- Java 主函数: 格式固定 、 被JVM识别
- 命名规范: 包名、类名、变量名、常量名
- 整型变量bit和表示范围
- long类型变量必须以”l”或”L”结尾,为什么吗?
- 浮点型常量
- 建议全使用utf-8编码,为什么?
- 基本类型的运算的特别点:byte、char、short做运算时,结果都为int类型,当操作数是浮点常量时,结果为double类型。
- java的8种基本数据类型是哪些?引用数据类型是哪些?
- String可以和所有(含boolean)的基本数据类型做运算,且只能是连接符+。如下,注意符号”+”是做加法运算还是连接运算?
- 进制的表示方式
- 关于模除(取模)的方法
- 补码是什么?计算底层都以补码的方式来存储数据, 又是为什么吗?。
- 关于异或
- +1和自增1有区别? 答:自增1不会改变本身的类型。
- & | ^ 到底是逻辑运算符吗?还是位运算符吗?
- 交换两个变量的值?(要求不能使用辅助空间)
- 三元运算符的三个细节
- 运算符优先级(不用记)
- ⭐️数组的默认初始值(数值元素):char型为0,boolea型为false,引用型为null;
- JVM - 内存的简化结构 ( 跳转到完整版 )
- 一维数组的内存解析(引用、垃圾回收机制)
- 二维及多维数组的理解。
int[][] arr; int[] arr[]; int arr[][]; - 二维数组中“各个空间的值”是什么?比如
[I@15db9742 - 常用api
- 数组常见异常 : 1. 索引越界异常 2. 空指针异常
- 面向对象的3条知识主线
- ⭐️面向过程 与 面向对象 的思想?POP考虑怎么做,OOP考虑谁来做。
- OOP完整d1类结构:属性、构造器、方法、代码块、内部类
- ⭐️JVM内存解析(完整版)
- ⭐️类中:成员变量(属性) 与 局部变量 的区别?
- 理解“万事万物皆对象”:
- 谈方法1:方法重载: 同名方法,但形参列表不同即可。(注:无关方法返回)
- 谈方法2: 可变个数的形参:
String[] a等价String ...a。 - ⭐️谈方法3: 方法参数的值传递机制(传递副本)。
- 方法4: 递归的方法。
- 封装与隐藏: 高内聚、低耦合; 4种访问权限修饰符
- ">

- 构造器:一旦显式定义构造器,jvm就不再提供默认的空参构造器。
- JavaBean: 符合特定标准的java类,好处:方便与其他“应用”交互数据。
- UML类图:
+ getName(id:int) : String - 类的this关键字的使用场景:
this.局部变量、this.方法、this(...)来简化重载构造 - package关键字:包是对工程中类的管理。用目录结构去理解package。
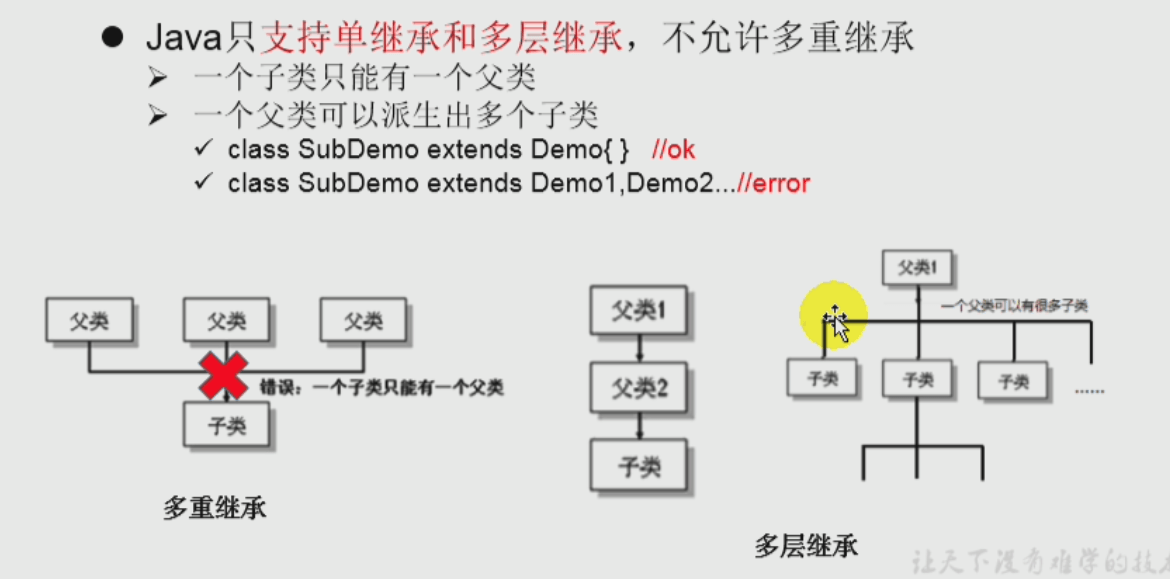
- ⭐️⭐️继承Interitance:
public class Stu extends Person{ ... }、private情况、单\多层继承、java.lang.Object类 - 方法的重写: 1. private方法不可被重写 2. static方法不是重写。
- super: 基类实例的本身。
this.id和super.id有啥区别?、super调用构造器。 - 1 子类对象的实例化过程
- 对象的多态性: 父类对象的多态性 = 子类重写父类方法 + 父类调用虚拟方法。
- 区分重载和重写: 从多态的角度
- 子类父类的类型转化: 子类对象向上转型(多态),父类对象向下转型
- java.lang.Object类 : 所有类的基类,它有许多通用的方法(值得一看)。
- == 与 类的equals()方法 : 重写、toString()同理
- 代码案例: 构造器重载、重写toString和equals
- 单元测试:
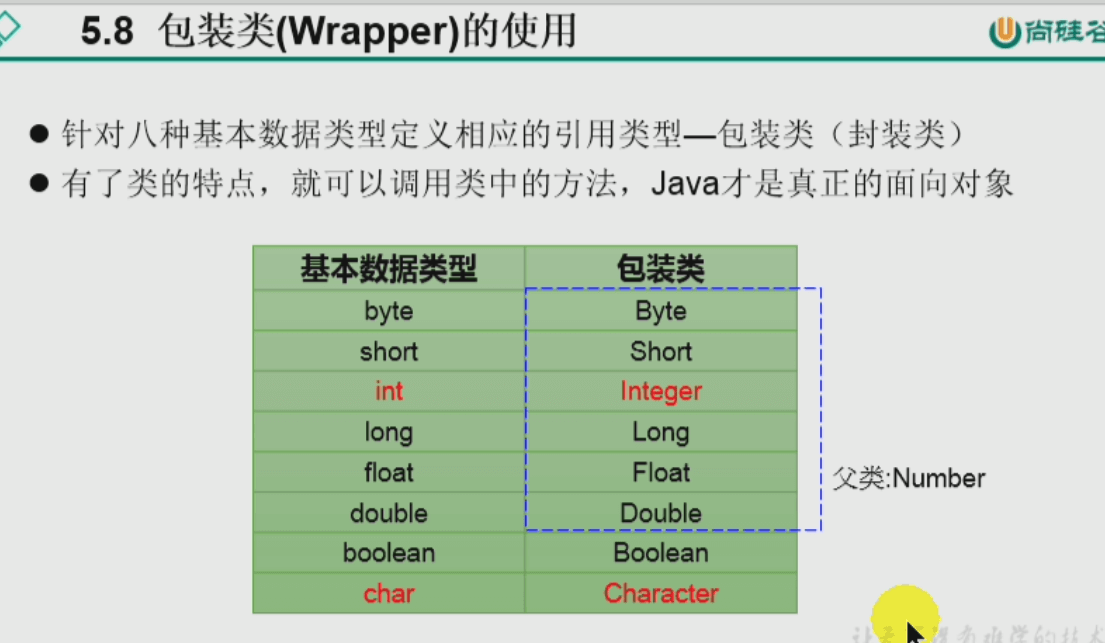
import org.junit.Test@Test - 包装类(对基本数据类型的包装): “基本数据类型、包装类与String类”的相互转换
- 自动装箱和自动拆箱(jdk5特性): 简写
Integer a = 1<—>Integer a = new Integer(1). 另外,对形参赋值、函数返回等也有效。 - static关键字 : 生命周期角度理解、类变量
- 单例设计模式:static实现
- 类:代码块(初始化块): 只能用static修饰,即(非)静态代码块
- final关键字修饰:类->不可继承,方法->不可重写,变量->变为常量
- abstract关键字:有抽象方法的类一定要抽象类,反之抽象类不一定有抽象方法。
- abstract特殊用法:匿名子类
- 模版设计模式(TemplateMethod): abstract + 多态
- 接口: 规范标准、多重继承的效果。
- 接口有4种实现方式:(非)匿名实现类(非)匿名对象。注:和抽象方法如出一辙。
- 接口的应用:代理模式、工厂模式
- 内部类(看懂即可,要求不高)
- 被内部类所使用的外部类的局部变量,必须要被 finnal 修饰。
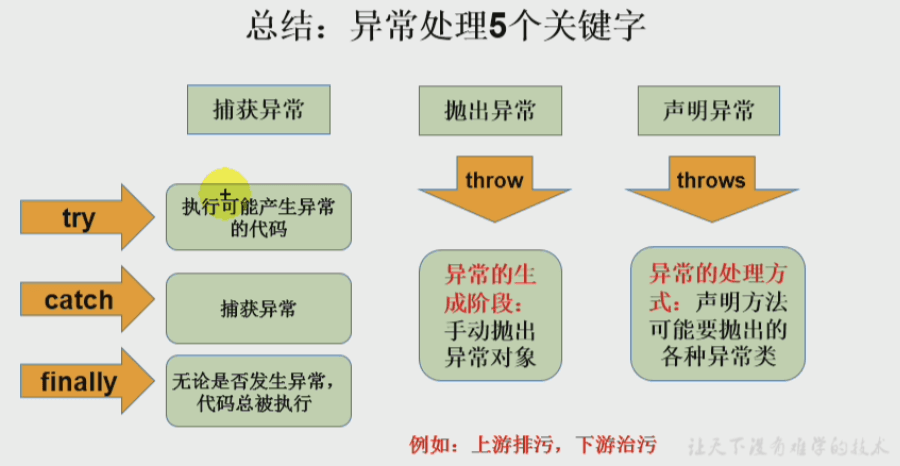
- 异常处理
- 异常处理方式一:try-catch-finally : 1. 处理编译时异常、2. 注意异常类型的子父类关系、3. finally可选1,但存在则一定会被执行2 哪些语句需要放在finally中呢?3:见下。
- 异常方式二:throws + 异常类型、重写异常方法的规则、如何选择throws 或者 try-catch-finally ?
- 手动抛出异常:比如:throw new Exception(“输入错误”)
- 自定义异常类
- 异常综合练习与总结
- 一些面试题
Java 主函数: 格式固定 、 被JVM识别



