Querying JPA
Querydsl 定义了一个通用静态类型的语法用于查询持久化的领域模型数据。JDO 和 JPA 是 Querydsl 主要的集成技术。这篇手册介绍了如何让Querydsl与JPA整合使用。
Querydsl JPA 是JPQL和标准条件查询(Criteria queries)的新的使用方式。它结合了条件查询的动态性和JPQL的表达能力,并且使用了完全的类型安全方式。
- JDO:Java数据对象(Java Data Object,JDO)是一个用于存取某种数据仓库中的对象的标准化API,它使开发人员能够间接的访问数据库。
JDO是JDBC的一个补充,它提供了透明的对象存储 - JPA:JPA是Java Persistence API的简称,中文名Java持久层API
- JPQL:JPQL 语言,即 Java Persistence Query Language 的简称。JPQL 和 HQL 是非常类似的,支持以面向对象的方式来写 SQL 语句,当然也支持本地的 SQL 语句。JPQL 最终会被编译成针对不同底层数据库的 SQL 查询从而屏蔽掉不同数据库的差异。
Maven 集成QueryDSL
在你的maven项目中添加下面的依赖:
<dependency><groupId>com.querydsl</groupId><artifactId>querydsl-apt</artifactId><version>${querydsl.version}</version><scope>provided</scope></dependency><dependency><groupId>com.querydsl</groupId><artifactId>querydsl-jpa</artifactId><version>${querydsl.version}</version></dependency><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId><version>1.6.1</version></dependency>
现在,来配置 maven APT 插件:
<project><build><plugins>...<plugin><groupId>com.mysema.maven</groupId><artifactId>apt-maven-plugin</artifactId><version>1.1.3</version><executions><execution><goals><goal>process</goal></goals><configuration><outputDirectory>target/generated-sources/java</outputDirectory><processor>com.querydsl.apt.jpa.JPAAnnotationProcessor</processor></configuration></execution></executions></plugin>...</plugins></build></project>
JPAAnnotationProcessor 查找带有 @javax.persistence.Entity 注解的领域类型并为其生成查询类型。
如果你在领域类型中使用的是Hibernate的注解,那应该使用 APT 处理器 com.querydsl.apt.hibernate.HibernateAnnotationProcessor 来代替 JPAAnnotationProcessor。
运行 clean install 命令后,在 target/generated-sources/java 目录下将生成相应的查询类型。
如果你使用Eclipse,运行 mvn eclipse:eclipse 更新你的Eclipse项目,将 target/generated-sources/java 作为源目录。
现在,你就可以构建 JPA 查询实例和查询领域模型的实例了
要使用Querydsl创建查询,您需要实例化变量和查询实现。我们从变量开始。
构建数据库信息
配置文件
spring.datasource.driver-class-name=org.postgresql.Driverspring.datasource.url=jdbc:postgresql://127.0.0.1:5432/demo_querydsl?currentSchema=publicspring.datasource.username=postgresspring.datasource.password=aaaaaaspring.jpa.show-sql=truespring.jpa.hibernate.ddl-auto=update
创建实体
(1)员工实体类Employee
