- 计算器相关题目
- 栈
- ">

- 队列
- 253. 会议室 II">253. 会议室 II
- 239. 滑动窗口最大值">239. 滑动窗口最大值
- 215. 数组中的第K个最大元素">215. 数组中的第K个最大元素
- 264. 丑数 II">264. 丑数 II
- 347. 前 K 个高频元素">347. 前 K 个高频元素
- 373. 查找和最小的K对数字">373. 查找和最小的K对数字
- 面试题 17.14. 最小K个数">面试题 17.14. 最小K个数
- 378. 有序矩阵中第 K 小的元素">378. 有序矩阵中第 K 小的元素
- 451. 根据字符出现频率排序">451. 根据字符出现频率排序
- 621. 任务调度器">621. 任务调度器
- 506. 相对名次">506. 相对名次
- 1046. 最后一块石头的重量">1046. 最后一块石头的重量
- 1337. 矩阵中战斗力最弱的 K 行">1337. 矩阵中战斗力最弱的 K 行
- 1464. 数组中两元素的最大乘积">1464. 数组中两元素的最大乘积
- 2099. 找到和最大的长度为 K 的子序列">2099. 找到和最大的长度为 K 的子序列
- 649. Dota2 参议院">649. Dota2 参议院
- 373. 查找和最小的 K 对数字">373. 查找和最小的 K 对数字
计算器相关题目
模板
面试题 16.26. 计算器
栈
- 判断栈中放入的是索引还是具体的值
- 判断栈中是不是需要用 -1 或者其他的值进行补位 ( 有效长度 = 当前索引-出栈的索引+1 改变为 当前索引 - 出栈后新的栈顶索引 题解)
- 判断栈顶与当前遍历的值的对比,进行下一步操作
- 遍历是从前往后遍历,还是从后往前遍历[
](https://leetcode-cn.com/problems/calculator-lcci/)
单调栈模板

496. 下一个更大元素 I
给你两个 没有重复元素 的数组 nums1 和 nums2 ,其中nums1 是 nums2 的子集。
请你找出 nums1 中每个元素在 nums2 中的下一个比其大的值。
nums1 中数字 x 的下一个更大元素是指 x 在 nums2 中对应位置的右边的第一个比 x 大的元素。如果不存在,对应位置输出 -1 。
示例 1:
输入: nums1 = [4,1,2], nums2 = [1,3,4,2]. 输出: [-1,3,-1] 解释: 对于 num1 中的数字 4 ,你无法在第二个数组中找到下一个更大的数字,因此输出 -1 。 对于 num1 中的数字 1 ,第二个数组中数字1右边的下一个较大数字是 3 。 对于 num1 中的数字 2 ,第二个数组中没有下一个更大的数字,因此输出 -1 。
示例 2:
输入: nums1 = [2,4], nums2 = [1,2,3,4]. 输出: [3,-1] 解释: 对于 num1 中的数字 2 ,第二个数组中的下一个较大数字是 3 。 对于 num1 中的数字 4 ,第二个数组中没有下一个更大的数字,因此输出 -1 。
提示:
- 1 <= nums1.length <= nums2.length <= 1000
- 0 <= nums1[i], nums2[i] <= 104
- nums1和nums2中所有整数 互不相同
- nums1 中的所有整数同样出现在 nums2 中
进阶:你可以设计一个时间复杂度为 O(nums1.length + nums2.length) 的解决方案吗?
class Solution:def nextGreaterElement(self, nums1: List[int], nums2: List[int]) -> List[int]:stack = []next_big = {} # 元素 : 下一个更大的数字的位置for i in range(len(nums2) - 1, -1, -1):while stack and nums2[i] >= stack[-1]:stack.pop(-1)if not stack:next_big[nums2[i]] = -1else:next_big[nums2[i]] = stack[-1]stack.append(nums2[i])res = []for i in range(len(nums1)):if nums1[i] in next_big:res.append(next_big[nums1[i]])return res
503. 下一个更大元素 II
给定一个循环数组(最后一个元素的下一个元素是数组的第一个元素),输出每个元素的下一个更大元素。数字 x 的下一个更大的元素是按数组遍历顺序,这个数字之后的第一个比它更大的数,这意味着你应该循环地搜索它的下一个更大的数。如果不存在,则输出 -1。
示例 1:
输入: [1,2,1] 输出: [2,-1,2] 解释: 第一个 1 的下一个更大的数是 2; 数字 2 找不到下一个更大的数; 第二个 1 的下一个最大的数需要循环搜索,结果也是 2。
注意: 输入数组的长度不会超过 10000。

1019. 链表中的下一个更大节点
给出一个以头节点 head 作为第一个节点的链表。链表中的节点分别编号为:node1, node_2, node_3, … 。
每个节点都可能有下一个更大值(_next largervalue):对于 nodei,如果其 next_larger(node_i) 是 node_j.val,那么就有 j > i 且 node_j.val > node_i.val,而 j 是可能的选项中最小的那个。如果不存在这样的 j,那么下一个更大值为 0 。
返回整数答案数组 answer,其中 answer[i] = next_larger(node{i+1}) 。
注意:在下面的示例中,诸如 [2,1,5] 这样的输入(不是输出)是链表的序列化表示,其头节点的值为 2,第二个节点值为 1,第三个节点值为 5 。
示例 1:
输入:[2,1,5] 输出:[5,5,0]
示例 2:
输入:[2,7,4,3,5] 输出:[7,0,5,5,0]
示例 3:
输入:[1,7,5,1,9,2,5,1] 输出:[7,9,9,9,0,5,0,0]
提示:
- 对于链表中的每个节点,1 <= node.val <= 10^9
- 给定列表的长度在 [0, 10000] 范围内
739. 每日温度
请根据每日 气温 列表 temperatures ,请计算在每一天需要等几天才会有更高的温度。如果气温在这之后都不会升高,请在该位置用 0 来代替。
示例 1:
输入: temperatures = [73,74,75,71,69,72,76,73] 输出: [1,1,4,2,1,1,0,0]
示例 2:
输入: temperatures = [30,40,50,60] 输出: [1,1,1,0]
示例 3:
输入: temperatures = [30,60,90] 输出: [1,1,0]
提示:
- 1 <= temperatures.length <= 105
- 30 <= temperatures[i] <= 100
通过次数209,454
提交次数308,299
从后往前遍历
class Solution:
def dailyTemperatures(self, temperatures: List[int]) -> List[int]:
stack = []
res = []
for i in range(len(temperatures) - 1, -1, -1):
while stack and temperatures[stack[-1]] <= temperatures[i]:
stack.pop(-1)
if not stack:
res.append(0)
else:
res.append(stack[-1] -i)
stack.append(i)
return res[::-1]
316. 去除重复字母
给你一个字符串 s ,请你去除字符串中重复的字母,使得每个字母只出现一次。需保证 返回结果的字典序最小(要求不能打乱其他字符的相对位置)。
注意:该题与 1081 https://leetcode-cn.com/problems/smallest-subsequence-of-distinct-characters 相同
示例 1:
输入:s = “bcabc” 输出:“abc”
示例 2:
输入:s = “cbacdcbc” 输出:“acdb”
提示:
- 1 <= s.length <= 104
- s 由小写英文字母组成
通过次数66,874
提交次数140,213
402. 移掉 K 位数字
给你一个以字符串表示的非负整数 num 和一个整数 k ,移除这个数中的 k位数字,使得剩下的数字最小。请你以字符串形式返回这个最小的数字。
示例 1 :
输入:num = “1432219”, k = 3 输出:“1219” 解释:移除掉三个数字 4, 3, 和 2 形成一个新的最小的数字 1219 。
示例 2 :
输入:num = “10200”, k = 1 输出:“200” 解释:移掉首位的 1 剩下的数字为 200. 注意输出不能有任何前导零。
示例 3 :
输入:num = “10”, k = 2 输出:“0” 解释:从原数字移除所有的数字,剩余为空就是 0 。
提示:
- 1 <= k <= num.length <= 105
- num 仅由若干位数字(0 - 9)组成
- 除了 0 本身之外,num 不含任何前导零
通过次数80,036
提交次数244,544
class Solution:
def removeKdigits(self, num: str, k: int) -> str:
if len(num) <= k:
return "0"
stack = []
remain = len(num) - k
for idx, n in enumerate(num):
while stack and n < stack[-1] and k > 0:
stack.pop(-1)
k -= 1
stack.append(n)
return ''.join(stack[:remain]).lstrip('0') or '0'
84. 柱状图中最大的矩形
给定 n 个非负整数,用来表示柱状图中各个柱子的高度。每个柱子彼此相邻,且宽度为 1 。
求在该柱状图中,能够勾勒出来的矩形的最大面积。
示例 1: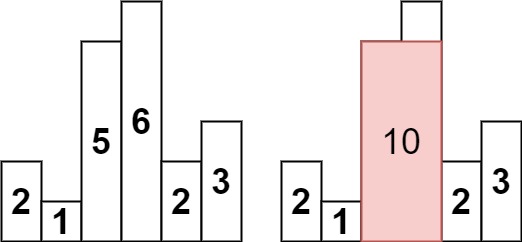
