- Hadoop:存储文件的数据特性
- hadoop为什么要从2.x升级到3.x?
- Hadoop: 不停机升级
- HDFS:组件及其作用
- HDFS:小文件处理
- HDFS: hdfs块管理优势
- HDFS:读/写、机架感知
- HDFS写数据过程的故障、处理、dataqueue和ackqueue
- HDFS: 为什么需要2NN? 如果没有2NN行不行。
- HDFS: 节点通信问题(RPC)
- HDFS: 数据一致性和租约管理以及RBF
- MapReduce优化
- MapReduce 实现基本SQL操作的原理(不需要掌握)
- MapReduce: shuffle不排序直接输出难道不好吗?
- Yarn:工作机制
- Yarn: 容器的启动
- Yarn: 是如何控制容器的内存大小
- Yarn:yarn如何保证数据一致性的(CAP),主要问的resourcemanager
- QJM: paxos算法怎么用的,知道字节为什么不用QJM而用Zookeeper?
- Zookeeper:选举机制
- Zookeeper:同步过程/Follower和Leader状态同步
- 说下raft、zab和paxos
- Zookeeper一致性算法
- Zookeeper 监听原理
- Zookeeper服务器动态上下线监听
- Zookeeper分布式锁
- Hive:内部表和外部表的区别
- Hive的特点有什么
- Hive和Hbase区别
- Flume:source、channel、slink有哪些
- Kafka:如何实现高吞吐
- Kafka : 零拷贝细节(低频)
- kafka: 组件熟悉吗,kafka 如何实现消息的有序的?
- Kafka: 消息确认(ack 应答)机制了解吗?
- Kafka: LEO、HW、LSO、LW 分别代表什么?
- flume和kafka怎么配置(数仓)
- Hbase存储原理和过程
- HBase:rowkey设计原则
- 数据倾斜
- 数据仓库场景,学生数据系统怎么搭?
- Scala实现wordcount
- scala闭包
- Saprk St reaming和Flink的区别
- Java : 集合的继承关系,array、set、map
- Java: ArrayList和linklist的底层实现原理
- Java:JVM 内存模型
- Java: Spring MVC运行流程
- java : JVM GC原理
- Java: G1垃圾回收器的原理
- Java: JVM 复制算法和标记清除算法、标记整理算法
- Java:object类有哪些方法?
- Java : 为什么要重写 equals 和 hashcode()方法
- Java : 封装、继承、多态、抽象
- Java: synchronize和volatile锁的区别
- Java: 多线程的实现 Thread、Runable、Callable (写出来)
- Java: 双亲委派机制( 类加载机制)
- Java: 线程池
- Java: 共享内存如何实现互斥
- Java: hashMap,TreeMap、hashTable(线程安全问题)
- Java: hashmap和concurenthashmap的区别和细节
- Sql: 姓名、分数,按分数排名如何实现
- Mysql: 引擎介绍
- Mysql: 索引失效
- Mysql: 慢查询如何开启关闭
- Mysql: 主从读写怎么实现
- Mysql: 如何看sql用到了索引,以及里面都是啥
- 算法题:归并排序
- 算法题:递归算法的缺点?
- 算法题:LRU
- 算法题:凑零钱和最大正方形面积(leetcode有)
- 数据结构: 二叉树、二叉搜索树、二叉平衡树、红黑树
- 数据结构: 数组和链表的适用场景,为什么?
从面试官的角度谈谈大数据面试 - 老蒙的文章 - 知乎 https://zhuanlan.zhihu.com/p/49888357
【大数据面试之对线面试官】MapReduce/HDFS/YARN面试题70连击 - 王知无的文章 - 知乎 https://zhuanlan.zhihu.com/p/343856307
https://mp.weixin.qq.com/s/_qFd-v3TF0W8lBo6ci-17w
https://github.com/wangzhiwubigdata/God-Of-BigData
Hadoop:存储文件的数据特性
趋势社招
- 4V
Volume(大量)。TB、PB、EB的存储单位级别。
Velocity(高速)。
Variety(多样)
Value(低价值密度)
- Hadoop的特点
(1)高可靠性:在处理数据时,Hadoop往往会将数据备份多份分发至不同的机器进行保存,这样就避免了在处理数据时,机器宕机导致数据丢失的麻烦,保证了数据的安全性、可靠性。
(2)高扩展性:在处理数据时,如果当前集群的资源(比如存储能力和运算能力)不足以完成数据处理和分析任务,可以通过快速扩充集群规模进行扩容和加强集群的运算能力。
(3)高效性:相比传统的单台机器处理数据,效率是极高的。
(4)高容错性:Hadoop能自动保存数据的多个副本,当某个节点宕机时,它可以自动的将副本复制给其他机器,保证数据的完整性,并且可以将失败的任务重新分发。
(5)低成本:Hadoop集群可以将程序运行在廉价的机器上并发的进行处理,成本低、效率高,是处理海量数据的最佳选择。
hadoop为什么要从2.x升级到3.x?
字节社招
Hadoop: 不停机升级
不停机升级过程中有哪些不兼容的地方(namenode的editlog、datanode的块布局等),你是怎么解决
的,社区是怎么解决的,版本回滚会有啥问题?
字节社招
HDFS:组件及其作用
趋势社招
(1)HDFS:Hadoop Distribute File System,分布式文件系统,用于存储海量数据。
(2)MapReduce:Hadoop的分布式计算框架。
(3)Yarn:分布式资源调度和任务监控和分配的平台。
(4)commons:Hadoop底层的技术支持
HDFS:小文件处理
趋势社招
HDFS: hdfs块管理优势
趋势社招
HDFS上的文件也被划分为块大小的多个分块作为独立的存储单元。
与通常的磁盘文件系统不同:HDFS中小于一个块大小的文件不会占据整个块的空间(当一个1MB的文件存储在一个128MB的块中时,文件只使用1MB的磁盘空间,而不是128MB)
设置数据块的好处:
(1)一个文件的大小可以大于集群任意节点磁盘的容量
(2)容易对数据进行备份,提高容错能力
(3)使用抽象块概念而非整个文件作为存储单元,大大简化存储子系统的设计
HDFS:读/写、机架感知
阿里×3,阿里社招,腾讯x2,字节x2,百度,拼多多x2,浩鲸云,小米,流利说,顺
丰,网易云音乐×2,有赞×2,祖龙娱乐,360×2,商汤科技,招银网络,深信服,
多益,大华,快手,电信云计算,转转,美团x4,shopee×2:回答越详细越好,猿
辅导×2,科大讯飞,恒生电子,搜狐,京东,头条,富途,网易
读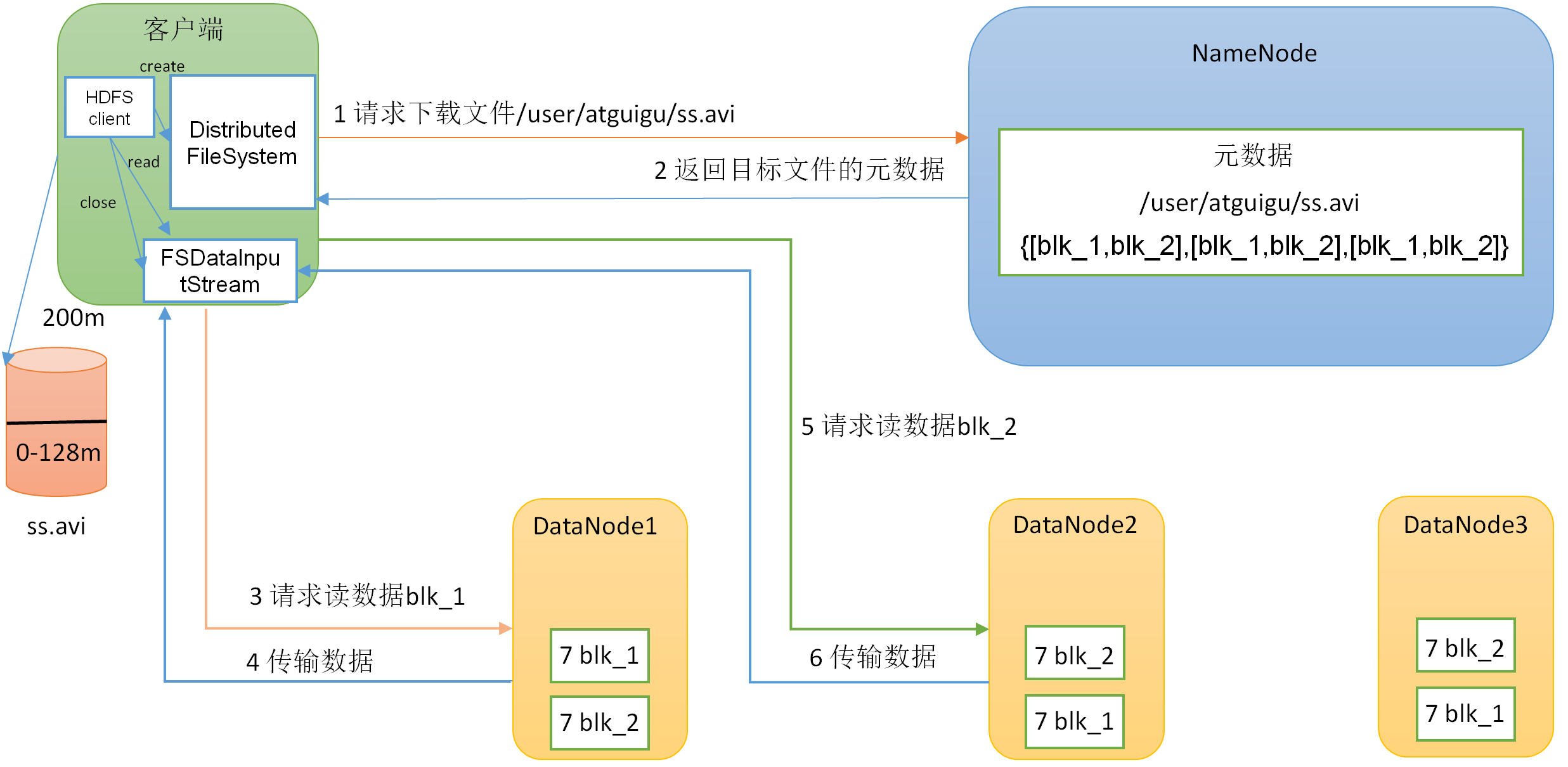
写
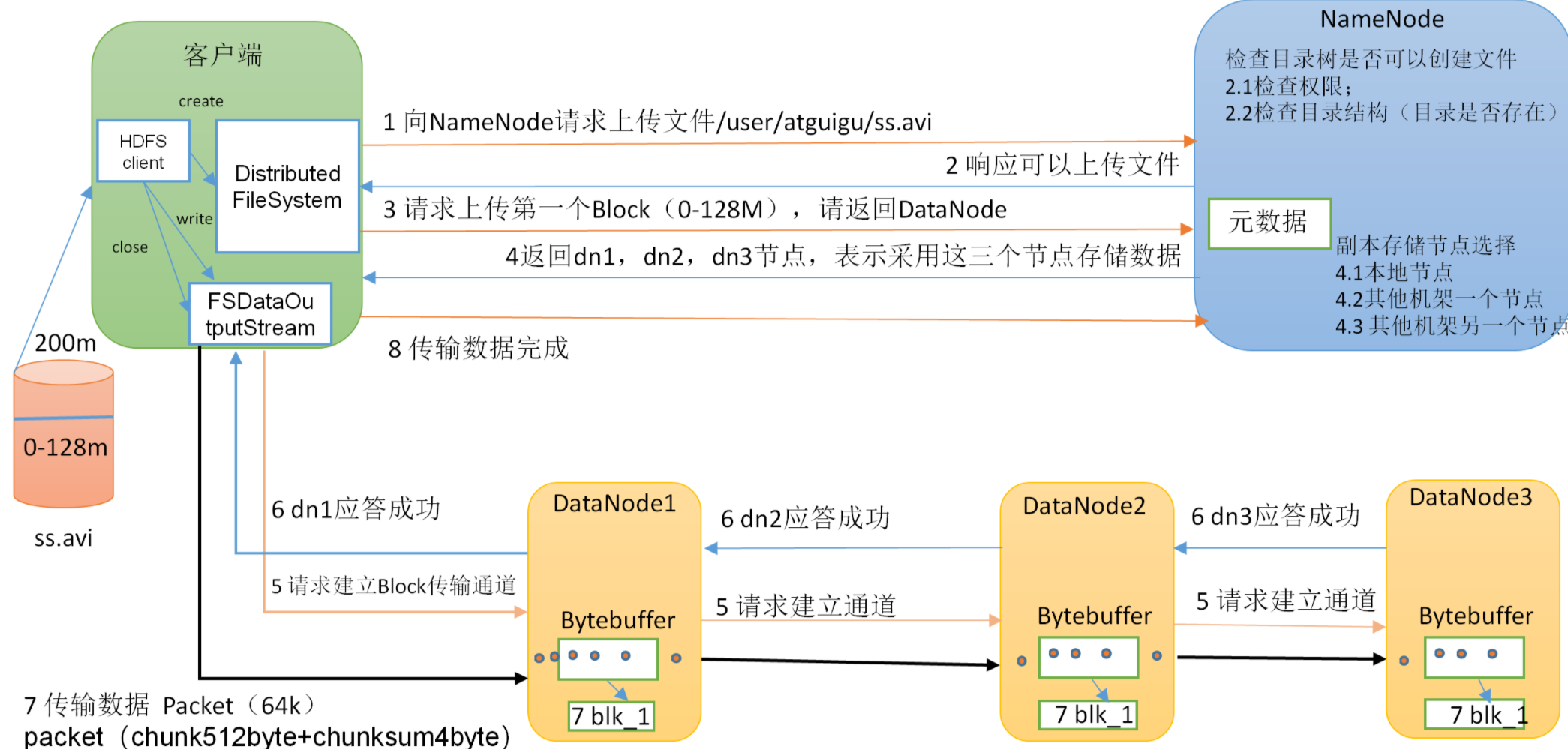
HDFS写数据过程的故障、处理、dataqueue和ackqueue
hdfs写数据过程,写的过程中有哪些故障,分别会怎么处理?dataqueue和ackqueue如何交互的?
ackqueue中的数据如何重新放回到dataqueue中?如何保证有序?写数据的过程中是一个个package写入
并确认成功后再写下一个吗?不过不是,是怎么写的,除了错误如何恢复的?
字节社招
HDFS: 为什么需要2NN? 如果没有2NN行不行。
海康威视
答:引入一个新的节点SecondaryNamenode,专门用于FsImage镜像和Edits日志的合并。
没有2NN其实也行,但是合并工作会非常影响NN的效率。
- NameNode的元数据存储在哪里?
NameNode节点经常要随机访问,还要响应客户请求。
为了提高Io效率,NameNode的策略是将元数据加载到内存中;进一步,为了防止断电等故障,需要备份元数据到磁盘(FsImage镜像);为了保证数据一致性,引入Edit日志(编辑日志、顺序写)来记录内存中元数据的变化。这样,即是NameNode节点断电,通过FsImage和Edit的合并,可以合成元数据,即做到故障恢复。
新问题是,FsImage和Edit需要定期合并,为了不耽误NameNode节点的效率,所以引入SecondaryNameNode专门负责这件事。显然,2NN和NN是部署在不同的节点上。
具体地,到达checkPoint触发条件时,fsimage文件和Edit文件会被拷贝到2NN中,在其内存中合并生成新的fsimage,再拷贝fsimage到nn中。
注:Edit日志顺序写,类似设计有InoDB、Kafka、Hbase。
HDFS: 节点通信问题(RPC)
网易
HDFS: 数据一致性和租约管理以及RBF
MapReduce优化
美团×15,阿里×3,字节×6,头条,滴滴,百度,腾讯×4,Shopee,小米,爱奇
艺,祖龙娱乐,360×5,商汤科技,网易×5,51×2,星环科技,招银网络,映客直
播 , 字 节 ×2 , 有 赞 , 58×3 , 华 为 x2 , 创 略 科 技 , 米 哈 游 , 快 手 , 京 东 ×3 , 趋 势 科
技,海康威视,顺丰,好未来,一点资讯,冠群驰骋,中信信用卡中心,金山云,米哈
游,途牛
1)MapReduce执行流程
2)对MapReduce的理解
3)MapReduce过程
4)MapReduce的详细过程
5)MapTask和ReduceTask工作机制
6)MapReduce中有没有涉及到排序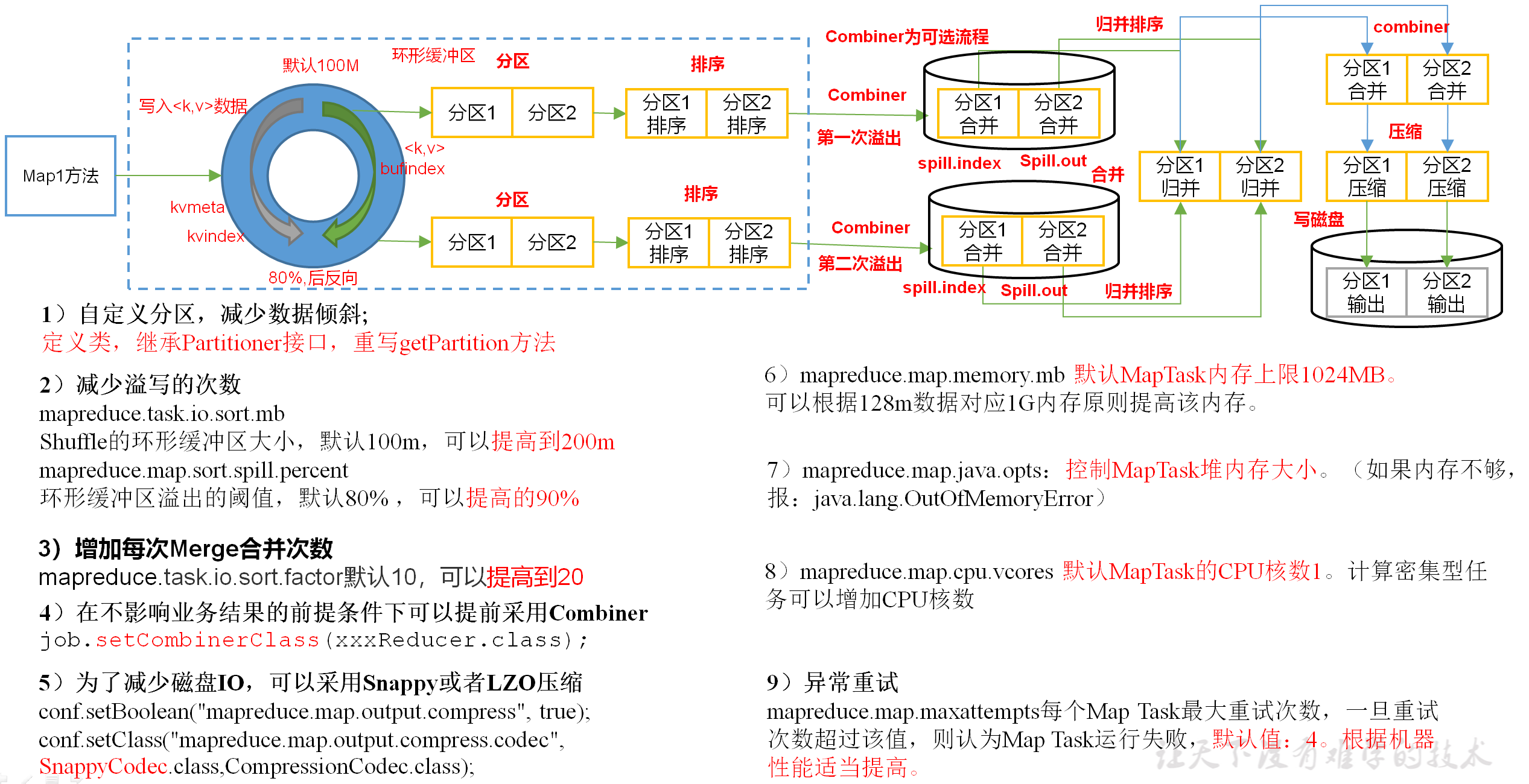

