re模块操作
- 使用过程

- match方法
- 作用:从字符串的起始位置匹配正则表达式,如果没有找到返回None
- 语法格式:
re.match(pattern, string, flags=0)- pattern:匹配的正则表达式
- string:待匹配的字符串
- flags:标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等
- 可以使用group(num) 或 groups()来获取所匹配的字符串
- group(num=0):默认返回所匹配的整个表达式的字符串,也可以指定num的值从而返回对应的小组字符串
- groups():返回一个包含所有小组字符串的元组,从1到最大的小组号
- 示例

匹配单个字符
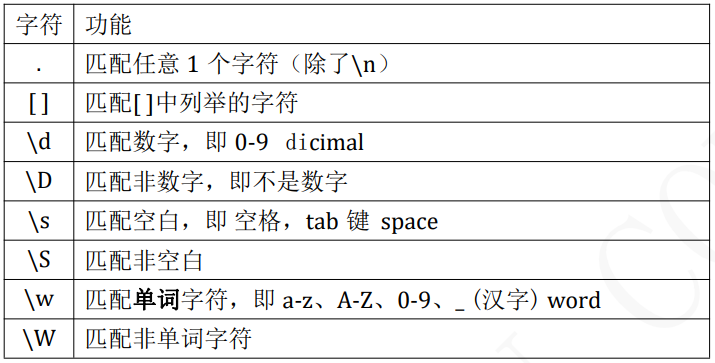
import reret = re.match(".", "M")print(ret.group()) # Mret = re.match("t.o", "too")print(ret.group()) # tooret = re.match("t.o", "two")print(ret.group()) # two
import re# 匹配大小写字母ret = re.match("[h]", "hello Python")print(ret.group()) # hret = re.match("[H]", "Hello Python")print(ret.group()) # Hret = re.match("[hH]", "hello Python")print(ret.group()) # hret = re.match("[hH]", "Hello Python")print(ret.group()) # Hret = re.match("[hH]ello Python", "Hello Python")print(ret.group()) # Hello Python# 匹配0到9的第一种写法ret = re.match("[0123456789]Hello Python", "7Hello Python")print(ret.group()) # 7Hello Python# 匹配0到9的第二种写法ret = re.match("[0-9]Hello Python", "7Hello Python")print(ret.group()) # 7Hello Pythonret = re.match("[0-35-9]Hello Python", "7Hello Python")print(ret.group()) # 7Hello Python# 下面这个正则表达式不能够匹配到数字4,因此ret为Noneret = re.match("[0-35-9]Hello Python", "4Hello Python")print(ret.group()) if ret else print("None") # None
import reret = re.match("嫦娥\d号", "嫦娥1号发射成功")print(ret.group()) # 嫦娥1号ret = re.match("嫦娥\d号", "嫦娥2号发射成功")print(ret.group()) # 嫦娥2号ret = re.match("嫦娥\d号", "嫦娥3号发射成功")print(ret.group()) # 嫦娥3号
匹配多个字符

import re# 要求:字符串的第一个字母是大写字母,后面都是小写字母并且数量是任意多个ret = re.match("[A-Z][a-z]*", "MM")print(ret.group()) # Mret = re.match("[A-Z][a-z]*", "MnnM")print(ret.group()) # Mnnret = re.match("[A-Z][a-z]*", "Aabcdef")print(ret.group()) # Aabcdef
import renames = ["name1", "_name", "2_name", "__name__"]for name in names:# 判断变量名是否有效ret = re.match("[a-zA-Z_]+[\w]*", name)if ret:print("%s符合要求" % ret.group()) # 0 1 3else:print("%s不符合要求" % name) # 2
import reret = re.match("[1-9]?[0-9]", "7")print(ret.group()) # 7ret = re.match("[1-9]?\d", "33")print(ret.group()) # 33ret = re.match("[1-9]?\d", "09")print(ret.group()) # 0
import reret = re.match("[a-zA-Z0-9_]{6}", "12a3g45678")print(ret.group()) # 12a3g4ret = re.match("[a-zA-Z0-9_]{8,20}", "1ad12f23s34455ff66")print(ret.group()) # 1ad12f23s34455ff66ret = re.match('[a-zA-Z0-9_]{4,20}@163.com', "luke1@163.com")print(ret.group()) # luke1@163.com
