列表
列表的定义
- 列表是Python中使用最频繁的数据类型,相当于其他语言中的数组
- 列表用 [ ] 定义,数据项之间使用逗号分隔,列表的数据项不需要具有相同的类型
- 创建一个列表,只需要把逗号分隔的不同的数据项使用方括号括起来即可
- 索引又被称为下标,列表的索引从 0 开始;也可以从尾部开始,最后一个元素的索引是 -1,往前一位是 -2
- 注意:从列表中取值时,如果超出索引范围,程序会报错
- 说明:尽管列表中可以存储不同类型的数据,但是在开发中,更多的应用场景是
- 列表存储相同类型的数据
- 通过迭代遍历,在循环体内部,针对列表中的每一项元素,执行相同的操作
注意:列表中把 True 当做 1,把 False 当做 0
列表的常用操作
增加
- 列表.insert(索引,数据):在指定索引处插入数据
- 列表.append(数据):在末尾追加数据
- 列表1.extend(列表2):将列表2的所有数据追加到列表1的末尾
- 列表1 += 列表2:等价于列表1.extend(列表2)
- 修改
- 列表[索引] = 数据:修改指定索引处的数据
- 删除
- 列表.remove[数据]:删除第一个出现的指定数据
- 列表.pop():删除末尾的数据,并且返回该数据的值
- 列表.pop(索引):删除指定索引处的数据,并且返回该数据的值
- del 列表[索引]:删除指定索引处的数据
- del 列表:删除整个列表,再访问会报错
- 列表.clear():清空列表
- 统计
- len(列表):得到列表长度
- max(列表):得到列表元素的最大值
- min(列表):得到列表元素的最小值
- 列表.count(数据):得到指定数据在列表中的出现次数
- 列表.index(数据):得到指定数据在列表中第一次出现的位置处的索引
排序
元组和列表类似,不同之处在于元组的元素不能修改
- 元组使用小括号( )定义,列表使用方括号[ ]定义
创建一个元组,只需要把逗号分隔的不同的数据项使用小括号括起来即可
增加:不允许
- 修改
- 元组中的数据是不允许修改的,比如 tup[0] = 10 是非法的
- 但是可以对旧的元组进行拼接操作,然后赋值给一个新的元组,比如 tup3 = tup1 + tup2
- 删除
- 元组中的数据也不允许删除,但可以使用 del 语句删除整个元组,比如 del tup,但是需要注意,元组被整个删除后,再访问元组会有异常信息
- 统计
- len(元组):得到元组长度
- max(元组):得到元组元素的最大值
- min(元组):得到元组元素的最小值
- 元组.count(数据):得到指定数据在元组中的出现次数
- 元组.index(数据):得到指定数据在元组中第一次出现的位置处的索引
-
元组的应用
函数可以有多个返回值,接收多个返回值的一个数据即是元组类型
- 格式化字符串后面的 ( ) 本质上就是一个元组 ```python info_tuple = (“小明”, 21, 1.85) print(“%s 年龄是 %d 身高是 %.2f” % info_tuple)
info_str = “%s 年龄是 %d 身高是 %.2f” % info_tuple print(info_str)
- 让列表不可以被修改,以保护数据安全<a name="Zd8RZ"></a>### 列表和元组之间的转换(可拓展)- 使用list函数可以把元组转换成列表:list1 = list(tuple1)- 使用tuple函数可以把列表转换成元组:tuple1 = tuple(list1)<a name="TzBzJ"></a>## 字典<a name="Pct8S"></a>### 字典的定义- 字典是Python中除列表之外最灵活的数据类型- 字典通常用于存储描述一个物体的相关信息- 字典中的数据是无序的- 字典用 { } 定义,使用键值对存储数据,键值对之间使用逗号分隔- 键key是索引,必须是不可变类型,往往是字符串- 注意:键必须是唯一的,如果创建时同一个键被赋值两次,后一个值才会被记住- 值value是数据,可以是任意数据类型- 键和值之间使用 : 分隔- 创建空字典的两种方式- dict1 = { }- dict1 = dict(),dict()是内置函数- 说明:dict是Python的关键字和内置函数,变量名不建议命名为dict<a name="Ad0u1"></a>### 字典的常用操作- 访问- 字典[键]:返回指定键对应的值,如果字典里没有该键会报错- 字典.get(键):返回指定键对应的值,如果字典里没有该键返回None- 