MapReduce 实现基本SQL操作的原理(不需要掌握)
json on
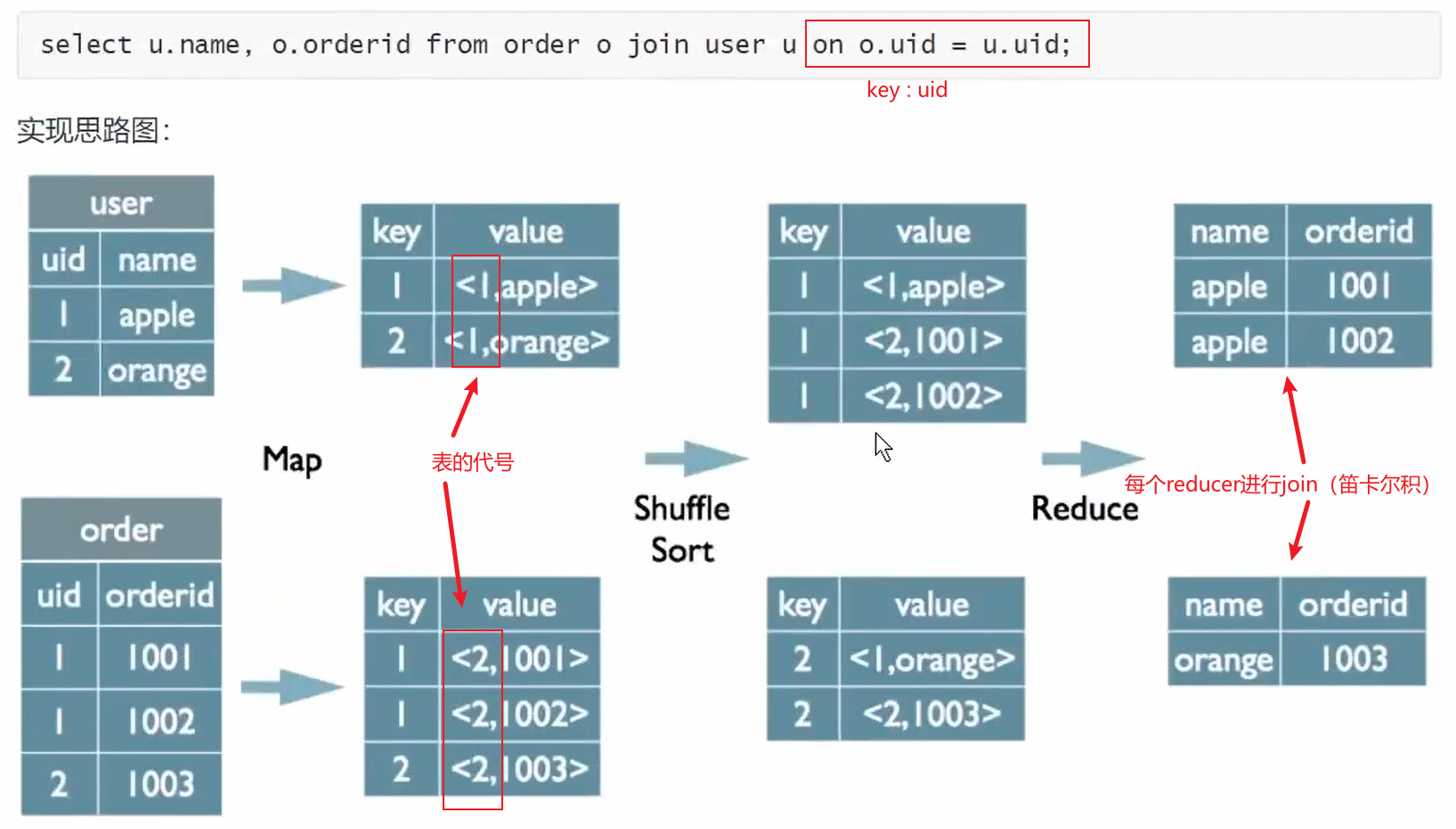
Group By

distinct
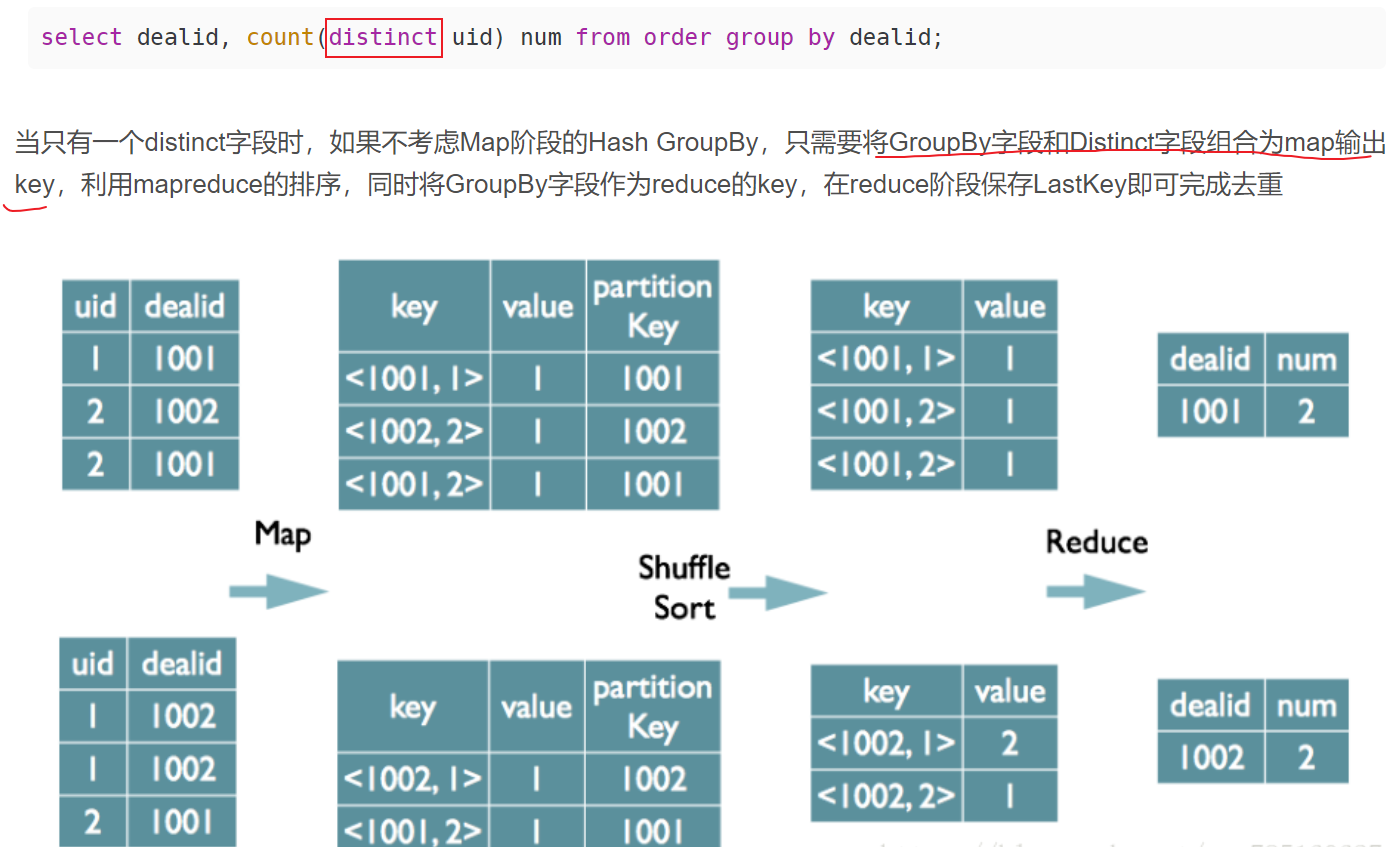
MapReduce: shuffle不排序直接输出难道不好吗?
答:
其实不用sort(排序)也能shuffle,也能把key相同的东西放到同一个分区,那为什么要sort排序呢?
MR在reduce阶段需要分组,将key相同的放在一起进行规约,为了达到该目的,有两种算法:hashmap和sort,前者太耗内存,而通过分阶段的外部排序可对任意数据量分组,减少内存压力,只要磁盘够大就行。在map端排序是为了减轻reduce端排序的压力,另外也方便做map Combine等操作。在spark中,除了sort的方法,也提供hashmap,用户可配置,毕竟sort开销太大了。
- 回顾溢写阶段:
(4)Spill阶段:即“溢写”,当环形缓冲区满后,MapReduce会将数据写到本地磁盘上,生成一个临时文件。需要注意的是,将数据写入本地磁盘之前,先要对数据进行一次本地排序,并在必要时对数据进行合并、压缩等操作。
溢写阶段详情:
步骤1:利用快速排序算法对缓存区内的数据进行排序,排序方式是,先按照分区编号Partition进行排序,然后按照key进行排序。这样,经过排序后,数据以分区为单位聚集在一起,且同一分区内所有数据按照key有序。
步骤2:按照分区编号由小到大依次将每个分区中的数据写入任务工作目录下的临时文件output/spillN.out(N表示当前溢写次数)中。如果用户设置了Combiner,则写入文件之前,对每个分区中的数据进行一次聚集操作。
步骤3:将分区数据的元信息写到内存索引数据结构SpillRecord中,其中每个分区的元信息包括在临时文件中的偏移量、压缩前数据大小和压缩后数据大小。如果当前内存索引大小超过1MB,则将内存索引写到文件output/spillN.out.index中。
(5)Merge阶段:当所有数据处理完成后,MapTask对所有临时文件进行一次合并,以确保最终只会生成一个数据文件。
当所有数据处理完后,MapTask会将所有临时文件合并成一个大文件,并保存到文件output/file.out中,同时生成相应的索引文件output/file.out.index。
在进行文件合并过程中,MapTask以分区为单位进行合并。对于某个分区,它将采用多轮递归合并的方式。每轮合并mapreduce.task.io.sort.factor(默认10)个文件,并将产生的文件重新加入待合并列表中,对文件排序后,重复以上过程,直到最终得到一个大文件。
让每个MapTask最终只生成一个数据文件,可避免同时打开大量文件和同时读取大量小文件产生的随机读取带来的开销。
Yarn:工作机制

