前言:
系统:macOS Catalina10.15.5
虚拟机:VMware-Fusion-12.0.0
Linux:centos6.5
三个节点:master、slave1、slave2
本文基于这篇博客,有更详细步骤,并修改其中错误
- 第一步:centos的安装与克隆
点击下载centos6.5
打开VMware—文件—新建—从光盘或映象中安装—继续—(选择刚刚下载的centos6.5)—输入用户名(自己设置)—继续—完成—(此处我把这台虚拟机取名为master,以便在VMware区分)等待安装完成即可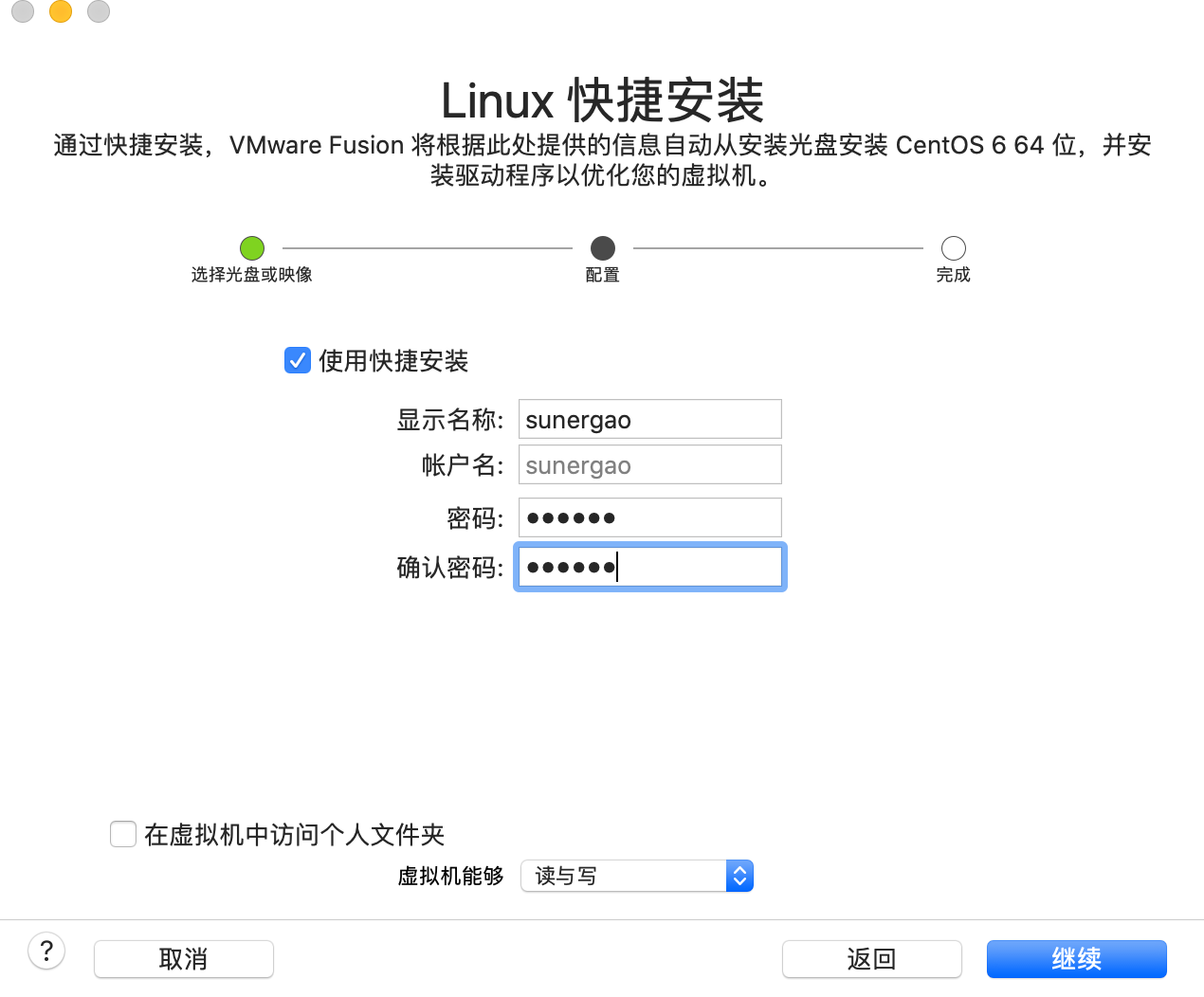
安装完之后,将master关机,进入VMware,选择master右键,创建完整克隆,并取名为slave1,
同样的方法创建slave2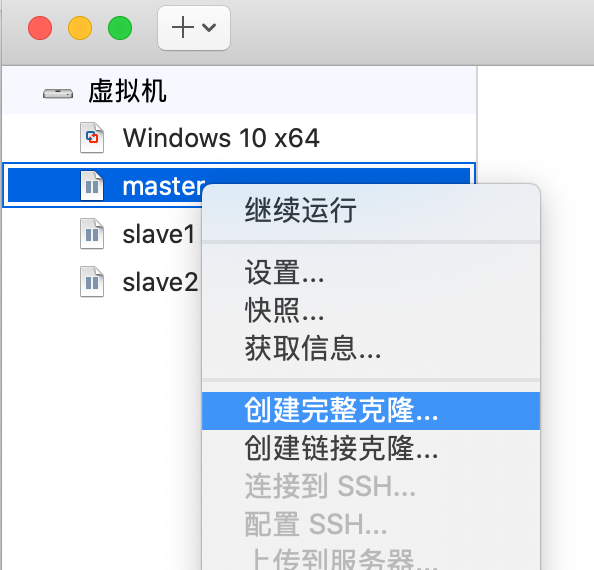
- 第二步:配置节点名
在master的终端:su 进入root用户下,以下操作我们全在root用户下。
输入vi /etc/sysconfig/network 开始编辑
按 i 进入INSERT模式,改为如下(为与虚拟机一致,我改成master)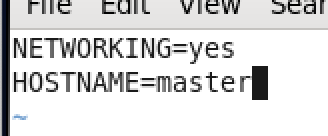
修改好后,按Esc键,输入 :wq 回车保存退出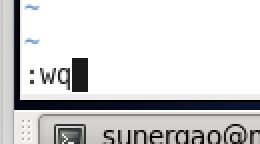
在slave1、slave2上做同样的操作,并修改HOSTNAME=slave1、HOSTNAME=slave2
重启各个节点,你会发现 root@名字 已修改
- 第三步:配置hosts
(1)root用户下,在master终端:ifconfig 查看ip地址(红线标注)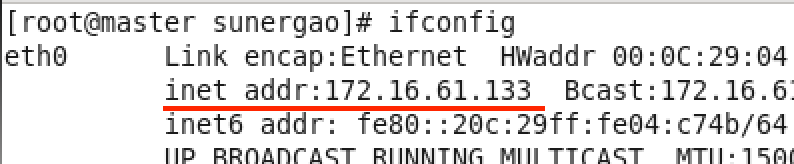
在slave1、slave2做同样的操作,并记下它们的ip地址
