环境背景
测试集群服务器规划
HDFS-NameNode、Yarn-Resourcemanager分散不同服务器上,其余默认(如Hive)装在hadoop102服务器上。
| 服务名称 | 子服务 | 服务器 hadoop102 |
服务器 hadoop103 |
服务器 hadoop104 |
|---|---|---|---|---|
| HDFS | NameNode | √ | ||
| DataNode | √ | √ | √ | |
| SecondaryNameNode | √ | |||
| Yarn | NodeManager | √ | √ | √ |
| Resourcemanager | √ | |||
| Zookeeper | Zookeeper Server | √ | √ | √ |
| Flume(采集日志) | Flume | √ | √ | |
| Kafka | Kafka | √ | √ | √ |
| Flume(消费Kafka) | Flume | √ | ||
| Hive | Hive | √ | ||
| MySQL | MySQL | √ | ||
| Sqoop | Sqoop | √ | ||
| Presto | Coordinator | √ | ||
| Worker | √ | √ | ||
| Azkaban | AzkabanWebServer | √ | ||
| AzkabanExecutorServer | √ | |||
| Spark | √ | |||
| Kylin | √ | |||
| HBase | HMaster | √ | ||
| HRegionServer | √ | √ | √ | |
| Superset | √ | |||
| Atlas | √ | |||
| Solr | Jar | √ | ||
| 服务数总计 | 19 | 8 | 8 |
参考:尚硅谷大数据项目之尚品汇(3数据仓库系统)V4.2.0.docx
数仓分层

数据仓库 vs 数据集市
数据集市data Market是微型的数据仓库,数据规模更小,因此是部门级的,而数据仓库则是企业级的。
命名规范
表命名
- 层级表命名:分层名表名,比如dwd表名
-
脚本命名
用户行为脚本以log为后缀:数据源to目标_log.sh
-
表字段类型
数量类型为bigint
- 金额类型为decimal(16, 2),表示:16位有效数字,其中小数部分2位
- 字符串(名字,描述信息等)类型为string
- 主键外键类型为string
- 时间戳类型为bigint
数仓理论
维度建模VS关系建模
关系建模
严格遵循3NF范式,数据较为松散、零碎,物理表数量多。
范式就是数据建模所遵循的规则。
- 好处是降低数据冗余、解决数据一致性;
- 坏处是更多的join操作,查询相对复杂,因为遵循的范式式越严格,表就拆分得越细越多(关系模式分解、消除字段间的耦合)。
在关系数据库中的1NF、2NF、3NF等
- 1NF — 消除属性可拆分性,
- 2NF — 消除部分函数依赖,
- 3NF — 消除传递函数依赖,
1NF,比如 “5个篮球”不可作为一个字段属性,它应该拆为商品的属性和数量的属性。 2NF、3NF,不满足会导致插入异常、删除异常、修改复杂。 ?
维度建模
维度模型以数据分析作为出发点,不遵循三范式,故数据存在一定的冗余。维度模型面向业务,将业务用事实表和维度表呈现出来。表结构简单,故查询简单,查询效率较高。
- 事实表(SalesOrder):事实表中的每行数据代表一个业务事件(下单、支付、退款、评价等“动作”),每一个业务事件都包括:可加性的数值型的度量值(统计次数、个数、金额等)、与维度表相连接的外键。
- 维度表(Date 、Order等):维度表是对某个事实的描述信息,如每个“下单事实“都有“时间维度和订单维度”。
事实表:经常发生变化,每天会新增加很多。三种类型:
- 事务型:每个事务或事件为单位,事务被提交,事实表即插入一行,更新方式为增量更新)。
- 周期型快照:不会保留所有数据,只保留固定时间间隔的数据。如:购物车只需要关心每天结束时的状态,而不必跟踪变化。
- 累积型快照:累计快照事实表用于跟踪业务事实的变化。如:物流动态
维度表:内容相对固定(编码表),跟事实表相比,行数相对较小
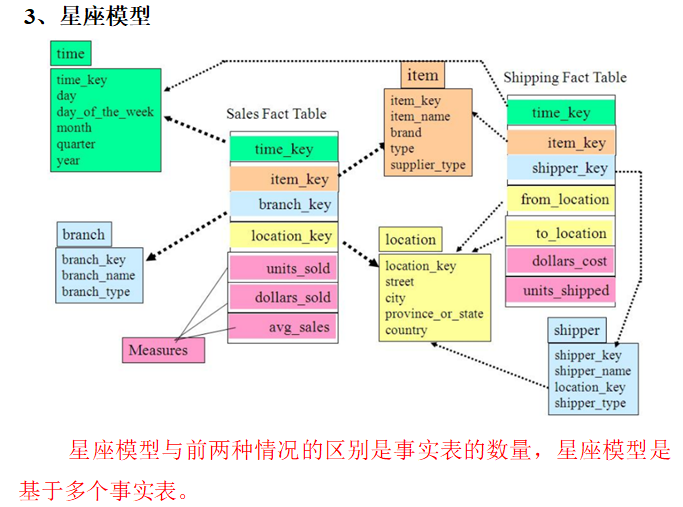
维度模型分类
辨别:星型和雪花有一个事实表,星座有多个事实表; 星型是一级维度,雪花是多级维度。
模型选择
- 多事实表:可以应对复杂业务;
- 多级维度表: 多级维度比一级维度更灵活,但是join操作更多,所以性能差一些。

建模(绝对重点)

ODS层
- HDFS用户行为数据
- HDFS业务数据
- 针对HDFS上的用户行为数据和业务数据,我们如何规划处理?
- 保持数据原貌不做任何修改,起到备份数据的作用。
- 数据采用LZO压缩,减少磁盘存储空间。100G数据可以压缩到10G以内。