匹配开头结尾

import re# 判断是否是合法的163邮箱email_list = ["xiaoWang@163.com", "xiaoWang@163.comheihei", ".com.xiaowang@qq.com"]for email in email_list:ret = re.match("[\w]{4,20}@163\.com$", email)if ret:print("%s符合要求" % ret.group()) # 0else:print("%s不符合要求" % email) # 1 2# 判断是否不是以4、7结尾的11位手机号码tel_list = ["13100001234", "18912344321", "10086", "18800007777"]for tel in tel_list:ret = re.match("1\d{9}[0-35-68-9]$", tel)if ret:print("%s符合要求" % ret.group()) # 1else:print("%s不符合要求" % tel) # 0 2 3
匹配分组
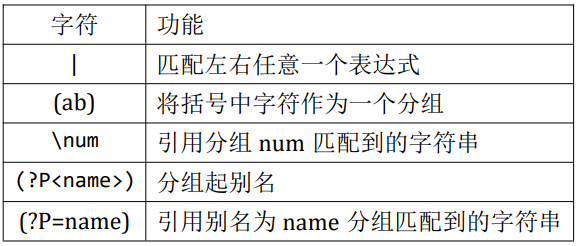
[^abc] —> 匹配除了a、b、c之外的字符
[^0-9] —> 匹配除了数字之外的字符
# 需求:匹配出0-100之间的数字import relist1 = ['0', '00', '08', '88', '100', '101']for item in list1:ret = re.match('[1-9]?\d$|100', item)if ret:print('{}在0-100之间'.format(ret.group())) # 0 88 100else:print('{}不在0-100之间'.format(item)) # 00 08 101
# 需求:匹配出163、126、qq邮箱import reemail_list = ["xiaoWang@163.com", "xiaoWang@qq.com", "xiaoWang@126.com","xiaoWang@163.comheihei", ".com.xiaowang@qq.com"]for email in email_list:ret = re.match('\w{4,20}@(163|126|qq)\.com$', email)if ret:print('{}符合要求'.format(ret.group())) # 0 1 2else:print('{}不符合要求'.format(email)) # 3 4
import re# 提取区号和电话号码ret = re.match('(\d+)-(\d+)', '010-66668888')if ret:print(ret.group()) # 010-66668888print(ret.group(1)) # 010print(ret.group(2)) # 66668888# ([^-]+)代表没有遇到小横杠-就一直匹配下去ret = re.match('([^-]+)-(\d+)', '我很帅abc123-66668888')if ret:print(ret.group()) # 我很帅abc123-66668888print(ret.group(1)) # 我很帅abc123print(ret.group(2)) # 66668888
import re
# 单个引用分组
ret = re.match("<[a-zA-Z]*>\w*</[a-zA-Z]*>", "<html>hh</html>")
print(ret.group()) if ret else print('None') # <html>hh</html>
ret = re.match("<[a-zA-Z]*>\w*</[a-zA-Z]*>", "<html>hh</htmlbalabala>")
print(ret.group()) if ret else print('None') # <html>hh</htmlbalabala>
ret = re.match(r"<([a-zA-Z]*)>\w*</\1>", "<html>hh</html>")
print(ret.group()) if ret else print('None') # <html>hh</html>
ret = re.match("<[a-zA-Z]*>\w*</\1>", "<html>hh</htmlbalabala>")
print(ret.group()) if ret else print('None') # None
# 多个引用分组
labels = ["<html><h1>www.cskaoyan.com</h1></html>",
"<html><h1>www.cskaoyan.com</h2></html>"]
for label in labels:
ret = re.match(r'<([a-z]+)><(\w*)>.*</\2></\1>', label)
if ret:
print("%s符合要求" % ret.group()) # 0
