数据框构建
1 读取文件
import pandas as pddf = pd.read_csv('test.csv')
2 手动构建
# 从字典构建df = pd.DataFrame({'name': ['luffy', 'zoro'], 'age': [18, 19] })# 从列表/数组构建df = pd.DataFrame([['luffy', 18], ['zoro', 19]], columns=['name', 'age'])# 设置header或替换headerdf = pd.DataFrame([['luffy', 18], ['zoro', 19]])df.set_axis(['name', 'age'], axis='columns', inplace=True)# 构建空数据框,后添加数据df = pd.DataFrame()df['name'] = ['luffy', 'zoro']df['age'] = [18, 19]
数据框截取
# 获取某一列df.name# ordf['name']# 获取多列, 或重新排列df[['name', 'age']]# ordf.filter(items=['name', 'age'], axis=1) # or axis='columns'# 注意# - axis=0 or 'index' 按行(索引)# - axis=1 or 'columns' 按列# 获取前/后N行df.head(N)df.tail(N)
数据框连接(concat)
pd.concat(df1, df2)
数据框合并(merge)
df1 = pd.DataFrame({'name': ['luffy', 'zoro'], 'age': [18, 19]})df2 = pd.DataFrame({'name': ['luffy', 'sanji'], 'like': ['meat', 'beauty']})df3 = pd.DataFrame({'uid': ['luffy', 'sanji'], 'like': ['meat', 'beauty']})pd.merge(df1, df2)# ordf1.merge(df2)# how: {'left', 'right', 'outer', 'inner'}df1.merge(df2, how='left') # 左连接,没有的补NaN# on: 指定合并的关键字df1.merge(df2, on='name')# left_on, right_on:当两个关键字不一致时df1.merge(df3, left_on='name', right_on='uid', how='left')
数据框过滤
df.loc
df.loc[exp] == df[exo] 多条件过滤用
&连接,而不是&&
# 单条件过滤df[df.name == 'luffy']df.loc[df.name == 'luffy']df[df.age > 18]# 多条件过滤df[(df.name=='zoro') & (df.age > 18)]
df.filter
df = pd.DataFrame({'name': ['luffy', 'zoro'], 'age': [18, 19] })# 按行的index过滤df.filter(items=[1, 3], axis=0)# 重新设置索引df1 = df.set_index('name')# items: 完全匹配df1.filter(items=['luffy'], axis='index')# like: 部分匹配df1.filter(like='ffy', axis='index')# regex: 正则匹配df1.filter(regex='ffy$', axis='index'
.isin
# 使用给定的列表过滤name列name_list = ['luffy', 'nami', 'robin']df[df.name.isin(name_list)]# 组合条件df[df.name.isin(name_list) & (df.age>=18)]
.fillna
# 替换NaN为指定字符df.fillna('.')
数据框header重命名
df = pd.DataFrame({'name': ['luffy', 'zoro'], 'age': [18, 19] })# 使用字典映射df.rename(index=str, columns={'name': 'Name', 'age': 'Age'})# ordf.rename(str, columns={'name': 'Name', 'age': 'Age'}# ordf.rename(columns={'name': 'Name', 'age': 'Age'}# 使用函数df.rename(str.upper, axis='columns')
数据框每列最大宽度设置
当一列的字符长度过长时,默认会显示不完整(只是显示,并非实际)
# 获取pd.get_option('max_colwidth') # default 50# orpd.options.display.max_colwidth# 设置pd.set_option('max_colwidth', 200)# orpd.options.display.max_colwidth = 200
数据框按条件转换数据
.apply
针对某一列进行
url = 'http://rest.kegg.jp/list/hsa:100750326+hsa:100422907'df = pd.read_csv(url, sep='\t', names=['geneid', 'symbol'])

import redf.symbol.apply(lambda x: re.split(r',|;', x, 1)[0])symbol = df.symbol.apply(lambda x: re.split(r',|;', x, 1)[0])alias = df.symbol.apply(lambda x: re.split(r',|;', x, 1)[1])df.symbol = symboldf['alias'] = alias

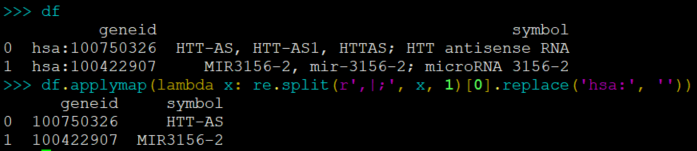
.applymap
针对真个数据框的每个值
df.applymap(lambda x: re.split(r',|;', x, 1)[0].replace('hsa:', ''))

若有收获,就点个赞吧
0 人点赞