(2)master终端:vi /etc/hosts 编辑hosts文件,注释掉前两行,添加各节点名信息(ip地址改成自己的),保存退出
继续输入:hostname master 使之生效
以后直接ping名字就可以,不用ping地址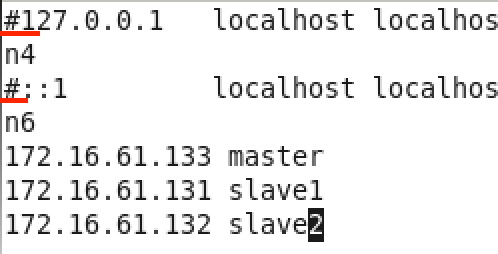
(3)在slave1、slave2做与(2)相同的操作(hostname那一步注意修改后面的名字)
(4)master终端:ping slave1 测试是否成功(crtl+c中止)
第四步、第五步建议先跳过
- 第四步:关闭防火墙
centos版本不同,操作不同,自行百度,直到成功
- 第五步:时间同步
root用户下,master终端:ntpdate -u ntp1.aliyun.com
继续输入:date 下图表示成功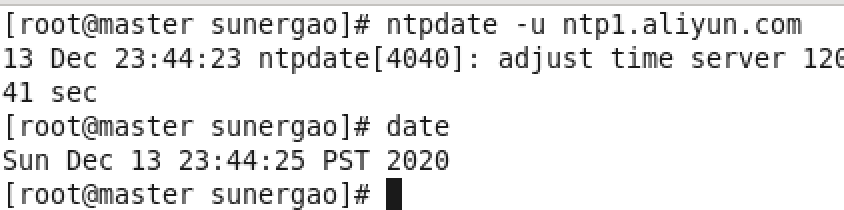
slave1、slave2相同操作
- 第六步:配置ssh无密码访问
(1)生成公钥密钥对
root用户下,在master终端:ssh-keygen -t rsa 一直回车,直到生成结束
此时,master终端:ls ~/.ssh 会看到两个文件,前者为私钥,后者为公钥
slave1、slave2做(1)的相同操作
(2)配置免密文件
将slave生成的文件拷贝到master(需要输入yes和密码):
slave1终端:scp /root/.ssh/id_rsa.pub root@master:/root/.ssh/id_rsa_slave1.pub
slave2终端:scp /root/.ssh/id_rsa.pub root@master:/root/.ssh/id_rsa_slave2.pub
将公钥全部放入到authorized_keys文件中:
master终端:cp /root/.ssh/id_rsa.pub /root/.ssh/authorized_keys
master终端:cat /root/.ssh/id_rsa_slave1.pub>> /root/.ssh/authorized_keys
master终端:cat /root/.ssh/id_rsa_slave2.pub>> /root/.ssh/authorized_keys
修改权限:
master终端:chmod 0600 ~/.ssh/authorized_keys
将主节点文件authorized_keys拷贝到子节点上(需要输入yes和密码):
master终端:scp /root/.ssh/authorized_keys root@slave1:/root/.ssh/
master终端:scp /root/.ssh/authorized_keys root@slave2:/root/.ssh/
(3)测试
分别在各个节点上 ssh 名字 ,这步一定要做,
如在master上,界面可能稍有不同,不用密码且能登录表示成功
终端:exit ssh 关闭ssh
- 第七步:配置jdk
jdk版本:jdk-8u144-linux-x64.tar.gz
下载好之后,如果你是macOS系统,直接拖拽到master的Downloads文件夹之下(需要先在VMware-master-设置-隔离-勾选启用拖拽、拷贝粘贴功能),如果你是Windows系统,推荐搜索FileZilla软件。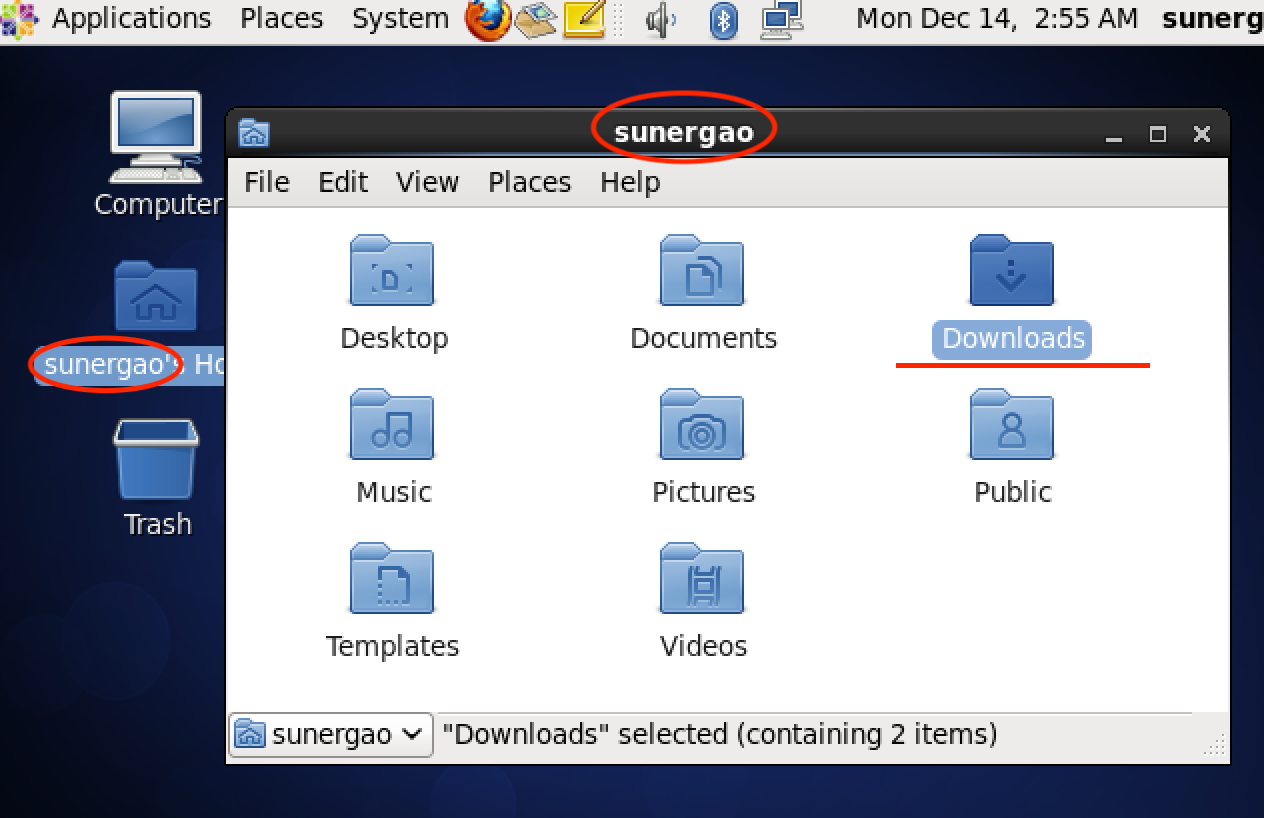
(1)解压jdk到/usr/local下(也可以解压到别的地方,但要记住这个路径)
root用户下,master终端:tar -zxvf /home/sunergao/Downloads/jdk-8u144-linux-x64.tar.gz -C /usr/local
红线标注:sunergao换成自己的(不知道看上图),C为大写