@Entity@Table(name = "employee")@Datapublic class Employee {@Id@GenericGenerator(name = "idGeneratorUUID",strategy = "uuid")@GeneratedValue(generator = "idGeneratorUUID")private String id;/**员工名称*/private String name;/**员工性别*/private int gender;/**员工电话*/private String phone;/**所在公司ID*/private String companyId;/**员工年龄*/private Integer age;}
(2)公司实体类 Company
@Entity@Table(name = "company")@Datapublic class Company{@Id@GenericGenerator(name = "idGeneratorUUID",strategy = "uuid")@GeneratedValue(generator = "idGeneratorUUID")private String id;/**公司名称*/private String name;/**公司所在城市*/private String city;}
生成Q类
之前有提到:JPAAnnotationProcessor 会查找带有 @javax.persistence.Entity 注解的领域类型并为其生成查询类型,即Q类。
执行maven complile 将会在 target/generated-sources/java 目录下将生成相应的Q类,如下: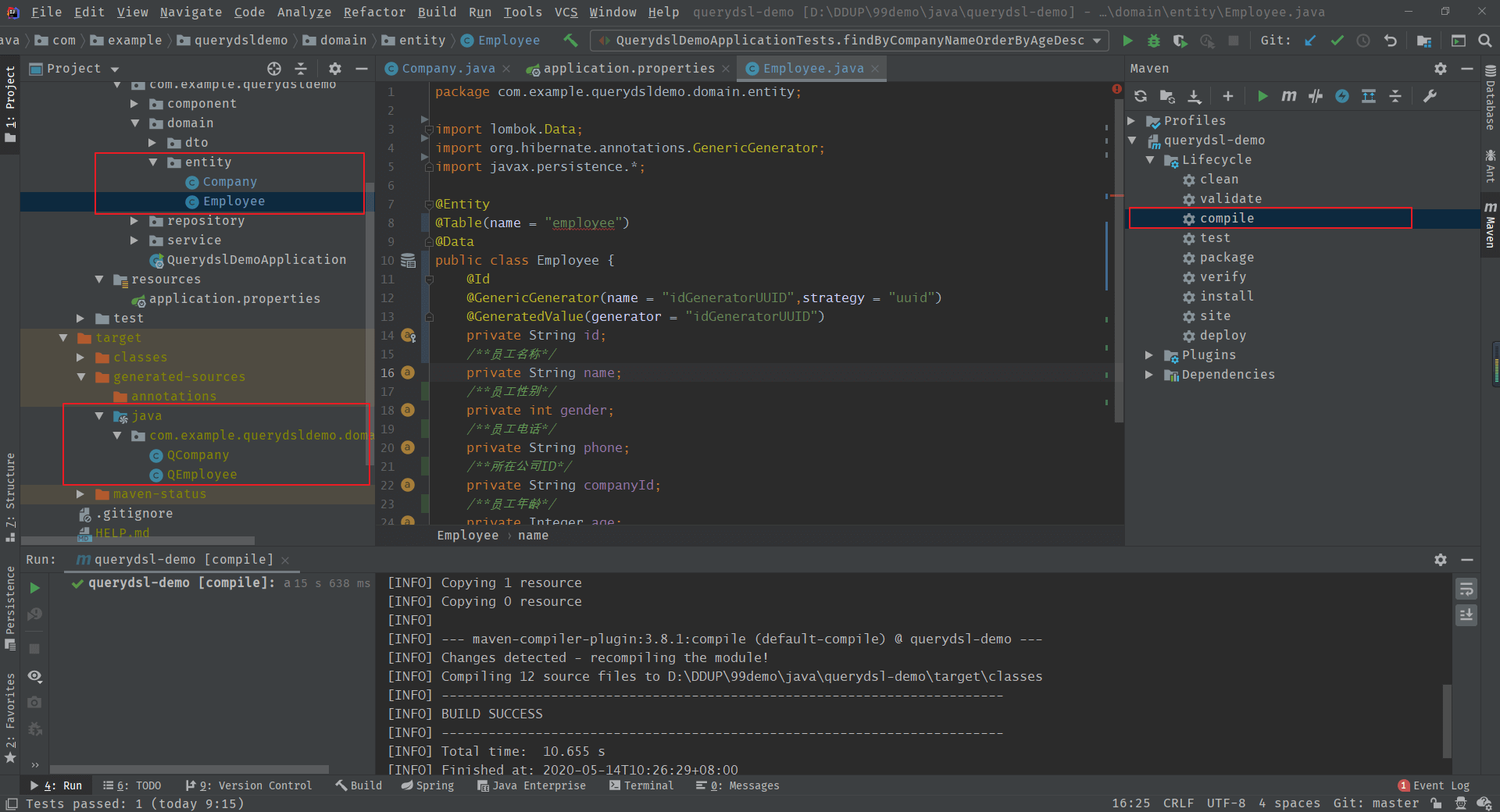
单表简单查询
@Autowiredprivate JPAQueryFactory jpaQueryFactory;private QCompany qCompany = QCompany.company;private QEmployee qEmployee = QEmployee.employee;
获取全部员工信息
@Testpublic void findAll(){JPAQuery<Employee> jpaQuery = jpaQueryFactory.selectFrom(qEmployee);List<Employee> employees = jpaQuery.fetch();System.out.println("员工信息如下:");for (Employee employee : employees) {System.out.println("------分割线------");System.out.println(employee.toString());}}
执行查询:
Hibernate:selectemployee0_.id as id1_1_,employee0_.age as age2_1_,employee0_.company_id as company_3_1_,employee0_.gender as gender4_1_,employee0_.name as name5_1_,employee0_.phone as phone6_1_from employee employee0_
输出:
员工信息如下:------分割线------Employee(id=1, name=李白, gender=1, phone=10086, companyId=1, age=22)------分割线------Employee(id=3, name=孙尚香, gender=0, phone=10011, companyId=1, age=23)------分割线------Employee(id=2, name=张飞, gender=1, phone=10010, companyId=1, age=20)------分割线------Employee(id=4, name=孙悟空, gender=1, phone=00001, companyId=2, age=89)------分割线------Employee(id=5, name=刘备, gender=1, phone=11111, companyId=1, age=25)------分割线------Employee(id=6, name=复苏刘, gender=0, phone=12123, companyId=2, age=10)
根据员工ID