命名规范: 包名、类名、变量名、常量名
包名: xxxyyyzzz
类名:XxxYyyZzz (大驼峰)
变量名、方法名: xxxYyyZzz (小驼峰)
常量名:XXX_YYY_ZZZ
整型变量bit和表示范围
字节byte = 8bit,表示范围 -27 ~ 27 -1
short = 2个byte, 表示范围 - 215 ~ 215 -1
int = 4个byte,表示范围 -231 ~ 231 -1
long = 8个byte, 表示范围 -263 ~ 263 -1
long类型变量必须以”l”或”L”结尾,为什么吗?
正确写法:long a = 2222L;
一个事实:jvm默认int类型创建整型,默认double类型创建浮点数。
- 先看
long a = 2222为什么编译通过?因为在jvm可以以int类型创建常量2222,也能创建以long类型的变量a, 之后再将该变量被指向了该常量, 期间该常量甚至强制类型转换为long类型。 - 再看
long a = 222222222222222222为什么编译错误?因为jvm在以int类型来创建该常量时就编译失败了,根本谈不上再此之后的强制类型转换的过程。
注:基本数据类型和引用类型的变量存放在栈中,常量等存放在堆中。
浮点型常量

建议全使用utf-8编码,为什么?
utf-8是互联网最通用最广泛使用的一种unicode编码方式, 全互联网符号都能被唯一编码,所以不存在乱码问题。什么是乱码呢?比如早期的英语系国家使用的ascll编码方式,但它只能编码28个字符, 可是全世界各种符号可不止这么一点,所以符号并不是被唯一编码,当写入和读出时采用不同的编码时,这就导致了乱码的问题。
基本类型的运算的特别点:byte、char、short做运算时,结果都为int类型,当操作数是浮点常量时,结果为double类型。
不仅如此,byte类型与byte类型的运算结果也是int类型。以上这些规定可以被理解为防止内存溢出。】
java的8种基本数据类型是哪些?引用数据类型是哪些?
8种基本数据类型 = 4个整型byte\short\int\long, 2个浮点型float\double, 1个字符型char ,1个布尔型boolean
引用数据类型 = 类、接口、数组等。
String可以和所有(含boolean)的基本数据类型做运算,且只能是连接符+。如下,注意符号”+”是做加法运算还是连接运算?
// + 做加法‘a’ + 1 结果为int类型‘a’ + 1.0 结果为double类型'a' + 'b' 结果为int类型// + 做连接"a" + 1 结果为String类型"a" + 1.0 结果为String类型"a" + 'b' 结果为String类型
进制的表示方式
二进制(binary) : 0b或0b开头
十进制(decimal)
八进制(octal):0开头
十六进制(hex):0x或0X开头, 从0~9以及A~F(或a~f)
关于模除(取模)的方法
”a mod n“ 的截断法取模(⚠️ 商向零取整):
应用举例,8位无符号整数的值的范围是0到255.因此4+254将上溢出,结果是2。
因为258 mod 256 = 258 - 256*向零取整(258/256) = 258 - 256 = 2。
应用举例,8位有符号整数的值的范围,如果规定为−128到127,则126+125将上溢出,结果是−5。
因为 251 mod 256 = 251 - 256*向零取整(251/256) = 251 - 256 = -5。
补码是什么?计算底层都以补码的方式来存储数据, 又是为什么吗?。
正数和0的补码就是该数字本身。负数的补码 = 反码+ 1(换言之,负数的补码 = 对应正数的按位取反 + 1)
为什么需要补吗? 一是因为在计算机的数字电路中只有加法器,没有所谓的“减法器”。二是因为加法可以实现减法。
为什么加法可以实现减法?
这是建立在数值表示范围的条件,因为会溢出,所以在模256下的加减法,用0, 1, 2,…, 254,255表示其值,或者用−128, −127,…, −1, 0, 1, 2,…,127是完全等价的,只是两者最终结果有128的偏移而已。如何理解呢?
- 先举个例子来理解”加法实现减法“:又一个12小时的圆形时钟⏰,不管在任何时刻,都满足:前进x小时=后退12-x小时,后退x小时=前进12-x小时,换句话说就是
+x = -(12-x), -x = +(12-x)。从其中的-x = +(12-x) > 0就可以知道减法是可以由加法实现的,也就是说把-x和+(12-x)互换后对结果没有任何影响。 - 结论:模256的加减法,不管是何种数值范围,始终都有“减x = 加 (256 减 x) ”, 其中(256 减 x) > 0。 我们可以发现,减法运算可以被替换为加法运算。所以原码的运算可以转化为补码运算,而得到原码的结果,只需要将补码下运算的结果偏移到原码即可。
- 那么补码怎么具体来的?
- 根据上面的解释,可以把−128到−1等价到高位二进制的1000 0000到1111 1111 ,0到127等价到低位二进制0000 0000到0111 11110。所以有符号数的加减法可以转为无符号的加法器来计算。这种解释的结果其实就是补码。注意,在计算上无符号二进制,但是认知上把高位1视为负数,0视为正数。
- 那么补码怎么具体来的?
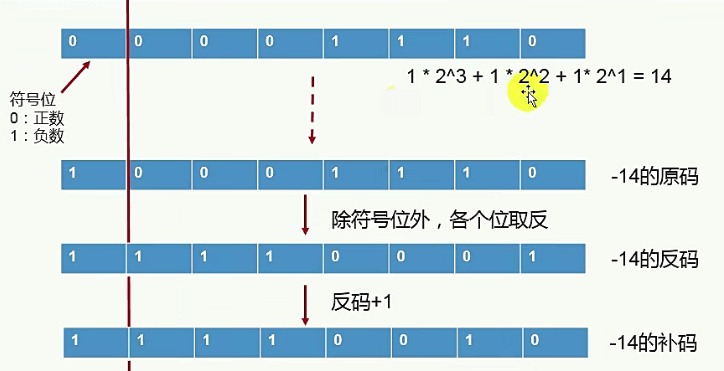
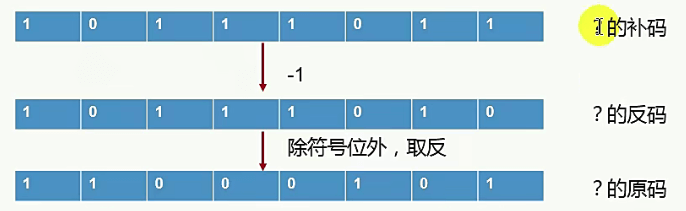
答:-69
关于异或


+1和自增1有区别? 答:自增1不会改变本身的类型。
s = s + 1 中的 1 和 s+=1 中的1是不同的概念,前者做加法运算(1的类型为int),后者叫自增(1的类型同自身)。
同理 s++; ++s; s+=1 ;s+=2; 等是自增操作,这种操作不会改变原类型,要区别于例如s = s + 1的加法运算。
& | ^ 到底是逻辑运算符吗?还是位运算符吗?
Java中:& | ^在两者中都用有,逻辑运算符的操作单位只能是boolean类型。位运算符的操作单位是二进制数字。
交换两个变量的值?(要求不能使用辅助空间)
方式一:(有缺点) 位运算符(异或) 结论: **b ^ a ^ a == a ^ b ^ a == b**
int a = 2;int b = 3;a = a ^ b; // 新a = a ^ bb = a ^ b; // 新b = 新a ^ b = a ^ b ^ b = aa = a ^ b; // 新新a = 新a ^ 新b = a ^ b ^ a = b
缺点:只能适用数值类型。
方式二(有缺点)
int a = 2;int b = 3;a = a + b; // 新a = a + bb = a - b; // 新b = 新a - b = ... = (a + b) - b = aa = a - b; // 新新a = 新a - 新b = ... = (a + b) - a = b
缺点1: 可能溢出; 缺点2: 只适用数值类型。
类似下面思路:
甲在左边,乙在右边,问甲乙怎么交换位置呢?答:甲先跳到乙头上,然后乙带着甲一起跳到左边;甲再从乙头上跳到右边。
三元运算符的三个细节
- 细节1:表达式的结果必须兼容
int和double是兼容类型,编译正确。 int和字符串不兼容,编译错误。

- 细节2: 允许嵌套。

- 细节3: 三元运算完全可以被if-else代替。反之则不成立。
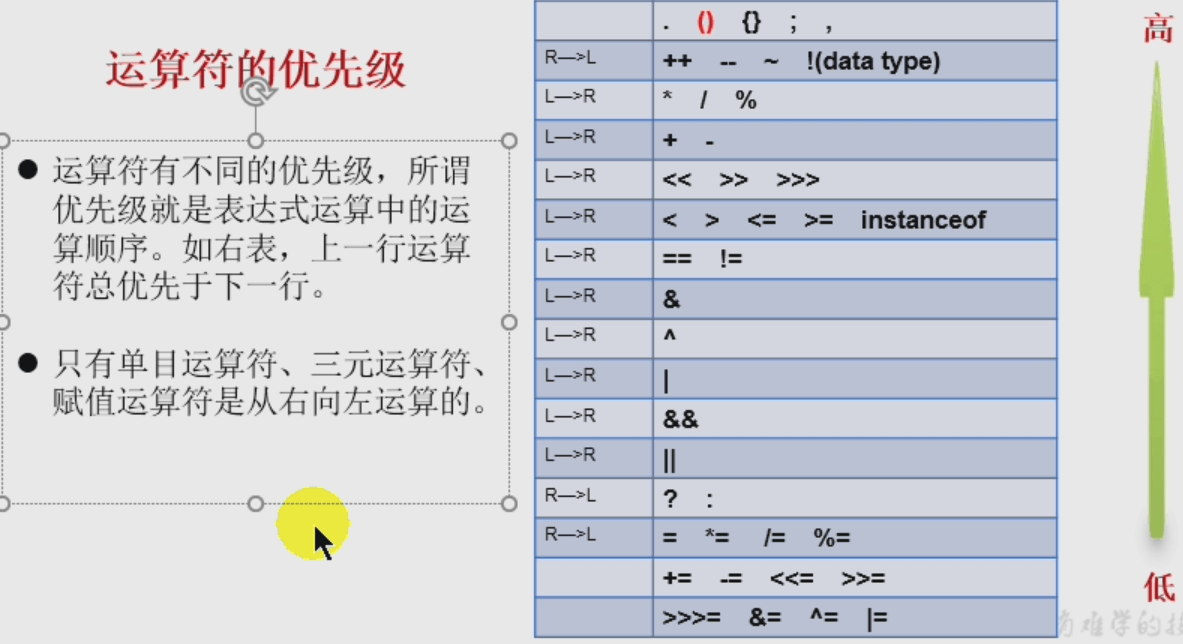
运算符优先级(不用记)
- (仅记下面几条吧)
- 单目运算符只有一个操作数,双目运算符有两个操作数,三目运算符则有三个操作数。

- && 优先级高于 ||
- 布尔运算 优先于 位运算符 优先于 逻辑运算符。
⭐️数组的默认初始值(数值元素):char型为0,boolea型为false,引用型为null;

