- 下方,标红为重点,蓝底为掌握。
- ">
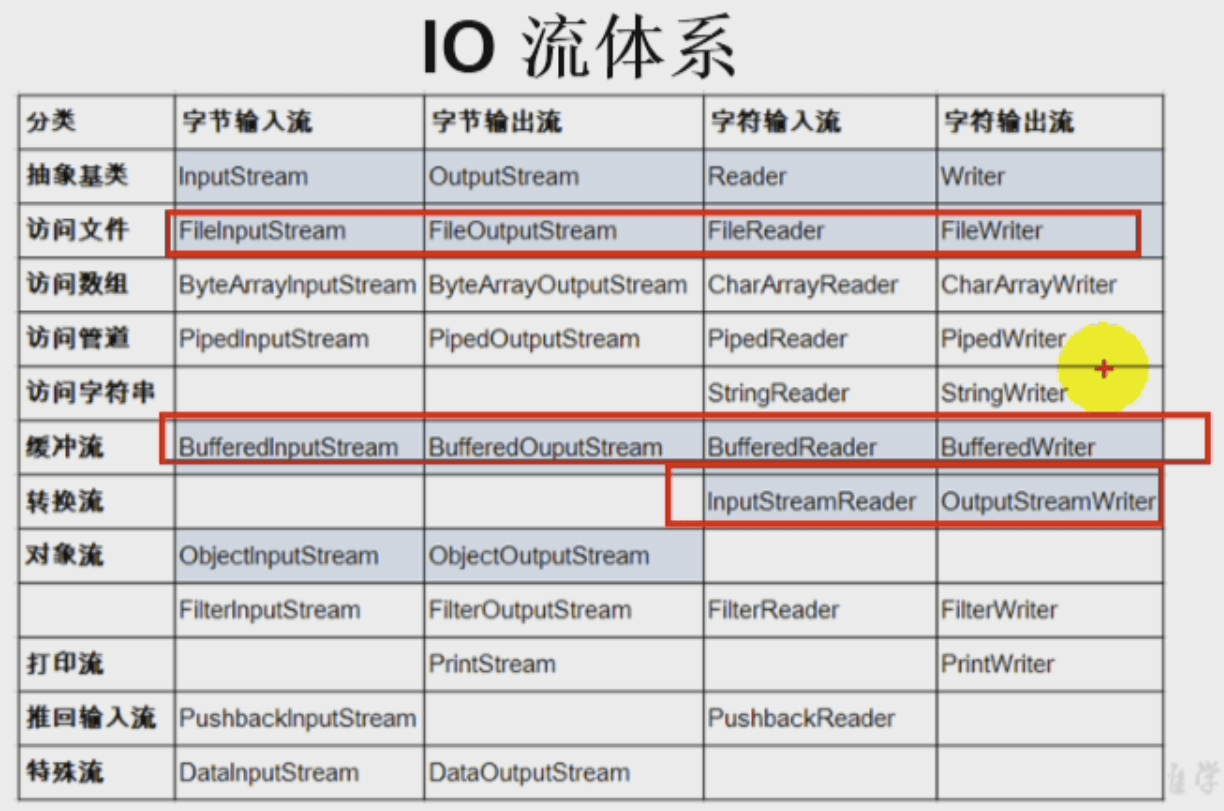
- 流的分类(重点):1.从存取方向上讲:所有流被分为输入流和输出流。2.从编码上讲,流分为字节流和字符流。3. 从类的实现上讲:节点流(或称文件流)分为4个基类(即,(输入 or 输出) & (字节 or 字符)共4种组合),而这4个基类的子类属于处理流(如缓冲流、转换流、等等)。
- ">

- “字节流、字符流、缓冲流”(个人观点)
- IO流的实现代码一般4个步骤:
- 拷贝文件:文件流(节点流) vs 缓冲流(更快)
- 字符缓冲流: 在读写方式上,对文本数据做了补充,比如readLine()方法。
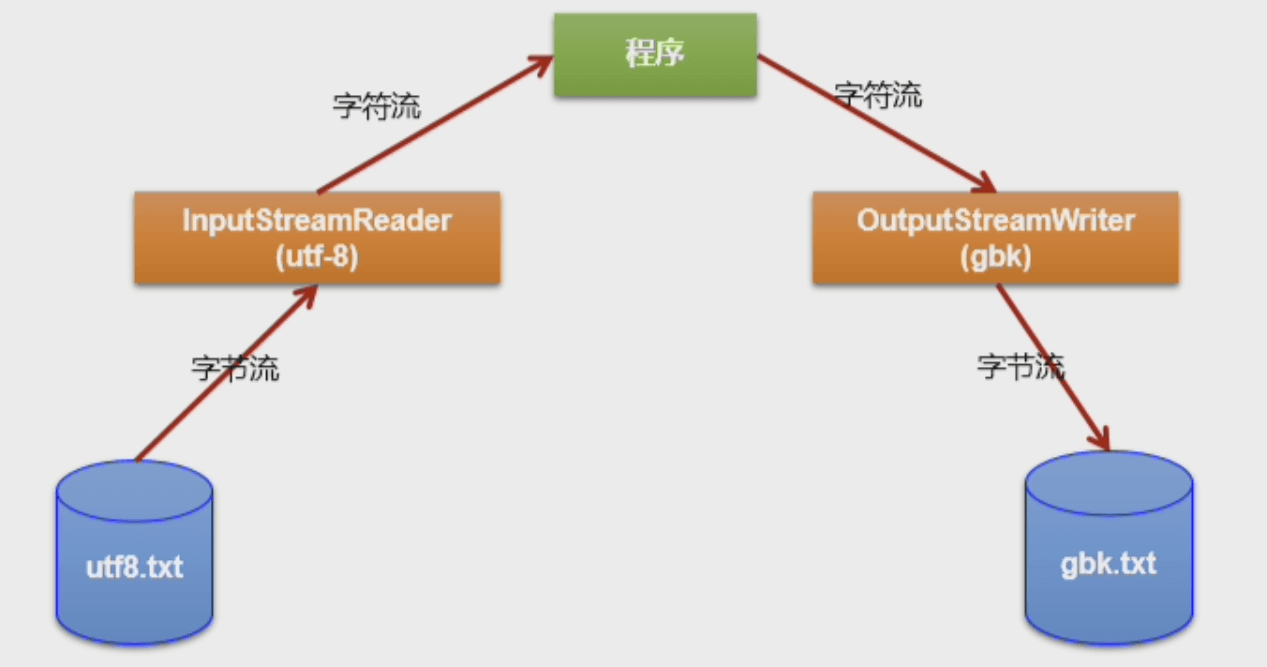
- 转换流: 属于字符流,它提供字节流与字符流之间的转换
- 对象流: 1.(反)序列化: 对象与字节数据的转换。2. 类可序列化3点要求:1.实现Serializable接口、 2.并提供static final long serialVersionUID属性、3. 内部属性满足可序列化、3. 开发上,一般不直接序列化对象为字节数据,而是先序列化为String,并用json格式来保存字符串。
- 随机存取文件流: 1.继承Object类,2.同时实现DataInput、DataOutput接口(由构造器的mode参数控制),3.文件记录指针:long getFilePointer(), void seek(long pos)。
- 方法补充:”abc”.getBytes()
- Java NIO(先了解,以后再展开): 1. jdk1.4推出的(Non-Blocking IO)。2. NIO面向缓冲区的(原IO面向流)、基于通道的IO操作。3. NIO有两套,分别针对标准IO、网络编程。4. jdk1.7推出NIO.2。
下方,标红为重点,蓝底为掌握。
流的分类(重点):1.从存取方向上讲:所有流被分为输入流和输出流。2.从编码上讲,流分为字节流和字符流。3. 从类的实现上讲:节点流(或称文件流)分为4个基类(即,(输入 or 输出) & (字节 or 字符)共4种组合),而这4个基类的子类属于处理流(如缓冲流、转换流、等等)。
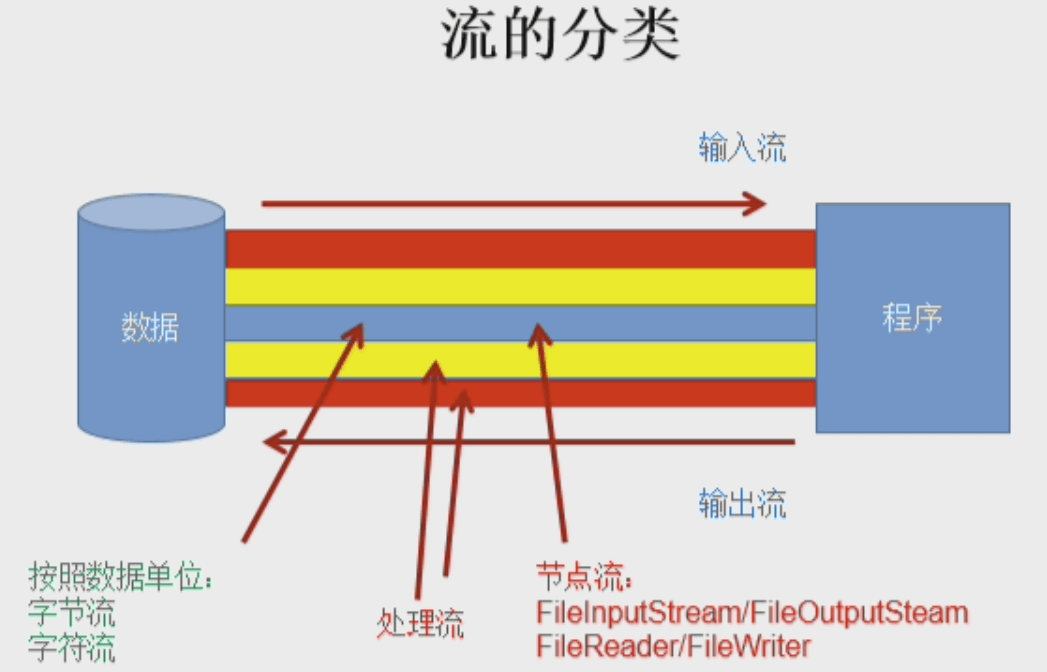
