadoop103 ~]$ nc hadoop102 7777
你好
我是hadoop103
服务端收到数据

Flink部署
快速启动
- Flink 主要组件
Client 提交任务
JobManager 对作业中央管理
TaskManager 具体干活的,也叫WorkerNodes
- 环境配置

- 本地启动
无需任何修改,bin/start-cluster.sh 即可启动
- 集群启动
分发flink环境
配置conf/masters
配置conf/workers
bin/start-cluster.sh 启动
- 向集群提交作业
sokcer文件流作为输出为例,nc -lk 7777
本地打包jar包
登录http://hadoop102:8081/#/submit,提交本地Jar包,设置运行参数。启动。
部署模式
- Session Mode
先有集群(所有资源都确定了,资源共享),再提交作业 <—— 缺点:集群生命周期优先,一旦资源不够,会导致提交作业失败。
- Per-job Mode(常用)
每一个作业启动,就启动一个集群。 <—- 优点:作业完成,对应集群关闭,资源释放。
- Application Mode
每一个jar包(应用),就启动一个集群。
独立模式 standalone
- 会话模式部署(常用)
- 单作业(per-job)模式部署
-
YARN 模式
flink不同版本对yarn支持不同,直接看最新的flink版本(最新版本只需要配置yarn即可)

会话模式部署
- 单作业(per-job)模式部署
- 应用模式部署
K8S部署
…作业提交流程
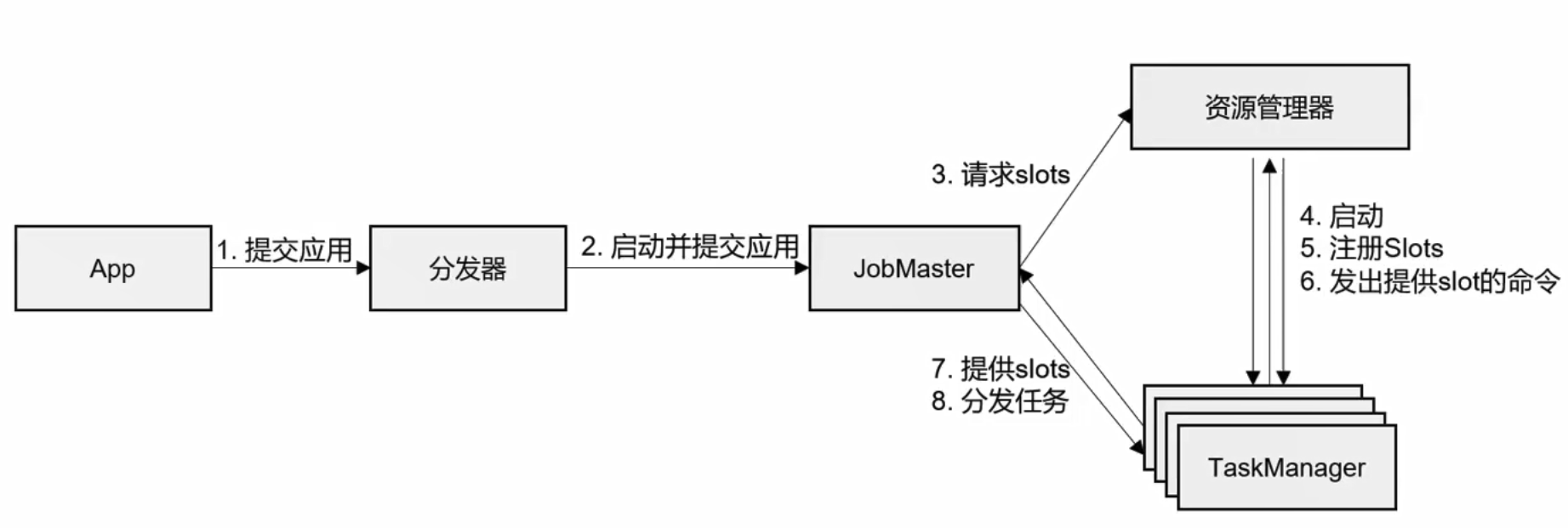
Standalone模式作业提交流程

Yarn会话模式作业提交流程
提交任务给分发器
Yarn单作业模式任务
提交任务给yarn
Flink运行时架构
DataFlow
flink的程序被映射为dataflows,包含三部分:sources、transformations、sinks。
dataflow类似有向无环图DAG,每个dataflow以任意个sources开始或任意个sinks结束。
每个算子对应一个transformation.s
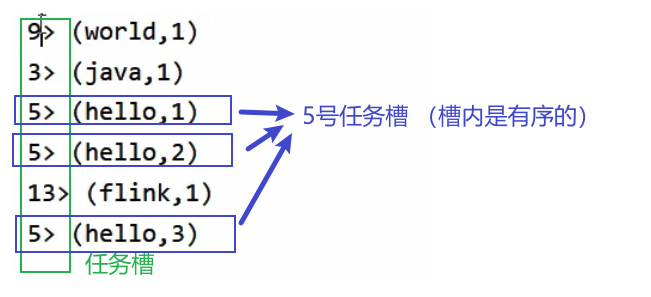
Parallelism
任务并行,数据并行
conf/flink-conf.yaml文件中parallelism.default: 1 <—- 集群默认并行度。 env.setParallelism(1); <—- 全局并行度设置。 sum(1).setParallelism(2); <—- 算子并行度设置。

数据传输形式
- 算子具有不同的并行度;算子之间的传输数据的形式有两种
One-to-one(forwarding):stream的分区不会变,如map、fliter、flatMap算子。
Redistributing:stream的分区会发生改变,如keyBy算子基于hashCode重分区、broadcast和rebalance算子会随机分区。
- 算子链(Operator Chains)
任务链优化技术:在特定条件下减少本地通信开销。连续的算子之间,当并行度相同且One-to-one传输模式时,fink认为它们整体一个task(原本的算子叫substask,这些substask通过local forward方式进行连接)。
执行图(ExecutionGraph)
- StreamGraph <—- Stream API代码生成的拓扑结构
- JobStream <—- 由StreamGraph的“任务链优化技术”等优化后生成,它提交给JobManager。
- ExecutionGraph <—- 由JobManager生成,它是JobGraph的并行化版本,是调度层最核心的数据结构。
- 物理执行图 <—- 不是具体的数据结构,只是可视化展示。
028

若有收获,就点个赞吧
0 人点赞