- 创建分区表,防止后续的全表扫描,在企业开发中大量使用分区表。
- 创建外部表。在企业开发中,除了自己用的临时表,创建内部表外,绝大多数场景都是创建外部表。

DIM层
DIM层创建维度表,有商品、优惠卷、活动、地区、时间、用户等维度表。
DWD层
DWD层,一般采用星型模型,使用外键连接DIM层。
- DWD层创建明细表(也叫事实表),每个事实表的外键是维度表,且每个明细表至少一个度量值(比如订单表的一条记录的度量值就可以是最终金额)。
- 用户行为日志的明细表,如启动日志表、页面日志表、动作曝光表、错误日志表。
- 业务数据的明细表,如订单、支付、收藏等事实(业务)表。
下面是业务数据明细表的业务总线矩阵表。
| 时间 | 用户 | 地区 | 商品 | 优惠券 | 活动 | 度量值 | |
|---|---|---|---|---|---|---|---|
| 订单 | √ | √ | √ | 运费/优惠金额/原始金额/最终金额 | |||
| 订单详情 | √ | √ | √ | √ | √ | √ | 件数/优惠金额/原始金额/最终金额 |
| 支付 | √ | √ | √ | 支付金额 | |||
| 加购 | √ | √ | √ | 件数/金额 | |||
| 收藏 | √ | √ | √ | 次数 | |||
| 评价 | √ | √ | √ | 次数 | |||
| 退单 | √ | √ | √ | √ | 件数/金额 | ||
| 退款 | √ | √ | √ | √ | 件数/金额 | ||
| 优惠券领用 | √ | √ | √ | 次数 |
维度建模一般按照以下四个步骤:选择业务过程(构建xx事实表)→声明粒度(xx事实表中一行表示什么)→确认维度(xx事实表哪些维度外键)→确认事实(xx事实表的度量值是什么类型)
加购事实表如下:
| 加购 | √ | √ | √ | 件数/金额 | |||
|---|---|---|---|---|---|---|---|
DWS层与DWT层
DWS层按照主题去建表,即DWS层的每个表蕴含了xx主题的汇总行为。主题是xx维度,而字段是xx事实表的度量值,因为事实表有很多,所以dws有很多字段,所以也叫宽表。
| 订单度量值 | 支付度量值 | 收藏度量值 | 优惠卷领用度量值 | |
|---|---|---|---|---|
| 用户主题(表1) | √ | √ | √ | √ |
| 地区主题(表2) | √ | √ | √ | √ |
DWT层是基于DWS,对某个或某些事实表的度量值进行聚合,体现行为的聚合,比如累计下单次数。
ADS层
对电商系统各大主题指标分别进行分析
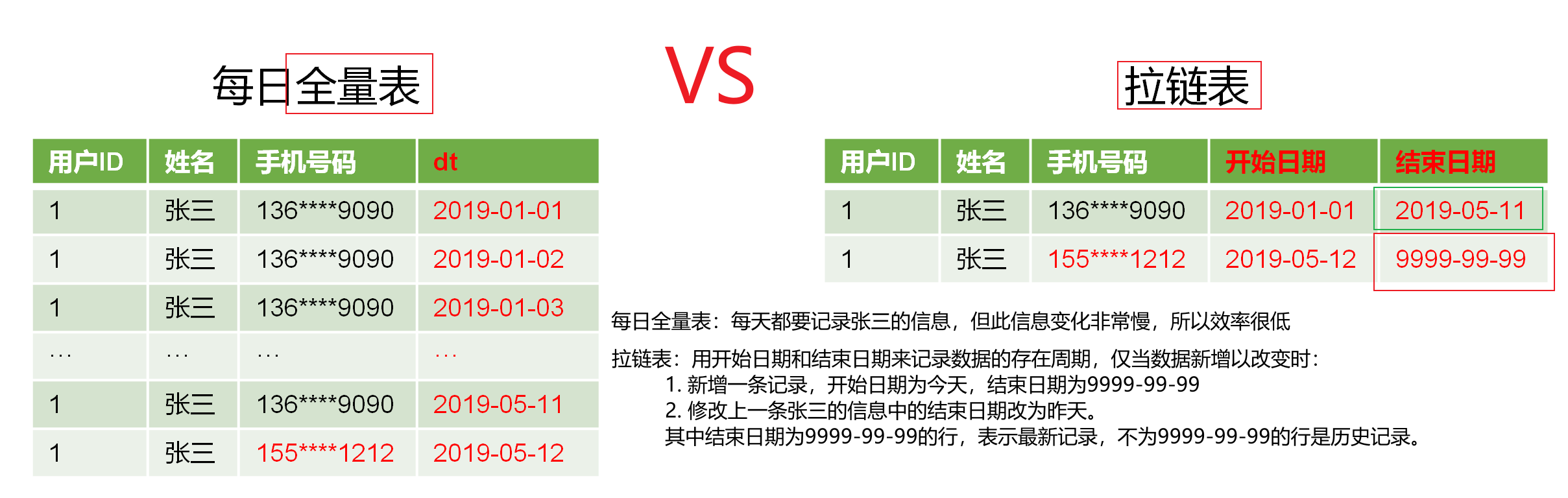
全量表、特殊表、拉链表
hive表需要装载数据,而根据hive表中数据变化频率决定了不同的装载策略,对应有三类表:
- 全量表:适合数据变化频率很快的场景,需要首日装载脚本和每日装载脚本, 如商品维度表、优惠券表、活动维度表。
- 特殊表:表数据变化频率极低,故只需要首日装载脚本,如地区维度表、时间维度表。
- 拉链表:表数据变化频率缓慢,故需要首日装载脚本和新增及变化装载脚本,如用户信息表。
数仓环境搭建与数据准备
hive配置
Hive的计算引擎有3种:
- 默认MR : 性能稍差,但是适合非常大规模,因为tez和spark计算引擎可能会Out Of Memery。
- tez : 适合测试
- spark : 能用则用
- hive on spark ,语法是HQL。Hive负责存储元数据、解析SQL、spark负责计算。
- spark on hive ,语法是spark SQL。Hive负责存储原始、spark负责解析SQL和计算。
- flink
建议:使用Hive的HQL,配合MR计算引擎,或者 hive、flink
如使用hive on spark,那么需要将spark部署在hive结点上(我的是hadoop102),并配置hive。
Yarn配置
- 修改hadoop-3.1.3/etc/hadoop/capacity-scheduler.xml文件
yarn.scheduler.capacity.maximum-am-resource-percent 由默认0.1 设置到0.8。
- 向集群分发这个xml文件
- 重启yarn服务
hadoop-3.1.3/sbin/stop-yarn.shhadoop-3.1.3/sbin/start-yarn.sh
补充1:
Application Master 中有 yarn.scheduler.capacity.maximum-am-resource-percent参数实现,其默认值是0.1,表示AM使用一个队列总资源的上限比例。默认设置为0.1是防止在生产环境下AM占用太高,导致Map/Reduce Task资源不够。学习环境下,集群资源本来就少,设置为0.1可能导致并发的job太少。
补充2:
- ResourceManager负责所有资源的监控、分配和管理,一个集群只有一个;
- NodeManager负责每一个节点的维护,一个集群有多个。
- Application Master负责每一个具体应用程序的调度和协调,一个集群有多个;
对于所有的applications,RM拥有绝对的控制权和对资源的分配权。而每个AM则会和RM协商资源,同时和NodeManager通信来执行和监控task。
数仓开发工具(DataGrip)
数仓开发工具选择DataGrip,它需要JDBC协议连接到Hive,故需要启动HiveServer2。
补充: HiveServer2(HS2)是一种能使客户端执行Hive查询的服务,为开放API客户端(如JDBC和ODBC)提供更好的支持。
- 启动HiverServer2
在hive结点上(我是hadoop102),hive/bin/hiveserver2
补充: nohup hive/bin/hiveserver2 > s2.log 2>&1 & ps -aux| grep hiveserver2 netstat -tunlp | grep 10000
- 配置DataGrip连接
创建hive连接:
配置连接属性
测试使用
创建名为gmall的数据库
修改连接配置
选择当前数据库为gmall
数据准备
用户行为日志
一般没有历史数据,日志只需要准备2020-06-14一天的数据。
启动日志采集服务,flume、kafak等。
修改日志服务器(我是hadoop102和hadoop103)。 /opt/module/applog/application.yml配置文件,将mock.date参数改为2020-06-14。
执行日志生成脚本lg.sh

业务数据
业务数据一般存在历史数据,此处需准备2020-06-10至2020-06-14的数据。
思路:生成模拟的历史数据到mysql中,最后全部将mysql数据导入到hdfs。
- 下面模拟生成2020-06-10(首日)的业务数据:
修改hadoop102节点的/opt/module/db_log/application.properties文件

模拟生成业务数据 java -jar /opt/module/db_log/gmall2020-mock-db-2021-01-22.jar
- 下面模拟生成2020-06-11的业务数据:
修改hadoop102节点的/opt/module/db_log/application.properties文件

模拟生成业务数据 java -jar /opt/module/db_log/gmall2020-mock-db-2021-01-22.jar
- 类似2020-06-11的操作,修改日期部分。生成2020-06-11,2020-06-13,2020-06-14的业务数据。
- 执行mysql_to_hdfs_init.sh脚本,将模拟生成的业务数据同步到HDFS
不需要历史日志,只导入当日日志,且导入所有表。 执行:
mysql_to_hdfs_init.sh all 2020-06-14
常用代码
MySQL —> HDFS
使用案例:
xx.sh order_info 2020-06-14 第一个参数是表名,第二个参数是分区名
import_data(){…}函数说明:
该函数使用sqoop通过jdbc来连接mysql中,将mysql指定的库/表/分区的数据,按照定义好的字段格式,导入到hdfs中库名/表名/分区目录下。在导入完毕后,调用hadoop-lzo.jar将导入的数据就地压缩为lzo文件。分区即为日期,它作为参数传入。
if [ -n "$2" ] ;thendo_date=$2elseecho "请传入日期参数"exitfi
#! /bin/bashAPP=gmallsqoop=/opt/module/sqoop/bin/sqoopif [ -n "$2" ] ;thendo_date=$2elsedo_date=`date -d '-1 day' +%F`fiimport_data(){$sqoop import \--connect jdbc:mysql://hadoop102:3306/$APP \--username root \--password 000000 \--target-dir /origin_data/$APP/db/$1/$do_date \--delete-target-dir \--query "$2 where \$CONDITIONS" \--num-mappers 1 \--fields-terminated-by '\t' \--compress \--compression-codec lzop \--null-string '\\N' \--null-non-string '\\N'hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/common/hadoop-lzo-0.4.20.jar