任务概述
- 对应指标:车辆实时位置、车辆实时下一站、
车辆实时舒适度、车辆实时状态、实时车速、实时累计行驶里程、实时车型状态分布 - 开发语言Scala,实时计算引擎flink
数据流向
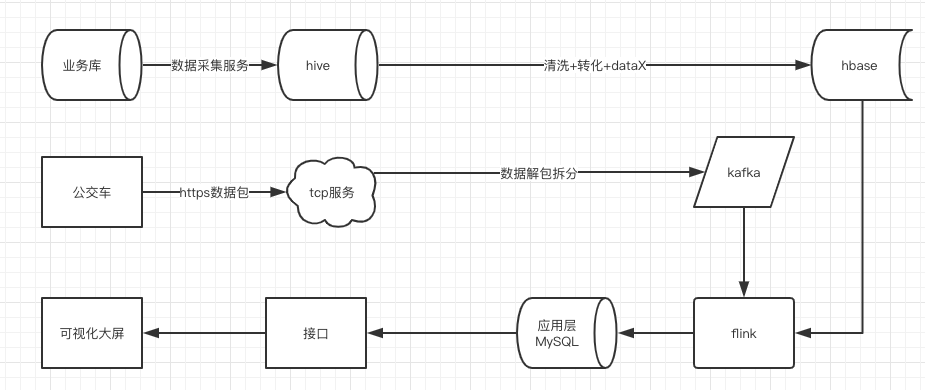
- 实时数据流
- 公交车定时(10s)通过http发送can总线原包数据到tcp服务
- tcp服务对http原始数据包进行解包,并按指定分隔符(FAF5)切割数据,发送(字节数组)到kafka
- flink利用自定义反序列化方法将字节数组转化成字符串
- 对gps数据进行拆分截取,并根据深标协议转码
- 根据相关ID到hbase取得维度信息
- 进一步计算相关指标,并将数据sink到后端mysql
- 维表
- 各业务库原始数据由平台采集同步到平台ods层
- 利用hql进行清洗转化得到dim层维度数据
- 用dataX将维表数据同步到hbse,供flink程序进行join
code
source 类
- 利用flink自带的kafka connector FlinkKafkaConsumer09创建DataSource
- 由于kafka中发送的数据为字节数组,所以序列化方法改用自定义的序列化方法
ByteArrayDeserializationSchema```scala package com.szbus.source
import java.util import java.util.Properties import com.szbus.util.ByteArrayDeserializationSchema import org.apache.flink.api.common.serialization.SimpleStringSchema import org.apache.flink.api.scala._ import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment} import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer09 import org.apache.flink.streaming.connectors.kafka.internals.KafkaTopicPartition
/*
- @author : 恋晨
- Date : 2019/7/12 3:44 PM
- 功能 : 获取各个数据流的source / class source {
/**
* 设置kafka参数*/
val properties = new Properties() properties.setProperty(“bootstrap.servers”, “10.128.1.13:9092,10.128.1.18:9092,10.128.1.19:9092”) properties.setProperty(“group.id”, “prd”) / key 反序列化 */ properties.setProperty(“key.deserializer”, “org.apache.kafka.common.serialization.StringDeserializer”) / value 反序列化 */ properties.setProperty(“value.deserializer”, “org.apache.kafka.common.serialization.StringDeserializer”)
/**
* 获取gps数据* @param env flink运行环境* @return 返回gps source*/
def getGpsSource(env:StreamExecutionEnvironment,parallelism:Int): DataStream[String] ={
val gpsSource = env.addSource(new FlinkKafkaConsumer09[String]("bus_gps",new ByteArrayDeserializationSchema(),properties).setStartFromLatest()).name("gpsSource").setParallelism(parallelism)gpsSource
} }
自定义序列化方法```javapackage com.szbus.util;import org.apache.flink.api.common.serialization.DeserializationSchema;import org.apache.flink.api.common.serialization.SerializationSchema;import org.apache.flink.api.common.typeinfo.TypeInformation;import java.io.IOException;/*** @author : 恋晨* Date : 2019/6/28 5:57 PM* 功能 : kafka Topic 字节数组反序列化类*/public class ByteArrayDeserializationSchema implements DeserializationSchema<String>,SerializationSchema<String>{public static String parseByte2HexStr(byte buf[]){StringBuffer sb = new StringBuffer();for (int i = 0 ; i < buf.length ; i++){String hex = Integer.toHexString(buf[i] & 0xFF);if(hex.length() == 1){hex = '0' + hex;}sb.append(hex.toUpperCase());}return sb.toString();}@Overridepublic String deserialize(byte[] bytes) throws IOException {String out = parseByte2HexStr(bytes);return out;}@Overridepublic boolean isEndOfStream(String s) {return false;}@Overridepublic byte[] serialize(String s) {return new byte[0];}@Overridepublic TypeInformation<String> getProducedType() {return TypeInformation.of(String.class);}}
join 类
- 这个类继承AsyncFunction,利用flink异步IO进行流维join
- 输入输出数据类型,分别数case class{ gps , gps_join_stop_previous}
- 从输入数据中取出bus_id和line_code,用这两个rowKey从维表dim_hbase_line_stop,dim_hbase_line_stop取得对应的数据(json格式)
- 从json取出需要的字段(up_end_order:上行终点站序号,down_end_order:下行终点站序号,stop_list:站点列表,bus_type:车辆型号),组合成新的case class gps_join_stop_previous
package com.szbus.joinimport com.szbus.cache.HbaseSideCacheimport org.apache.flink.streaming.api.scala.async.{AsyncFunction, ResultFuture}import com.szbus.main.caseClasses.gpsimport com.szbus.main.caseClasses.gps_join_stop_previous/**** @author : 恋晨* Date : 2019/7/23 2:26 PM* 功能 :**/class gpsJoinStop extends AsyncFunction [gps , gps_join_stop_previous]{override def asyncInvoke(input: gps, resultFuture: ResultFuture[gps_join_stop_previous]): Unit = {val bus_id = input.busIdval line_code = input.line_codeval stop_list = HbaseSideCache.getValueByKey("dim_hbase_line_stop" , line_code)val bus_type = HbaseSideCache.getValueByKey("dim_hbase_bus_type" , bus_id)val obj = Seq(gps_join_stop_previous.apply(input.busId,input.runType,input.lng,input.lat,input.speed,input.mileage,input.dataTime,input.direction,input.station_num,stop_list.getString("up_end_order"),stop_list.getString("down_end_order"),stop_list.getString("stop_list"),bus_type.getString("bus_type")))resultFuture.complete(obj)}}