else:
print("%s不符合要求" % label) # 1
import re
# 给分组起别名,通过别名来引用分组
label1 = '<html><h1>www.cskaoyan.com</h1></html>'
label2 = '<html><h1>www.cskaoyan.com</h2></html>'
ret = re.match(r'<(?P<n1>\w*)><(?P<n2>\w*).*</(?P=n2)></(?P=n1)>', label1)
print(ret.group()) if ret else print('None') # '<html><h1>www.cskaoyan.com</h1></html>'
ret = re.match(r'<(?P<name1>\w*)><(?P<name2>\w*)>.*</(?P=name2)></(?P=name1)>', label2)
print(ret.group()) if ret else print('None') # None
# 注意:(?P<name>)和(?P=name)中的字母P需要大写
re模块的高级用法
search方法
- 作用:扫描整个字符串并返回第一个成功的匹配
- 语法格式:
re.search(pattern, string, flags=0) - match和search的区别:match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,返回None;而search匹配整个字符串,直到找到一个匹配 ```python import re
ret = re.search(r”\d+”, “阅读次数为9999”)
print(type(ret)) #
ret = re.search(r’(.) are (.?) .*’, “Cats are smarter than dogs”) if ret: print(ret.group()) # Cats are smarter than dogs print(ret.group(1)) # Cats print(ret.group(2)) # smarter else: print(“None”)
<a name="URDNF"></a>
### findall方法
- 作用:在字符串中找到正则表达式所匹配的所有子串,并返回一个列表。如果有多个匹配模式,则返回元组列表;如果没有找到匹配的,则返回空列表
- 语法格式:
- 方式一:`re.findall(pattern, string, flags=0)`
- 方式二:`pattern.findall(string[, pos[, endpos]])`
- pos:指定字符串的起始位置,默认为0
- endpos:指定字符串的结束位置,默认为字符串的长度
- 注意:返回值是列表,没有group方法
```python
import re
ret = re.findall(r'\d+', "python = 9999, c = 7890, c++ = 12345")
print(ret) # ['9999', '7890', '12345']
# 多个匹配模式,返回元组列表
result = re.findall(r'(\w+)=(\d+)', 'set width=20 and height=10')
print(result) # [('width', '20'), ('height', '10')]
finditer方法
- 和findall类似,在字符串中找到正则表达式所匹配的所有子串,区别是返回一个迭代器
- 语法格式:
re.finditer(pattern, string, flags=0)```python import re
it = re.finditer(r”\d+”, “12a32bc43jf3”) for match in it: print(match.group()) # 12 32 43 3
<a name="BM2nU"></a>
### sub方法
- 作用:替换字符串中的匹配项
- 语法格式:`re.sub(pattern, repl, string, count=0, flags=0)`
- pattern:匹配的正则表达式
- repl:替换的字符串,也可为一个函数
- string:要被查找替换的原始字符串
- count:替换的最大次数,默认值为0,表示替换所有的匹配
- flags:编译时用的匹配模式,数字形式
```python
import re
phone = "2004-959-559 # 这是一个电话号码"
# 删除注释
num = re.sub(r'#.*$', "", phone)
print(num) # 2004-959-559
# 移除非数字的内容
num = re.sub(r'\D', "", phone)
print(num) # 2004959559
ret = re.sub(r'\d+', '998', 'python 997')
print(type(ret)) # <class 'str'>
print(ret) # python 998
def add(temp):
str_num = temp.group()
num = int(str_num) + 5
return str(num)