com.hadoop.compression.lzo.DistributedLzoIndexer /origin_data/$APP/db/$1/$do_date}import_order_info(){import_data order_info "selectid,total_amount,order_status,user_id,payment_way,delivery_address,out_trade_no,create_time,operate_time,expire_time,tracking_no,province_id,activity_reduce_amount,coupon_reduce_amount,original_total_amount,feight_fee,feight_fee_reducefrom order_info"}// 省略中间代码case $1 in"order_info")import_order_info// 省略中间代码;;"all")import_base_category1import_base_category2// 省略中间代码;;esac
注意: mysql导入数据到hdfs,数据只是被放在按照“库名/表名/分区名”所规划的hdfs目录下而已,而并非导入到hive表中,只有后续hive去建立表,且向表执行hive -e “load date inpath….”等导入指令时,它们才能真正被hive用起来。
HDFS出现相应文件。
总的来说
模拟的数据保存到mysql,再通过sqoop导入到hdfs中。
HDFS -> ODS
hdfs_to_ods_log.sh 2020-06-14
- $APP=gmall <——库名
- do_date=$1 <——分区。
hive -e "load data 命令"将hdfs中对应目录下的数据导入到hive的库/表/分区下hadoop-lzo.jar由于导入的数据是lzo压缩,所以去建立lzo索引 ```shell!/bin/bash
定义变量方便修改
APP=gmall
如果是输入的日期按照取输入日期;如果没输入日期取当前时间的前一天
if [ -n “$1” ] ;then
do_date=$1
else
do_date=date -d "-1 day" +%F
fi
echo ================== 日志日期为 $do_date ================== sql=” load data inpath ‘/origin_data/$APP/log/topic_log/$do_date’ into table ${APP}.ods_log partition(dt=’$do_date’); “
hive -e “$sql”
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/common/hadoop-lzo-0.4.20.jar com.hadoop.compression.lzo.DistributedLzoIndexer /warehouse/$APP/ods/ods_log/dt=$do_date
<a name="KmmIp"></a>## 建表(非拉链表)```sqlDROP TABLE IF EXISTS dim_sku_info;CREATE EXTERNAL TABLE dim_sku_info (`id` STRING COMMENT '商品id',`price` DECIMAL(16,2) COMMENT '商品价格',`sku_name` STRING COMMENT '商品名称',-- ARRAY<STRUCT... 结构体数组格式`sku_attr_values` ARRAY<STRUCT<attr_id:STRING,value_id:STRING,attr_name:STRING,value_name:STRING>> COMMENT '平台属性',`create_time` STRING COMMENT '创建时间') COMMENT '商品维度表'-- 按照dt分区PARTITIONED BY (`dt` STRING)-- hive表存储为parquet格式,它采用列式存储。列式存储查询效率更高,更容易被压缩。STORED AS PARQUET-- Location一般与外部表(EXTERNAL)一起使用。EXTERNAL指向任何HDFS位置,而不是HIVE元数据默认<hive.metastore.warehouse.dir>指定的路径。LOCATION '/warehouse/gmall/dim/dim_sku_info/'-- 修改hive表的属性,此次指定parquet采用lzo压缩TBLPROPERTIES ("parquet.compression"="lzo");
建表(拉链表)
拉链表有start_date和end_date字段。