- “数组元素是引用类型”举例:
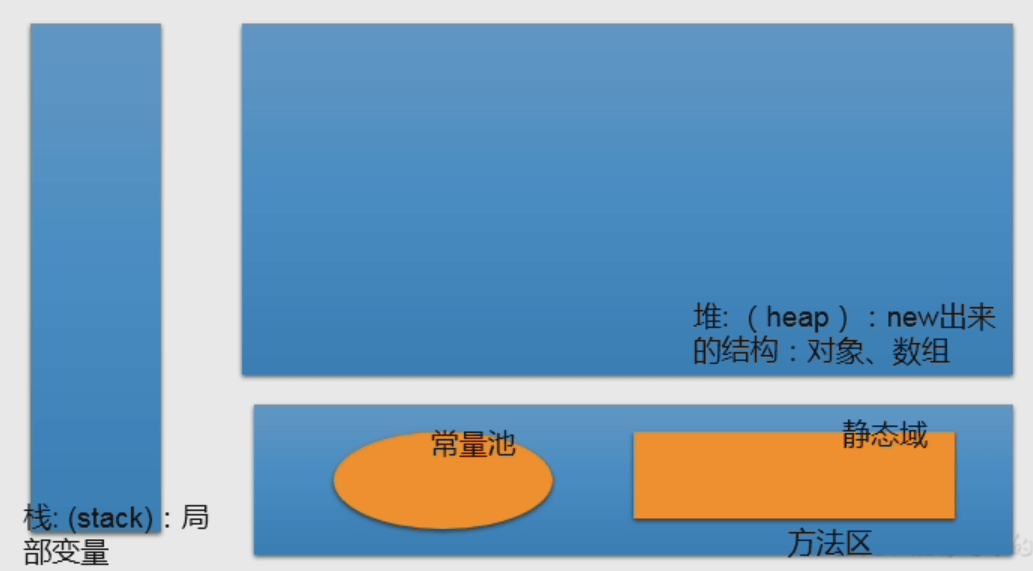
JVM - 内存的简化结构 (跳转到完整版)
- 局部变量:放在方法中的变量都是局部变量。
- 引用类型:即new出来的结构:对象实例(类、数组、接口)。
- 特别地:
int[] arr = {1,2,3}; 这里的数组不是new出来的呀?- 答:其实是new出来的,只是因为jvm的推断机制下的简化写法,其标准写法是
int[] arr = new int[3]{1,2,3}。同理,int[] arr = new int[]{1,2,3}, 这里int[]部分也使用了推断机制。
- 答:其实是new出来的,只是因为jvm的推断机制下的简化写法,其标准写法是
- 特别地:
- 堆:new 一个对象(或数组)时,堆中开辟出一段连续的内存。
一维数组的内存解析(引用、垃圾回收机制)

注意:相同类型
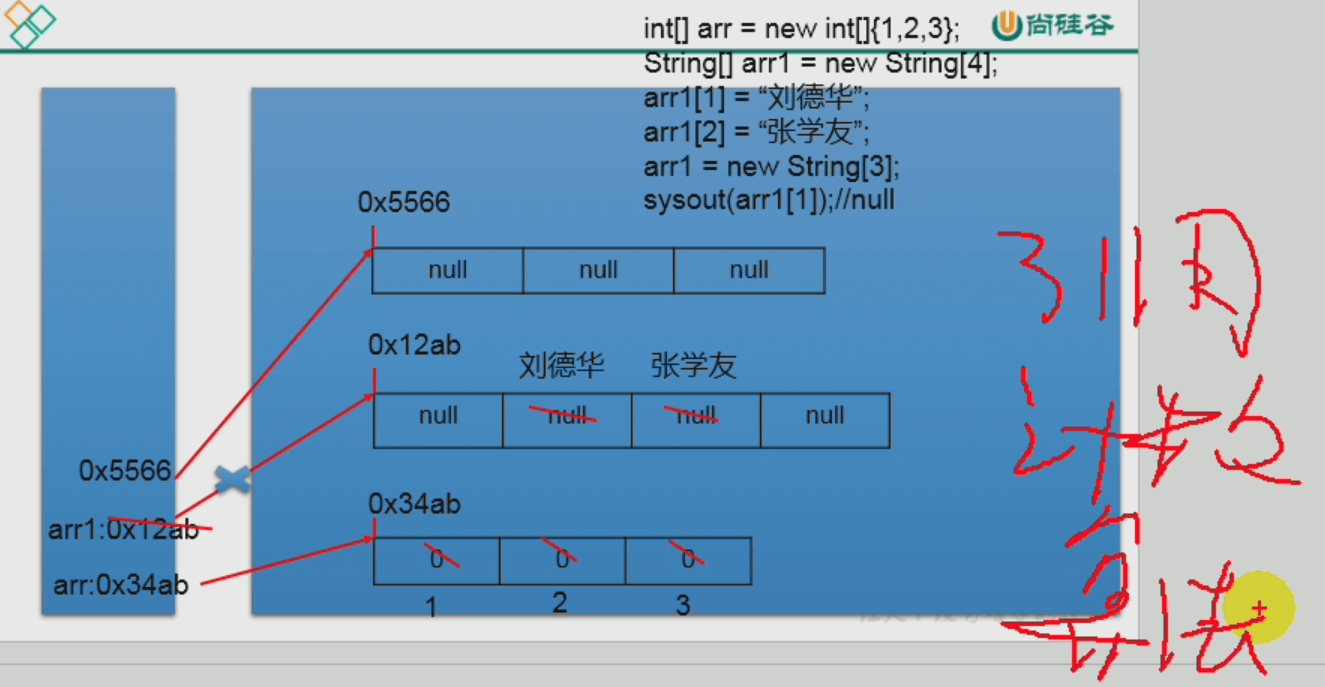
以上不完全正确:其中“刘德华”和“张学友”是常量,它们在常量池中,而非堆中。
- 栈和堆之间的联系: 栈中局部变量的值 = 堆中对象(或数组)的首地址值。
- 引用计数算法(堆中的垃圾回收机制): 对栈中的每个对象或数组的被引用进行计数,从而实现垃圾回收机制。
- 当函数开始后,对应着局部变量的入栈,也伴随着一些局部变量对堆中对象或数组的引用。- 而当函数结束时,局部变量也出栈了,伴随着堆中对象或数组的引用计数减小。- 当某个对象或数值的引用计数为0时,稍后被JVM回收其空间。
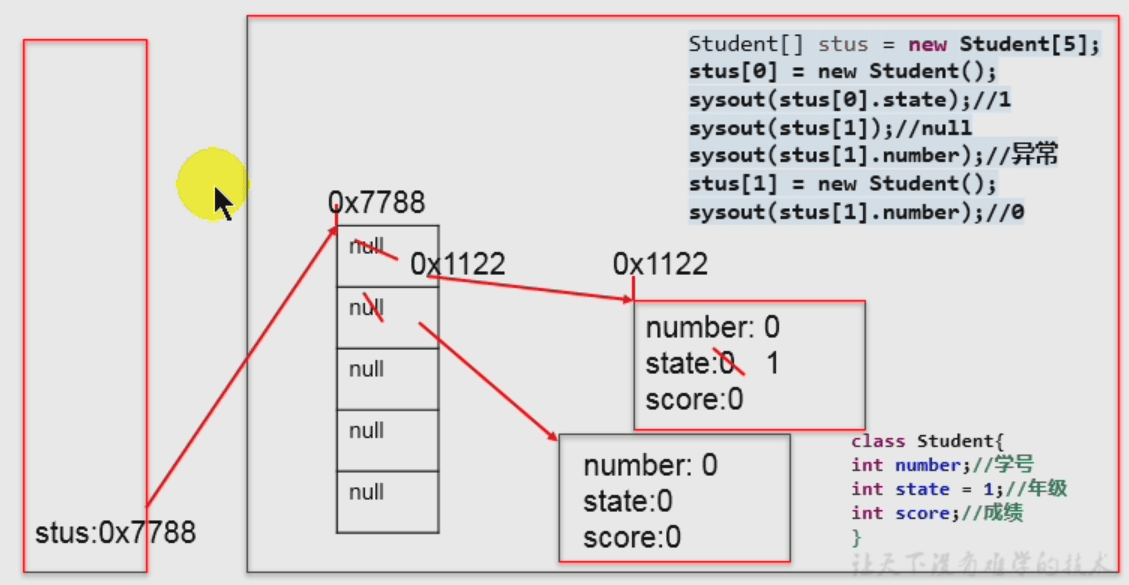
二维及多维数组的理解。
int[][] arr; int[] arr[]; int arr[][];
所以,下面写法等价:
int[][] arr = new int[3][];(主张写法)int arr[][] = new int[3][];int[] arr[] = new int[3][];
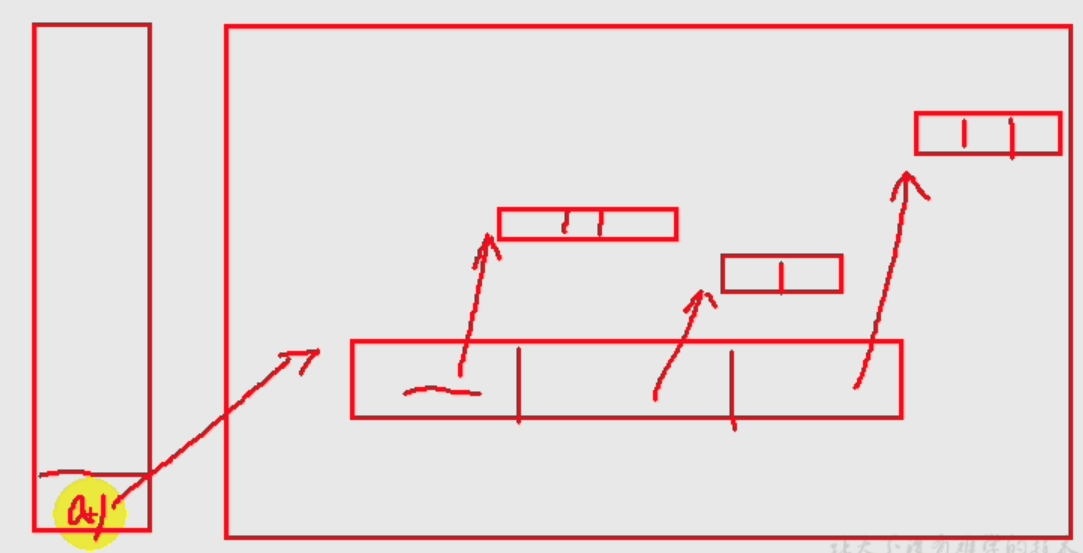
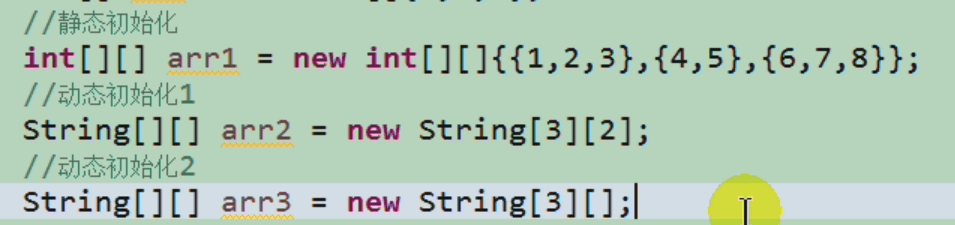
二维数组中“各个空间的值”是什么?比如[I@15db9742
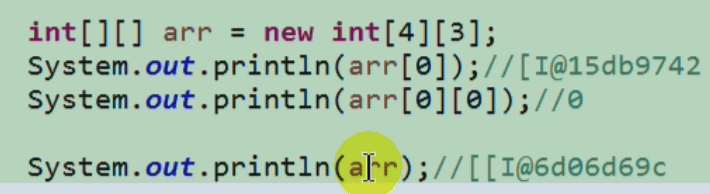
arr[0]值是[I@15db9742:
[表示指向一维数组。I表示指向的是Int类型的数组。15db9742表示指向数组的首地址。- arr[0][0]值是常量
0arr值是[[I@6d06d69c:
[[表示指向二维数组
常用api