输入:heights = [2,1,5,6,2,3] 输出:10 解释:最大的矩形为图中红色区域,面积为 10
示例 2: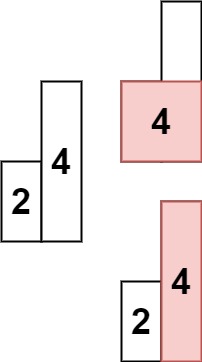
输入: heights = [2,4] 输出: 4
提示:
- 1 <= heights.length <=105
- 0 <= heights[i] <= 104
通过次数182,260
提交次数420,639
42. 接雨水
给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。
示例 1:
输入:height = [0,1,0,2,1,0,1,3,2,1,2,1] 输出:6 解释:上面是由数组 [0,1,0,2,1,0,1,3,2,1,2,1] 表示的高度图,在这种情况下,可以接 6 个单位的雨水(蓝色部分表示雨水)。
示例 2:
输入:height = [4,2,0,3,2,5] 输出:9
提示:
- n == height.length
- 0 <= n <= 3 * 104
- 0 <= height[i] <= 105
通过次数323,436
提交次数557,776
https://qingfengpython.cn/#/markdown/Algorithm/%E6%A0%88/42.%E6%8E%A5%E9%9B%A8%E6%B0%B4
class Solution:
def trap(self, height: List[int]) -> int:
res = 0
stack = []
for idx, num in enumerate(height):
while stack and height[stack[-1]] < num:
low = height[stack.pop()]
if not stack: break
high = min(height[stack[-1]], num) - low
width = idx - stack[-1] - 1
res += high * width
stack.append(idx)
return res
735. 行星碰撞
给定一个整数数组 asteroids,表示在同一行的行星。
对于数组中的每一个元素,其绝对值表示行星的大小,正负表示行星的移动方向(正表示向右移动,负表示向左移动)。每一颗行星以相同的速度移动。
找出碰撞后剩下的所有行星。碰撞规则:两个行星相互碰撞,较小的行星会爆炸。如果两颗行星大小相同,则两颗行星都会爆炸。两颗移动方向相同的行星,永远不会发生碰撞。
示例 1:
输入:asteroids = [5,10,-5] 输出:[5,10] 解释:10 和 -5 碰撞后只剩下 10 。 5 和 10 永远不会发生碰撞。
示例 2:
输入:asteroids = [8,-8] 输出:[] 解释:8 和 -8 碰撞后,两者都发生爆炸。
示例 3:
输入:asteroids = [10,2,-5] 输出:[10] 解释:2 和 -5 发生碰撞后剩下 -5 。10 和 -5 发生碰撞后剩下 10 。
示例 4:
输入:asteroids = [-2,-1,1,2] 输出:[-2,-1,1,2] 解释:-2 和 -1 向左移动,而 1 和 2 向右移动。 由于移动方向相同的行星不会发生碰撞,所以最终没有行星发生碰撞。
提示:
- 2 <= asteroids.length <= 104
- -1000 <= asteroids[i] <= 1000
- asteroids[i] != 0
直观解法,利用单调栈,首先判断是否碰撞
- 如果碰撞,
- 判断栈顶元素是否大于当前元素,如果大,则直接循环下一个元素
- 如果小于,则判断
- 栈顶和当前元素是否相等,如果相等,则弹出栈顶,循环下一个元素
- 栈顶小于当前元素,则栈顶不断弹出,知道栈顶元素大于当前元素,或者栈为空
- 不碰,则直接放入栈中
class Solution { public int[] asteroidCollision(int[] asteroids) { Stack<Integer> stack = new Stack(); for (int i = 0; i < asteroids.length; i++) { boolean flag = true; while (!stack.isEmpty() && asteroids[i] <0 && stack.peek() > 0) { if (stack.peek() == -asteroids[i]) { stack.pop(); flag = false; break; } if (stack.peek() < -asteroids[i]) { stack.pop(); } else { flag = false; break; } } if (flag) { stack.push(asteroids[i]); } } int[] res = new int[stack.size()]; for(int i = res.length - 1; i >=0; --i) { res[i] = stack.pop(); } return res; } }
优化的写法
class Solution {
public int[] asteroidCollision(int[] asteroids) {
Stack<Integer> s = new Stack<>();
int p = 0;
while (p < asteroids.length) {
if (s.empty() || s.peek() < 0 || asteroids[p] > 0) { // 先找出一定放入栈的情况
s.push(asteroids[p]);
} else if (s.peek() <= -asteroids[p]) { // 再判断栈顶小于当前时
if (s.pop() < -asteroids[p]) {
continue; // 如果栈顶小于当前元素, continue while循环,省略掉flag的作用
}
}
p++;
}
int[] ret = new int[s.size()];
for (int i = ret.length - 1; i >= 0; i--) {
ret[i] = s.pop();
}
return ret;
}
}
作者:qingfengpython
链接:https://leetcode-cn.com/problems/asteroid-collision/solution/735xing-xing-peng-zhuang-ji-yu-zhan-qu-f-xpd1/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
class Solution:
def asteroidCollision(self, asteroids: List[int]) -> List[int]:
stack = []
for i in range(len(asteroids)):
cur = asteroids[i]
flag = True # 当代表当前的星球是不是需要放入栈
while stack and 0 < stack[-1] and cur < 0:
if stack[-1] == -cur: # 同向且速度相等
stack.pop(-1)
flag = False
break
elif stack[-1] < -cur: # 同向且右边速度大,则一直弹出左边的星球
stack.pop(-1)
else : # 同向且左边的星球大,则跳过当前星球
flag = False
break
if flag:
stack.append(asteroids[i])
return stack
32. 最长有效括号
给你一个只包含 ‘(‘ 和 ‘)’ 的字符串,找出最长有效(格式正确且连续)括号子串的长度。
示例 1:
输入:s = “(()” 输出:2 解释:最长有效括号子串是 “()”
示例 2:
输入:s = “)()())” 输出:4 解释:最长有效括号子串是 “()()”
示例 3:
输入:s = “” 输出:0
提示:
- 0 <= s.length <= 3 * 104
- s[i] 为 ‘(‘ 或 ‘)’
反推法, leetcode题解
栈中放入的是不能构成有效的括号的位置, 弹出的是能构成有效括号的栈顶,同时计算当前长度
class Solution:
def longestValidParentheses(self, s: str) -> int:
stack = [] # 将不会组成有效字符串的括号放入到栈里, 栈中放入是索引
res = 0
for idx, ch in enumerate(s):
# 判断不会组成有效括号的ch
if not stack or s[stack[-1]] == ')' or ch == '(':
stack.append(idx)
else:
stack.pop() # 此时放入的肯定是 ')' ,且能与栈顶构成有效字符串
if not stack:
res = max(res, idx + 1) # 如果栈弹出后为空,则说明上一步只匹配到了 () , 长度为2
else:
res = max(res, idx - stack[-1])
return res
使用哨兵节点, 预先放置-1到栈中
题解
const longestValidParentheses = (s) => {
let maxLen = 0;
const stack = [];
stack.push(-1);
for (let i = 0; i < s.length; i++) {
const c = s[i];
if (c == '(') { // 左括号的索引,入栈
stack.push(i);
} else { // 遍历到右括号
stack.pop(); // 栈顶的左括号被匹配,出栈
if (stack.length) { // 栈未空
const curMaxLen = i - stack[stack.length - 1]; // 计算有效连续长度
maxLen = Math.max(maxLen, curMaxLen); // 挑战最大值
} else { // 栈空了
stack.push(i); // 入栈充当参照
}
}
}
return maxLen;
};
作者:xiao_ben_zhu