DROP TABLE IF EXISTS dim_user_info;CREATE EXTERNAL TABLE dim_user_info(`id` STRING COMMENT '用户id',`login_name` STRING COMMENT '用户名称',`nick_name` STRING COMMENT '用户昵称',`name` STRING COMMENT '用户姓名',`phone_num` STRING COMMENT '手机号码',`email` STRING COMMENT '邮箱',`user_level` STRING COMMENT '用户等级',`birthday` STRING COMMENT '生日',`gender` STRING COMMENT '性别',`create_time` STRING COMMENT '创建时间',`operate_time` STRING COMMENT '操作时间',`start_date` STRING COMMENT '开始日期',`end_date` STRING COMMENT '结束日期') COMMENT '用户表'PARTITIONED BY (`dt` STRING)STORED AS PARQUETLOCATION '/warehouse/gmall/dim/dim_user_info/'TBLPROPERTIES ("parquet.compression"="lzo");
数据装载脚本(业务数据、全量)
if [ -n "$2" ] ;thendo_date=$2elseecho "请传入日期参数"exitfi
#!/bin/bashAPP=gmall# 如果是输入的日期按照取输入日期;如果没输入日期取当前时间的前一天if [ -n "$2" ] ;thendo_date=$2elsedo_date=`date -d "-1 day" +%F`fiods_order_info="load data inpath '/origin_data/$APP/db/order_info/$do_date' OVERWRITE into table ${APP}.ods_order_info partition(dt='$do_date');"# 省略其他代码case $1 in"ods_order_info"){hive -e "$ods_order_info"};;// 省略其他代码"all"){hive -e "$ods_order_info$ods_order_detail$ods_sku_info$ods_user_info$ods_payment_info$ods_base_category1$ods_base_category2$ods_base_category3$ods_base_trademark$ods_activity_info$ods_cart_info$ods_comment_info$ods_coupon_info$ods_coupon_use$ods_favor_info$ods_order_refund_info$ods_order_status_log$ods_spu_info$ods_activity_rule$ods_base_dic$ods_order_detail_activity$ods_order_detail_coupon$ods_refund_payment$ods_sku_attr_value$ods_sku_sale_attr_value"};;esac
数据装载脚本(业务数据、拉链表)
#!/bin/bashAPP=gmall# 如果是输入的日期按照取输入日期;如果没输入日期取当前时间的前一天if [ -n "$2" ] ;thendo_date=$2elsedo_date=`date -d "-1 day" +%F`fidim_user_info="set hive.exec.dynamic.partition.mode=nonstrict;set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;withtmp as(selectold.id old_id,old.login_name old_login_name,old.nick_name old_nick_name,new.start_date new_start_date,new.end_date new_end_datefrom(selectid,login_name,nick_name,start_date,end_datefrom ${APP}.dim_user_infowhere dt='9999-99-99'and start_date<'$do_date')oldfull outer join(selectid,login_name,nick_name,'$do_date' start_date,'9999-99-99' end_datefrom ${APP}.ods_user_infowhere dt='$do_date')newon