- 553. 最优除法">553. 最优除法
- 1668. 最大重复子字符串">1668. 最大重复子字符串
- 1249. 移除无效的括号">1249. 移除无效的括号
- 128. 最长连续序列">128. 最长连续序列
- 221. 最大正方形">221. 最大正方形
- 2130. 链表最大孪生和">2130. 链表最大孪生和
- 2129. 将标题首字母大写">2129. 将标题首字母大写
- 2131. 连接两字母单词得到的最长回文串">2131. 连接两字母单词得到的最长回文串
- 5980. 将字符串拆分为若干长度为 k 的组">5980. 将字符串拆分为若干长度为 k 的组
- 5194. 得到目标值的最少行动次数">5194. 得到目标值的最少行动次数
- 5. 最长回文子串">5. 最长回文子串
- 15. 三数之和">15. 三数之和
553. 最优除法
给定一组正整数,相邻的整数之间将会进行浮点除法操作。例如, [2,3,4] -> 2 / 3 / 4 。
但是,你可以在任意位置添加任意数目的括号,来改变算数的优先级。你需要找出怎么添加括号,才能得到最大的结果,并且返回相应的字符串格式的表达式。你的表达式不应该含有冗余的括号。
示例:
输入: [1000,100,10,2] 输出: “1000/(100/10/2)” 解释: 1000/(100/10/2) = 1000/((100/10)/2) = 200 但是,以下加粗的括号 “1000/((100/10)/2)” 是冗余的, 因为他们并不影响操作的优先级,所以你需要返回 “1000/(100/10/2)”。 其他用例: 1000/(100/10)/2 = 50 1000/(100/(10/2)) = 50 1000/100/10/2 = 0.5 1000/100/(10/2) = 2
说明:
- 输入数组的长度在 [1, 10] 之间。
- 数组中每个元素的大小都在 [2, 1000] 之间。
- 每个测试用例只有一个最优除法解。
利用贪心的思想, a/b, b越小则 a/b 越大, 同理 b/c, c越小b越大, 因此直接除就可以了
class Solution:def optimalDivision(self, nums: List[int]) -> str:if len(nums) == 1:return str(nums[0])if len(nums) == 2:return str(nums[0]) + '/' + str(nums[1])res = ""for i in range(len(nums)):if i == 0:res += str(nums[i])res += '/'res += '('elif i == len(nums) - 1:res += str(nums[i])res += ')'else:res += str(nums[i])res += '/'return res
1668. 最大重复子字符串
给你一个字符串 sequence ,如果字符串 word 连续重复 k 次形成的字符串是 sequence 的一个子字符串,那么单词 word 的 重复值为 k。单词 word 的 最大重复值 是单词 word 在 sequence 中最大的重复值。如果 word 不是 sequence 的子串,那么重复值 k 为 0 。
给你一个字符串 sequence 和 word ,请你返回 最大重复值 k。
示例 1:
输入:sequence = “ababc”, word = “ab” 输出:2 解释:“abab” 是 “ababc” 的子字符串。
示例 2:
输入:sequence = “ababc”, word = “ba” 输出:1 解释:“ba” 是 “ababc” 的子字符串,但 “baba” 不是 “ababc” 的子字符串。
示例 3:
输入:sequence = “ababc”, word = “ac” 输出:0 解释:“ac” 不是 “ababc” 的子字符串。
提示:
- 1 <= sequence.length <= 100
- 1 <= word.length <= 100
- sequence 和 word 都只包含小写英文字母。
class Solution:def maxRepeating(self, sequence: str, word: str) -> int:k = 0s = wordwhile s in sequence:k += 1s += wordreturn k