数组常见异常 : 1. 索引越界异常 2. 空指针异常
空指针的3种情况:
空指针:访问地址值为null,一般情况都是局部变量的值为null。注:null是引用数据类型的默认值。
面向对象的3条知识主线

⭐️面向过程 与 面向对象 的思想?POP考虑怎么做,OOP考虑谁来做。

- “人把大象装进冰箱” 面向过程。(考虑怎么做)

- “人把大象装进冰箱” 面向对象。(考虑谁来做)
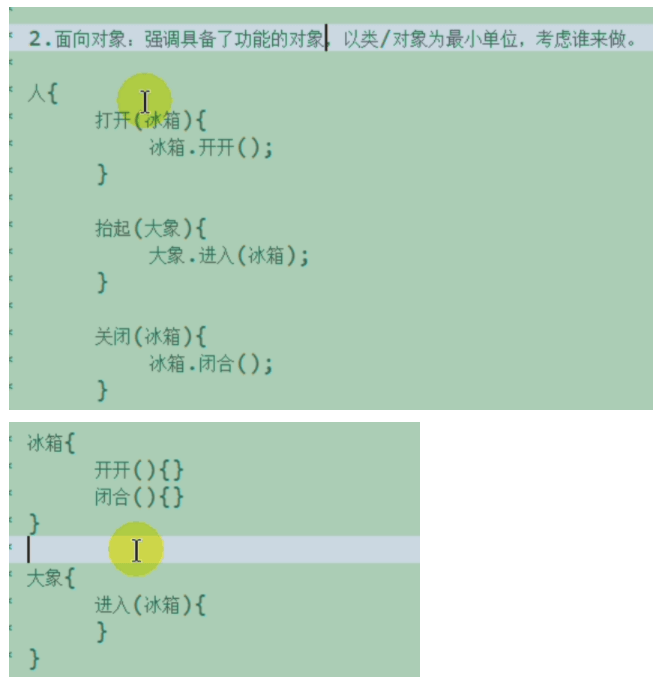

OOP完整d1类结构:属性、构造器、方法、代码块、内部类

⭐️JVM内存解析(完整版)
- 内存解析之前。

- 内存解析的过程。(参考书《JVM规范》)
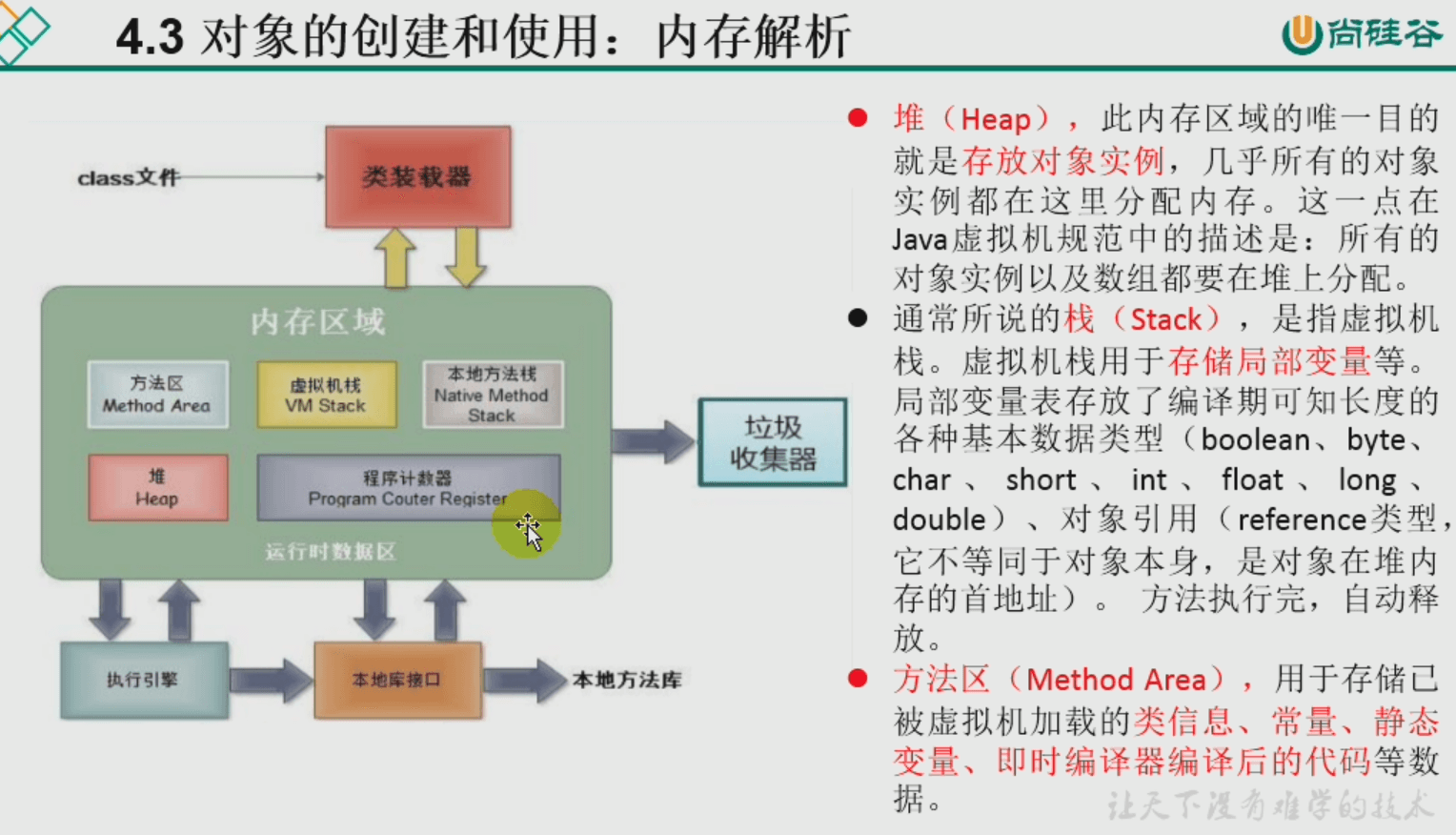
- 说明
本地方法栈:是留给本地的其他语言的局部变量,比如C等。
虚拟机栈:是我们通常简称的栈,它主要存储Java方法中的局部变量。
堆:new 出来的对象实例(类、数组、接口),会在堆中开辟出一段连续的内存。
方法区:这里的常量和静态变量,在方法区内部又划分出了所谓常量池和静态域。 注:静态变量比如static String a; ,静态变量可以修改,特性是属于类变量,随着类加载而加载,不需要实例化即可调用。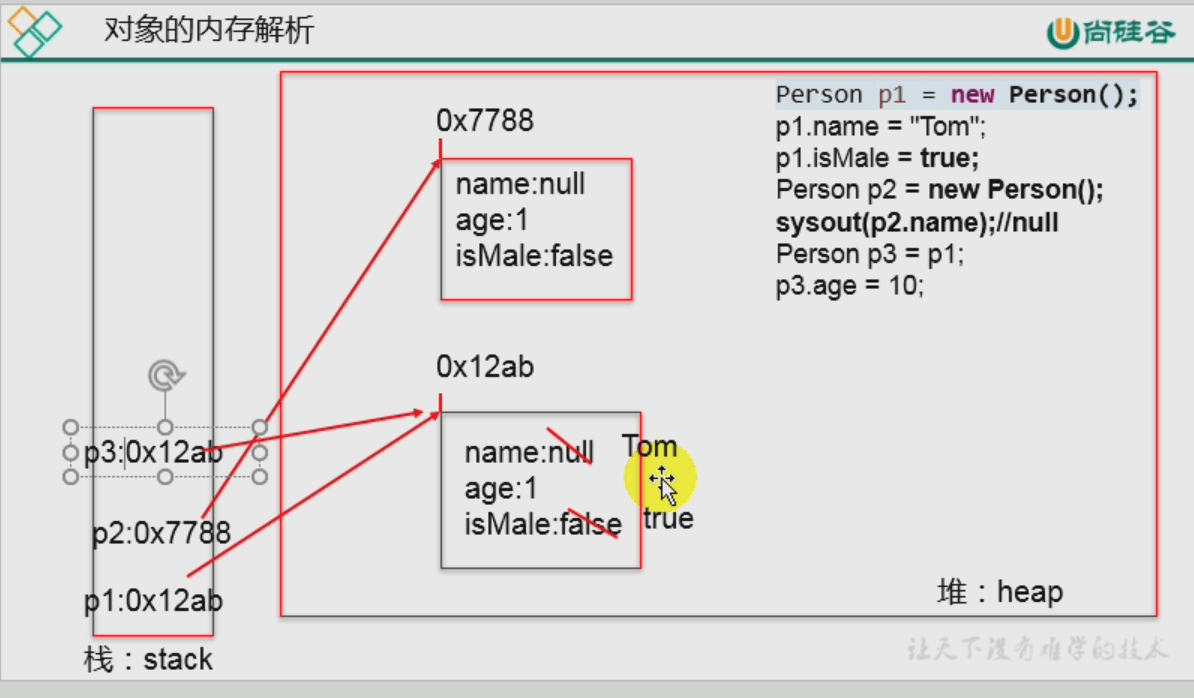
注意:“Tome”等常量其实在常量池中,而不在堆中。
- 引用类型的数组
- 下面是更具体的

⭐️类中:成员变量(属性) 与 局部变量 的区别?
相同点:定义格式、先声明后使用、对应作用域。
不同点:声明位置不同、权限修饰符不同、默认初始化值不同、内存加载位置不同。
- 特别注意


理解“万事万物皆对象”:

- 下面举个例子:
前端中的每个元素对应后台中的一个实例。
数据表中的这些列对应着类的多个属性,数据表的行对应类的多个实例。
谈方法1:方法重载: 同名方法,但形参列表不同即可。(注:无关方法返回)
简单说:同名且形参列表不同,就可以唯一表示方法入口。


谈方法2: 可变个数的形参:String[] a 等价 String ...a。

- 实参的区别(举例)
- 旧方式,

- 新方式:
- 旧方式,
- 注意:两种方式对jvm是等价的,所以两者不可共存,不可构成方法重载。


⭐️谈方法3: 方法参数的值传递机制(传递副本)。

注意:不同变量类型在值传递机制下的区别。见下,数组元素交换的错误案例:
int main(){int[] arr = new int[]{1,2};swap(arr[0),arr[1]); // 错误写法,由于值传递机制,所以并不能完成数组元素交换。}void swap(int a,int b){int tmp = a;a = b;b = tmp;}
方法4: 递归的方法。