ret = re.sub(r'\d+', add, 'python 997')
print(ret) # python 1002
ret = re.sub(r'\d+', lambda x: str(int(x.group()) + 5), 'python 997')
print(ret) # python 1002
split方法
- 作用:按照能够匹配的子串将字符串分割后,返回列表
- 语法格式:
re.split(pattern, string, maxsplit=0, flags=0)- pattern:匹配的正则表达式
- string:待匹配的字符串
- maxsplit:分割次数,默认值为0,表示不限制次数
- flags:标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等 ```python import re
ret = re.split(r”:| “, “info:xiaoZhang 33 shandong”) print(ret) # [‘info’, ‘xiaoZhang’, ‘33’, ‘shandong’]
<a name="xWDC9"></a>
### compile方法
- 作用:用于编译震泽表达式,生成一个正则表达式对象,供match()和search()这两个方法使用
- 语法格式:`re.compile(pattern[, flags])`
- pattern:一个字符串形式的正则表达式
- flags:标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等
```python
import re
pattern = re.compile(r'\d+') # 查找数字
print(pattern.findall('runoob 123 google 456')) # ['123', '456']
print(pattern.findall('run88oob123google456', 0, 10)) # ['88', '12']
贪婪和非贪婪
- Python里数量词默认是贪婪的,总是尝试匹配尽可能多的字符;非贪婪则相反,总是尝试匹配尽可能少的字符
- 在 ‘*’、’+’、’?’、’{m,n}’ 后面加上 ?,使贪婪变成非贪婪
- 举例

说明:第一个例子中,’+’ 会从字符串的开始处抓取满足模式的最长字符,而 ‘\d+’ 只需要一位字符就可以匹配,所以它匹配了数字4,而 ‘.+’ 则匹配了从字符串开始处到这个第一位数字4之前的所有字符。第二个例子中,’+?’ 会从字符串的开始处抓取满足模式的最短字符,那就是一个也不匹配,所以后面的 ‘\d+’ 匹配了234
import re
print(re.match(r"aa(\d+)", "aa2343ddd").group(1)) # 2343
print(re.match(r"aa(\d+?)", "aa2343ddd").group(1)) # 2
print(re.match(r"aa(\d+)ddd", "aa2343ddd").group(1)) # 2343
print(re.match(r"aa(\d+?)ddd", "aa2343ddd").group(1)) # 2343
r的作用
- 正则表达式里使用 ‘\’ 作为转义字符,这就可能造成反斜杠困扰。如果你需要匹配文本中的字符 ‘\’,那么使用编程语言表示的正则表达式里将需要四个反斜杠 ‘\\‘,前两个和后两个分别用于在编程语言里转义成一个反斜杠,转换后的得到的两个反斜杠再在正则表达式里专业成一个反斜杠
- Python中字符串前面加上 r 表示原生字符串,有了原生字符串,再也不用担心是不是漏写了反斜杠,写出来的表达式也更直观
- 注意:r 只服务与 ‘\’,不对其他进行转义 ```python import re
mm = “c:\a\b\c”
print(mm) # c:\a\b\c
print(re.match(“c:\\“, mm).group()) # c:\
print(re.match(“c:\\a”, mm).group()) # c:\a
print(re.match(r”c:\a”, mm).group()) # c:\a
print(re.match(r”c:\“, mm).group()) # c:\
print(re.match(r”c:\a”, mm).group())
AttributeError: ‘NoneType’ object has no attribute ‘group’
<a name="WYrIQ"></a>
## 正则表达式的可选标志
正则表达式可以包含一些可选标志修饰符来控制匹配的模式,修饰符被指定为一个可选的标志,多个标志可以通过 | 来指定,例如 re.I | re.M 被设置成 I 和 M 标志<br />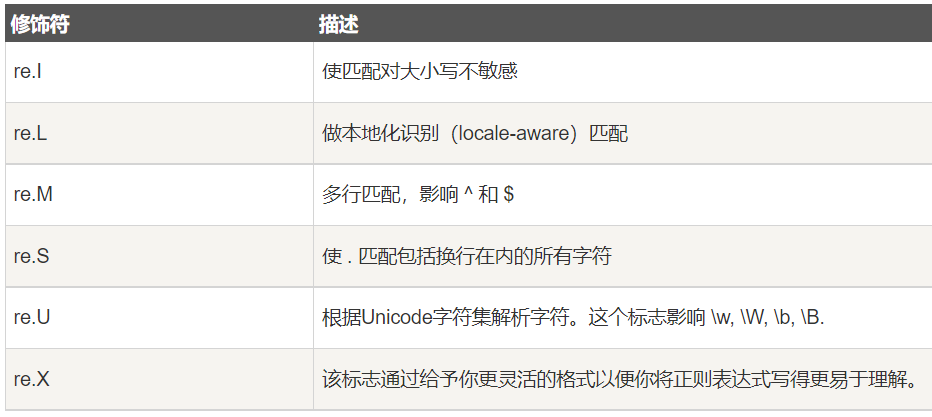
```python
import re
ret = re.match(r'a', 'A', re.I) # 不区分大小写
print(ret.group())
ret = re.match(r'.bc', '\nbc', re.S) # 使.匹配包括换行在内的所有字符
print(ret.group())

若有收获,就点个赞吧
0 人点赞