Yarn: 容器的启动
海康威视
https://blog.csdn.net/ThreeAspects/article/details/108918858
Container启动命令,是由AppMaster通过RPC函数ContainerManager.startContainer()向NodeManager发起,
主要经历三个阶段:
- 资源本地化
- 启动并运行container
- 资源回收。
资源本地化指创建container工作目录,从HDFS下载运行container所需的各种资源(jar包、可执行文件等)等;资源回收则是资源本地化的逆过程,它负责清理各种资源,它们均由ResourceLocalizationService服务完成的;
启动container是由ContainersLauncher服务完成的,而运行container是由插拔式组件ContainerExecutor完成的,YARN提供了两种ContainerExecutor实现,一种是DefaultContainerExecutor,另一种LinuxContainerExecutor。
资源本地化
资源本地化是指准备container运行所需的环境,包括创建container工作目录,从HDFS下载运行container所需的各种资源(jar包、可执行文件等)等。由ResourceLocalizationService服务完成。
YARN将资源分为两类:
- public级别:存放在公共目录,所有用户共享;由PublicLocalizer线程负责下载,线程内部维护了一个线程池加快下载速度。
- private级别:存放用户沐浴露,只能用户各个作业间共享;LocalizerRunner线程负责下载。
启动并运行Container
启动Container是由ContainersLauncher完成的,该过程主要工作是将运行container对应的完整shell命令写到私有目录下的launch_container.sh中,并将token文件写到container_tokens中。之所以要将container运行命令写到launch_container.sh中,然后通过运行shell脚本的形式运行container,主要是因为直接执行命令可能会有些特殊符号不识别。
而运行container是由插拔式组件ContainerExecutor完成的,YARN提供了两种ContainerExecutor实现,一种是DefaultContainerExecutor,另一种是LinuxContainerExecutor。DefaultContainerExecutor只是简单的以管理员身份运行launch_container.sh脚本,而LinuxContainerExecutor则是以container所属用户身份运行该脚本,它是Hadoop引入安全机制后加入的。
资源回收
资源回收由ResourceLocalizationService服务完成的,该过程与资源本地化正好相反,它负责撤销container运行过程中使用的各种资源。
资源隔离方案
YARN对内存资源和CPU资源采用了不同的资源隔离方案。对于内存资源,为了能够更灵活的控制内存使用量,YARN采用了进程监控的方案控制内存使用,即每个NodeManager会启动一个额外监控线程监控每个container内存资源使用量,一旦发现它超过约定的资源量,则会将其杀死。采用这种机制的另一个原因是java中创建子进程采用了fork()+exec()的方案,子进程启动瞬间,它使用的内存量与父进程一致,从外面看来,一个进程使用内存量可能瞬间翻倍,然后又降下来,采用线程监控的方法可防止这种情况下导致swap操作。对于CPU资源,则采用了Cgroups进行资源隔离。
Yarn: 是如何控制容器的内存大小
yarn-site.xml :
yarn.nodemanager.resource.memory-mb
yarn.nodemanager.resource.cpu-vcores
yarn.scheduler.minimum-allocation-mb
yarn.scheduler.maximum-allocation-mb
yarn.scheduler.minimum-allocation-vcores
yarn.scheduler.maximum-allocation-vcores
Yarn:yarn如何保证数据一致性的(CAP),主要问的resourcemanager
字节社招
QJM: paxos算法怎么用的,知道字节为什么不用QJM而用Zookeeper?
聊聊QJM吧,这边paxos算法怎么用的,你知道为什么字节不用QJM而是使用bookkeeper吗?
字节社招
Zookeeper:选举机制
阿里,字节x2,腾讯,贝壳,网易,去哪儿
1)Zookeeper的选举策略
2)Zookeeper的选举过程
3)Zookeeper的Leader选举是如何实现的


Zookeeper:同步过程/Follower和Leader状态同步
网易

说下raft、zab和paxos
字节社招
Zookeeper一致性算法
海康威视
Zookeeper 监听原理

简单命令
1、
2、
zkCli.sh 客户端脚本,运行即可进入zk客户端命令行。 
3、create 创建节点,并且获取节点的值
4、在任意客户端,修改节点值
set /myzk value999
5、 在任意客户端,观察修改后的节点信息
get -s /myzk 或者 stat /myzk
6、 创建临时节点 
7、删除节点
delete /myzk
deleteall /myzk 递归删除
客户端监听
每个客户端都会开启两个线程,负责与服务器通信的connect和负责监听主机端口的Listener。
1、创建一个节点create /sanguo "sunwukong"
2、A客户端使用get -w /sanguo 在服务器端的监听列表中注册了“监听/sanguo节点”的需求,或者ls -w /sanguo来注册“监听子节点”的需求。
3、任何客户端(包括A自己)修改了该节点,比如修改值set /sanguo sunwukong,或删除节点delete /sanguo或修改子节点create /sanguo/jin "simayi",服务端就会向A客户端的监听端口发送消息,
值变化:
WatchedEvent state:SyncConnected type:NodeDataChanged path:/sanguo
节点删除:
WatchedEvent state:SyncConnected type:NodeDeleted path:/sanguo
子节点变化:
WatchedEvent state:SyncConnected type:NodeChildrenChanged path:/sanguo
注意:一次监听注册,只能监听一次变换。
注意:临时节点没有不能创建子节点。
Zookeeper服务器动态上下线监听

服务器端 <—- 注册服务器到zk集群

客户端 <— 反复监听
1、获取zk连接(一次注册只能监听一次,所以这里在重写的process方法中调用getServerList(),即“监听 -> 客户端处理好服务端的消息 -> 监听”这样一直循环)
2、监听/servers下子节点的增加和删除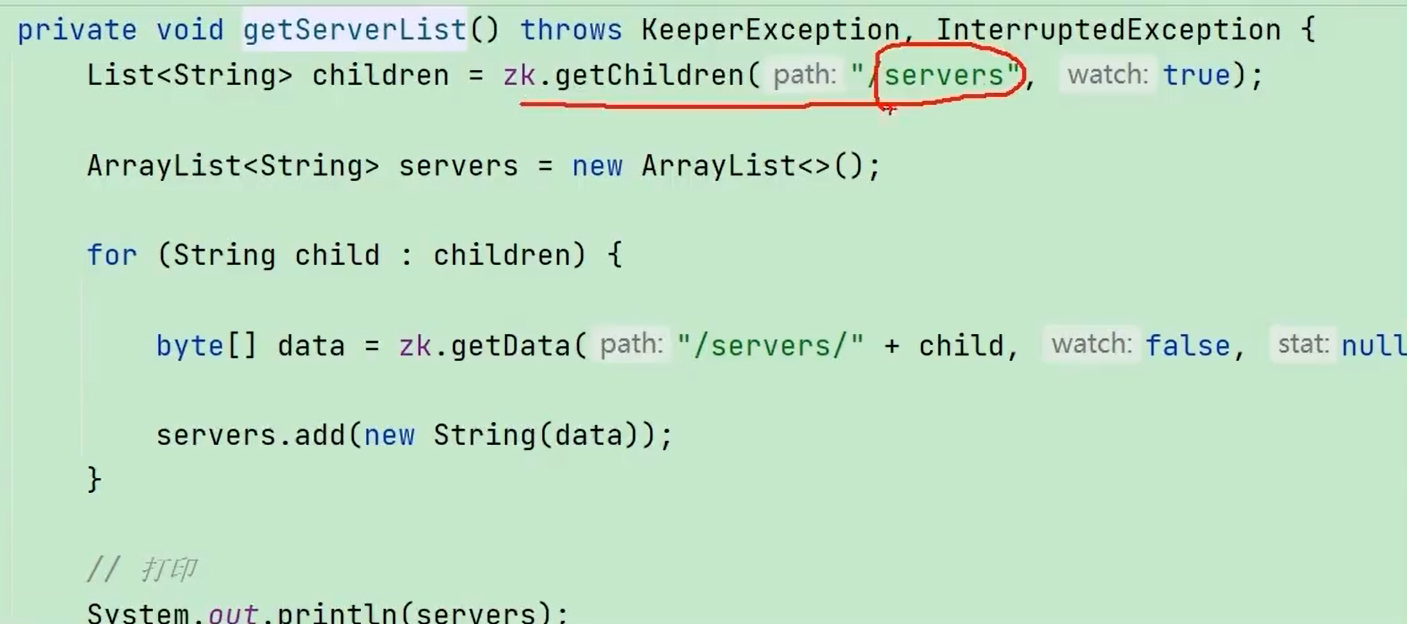
3、业务逻辑(这里的就是睡觉,即定期)
Zookeeper分布式锁

public class DistributedLock{private final String connectString = "hadoop102:2181,hadoop103:2181,hadoop104:2181";private final int sessionTimeout = 2000;private final Zookeeper zk;private CountDownLatch connectLatch = new CountDownLatch(1); // 锁private CountDownLatch waitLatch = new CountDownLatch(1);String waitPath;String currentPath;public DistributedLock(){// 获取连接Zookeeper zk = new Zookeeper(connectString,sessionTimeout,new Watcher(){@overridepublic void process(WatchedEvent watchedEvent){// 处理zk的消息,这里是控制CountDownLatch锁。// connectLatch: 如何连接上zk,那么释放一个connectLatch计数if(watchedEvent.getState()==Event.keeperState.SyncConnected){connectLatch.countDown();}// waitLatch: 如果前一个节点删除,那么释放一个waitLatch计数。if (watchedEvent.getType()==EventType.NodeDelected && watchedEvent.getType().equals(waitPath)){waitLatch.countDown();}}})// 等待zk正常连接后,往下走程序connectLatch.await();// 判断根结点/locks是否存在Stat stat = zk.exists("/locks",false)if (stat == null){// 创建一个根结点(完全开放ACL、永久节点)zk.create("/locks","locks".getBytes(),ZooDefs.Ids.OPEN_ACL_UNSAFE,CreateMode.PERSISTENT);}}// 加锁public void zkLock(){// 创建对应的临时带序号节点 (完全开放ACL、EPHEMERAL_SEQUE节点)currentPath = zk.create("/locks/" + "seq-",null,ZooDefs.Ids.OPEN_ACL_UNSAFE,CreateMode.EPHEMERAL_SEQUE)// 判断创建的节点是否是最小的,如果是获取锁; 如果不是,监听他序号前一个节点List<String> children = zk.getChildren("/locks",false); // watch=falseif (childern.size() == 1){return;}else{Collections.sort(children); // 数组排序// 获取节点名称 seq-0000000, 获得在数组中的索引int index = children.indexOf( currentPath.substring("/locks/".length()))// 判断if (index == 0){// 可以获取锁return;}else{// 监听前一个节点waitPath = "/locks/" + children.get(index-1);zk.getData(waitPath,true,null); // watch=truewaitLatch.await();return;}}}// 解锁public void unzkLock(){// 删除节点zk.delete(currentPath,-1); // version=-1随意指定}}
Zookeeper ZooDefs.Ids OPEN_ACL_UNSAFE : 完全开放的ACL,任何连接的客户端都可以操作该属性znode CREATOR_ALL_ACL : 只有创建者才有ACL权限 READ_ACL_UNSAFE:只能读取ACL
CreateMode.EPHEMERAL_SEQUE 临时带序号节点
private CountDownLatch waitLatch = new CountDownLatch(1); waitLatch.await() 每当一个线程执行完毕后,计数器的值就减1
Hive:内部表和外部表的区别
字节,阿里社招,快手,美团x2,蘑菇街x2,祖龙娱乐,作业帮x2,360,小米,竞
技世界,猿辅导,冠群驰骋,好未来,富途
关键字:由谁管理、存储位置、删除、修改
内部表(managed table ): 未被external修饰
外部表(external table): 被external修饰
hive的元数据保存在关系型数据库中,如hive内置的Derby、第三方如MySQL。
内部表和外部表的区别体现在对于原始数据的管理上。
区别
- 内部表原始数据由Hive自身管理,外部表原始数据由HDFS管理;
- 内部表的数据存储位置是 hive.metas tore.warehouse.dir,默认位置 : /user /hive/warehouse,外部表数据的存储位置由自己制定(如果没有LOCATION,Hive将在HDFS的/user/hive/warehouse文件夹下以外部表的表名创建一个文件夹,并将属于这个表的数据存放在这里);
- 删除内部表会直接删除元数据(metadata)及原始数据;删除外部表仅仅会删除元数据,HDFS上的文件并不会被删除;
- 对内部表的修改会将修改直接同步给元数据 ,而对外部表的表结构和分区进行修改,则需要修复(MSCK REPAIR TABLE table_name;)
Hive的特点有什么
网易
Hive和Hbase区别
趋势社招
Flume:source、channel、slink有哪些
阿 里 x2 , 腾 讯 , 字 节 , 快 手 x2 , 流 利 说 , 创 略 科 技 , 宇 信 科 技 , 猿 辅 导 , 转 转 ,
bigo,多益,富途x2
Source是负责接收数据到Flume Agent的组件。
taildir source:
- 支持:断点续传、多目录
- 不支持:递归遍历文件夹读取文件
- 挂了重启:不会丢数据,但可能重复数据,一般在hive中去重;
Channel是缓冲区,是线程安全的,可以同时处理多个Source写入和多个Sink读取。
file channel
- 数据存储于磁盘,优势:可靠性高;劣势:传输速度低
- 默认容量:100万event
- 注意:FileChannel可以通过配置dataDirs指向多个路径,每个路径对应不同的硬盘,增大Flume吞吐量。
memory channel
- 数据存储于内存,优势:传输速度快;劣势:可靠性差
- 默认容量:100个event
kafka channel
- 数据存储于Kafka,基于磁盘;
- 优势:可靠性高;
- 传输速度快Kafka Channel 大于Memory Channel + Kafka Sink 原因省去了Sink阶段
channel生产环境选择
- 如果是金融、对钱要求准确的公司,选择File Channel
- 如果就是普通的日志,通常可以选择Memory Channel
- 其他日志,选择kafka channel
Sink轮询向Channel中批量拉取event,并批量写入存储或索引系统,或者发送到另一个Flume Agent.
HDFS sink
- 1小时-2小时刷新, 128m固定大小刷新、event个数刷新(0禁止)
- 具体参数:hdfs.rollInterval=3600,hdfs.rollSize=134217728,hdfs.rollCount =0
HBASE sink
Kafka sink
Hive sink
Kafka:如何实现高吞吐
蘑菇街x2,腾讯,美团x2,猿辅导,转转,小鹏汽车,京东,字节,网易、字节社招
- kafka本身是分布式集群,同时采用分区技术,并发度高。
- 磁盘顺序读写
消息不断追加到文件中,省去随机读写的磁头寻道时间,只需要很少的扇区旋转时间。
- 零拷贝
跳过不必要的拷贝,尤其是用户缓冲区的拷贝,建立一个磁盘空间和内存的直接映射,数据不再复制到“用户态缓冲区”,且减少系统上下文切换。
Kakfa 服务端接收 Producer 的消息并持久化的场景下使用 mmap 机制,能够基于顺序磁盘 I/O 提供高效的持久化能力,使用的 Java 类为 java.nio.MappedByteBuffer。
Kakfa 服务端向 Consumer 发送消息的场景下使用 sendfile 机制。其他好处,sendfile基于page cache实现,当多个consumer消费同一个topic时,只需要一次磁盘IO。
- 批量发送
固定大小、固定时间批量发送消息,大量减少服务端的I/O次数。
Kafka : 零拷贝细节(低频)