(2)配置环境变量
master终端:vi /etc/profile
在文件末尾添加以下信息:
export JAVA_HOME=/usr/local/jdk1.8.0_144
export JRE_HOME=$JAVA_HOME/jre
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=$JAVA_HOME/lib:$JRE_HOME/lib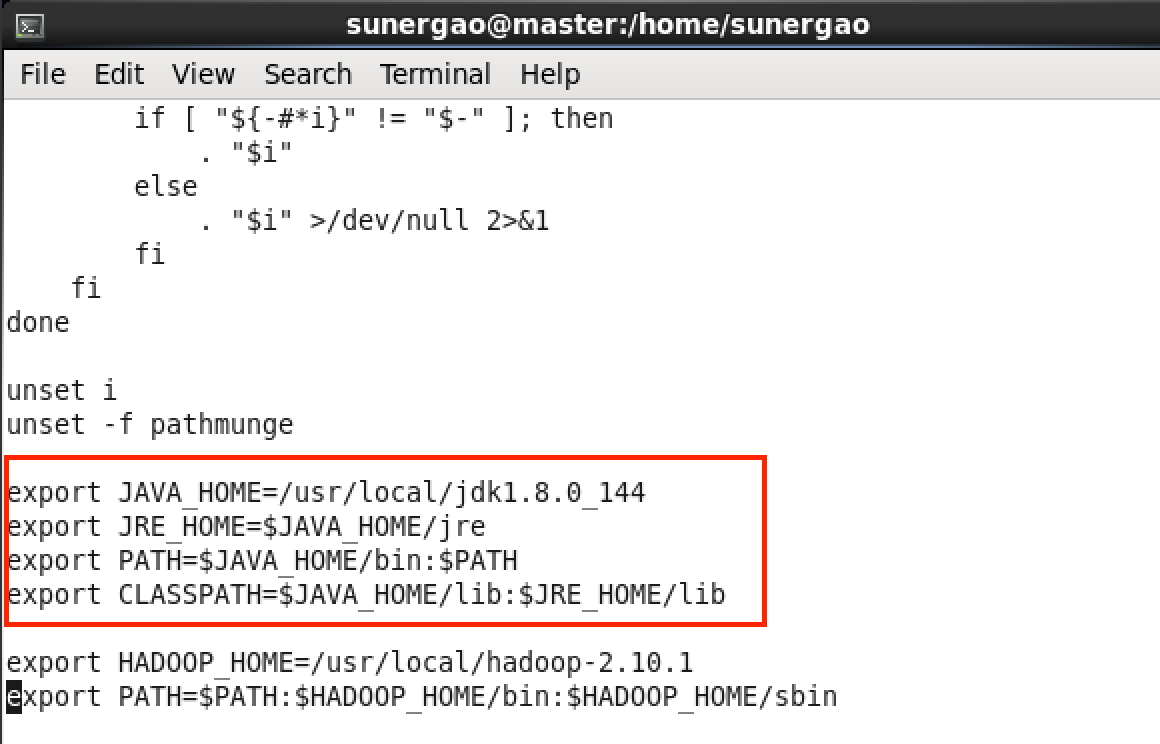
保存退出,继续输入使刚才的更改生效:source /etc/profile
(3)测试
master终端:java -version 下图表示成功
(4)拷贝jdk到子节点
master终端:scp -r /usr/local/jdk1.8.0_144 root@slave1:/usr/local/
master终端:scp -r /usr/local/jdk1.8.0_144 root@slave2:/usr/local/
(5)拷贝配置文件profile到子节点
此处先不拷贝,配置完Hadoop后一起拷贝
在开始第八步之前建议用VMware拍摄下master的快照,保存下当前的状态,因为后面容易出错,不然还得从头再来。。。
- 第八步:安装Hadoop、配置Hadoop
Hadoop版本:hadoop-2.10.1.tar.gz
(1)解压hadoop-2.10.1.tar.gz到/usr/local下
参照jdk的解压方法,将其解压到/usr/local路径下
(2)配置环境变量
master终端:vi /etc/profile
在文件末尾添加以下信息:
export HADOOP_HOME=/usr/local/hadoop-2.10.1