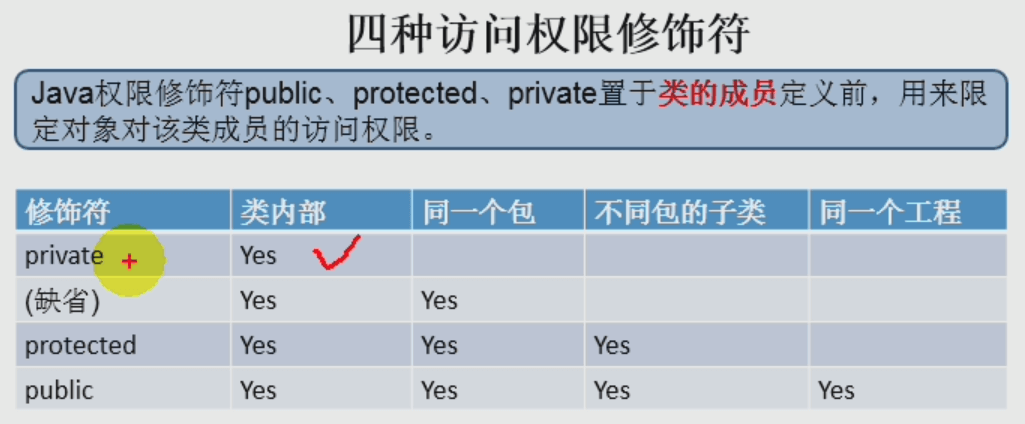
封装与隐藏: 高内聚、低耦合; 4种访问权限修饰符

高内聚低耦合:该自己的事自己做,该帮助别人的事我才帮。
- 修饰符权限范围 (助记:private类内,default包內,public工程內)
构造器:一旦显式定义构造器,jvm就不再提供默认的空参构造器。
JavaBean: 符合特定标准的java类,好处:方便与其他“应用”交互数据。

疑问: 为何要无参的公共构造器? 答:除了new的方式实例化类,还有更为常见的反射方式,反射方式就需要空参构造器。
UML类图:+ getName(id:int) : String
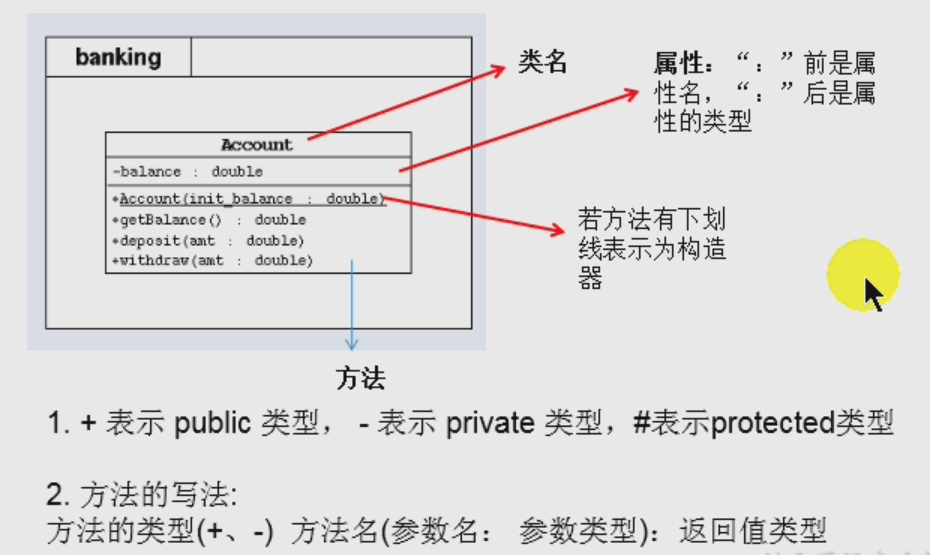
类的this关键字的使用场景:this.局部变量、this.方法、this(...)来简化重载构造
this(…)来简化重载构造器。默认构造器始终要调用的,只不过有时可省略它,所以重载构造器更像是对默认构造器的封装。 注: 构造器的首行必须是this()或this(…)或super()或super(…),如果没有显式给出,那么就隐式调用默认构造器this()或super()。
// 重载构造器不断复杂,可以使用this相互调用不同的构造器来简化。public class Stu(){public Stu(){}; // 默认构造器 等价于 this()。public Stu(String name){ // 构造器2// 该构造器没有显式给出this(...), 所以隐式调用了this()默认构造器。self.name = name;}public Stu(String name, int id){ // 构造器3this(name);self.id = id;}}
package关键字:包是对工程中类的管理。用目录结构去理解package。
举个例子: ```java // 要管理某java文件中的类, 可将该文件放在”com/xu/“目录下,并在该文件首行添加如下代码: package com.xu // 如此该文件中的类就被管理在“com.xu”包下了,便被其他文件所import。
// 其他代码
<a name="BIejB"></a>### - mvc的三种层次,从实现上就是特定的包名。<a name="yiUaM"></a>### import关键字。1.“`java.lang`包”和“当前包”无需import。2. 不同包下的同名类有import冲突。3. import static- 处理不同包的同名类的import冲突。(完整包路径的类名来显式导入)- import static 导入类或接口中静态结构。 注意:不是导入类,而是类中静态结构。举例:```javapackage com.xu;public class Math{public static double pi = 3.141592;public static double circular_area(double r){return pi * r * r;}}
⭐️⭐️继承Interitance: public class Stu extends Person{ ... } 、private情况、单\多层继承、java.lang.Object类
- ⭐️《Java编程思想》第129页说”继承不只是复制基类的接口,当创建了一个导出对象时,该对象包含了一个基类的子对象“。第137页说“组合和继承都允许在新的类中放置子类对象,组合是显式的这样做,而继承则是隐式的做”。依据《Java编程思想》所说,子类实例隐式地持有了一个基类实例,并且在子类实例中复制了基类接口(个人注:仅限非private的接口 ??),这样子类既可以调用自己声明的方法,又可以调用父类声明的方法们。
- 补充:
- 重写父类的方法:重写并不是说真正修改或覆盖了父类的方法,而是说子类调用自定义的同名同参方法而已。
- 子类不能直接访问父类的private方法和属性的原因并不特殊,就是private的权限仅在父类实例的内部而已。通过父类的set()get()封装方法,子类依然可以间接“使用”它们。
- 父类的实例先于子类创建。这点从子父类的构造器的使用先后顺序可说明。
- java.lang.Object 公共父类

方法的重写: 1. private方法不可被重写 2. static方法不是重写。
- 详细见继承。
- 子类实例的并没有复制父类实例的private接口(个人理解可能有误),所以谈不上被重写这一说法。
: 假如父类方法返回值类似为A类,那么子类重写方法的返回值类型为A类或A类的子类。(基本类型的话,那就必须一致了。)

super: 基类实例的本身。this.id和super.id有啥区别?、super调用构造器。
类继承后,this.id和super.id有啥区别?
答:this.id时,先在子类实例中找id属性,找不到再去父类实例中找id属性。super.id时,只在父类实例中找id属性。
结论:子类和父类的默认构造器“this()和super()”两者都要被调用一次,如此开辟了子类实例和父类实例的内存空间。至于重载的构造器,无非是封装了默认构造器。
1 子类对象的实例化过程
子类对象使用构造器来实例化时,调用super(…)\super()等方法间接实例化了父类对象,同理,父类对象间接实例化间接父类对象,直到实例化了Object对象为主。
注意:虽然实例化了许多对象,但是外部看来只是一个对象(因为只暴露了子类对象的指针)。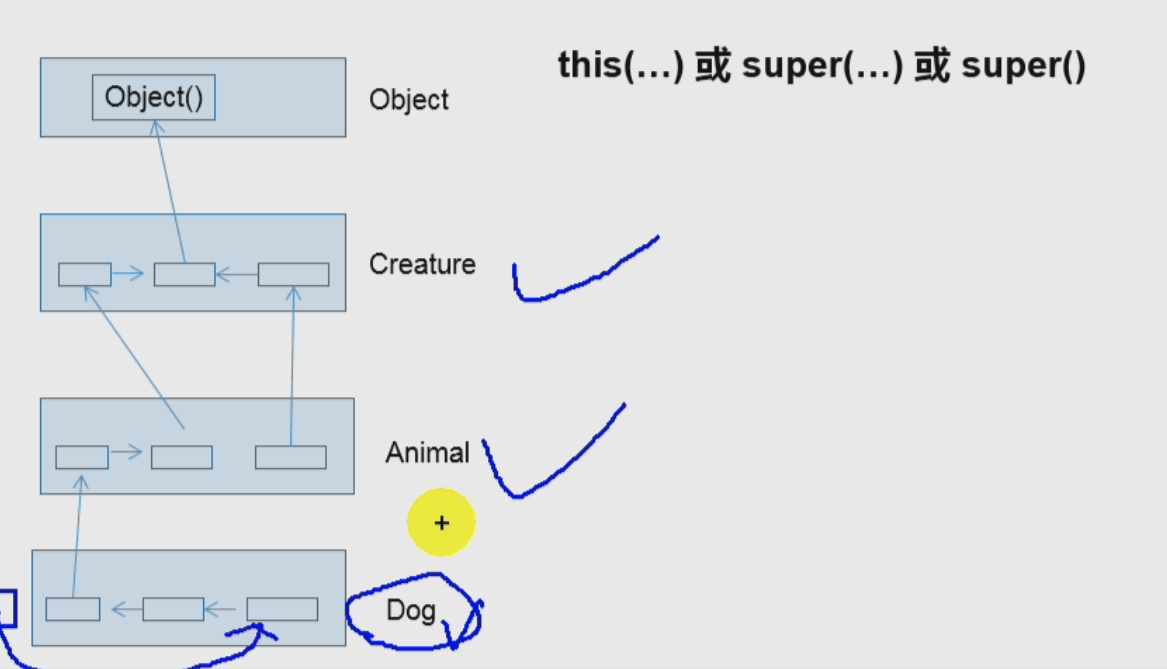
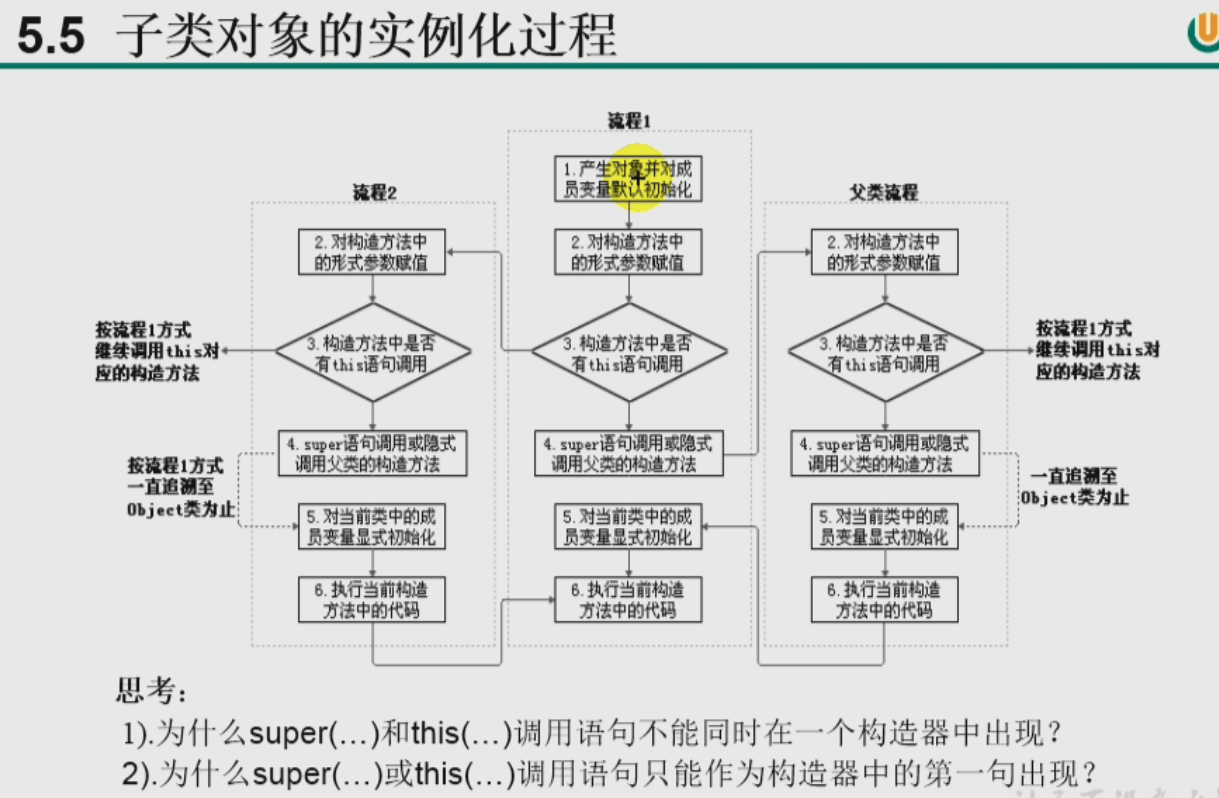