链接:https://leetcode-cn.com/problems/longest-valid-parentheses/solution/shou-hua-tu-jie-zhan-de-xiang-xi-si-lu-by-hyj8/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
1996. 游戏中弱角色的数量
你正在参加一个多角色游戏,每个角色都有两个主要属性:攻击 和 防御 。给你一个二维整数数组 properties ,其中 properties[i] = [attacki, defensei] 表示游戏中第 i 个角色的属性。
如果存在一个其他角色的攻击和防御等级 都严格高于 该角色的攻击和防御等级,则认为该角色为 弱角色 。更正式地,如果认为角色 i弱于 存在的另一个角色 j ,那么 attackj > attacki 且 defensej > defensei 。
返回 弱角色 的数量。
示例 1:
输入:properties = [[5,5],[6,3],[3,6]] 输出:0 解释:不存在攻击和防御都严格高于其他角色的角色。
示例 2:
输入:properties = [[2,2],[3,3]] 输出:1 解释:第一个角色是弱角色,因为第二个角色的攻击和防御严格大于该角色。
示例 3:
输入:properties = [[1,5],[10,4],[4,3]] 输出:1 解释:第三个角色是弱角色,因为第二个角色的攻击和防御严格大于该角色。
提示:
- 2 <= properties.length <= 105
- properties[i].length == 2
- 1 <= attacki, defensei <= 105
错误的答案
错误点:
- 按照攻击力从小到大排序,有可能相等, 比如[1,1],[1,2]
- 按照攻击力从小到大排序, 防御力大, 可能需要跟之前的数组比 [[1, 1], [1, 2], [2, 1], [2, 2]]
properties = [[1,1],[2,1],[2,2],[1,2]]
properties.sort()
def numberOfWeakCharacters(properties) -> int:
properties.sort()
print(properties)
stack = []
res = 0
for i in range(0, len(properties)):
while stack and properties[i][1] > properties[stack[-1]][1]:
if properties[i][0] != properties[stack[-1]][0]:
res += 1
stack.pop(-1)
stack.append(i)
print(res +len(stack))
return res
numberOfWeakCharacters(properties)
[[1, 1], [1, 2], [2, 1], [2, 2]]
2
正确答案
package 数组;
import java.util.Arrays;
import java.util.Comparator;
import java.util.function.IntPredicate;
public class _5864_游戏中弱角色的数量 {
public int numberOfWeakCharacters(int[][] properties) {
// 先排序
Arrays.sort(properties,new Comparator<int[]>() {
public int compare(int[] o1,int[] o2) {
// 我们按照攻击多少进行排序,谁越小排在前面
if (o1[0]!=o2[0]) {
return o1[0]-o2[0];
}
// 否则两个数相等就根据防御排名,谁越大就排在前面
else {
return o2[1]-o1[1];
}
}
});
for(int i=0;i<properties.length;i++) {
System.out.print(properties[i][0]+","+properties[i][1]+"_");
}
// 获取长度
int len=properties.length;
// 弱对手数量
int people=0;
// for循环遍历数组,由于已经排序好了,我们只要比较防御的大小就可以知道前面的数是不是弱角色
for(int i=len-1;i>=0;i--) {//这里从后往前遍历,因为要获取最大的防御值
int[] left=properties[i];
// 定义一个defense,为了获取右边的最大防御值
int defense=-1;
// 如果右边的防御值大于左边的防御值,那么左边肯定是弱对手
if (defense>left[1]) {
people++;
}
// 然后获取右边最大防御值
defense=Math.max(defense, left[1]);
}
return people;
}
}
作者:RodmaChen
链接:https://leetcode-cn.com/problems/the-number-of-weak-characters-in-the-game/solution/leetcodeshua-ti-100tian-5864-you-xi-zhon-4dvd/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
173. 二叉搜索树迭代器
实现一个二叉搜索树迭代器类BSTIterator ,表示一个按中序遍历二叉搜索树(BST)的迭代器:
- BSTIterator(TreeNode root) 初始化 BSTIterator 类的一个对象。BST 的根节点 root 会作为构造函数的一部分给出。指针应初始化为一个不存在于 BST 中的数字,且该数字小于 BST 中的任何元素。
- boolean hasNext() 如果向指针右侧遍历存在数字,则返回 true ;否则返回 false 。
- int next()将指针向右移动,然后返回指针处的数字。
注意,指针初始化为一个不存在于 BST 中的数字,所以对 next() 的首次调用将返回 BST 中的最小元素。
你可以假设 next() 调用总是有效的,也就是说,当调用 next() 时,BST 的中序遍历中至少存在一个下一个数字。
示例:
输入 [“BSTIterator”, “next”, “next”, “hasNext”, “next”, “hasNext”, “next”, “hasNext”, “next”, “hasNext”] [[[7, 3, 15, null, null, 9, 20]], [], [], [], [], [], [], [], [], []] 输出 [null, 3, 7, true, 9, true, 15, true, 20, false] 解释 BSTIterator bSTIterator = new BSTIterator([7, 3, 15, null, null, 9, 20]); bSTIterator.next(); // 返回 3 bSTIterator.next(); // 返回 7 bSTIterator.hasNext(); // 返回 True bSTIterator.next(); // 返回 9 bSTIterator.hasNext(); // 返回 True bSTIterator.next(); // 返回 15 bSTIterator.hasNext(); // 返回 True bSTIterator.next(); // 返回 20 bSTIterator.hasNext(); // 返回 False
提示:
- 树中节点的数目在范围 [1, 105] 内
- 0 <= Node.val <= 106
- 最多调用 105 次 hasNext 和 next 操作
先提前保存全部的节点,然后再用数组地方法写
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
import collections
class BSTIterator:
def __init__(self, root: TreeNode):
self.queue = collections.deque()
self.in_order(root)
def in_order(self, root):
if not root: return
self.in_order(root.left)
self.queue.append(root.val)
self.in_order(root.right)
def next(self) -> int:
return self.queue.popleft()
def hasNext(self) -> bool:
return len(self.queue) > 0
# Your BSTIterator object will be instantiated and called as such:
# obj = BSTIterator(root)
# param_1 = obj.next()
# param_2 = obj.hasNext()
迭代时计算 next 节点
在前几天的设计迭代器的每日一题中,我说过提前把所有的值遍历并且保存起来的做法并不好,不是面试官想要的。举个场景:想通过 BST 的迭代器,判断 BST 中有没有 数值x。此时哪怕 数值x 是 BST 迭代器的第一个元素,上面的方法也会先把所有的值都遍历出来,时间复杂度到了O(N)O(N)O(N)。
所以,设计迭代器的时候,应避免提前把所有的值都遍历出来;最好能设计成遍历过程中求 next 节点。那就需要用迭代方法了。
把递归转成迭代,基本想法就是用栈。 迭代总体思路是:栈中只保留左节点。思路必须从递归的访问顺序说起:中序遍历的访问顺序是 左子树 -> 根节点 -> 右子树 的顺序,并且对 左子树 和 右子树 也进行递归。
结合下图,实际访问节点的顺序是:
从 根节点12 开始一路到底遍历到所有左节点,路径保存到栈中;此时栈为 [12, 6, 5]。 弹出栈顶节点,即 叶子节点5 ; 下一个栈顶元素是 该叶子节点 的 根节点6; 然后把 该新的根节点的右子树9 一路到底遍历其所有左节点;栈为 [12, 9, 8, 7]。 继续运行下去,直到栈为空。中序遍历流程如下图所示:
发现了没有?这就是一个「单调栈」啊!