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin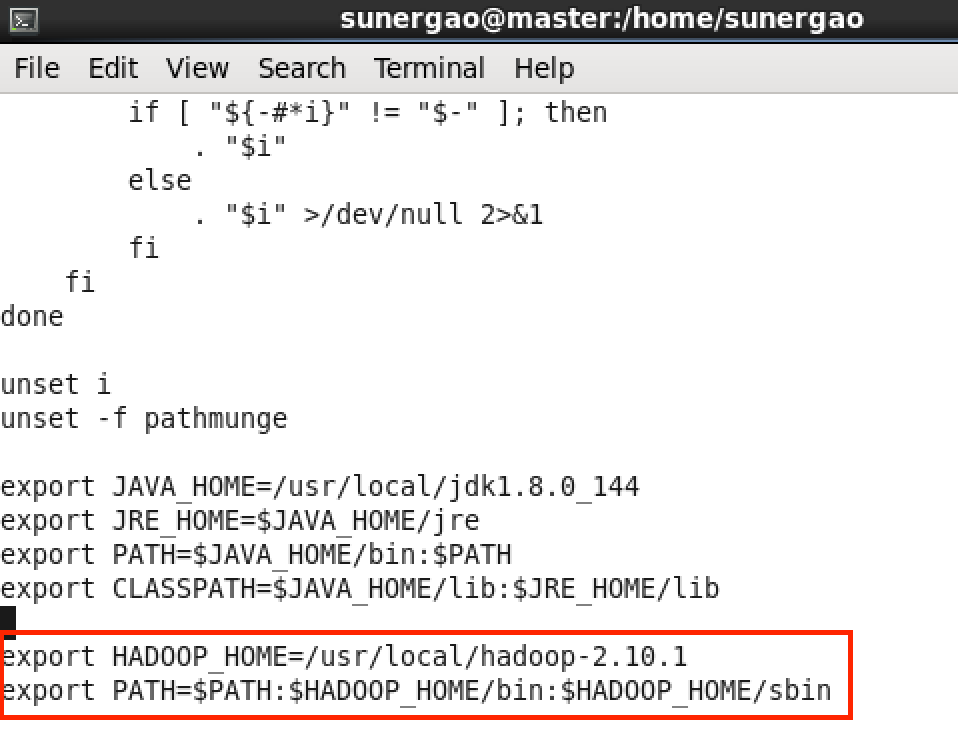
保存退出,继续输入使刚才的更改生效:source /etc/profile
(3)配置hadoop
首先进入配置路径看看
master终端:cd /usr/local/hadoop-2.10.1/etc/hadoop/
master终端:ls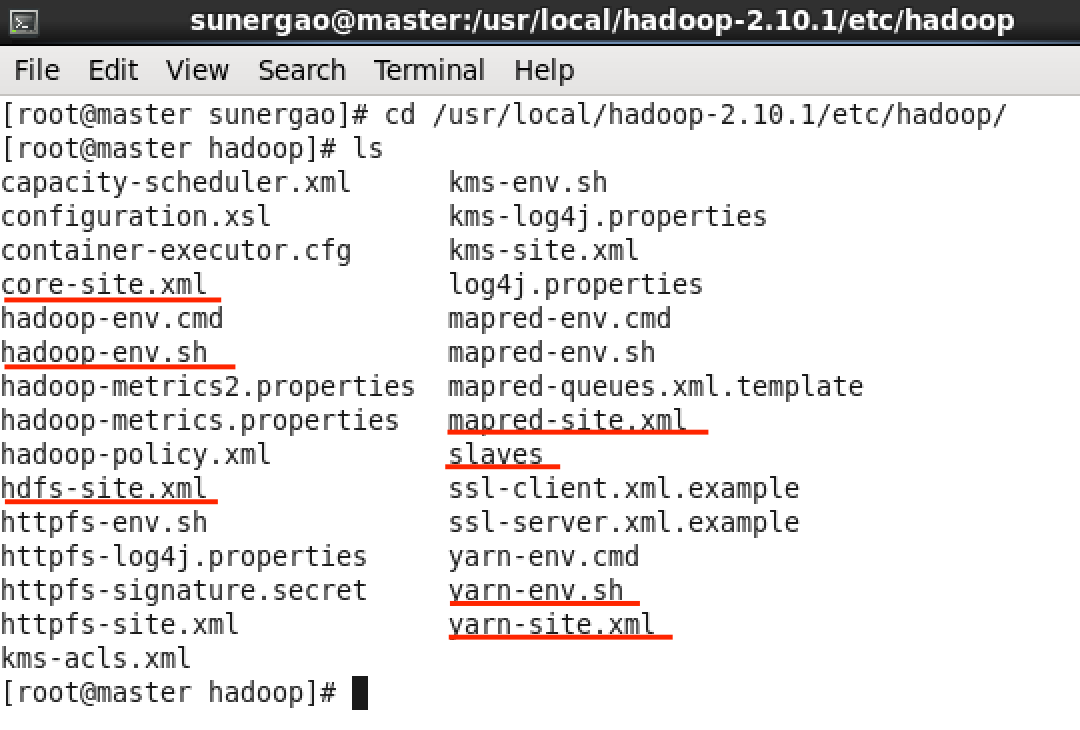
我们需要对红线标注的文件修改(mapred-site.xml你可能没有,下面再说)
- master终端:vi hadoop-env.sh
添加export JAVA_HOME=/usr/local/jdk1.8.0_144到下图位置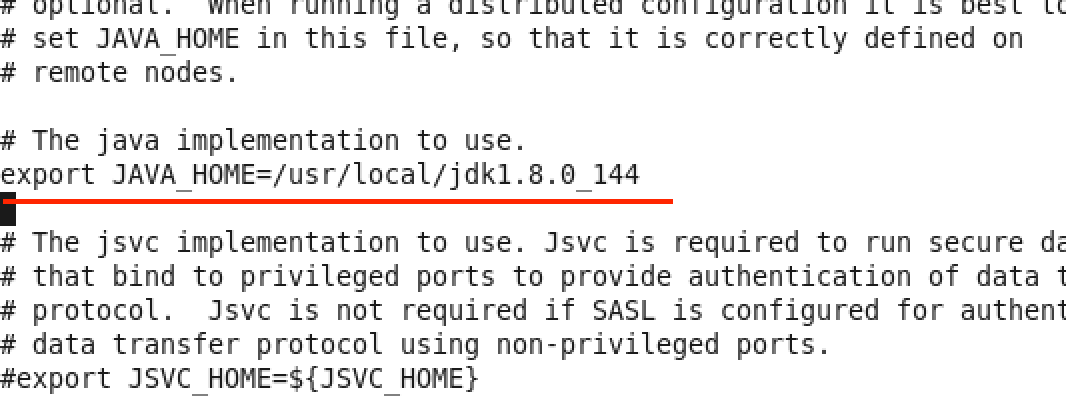
- master终端:vi yarn-env.sh
添加export JAVA_HOME=/usr/local/jdk1.8.0_144到下图位置
- 先创建个temp文件夹,master终端:mkdir /usr/temp2
master终端:vi core-site.xml
末尾添加以下代码,将原来的
**
先创建个data文件夹,master终端:mkdir /usr/dfs
master终端:**mkdir /usr/dfs/data**<br />master终端:**vi hdfs-site.xml**<br />末尾添加以下代码,将原来的<configuration></configuration>标签删掉<br />**<configuration>**<br />** <property>**<br />** <name>dfs.namenode.secondary.http-address</name>**<br />** <value>master:9001</value>**<br />** </property>**<br />** <property>**<br />** <name>dfs.namenode.name.dir</name>**<br />** <value>file:/usr/dfs/name</value>**<br />** </property>**<br />** <property>**<br />** <name>dfs.datanode.data.dir</name>**<br />** <value>file:/usr/dfs/data</value>**<br />** </property>**<br />** <property>**<br />** <name>dfs.replication</name>**<br />** <value>2</value>**<br />** </property>**<br />** <property>**<br />** <name>dfs.webhdfs.enabled</name>**<br />** <value>true</value>**<br />** </property>**<br />** <property>**<br />** <name>dfs.permissions</name>**<br />** <value>false</value>**<br />** </property>**<br />** <property>**<br />** <name>dfs.web.ugi</name>**<br />** <value>supergroup</value>**<br />** </property>**<br />**</configuration>**<br />**
缺少mapred-site.xml文件,把mapred-site.xml.template重命名
master终端:mv mapred-site.xml.template mapred-site.xml
master终端:vi mapred-site.xml
末尾添加以下代码,将原来的
**
- master终端:vi yarn-site.xml
末尾添加以下代码,将原来的
**
- master终端:vi slaves
注释掉localhost(前面加#),添加以下内容
master
slave1
slave2
(4)拷贝hadoop到子节点
master终端:scp -r /usr/local/hadoop-2.10.1 root@slave1:/usr/local/
master终端:scp -r /usr/local/hadoop-2.10.1 root@slave2:/usr/local/
(5)拷贝配置文件profile到子节点
master终端:scp /etc/profile root@slave1:/etc/
master终端:scp /etc/profile root@slave2:/etc/
在三个节点上分别执行:source /etc/profile 使之生效
在三个节点上分别执行:hadoop version 测试是否安装
到此配置完成,最好重启下三个节点,并保存快照。
- 第九步:测试
(1)格式化主节点的namenode
root用户下,master终端:hdfs namenode -format
出现上图表示成功,hdfs namenode -format这个操作一般运行这一次就可以了,除非遇到问题。
(2)启动hadoop
master终端:start-dfs.sh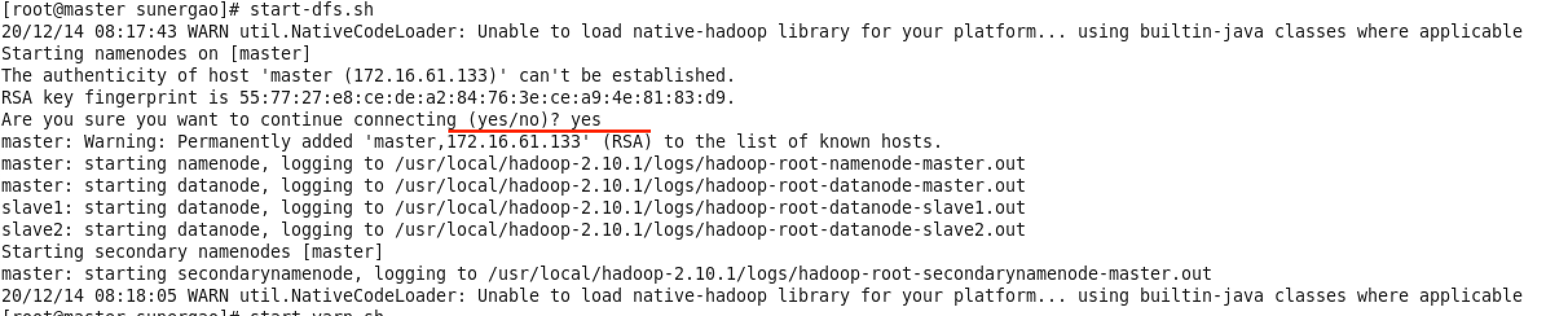
出现上图表示成功,中间可能要输入一次 yes
master终端:start-yarn.sh
出现上图表示成功
(3)查看jps