1249. 移除无效的括号
给你一个由 ‘(‘、’)’ 和小写字母组成的字符串 s。
你需要从字符串中删除最少数目的 ‘(‘ 或者 ‘)’ (可以删除任意位置的括号),使得剩下的「括号字符串」有效。
请返回任意一个合法字符串。
有效「括号字符串」应当符合以下 任意一条 要求:
- 空字符串或只包含小写字母的字符串
- 可以被写作 AB(A 连接 B)的字符串,其中 A 和 B 都是有效「括号字符串」
- 可以被写作 (A) 的字符串,其中 A 是一个有效的「括号字符串」
示例 1:
输入:s = “lee(t(c)o)de)” 输出:“lee(t(c)o)de” 解释:“lee(t(co)de)” , “lee(t(c)ode)” 也是一个可行答案。
示例 2:
输入:s = “a)b(c)d” 输出:“ab(c)d”
示例 3:
输入:s = “))((“ 输出:“” 解释:空字符串也是有效的
示例 4:
输入:s = “(a(b(c)d)” 输出:“a(b(c)d)”
提示:
- 1 <= s.length <= 10^5
- s[i] 可能是 ‘(‘、’)’ 或英文小写字母
class Solution:def minRemoveToMakeValid(self, s: str) -> str:stack = []remove_index = []for i in range(len(s)):c = s[i]if c != '(' and c != ')':continueelif not stack and c == ')':remove_index.append(i)elif c == '(':stack.append(i)elif s[stack[-1]] == '(' and c == ')':stack.pop(-1)res = ""for i in range(len(s)):if i in stack or i in remove_index: continueres += s[i]return res
128. 最长连续序列
给定一个未排序的整数数组 nums ,找出数字连续的最长序列(不要求序列元素在原数组中连续)的长度。
请你设计并实现时间复杂度为 O(n)的算法解决此问题。
示例 1:
输入:nums = [100,4,200,1,3,2] 输出:4 解释:最长数字连续序列是 [1, 2, 3, 4]。它的长度为 4。
示例 2:
输入:nums = [0,3,7,2,5,8,4,6,0,1] 输出:9
提示:
- 0 <= nums.length <= 105
- -109 <= nums[i] <= 109
通过次数176,538
提交次数324,848
暴力法
class Solution:def longestConsecutive(self, nums: List[int]) -> int:if len(nums) == 0:return 0if len(nums) == 1:return 1nums.sort()count = 1res = 1for i in range(len(nums) - 1):if nums[i] + 1 == nums[i + 1]:count += 1res = max(res, count)elif nums[i] == nums[i+1]:continueelse:count = 1return res
利用hash表
1、思路
(哈希) O(n)O(n)O(n)
在一个未排序的整数数组 nums中 ,找出最长的数字连续序列,朴素的做法是:枚举nums中的每一个数x,并以x起点,在nums数组中查询x + 1,x + 2,,,x + y是否存在。假设查询到了 x + y,那么长度即为 y - x + 1,不断枚举更新答案即可。
如果每次查询一个数都要遍历一遍nums数组的话,时间复杂度为O(n)O(n)O(n) ,其实我们可以用一个哈希表来存贮数组中的数,这样查询的时间就能优化为O(1)O(1)O(1) 。
为了保证O(n)O(n)O(n)的时间复杂度,避免重复枚举一段序列,我们要从序列的起始数字向后枚举。也就是说如果有一个x, x+1, x+2,,,, x+y的连续序列,我们只会以x为起点向后枚举,而不会从x+1,x+2,,,向后枚举。
如何每次只枚举连续序列的起始数字x?