根据上面的遍历顺序,我们得出迭代的思路:
构造方法:一路到底,把根节点和它的所有左节点放到栈中; 调用 next() 方法:弹出栈顶的节点; 如果它有右子树,则对右子树一路到底,把它和它的所有左节点放到栈中。作者:fuxuemingzhu 链接:https://leetcode-cn.com/problems/binary-search-tree-iterator/solution/fu-xue-ming-zhu-dan-diao-zhan-die-dai-la-dkrm/ 来源:力扣(LeetCode) 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class BSTIterator:
def __init__(self, root: TreeNode):
self.stack = []
while root:
self.stack.append(root)
root = root.left
def next(self) -> int:
cur = self.stack.pop(-1)
root = cur.right
while root:
self.stack.append(root)
root = root.left
return cur.val
def hasNext(self) -> bool:
return len(self.stack) > 0
# Your BSTIterator object will be instantiated and called as such:
# obj = BSTIterator(root)
# param_1 = obj.next()
# param_2 = obj.hasNext()
150. 逆波兰表达式求值
根据逆波兰表示法,求表达式的值。
有效的算符包括 +、-、*、/ 。每个运算对象可以是整数,也可以是另一个逆波兰表达式。
说明:
- 整数除法只保留整数部分。
- 给定逆波兰表达式总是有效的。换句话说,表达式总会得出有效数值且不存在除数为 0 的情况。
示例 1:
输入:tokens = [“2”,”1”,”+”,”3”,”“] 输出:9 解释:该算式转化为常见的中缀算术表达式为:((2 + 1) 3) = 9
示例 2:
输入:tokens = [“4”,”13”,”5”,”/“,”+”] 输出:6 解释:该算式转化为常见的中缀算术表达式为:(4 + (13 / 5)) = 6
示例 3:
输入:tokens = [“10”,”6”,”9”,”3”,”+”,”-11”,”“,”/“,”“,”17”,”+”,”5”,”+”] 输出:22 解释: 该算式转化为常见的中缀算术表达式为: ((10 (6 / ((9 + 3) -11))) + 17) + 5 = ((10 (6 / (12 -11))) + 17) + 5 = ((10 (6 / -132)) + 17) + 5 = ((10 0) + 17) + 5 = (0 + 17) + 5 = 17 + 5 = 22
提示:
- 1 <= tokens.length <= 104
- tokens[i] 要么是一个算符(”+”、”-“、”*” 或 “/“),要么是一个在范围 [-200, 200] 内的整数
逆波兰表达式:
逆波兰表达式是一种后缀表达式,所谓后缀就是指算符写在后面。
- 平常使用的算式则是一种中缀表达式,如 ( 1 + 2 ) * ( 3 + 4 ) 。
- 该算式的逆波兰表达式写法为 ( ( 1 2 + ) ( 3 4 + ) * ) 。
逆波兰表达式主要有以下两个优点:
- 去掉括号后表达式无歧义,上式即便写成 1 2 + 3 4 + * 也可以依据次序计算出正确结果。
- 适合用栈操作运算:遇到数字则入栈;遇到算符则取出栈顶两个数字进行计算,并将结果压入栈中。
通过次数139,135
提交次数260,287
class Solution:
def evalRPN(self, tokens: List[str]) -> int:
stack = []
for ch in tokens:
if ch.isdigit() or ch.lstrip('-').isdigit():
stack.append(int (ch))
else:
right = int(stack.pop(-1))
left = int(stack.pop(-1))
if ch == '*':
stack.append(left * right)
elif ch == '+':
stack.append(left + right)
elif ch == '/':
stack.append(int (left / float(right)))
elif ch == '-':
stack.append(left - right)
return stack[0]
20. 有效的括号
给定一个只包括 ‘(‘,’)’,’{‘,’}’,’[‘,’]’ 的字符串 s ,判断字符串是否有效。
有效字符串需满足:
- 左括号必须用相同类型的右括号闭合。
- 左括号必须以正确的顺序闭合。
示例 1:
输入:s = “()” 输出:true
示例 2:
输入:s = “()[]{}” 输出:true
示例 3:
输入:s = “(]” 输出:false
示例 4:
输入:s = “([)]” 输出:false
示例 5:
输入:s = “{[]}” 输出:true
提示:
- 1 <= s.length <= 104
- s 仅由括号 ‘()[]{}’ 组成
通过次数835,141
提交次数1,875,489
class Solution:
def isValid(self, s: str) -> bool:
stack = []
for i in s:
if i not in ")]}":
stack.append(i)
elif i == ')':
if not stack or stack[-1] != '(':
return False
else:
stack.pop()
elif i == ']':
if not stack or stack[-1] != '[':
return False
else:
stack.pop()
elif i == '}':
if not stack or stack[-1] != '{':
return False
else:
stack.pop()
if len(stack) == 0:
return True
else:
return False
class Solution:
def isValid(self, s: str) -> bool:
stack = []
for i in s:
if i == '(' or i == '{' or i =='[' or len(stack) == 0:
stack.append(i)
else:
char = stack[-1]
if char == '(' and i ==')':
stack.pop(-1)
elif char == '{' and i =='}':
stack.pop(-1)
elif char == '[' and i ==']':
stack.pop(-1)
else:
stack.append(i)
return len(stack) ==0
32. 最长有效括号
给你一个只包含 ‘(‘ 和 ‘)’ 的字符串,找出最长有效(格式正确且连续)括号子串的长度。
示例 1:
输入:s = “(()” 输出:2 解释:最长有效括号子串是 “()”
示例 2:
输入:s = “)()())” 输出:4 解释:最长有效括号子串是 “()()”
示例 3:
输入:s = “” 输出:0
提示:
- 0 <= s.length <= 3 * 104
- s[i] 为 ‘(‘ 或 ‘)’
栈操作
之前说过遇到括号匹配,直接上栈,没毛病。这道题也是一样的。
初始栈为stack = [-1]即哨兵节点,这个是老套路...<br /> 然后开始遍历s的下标<br /> 当s[i]为左括号时,无脑入栈<br /> 当s[i]为右括号时<br /> 我们先pop栈顶<br /> 如果栈为空,则我们将哨兵pop掉了,没有正确匹配,将当前的i压栈继续当哨兵。<br /> 当pop出的栈顶为左括号,那么更新ret = max(ret, i- 此时栈顶)<br /> 重复3、4操作,即可获取最终结果
作者:qingfengpython
链接:https://leetcode-cn.com/problems/longest-valid-parentheses/solution/32zui-chang-you-xiao-gua-hao-python-bao-tgw1x/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
class Solution:
def longestValidParentheses(self, s: str) -> int:
stack = [-1]
res = 0
for i, c in enumerate(s):
if c == '(':
stack.append(i)
else:
stack.pop()
if not stack:
stack.append(i)
else:
res = max(res, i - stack[-1])
return res
94. 二叉树的中序遍历
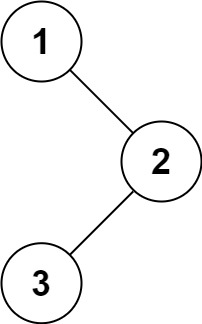
给定一个二叉树的根节点 root ,返回它的 中序 遍历。
示例 1:
输入:root = [1,null,2,3] 输出:[1,3,2] 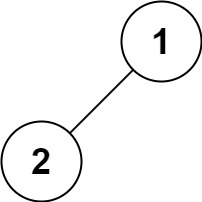
示例 2:
输入:root = [] 输出:[]
示例 3:
输入:root = [1] 输出:[1]
示例 4:
输入:root = [1,2] 输出:[2,1]
示例 5:
输入:root = [1,null,2] 输出:[1,2]
提示:
- 树中节点数目在范围 [0, 100] 内
- -100 <= Node.val <= 100
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def inorderTraversal(self, root: TreeNode) -> List[int]:
stack = []
res = []
while stack or root:
if root:
stack.append(root)
root = root.left
node = stack.pop(-1)
res.append(node.val)
root = root.right
return res

388. 文件的最长绝对路径
假设有一个同时存储文件和目录的文件系统。下图展示了文件系统的一个示例: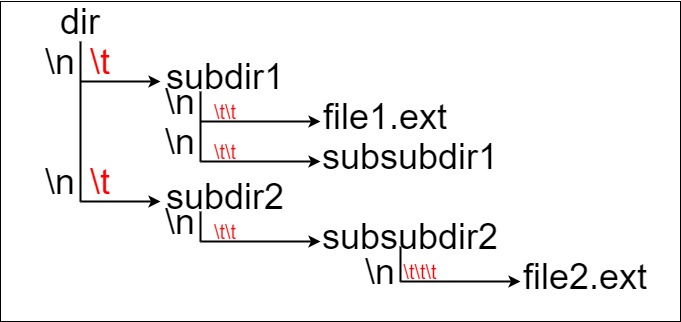
这里将 dir 作为根目录中的唯一目录。dir 包含两个子目录 subdir1 和 subdir2 。subdir1 包含文件 file1.ext 和子目录 subsubdir1;subdir2 包含子目录 subsubdir2,该子目录下包含文件 file2.ext 。
在文本格式中,如下所示(⟶表示制表符):
dir ⟶ subdir1 ⟶ ⟶ file1.ext ⟶ ⟶ subsubdir1 ⟶ subdir2 ⟶ ⟶ subsubdir2 ⟶ ⟶ ⟶ file2.ext 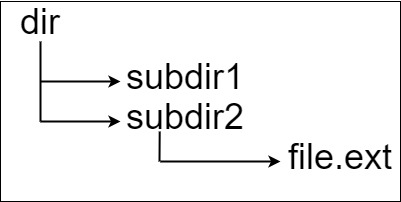
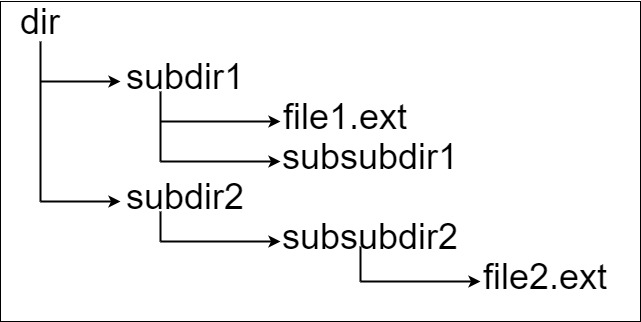