@Testpublic void findById() {String id = "1";JPAQuery<Employee> jpaQuery = jpaQueryFactory.selectFrom(qEmployee).where(qEmployee.id.eq(id));//.selectFrom(entity) == .select(entity).from (entity)Employee employee = jpaQuery.fetchOne();if (employee ==null) {System.out.println("ID为" + id + "的员工不存在!");} else {System.out.println("员工信息:"+employee.toString());}}
执行查询:
Hibernate:selectemployee0_.id as id1_1_,employee0_.age as age2_1_,employee0_.company_id as company_3_1_,employee0_.gender as gender4_1_,employee0_.name as name5_1_,employee0_.phone as phone6_1_from employee employee0_where employee0_.id=?
输出:
员工信息:Employee(id=1, name=李白, gender=1, phone=10086, companyId=1, age=22)
根据员工性别进行查询
@Testpublic void findByGender() {int gender = 1;//男JPAQuery<Employee> jpaQuery = jpaQueryFactory.selectFrom(qEmployee).where(qEmployee.gender.eq(gender)).distinct();List<Employee> employees = jpaQuery.fetch();System.out.println("员工信息如下:");for (Employee employee : employees) {System.out.println("------分割线------");System.out.println(employee.toString());}}
执行查询:
Hibernate: select distinct employee0_.id as id1_1_, employee0_.age as age2_1_, employee0_.company_id as company_3_1_, employee0_.gender as gender4_1_, employee0_.name as name5_1_, employee0_.phone as phone6_1_ from employee employee0_ where employee0_.gender=?
输出:
员工信息如下:------分割线------Employee(id=1, name=李白, gender=1, phone=10086, companyId=1, age=22)------分割线------Employee(id=2, name=张飞, gender=1, phone=10010, companyId=1, age=20)------分割线------Employee(id=4, name=孙悟空, gender=1, phone=00001, companyId=2, age=89)------分割线------Employee(id=5, name=刘备, gender=1, phone=11111, companyId=1, age=25)
根据员工名称模糊查询
@Testpublic void findByLikeName() {String name = "%刘%";//男JPAQuery<Employee> jpaQuery = jpaQueryFactory.selectFrom(qEmployee).where(qEmployee.name.like(name)).distinct();List<Employee> employees = jpaQuery.fetch();System.out.println("员工信息如下:");for (Employee employee : employees) {System.out.println("------分割线------");System.out.println(employee.toString());}}
执行查询:
Hibernate:select distinctemployee0_.id as id1_1_,employee0_.age as age2_1_,employee0_.company_id as company_3_1_,employee0_.gender as gender4_1_,employee0_.name as name5_1_,employee0_.phone as phone6_1_from employee employee0_where employee0_.name like ? escape '!'