root用户下,master终端:jps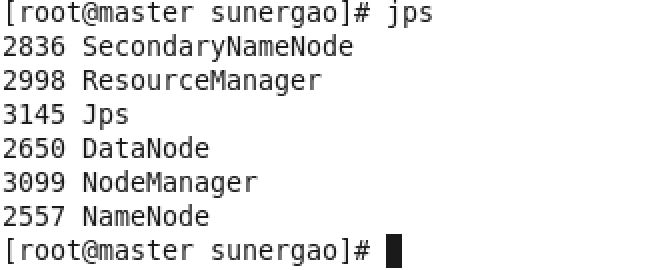
出现上图表示成功
root用户下,slave1终端:jps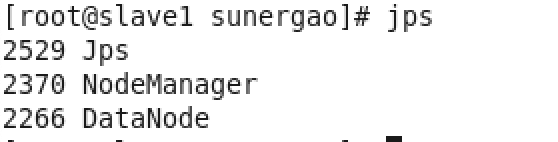
出现上图表示成功
root用户下,slave2终端:jps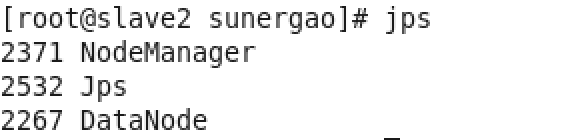
出现上图表示成功
(4)master节点浏览器打开http://localhost:50070/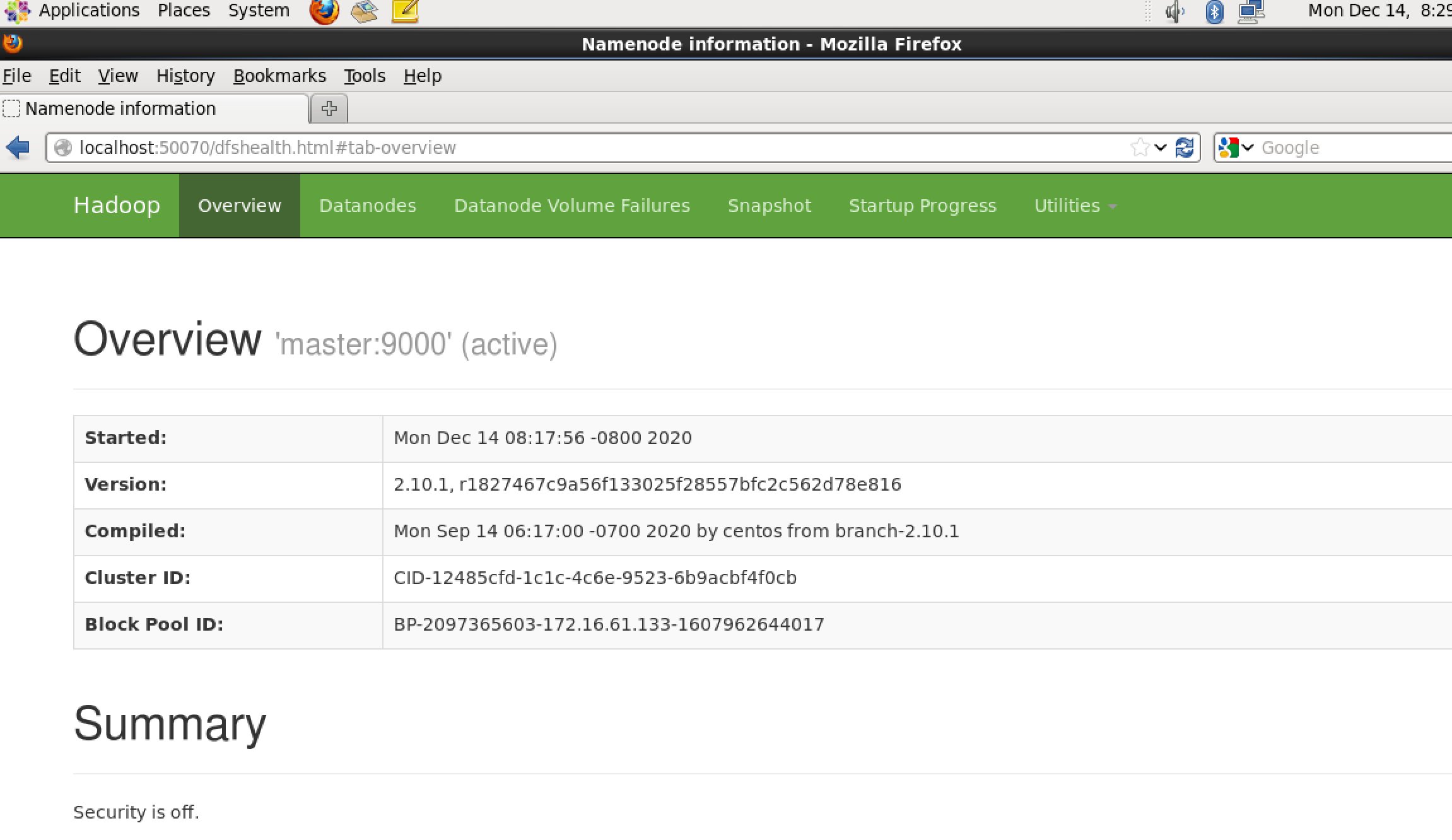
此页面表示成功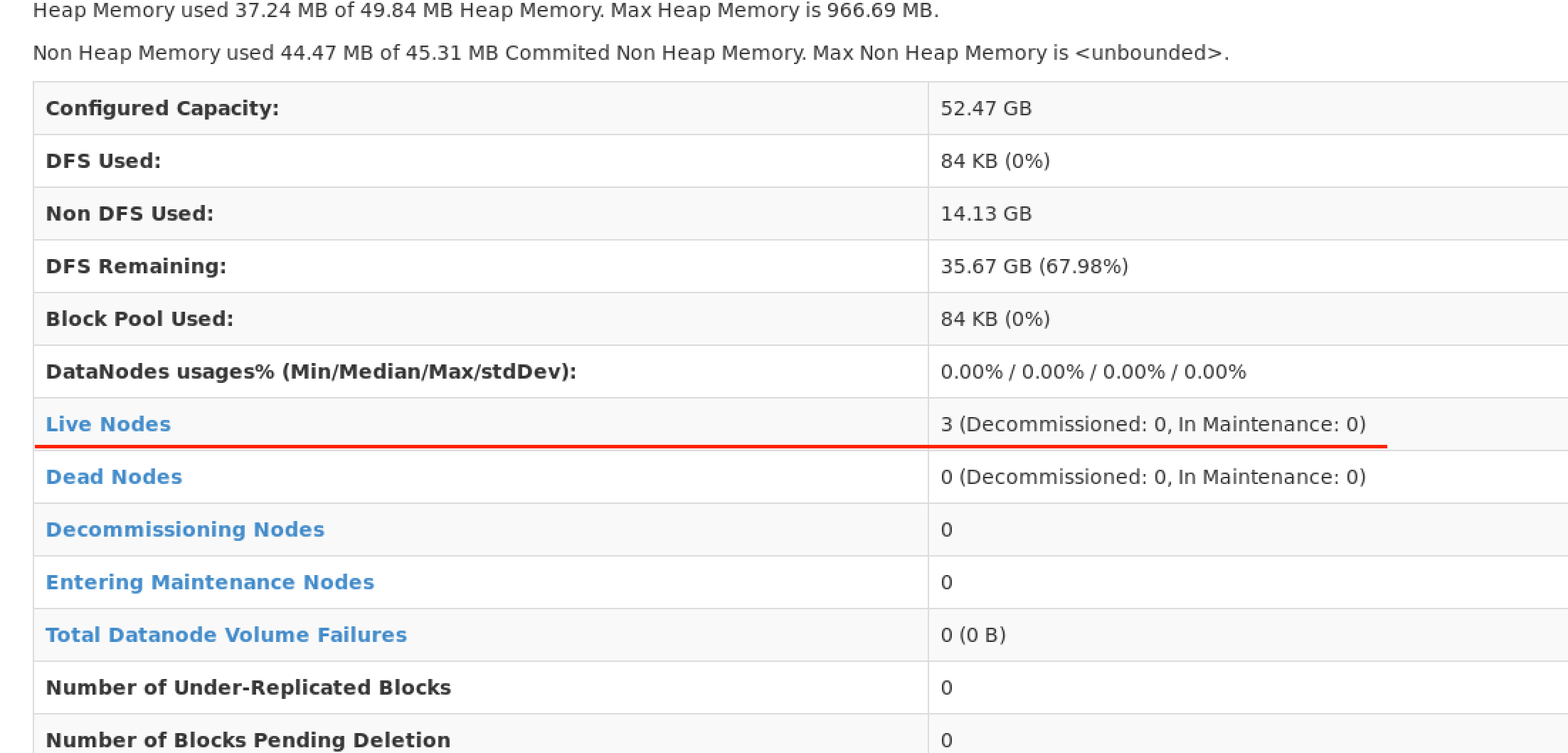
此页面表示成功,可以看到存活节点数有3个
(5)建立文件夹,上传个文件试一下
root用户下,master终端:hdfs dfs -mkdir -p /test/ 建一个test文件夹
有个WARN ……. 临时解决办法
master终端:cd /home/sunergao/Downloads/ 进入Downloads文件夹,里面有两个文件
master终端:hdfs dfs -put hadoop-2.10.1.tar.gz /test/ 把第一个文件传上去
回到网站,查看这个地方
点击 test 文件夹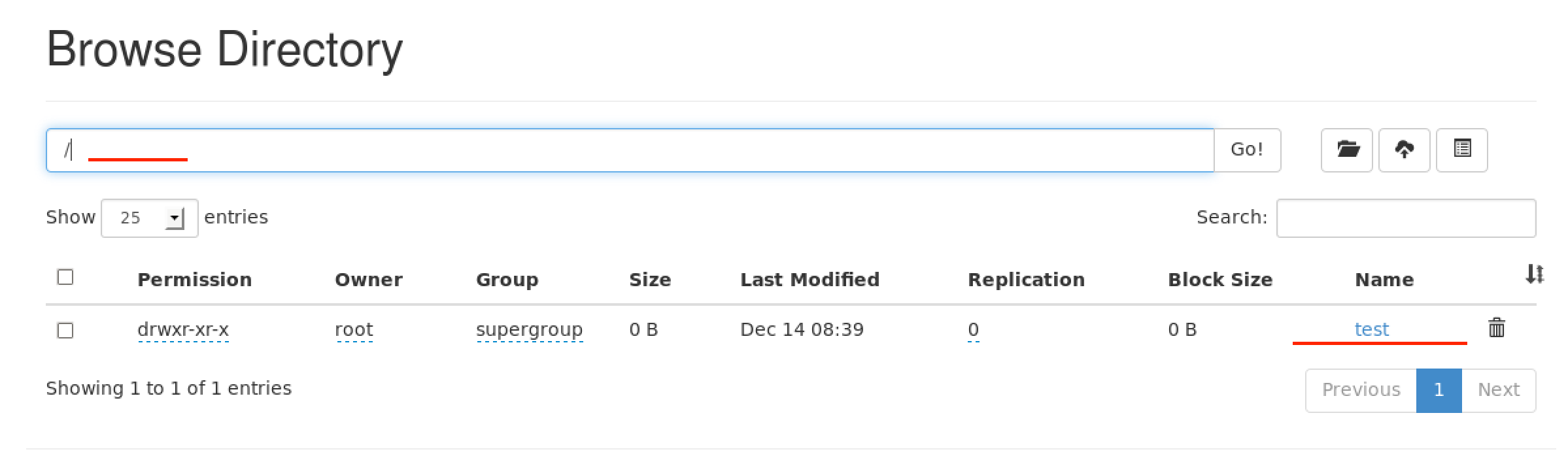
点击刚刚上传的文件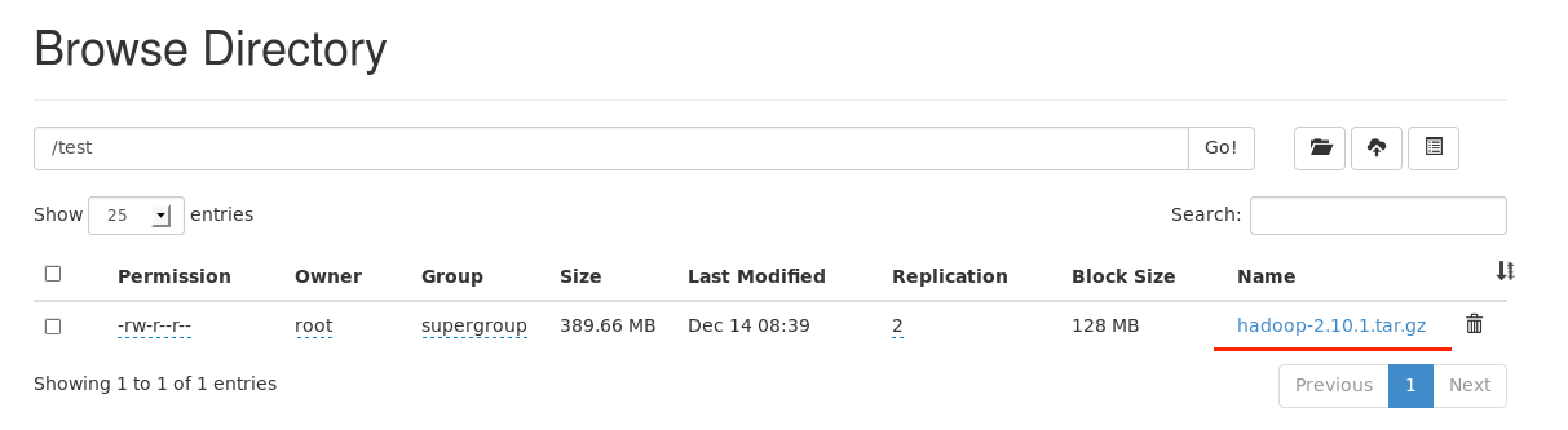
可以看到文件分成4块,存放在不同的节点上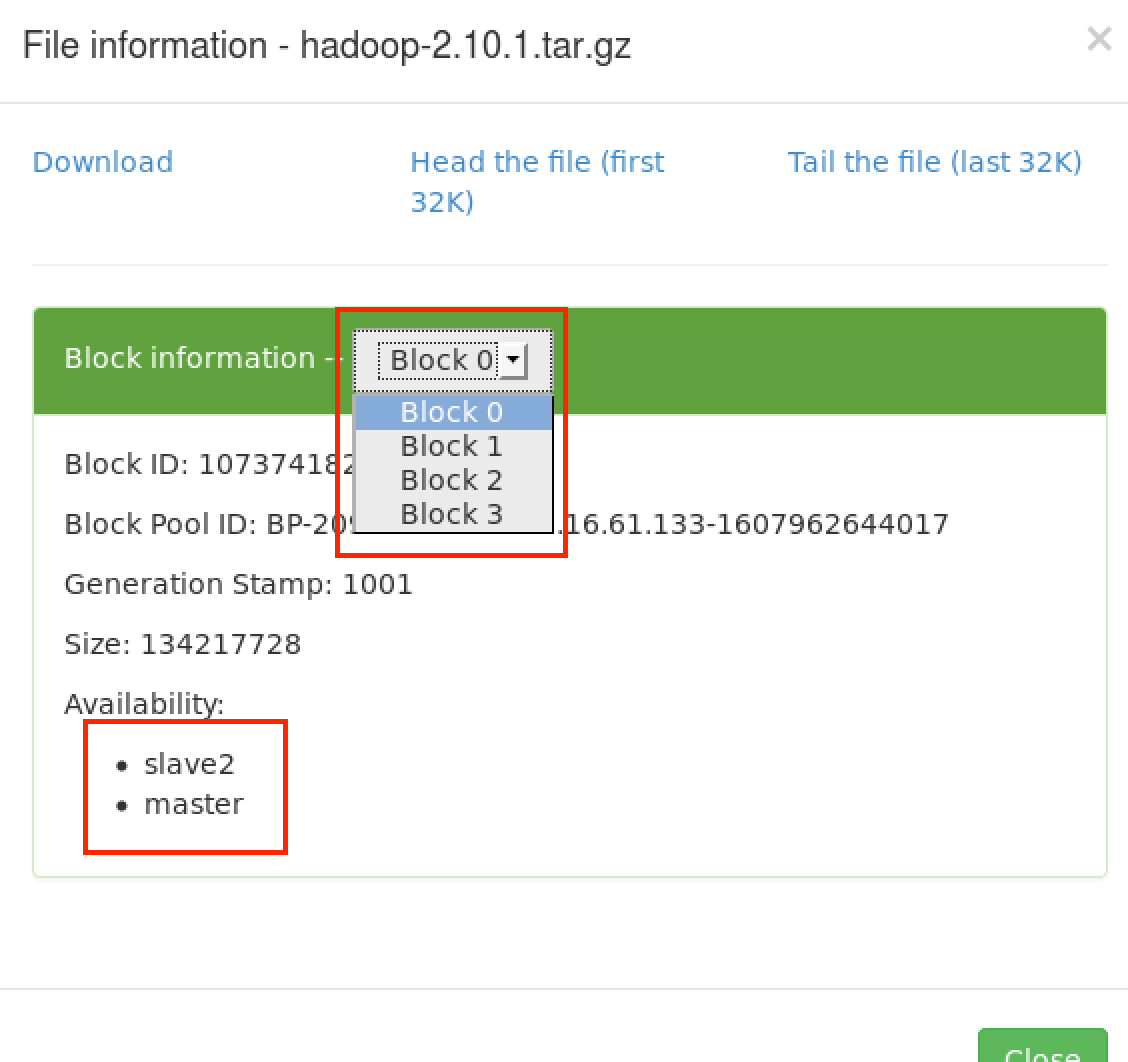
最后,可以在master终端:stop-dfs.sh
master终端:stop-yarn.sh 停止HDFS系统
至此Hadoop完全分布式搭建完毕————2020.12.15 00:55

若有收获,就点个赞吧
0 人点赞