下面是this()和super()解释:
public class Man extends Person {public int id;// 默认构造。注意:下面三种构造是等价的, 不同程度上的省略。省略的前提是父类显式给出了默认构造器。// 第一种,省略所有默认构造器// 第二种,省略父类默认构造器public Man(){}// 第三种,显式地子父类默认构造器public Man(){super(); // 如果你要重载父类构造器的话,这里可以替换为super(10)等手段;}// 重载子类构造器,父类使用默认构造器public Man(int id){this(); // 这里面包括了super()this.id = id;}// 重载子类和父类构造器public Man(int id_child,int id_father){}}class Person{public int id;public Person(){};public Person(int id){this();this.id = id;};}
对象的多态性: 父类对象的多态性 = 子类重写父类方法 + 父类调用虚拟方法。

- 多态的好处(个人理解): 简单说:父类多态性 = 子类重写父类方法 + 父类调用虚拟方法。—— 子类重写父类的方法是实现多态的基础,如果再让父类能够去调用指定(动态的)子类重写后的方法(即父类调用虚拟方法),那么就实现了父类的多态性。
- 工程上讲多态易于API的维护和规范化。比如数据连接的例子,因为现实有mysql、sqlite等多种数据库,难道要为每个数据库都设计重载方法吗?并且不同数据库采用不同的API吗?其实不用,只要设计好的数据库该有的方法,具体地实现差异交给不同的子类们去重写这些方法,然后父类再使用子类重写好的方法即可。可见,数据库的例子中,多态机制可以允许规范的API,并屏蔽了不同子类的实现差异。:
- 核心内容
注意1: 多态的使用(虚拟方法的调用): 编译的时候调用了父类声明的方法,但是运行期,实际执行了子类重写父类的方法。 结论: 多态是运行时行为,而非编译时行为。如果说重载是静态绑定(早绑定),那么多态就是动态绑定(晚绑定)。

注意2: 多态性不适用属性。对于属性,调用的一定是父类的属性。


区分重载和重写: 从多态的角度

子类父类的类型转化: 子类对象向上转型(多态),父类对象向下转型
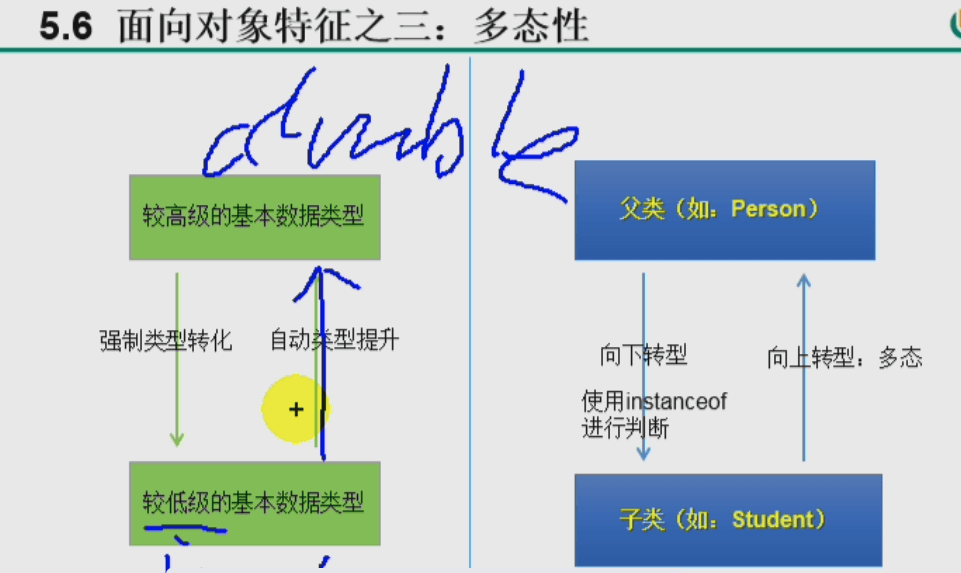
java.lang.Object类 : 所有类的基类,它有许多通用的方法(值得一看)。

== 与 类的equals()方法 : 重写、toString()同理
- “==”是比较值,对于基本数据类型时,可能发生类型转换比如,1.0 == 1是被允许比较的,答案为true.
- java.lang.Object类中的equals(obj){this == obj}就是用”==”来比较,只不过比较的是对象的地址值。
- 但在一些特别的类,比如String、Data,重写equals()。因为更希望比较的是实体内容,而非对象的地址值。
toString()方法也同理,java.lang.Object类中的toString()原本是”类名@jvm虚拟地址”的输出,但在String、Data子类中被重写为实体内容的输出。
代码案例: 构造器重载、重写toString和equals
package com.caffeflow.java;public class Person {public static void main(String[] args) {Person person = new Person(new String("xujia"), 27);Person person_2 = new Person(new String("quan"), 27);System.out.println(person.toString());System.out.println(person.equals(person_2));}private String name;private int age;private int weight;Person() { // 默认构造器};Person(String name, int age) {this(); // 调用默认构造器this.name = name;this.age = age;}Person(String name, int age, int weight) {this(name, age); // 调用其他构造器this.weight = weight;}@Overridepublic String toString() { // 重写toString为实体内容返回return "super:" + super.toString() + " this:" + this.name + " " + age;}@Overridepublic boolean equals(Object obj) { // 重写equals为实体内容比较if (this == obj) return true;if (obj instanceof Person) {Person p = (Person)obj; // 向下转型return p.age == this.age;}return false;}}
单元测试: import org.junit.Test @Test
注: 单元测试并非必须,且需要额外的包,可以暂时忽略。
第一步:确保在vscode中确保已经安装如下插件:
第二步:使用vscode创建一个java项目结构,并下载和导入包到java项目的referenced Libraries中。重启IDE。
从 https://github.com/junit-team/junit4/wiki/Download-and-Install 中下载如下两个文件:junit.jar、hamcrest-core.jar。
具体地,你可以手动将包放到lib目录中,然后确保settings.json中有如下阴影部分的配置项。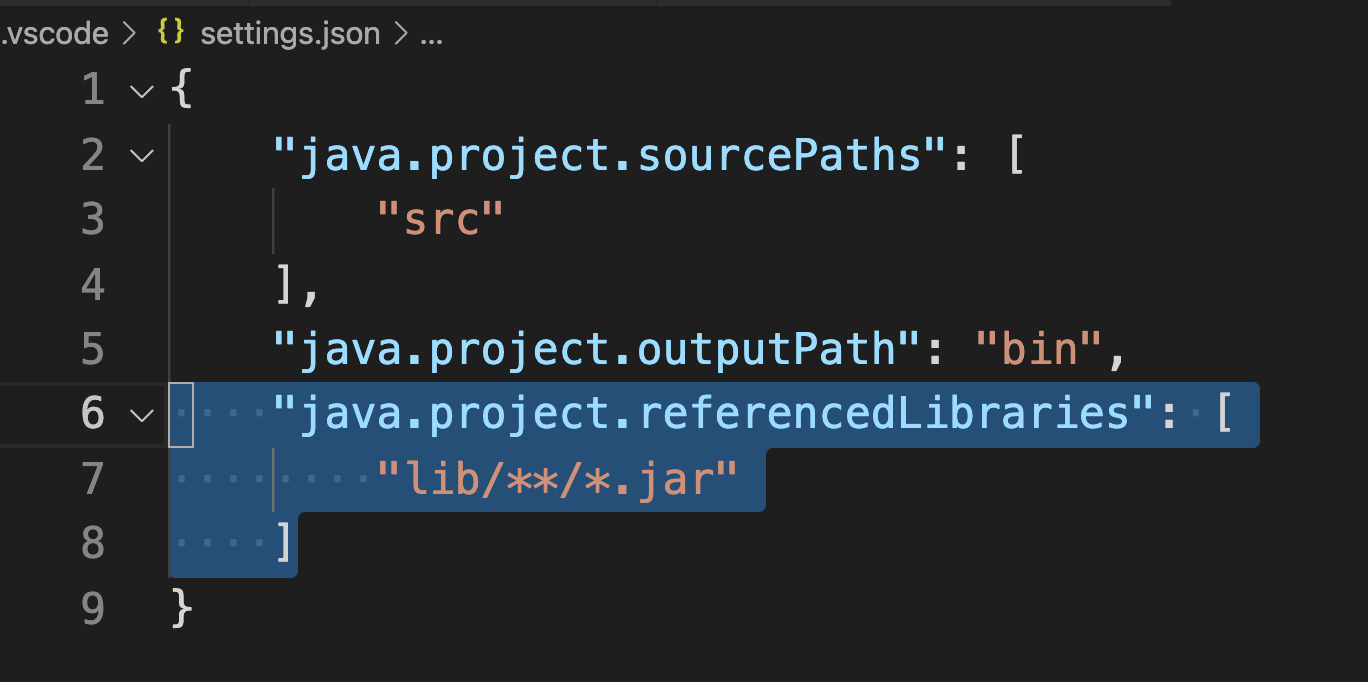
第三步:import org.junit.Test包,并对测试的方法上添加@Test。
单元测试: 如下代码,在vscode点击测试按钮,即可直接运行方法,而无需static main()方法。