“字节流、字符流、缓冲流”(个人观点)
- 关于字节流和字符流:从机器的角度讲,字节流就够了,但是对于人而言,字符是字节编码而来的,为了适应这种编码机制,专门提供了处理字符数据的字符流。
- 缓冲流并非字节流和字符流的并行概念,它是对字节流和字符流的“赋能”(即继承自节点流,属于处理流的一种),它提供一个额外的缓冲区(默认8kb)及配套方法,增强了读写速度。所以在开发中,一般都用字节缓冲流、字符缓冲流。
IO流的实现代码一般4个步骤:


拷贝文件:文件流(节点流) vs 缓冲流(更快)
如下代码的结论:
fileStream copy 完成.平均耗时:256
bufferStream copy 完成.平均耗时:76
可见,缓冲流更快,关键原因其实它内部额外提供来一个比较大的缓冲区: buffer流额外提供了默认大小为DEFAULT_BUFFER_SIZE=1024*8 (即8kb) 的缓冲区。
注意:下方代码里也定义了 byte[] bbuf = new byte[1024] 来读写字节数据,也是算是简单的缓冲区,所以如果将文件流这里的bbuf设置大一些,文件流的速度也会很快。 但是注意,缓冲流中的缓冲区额外还有 flush()方法来刷新缓冲区等机制。
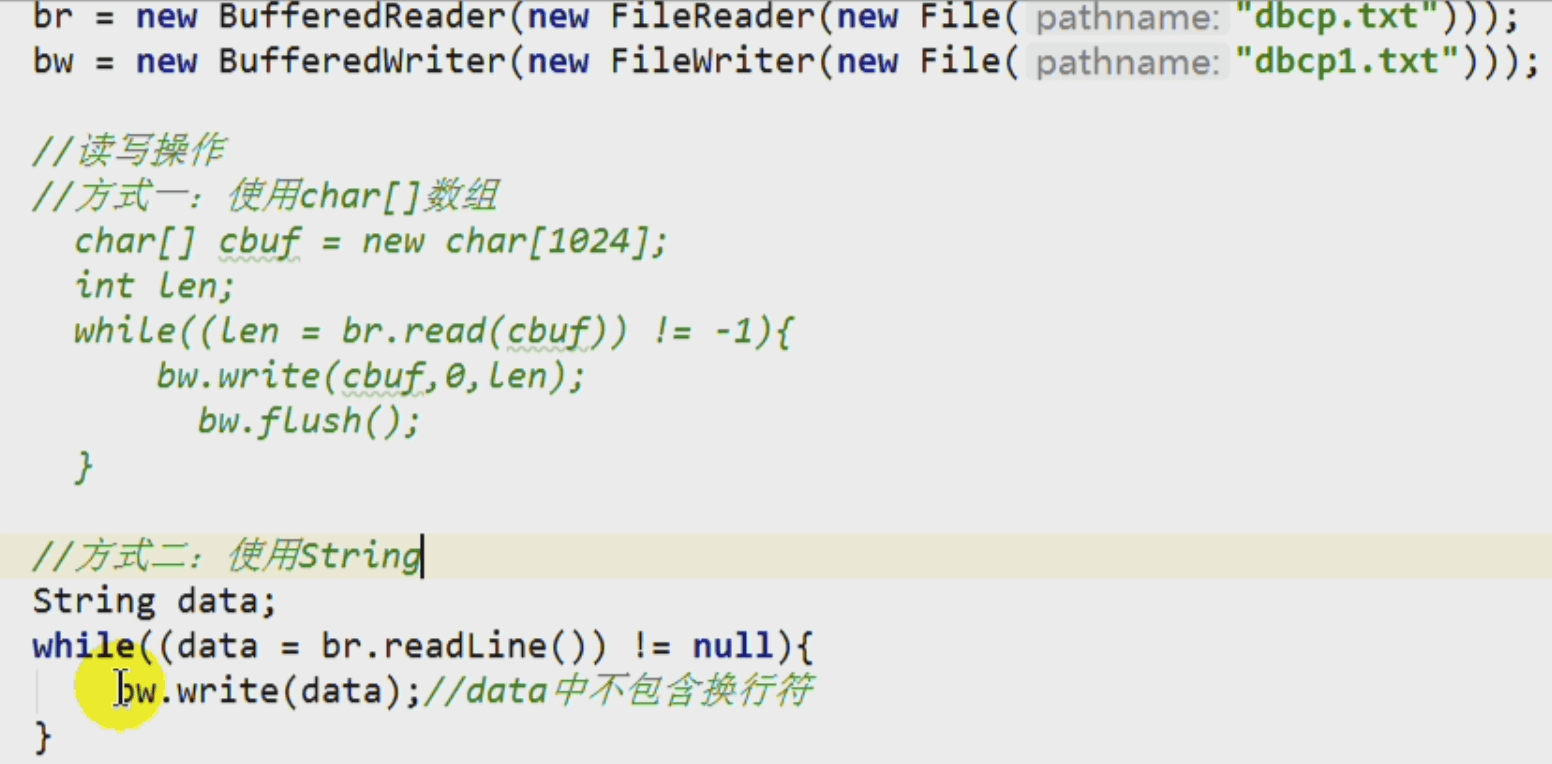
代码
package xj.java;import org.junit.jupiter.api.Test;import java.io.*;/*** @author jia* @create 2021-12-01 6:16 下午*/public class CopyFile {@Testpublic void copyTest(){String src = "/Users/xujia/Desktop/bigdata/1.尚硅谷大数据学科--核心基础/尚硅谷Java核心基础/v.avi";String des = "/Users/xujia/Desktop/bigdata/1.尚硅谷大数据学科--核心基础/尚硅谷Java核心基础/v-filecopy.avi";String bufferdes = "/Users/xujia/Desktop/bigdata/1.