其实只需要每次在哈希表中检查是否存在 x−1即可。如果x-1存在,说明当前数x不是连续序列的起始数字,我们跳过这个数。
具体过程如下:
1、定义一个哈希表hash,将nums数组中的数都放入哈希表中。<br /> 2、遍历哈希表hash,如果当前数x的前驱x-1不存在,我们就以当前数x为起点向后枚举。<br /> 3、假设最长枚举到了数y,那么连续序列长度即为y-x+1。<br /> 4、不断枚举更新答案。
时间复杂度分析: while循环最多执行nnn次,因此时间复杂度为O(n)O(n)O(n) 。
class Solution:
def longestConsecutive(self, nums: List[int]) -> int:
hashset = set(nums)
res = 0
for x in hashset:
if x - 1 not in hashset:
cur_len = 1
while x + 1 in hashset:
cur_len += 1
x += 1
res = max(res, cur_len)
return res
注意遍历hashset 比 nums速度快的多
【图解】遇到就深究——并查集
https://leetcode-cn.com/problems/longest-consecutive-sequence/solution/tu-jie-yu-dao-jiu-shen-jiu-bing-cha-ji-by-chun-men/
221. 最大正方形
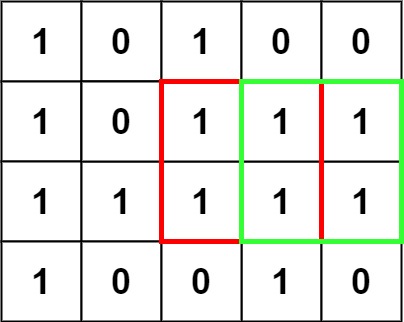
在一个由 ‘0’ 和 ‘1’ 组成的二维矩阵内,找到只包含 ‘1’ 的最大正方形,并返回其面积。
示例 1:
输入:matrix = [[“1”,”0”,”1”,”0”,”0”],[“1”,”0”,”1”,”1”,”1”],[“1”,”1”,”1”,”1”,”1”],[“1”,”0”,”0”,”1”,”0”]] 输出:4 
示例 2:
输入:matrix = [[“0”,”1”],[“1”,”0”]] 输出:1
示例 3:
输入:matrix = [[“0”]] 输出:0
提示:
- m == matrix.length
- n == matrix[i].length
- 1 <= m, n <= 300
- matrix[i][j] 为 ‘0’ 或 ‘1’
直接bfs超时了
class Solution:
def maximalSquare(self, matrix: List[List[str]]) -> int:
res = 0
for i in range(len(matrix)):
for j in range(len(matrix[0])):
if matrix[i][j] == '1':
max_len = self.bfs(i, j, matrix)
res = max(res, max_len)
return res if res == 1 else res ** 2
def bfs(self, x, y, matrix):
temp = 2
while True:
for i in range(temp):
for j in range(temp):
if not self.is_valid(x + i, y + j , matrix):
return temp - 1
temp += 1
def is_valid(self, x, y, matrix):
return 0 <= x < len(matrix) and 0 <= y < len(matrix[0]) and matrix[x][y] == '1'
其他答案
class Solution {
int m;
int n;
int res=0;
public int maximalSquare(char[][] matrix) {
m=matrix.length;
if(m==0) return 0;
n=matrix[0].length;
for(int i=0;i<m;i++){
for(int j=0;j<n;j++){
if(matrix[i][j]=='1'){
dfs(matrix,1,i,j);
}
}
}
return res;
}
// 以 x,y为起点 dfs
void dfs(char [][]matrix,int len,int x,int y){
if(!judge(matrix,x,y,len)){
return;
}
res=Math.max(res,len*len);
dfs(matrix,len+1,x,y);
}
boolean judge(char [][]matrix,int x,int y,int len){
if(x+len>m||y+len>n){
return false;
}
for(int i=x;i<x+len;i++){
for(int j=y;j<y+len;j++){
if(matrix[i][j]!='1'){
return false;
}
}
}
return true;
}
}
2130. 链表最大孪生和
在一个大小为 n 且 n 为 偶数 的链表中,对于 0 <= i <= (n / 2) - 1 的 i ,第 i 个节点(下标从 0 开始)的孪生节点为第 (n-1-i) 个节点 。
- 比方说,n = 4 那么节点 0 是节点 3 的孪生节点,节点 1 是节点 2 的孪生节点。这是长度为 n = 4 的链表中所有的孪生节点。
孪生和 定义为一个节点和它孪生节点两者值之和。
给你一个长度为偶数的链表的头节点 head ,请你返回链表的 最大孪生和 。
示例 1:
输入:head = [5,4,2,1] 输出:6 解释: 节点 0 和节点 1 分别是节点 3 和 2 的孪生节点。孪生和都为 6 。 链表中没有其他孪生节点。 所以,链表的最大孪生和是 6 。