输出:
员工信息如下:------分割线------Employee(id=5, name=刘备, gender=1, phone=11111, companyId=1, age=25)------分割线------Employee(id=6, name=复苏刘, gender=0, phone=12123, companyId=2, age=10)
多条件查询AND
@Testpublic void findByGenderAndAgeGt() {int gender = 1;int age = 21;JPAQuery<Employee> jpaQuery = jpaQueryFactory.selectFrom(qEmployee).where(qEmployee.gender.eq(gender), qEmployee.age.gt(age));//.where(qEmployee.gender.eq(gender), qEmployee.age.gt(age)) = .where(qEmployee.gender.eq(gender).and(qEmployee.age.gt(age))List<Employee> employees = jpaQuery.fetch();System.out.println("员工信息如下:");for (Employee employee : employees) {System.out.println("------分割线------");System.out.println(employee.toString());}}
执行查询:
Hibernate:selectemployee0_.id as id1_1_,employee0_.age as age2_1_,employee0_.company_id as company_3_1_,employee0_.gender as gender4_1_,employee0_.name as name5_1_,employee0_.phone as phone6_1_from employee employee0_whereemployee0_.gender=?andemployee0_.age>?
输出:
员工信息如下:------分割线------Employee(id=1, name=李白, gender=1, phone=10086, companyId=1, age=22)------分割线------Employee(id=4, name=孙悟空, gender=1, phone=00001, companyId=2, age=89)------分割线------Employee(id=5, name=刘备, gender=1, phone=11111, companyId=1, age=25)
多条件查询OR
@Testpublic void findByNameOrAgeGt() {String name="李白";int age = 25;JPAQuery<Employee> jpaQuery = jpaQueryFactory.selectFrom(qEmployee).where(qEmployee.name.eq(name).or(qEmployee.age.gt(age)));List<Employee> employees = jpaQuery.fetch();for (Employee employee : employees) {System.out.println("------分割线------");System.out.println(employee.toString());}}
执行查询:
Hibernate: select employee0_.id as id1_1_, employee0_.age as age2_1_, employee0_.company_id as company_3_1_, employee0_.gender as gender4_1_, employee0_.name as name5_1_, employee0_.phone as phone6_1_ from employee employee0_ where employee0_.name=? or employee0_.age>?
输出:
------分割线------Employee(id=1, name=李白, gender=1, phone=10086, companyId=1, age=22)------分割线------Employee(id=4, name=孙悟空, gender=1, phone=00001, companyId=2, age=89)
查询分页
@Testpublic void findAllPaged(){//第2页,每页2条数据int page = 2;int size = 2;JPAQuery<Employee> jpaQuery = jpaQueryFactory.selectFrom(qEmployee).offset((page-1)*size).limit(size);List<Employee> employees = jpaQuery.fetch();System.out.println("员工信息如下:");for (Employee employee : employees) {System.out.println("------分割线------");System.out.println(employee.toString());}}
执行查询:
Hibernate:selectemployee0_.id as id1_1_,employee0_.age as age2_1_,employee0_.company_id as company_3_1_,employee0_.gender as gender4_1_,employee0_.name as name5_1_,employee0_.phone as phone6_1_from employee employee0_limit ? offset ?
输出:
员工信息如下:------分割线------Employee(id=2, name=张飞, gender=1, phone=10010, companyId=1, age=20)------分割线------Employee(id=4, name=孙悟空, gender=1, phone=00001, companyId=2, age=89)
指定查询返回
指定查询列(Tuple)
有时候在查询时,我们只希望返回指定的列数据,示例:查询全部源信息,只获取name和age信息:
@Testvoid findNameAndAge(){List<Tuple> tuples = jpaQueryFactory.select(qEmployee.name, qEmployee.age).from(qEmployee).fetch();System.out.println("员工信息如下:");for (Tuple tuple:tuples){System.out.println("name="+tuple.get(qEmployee.name)+",age="+tuple.get(qEmployee.age));}}
执行SQl:
Hibernate: select employee0_.name as col_0_0_, employee0_.age as col_1_0_ from employee employee0_