字典.get(键,默认值):返回指定键对应的值,如果字典里没有该键返回默认值- 字典.keys():返回一个由键组成的视图对象,形如dict_keys(['height', 'age', 'ID'])- 字典.values():返回一个由值组成的视图对象,形如dict_values([1.75, 20, 333])- 字典.items():返回一个由键值对组成的视图对象,形如dict_items([('height', 1.75), ('age', 20), ('ID', 333)])- 增加 / 修改- 字典[键] = 值:如果键不存在,会新增键值对;如果键存在,会修改已经存在的键值对- 字典.setdefault(键, 值):对应键不存在的时候增加,存在时不修改- 字典1.update(字典2):用字典2中的同key键值对覆盖字典1中的同key键值对,字典2未修改- 删除- 字典.pop(键):删除指定键值对,并返回指定键对应的值- 注意:如果指定的键不存在,会报错- 字典.pop(键, 默认值):删除指定键值对,并返回指定键对应的值- 注意:如果指定的键不存在,不会报错,此时返回默认值- 字典.popitem():返回并删除字典中的最后一对键值对- del 字典[键]:删除指定键值对,没有返回值- del 字典:删除整个字典,再访问会报错- 字典.clear():清空字典,再访问不会报错- 统计- len(字典):得到字典长度- 其他- 字典.copy():返回一个拷贝的字典,id不同了- dict.fromkeys(列表, val):创建一个新字典,以列表中的元素作为字典的键,val作为所有键对应的初始值<a name="YeanM"></a>### 遍历字典```pythondict1 = {'Alice': 20, 'Beth': 18, 'Cecil': 21}# 方法一for item in dict1:print("%s: %d" % (item, dict1[item]))# 方法二for k, v in dict1.items():print("%s: %d" % (k, v))
集合
集合的定义
- 集合是一个无序的不重复元素序列
- 可以使用大括号 { } 或者 set( ) 函数创建集合
- 注意:创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典
- 举例

集合的常用操作
- 增加
- 集合.add(数据):为集合添加指定的数据
- 注意:只能增加一个数据,且数据类型不能是列表、元组、字典、集合,否则会报错
- 集合.update(数据):为集合添加指定的数据
- 注意:可以增加任意类型的数据,如果该数据是复杂数据类型,会将该数据分割成一个个单元数据
- 集合.add(数据):为集合添加指定的数据

- 修改
- 删除
- 集合.discard(数据):删除集合中指定的数据,没找到不报错
- 集合.remove(数据):删除集合中指定的数据,没找到会报错
- 集合.pop():随机删除集合中的一个数据
- 集合1.difference_update(集合2, 集合3, …):删除集合1中在其他集合中也出现的元素
- 集合1.symmetric_difference_update(集合2):删除集合1中在集合2中也出现的元素,并且将集合2中出现但在集合1中未出现的元素增加到集合1中
- 集合.clear():清空集合
其他
- 集合1.difference(集合2, 集合3, …):返回集合1和其他集合的差集,赋值给新的集合
- 集合1.intersection(集合2, 集合3, …):返回集合1和其他集合的交集,赋值给新的集合
- 集合1.union(集合2, 集合3, …):返回集合1和其他集合的并集,赋值给新的集合
- 集合1.symmetric_difference(集合2):返回集合1和集合2中不重复的元素集合,赋值给新的集合,参数只能有一个
- 集合.copy():返回一个拷贝的集合,id不同了
- 集合1.isdisjoint(集合2):判断集合1和集合2是否包含相同的元素,如果没有包含相同的元素返回True,如果有相同的元素返回False
- 集合1.issubset(集合2):判断集合1是否是集合2的子集,如果是返回True,如果不是返回False
- 集合1.issuperset(集合2):判断集合2是否是集合1的子集,如果是返回True,如果不是返回False
字符串
字符串的定义
字符串是Python中最常用的数据类型,可使用一对双引号或者一对单引号来定义一个字符串
- 虽然可以使用 \” 或者 \’ 定义一个字符串,但是在实际开发中