示例 2:
输入:head = [4,2,2,3] 输出:7 解释: 链表中的孪生节点为: - 节点 0 是节点 3 的孪生节点,孪生和为 4 + 3 = 7 。 - 节点 1 是节点 2 的孪生节点,孪生和为 2 + 2 = 4 。 所以,最大孪生和为 max(7, 4) = 7 。
示例 3:
输入:head = [1,100000] 输出:100001 解释: 链表中只有一对孪生节点,孪生和为 1 + 100000 = 100001 。
提示:
- 链表的节点数目是 [2, 105] 中的 偶数 。
- 1 <= Node.val <= 105
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:
def pairSum(self, head: Optional[ListNode]) -> int:
res = 0
temp = []
while head:
temp.append(head.val)
head = head.next
temp2 = temp[::-1]
for i in range(len(temp)):
res = max(temp[i] + temp2[i], res)
return res
2129. 将标题首字母大写
给你一个字符串 title ,它由单个空格连接一个或多个单词组成,每个单词都只包含英文字母。请你按以下规则将每个单词的首字母 大写 :
- 如果单词的长度为 1 或者 2 ,所有字母变成小写。
- 否则,将单词首字母大写,剩余字母变成小写。
请你返回 大写后 的_ _title 。
示例 1:
输入:title = “capiTalIze tHe titLe” 输出:“Capitalize The Title” 解释: 由于所有单词的长度都至少为 3 ,将每个单词首字母大写,剩余字母变为小写。
示例 2:
输入:title = “First leTTeR of EACH Word” 输出:“First Letter of Each Word” 解释: 单词 “of” 长度为 2 ,所以它保持完全小写。 其他单词长度都至少为 3 ,所以其他单词首字母大写,剩余字母小写。
示例 3:
输入:title = “i lOve leetcode” 输出:“i Love Leetcode” 解释: 单词 “i” 长度为 1 ,所以它保留小写。 其他单词长度都至少为 3 ,所以其他单词首字母大写,剩余字母小写。
提示:
- 1 <= title.length <= 100
- title 由单个空格隔开的单词组成,且不含有任何前导或后缀空格。
- 每个单词由大写和小写英文字母组成,且都是 非空 的。
class Solution: def capitalizeTitle(self, title: str) -> str: arr = title.split(' ') res = [] for i in arr: if len(i) <= 2: res.append(i.lower()) else: res.append(i.capitalize()) return ' '.join(res)2131. 连接两字母单词得到的最长回文串
给你一个字符串数组 words 。words 中每个元素都是一个包含 两个 小写英文字母的单词。
请你从 words 中选择一些元素并按 任意顺序 连接它们,并得到一个 尽可能长的回文串 。每个元素 至多 只能使用一次。
请你返回你能得到的最长回文串的 长度 。如果没办法得到任何一个回文串,请你返回 0 。
回文串 指的是从前往后和从后往前读一样的字符串。
示例 1:
输入:words = [“lc”,”cl”,”gg”] 输出:6 解释:一个最长的回文串为 “lc” + “gg” + “cl” = “lcggcl” ,长度为 6 。 “clgglc” 是另一个可以得到的最长回文串。
示例 2:
输入:words = [“ab”,”ty”,”yt”,”lc”,”cl”,”ab”] 输出:8 解释:最长回文串是 “ty” + “lc” + “cl” + “yt” = “tylcclyt” ,长度为 8 。 “lcyttycl” 是另一个可以得到的最长回文串。
示例 3:
输入:words = [“cc”,”ll”,”xx”] 输出:2 解释:最长回文串是 “cc” ,长度为 2 。 “ll” 是另一个可以得到的最长回文串。”xx” 也是。
提示:
- 1 <= words.length <= 105
- words[i].length == 2
- words[i] 仅包含小写英文字母。
通过次数3,173
提交次数8,765
- 找出中心回文词
- 如果回文词只有1个,长度+2,且不再判断
- 如果回文词有多个,长度+4,数量-2,继续执行步骤1
- 如果已经找出中心的回文词,则找出回文的词, 长度+4 ```python from collections import defaultdict, Counter
class Solution: def longestPalindrome(self, words: List[str]) -> int: counter = Counter(words) res = 0 no_parlindome = True for w in words: temp = w[::-1] if temp == w and w in counter: # 如果本身是回文子串 if counter[w] > 1: # 有多个回文子串,可以进行拼接 res += 4 counter[w] -= 2 if counter[w] == 0: del counter[w] elif counter[w] == 1 and no_parlindome: # 只有一个,且没有做中心词 res += 2 counter[w] -= 1 if counter[w] == 0: del counter[w] no_parlindome = False continue