kafka: 组件熟悉吗,kafka 如何实现消息的有序的?
哔哩哔哩
- 分区内有序,分区间无序。
kafka 每个 partition 中的消息在写入时都是有序的,消费时, 每个 partition 只能被每一个消费者组
中的一个消费者消费,保证了消费时也是有序的。
zookeeper:kafka01/consumers/consumer-groups/offsets….
- kafka Producer 发送消息时,topic的分区选择
public ProducerRecord(String topic, Integer partition, Long timestamp, K key, V value){ … };
- 指定分区
- 不指定分区,有指定key: 采用HashPartitioner来计算消息的分区号。
- 不指定分区,不指定key:轮询各分区发送
- 有序方案1(限制了并发,不建议)
kafka topic 只设置一个partition分区
- 有序方案2:producer将消息发送到指定同一个partition分区
同一张表的数据放到同一个分区:ProducerRecord 方法中传入特定key(如 库/表名)来指定分区号。
Kafka: 消息确认(ack 应答)机制了解吗?
哔哩哔哩
Kafka: LEO、HW、LSO、LW 分别代表什么?
哔哩哔哩
LEO:是 LogEndOffset 的简称,代表当前日志文件中最大偏移量。
HW: 取 partition 对应的 ISR 中最小的 LEO 作为 HW,HW之前的数据才对Consumer可见。
LSO: 是 LastStableOffset 的简称,对未完成的事务而言,LSO 的值等于事务中第一条消息的位置
(firstUnstableOffset),对已完成的事务而言,它的值同HW 相同。
LW: Low Watermark 低水位,代表 AR 集合中最小的 logStartOffset 值。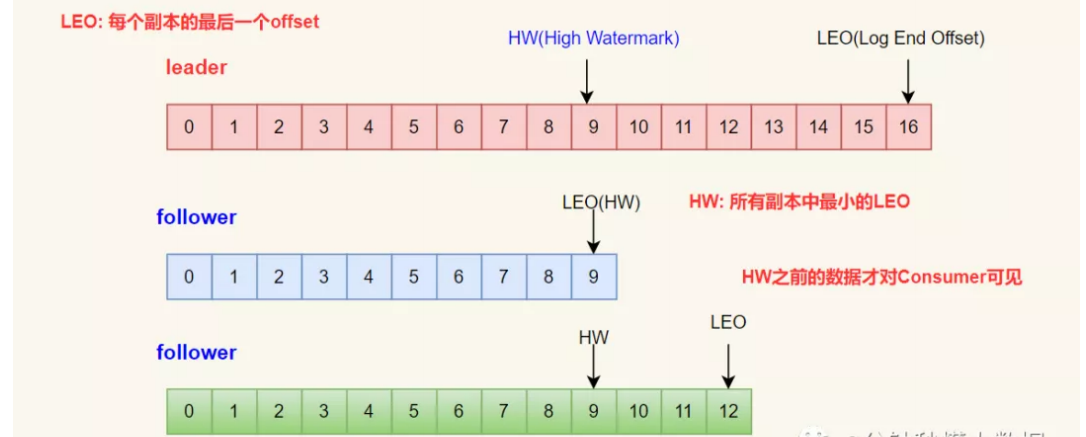
flume和kafka怎么配置(数仓)
- 用户日志 —> “采集日志的flume —> 消息缓存的kafka —-> 消费kafka的flume” —> HDFS
并没有单独使用kafka, 而是在flume中使用了kafka channel 和 kafka source。
- [采集日志的flume —> 消息缓存的kafka]放在同一节点,且放在了3台节点上。
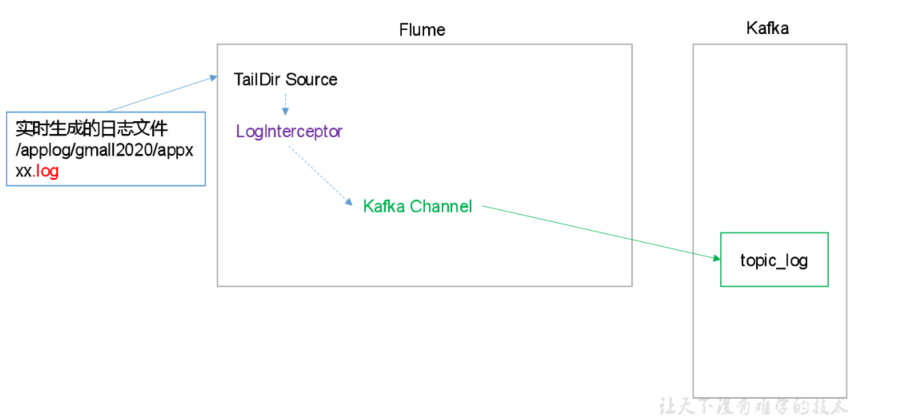
TailDir Source: 断点续传、多目录
- 消费kafka的flume放在一台节点上。

时间戳拦截器(防止零点漂移问题):拦截json日志,通过fastjson框架解析json,获取实际时间ts。将获取的ts时间写入拦截器header头,header的key必须是timestamp,因为Flume框架会根据这个key的值识别为时间,写入到HDFS。
File channel: dataDirs指向多个路径,每个路径对应不同的硬盘,增大Flume吞吐量.
HDFS Sink: hdfs.rollInterval=3600,hdfs.rollSize=134217728,hdfs.rollCount =0 来尽量避免小文件。
File channel底层原理
关于Flume配置和拦截器的编写
在/opt/module/flume/conf目录下创建file-flume-kafka.conf
各组件命名、各组件type、组件之间关系
#为各组件命名a1.sources = r1a1.channels = c1#描述sourcea1.sources.r1.type = TAILDIRa1.sources.r1.filegroups = f1a1.sources.r1.filegroups.f1 = /opt/module/applog/log/app.*a1.sources.r1.positionFile = /opt/module/flume/taildir_position.jsona1.sources.r1.interceptors = i1a1.sources.r1.interceptors.i1.type = com.atguigu.flume.interceptor.ETLInterceptor$Builder#描述channela1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannela1.channels.c1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092a1.channels.c1.kafka.topic = topic_loga1.channels.c1.parseAsFlumeEvent = false#绑定source和channel以及sink和channel的关系a1.sources.r1.channels = c1
import com.alibaba.fastjson.JSON;import org.apache.flume.Context;import org.apache.flume.Event;import org.apache.flume.interceptor.Interceptor;public class ETLInterceptor implements Interceptor {@Overridepublic void initialize() {}@Overridepublic Event intercept(Event event) {}@Overridepublic List<Event> intercept(List<Event> list) {}@Overridepublic void close() {}public static class Builder implements Interceptor.Builder{@Overridepublic Interceptor build() {return new ETLInterceptor();}@Overridepublic void configure(Context context) {}}
Hbase存储原理和过程
网易
逻辑上,HBase的数据模型同关系型数据库很类似,数据存储在一张表中,有行有列。但从HBase的底层物理存储结构(K-V)来看,HBase更像是一个multi-dimensional map。、
- 逻辑结构