输出:
员工信息如下:name=李白,age=22name=孙尚香,age=23name=张飞,age=20name=孙悟空,age=89name=刘备,age=25name=复苏刘,age=10
映射DTO(Projections)
有时候,我们想直接返回一个对象类型,这个对象的值可以由查询类型对象的部分字段组成。
Projections,这个类型是QueryDSL内置针对处理自定义返回结果集的解决方案,里面包含了构造函数、实体、字段等处理方法。
Bean
JPAQueryFactory工厂select方法可以将Projections方法返回的QBean作为参数,我们通过Projections的bean方法来构建返回的结果集映射到实体内。
bean:
@Datapublic class EmployeeDyo1 {private String id;private String name;private Integer age;}
查询:
/*** bean 映射*/@Testvoid findEmployeeDyo1(){List<EmployeeDyo1> employeeDyo1s = jpaQueryFactory.select(Projections.bean(EmployeeDyo1.class,qEmployee.id,qEmployee.name,qEmployee.age)).from(qEmployee).fetch();System.out.println("员工信息如下:");for (EmployeeDyo1 dyo1:employeeDyo1s){System.out.println("------分割线------");System.out.println(dyo1.toString());}}
执行SQl:
Hibernate: select employee0_.id as col_0_0_, employee0_.name as col_1_0_, employee0_.age as col_2_0_ from employee employee0_
输出:
员工信息如下:------分割线------EmployeeDyo1(id=1, name=李白, age=22)------分割线------EmployeeDyo1(id=3, name=孙尚香, age=23)------分割线------EmployeeDyo1(id=2, name=张飞, age=20)------分割线------EmployeeDyo1(id=4, name=孙悟空, age=89)------分割线------EmployeeDyo1(id=5, name=刘备, age=25)------分割线------EmployeeDyo1(id=6, name=复苏刘, age=10)
Bean as
如果QueryDSL查询实体内的字段与DTO实体的字段名字不一样时,我们就可以采用as方法来处理,为查询的结果集指定的字段添加别名,这样就会自动映射到DTO实体内。
@Data@AllArgsConstructor@NoArgsConstructorpublic class EmployeeDto2 {private String code;private String userName;private Integer age;}
首先我们试一下不使用as会查询出什么东西来:
测试查询:
@Testvoid findEmployeeDyo2(){List<EmployeeDto2> EmployeeDto2s = jpaQueryFactory.select(Projections.bean(EmployeeDto2.class,qEmployee.id,qEmployee.name,qEmployee.age)).from(qEmployee).fetch();System.out.println("员工信息如下:");for (EmployeeDto2 dto:EmployeeDto2s){System.out.println("------分割线------");System.out.println(dto.toString());}}
执行SQl:
Hibernate:selectemployee0_.id as col_0_0_,employee0_.name as col_1_0_,employee0_.age as col_2_0_from employee employee0_
输出:
员工信息如下:------分割线------EmployeeDto2(code=null, userName=null, age=22)------分割线------EmployeeDto2(code=null, userName=null, age=23)------分割线------EmployeeDto2(code=null, userName=null, age=20)------分割线------EmployeeDto2(code=null, userName=null, age=89)------分割线------EmployeeDto2(code=null, userName=null, age=25)------分割线------EmployeeDto2(code=null, userName=null, age=10)
我们可以发现,code和userName两个字段都为null,因为与执行使用的默认as字段不相匹配,现在我们试着指定as:
测试查询:
@Testvoid findEmployeeDto3(){List<EmployeeDto2> EmployeeDto2s = jpaQueryFactory.select(Projections.bean(EmployeeDto2.class,qEmployee.id.as("code"),//指定as为我们需要的字段名称codeqEmployee.name.as("userName"), //指定as为我们需要的字段名称userNameqEmployee.age)).from(qEmployee).fetch();System.out.println("员工信息如下:");for (EmployeeDto2 dto:EmployeeDto2s){System.out.println("------分割线------");System.out.println(dto.toString());}}
执行SQl:
Hibernate:selectemployee0_.id as col_0_0_,employee0_.name as col_1_0_,employee0_.age as col_2_0_from employee employee0_
输出:
员工信息如下:------分割线------EmployeeDto2(code=1, userName=李白, age=22)------分割线------EmployeeDto2(code=3, userName=孙尚香, age=23)------分割线------EmployeeDto2(code=2, userName=张飞, age=20)------分割线------EmployeeDto2(code=4, userName=孙悟空, age=89)------分割线------EmployeeDto2(code=5, userName=刘备, age=25)------分割线------EmployeeDto2(code=6, userName=复苏刘, age=10)