if w in counter and temp in counter and w != temp:
res += 4
counter[w] -= 1
counter[temp] -= 1
if counter[w] == 0:
del counter[w]
if counter[temp] == 0:
del counter[temp]
return res
参考优化的代码
```python
class Solution:
def longestPalindrome(self, words: List[str]) -> int:
cnt = Counter() # 哈希表,记录未匹配得word出现的次数
ans = 0
# 遍历words,对于每个word看是否能匹配到其配对的回文串rword
for word in words:
rword = word[1]+word[0]
if cnt[rword] >= 1: # rword存在,且未被word匹配
cnt[rword] -= 1
ans += 4
else: # 否则,记录当前word
cnt[word] += 1
# 对于本身即为回文串的word,判断是否还剩余有未匹配的 【最多只能加一个】
for word in cnt:
if word[0] == word[1] and cnt[word] >= 1:
ans += 2
break
return ans
作者:flix
链接:https://leetcode-cn.com/problems/longest-palindrome-by-concatenating-two-letter-words/solution/ha-xi-biao-liang-ci-bian-li-qing-song-yi-5t0j/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
加大难度的解法
import java.util.*;
class Solution {
public int longestPalindrome(String[] words) {
Map<String, Integer> map = new HashMap<>();
Map<String, Integer> equal = new HashMap<>();
int ans = 0;
for (String word : words) {
StringBuilder sb = new StringBuilder();
sb.append(word);
String reverse = sb.reverse().toString();
if (word.equals(reverse)) {
equal.put(reverse, equal.getOrDefault(reverse, 0) + 1);
continue;
}
if (map.containsKey(reverse)) {
ans += word.length() * 2;
if (map.get(reverse) == 1) {
map.remove(reverse);
} else {
map.put(reverse, map.get(reverse) - 1);
}
} else {
map.put(word, map.getOrDefault(word, 0) + 1);
}
}
int max = 0;
for (Map.Entry<String, Integer> entry : equal.entrySet()) {
if (entry.getValue() == 1) {
max = Math.max(max, entry.getKey().length());
} else {
if (entry.getValue() % 2 == 1) {
ans += (entry.getValue() - 1) * entry.getKey().length();
max = Math.max(max, entry.getKey().length());
} else {
ans += entry.getValue() * entry.getKey().length();
}
}
}
return ans + max;
}
}
//[lc,cl, ]
作者:Relll-1037
链接:https://leetcode-cn.com/problems/longest-palindrome-by-concatenating-two-letter-words/solution/javayun-yong-liang-shu-zhi-he-de-si-lu-q-bap5/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
5980. 将字符串拆分为若干长度为 k 的组
字符串 s 可以按下述步骤划分为若干长度为 k 的组:
- 第一组由字符串中的前 k 个字符组成,第二组由接下来的 k 个字符串组成,依此类推。每个字符都能够成为 某一个 组的一部分。
- 对于最后一组,如果字符串剩下的字符 不足k 个,需使用字符 fill 来补全这一组字符。
注意,在去除最后一个组的填充字符 fill(如果存在的话)并按顺序连接所有的组后,所得到的字符串应该是 s 。
给你一个字符串 s ,以及每组的长度 k 和一个用于填充的字符 fill ,按上述步骤处理之后,返回一个字符串数组,该数组表示 s 分组后 每个组的组成情况 。
示例 1:
输入:s = “abcdefghi”, k = 3, fill = “x” 输出:[“abc”,”def”,”ghi”] 解释: 前 3 个字符是 “abc” ,形成第一组。 接下来 3 个字符是 “def” ,形成第二组。 最后 3 个字符是 “ghi” ,形成第三组。 由于所有组都可以由字符串中的字符完全填充,所以不需要使用填充字符。 因此,形成 3 组,分别是 “abc”、”def” 和 “ghi” 。
示例 2:
输入:s = “abcdefghij”, k = 3, fill = “x” 输出:[“abc”,”def”,”ghi”,”jxx”] 解释: 与前一个例子类似,形成前三组 “abc”、”def” 和 “ghi” 。 对于最后一组,字符串中仅剩下字符 ‘j’ 可以用。为了补全这一组,使用填充字符 ‘x’ 两次。 因此,形成 4 组,分别是 “abc”、”def”、”ghi” 和 “jxx” 。
提示:
- 1 <= s.length <= 100
- s 仅由小写英文字母组成
- 1 <= k <= 100
- fill 是一个小写英文字母
class Solution:
def divideString(self, s: str, k: int, fill: str) -> List[str]:
res = []
i = 0
while i < len(s):
res.append(s[i:i + k])
i += k
if len(res[-1]) < k:
res[-1] += fill * (k - len(res[-1]))
return res
5194. 得到目标值的最少行动次数
你正在玩一个整数游戏。从整数 1 开始,期望得到整数 target 。
在一次行动中,你可以做下述两种操作之一:
- 递增,将当前整数的值加 1(即, x = x + 1)。
- 加倍,使当前整数的值翻倍(即,x = 2 * x)。
在整个游戏过程中,你可以使用 递增 操作 任意 次数。但是只能使用 加倍 操作 至多maxDoubles 次。
给你两个整数 target 和 maxDoubles ,返回从 1 开始得到target需要的最少行动次数。
示例 1:
输入:target = 5, maxDoubles = 0 输出:4 解释:一直递增 1 直到得到 target 。
示例 2:
输入:target = 19, maxDoubles = 2 输出:7 解释:最初,x = 1 。 递增 3 次,x = 4 。 加倍 1 次,x = 8 。 递增 1 次,x = 9 。 加倍 1 次,x = 18 。 递增 1 次,x = 19 。
示例 3:
输入:target = 10, maxDoubles = 4 输出:4 解释: 最初,x = 1 。 递增 1 次,x = 2 。 加倍 1 次,x = 4 。 递增 1 次,x = 5 。 加倍 1 次,x = 10 。
提示:
- 1 <= target <= 109
- 0 <= maxDoubles <= 100
```python
class Solution:
def minMoves(self, target: int, maxDoubles: int) -> int:
res = 0 while True: if target == 1: return res elif target == 2: return res + 1 elif maxDoubles == 0: return res + target - 1 elif target % 2 == 0: target = target// 2 maxDoubles -= 1 res += 1 else: target -= 1 res += 1
<a name="Sq1S2"></a>
#### [5982. 解决智力问题](https://leetcode-cn.com/problems/solving-questions-with-brainpower/)
给你一个下标从 **0** 开始的二维整数数组 questions ,其中 questions[i] = [pointsi, brainpoweri] 。<br />这个数组表示一场考试里的一系列题目,你需要 **按顺序** (也就是从问题 0** **开始依次解决),针对每个问题选择 **解决** 或者 **跳过** 操作。解决问题 i 将让你 **获得** pointsi 的分数,但是你将 **无法** 解决接下来的 brainpoweri 个问题(即只能跳过接下来的 brainpoweri 个问题)。如果你跳过问题 i ,你可以对下一个问题决定使用哪种操作。<br />
- 比方说,给你 questions = [[3, 2], [4, 3], [4, 4], [2, 5]] :
- 如果问题 0 被解决了, 那么你可以获得 3 分,但你不能解决问题 1 和 2 。
- 如果你跳过问题 0 ,且解决问题 1 ,你将获得 4 分但是不能解决问题 2 和 3 。
请你返回这场考试里你能获得的 **最高** 分数。
**示例 1:**<br />**输入:**questions = [[3,2],[4,3],[4,4],[2,5]] **输出:**5 **解释:**解决问题 0 和 3 得到最高分。 - 解决问题 0 :获得 3 分,但接下来 2 个问题都不能解决。 - 不能解决问题 1 和 2 - 解决问题 3 :获得 2 分 总得分为:3 + 2 = 5 。没有别的办法获得 5 分或者多于 5 分。 <br />**示例 2:**<br />**输入:**questions = [[1,1],[2,2],[3,3],[4,4],[5,5]] **输出:**7 **解释:**解决问题 1 和 4 得到最高分。 - 跳过问题 0 - 解决问题 1 :获得 2 分,但接下来 2 个问题都不能解决。 - 不能解决问题 2 和 3 - 解决问题 4 :获得 5 分 总得分为:2 + 5 = 7 。没有别的办法获得 7 分或者多于 7 分。
**提示:**<br />
- 1 <= questions.length <= 105