- 物理结构

- RegionServer架构

- 写流程

- 读流程

HBase:rowkey设计原则
阿里x3,腾讯x2,美团x3,顺丰,360,小米x4,富途,蘑菇街,陌陌x2,美团,冠
群驰骋,携程x2,vivo
1)HBase如何设计rowkey?
2)你HBase的rowkey为什么这么设计?有什么优缺点?
3)Hbase rowKey设置讲究
1、rowkey长度原则
Rowkey是一个二进制码流,Rowkey的长度被很多开发者建议说设计在10~100个字
节,不过建议是越短越好,不要超过16个字节。
原因如下:
1)数据的持久化文件HFile中是按照Key Value 存储的,如果Rowkey过长比如100
个字节,1000万列数据光Rowkey就要占用1001000 万=10亿个字节,将近1G数据,这会极大影响 HFile的存储效率;
2)MemStore将缓存部分数据到内存,如果 Rowkey字段过长内存的有效利用率会
降低,系统将无法缓存更多的数据,这会降低检索效率。因此Rowkey的字节长度越短
越好;
3)目前操作系统是都是64位系统,内存8字节对齐。控制在16个字节,8字节的整数
倍利用操作系统的最佳特性。
2、rowkey散列原则
如 果 Rowkey 是 按 时 间 戳 的 方 式 递 增 , 不 要 将 时 间 放 在 二 进 制 码 的 前 面 , 建 议 将
Rowkey的高位作为散列字段,由程序循环生成,低位放时间字段,将会提高数据均衡
分布在每个Regionser ver实现负载均衡的几率。如果没有散列字段,首字段直接是时
间信息将产生所有新数据都在一个 RegionSer ver上堆积的热点现象,这样在做数据
检索的时候负载将会集中在个别 RegionSer ver,降低查询效率。
*3、rowkey唯一原则
必 须 在 设 计 上 保 证 其 唯 一 性 。 rowkey 是 按 照 字 典 顺 序 排 序 存 储 的 , 因 此 , 设 计
rowkey的时候,要充分利用这个排序的特点,将经常读取的数据存储到一块,将最近
可能会被访问的数据放到一块。
Hbase是kv存储,k是三维结构,由rowkey,colFamily,TimeStamp构成。
rowkey设计原则:唯一性、散列性、rowkey长度(短一些节省存储)
一条数据的唯一标识就是rowkey,那么这条数据存储于哪个分区,取决于rowkey处于哪个一个预分区的区间内,设计rowkey的主要目的 ,就是让数据均匀的分布于所有的region中,在一定程度上防止数据倾斜。
(原因:一个region对应一个map)
1.生成随机数、hash、散列值
| 比如: 原本rowKey为1001的,SHA1后变成:dd01903921ea24941c26a48f2cec24e0bb0e8cc7 原本rowKey为3001的,SHA1后变成:49042c54de64a1e9bf0b33e00245660ef92dc7bd 原本rowKey为5001的,SHA1后变成:7b61dec07e02c188790670af43e717f0f46e8913 在做此操作之前,一般我们会选择从数据集中抽取样本,来决定什么样的rowKey来Hash后作为每个分区的临界值。 |
|---|
2.字符串反转
| 20170524000001转成10000042507102 20170524000002转成20000042507102 |
|---|
这样也可以在一定程度上散列逐步put进来的数据。
3.字符串拼接
| 20170524000001_a12e 20170524000001_93i7 |
|---|
场景: 运营商电话记录
一条记录构成: 1881231342(主叫) 180812818231(被叫) 2021-06-22 12:12:12(开始时间) 00:03:01(结束时间) asdfafaffasfdsf(通话数据)
业务:查询某个用户 某天 某也 某年 的通话记录 (查询某天、某月的业务更多)
- 初步设计
rowkey可以是1881231342_2021-06-22 12:12:12;
colFamily可以是info;
info:c1是被叫电话,info:c2是结束时间,info:c3是通话数据。
- 那么预分区规划可以是50个分区,分区规划是:
-∞ ~ 00|
00| ~ 01|
01| ~ 02|
….
49| ~ 50|
- 改进rowkey
更具业务需求,查询某天、某月的业务更多,所以将rowkey中的1881231342_2021-06部分,即Phone_YYYY-MM作为分区规划的依据更好。
计算1881231342_2021-06 % 50 作为rowkey的前缀,这些前缀的范围在0 ~ 50之间,
那么有如下这些rowkey:
01_1881231342_2021-06-22 12:12:12
01_1881231342_2021-06-24 12:12:12
02_1991000002_2021-09-11 12:03:00
那么根据分区规划,某个用户的指定月份内的通话都会存放到一个分区中(符合业务需求),但是不同用户或者同一个用户的不同月、不同年都分散到不同的分区中(防止后续MR中数据倾斜)。
数据倾斜
字节跳动x8,安恒信息,顺丰,腾讯,网易云音乐x2,小米,祖龙娱乐,商汤科技,
阿里,米哈游,快手,百度社招,触宝,多益,贝壳,ebayx2,京东,嘉云数据
- 数据倾斜
数据倾斜是指,并行处理数据集中,大量相同的key被分配到了同一个任务上,造成“一个人累死、其他人闲死”的状况,违背分布式计算的初衷。导致两个致命后果:某个task成为处理速度的瓶颈,Out of Memory;。
- 直观表现
任务进度长时间维持在99%(或100%),查看任务监控页面,发现只有少量(1个或几个)reduce子任务未完成。
- 4类产生原因
1、key分布不均匀;
2、业务数据本身的特性;
3、建表时考虑不周;
4、某些SQL语句本身就有数据倾斜
- 主要发生在Reduce阶段,很少在map阶段
1、 很少发生在Map阶段,是因为Map端数据倾斜一般由于HDFS数据存储不均匀导致,一般存储都是均匀分块存储的。
2、Reduce阶段几乎是因为开发者没有考虑key的分布情况(非常不均匀),一般在shuffle阶段,最常见场景是Group by、Join、Count Distinct。
Hive数据倾斜-解决方案
- 优先开启负载均衡 <—- 局部MR(随机分区)+全局MR(按key分区)。
- 表join连接时引发的数据倾斜
- 小表join大表,某个key过大 <—- set hive.groupby.skewindata=true 开启MapJoin优化
- 表中作为关联条件的字段为0或空值的较多 <—- 空值添加随机key值,或提前在临时表中去除空值的行
- 表中作为关联条件的字段重复值过多 <—- join前过滤掉过时\无用的行(如
- 空值引发的数据倾斜 <—- from a join b中,a中不为null的行的join的结果集 UNION ALL a中为null的行的结果集
- 不同数据类型关联引发的数据倾斜 <—- 统一数据类型(表规范问题)
- count distinct大量相同特殊值 <—- 先去重、然后分组统计(因为distinct会进行排序操作)
- 数据膨胀引发的数据倾斜 <—- hive.new.job.grouping.set.cardinality=10 自动作业拆解
1、优先开启负载均衡
MapReduce 进程则会生成两个额外的 MR Job。
第一步:局部MR Job,将Map的结果集合随机分配到Reduce中做局部聚合操作
第二步:全局MR Job,将局部聚合的结果进行正常的shuffle过程(如group by key)分配给Reduce完成全局聚合。
-- map端的Combiner,默认为tureset hive.map.aggr=true;-- 开启负载均衡set hive.groupby.skewindata=true (默认为false)
2、表join连接时引发的数据倾斜
表连接的key倾斜,导致shuffle阶段数据倾斜。
- 小表join大表,某个key过大
MapJoin优化:将倾斜的数据,分发到各个Map任务所在节点的分布式缓存中,在Map阶段完成Join,避免了Reduce任务进行shuffle,从而避免数据倾斜和提高Join效率。
Hive 0.11版本及之后,Hive默认启动该优化(默认25M来区分大小表)
-- 自动开启MAPJOIN优化,默认值为true,
set hive.auto.convert.join=true;
-- 通过配置该属性来确定使用该优化的表的大小,如果表的大小小于此值就会被加载进内存中,默认值为2500000(25M),
set hive.mapjoin.smalltable.filesize=2500000;
-- 特殊说明
使用默认启动该优化的方式如果出现莫名其妙的BUG(比如MAPJOIN并不起作用),就将以下两个属性置为fase手动使用MAPJOIN标记来启动该优化:
-- 关闭自动MAPJOIN转换操作
set hive.auto.convert.join=false;
-- 不忽略MAPJOIN标记
set hive.ignore.mapjoin.hint=false;
-- join on 语句
SELECT a.id FROM a LEFT JOIN b ON a.id=b.id ;
注1:通过参数 mapreduce.map.memory.mb 调节Map端内存的大小,来防止MapJoin造成Map节点内存溢出。
注2:mapreduce.map.memory.mb 调节Reduce端内存大小。
- 表中作为关联条件的字段为0或空值的较多
原因:0或空值是指无意义的值,但是作为Key,在MR的shuffle过程中,它们会被分到同一个分区文件中,所以空值较多,将导致数据倾斜。
解决1:给空值添加随机key值,将其分发到不同的reduce中处理。由于null值关联不上,所以对结果无影响。
涉及语法:case when then else end ,或用 nvl(a.user_id, concat('hive',rand())) = b.user_id;
解决2:在临时表中去除关联字段的无意义行
-- 方案一、给空值添加随机key值,将其分发到不同的reduce中处理。由于null值关联不上,所以对结果无影响。
SELECT *
FROM log a left join users b
on case when a.user_id is null then concat('hive',rand()) else a.user_id end = b.user_id;
-- 方案二:在临时表中去除关联字段的无意义行
SELECT a.*,b.name
FROM
(SELECT * FROM users WHERE LENGTH(user_id) > 1 OR user_id IS NOT NULL ) a
JOIN
(SELECT * FROM log WHERE LENGTH(user_id) > 1 OR user_id IS NOT NULL) B
ON a.user_id; = b.user_id;
表中作为关联条件的字段重复值过多
用于join的字段存在重复值,那么联表查询的结果将会产生多条重复数据,从而导致数据倾斜。