- 如果字符串内部需要使用 “,则使用 ‘ 定义字符串
- 如果字符串内部需要使用 ‘,则使用 “ 定义字符串
- 虽然可以使用 \” 或者 \’ 定义一个字符串,但是在实际开发中
Python不支持单字符类型,单字符在Python中也是作为一个字符串使用
字符串的常用操作
判断
- 字符串.isspace():如果字符串只包含空格,则返回True
- 字符串.isalnum():如果字符串至少有一个字符并且所有字符都是字母或数字则返回True
- 字符串.isalpha():如果字符串至少有一个字符并且所有字符都是字母则返回True
- 字符串.isdecimal():如果字符串至少有一个字符并且所有字符都是十进制数字则返回True
- 字符串.isdigit():如果字符串至少有一个字符并且所有字符都是数字则返回True
- 字符串.isnumeric():如果字符串只包含数字字符,则返回True
- 字符串.islower():如果字符串包含至少一个区分大小写的字符,并且所有这些区分大小写的字符都是小写,则返回True
- 字符串.isupper():如果字符串包含至少一个区分大小写的字符,并且所有这些区分大小写的字符都是大写,则返回True
- 查找和替换
- len(字符串):返回字符串的长度
- max(字符串):返回字符串中的最大字符
- min(字符串):返回字符串中的最小字符
- 字符串1.startswith(字符串2):检查字符串1是否以字符串2开头,如果是则返回True
- 字符串1.endswith(字符串2):检查字符串1是否以字符串2结束,如果是则返回True
- 字符串1.find(字符串2, start=0, end=len(字符串1) ):检查字符串1是否包含字符串2,如果指定范围start和end,则检查在指定范围内是否包含。如果包含则返回开始的索引值,否则返回-1
- 字符串1.rfind(字符串2, start=0, end=len(字符串1) ):类似于find函数,不过是从右边开始查找
- 字符串1.index(字符串2, start=0, end=len(字符串1) ):类似于find函数,区别在于如果字符串2不在字符串1中会报错
- 字符串1.rindex(字符串2, start=0, end=len(字符串1) ):类似于rindex函数,区别在于如果字符串2不在字符串1中会报错
- 字符串1.count(字符串2, start=0, end=len(字符串1)):返回字符串2在字符串1中出现的次数,可以指定范围start和end
- 字符串.replace(old_str, new_str, num=字符串.count(old_str)):把字符串中的old_str替换成new_str,如果num指定,则替换不超过num次
- 大小写转换
- 字符串.capitalize():把字符串的第一个字母大写
- 字符串.title():将字符串标题化,即每个单词以大写字母开始,其余字母均为小写
- 字符串.lower():把字符串中的所有大写字母转换为小写
- 字符串.upper():把字符串中的所有小写字母转换为大写
- 字符串.swapcase():把字符串的大写字母转换为小写,小写字母转换为大写
- 文本对齐
- 字符串.ljush(width):返回一个原字符串左对齐,并使用空格填充至长度width的新字符串
- 字符串.rjush(width):返回一个原字符串右对齐,并使用空格填充至长度width的新字符串
- 字符串.center(width):返回一个原字符串居中,并使用空格填充至宽度width的新字符串
- 字符串.zfill(width):返回一个原字符串右对齐,并使用0补充至长度width的新字符串
- 去除空白字符
- 字符串.lstrip(char):截掉字符串左边的空格,也可以指定字符
- 字符串.rstrip(char):截掉字符串右边的空格,也可以指定字符
- 字符串.strip(char):截掉字符串左右两边的空格,也可以指定字符
- 拆分和连接
- 字符串.partition(str):把字符串分隔成一个三元素的元组(str前面, str, str后面)
- 字符串.rpartition(str):类似于partition()方法,不过是从右边开始查找
- 字符串.split(str=’’, num):以str为分隔符拆分字符串,如果num有指定值,则仅分隔成 num + 1 个字符串,str默认包含空格