old.id=new.id)insert overwrite table ${APP}.dim_user_info partition(dt)selectnvl(new_id,old_id),nvl(new_login_name,old_login_name),nvl(new_nick_name,old_nick_name),nvl(new_start_date,old_start_date),nvl(new_end_date,old_end_date),nvl(new_end_date,old_end_date) dtfrom tmpunion allselectold_id,old_login_name,old_nick_name,old_start_date,cast(date_add('$do_date',-1) as string),cast(date_add('$do_date',-1) as string) dtfrom tmpwhere new_id is not null and old_id is not null;"case $1 in"dim_user_info"){hive -e "$dim_user_info"};;"all"){hive -e "$dim_user_info$dim_sku_info$dim_coupon_info$dim_activity_rule_info"};;esac
数据装载脚本(日志数据、全量)
日志数据是json格式
APP=gmall# 如果是输入的日期按照取输入日期;如果没输入日期取当前时间的前一天if [ -n "$2" ] ;thendo_date=$2elsedo_date=`date -d "-1 day" +%F`fidwd_start_log="set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;insert overwrite table ${APP}.dwd_start_log partition(dt='$do_date')selectget_json_object(line,'$.common.ar'),get_json_object(line,'$.common.ba'),get_json_object(line,'$.common.ch'),get_json_object(line,'$.common.is_new'),get_json_object(line,'$.common.md'),get_json_object(line,'$.common.mid'),get_json_object(line,'$.common.os'),get_json_object(line,'$.common.uid'),get_json_object(line,'$.common.vc'),get_json_object(line,'$.start.entry'),get_json_object(line,'$.start.loading_time'),get_json_object(line,'$.start.open_ad_id'),get_json_object(line,'$.start.open_ad_ms'),get_json_object(line,'$.start.open_ad_skip_ms'),get_json_object(line,'$.ts')from ${APP}.ods_logwhere dt='$do_date'and get_json_object(line,'$.start') is not null;"# 代码省略case $1 indwd_start_log )hive -e "$dwd_start_log";;# 代码省略all )hive -e "$dwd_start_log$dwd_page_log$dwd_action_log$dwd_display_log$dwd_error_log";;esac
select 和 select count()的不同。
select * from ods_log 和 select count(*) from ods_log 的结果是不同的。
因为前者不进行MR,而后者因为count()函数会进行MR。
hive读取索引文件的问题
hive > set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
原因是hive.input.format的默认值是CombinHiveInputFormat,会Map之前合并小文件,导致lzo索引也合并了。
日志中的json解析
hive (gmall)>
SELECT get_json_object(‘[{“name”:”大郎”,”sex”:”男”,”age”:”25”},{“name”:”西门庆”,”sex”:”男”,”age”:”47”}]’,”$[0].age”);

若有收获,就点个赞吧
0 人点赞