例如,对于关联字段id,存在create_time不同的多个行,可以在join前过滤掉过时的行。SELECT a.*,b.name FROM (SELECT * FROM users WHERE LENGTH(user_id) > 1 OR user_id IS NOT NULL ) a JOIN (SELECT * FROM (SELECT *,row_number() over(partition by user_id order by create_time desc) rk FROM log WHERE LENGTH(user_id) > 1 OR user_id IS NOT NULL) temp where rk = 1) B ON a.user_id; = b.user_id;3、空值引发的数据倾斜
null被会分配到同一个分区文件中(只要key的hash一样),导致reduce的shuffle阶段数据倾斜。
方案二优于方案一:因为方案一job两次,io两次,方案二job1次,io一次。
SELECT * FROM log a LEFT JOIN users b , 下面用join 和 union来分解它。
-- 解决方案
-- 场景:如日志中,常会有信息丢失的问题,比如日志中的 user_id,如果取其中的 user_id 和 用户表中的user_id 关联,会碰到数据倾斜的问题。
-- 方案一:可以直接不让null值参与join操作,即不让null值有shuffle阶段,所以user_id为空的不参与关联
SELECT * FROM log a JOIN users b ON a.user_id IS NOT NULL AND a.user_id = b.user_id UNION ALL SELECT * FROM log a WHERE a.user_id IS NULL;
-- 方案二:因为null值参与shuffle时的hash结果是一样的,那么我们可以给null值随机赋值,这样它们的hash结果就不一样,就会进到不同的reduce中:
SELECT * FROM log a LEFT JOIN users b ON CASE WHEN a.user_id IS NULL THEN concat('hive_', rand()) ELSE a.user_id END = b.user_id;'
4、不同数据类型关联引发的数据倾斜
对于两个表join, 表a中需要关联字段key为int类型,表b中关联字段key既有string类型也有int类型。当按照key进行join时,默认的hash操作会对key按int类型对进行分区,这样所有的string类型都被分配到同一个分区文件中,导致reduce的shuffle阶段数据倾斜。
-- 如果key字段既有string类型也有int类型,默认的hash就都会按int类型来分配,
-- 那我们直接把int类型都转为string就好了,这样key字段都为string,hash时就按照string类型分配了:
方案一:把数字类型转换成字符串类型
SELECT * FROM users a LEFT JOIN logs b ON a.usr_id = CAST(b.user_id AS string);
方案二:建表时按照规范建设,统一词根,同一词根数据类型一致
5、count distinct大量相同特殊值
由于SQL中的Distinct操作本身会有一个全局排序的过程,一般情况下,不建议采用Count Distinct方式进行去重计数,除非表的数量比较小。当SQL中不存在分组字段时,Count Distinct操作仅生成一个Reduce 任务,该任务会对全部数据进行去重统计;当SQL中存在分组字段时,可能某些 Reduce 任务需要去重统计的数量非常大。在这种情况下,我们可以通过以下方式替换。
-- 可能会造成数据倾斜的sql
select a,count(distinct b) from t group by a;
-- 先去重、然后分组统计
select a,sum(1) from (select a, b from t group by a,b) u
-- 总结: 如果分组统计的数据存在多个distinct结果,可以先将值为空的数据占位处理,分sql统计数据,然后将两组结果union all进行汇总结算。
6、数据膨胀引发的数据倾斜(适合多维聚合操作)
在多维聚合计算时,如果进行分组聚合的字段过多,且数据量很大,Map端的聚合不能很好地起到数据压缩的情况下,会导致Map端产出的数据急速膨胀,这种情况容易导致作业内存溢出的异常。如果log表含有数据倾斜key,会加剧Shuffle过程的数据倾斜。
set hive.new.job.grouping.set.cardinality=10;
-- 造成倾斜或内存溢出的情况
-- sql01
select a,b,c,count(1)from log group by a,b,c with rollup;
-- sql02
select a,b,c,count(1)from log grouping sets a,b,c;
-- 解决方案
-- 可以拆分上面的sql,将with rollup拆分成如下几个sql
select a,b,c,sum(1) from (
SELECT a, b, c, COUNT(1) FROM log GROUP BY a, b, c
union all
SELECT a, b, NULL, COUNT(1) FROM log GROUP BY a, b
union all
SELECT a, NULL, NULL, COUNT(1) FROM log GROUP BY a
union all
SELECT NULL, NULL, NULL, COUNT(1) FROM log
) temp;
-- 结论:但是上面这种方式不太好,因为现在是对3个字段进行分组聚合,那如果是5个或者10个字段呢,那么需要拆解的SQL语句会更多。
-- 在Hive中可以通过参数 hive.new.job.grouping.set.cardinality 配置的方式自动控制作业的拆解,该参数默认值是30。
-- 该参数主要针对grouping sets/rollups/cubes这类多维聚合的操作生效,如果最后拆解的键组合大于该值,会启用新的任务去处理大于该值之外的组合。
-- 如果在处理数据时,某个分组聚合的列有较大的倾斜,可以适当调小该值。
set hive.new.job.grouping.set.cardinality=10;
select a,b,c,count(1)from log group by a,b,c with rollup;
Spark数据倾斜
Reduce s ide Join转变为Map s ide Join
查看key的分布
可以pairs采样10%的样本数据使用countByKey算子统计出每个key的出现次数。
val sampledPairs = pairs.sample(false, 0.1)
val sampledWordCounts = sampledPairs.countByKey()
sampledWordCounts.foreach(println(_))
Spark定位数据倾斜代码
Spark数据倾斜只会发生再shuffle过程中。可能的触发算子:distinct、groupByKey、reduceByKey、aggregateByKey、join、cogroup、repartition等。
某个task执行特别慢
- suffle类算子将代码分为两个stage,见下。 ```scala val conf = new SparkConf() val sc = new SparkContext(conf)
// stage0,执行从textFile到map操作,以及shuffle write操作。 val lines = sc.textFile(“hdfs://…”) val words = lines.flatMap(.split(“ “)) val pairs = words.map((, 1)) // stage1,执行shuffle read操作,以及从reduceByKey到collect操作。 val wordCounts = pairs.reduceByKey( + ) // suffle类算子,可能导致数据倾斜 wordCounts.collect().foreach(println(_))
- 代码定位
Spark Web UI或者本地log中发现,stage1的某个几个task非常慢,可判定stage1出现数据倾斜,定位stage1部分代码,发现reduceByKey这个shuffle类算子,基本确定是该算子导致数据倾斜问题。
<a name="ArwOK"></a>
#### 某个task内存溢出
内存溢出也可能是代码bug,下面假设是因为数据倾斜产生的。<br />通过YARN查看yarn-cluster模式下的log中的异常栈,通过异常栈信息就能定位到代码附近,一般也有shuffle类算子。
<a name="wYWeu"></a>
# Spark: RDD的宽依赖和窄依赖
字 节 x7 , 小 米 x5 , 阿 里 x4 , 快 手 x3 , 美 团 x2 , 妙 盈 科 技 , 头 条 x2 , 网 易 云 , 蘑 菇 <br />街,京东x3,海康,抖音,米哈游,顺丰x2,360,拼多多,腾讯x2,作业帮社招, <br />猿辅导,ebay
---
Spark的宽依赖和窄依赖,为什么要这么划分?
---
RDD 和 它 依 赖 的 parent RDD( s ) 的 关 系 有 两 种 不 同 的 类 型 , 窄 依 赖 ( narrow <br />dependency)和宽依赖(wide dependency) <br />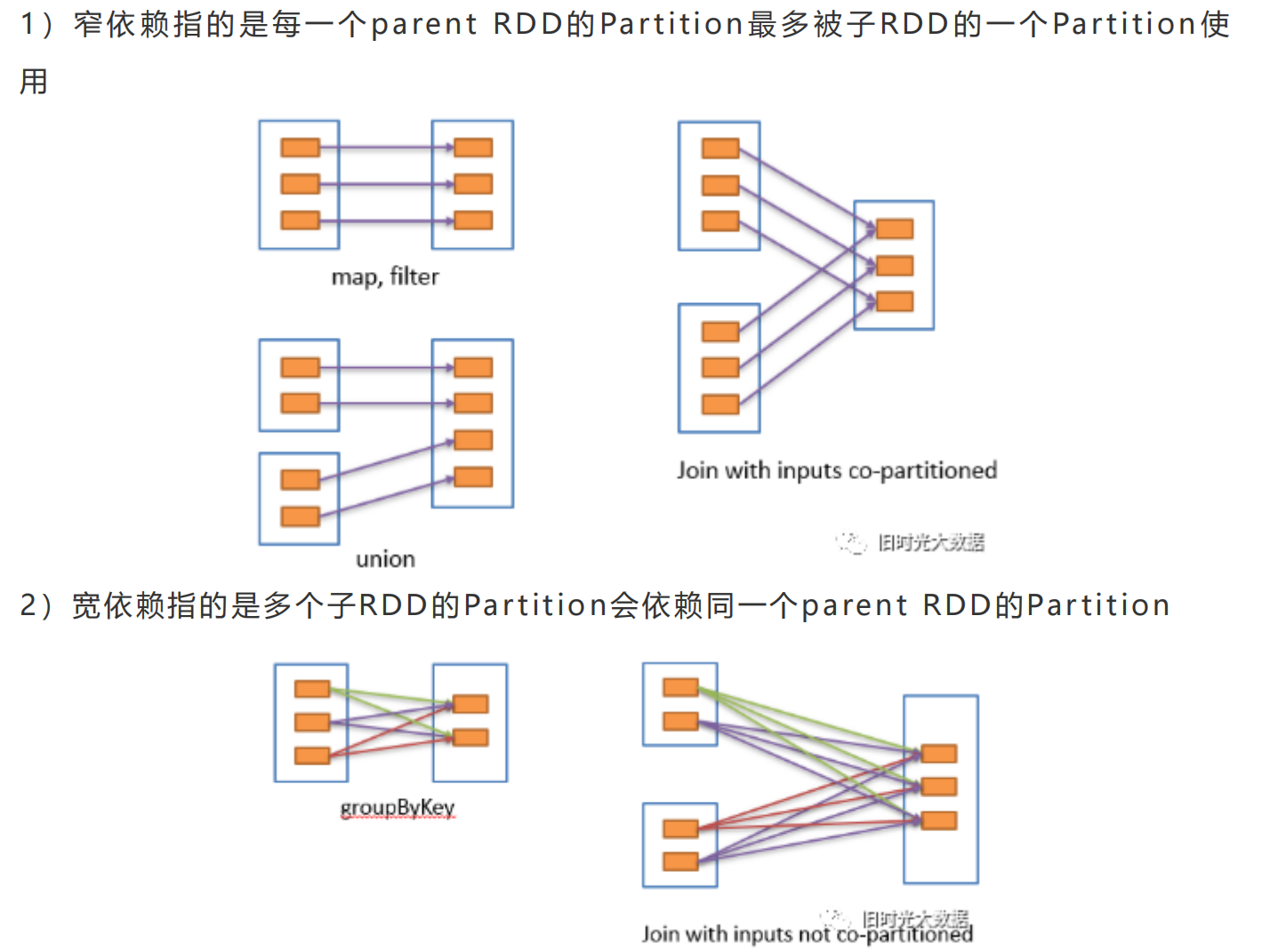
<a name="UwUgn"></a>
# Spark : cache、persist
趋势社招
---
<a name="AT1zE"></a>
# Spark: checkpoint和cache区别
趋势社招
---
<a name="TtWGM"></a>
# Spark: master、worker作用
趋势社招
---
<a name="Obo6R"></a>
# Spark:实际部署
趋势社招
---
<a name="khuX0"></a>
# spark:运行模式
网易
---
<a name="qisDh"></a>
# Flink:Exactly Once语义怎么保证
头条x3,一点咨询,字节,微众,陌陌,触宝,网易,贝壳
---
1)Flink怎么保证精准一次消费?<br />2)Flink如何实现Exac tly Once? <br />3)Flink如何保证仅一次语义? <br />4)Flink的端到端Exac tly Once?
---
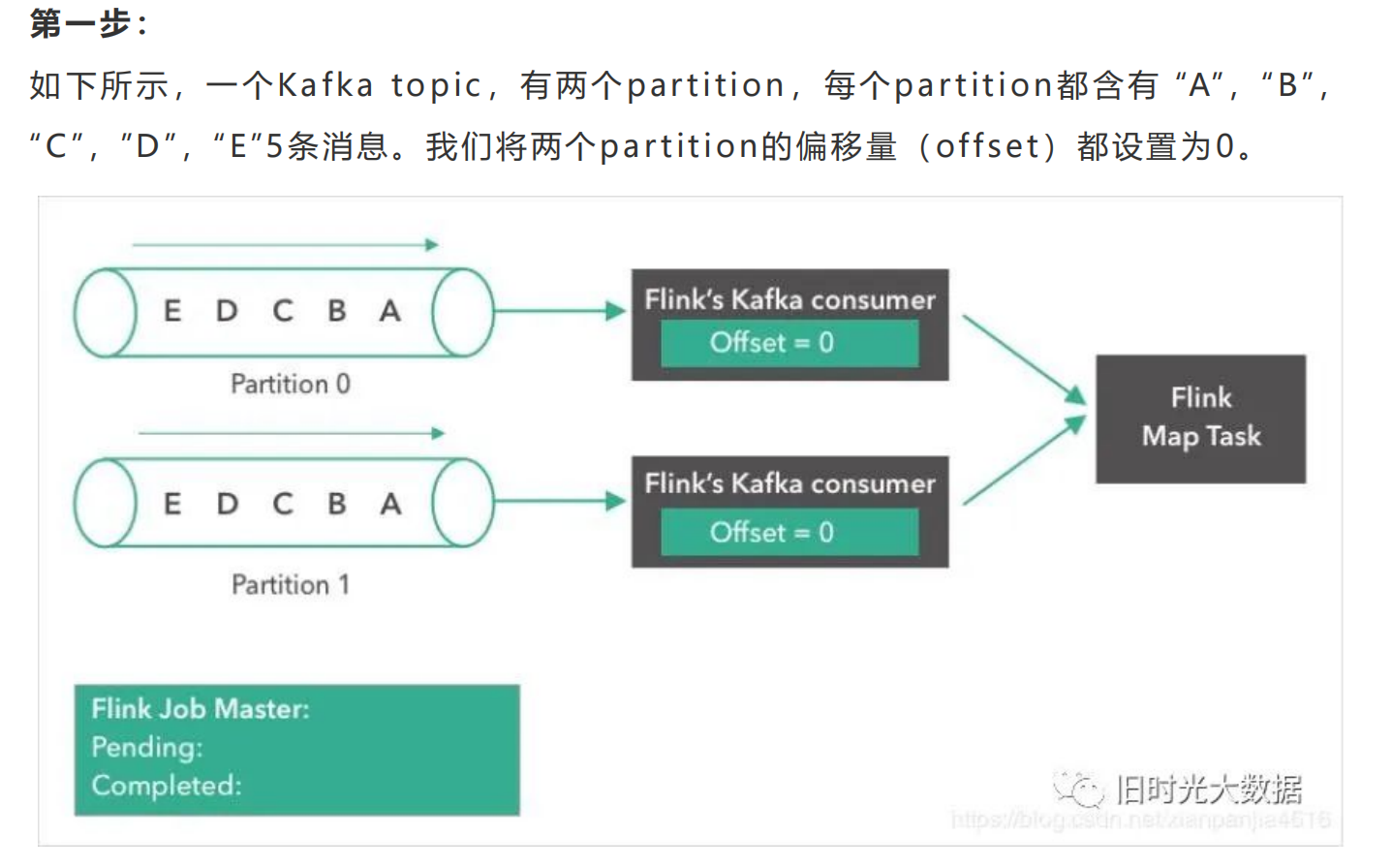
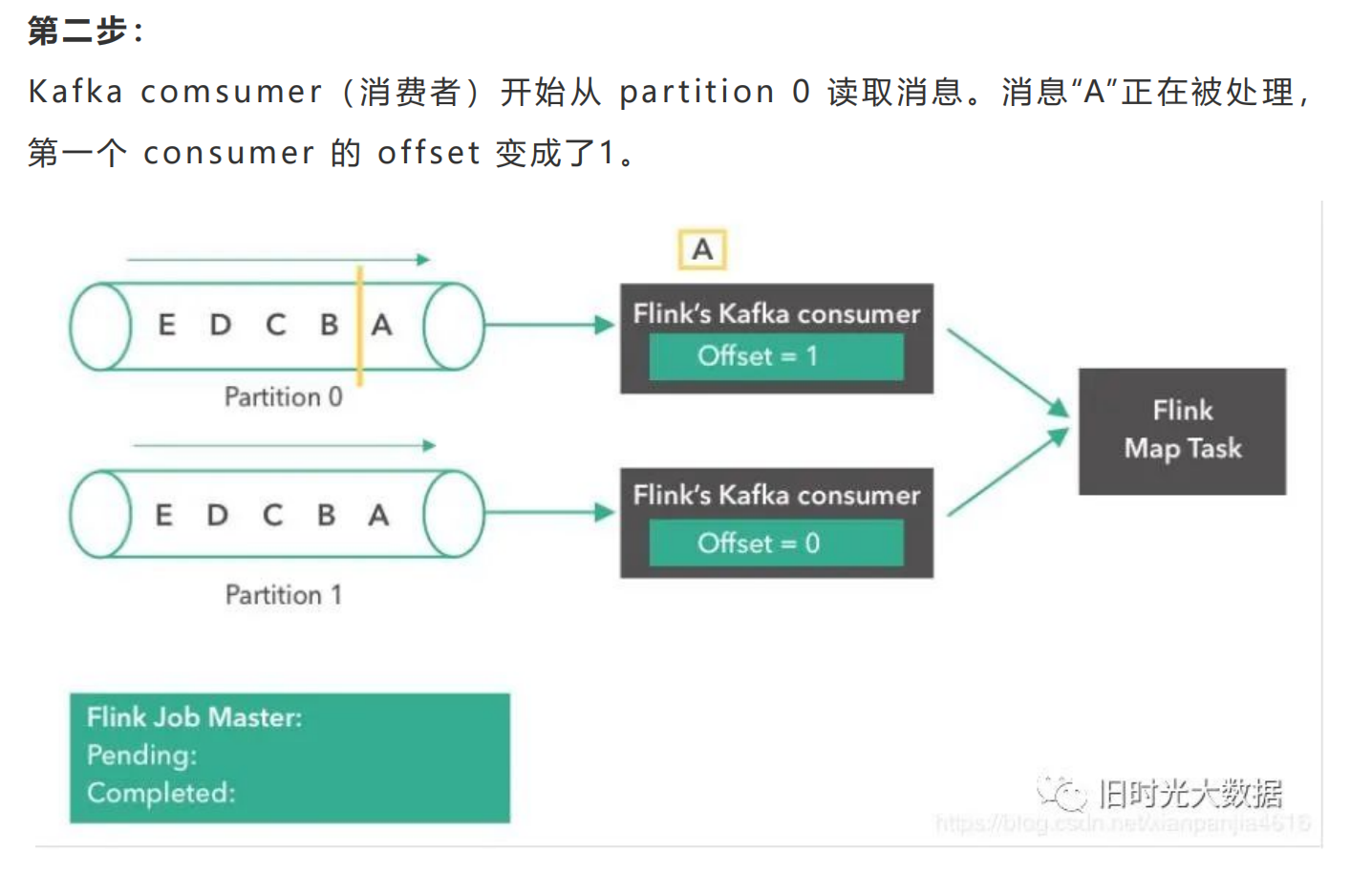