尚硅谷大数据学科--核心基础/尚硅谷Java核心基础/v-buffercopy.avi";long a;long file_total = 0;long buffer_total = 0;int times = 10;for (int i=0 ; i < times;i++){a = System.currentTimeMillis();filecopy(src,des);file_total += (System.currentTimeMillis() - a);a = System.currentTimeMillis();buffercopy(src,bufferdes);buffer_total += (System.currentTimeMillis() - a);}System.out.println("fileStream copy 完成.平均耗时:" + (file_total / times));System.out.println("bufferStream copy 完成.平均耗时:" + (buffer_total / times));}public static void buffercopy(String src,String des){BufferedInputStream bis = null;BufferedOutputStream bos = null;try {bis = new BufferedInputStream(new FileInputStream(src));bos = new BufferedOutputStream(new FileOutputStream(des));byte[] bbuf = new byte[1024];int bbuf_size = 0;while ((bbuf_size = bis.read(bbuf)) != -1){bos.write(bbuf,0,bbuf_size);}} catch (IOException e) {e.printStackTrace();} finally {try {if (bis != null)bis.close();if (bos != null)bos.close();} catch (IOException e) {e.printStackTrace();}}}public static void filecopy(String src,String des){FileInputStream fis = null;FileOutputStream fos = null;try {// make streamfis = new FileInputStream(src);fos = new FileOutputStream(des);// copybyte[] bbuf = new byte[1024];int bbuf_size = 0;while ((bbuf_size = fis.read(bbuf)) != -1){fos.write(bbuf,0,bbuf_size);}} catch (IOException e) {e.printStackTrace();} finally {try {if (fis != null)fis.close();if (fos != null)fos.close();} catch (IOException e) {e.printStackTrace();}}}}
字符缓冲流: 在读写方式上,对文本数据做了补充,比如readLine()方法。
转换流: 属于字符流,它提供字节流与字符流之间的转换


对象流: 1.(反)序列化: 对象与字节数据的转换。2. 类可序列化3点要求:1.实现Serializable接口、 2.并提供static final long serialVersionUID属性、3. 内部属性满足可序列化、3. 开发上,一般不直接序列化对象为字节数据,而是先序列化为String,并用json格式来保存字符串。
关于序列化中的 serialVersionUID属性: 可唯一标识类,即使在序列化后对类进行了修改,那么反序列化依然能进行。反之,如果不提供该属性,虽然序列化依然可进行,一旦类进行了修改,则反序列化失败。


(代码)将Person对象序列化
package xj.java;import org.junit.jupiter.api.Test;import java.io.*;/*** @author jia* @create 2021-12-01 10:46 下午*/public class Serialize {@Testpublic void SerialTest(){Person person = new Person("jia", 12306,1000);OutputStream os = null;ObjectOutputStream objectOutputStream = null;// 1. 