如果是代码表示,上面的文件系统可以写为 “dir\n\tsubdir1\n\t\tfile1.ext\n\t\tsubsubdir1\n\tsubdir2\n\t\tsubsubdir2\n\t\t\tfile2.ext” 。’\n’ 和 ‘\t’ 分别是换行符和制表符。
文件系统中的每个文件和文件夹都有一个唯一的 绝对路径 ,即必须打开才能到达文件/目录所在位置的目录顺序,所有路径用 ‘/‘ 连接。上面例子中,指向 file2.ext 的绝对路径是 “dir/subdir2/subsubdir2/file2.ext” 。每个目录名由字母、数字和/或空格组成,每个文件名遵循 name.extension 的格式,其中名称和扩展名由字母、数字和/或空格组成。
给定一个以上述格式表示文件系统的字符串 input ,返回文件系统中 指向文件的最长绝对路径 的长度。 如果系统中没有文件,返回 0。
示例 1:
输入:input = “dir\n\tsubdir1\n\tsubdir2\n\t\tfile.ext” 输出:20 解释:只有一个文件,绝对路径为 “dir/subdir2/file.ext” ,路径长度 20
示例 2:
输入:input = “dir\n\tsubdir1\n\t\tfile1.ext\n\t\tsubsubdir1\n\tsubdir2\n\t\tsubsubdir2\n\t\t\tfile2.ext” 输出:32 解释:存在两个文件: “dir/subdir1/file1.ext” ,路径长度 21 “dir/subdir2/subsubdir2/file2.ext” ,路径长度 32 返回 32 ,因为这是最长的路径
示例 3:
输入:input = “a” 输出:0 解释:不存在任何文件
示例 4:
输入:input = “file1.txt\nfile2.txt\nlongfile.txt” 输出:12 解释:根目录下有 3 个文件。 因为根目录中任何东西的绝对路径只是名称本身,所以答案是 “longfile.txt” ,路径长度为 12
提示:
- 1 <= input.length <= 104
- input 可能包含小写或大写的英文字母,一个换行符 ‘\n’,一个制表符 ‘\t’,一个点 ‘.’,一个空格 ‘ ‘,和数字。
class Solution:
def lengthLongestPath(self, input: str) -> int:
files = input.split('\n')
stack = []
res = 0
for i in files:
cur_level = i.count('\t')
while len(stack) > cur_level:
stack.pop()
i = i.replace('\t', '')
stack.append(i)
if '.' in i:
temp = len('/'.join(stack))
res = max(res, temp)
return res
关键点:
利用\t来判断层级,弹出栈来弹出到当前自己的层级
队列


253. 会议室 II
给你一个会议时间安排的数组 intervals ,每个会议时间都会包括开始和结束的时间 intervals[i] = [starti, endi] ,为避免会议冲突,同时要考虑充分利用会议室资源,请你计算至少需要多少间会议室,才能满足这些会议安排。
示例 1:
输入:intervals = [[0,30],[5,10],[15,20]] 输出:2
示例 2:
输入:intervals = [[7,10],[2,4]] 输出:1
提示:
- 1 <= intervals.length <= 104
- 0 <= starti < endi <= 106
通过次数30,162
提交次数60,685
参考视频
[LeetCode]253. Meeting Rooms II 中文
import heapq
class Solution:
def minMeetingRooms(self, intervals: List[List[int]]) -> int:
intervals.sort(key=lambda x: x[0])
res = []
res.append(intervals[0][1])
for i in range(1, len(intervals)):
if intervals[i][0] >= res[0]:
heapq.heappop(res)
heapq.heappush(res, intervals[i][1])
return (len(res))
思维导图
239. 滑动窗口最大值
给你一个整数数组 nums,有一个大小为 k 的滑动窗口从数组的最左侧移动到数组的最右侧。你只可以看到在滑动窗口内的 k 个数字。滑动窗口每次只向右移动一位。
返回滑动窗口中的最大值。
示例 1:
输入:nums = [1,3,-1,-3,5,3,6,7], k = 3 输出:[3,3,5,5,6,7] 解释: 滑动窗口的位置 最大值 ———————- ——- [1 3 -1] -3 5 3 6 7 3 1 [3 -1 -3] 5 3 6 7 3 1 3 [-1 -3 5] 3 6 7 5 1 3 -1 [-3 5 3] 6 7 5 1 3 -1 -3 [5 3 6] 7 6 1 3 -1 -3 5 [3 6 7] 7
示例 2:
输入:nums = [1], k = 1 输出:[1]
示例 3:
输入:nums = [1,-1], k = 1 输出:[1,-1]
示例 4:
输入:nums = [9,11], k = 2 输出:[11]
示例 5:
输入:nums = [4,-2], k = 2 输出:[4]
提示:
- 1 <= nums.length <= 105
- -104 <= nums[i] <= 104
- 1 <= k <= nums.length
通过次数191,632
提交次数385,815
215. 数组中的第K个最大元素
给定整数数组 nums 和整数 k,请返回数组中第 k 个最大的元素。
请注意,你需要找的是数组排序后的第 k 个最大的元素,而不是第 k 个不同的元素。
示例 1:
输入: [3,2,1,5,6,4] 和 k = 2 输出: 5
示例 2:
输入: [3,2,3,1,2,4,5,5,6] 和 k = 4 输出: 4
提示:
- 1 <= k <= nums.length <= 104
- -104 <= nums[i] <= 104
通过次数479,505
提交次数741,815
import heapq
class Solution:
def findKthLargest(self, nums: List[int], k: int) -> int:
heapq.heapify(nums)
return heapq.nlargest(k, nums)[-1]
使用大顶堆
class Solution:
def findKthLargest(self, nums: List[int], k: int) -> int:
n = len(nums)
heap = [-num for num in nums]
heapq.heapify(heap)
for _ in range(k):
heapq.heappop(heap)
return -heap[0]
作者:123-2621
链接:https://leetcode-cn.com/problems/kth-largest-element-in-an-array/solution/xiao-ding-dui-da-ding-dui-by-123-2621-jveq/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
264. 丑数 II
给你一个整数 n ,请你找出并返回第 n 个 丑数 。
丑数 就是只包含质因数 2、3 和/或 5 的正整数。
示例 1:
输入:n = 10 输出:12 解释:[1, 2, 3, 4, 5, 6, 8, 9, 10, 12] 是由前 10 个丑数组成的序列。
示例 2:
输入:n = 1 输出:1 解释:1 通常被视为丑数。
提示:
- 1 <= n <= 1690
import heapq
class Solution:
def nthUglyNumber(self, n: int) -> int:
seen = set()
seen.add(1)
factors = [2,3,5]
q = [1]
heapq.heapify(q)
cur_ugly = 1
for _ in range(n):
cur_ugly = heapq.heappop(q)
for i in factors:
new_i = cur_ugly * i
if new_i not in seen:
seen.add(new_i)
heapq.heappush(q, new_i)
return cur_ugly
最小堆
解题思路
很容易想到的方法是:从1起检验每个数是否为丑数,直到找到n个丑数为止。但是随着n的增大,绝大部分数字都不是丑数,我们枚举的效率非常低。因此,换个角度思考,如果我们只生成丑数,且生成n个,这道题就迎刃而解。<br /> 不难发现生成丑数的规律:如果已知丑数ugly,那么ugly * 2,ugly * 3和ugly * 5也都是丑数。<br /> 既然求第n小的丑数,可以采用最小堆来解决。每次弹出堆中最小的丑数,然后检查它分别乘以2、3和 5后的数是否生成过,如果是第一次生成,那么就放入堆中。第n个弹出的数即为第n小的丑数。
算法流程
创建最小堆heap,哈希表 seen和质因数列表factors = [2, 3, 5]。heap用于存储已生成的丑数,弹出最小值;seen用于标记堆中出现过的元素,避免重复入堆。<br /> 初始化将1入堆,并添加到seen。<br /> 重复以下步骤n次:<br /> 弹出堆中最小的数字 curr_ugly。<br /> 对于factors中每个因数f,生成新的丑数new_ugly。若new_ugly不在seen中,则将其添加到heap中并更新seen。<br /> curr_ugly即为第n小的丑数,返回。
复杂度分析
时间复杂度:O(nlog(n))O(nlog(n))O(nlog(n))。弹出每个最小值时,时间复杂度都为堆的高度,因此时间复杂度为O(nlog(n))O(nlog(n))O(nlog(n))。<br /> 空间复杂度:O(n)O(n)O(n)。遍历n个丑数,并将每个丑数乘以2、3和5的结果存入堆中。堆和哈希表的元素个数都不会超过n * 3。
作者:coldme-2
链接:https://leetcode-cn.com/problems/ugly-number-ii/solution/1-zui-xiao-dui-2-dong-tai-gui-hua-san-zhi-zhen-pyt/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
347. 前 K 个高频元素
给你一个整数数组 nums 和一个整数 k ,请你返回其中出现频率前 k 高的元素。你可以按 任意顺序 返回答案。
示例 1:
输入: nums = [1,1,1,2,2,3], k = 2 输出: [1,2]
示例 2:
输入: nums = [1], k = 1 输出: [1]
提示:
- 1 <= nums.length <= 105
- k 的取值范围是 [1, 数组中不相同的元素的个数]
- 题目数据保证答案唯一,换句话说,数组中前 k 个高频元素的集合是唯一的
进阶:你所设计算法的时间复杂度 必须 优于 O(n log n) ,其中 n 是数组大小。
使用 python的Counter函数
from collections import Counter
class Solution:
def topKFrequent(self, nums: List[int], k: int) -> List[int]:
c = Counter(nums)
return [i[0] for i in c.most_common(k)]
373. 查找和最小的K对数字
给定两个以升序排列的整数数组 nums1 和nums2 , 以及一个整数 k 。
定义一对值 (u,v),其中第一个元素来自 nums1,第二个元素来自 nums2 。
请找到和最小的 k 个数对 (u1,v1), (u2,v2) … (uk,vk) 。
示例 1:
输入: nums1 = [1,7,11], nums2 = [2,4,6], k = 3 输出: [1,2],[1,4],[1,6] 解释: 返回序列中的前 3 对数: [1,2],[1,4],[1,6],[7,2],[7,4],[11,2],[7,6],[11,4],[11,6]
示例 2:
输入: nums1 = [1,1,2], nums2 = [1,2,3], k = 2 输出: [1,1],[1,1] 解释: 返回序列中的前 2 对数: [1,1],[1,1],[1,2],[2,1],[1,2],[2,2],[1,3],[1,3],[2,3]
示例 3:
输入: nums1 = [1,2], nums2 = [3], k = 3 输出: [1,3],[2,3] 解释: 也可能序列中所有的数对都被返回:[1,3],[2,3]
提示:
- 1 <= nums1.length, nums2.length <= 104
- -109 <= nums1[i], nums2[i] <= 109
- nums1, nums2 均为升序排列
- 1 <= k <= 1000
class Solution:
def kSmallestPairs(self, nums1: List[int], nums2: List[int], k: int) -> List[List[int]]:
if not len(nums1) or not len(nums2): return []
hq = [(nums1[0] + nums2[0], 0, 0)]
ans = []
visited = set()
while len(hq) and len(ans) < k:
_, i, j = heapq.heappop(hq)
if (i, j) in visited: continue
ans.append((nums1[i], nums2[j]))
visited.add((i, j))
if i+1 < len(nums1):
heapq.heappush(hq, (nums1[i+1]+nums2[j], i+1, j))
if j+1 < len(nums2):
heapq.heappush(hq, (nums1[i]+nums2[j+1], i, j+1))
return ans
作者:monk-6
链接:https://leetcode-cn.com/problems/find-k-pairs-with-smallest-sums/solution/monkti-jie-yong-zui-shao-de-yu-yan-he-da-42rk/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
面试题 17.14. 最小K个数
设计一个算法,找出数组中最小的k个数。以任意顺序返回这k个数均可。
示例:
输入: arr = [1,3,5,7,2,4,6,8], k = 4 输出: [1,2,3,4]
提示:
- 0 <= len(arr) <= 100000
- 0 <= k <= min(100000, len(arr))
通过次数79,900
提交次数134,011
import heapq
class Solution:
def smallestK(self, arr: List[int], k: int) -> List[int]:
return heapq.nsmallest(k,arr)
378. 有序矩阵中第 K 小的元素
给你一个 n x n 矩阵 matrix ,其中每行和每列元素均按升序排序,找到矩阵中第 k 小的元素。
请注意,它是 排序后 的第 k 小元素,而不是第 k 个 不同 的元素。
示例 1:
输入:matrix = [[1,5,9],[10,11,13],[12,13,15]], k = 8 输出:13 解释:矩阵中的元素为 [1,5,9,10,11,12,13,13,15],第 8 小元素是 13
示例 2:
输入:matrix = [[-5]], k = 1 输出:-5
提示:
- n == matrix.length
- n == matrix[i].length
- 1 <= n <= 300
- -109 <= matrix[i][j] <= 109
- 题目数据 保证matrix 中的所有行和列都按 非递减顺序 排列
- 1 <= k <= n2
通过次数83,978
提交次数131,384
import heapq
class Solution:
def kthSmallest(self, matrix: List[List[int]], k: int) -> int:
heapq.heapify(matrix)
while k > 1:
temp = heapq.heappop(matrix)
if temp:
heapq.heappop(temp)
if temp:
heapq.heappush(matrix, temp)
k -= 1
return heapq.heappop(heapq.heappop(matrix))
451. 根据字符出现频率排序
给定一个字符串,请将字符串里的字符按照出现的频率降序排列。
示例 1:
输入: “tree” 输出: “eert” 解释: ‘e’出现两次,’r’和’t’都只出现一次。 因此’e’必须出现在’r’和’t’之前。此外,”eetr”也是一个有效的答案。
示例 2:
输入: “cccaaa” 输出: “cccaaa” 解释: ‘c’和’a’都出现三次。此外,”aaaccc”也是有效的答案。 注意”cacaca”是不正确的,因为相同的字母必须放在一起。
示例 3:
输入: “Aabb” 输出: “bbAa” 解释: 此外,”bbaA”也是一个有效的答案,但”Aabb”是不正确的。 注意’A’和’a’被认为是两种不同的字符。
通过次数86,454
提交次数121,456
import collections
class Solution:
def frequencySort(self, s: str) -> str:
c = collections.Counter(s).most_common(len(s))
res = ""
for i in c:
res += i[0] * i[1]
return res
621. 任务调度器
给你一个用字符数组 tasks 表示的 CPU 需要执行的任务列表。其中每个字母表示一种不同种类的任务。任务可以以任意顺序执行,并且每个任务都可以在 1 个单位时间内执行完。在任何一个单位时间,CPU 可以完成一个任务,或者处于待命状态。
然而,两个 相同种类 的任务之间必须有长度为整数n的冷却时间,因此至少有连续 n 个单位时间内 CPU 在执行不同的任务,或者在待命状态。
你需要计算完成所有任务所需要的 最短时间 。
示例 1:
输入:tasks = [“A”,”A”,”A”,”B”,”B”,”B”], n = 2 输出:8 解释:A -> B -> (待命) -> A -> B -> (待命) -> A -> B 在本示例中,两个相同类型任务之间必须间隔长度为 n = 2 的冷却时间,而执行一个任务只需要一个单位时间,所以中间出现了(待命)状态。
示例 2:
输入:tasks = [“A”,”A”,”A”,”B”,”B”,”B”], n = 0 输出:6 解释:在这种情况下,任何大小为 6 的排列都可以满足要求,因为 n = 0 [“A”,”A”,”A”,”B”,”B”,”B”] [“A”,”B”,”A”,”B”,”A”,”B”] [“B”,”B”,”B”,”A”,”A”,”A”] … 诸如此类
示例 3:
输入:tasks = [“A”,”A”,”A”,”A”,”A”,”A”,”B”,”C”,”D”,”E”,”F”,”G”], n = 2 输出:16 解释:一种可能的解决方案是: A -> B -> C -> A -> D -> E -> A -> F -> G -> A -> (待命) -> (待命) -> A -> (待命) -> (待命) -> A
提示:
- 1 <= task.length <= 104
- tasks[i] 是大写英文字母
利用优先队列
时间上实现的是操作系统的轮询机制(round robin)。哈希表统计task频率,然后优先级队列按照降序调度频率最高的任务,每一轮(n + 1 cycles)同一个task只能执行一次,因此要用一个queue中转一下,避免高频率的任务一直占着CPU。执行完一轮之后再把queue里面的任务频率减1,如果还大于0,重新压入优先级队列继续下一轮轮询。只要pq优先级队列不空,我们就必须加(n+1)cycles到最后结果,即使中间有等待的时间(idle time)。如果最后一轮不满,则只需加实际执行的任务数目count。
作者:jyj407
链接:https://leetcode-cn.com/problems/task-scheduler/solution/zhong-gui-zhong-ju-621-ren-wu-diao-du-qi-arnc/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
class Solution {
public:
int leastInterval(vector<char>& tasks, int n) {
unordered_map<char, int> mp;
for (const auto& task : tasks) {
mp[task]++;
}
priority_queue<int> pq;
for (const auto& m : mp) {
pq.push(m.second); // just care frequency, but not the task name
}
int cycle = n + 1;
int res = 0;
// Have to temporarily save the poped elements into a queue
// so that two consectutive elements wouldn't be scheduled
// together even it still has very high frequency
while (!pq.empty()) {
queue<int> q;
int count = 0;
for (int i = 0; i < cycle; i++) {
if (!pq.empty()) {
q.push(pq.top());
pq.pop();
count++;
}
}
while (!q.empty()) {
auto freq = q.front();
q.pop();
freq--;
if (freq > 0) {
pq.push(freq);
}
}
// As long as pq is not empty, we have to add n + 1 cycles to res
// it is possible that we didn't fully utilize the n + 1 cycles
// meaning there could be CPU idle time
// when pq is empty, meaning this is the last batch of tasks, we don't