包装类(对基本数据类型的包装): “基本数据类型、包装类与String类”的相互转换
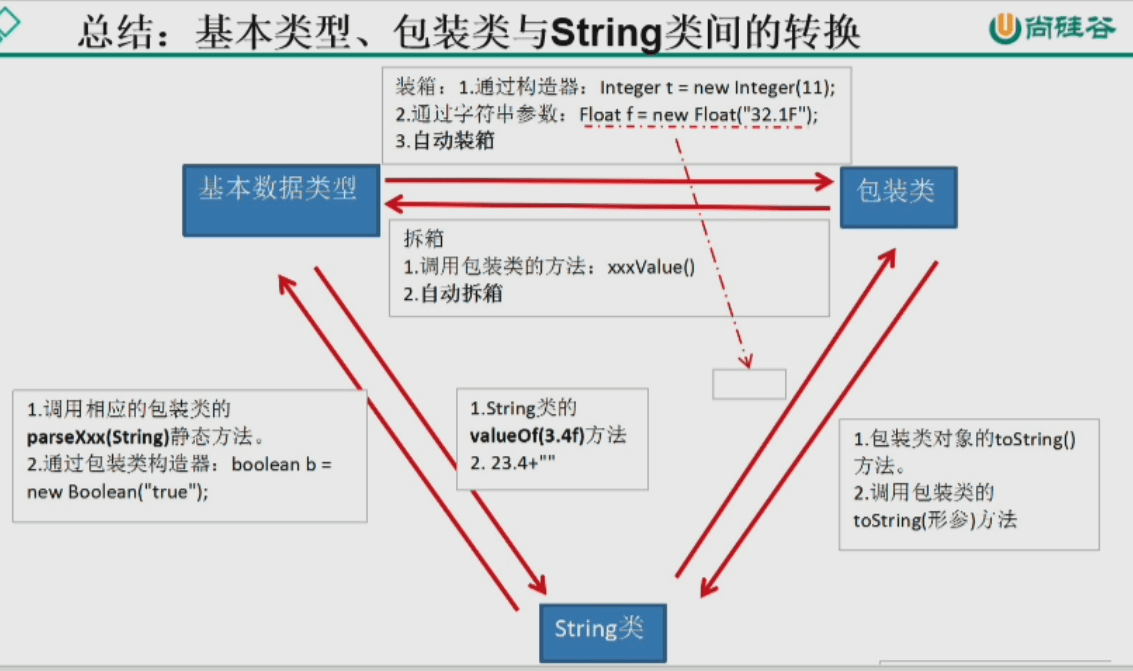
自动装箱和自动拆箱(jdk5特性): 简写Integer a = 1 <—> Integer a = new Integer(1). 另外,对形参赋值、函数返回等也有效。

- 自动装箱带来的好处
注意: java.util.Vector数组容器的addElement(Object obj)方法,只允许操作对象。
import java.util.Vector;Vector v = new Vector();int a = 1;// jdk5之前v.add(new Integer(a));// jdk5之后v.add(a) // 自动装箱

static关键字 : 生命周期角度理解、类变量
希望无论是否创建对象或创建多少对象,某些特定数据在内存中只有一份,它被所有实例所共享。
- 静态结构应该从生命周期的角度理解: 静态结构的生命周期同类本身,非静态结构的生命周期同实例本身。

- 静态变量(类变量)随着类加载而加载,存放在方法区的静态域中。换言之:静态变量的加载早于对象实例的创建。静态方法同理。 => 静态结构不可调用非静态结构(静态结构不可使用this或super关键字)。
- 什么时候声明为static? 比如Math.PI

单例设计模式:static实现
类的生命周期中只允许存在一个实例。场景举例: java.lang.runtime(运行时)、计数器、任务管理器、回收站、数据库连接池、
- 有种实现方式

// 懒汉式 (建议)class Order{private Order(){} // 关键1private static obj = null; // 关键2public static Order getObj(){ // 关键3if (obj == null)obj = new Order(); // 注意静态方法不可调用this关键字。return obj;}}// 饿汉class Order{private Order(){}; // 关键1private static obj = new Order(); // 关键2public static Order getObj(){ // 关键3return obj;}
类:代码块(初始化块): 只能用static修饰,即(非)静态代码块
- 代码块不可以调用,加载即执行。具体地,静态代码块,随着类而加载并执行;非静态代码块,随着实例的创建而加载并执行。
- 案例: JDBCUtils类。
- 注意1:静态结构不可以调用非静态结构。
- 注意2:调用顺序(与代码顺序无关):静态结构 > 非静态结构体 > 构造器 ```java public int a;
static { a = 1; } { a = 2; }
<a name="WB3Tx"></a>### 执行顺序: 任何静态结构类加载 > [非静态结构体 > 默认构造器 > 重载构造器]实例创建 。- 执行顺序:[父类静态结构体 > 子类静态结构体] ><br />[父类非静态结构体 > 父类类默认构造器 > 父类重载构造器] ><br />[子类非静态结构体 > 子类默认构造器 > 子类重载构造器]- 总结父类静态结构 > 子类静态结构 > 父类实例创建 > 子类实例创建<br />实例创建:非静态结构 > 默认构造器 > 重载构造器```javapackage com.caffeflow.java;public class son extends Father {public static void main(String[] args) {son obj = new son(1);}static {System.out.println("静态结构体");}{System.out.println("非静态结构体1");}public son() {super();System.out.println("默认构造器");}public son(int a) {this();System.out.println("重载构造器");}}class Father {public Father() {System.out.println("父类默认构造器");}public Father(int i) {System.out.println("父类重载构造器");}}
final关键字修饰:类->不可继承,方法->不可重写,变量->变为常量
变量分为:局部变量(方法内和形参)和属性
- “final 属性”的赋值方式: 显式初始化、结构体、构造器、重载构造的形参
- “final 局部变量”的赋值方式:显式初始化、方法的形参
static final: 仅可修饰属性和方法
- static final 属性: 全局常量 (注:接口中常量均是static final修饰)
- static final 方法
abstract关键字:有抽象方法的类一定要抽象类,反之抽象类不一定有抽象方法。
抽象类和抽象方法,必须要用abstract修饰。


abstract特殊用法:匿名子类
// 抽象类public abstract Person{public abstract eat();public abstract breath();}// 匿名子类对象。 注意:Person是抽象类。Person p = new Person(){@Overridepublic void eat(){};@Overridepublic void breath(){};}
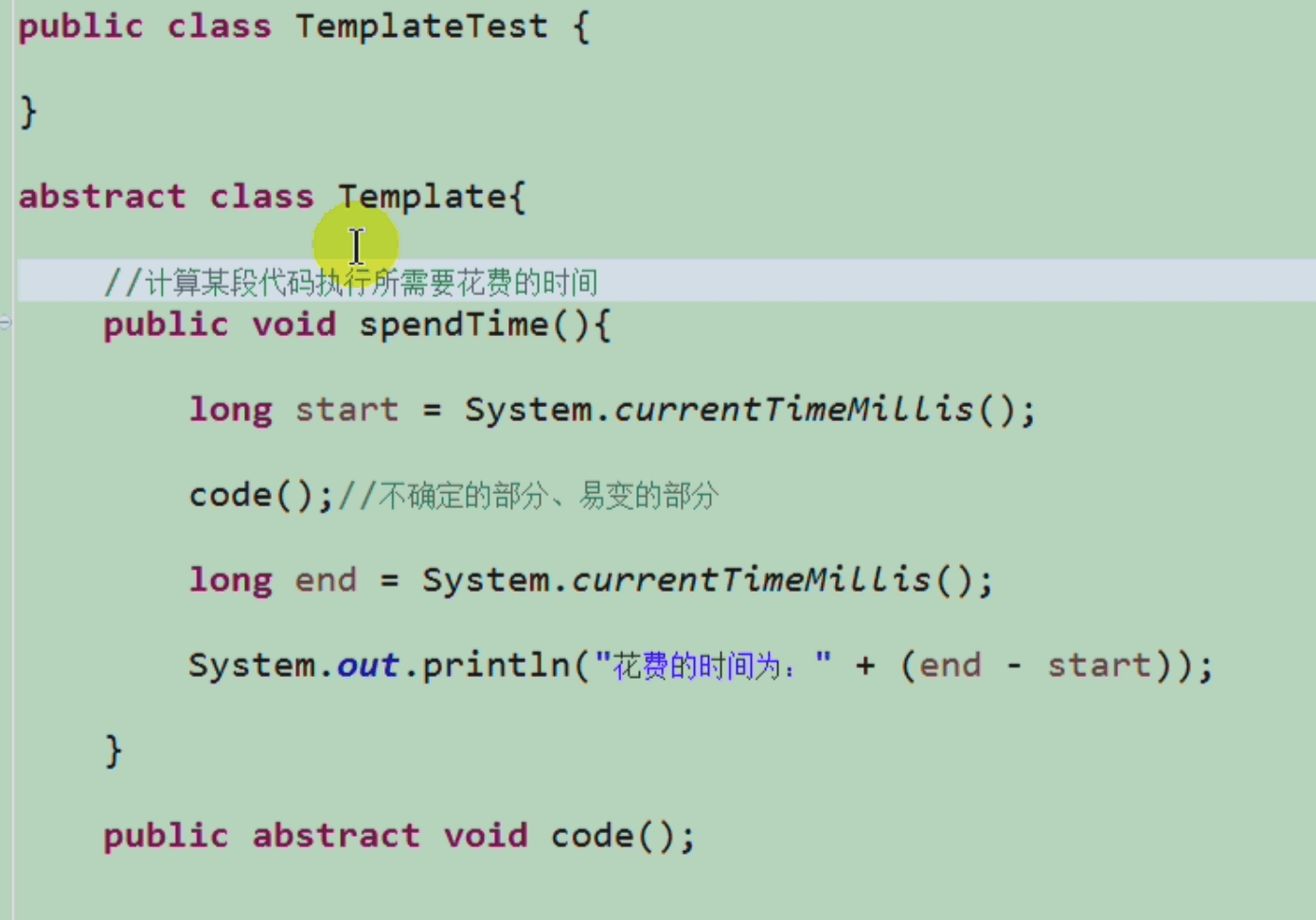
模版设计模式(TemplateMethod): abstract + 多态

- 举个例子:计算某段代码执行时间的类。由于具体代码不确定,所以讲具体代码以抽象方法的形式暴露给子类实现。 下面代码中,子类讲实现code()抽象方法。
接口: 规范标准、多重继承的效果。
- 接口: 接口是规范标准,而不是继承,但是可以实现(多)继承的效果。
- 区分类和接口:比如u盘不是移动硬盘(不是继承关系),但它们都有存储功能(但有相似功能)。



// 接口定义interfact A{public void fun1();public void fun2();}// 部分实现接口(抽象类)abstract class B implements A{public void fun1(){// 实现代码}}// 全部实现接口(类)class C implements A{public void fun1(){//实现代码}public void func2(){// 实现代码}}// 单继承与多继承接口的实现class CC{}interfact AA{}interfact BB{}class DD extends CC implements AA,BB{} //
接口有4种实现方式:(非)匿名实现类(非)匿名对象。注:和抽象方法如出一辙。
直接看下面代码即可了解“接口的匿名实现类及其匿名对象”
public class App {public static void main(String[] args) throws Exception {// 代码可以看见,我实现了Human接口,并且实例化了实现类,且调用了实现的接口。// 但是匿名了接口的实现类,且匿名了实例化对象的名称。new Human() {@Overridepublic void printName() {// TODO Auto-generated method stubSystem.out.println(name);}}.printName();}}interface Human {public String name = "xujia";public abstract void printName();}