序列化try {os = new FileOutputStream("person.bin");objectOutputStream = new ObjectOutputStream(os);objectOutputStream.writeObject(person);} catch (IOException e) {e.printStackTrace();} finally {if (objectOutputStream != null){try {objectOutputStream.close();} catch (IOException e) {e.printStackTrace();}}}// 2. 反序列化InputStream is = null;Person person2 = null;ObjectInputStream objectInputStream = null;try {is = new FileInputStream("person.bin");objectInputStream = new ObjectInputStream(is);try {person2 = (Person) objectInputStream.readObject();} catch (ClassNotFoundException e) {e.printStackTrace();}} catch (IOException e) {e.printStackTrace();} finally {try {if (objectInputStream != null)objectInputStream.close();} catch (IOException e) {e.printStackTrace();}}// 测试 原对象和反序列化对象System.out.println("原对象: " + person);System.out.println("反序列化对象: " + person2);}}class Acount implements Serializable{@java.io.Serialprivate static final long serialVersionUID = -6849794470712367710L;float balance;public Acount(float balance) {this.balance = balance;}@Overridepublic String toString() {return "balance=" + balance ;}}class Person implements Serializable {// 1. 实现Serializable接口// 2. 唯一化标识@java.io.Serialprivate static final long serialVersionUID = -6821941230754667710L;String name;int carId;Acount acount; // 3. 所有属性要可序列化public Person(String name, int carId, float acount) {this.name = name;this.carId = carId;this.acount = new Acount(acount);}@Overridepublic String toString() {return "Person{" +"name='" + name + '\'' +", carId=" + carId +", acount=" + acount +'}';}}
随机存取文件流: 1.继承Object类,2.同时实现DataInput、DataOutput接口(由构造器的mode参数控制),3.文件记录指针:long getFilePointer(), void seek(long pos)。

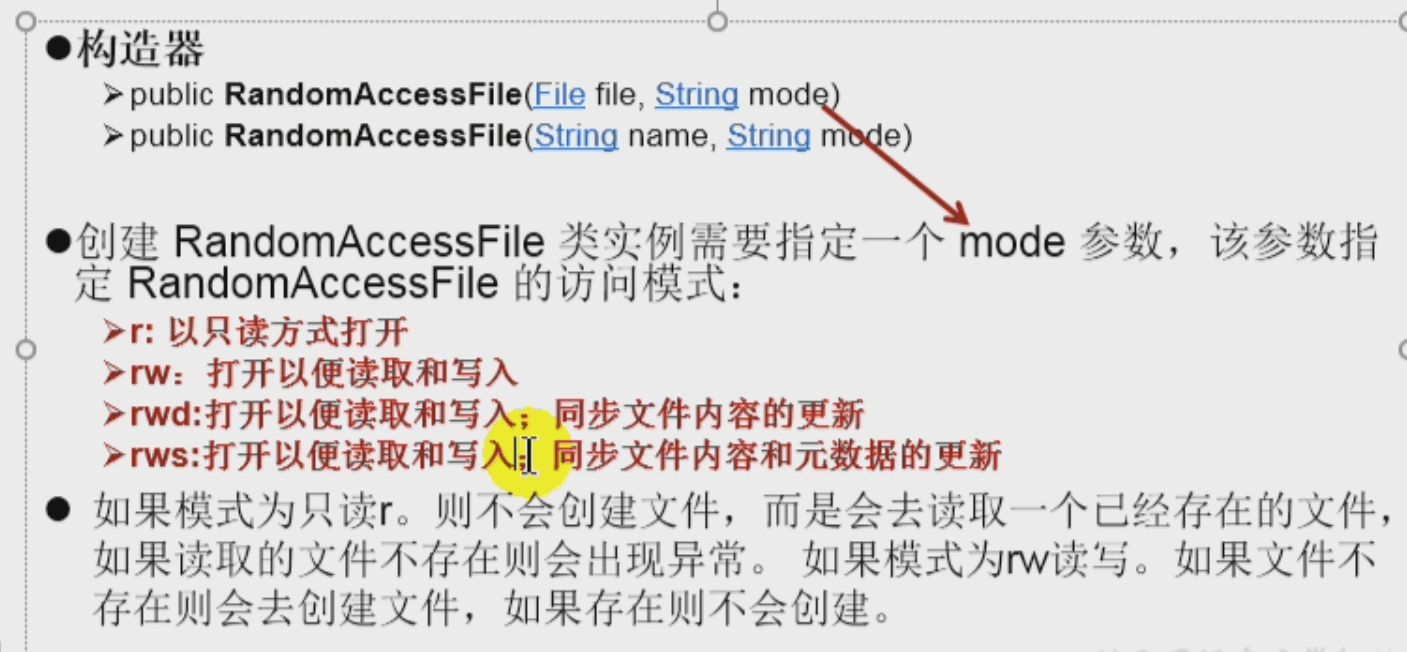
seek: 比如实现多线程断点下载。

方法补充:”abc”.getBytes()
Java NIO(先了解,以后再展开): 1. jdk1.4推出的(Non-Blocking IO)。2. NIO面向缓冲区的(原IO面向流)、基于通道的IO操作。3. NIO有两套,分别针对标准IO、网络编程。4. jdk1.7推出NIO.2。

- NIO.2 : 引入Path类替代原Files类,提供Files工具类来操作文件或目录




若有收获,就点个赞吧
0 人点赞