Construct
同样也可以考虑以构造函数的形式来构造查询返回对象:
测试查询:
//EmployeeDto2(String code,String userName,int age)@Testvoid findEmployeeDto4(){List<EmployeeDto2> EmployeeDto2s = jpaQueryFactory.select(Projections.constructor(EmployeeDto2.class,qEmployee.id,qEmployee.name,qEmployee.age)).from(qEmployee).fetch();System.out.println("员工信息如下:");for (EmployeeDto2 dto:EmployeeDto2s){System.out.println("------分割线------");System.out.println(dto.toString());}}
执行SQl:
Hibernate:selectemployee0_.id as col_0_0_,employee0_.name as col_1_0_,employee0_.age as col_2_0_from employee employee0_
输出:
员工信息如下:------分割线------EmployeeDto2(code=1, userName=李白, age=22)------分割线------EmployeeDto2(code=3, userName=孙尚香, age=23)------分割线------EmployeeDto2(code=2, userName=张飞, age=20)------分割线------EmployeeDto2(code=4, userName=孙悟空, age=89)------分割线------EmployeeDto2(code=5, userName=刘备, age=25)------分割线------EmployeeDto2(code=6, userName=复苏刘, age=10)
连表查询
Querydsl 在JPQL中支持的联合查询:inner join, join, left join, right join。参看以下示例:
查询某个公司的员工
测试查询
public void findEmployeesByCompanyName() {String name = "三国";// JPAQuery<Customer> jpaQuery = jpaQueryFactory.select(qEmployee).from(qCompany, qEmployee).where(qCompany.id.eq(qEmployee.companyId).and(qCompany.name.eq(name)));JPAQuery<Employee> jpaQuery = jpaQueryFactory.select(qEmployee).from(qEmployee).rightJoin(qCompany) //右连接.on(qCompany.id.eq(qEmployee.companyId)).where(qCompany.name.eq(name));List<Employee> employees = jpaQuery.fetch();System.out.println("员工信息如下:");for (Employee employee : employees) {System.out.println("------分割线------");System.out.println(employee.toString());}}
执行SQL:
Hibernate:selectemployee0_.id as id1_1_,employee0_.age as age2_1_,employee0_.company_id as company_3_1_,employee0_.gender as gender4_1_,employee0_.name as name5_1_,employee0_.phone as phone6_1_from employee employee0_right outer join company company1_ on (company1_.id=employee0_.company_id)where company1_.name=?
输出:
员工信息如下:------分割线------Employee(id=1, name=李白, gender=1, phone=10086, companyId=1, age=22)------分割线------Employee(id=3, name=孙尚香, gender=0, phone=10011, companyId=1, age=23)------分割线------Employee(id=2, name=张飞, gender=1, phone=10010, companyId=1, age=20)------分割线------Employee(id=5, name=刘备, gender=1, phone=11111, companyId=1, age=25)
子查询
使用 JPAExpressions 的静态工厂方法创建一个子查询,并且通过调用 from,where 等定义查询参数。
示例:查询 在上海的公司的所有员工
执行查询:
@Testpublic void findEmployeesInCompanyInShangHai() {String name = "三国";JPQLQuery<String> jpqlQuery = JPAExpressions.select(qCompany.id).from(qCompany).where(qCompany.city.eq("上海"));List<Employee> employees = jpaQueryFactory.selectFrom(qEmployee).where(qEmployee.companyId.in(jpqlQuery)).fetch();System.out.println("员工信息如下:");for (Employee employee : employees) {System.out.println("------分割线------");System.out.println(employee.toString());}}
执行查询:
Hibernate:selectemployee0_.id as id1_1_,employee0_.age as age2_1_,employee0_.company_id as company_3_1_,employee0_.gender as gender4_1_,employee0_.name as name5_1_,employee0_.phone as phone6_1_from employee employee0_where employee0_.company_id in (select company1_.idfrom company company1_where company1_.city=?)