// have to wait full (n + 1) cycles if count < (n +1)
res += pq.empty() ? count : cycle;
}
return res;
}
};
作者:jyj407
链接:https://leetcode-cn.com/problems/task-scheduler/solution/zhong-gui-zhong-ju-621-ren-wu-diao-du-qi-arnc/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
优先队列
class Solution:
def leastInterval(self, tasks: List[str], n: int) -> int:
cnt = Counter(tasks)
tasks_pro = []
for i in cnt:
heapq.heappush(tasks_pro, -cnt[i])
res = 0
st = heapq.heappop(tasks_pro)
res += 1 + (n + 1) * (-st - 1)
waited = n * (-st - 1)
while tasks_pro:
#每次取出任务数最大的任务种类
cur = heapq.heappop(tasks_pro)
#剩余空位,可穿插在当前任务排列中的空位
#如,["A","A","A","B","B","B"], n = 2
#则 A _ _ A _ _ A为一开始的任务组合,B任务可插入空位
if waited > 0:
#此条件下当前任务可以直接插入空位
if -cur <= -st - 1:
if waited + cur >= 0:
waited += cur
#空位用完,需要额外的位置执行多出来的任务,此类任务每个可只占一个位置
#因为不是直接放后面,比如上一个例子["A","A","A","B","B","B"], n = 2
#我们可以插在A _ _ A的后一个A前面,成A _ _ _ A
else:
res += -cur - waited
waited = 0
#不满足此条件说明,当前任务数和最大任务数一样多,所以会多出一个任务无法插入空位,需单独处理
else:
res += -cur - (-st - 1)
waited -= -st - 1
#空位用完,需要额外的位置执行多出来的任务,此类任务每个可只占一个位置
#因为不是直接放后面,比如上一个例子["A","A","A","B","B","B"], n = 2
#我们可以插在A _ _ A的后一个A前面,成A _ _ _ A
else:
res -= cur
return res
作者:fff-202009
链接:https://leetcode-cn.com/problems/task-scheduler/solution/you-xian-dui-lie-ye-ke-yi-pai-xu-by-fff-77623/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
class Solution:
def leastInterval(self, tasks: List[str], n: int) -> int:
m = collections.Counter(tasks)
a = []
for task in m:
heapq.heappush(a, (-m[task], 1, task))
time = 0
res=[]
while a:
time += 1
for i in range(len(a)):
if a[i][1] <= time:
x = a.pop(i)
x = (-(-x[0] - 1), x[1] + n + 1,x[2])
if x[0] != 0:
heapq.heappush(a, x)
res.append(x[2])
break
else:
res.append('待命')
return time
作者:tooooo_the_moon
链接:https://leetcode-cn.com/problems/task-scheduler/solution/mo-ni-fa-dui-by-tooooo_the_moon-8er6/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
class Solution:
def leastInterval(self, tasks: List[str], n: int) -> int:
res = []
for task in set(tasks):
res.append(tasks.count(task))
length = 0
res.sort(reverse=True)
while res[0] > 1:
res = [x - 1 for x in res[: n + 1]] + res[n + 1:]
res = [x for x in res if x > 0]
res.sort(reverse=True)
length += 1
return length * (n + 1) + len(res)
作者:haobq2008
链接:https://leetcode-cn.com/problems/task-scheduler/solution/ren-wu-diao-du-qi-jian-dan-yi-dong-by-ha-l7wz/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
from heapq import heapify, heappush, heappop
from collections import Counter
class Solution:
def leastInterval(self, tasks, n: int) -> int:
res = 0
counter = Counter(tasks)
array = []
for key in counter:
array.append((-counter[key], key))
# 临时存放中最小堆中取出来的元素
temp = []
# 构建负数的最小堆即最大堆
heapify(array)
while array or temp:
# 时间
number = 0
# 堆中还有元素
while array:
# 取出的元素个数<=n
if number <= n:
val, ele = heappop(array)
if val < - 1:
temp.append((val + 1, ele))
number += 1
res += 1
# 从堆中取了n个数,即使下次遇到上次最大堆的堆顶元素也无所谓了
else:
break
# 如果还有任务没有执行并且两个相同任务之间的冷却时间不到,则处于待命状态
if temp and number < n + 1:
res += n + 1 - number
while temp:
heappush(array, temp.pop())
return res
作者:xin-nochang-da
链接:https://leetcode-cn.com/problems/task-scheduler/solution/kan-ji-ben-shang-du-shi-tong-pai-xu-gong-iqo5/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
506. 相对名次
给你一个长度为 n 的整数数组 score ,其中 score[i] 是第 i 位运动员在比赛中的得分。所有得分都 互不相同 。
运动员将根据得分 决定名次 ,其中名次第 1 的运动员得分最高,名次第 2 的运动员得分第 2 高,依此类推。运动员的名次决定了他们的获奖情况:
- 名次第 1 的运动员获金牌 “Gold Medal” 。
- 名次第 2 的运动员获银牌 “Silver Medal” 。
- 名次第 3 的运动员获铜牌 “Bronze Medal” 。
- 从名次第 4 到第 n 的运动员,只能获得他们的名次编号(即,名次第 x 的运动员获得编号 “x”)。
使用长度为 n 的数组 answer 返回获奖,其中 answer[i] 是第 i 位运动员的获奖情况。
示例 1:
输入:score = [5,4,3,2,1] 输出:[“Gold Medal”,”Silver Medal”,”Bronze Medal”,”4”,”5”] 解释:名次为 [1st, 2nd, 3rd, 4th, 5th] 。
示例 2:
输入:score = [10,3,8,9,4] 输出:[“Gold Medal”,”5”,”Bronze Medal”,”Silver Medal”,”4”] 解释:名次为 [1st, 5th, 3rd, 2nd, 4th] 。
提示:
- n == score.length
- 1 <= n <= 104
- 0 <= score[i] <= 106
- score 中的所有值 互不相同
通过次数56,109
提交次数85,835
class Solution:
def findRelativeRanks(self, score: List[int]) -> List[str]:
hashmap = {}
for i in range(len(score)):
hashmap[score[i]] = i
arr =sorted(list(hashmap.keys()), reverse=True)
res = [-1 for _ in range(len(score))]
for i in range(len(arr)):
if i == 0:
res[hashmap[arr[i]]] = "Gold Medal"
elif i == 1:
res[hashmap[arr[i]]] = "Silver Medal"
elif i == 2:
res[hashmap[arr[i]]] = "Bronze Medal"
else:
res[hashmap[arr[i]]] = str(i + 1)
return res
1046. 最后一块石头的重量
有一堆石头,每块石头的重量都是正整数。
每一回合,从中选出两块 最重的 石头,然后将它们一起粉碎。假设石头的重量分别为 x 和 y,且 x <= y。那么粉碎的可能结果如下:
- 如果 x == y,那么两块石头都会被完全粉碎;
- 如果 x != y,那么重量为 x 的石头将会完全粉碎,而重量为 y 的石头新重量为 y-x。
最后,最多只会剩下一块石头。返回此石头的重量。如果没有石头剩下,就返回 0。
示例:
输入:[2,7,4,1,8,1] 输出:1 解释: 先选出 7 和 8,得到 1,所以数组转换为 [2,4,1,1,1], 再选出 2 和 4,得到 2,所以数组转换为 [2,1,1,1], 接着是 2 和 1,得到 1,所以数组转换为 [1,1,1], 最后选出 1 和 1,得到 0,最终数组转换为 [1],这就是最后剩下那块石头的重量。
提示:
- 1 <= stones.length <= 30
- 1 <= stones[i] <= 1000
通过次数68,451
提交次数103,865
import heapq
class Solution:
def lastStoneWeight(self, stones: List[int]) -> int:
arr = [-i for i in stones]
heapq.heapify(arr)
while len(arr) > 1:
x = heapq.heappop(arr)
y = heapq.heappop(arr)
if x < y:
heapq.heappush(arr, x - y)
if arr:
return -arr[0]
else :
return 0