Flink跟其他的流计算引擎相比,最突出或者做的最好的就是状态的管理。什么是状态 <br />呢?比如我们在平时的开发中,需要对数据进行count,sum,max等操作,这些中 <br />间的结果(即是状态)是需要保存的,因为要不断的更新,这些值或者变量就可以理解为 <br />是一种状态,拿读取kafka为例,我们需要记录数据读取的位置(即是偏移量),并保存 <br />offes t,这时offes t也可以理解为是一种状态。 <br />Flink 是 怎 么 保 证 容 错 恢 复 的 时 候 保 证 数 据 没 有 丢 失 也 没 有 数 据 的 冗 余 呢 ? <br />checkpoint是使Flink 能从故障恢复的一种内部机制。检查点是 Flink 应用状态的一 <br />个一致性副本,包括了输入的读取位点。在发生故障时,Flink 通过从检查点加载应用 <br />程 序 状 态 来 恢 复 , 并 从 恢 复 的 读 取 位 点 继 续 处 理 , 就 好 像 什 么 事 情 都 没 发 生 一 样 。 <br />Flink的状态存储在Flink的内部,这样做的好处就是不再依赖外部系统,降低了对外 <br />部 系 统 的 依 赖 。 在 Flink 的 内 部 。 通 过 自 身 的 进 程 去 访 问 状 态 变 量 。 同 时 会 定 期 的 做 <br />checkpoint持久化。把checkpoint存储在一个分布式的持久化系统中。如果发生故 <br />障。就会从最近的一次checkpoint中将整个流的状态进行恢复。 <br />下面通过Flink从Kafka中获取数据,来说下怎么管理offes t实现exac tly-once的。 <br />Apache Flink中实现的Kafka消费者是一个有状态的算子(operator),它集成了 <br />Flink的检查点机制,它的状态是所有Kafka分区的读取偏移量。当一个检查点被触发 <br />时 , 每 一 个 分 区 的 偏 移 量 都 被 存 到 了 这 个 检 查 点 中 。 Flink 的 检 查 点 机 制 保 证 了 所 有 <br />operator task的存储状态都是一致的。这里的“一致的”是什么意思呢?意思是它们存 <br />储 的 状 态 都 是 基 于 相 同 的 输 入 数 据 。 当 所 有 的 operator task 成 功 存 储 了 它 们 的 状 <br />态 , 一 个 检 查 点 才 算 完 成 。 因 此 , 当 从 潜 在 的 系 统 故 障 中 恢 复 时 , 系 统 提 供 了 <br />excatly-once的状态更新语义。 <br />下面我们将一步步地介绍Apache Flink中的 Kafka消费位点是如何做检查点的。在本 <br />文的例子中,数据被存在了Flink的JobMas ter中。值得注意的是,在POC或生产用 <br />例下,这些数据最好是能存到一个外部文件系统(如HDFS或S3)中。
<a name="vUSho"></a>
### 
<br />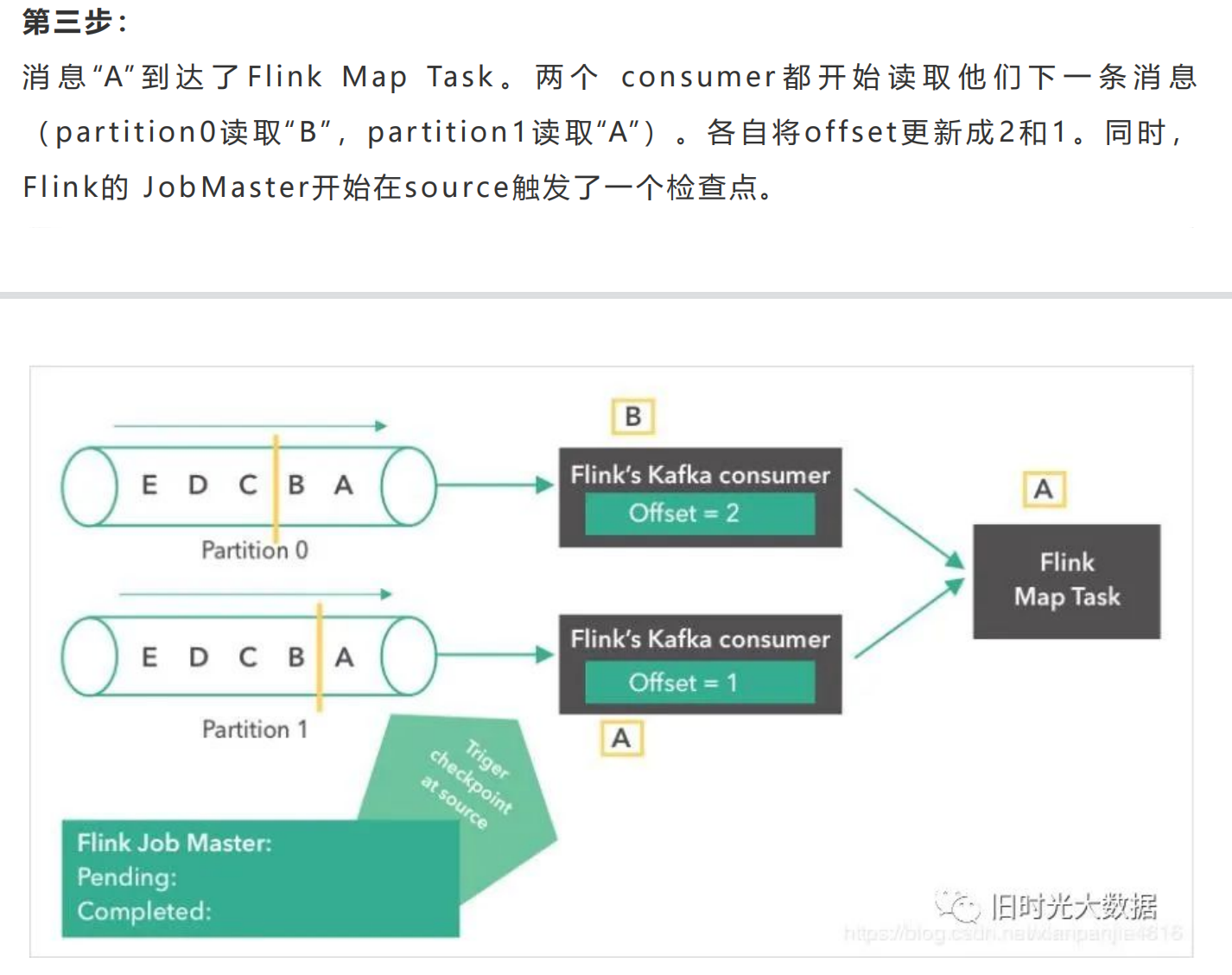<br />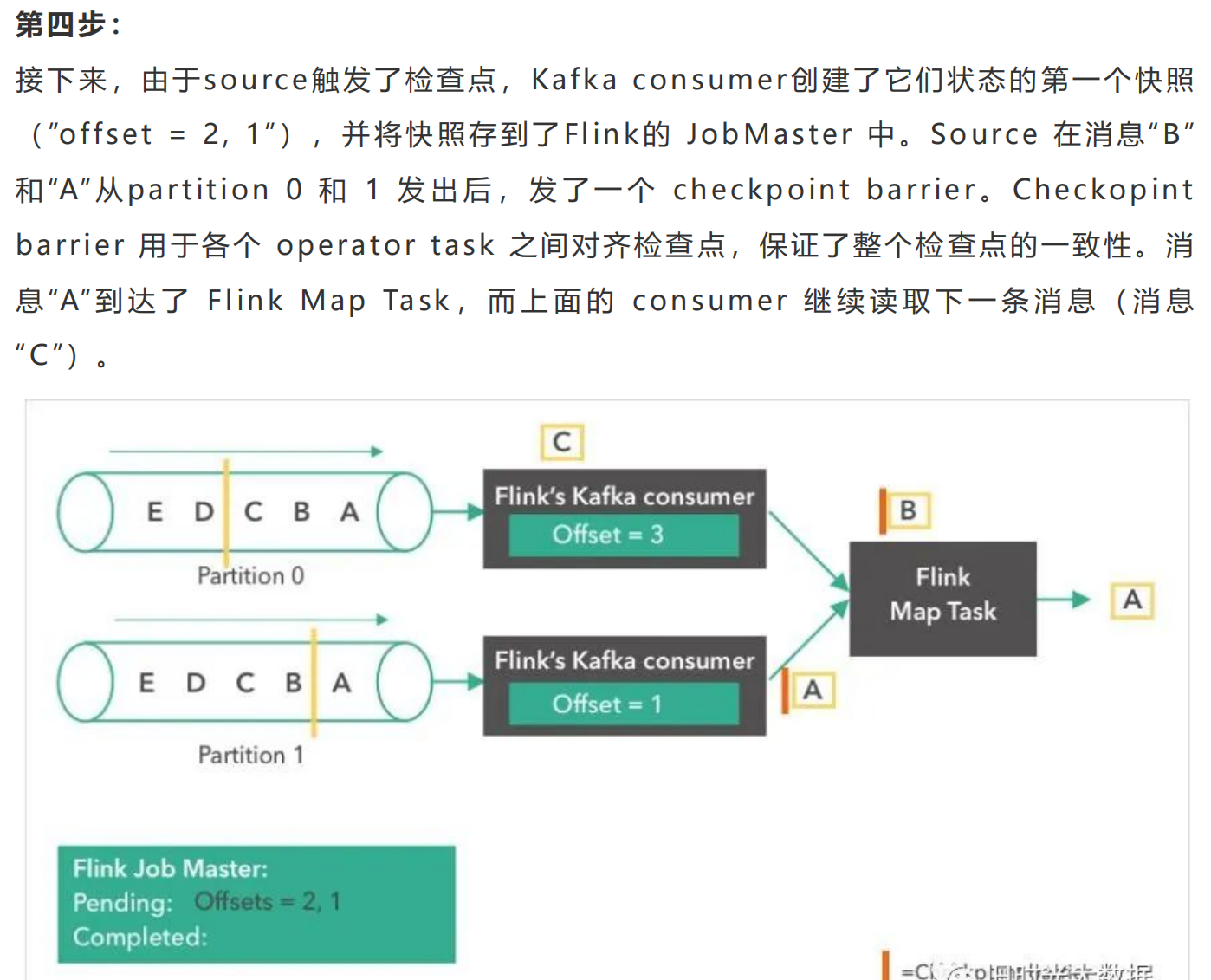<br />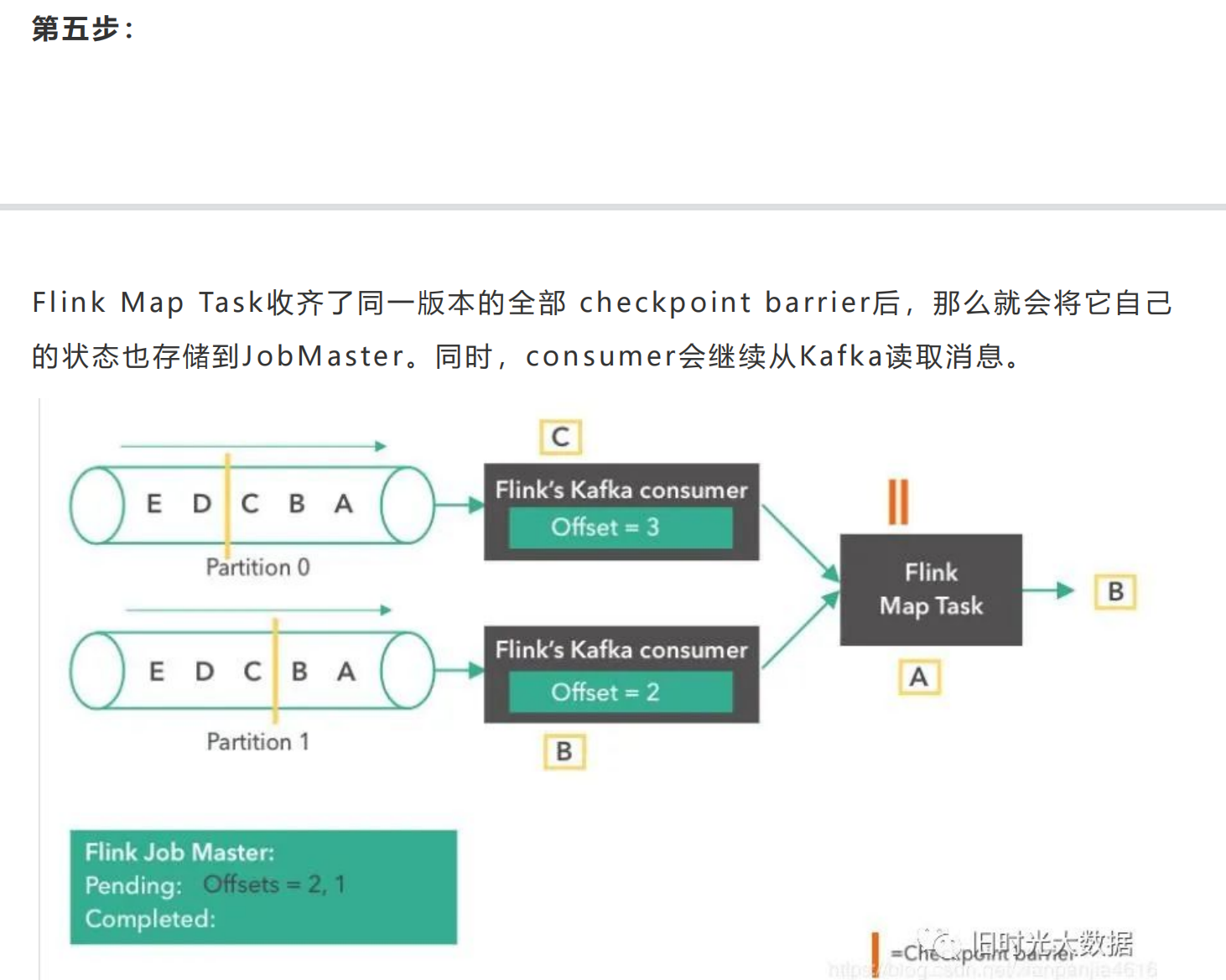<br />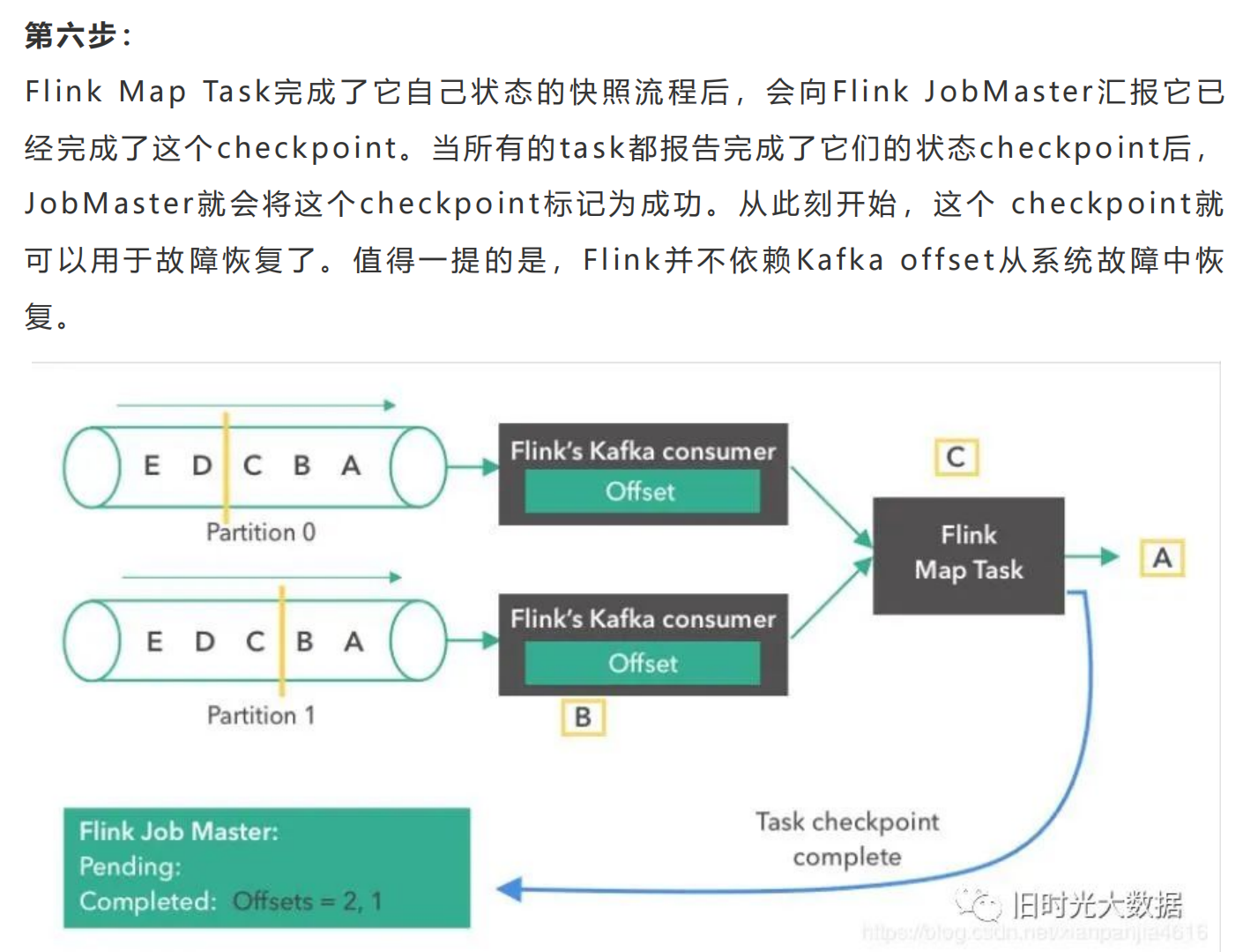<br />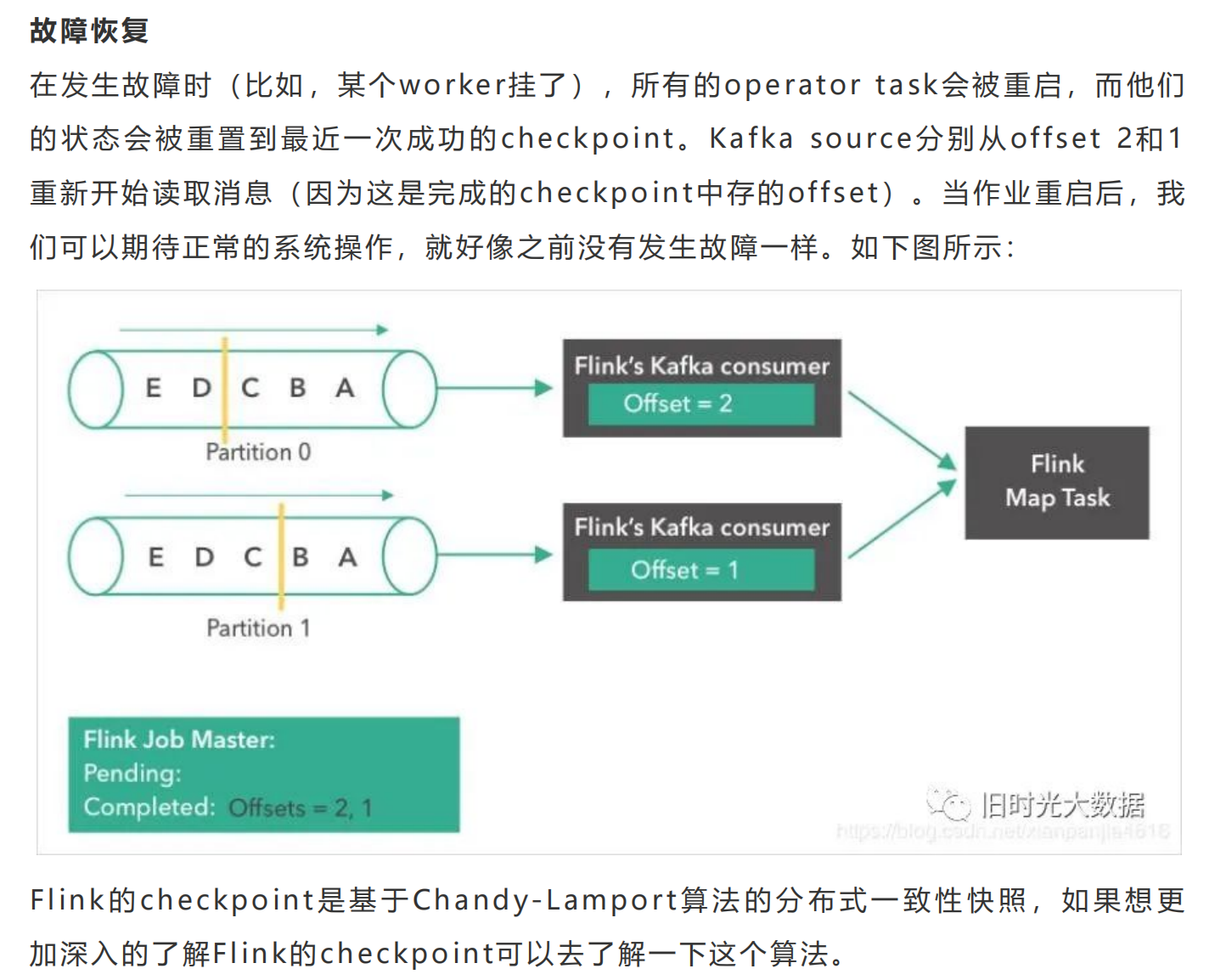
<a name="RDlr3"></a>
# flink和Spark区别
<a name="ocpKG"></a>
# 数据仓库建模
字 节 , 阿 里 x2 , 爱 奇 艺 , 百 度 x2 , 网 易 x3 , 美 团 x5 , 贝 壳 , keep , 马 蜂 窝 x2 , 转 <br />转,滴滴,小米,米哈游,有赞x2,猿辅导,58x2,作业帮社招,字节社招,腾讯社 <br />招x2,京东,触宝,趋势社招
---
数据仓库分层(层级划分),每层做什么
---
[https://www.cnblogs.com/shengyang17/p/10545198.html](https://www.cnblogs.com/shengyang17/p/10545198.html)<br />[https://www.yuque.com/theta/lvh6s6/pzpvdl#Txqag](https://www.yuque.com/theta/lvh6s6/pzpvdl#Txqag)<br /><br />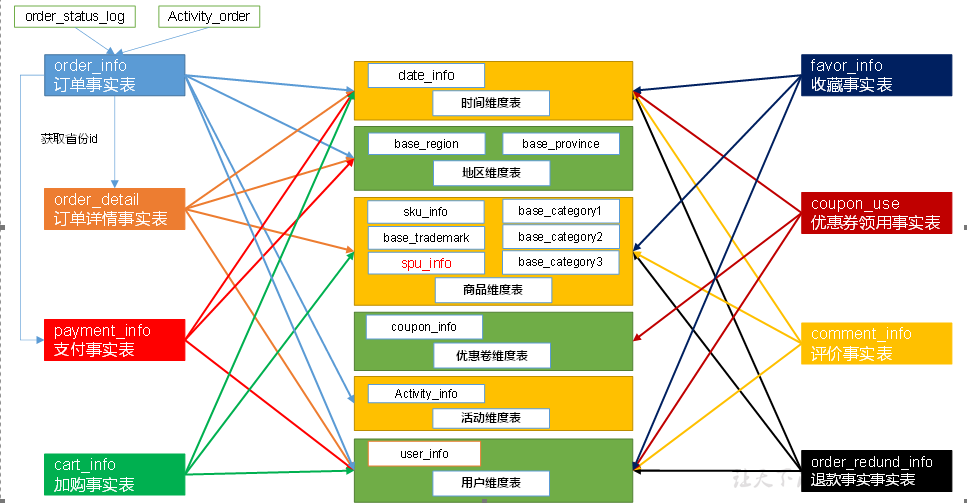<br />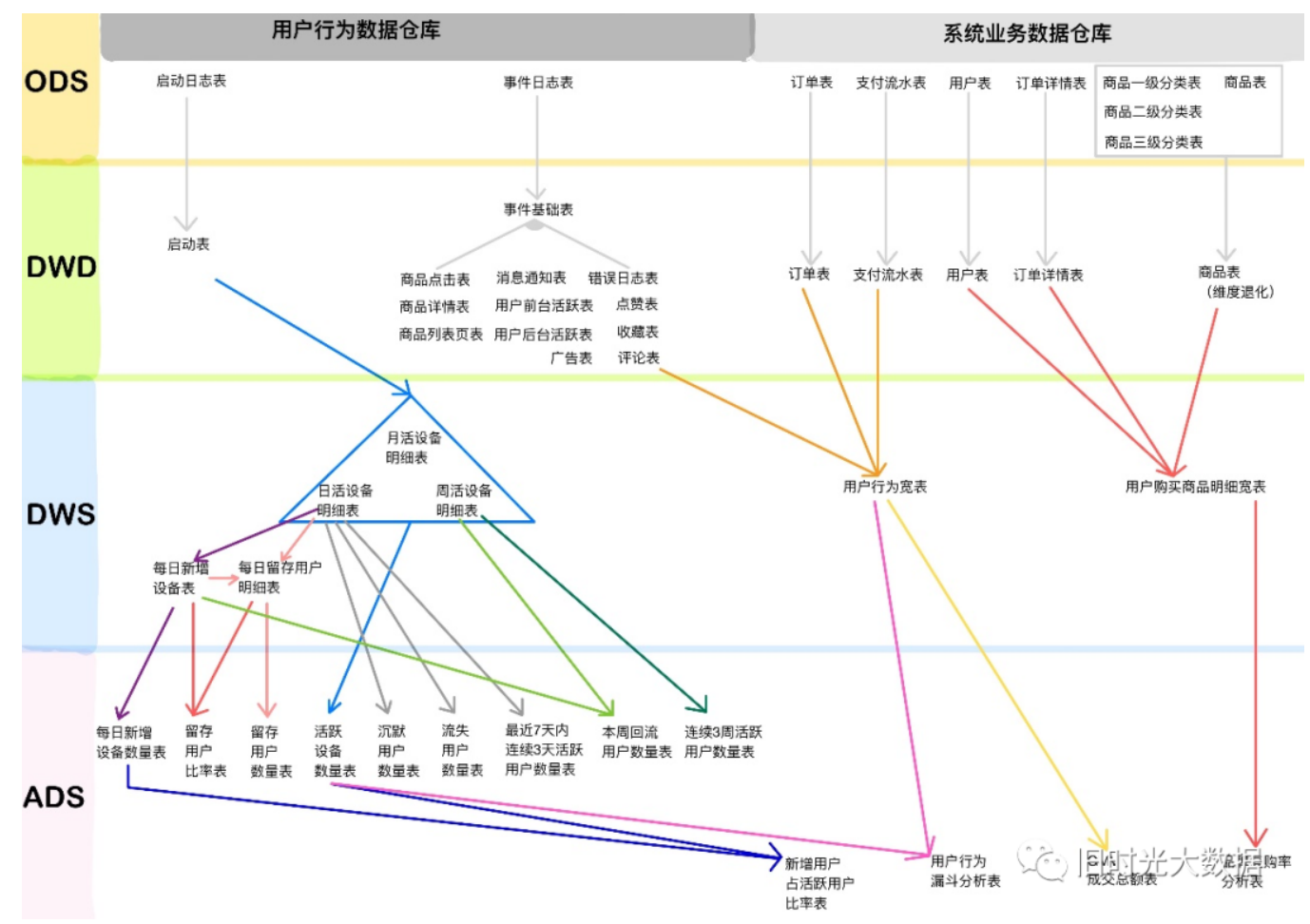<br />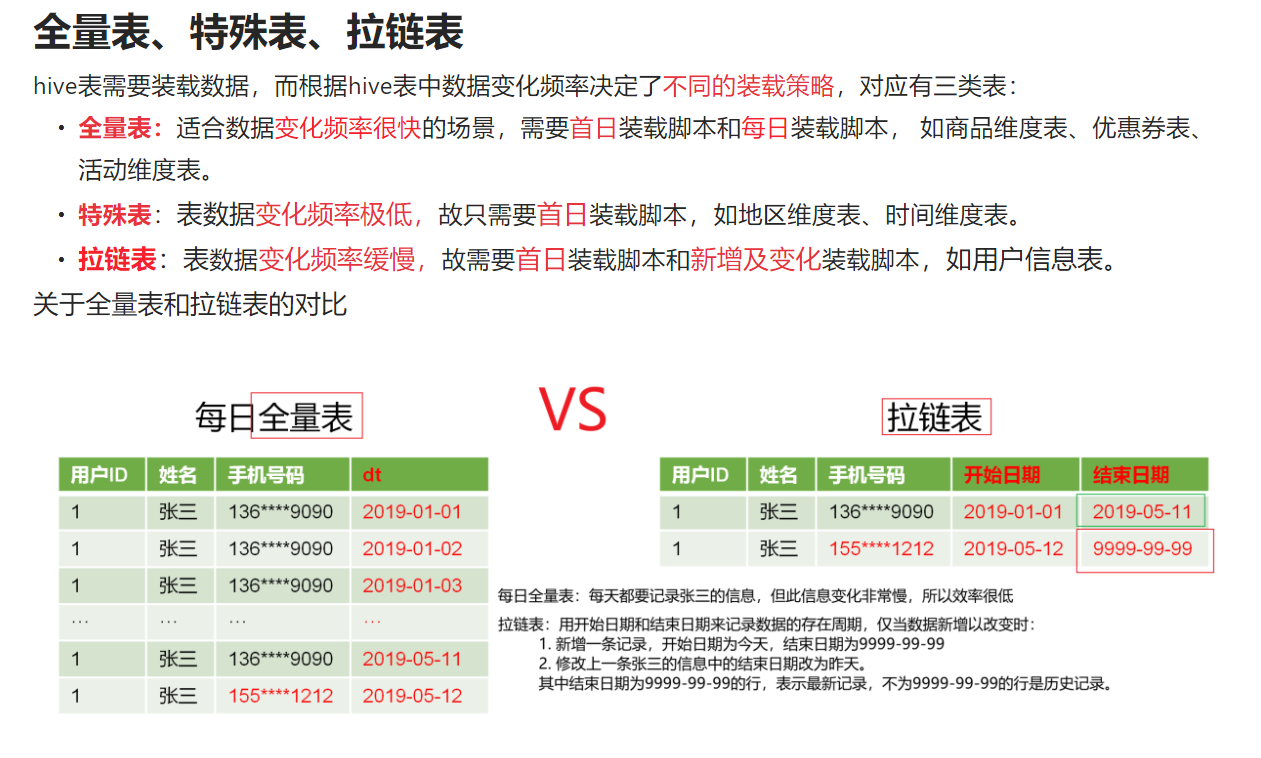
```sql
DROP TABLE IF EXISTS dim_user_info;
CREATE EXTERNAL TABLE dim_user_info(
`id` STRING COMMENT '用户id',
`login_name` STRING COMMENT '用户名称',
`nick_name` STRING COMMENT '用户昵称',
`name` STRING COMMENT '用户姓名',
`phone_num` STRING COMMENT '手机号码',
`email` STRING COMMENT '邮箱',
`user_level` STRING COMMENT '用户等级',
`birthday` STRING COMMENT '生日',
`gender` STRING COMMENT '性别',
`create_time` STRING COMMENT '创建时间',
`operate_time` STRING COMMENT '操作时间',
`start_date` STRING COMMENT '开始日期',
`end_date` STRING COMMENT '结束日期'
) COMMENT '用户表'
PARTITIONED BY (`dt` STRING)
STORED AS PARQUET
LOCATION '/warehouse/gmall/dim/dim_user_info/'
TBLPROPERTIES ("parquet.compression"="lzo");
#!/bin/bash
APP=gmall
# 如果是输入的日期按照取输入日期;如果没输入日期取当前时间的前一天
if [ -n "$2" ] ;then
do_date=$2
else
do_date=`date -d "-1 day" +%F`
fi
dim_user_info="
set hive.exec.dynamic.partition.mode=nonstrict;
set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
with
tmp as
(
select
old.id old_id,
old.login_name old_login_name,
old.nick_name old_nick_name,
new.start_date new_start_date,
new.end_date new_end_date
from
(
select
id,
login_name,
nick_name,
start_date,
end_date
from ${APP}.dim_user_info
where dt='9999-99-99'
and start_date<'$do_date'
)old
full outer join
(
select
id,
login_name,
nick_name,
'$do_date' start_date,
'9999-99-99' end_date
from ${APP}.ods_user_info
where dt='$do_date'
)new
on old.id=new.id
)
insert overwrite table ${APP}.dim_user_info partition(dt)
select
nvl(new_id,old_id),
nvl(new_login_name,old_login_name),
nvl(new_nick_name,old_nick_name),
nvl(new_start_date,old_start_date),
nvl(new_end_date,old_end_date),
nvl(new_end_date,old_end_date) dt
from tmp
union all
select
old_id,
old_login_name,
old_nick_name,
old_start_date,
cast(date_add('$do_date',-1) as string),
cast(date_add('$do_date',-1) as string) dt
from tmp
where new_id is not null and old_id is not null;
"
case $1 in
"dim_user_info"){
hive -e "$dim_user_info"
};;
"all"){
hive -e "$dim_user_info$dim_sku_info$dim_coupon_info$dim_activity_rule_info"
};;
esac
数据仓库场景,学生数据系统怎么搭?
思特奇
Scala实现wordcount
网易云,字节x2,第四范式
scala闭包
网易
Saprk St reaming和Flink的区别
字节x3,阿里x3,爱奇艺x2,嘉云,腾讯,快手,蘑菇街x2,360,中信信用卡,美
团社招,贝壳,安恒信息,海康,招银网络,触宝,竞技世界,趋势科技,网易,美团
1)Saprk和Flink的区别
2)Flink和Spark对于批处理的区别?
3)Spark Streaming相比Flink的优劣势
这个问题是一个非常宏观的问题,因为两个框架的不同点非常之多。但是在面试时有非
常 重 要 的 一 点 一 定 要 回 答 出 来 : Flink 是 标 准 的 实 时 处 理 引 擎 , 基 于 事 件 驱 动 。 而
Spark Streaming是微批(Mic ro-Batch)的模型。
下面我们就分几个方面介绍两个框架的主要区别:
1)从流处理的角度来讲,Spark基于微批量处理,把流数据看成是一个个小的批处理
数据块分别处理,所以延迟性只能做到秒级。而Flink基于每个事件处理,每当有新的
数 据 输 入 都 会 立 刻 处 理 , 是 真 正 的 流 式 计 算 , 支 持 毫 秒 级 计 算 。 由 于 相 同 的 原 因 ,
Spark只支持基于时间的窗口操作(处理时间或者事件时间),而Flink支持的窗口操
作 则 非 常 灵 活 , 不 仅 支 持 时 间 窗 口 , 还 支 持 基 于 数 据 本 身 的 窗 口 ( 另 外 还 支 持 基 于time、count、ses s ion,以及data-driven的窗口操作),开发者可以自由定义想要
的窗口操作。
2 ) 从 SQL 功 能 的 角 度 来 讲 , Spark 和 Flink 分 别 提 供 SparkSQL 和 Table APl 提 供
SQL
3)交互支持。两者相比较,Spark对SQL支持更好,相应的优化、扩展和性能更好,
而Flink在SQL支持方面还有很大提升空间。
4)从迭代计算的角度来讲,Spark对机器学习的支持很好,因为可以在内存中缓存中