- questions[i].length == 2
- 1 <= pointsi, brainpoweri <= 105
通过次数2,957<br />提交次数8,825
```python
class Solution:
def mostPoints(self, questions: List[List[int]]) -> int:
n = len(questions)
@cache
def dfs(cur):
if cur > n - 1:
return 0
if cur == n - 1:
return questions[n - 1][0]
score, jump = questions[cur]
return max(score +dfs(cur + jump + 1), dfs(cur + 1))
return dfs(0)
5. 最长回文子串
给你一个字符串 s,找到 s 中最长的回文子串。
示例 1:
输入:s = “babad” 输出:“bab” 解释:“aba” 同样是符合题意的答案。
示例 2:
输入:s = “cbbd” 输出:“bb”
示例 3:
输入:s = “a” 输出:“a”
示例 4:
输入:s = “ac” 输出:“a”
提示:
- 1 <= s.length <= 1000
- s 仅由数字和英文字母(大写和/或小写)组成
通过次数844,497
提交次数2,344,413
class Solution:
def longestPalindrome(self, s: str) -> str:
n = len(s)
if n == 1:
return s
res = ""
max_val = 0
@cache
def getParlidrome(l, r):
while l >= 0 and r < n:
if s[l] == s[r]:
l -= 1
r += 1
else:
break
return s[l + 1 : r]
for i in range(n):
res1 = getParlidrome(i, i) # 奇数
res2 = getParlidrome(i, i + 1) #偶数
if max(len(res1), len(res2)) > max_val:
max_val = max(len(res1), len(res2))
res = res1 if len(res1) > len(res2) else res2
return res
15. 三数之和
给你一个包含 n 个整数的数组 nums,判断 nums 中是否存在三个元素 a,b,c ,使得 _a + b + c = _0 ?请你找出所有和为 0 且不重复的三元组。
注意:答案中不可以包含重复的三元组。
示例 1:
输入:nums = [-1,0,1,2,-1,-4] 输出:[[-1,-1,2],[-1,0,1]]
示例 2:
输入:nums = [] 输出:[]
示例 3:
输入:nums = [0] 输出:[]
提示:
- 0 <= nums.length <= 3000
- -105 <= nums[i] <= 105
通过次数859,803
提交次数2,468,588
回溯超时
from collections import deque
class Solution:
def threeSum(self, nums: List[int]) -> List[List[int]]:
nums.sort()
visited = set()
def dfs(index, temp, arr):
if temp > 0 or len(arr) > 3:
return
if temp == 0 and len(arr) == 3:
visited.add(tuple(arr))
return
if len(arr) == 3:
return
for i in range(index, len(nums)):
arr.append(nums[i])
temp += nums[i]
dfs(i + 1, temp, arr)
arr.pop()
temp -= nums[i]
dfs(0, 0, deque([]))
ans = []
for i in visited:
ans.append([i[0], i[1], i[2]])
return ans
双指针
注意剪枝
class Solution:
def threeSum(self, nums: List[int]) -> List[List[int]]:
ans = []
nums.sort()
for i in range(len(nums) - 2):
if nums[i] > 0:
break
if i > 0 and nums[i] == nums[i - 1]:
continue
l = i + 1
r = len(nums) - 1
while l < r:
total = nums[i] + nums[l] + nums[r]
if total == 0:
ans.append([nums[i], nums[l], nums[r]])
while l < r and nums[l] == nums[l+1]:
l +=1
while l < r and nums[r] == nums[r-1]:
r -=1
l +=1
r -=1
elif total > 0:
r -= 1
else:
l += 1
return ans

若有收获,就点个赞吧
0 人点赞