输出:
员工信息如下:------分割线------Employee(id=4, name=孙悟空, gender=1, phone=00001, companyId=2, age=89)------分割线------Employee(id=6, name=复苏刘, gender=0, phone=12123, companyId=2, age=10)
聚合函数
QueryDSL内置了SQL所有的聚合函数,下面介绍我们常用的几个聚合函数。
sum 、avg 、count、max、min
@Testvoid analyzeEmployee(){long count = jpaQueryFactory.selectFrom(qEmployee).fetchCount();//Long count = jpaQueryFactory.select(qEmployee.count()).from(qEmployee).fetchOne();System.out.println("用户表中共有"+count+"条数据!");Integer sum = jpaQueryFactory.select(qEmployee.age.sum()).from(qEmployee).fetchOne();System.out.println("员工总年龄是"+sum);Integer max = jpaQueryFactory.select(qEmployee.age.max()).from(qEmployee).fetchOne();System.out.println("员工最大年龄是"+max);Integer min = jpaQueryFactory.select(qEmployee.age.min()).from(qEmployee).fetchOne();System.out.println("员工最大年龄是"+min);Double avg = jpaQueryFactory.select(qEmployee.age.avg()).from(qEmployee).fetchOne();System.out.println("员工平均年龄是"+avg);}
执行SQL:
Hibernate: select count(employee0_.id) as col_0_0_ from employee employee0_Hibernate: select sum(employee0_.age) as col_0_0_ from employee employee0_Hibernate: select max(employee0_.age) as col_0_0_ from employee employee0_Hibernate: select min(employee0_.age) as col_0_0_ from employee employee0_Hibernate: select avg(employee0_.age) as col_0_0_ from employee employee0_
输出:
用户表中共有6条数据!员工总年龄是189员工最大年龄是89员工最大年龄是10员工平均年龄是31.5
group by
查询北京上海两座城市员工的的平均年龄
@Testvoid testGroupBy(){List<Tuple> tuples = jpaQueryFactory.select(qCompany.city, qEmployee.age.avg()).from(qCompany, qEmployee).where(qEmployee.companyId.eq(qCompany.id)).groupBy(qCompany.city).fetch();System.out.println("查询结果:");for (Tuple tuple:tuples){String city = tuple.get(qCompany.city);Double avg = tuple.get(qEmployee.age.avg());System.out.println(city+"城市的平均员工年龄是:"+avg);}}
执行SQl:
Hibernate:selectcompany0_.city as col_0_0_,avg(employee1_.age) as col_1_0_from company company0_ cross join employee employee1_where employee1_.company_id=company0_.idgroup by company0_.city
输出:
查询结果:北京城市的平均员工年龄是:22.5上海城市的平均员工年龄是:49.5
更新删除
更新员工信息
在Querydsl JPA中,更新语句是简单的 update-set/where-execute 形式。下面是一个例子:
queryFactory.update(customer).where(customer.name.eq("Bob")).set(customer.name, "Bobby").execute();
调用 set 方法以 SQL-Update-style 方式定义要更新的属性,execute 调用指行更新操作并返回被更新的实体的数量。
JPA中的DML语句并不考虑JPA级联规则,也不提供细粒度二级缓存的交互。
测试代码:
@Test@Transactional() //更新需加入事务,不然抛出异常 Executing an update/delete querypublic void updateEmployee(){long execute = jpaQueryFactory.update(qEmployee).set(qEmployee.age, 100).set(qEmployee.phone, "10009").where(qEmployee.name.eq("李白")).execute();System.out.println("更新成功,影响了"+execute+"条数据!");}
执行SQL:
Hibernate: update employee set age=?, phone=? where name=?
输出:
更新成功,影响了1条数据!
删除员工信息
在Querydsl JPA中,删除语句是简单的 delete-where-execute 形式。下面是一个例子:
QCustomer customer = QCustomer.customer;// delete all customersqueryFactory.delete(customer).execute();// delete all customers with a level less than 3queryFactory.delete(customer).where(customer.level.lt(3)).execute();
调用 where 方法是可选的,调用 execute 方法是执行删除操作并返回被删除实体的数量。
JPA中的DML语句并不考虑JPA级联规则,也不提供细粒度二级缓存的交互。
测试代码:
@Test@Transactional() //删除需加入事务,不然抛出异常 Executing an update/delete queryvoid deleteEmployee(){long result = jpaQueryFactory.delete(qEmployee).where(qEmployee.age.gt(30)).execute();System.out.println("删除更成功,影响了"+result+"条数据!");}
执行SQL:
Hibernate: delete from employee where age>?
输出:
删除更成功,影响了1条数据!
项目地址:

若有收获,就点个赞吧
0 人点赞