间计算结果来加速机器学习算法的运行。但是大部分机器学习算法其实是一个有环的数
据流,在Spark中,却是用无环图来表示。而Flink支持在运行时间中的有环数据流,
从而可以更有效的对机器学习算法进行运算。
5 ) 从 相 应 的 生 态 系 统 角 度 来 讲 , Spark 的 社 区 无 疑 更 加 活 跃 。 Spark 可 以 说 有 着
Apache旗下最多的开源贡献者,而且有很多不同的库来用在不同场景。而Flink由于
较 新 , 现 阶 段 的 开 源 社 区 不 如 Spark 活 跃 , 各 种 库 的 功 能 也 不 如 Spark 全 面 。 但 是
Flink还在不断发展,各种功能也在逐渐完善。
Java : 集合的继承关系,array、set、map
网易,华为

Java: ArrayList和linklist的底层实现原理
网易,
Java:JVM 内存模型
网易
Java: Spring MVC运行流程
java : JVM GC原理
GC是垃圾收集的意思(Gabage Collection),内存处理是编程人员容易出现问题的地方,忘记或者错误的内存回收会导致程序或系统的不稳定甚至崩溃,Java提供的GC功能可以自动监测对象是否超过作用域从而达到自动回收内存的目的,Java语言没有提供释放已分配内存的显示操作方法。
垃圾回收可以有效的防止内存泄露,有效的使用可以使用的内存。
当程序员创建对象时,GC就开始监控这个对象的地址、大小以及使用情况。通常,GC采用有向图的方式记录和管理堆(heap)中的所有对象。通过这种方式确定哪些对象是”可达的”,哪些对象是”不可达的”。当GC确定一些对象为”不可达”时,GC就有责任回收这些内存空间。可以。程序员可以手动执行System.gc(),通知GC运行,但是Java语言规范并不保证GC一定会执行
Java: G1垃圾回收器的原理
字节社招
Java: JVM 复制算法和标记清除算法、标记整理算法
JVM中复制算法和标记清除算法、标记整理算法的区别,你分析下为什么复制算法不能用到老年
代,有啥问题等
字节社招
Java:object类有哪些方法?
哔哩哔哩
clone 对象浅复制,需要实现Cloneable接口
getClass final修饰,获取对象的运行时对象的类。
toString
finalize 释放资源。一般垃圾回收器(GC)调用此方法;
当对象变成(GC Roots)不可达时,GC会判断该对象是否覆盖了finalize方法,若未覆盖,则直接将其回收。否则,若对象未执行过finalize方法,将其放入F-Queue队列,由一低优先级线程执行该队列中对象的finalize方法。执行finalize方法完毕后,GC会再次判断该对象是否可达,若不可达,则进行回收,否则,对象“复活”。
equals 对象比较,子类一般需要重写
hashCode 获取对象的 hash 值
- wait-notify机制只能在synchronized锁范围内里使用。
wait 使调用该方法的线程释放共享资源锁,然后从运行状态退出,进入等待队列,直到被再次唤醒。
wait(long timeout)
notify() 随机唤醒等待队列中等待同一共享资源的一个线程,并使该线程退出等待队列,进入可运行状态,也就是notify()方法仅通知一个线程。
notifyAll() 
Java : 为什么要重写 equals 和 hashcode()方法
哔哩哔哩
默认的equals 比较的是两个对象的引用;而hashcode也是根据对象地址生成一个整数数值;
而我们更关心的是与业务相关的比较和hashcode,比如字符串的值,而不是字符串的地址。
Java : 封装、继承、多态、抽象
华为
Java: synchronize和volatile锁的区别
网易,其他
Java: 多线程的实现 Thread、Runable、Callable (写出来)
华为,趋势社招,网易
Java: 双亲委派机制( 类加载机制)
如果打破双亲委派机制,加载了不同系统同名的类会出现什么问题
https://blog.csdn.net/weixin_46141936/article/details/120953564
类加载器:
- 启动类加载器 加载JAVA_HOME/lib下的核心类
- 扩展类加载器 加载JAVA_HOME/lib/ext下的扩展类
- 系统类加载器 加载classpath下 我们自己编写的类
- 自定义加载器 用户自定义路径
双亲委派机制:
加载一个类的过程:
系统类加载器遇到一个class, 先看看扩展类加载器里有没有这个同全类名的class
如果父类有,便让父类加载器去加载;如果没有,便继续上抛,直至抛到启动类加载器为止
如果启动类也没有,那就下抛,直至能加载为止
注意: 类加载器间的上下级关系, 和它们各自能加载哪些类
优点:
保证了jdk类库的安全问题,自带的类不会被用户自己编写的同名类进行覆盖,而且促使核心类优先加载
缺点:
1、父类级加载器想要加载一些class,而这个class所处位置只有子类加载器才能加载
这个问题出现在JDBC中, 启动类加载器加载了JDK自带的DriverManager后, DriverManager用到了MySQL厂商的Driver实现。JVM规定某一类加载器加载A类时发现A用到了B,那么它就得先去加载B。所以启动类加载器就也想加载MySQLDriver, 但这个MySQLDriver实现类不在JAVA_HOME/lib下。所以要打破双亲委派,让父类加载器去使用子类加载器加载原本父类够不到的class文件
2、同一个类加载器, (不管是不是同一个类加载器实例) 都只能加载一个全类名相同的class, 不能区分版本
这个问题出现在Tomcat中, Tomcat自定义如上图的多个有上下级关系的自定义加载器。Tomcat可以运行多个webapp, 而它们可能需要使用不同版本的jar(class); 当第一个webapp要用WebAppClassLoader想加载jar-version1.0后, 抛给了父类的CommonClassLoader去加载, 于是它加载了jar-version1.0;那么等到第一个webapp要用WebAppClassLoader想加载jar-version2.0时, 直接去CommonClassLoader中去取了, 直接得到了jar-version1.0, 而jar-version2.0就不会再被加载。所以要打破双亲委派,让其不向上抛掷

什么时候需要打破双亲委派机制?
即面临上述的缺点的时候:
父类加载器想要使用子类加载器加载原本父类够不到的class文件时
想要同时加载同一个class的不同版本时
如何打破双亲委派机制?
使用当前线程上下文加载器(当前线程上下文加载器默认是应用类加载器) (JDBC用的是这种)
使用自定义类加载器, 重写loadclass方法, 不去父类中检查 (Tomcat用的是这种)
自定义类加载器也可以不打破双亲委派,主要是看你是否重写loadclass方法搞事情
什么时候需要自定义类加载器?
想加载不在classpath路径下的class文件
想要加载一个相同全类名但不同版本的class文件, 使之共存
热部署时, 只需要GC回收掉之前的老的类, 然后重新创建自定义类加载器实例进行加载这个新的class文件
Tomcat自定义类加载的好处:
实现了父类Common加载器加载的class, 子类加载器就不用重复加载了
可以同时使用不同版本的jar(重写loadclass打破双亲委派机制)
JSP类加载器对JSP的热部署
class MyClassLoader extends ClassLoader {
@Override
protected Class<?> findClass(String classFilePath) throws ClassNotFoundException {
ByteArrayOutputStream baos = new ByteArrayOutputStream( );
try {
Files.copy(Paths.get(classFilePath), baos);
byte[] bytes = baos.toByteArray( );
String className = classFilePath.split("/")[2].replace(".class", "");
return defineClass(className, bytes, 0, bytes.length);
} catch (IOException e) {
e.printStackTrace( );
throw new ClassNotFoundException("class文件找不到");
}
}
}
// 使用
MyClassLoader myClassLoader1 = new MyClassLoader( );
MyClassLoader myClassLoader2 = new MyClassLoader( );
Class<?> userClzVersion1 = myClassLoader1.loadClass("C:/version1/com.hellosrc.User.class");
Class<?> userClzVersion2 = myClassLoader2.loadClass("C:/version1/com.hellosrc.User.class");
// 不打破双亲委派机制
// 虽然打印结果为false, 但实际上User类只被加载了一次,
// 因为myClassLoader1和myClassLoader2 本质都是用共同的父类加载器(即系统类加载器)去加载
System.out.println(userClzVersion1 == userClzVersion2);
// 触发静态代码块, 发现只被执行了一次, 再次印证了不打破双亲委派机制时, 不能把一个全类名相同的类重复加载
Object userVersion2 = userClzVersion1.newInstance( );
Object userVersion1 = userClzVersion1.newInstance( );
Java: 线程池
Java: 共享内存如何实现互斥
趋势社招
Java: hashMap,TreeMap、hashTable(线程安全问题)
趋势社招,网易
Java: hashmap和concurenthashmap的区别和细节
字节社招
Sql: 姓名、分数,按分数排名如何实现
趋势社招
Mysql: 引擎介绍
网易
Mysql: 索引失效
趋势社招
Mysql: 慢查询如何开启关闭
趋势社招
Mysql: 主从读写怎么实现
趋势社招
Mysql: 如何看sql用到了索引,以及里面都是啥
趋势社招
算法题:归并排序
哔哩哔哩
O(nlogn)
算法题:递归算法的缺点?
哔哩哔哩
递归 由于是函数调用自身。
优点:代码简洁、清晰,并且容易验证正确性。
缺点:函数调用是有时间和空间的消耗的:每一次函数调用,都需要在内存栈中分配空间以保存参数、返回地址以及临时变量,而往栈中压入数据和弹出数据都需要时间。这样效率会比较低。
算法题:LRU
不能使用LinkedHashMap,要自己实现底层结构。
字节社招
算法题:凑零钱和最大正方形面积(leetcode有)
字节社招
数据结构: 二叉树、二叉搜索树、二叉平衡树、红黑树
华为
数据结构: 数组和链表的适用场景,为什么?
华为

若有收获,就点个赞吧
0 人点赞