1337. 矩阵中战斗力最弱的 K 行
给你一个大小为 m n 的矩阵 mat,矩阵由若干军人和平民组成,分别用 1 和 0 表示。
请你返回矩阵中战斗力最弱的 k 行的索引,按从最弱到最强排序。
如果第 i 行的军人数量少于第 j 行,或者两行军人数量相同但 i 小于 j,那么我们认为第 i 行的战斗力比第 j 行弱。
军人 *总是 排在一行中的靠前位置,也就是说 1 总是出现在 0 之前。
示例 1:
输入:mat = [[1,1,0,0,0], [1,1,1,1,0], [1,0,0,0,0], [1,1,0,0,0], [1,1,1,1,1]], k = 3 输出:[2,0,3] 解释: 每行中的军人数目: 行 0 -> 2 行 1 -> 4 行 2 -> 1 行 3 -> 2 行 4 -> 5 从最弱到最强对这些行排序后得到 [2,0,3,1,4]
示例 2:
输入:mat = [[1,0,0,0], [1,1,1,1], [1,0,0,0], [1,0,0,0]], k = 2 输出:[0,2] 解释: 每行中的军人数目: 行 0 -> 1 行 1 -> 4 行 2 -> 1 行 3 -> 1 从最弱到最强对这些行排序后得到 [0,2,3,1]
提示:
- m == mat.length
- n == mat[i].length
- 2 <= n, m <= 100
- 1 <= k <= m
- matrix[i][j] 不是 0 就是 1
通过次数40,117
提交次数56,948
import heapq
class Solution:
def kWeakestRows(self, mat: List[List[int]], k: int) -> List[int]:
for i in range(len(mat)):
mat[i].append(i)
heapq.heapify(mat)
res = []
while k and mat:
k -= 1
temp = heapq.heappop(mat)
res.append(temp[-1])
return res
利用hashmap优化
class Solution:
def kWeakestRows(self, mat: List[List[int]], k: int) -> List[int]:
if not mat:
return []
hash_map = {}
for i in range(len(mat)):
hash_map[i] = sum(mat[i])
hash_map = sorted(hash_map.items(), key=lambda x: x[1])[:k]
res = []
for i in range(len(hash_map)):
res.append(hash_map[i][0])
return res
作者:zhsama
链接:https://leetcode-cn.com/problems/the-k-weakest-rows-in-a-matrix/solution/yong-hashbao-cun-ji-suan-jie-guo-da-bai-efron/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
1464. 数组中两元素的最大乘积
给你一个整数数组 nums,请你选择数组的两个不同下标 i 和 j,使 (nums[i]-1)*(nums[j]-1) 取得最大值。
请你计算并返回该式的最大值。
示例 1:
输入:nums = [3,4,5,2] 输出:12 解释:如果选择下标 i=1 和 j=2(下标从 0 开始),则可以获得最大值,(nums[1]-1)(nums[2]-1) = (4-1)(5-1) = 34 = 12 。
示例 2:
输入:nums = [1,5,4,5] 输出:16 解释:选择下标 i=1 和 j=3(下标从 0 开始),则可以获得最大值 (5-1)(5-1) = 16 。
示例 3:
输入:nums = [3,7] 输出:12
提示:
- 2 <= nums.length <= 500
- 1 <= nums[i] <= 10^3
class Solution:
def maxProduct(self, nums: List[int]) -> int:
nums.sort()
return (nums[-1] - 1) * (nums[-2] - 1)
2099. 找到和最大的长度为 K 的子序列
给你一个整数数组 nums 和一个整数 k 。你需要找到 nums 中长度为 k 的 子序列 ,且这个子序列的 和最大 。
请你返回 任意 一个长度为 k 的整数子序列。
子序列 定义为从一个数组里删除一些元素后,不改变剩下元素的顺序得到的数组。
示例 1:
输入:nums = [2,1,3,3], k = 2 输出:[3,3] 解释: 子序列有最大和:3 + 3 = 6 。
示例 2:
输入:nums = [-1,-2,3,4], k = 3 输出:[-1,3,4] 解释: 子序列有最大和:-1 + 3 + 4 = 6 。
示例 3:
输入:nums = [3,4,3,3], k = 2 输出:[3,4] 解释: 子序列有最大和:3 + 4 = 7 。 另一个可行的子序列为 [4, 3] 。
提示:
- 1 <= nums.length <= 1000
- -105 <= nums[i] <= 105
- 1 <= k <= nums.length
通过次数3,601
提交次数7,346
请问您在哪类招聘中遇到此题?
class Solution:
def maxSubsequence(self, nums: List[int], k: int) -> List[int]:
# 保留索引
nums = [(i, nums[i]) for i in range(len(nums))]
# 第一次排序
nums = sorted(nums, key = lambda x:x[1])
# 提取topk
sub_num = nums[len(nums)-k:]
# 第二次排序
sub_num = sorted(sub_num, key= lambda x:x[0])
# 提取结果
sub_num = [x[1] for x in sub_num]
return sub_num
649. Dota2 参议院
Dota2 的世界里有两个阵营:Radiant(天辉)和 Dire(夜魇)
Dota2 参议院由来自两派的参议员组成。现在参议院希望对一个 Dota2 游戏里的改变作出决定。他们以一个基于轮为过程的投票进行。在每一轮中,每一位参议员都可以行使两项权利中的一项:
- 禁止一名参议员的权利: 参议员可以让另一位参议员在这一轮和随后的几轮中丧失所有的权利。
- 宣布胜利:
如果参议员发现有权利投票的参议员都是同一个阵营的,他可以宣布胜利并决定在游戏中的有关变化。
给定一个字符串代表每个参议员的阵营。字母 “R” 和 “D” 分别代表了 Radiant(天辉)和 Dire(夜魇)。然后,如果有 n 个参议员,给定字符串的大小将是 n。
以轮为基础的过程从给定顺序的第一个参议员开始到最后一个参议员结束。这一过程将持续到投票结束。所有失去权利的参议员将在过程中被跳过。
假设每一位参议员都足够聪明,会为自己的政党做出最好的策略,你需要预测哪一方最终会宣布胜利并在 Dota2 游戏中决定改变。输出应该是 Radiant 或 Dire。
示例 1:
输入:“RD” 输出:“Radiant” 解释:第一个参议员来自 Radiant 阵营并且他可以使用第一项权利让第二个参议员失去权力,因此第二个参议员将被跳过因为他没有任何权利。然后在第二轮的时候,第一个参议员可以宣布胜利,因为他是唯一一个有投票权的人
示例 2:
输入:“RDD” 输出:“Dire” 解释: 第一轮中,第一个来自 Radiant 阵营的参议员可以使用第一项权利禁止第二个参议员的权利 第二个来自 Dire 阵营的参议员会被跳过因为他的权利被禁止 第三个来自 Dire 阵营的参议员可以使用他的第一项权利禁止第一个参议员的权利 因此在第二轮只剩下第三个参议员拥有投票的权利,于是他可以宣布胜利
提示:
- 给定字符串的长度在 [1, 10,000] 之间.
import heapq
class Solution:
def predictPartyVictory(self, senate: str) -> str:
hd = [i for i, s in enumerate(senate) if s == 'D']
hr = [i for i, s in enumerate(senate) if s == 'R']
while hr and hd:
if hr[0] < hd[0]:
heapq.heappop(hd)
heapq.heappush(hr, heapq.heappop(hr) + len(senate))
else:
heapq.heappop(hr)
heapq.heappush(hd, heapq.heappop(hd) + len(senate))
return 'Dire' if not hr else 'Radiant'
373. 查找和最小的 K 对数字
给定两个以 升序排列 的整数数组 nums1 和nums2 , 以及一个整数 k 。
定义一对值 (u,v),其中第一个元素来自 nums1,第二个元素来自 nums2 。
请找到和最小的 k 个数对 (u1,v1), (u2,v2) … (uk,vk) 。
示例 1:
输入: nums1 = [1,7,11], nums2 = [2,4,6], k = 3 输出: [1,2],[1,4],[1,6] 解释: 返回序列中的前 3 对数: [1,2],[1,4],[1,6],[7,2],[7,4],[11,2],[7,6],[11,4],[11,6]
示例 2:
输入: nums1 = [1,1,2], nums2 = [1,2,3], k = 2 输出: [1,1],[1,1] 解释: 返回序列中的前 2 对数: [1,1],[1,1],[1,2],[2,1],[1,2],[2,2],[1,3],[1,3],[2,3]
示例 3:
输入: nums1 = [1,2], nums2 = [3], k = 3 输出: [1,3],[2,3] 解释: 也可能序列中所有的数对都被返回:[1,3],[2,3]
提示:
- 1 <= nums1.length, nums2.length <= 105
- -109 <= nums1[i], nums2[i] <= 109
- nums1 和 nums2 均为升序排列
- 1 <= k <= 1000
通过次数36,449
提交次数88,164
import heapq
class Solution:
def kSmallestPairs(self, nums1: List[int], nums2: List[int], k: int) -> List[List[int]]:
res = []
visted = set()
x = 0
y = 0
arr = [(nums1[0] + nums2[0], 0, 0)]
while arr and k > 0:
_, x, y = heapq.heappop(arr)
if (x,y) in visted:
continue
res.append([nums1[x], nums2[y]])
visted.add((x,y))
k -= 1
if x + 1 < len(nums1):
heapq.heappush(arr, (nums1[x + 1] + nums2[y], x + 1, y))
if y + 1 < len(nums2):
heapq.heappush(arr, (nums1[x] + nums2[y + 1], x, y + 1))
return res

若有收获,就点个赞吧
0 人点赞