- 字符串.splitlines():按照行(‘\r’, ‘\r\n’, \n’)分隔,返回一个包含各行作为元素的列表,如果参数 keepends 为 False,不包含换行符,如果为 True,则保留换行符
- 字符串.join(seq):以指定字符串作为连接符,将seq中的所有字符以指定字符串连接成一个新的字符串
其他
len(item):计算容器中元素个数
- del(item) 或者 del item:删除变量
- max(item):返回容器中元素的最大值
- 注意:一般不用于字典,如果是字典,值针对 key 比较
-
索引
对于字符串、列表和元组,索引值以 0 作为开始值,以 -1 作为从末尾的开始位置,用法为:变量[索引]
- 对于字典:用法为:字典[键值]
对于集合,由于集合存储的是无序元素,且没有键值对,因此没法通过索引访问集合中的元素,只能判断某个元素是否在集合中
切片
切片适用于字符串、列表、元组,而字典和集合是无序的,不能使用切片
- 切片的使用:item[开始索引 : 结束索引 : 步长]
- 指定的区间属于左闭右开型,即从开始索引开始,到结束索引的前一位结束
- 如果从头开始,则开始索引可以省略,但是冒号不能省略
- 如果到末尾结束,则结束索引可以省略,但是冒号不能省略
- 步长默认是1,如果连续切片,冒号和步长都能省略
- 在Python中,不仅支持顺序索引,同时还支持倒序索引
- 所谓倒序索引就是从右往左计算索引
- 最右边的索引值是 -1,往左依次递减
一些例子
+:拼接,适用于字符串、列表、元组
- 字符串:”Hello” + “World” = “HelloWorld”
- 列表:[1, 2, 3] + [4, 5, 6] = [1, 2, 3, 4, 5, 6]
- 元组:(1, 2, 3) + (4, 5, 6) = (1, 2, 3, 4, 5, 6)
- *:重复,适用于字符串、列表、元组
- 字符串:”Hello” * 2 = “HelloHello”
- 列表:[“Hi”] * 4 = [“Hi”, “Hi”, “Hi”, “Hi”]
- 元组:(“Hi”, ) * 4 = (“Hi”, “Hi”, “Hi”, “Hi”)
- in:判断元素是否存在,适用于字符串、列表、元组、字典、集合
- not in:判断元素是否不存在,适用于字符串、列表、元组、字典、集合
- 说明:in 在对字典操作时,判断的是字典的键
- in 和 not in 被称为成员运算符
生成式
列表生成式
格式
- [表达式 for 变量 in 列表]
- [表达式 for 变量 in 列表 if 条件]
举例
元组生成式和列表生成式的用法完全相同,只是元组生成式是用圆括号( )将各部分括起来,而列表生成式用的是中括号[ ],另外元组表达式返回的结果是一个生成器对象,因此需要使用 tuple( ) 将该生成器对象转换成元组
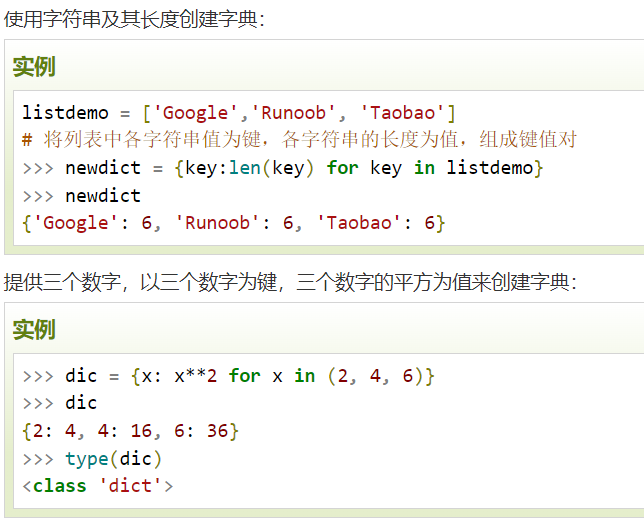
字典生成式
格式
- { key_expr: value_expr for value in collection }
- { key_expr: value_expr for value in collection if condition }
- 举例

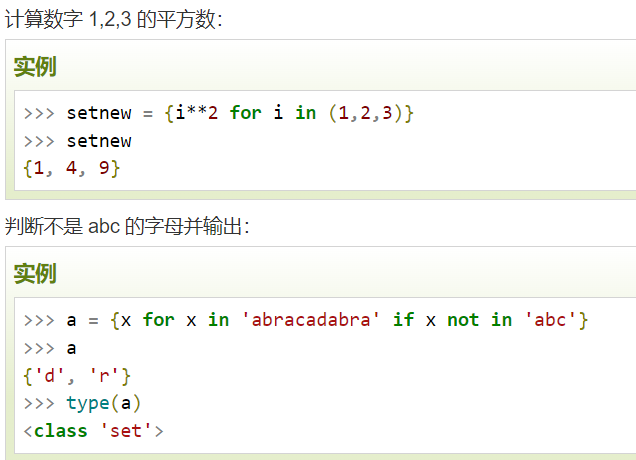
集合生成式
- 集合生成式和列表推导式的用法完全相同,只是集合推导式是用花括号{ }将各部分括起来,而列表推导式用的是中括号[ ]
- 举例
补充
zip的用法
a = (1, 2, 3)
b = ('a', 'b', 'c')
print(list(zip(a, b)) # [(1, 'a'), (2, 'b'), (3, 'c')]
print(tuple(zip(a, b)) # ((1, 'a'), (2, 'b'), (3, 'c'))
enumerate的用法
seasons = ['Spring', 'Summer', 'Fall', 'Winter']
print(list(enumerate(seasons)))
# [(0, 'Spring'), (1, 'Summer'), (2, 'Fall'), (3, 'Winter')]
print(tuple(enumerate(seasons)))
# ((0, 'Spring'), (1, 'Summer'), (2, 'Fall'), (3, 'Winter'))
for i, v in enumerate(seasons):
print(i, v)
'''
0 Spring
1 Summer
2 Fall
3 Winter
'''

若有收获,就点个赞吧
0 人点赞