接口的应用:代理模式、工厂模式
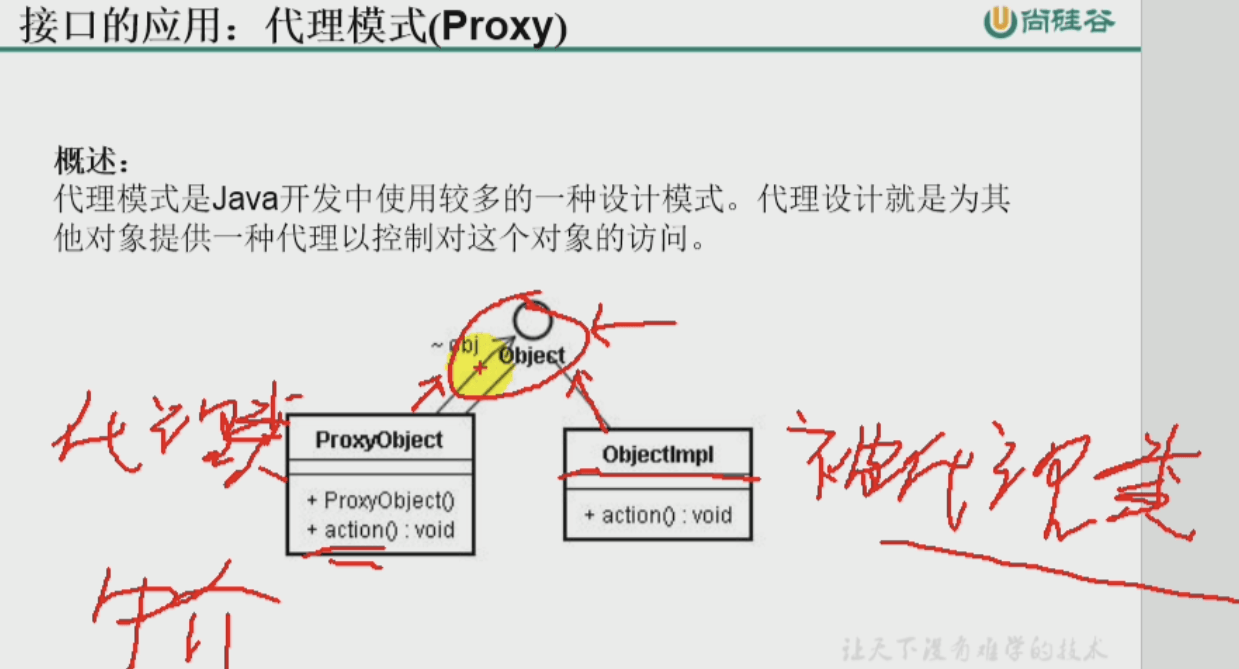

public class App {/*** 在下面代码中有:** 1. 网页数据类Page** 2. 浏览器核心接口(是被代理的)BrowserCore** 3. 浏览器核接口的实现类 BrowserCoreImpl** 4. 浏览器客户端类(作为浏览器核心的代理类)**/public static void main(String[] args) throws Exception {// 完成代理类的实例化BrowserClient browserClient = new BrowserClient(new BrowserCoreImpl());// 使用代理类来完成打开网页的操作String url = "www.baidu.com";browserClient.open_page(url);}}class Page {public String url;public Page() {url = "404";}public Page(String url) {this.url = url;}public Object getHtml() {return this.url + ":html文本";}public Object getVideo() {return this.url + ":视频文件";}}interface BrowserCore {abstract public void open_html(Page page);abstract public void open_video(Page page);}class BrowserCoreImpl implements BrowserCore {@Overridepublic void open_html(Page page) {// TODO Auto-generated method stubSystem.out.println("我是浏览器核心的实现类,已取回html数据,并打开:" + page.getHtml());}@Overridepublic void open_video(Page page) {// TODO Auto-generated method stubSystem.out.println("我是浏览器核心的实现类:已取回video数据,并打开:" + page.getVideo());}}class BrowserClient implements BrowserCore {// BrowserClient是BrowserCore的代理类private BrowserCore browserCore;public BrowserClient(BrowserCore browserCore) {this.browserCore = browserCore;}public boolean checkUrl(String url) {if (url != "404")return true;elsereturn false;}public void web_page_render() {System.out.println("我是浏览器客户端(代理类),我进行了网页渲染");}public void open_page(String url) {if (checkUrl(url)) { // 1. url检测System.out.println("我是浏览器客户端(代理类):url安全性检测通过");Page page = new Page(url); // 2. 拿到网页对象this.open_html(page); // 3.代理浏览器核心去打开html文件this.open_video(page); // 4. 同上,打开video文件this.web_page_render(); // 5. 进行了网页渲染} elseSystem.out.println("我是浏览器客户端(代理类):url安全性检测失败");}@Overridepublic void open_html(Page page) {this.browserCore.open_html(page);}@Overridepublic void open_video(Page page) {this.browserCore.open_video(page);}}


工厂: 专门造对象的东西,目的是想把创建者和调用者分离。 下面是无工厂的代码,Clent01类同时作为创建者和调用者。
下面是简单工厂的代码,Client02类只是调用者,创建者由CarFactory类全权负责。注意:这里CarFactory是类,而非接口。
简单工厂缺点:违反开闭原则,即对扩展开放,对修改封闭。 比如上面代码,如果要新增”宝马车”,那么必须要修改CarFactory类,即修改工厂角色中的判断语句。 下面是工厂方法模式,简单工厂的缺点是由于工厂类的原因,那么可以由工厂接口来代替工厂类,同样是新增“宝马车”的情况下,只需要写一个实现接口的类即可。

工厂模式同样有问题,还是违反了开闭原则,要么将接口类写死要么将接口的实现类写死。
其实可以真正实现了开闭原则。 原理:java的反射机制于配置文件的巧妙结合突破了这个限制—这在spring中体现的玲离尽致。

内部类(看懂即可,要求不高)

- 内部类的2种实例化情况。
App.A a = new App().new A()
App.B b = new App.B();
public class App {public static void main(String[] args) throws Exception {// 一般内部类实例化App app = new App();App.A a = app.new A(); // 或者A a = ...System.out.println(a.name);// 被static修饰的内部类的实例化App.B b = new App.B(); // 或者B b = ...System.out.println(b.name);}class A {public String name = "xiaomei";}static class B {public String name = "xiaoxu";}}
被内部类所使用的外部类的局部变量,必须要被 finnal 修饰。
如下代码中的int num即是被内部类所使用外部类的局部变量。
jdk7及之前必须显式写为final int num = 10,jdk8及之后省略final隐式写为int num = 10;
- 一种解释:
从int num的作用域上讲,的确覆盖了内部类,但是从字节码文件上讲,外部类和内部类分别有各自的字节码文件,即从生命周期上讲,int num出了外部类的方法体就结束了,但是内部类的生命周期却与外部类一样长。总结来讲,int num的作用域覆盖了内部类,但是int num的生命周期却比内部类短,于是乎,将num的副本传递给了内部类使用,而非num本身,且为了保证该副本与num的一致性,便使用了final int num,让num成为”常量“。
`
异常处理

- 编译时异常(或称受检异常) 、运行时异常


异常处理方式一:try-catch-finally : 1. 处理编译时异常、2. 注意异常类型的子父类关系、3. finally可选1,但存在则一定会被执行2 哪些语句需要放在finally中呢?3:见下。
finally存在则一定会被执行:
try-catch-finally中,首先执行try或者catch中的语句中的非return和throws部分,然后跳到finally中执行全部语句,最后再回到try或catch中去执行其return或throws部分(前提是finally中没有return等,否则直接退出)。
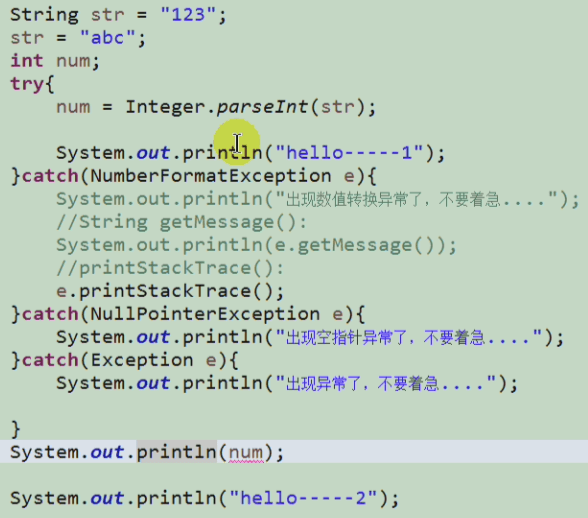
@Testpublic void test_test2() {System.out.println(test2());}public int test2() {try {System.out.println('a');return 1;} catch (Exception e) {System.out.println('b');return 2;} finally {System.out.println('c');return 3;}}
以上结果为: a c 3
@Testpublic void test_test2() {System.out.println(test2());}public int test2() {try {System.out.println('a');return 1;} catch (Exception e) {System.out.println('b');return 2;} finally {System.out.println('c');// return 3;}}
以上结果为:a c 1


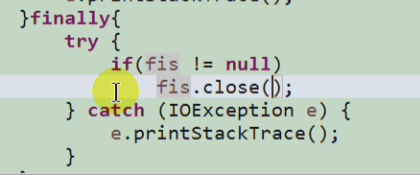
- finally:存在则必定执行 -比如: 资源关闭
异常方式二:throws + 异常类型、重写异常方法的规则、如何选择throws 或者 try-catch-finally ?
- thows + 异常类型
简单说:不自己处理异常,只是将异常抛给方法的调用者,你可以不断地抛,但是一般最多抛到main方法为止,最终使用try-catch-finally来真正处理异常。
- 重写异常方法的规则:
子类的异常类型 <= 父类的异常类型 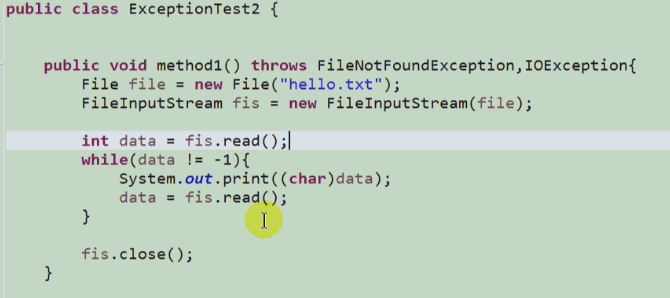

手动抛出异常:比如:throw new Exception(“输入错误”)
以下3个要点
import org.junit.Test;public class ExceptionTest {@Testpublic void test() {Student stu;// 要点3: 使用try-catch真正处理异常try {stu = new Student(-1);System.out.println(stu.id);} catch (Exception e) {System.out.print(e.getMessage());}}}class Student {public int id;// 要点2: 函数throws将异常继续往上抛public Student(int id) throws Exception {if (id < 0) {// 要点1: 手动抛出异常对象throw new Exception("ID不能为负数哦");}this.id = id;}}
自定义异常类
class MyException extends Exception {static final long serialVersionUID = -3387511111124229948L;public MyException() {}public MyException(String msg) {super(msg);}}
异常综合练习与总结
对一个除法操作进行异常处理
package 异常;import org.junit.Test;public class Exce {@Testpublic void test_div() {String[] ss = new String[] { "4","-1"};div(ss);}public void div(String[] args) {try {int a = Integer.parseInt(args[0]);int b = Integer.parseInt(args[1]);int res = ecm(a, b);System.out.print(res);} catch (ArrayIndexOutOfBoundsException e) {System.out.println("缺少参数");} catch (NumberFormatException e) {System.out.println("数据类型不一致");} catch (ArithmeticException e) {System.out.println("除0");} catch (EcDefException e) {System.out.println(e.getMessage());}}public int ecm(int a, int b) throws EcDefException {if (a < 0 || b < 0)throw new EcDefException("分子或分母为负");return a / b;}}class EcDefException extends Exception {// 自定义异常类static final long serialVersionUID = -338751699329948L;public EcDefException() {};public EcDefException(String msg) {super(msg);}}

一些面试题


若有收获,就点个赞吧
0 人点赞