sink 类
package com.szbus.sinkimport java.sql.{Connection, PreparedStatement}import com.szbus.util.MySqlClientimport com.szbus.main.caseClasses.gpsSinkimport org.apache.flink.configuration.Configurationimport org.apache.flink.streaming.api.functions.sink.{RichSinkFunction, SinkFunction}import org.apache.flink.types.Rowimport org.slf4j.LoggerFactory/**** @author : 恋晨* Date : 2019/7/3 9:06 PM* 功能 : 自定义mysql sink类**/class gpsSinkToMySql extends RichSinkFunction[gpsSink]{final val log = LoggerFactory.getLogger("gpsSinkToMySql")private var connection:Connection = _private var ps:PreparedStatement = _/*** 初始化方法* 获取数据库连接*/override def open(parameters: Configuration): Unit ={connection = MySqlClient.getConnection()}/*** close方法* 关闭连接释放资源*/override def close(): Unit = {try{if (connection != null) {connection.close();}if (ps != null) {ps.close();}}catch {case e: Exception => log.error(e.getMessage)}}/*** invoke方法* 每条数据都会调用一次invoke方法*/override def invoke(value: gpsSink, context: SinkFunction.Context[_]): Unit = {try{val insertSql = "INSERT INTO bas_tech_bus_real_time(bus_id,run_type,lng,lat,speed,mileage,direction,next_station,event_time,car_type,comfort_level) VALUES (?,?,?,?,?,?,?,?,?,?,?) ON DUPLICATE KEY UPDATE run_type=?,lng=?,lat=?,speed=?,mileage=?,direction=?,next_station=?,event_time=?,car_type=?,comfort_level=?;"ps = connection.prepareStatement(insertSql)/**组装数据,执行插入操作*/ps.setString(1, value.busId)ps.setString(2, value.runType)ps.setString(3, value.lng)ps.setString(4, value.lat)ps.setString(5, value.speed)ps.setString(6, value.mileage)ps.setString(7, value.direction)ps.setString(8, value.nextStation)ps.setString(9, value.dataTime)ps.setString(10, value.bus_type)ps.setInt(11 , value.comfort)ps.setString(12, value.runType)ps.setString(13, value.lng)ps.setString(14, value.lat)ps.setString(15, value.speed)ps.setString(16, value.mileage)ps.setString(17, value.direction)ps.setString(18, value.nextStation)ps.setString(19, value.dataTime)ps.setString(20, value.bus_type)ps.setInt(21 , value.comfort)ps.executeLargeUpdate()}catch {case e: Exception => log.error(e.getMessage)}}}
flink 主类
package com.szbus.mainimport com.alibaba.fastjson.JSONimport com.szbus.join.gpsJoinStopimport com.szbus.main.caseClasses.{gps,gpsSink}import com.szbus.sink.gpsSinkToMySqlimport com.szbus.udf.{IFF, Key2Type, getInterval, nextStation}import com.szbus.util.gpsAnalyzeFunctions._import com.szbus.source.sourceimport org.apache.flink.api.common.time.Timeimport org.apache.flink.configuration.{CheckpointingOptions, Configuration}import org.apache.flink.contrib.streaming.state.{RocksDBOptions, RocksDBStateBackend}import org.apache.flink.runtime.state.StateBackendimport org.apache.flink.runtime.state.filesystem.FsStateBackendimport org.apache.flink.streaming.api.CheckpointingModeimport org.apache.flink.streaming.api.scala.{StreamExecutionEnvironment, _}import org.apache.flink.table.api.{StreamQueryConfig, TableEnvironment}import org.apache.flink.types.Rowimport org.apache.flink.util.{Collector, TernaryBoolean}import org.slf4j.LoggerFactoryimport scala.concurrent.durationimport scala.util.Random/**** @author : 恋晨* Date : 2019/6/28 4:59 PM* 功能 : 解析GPS主程序**/object szBusGps {final val log = LoggerFactory.getLogger("szbusGps")final val seq = (70 to 90).map(x=>x)def main(args: Array[String]): Unit = {/*** 获取flink执行环境*/val env = StreamExecutionEnvironment.getExecutionEnvironment/*** 启用checkpoint* 设置checkpoint最小间隔为20000ms* 设置checkpoint超时时间* 设置任务的默认并行度为4** 在数据量很大的情况下,缩短checkpoint的时间,* 可以减小每次checkpoint 的state的大小,提高稳定性*/env.enableCheckpointing(30000, CheckpointingMode.AT_LEAST_ONCE)env.getCheckpointConfig.setMinPauseBetweenCheckpoints(30000)env.getCheckpointConfig.setMaxConcurrentCheckpoints(1)env.getCheckpointConfig.setCheckpointTimeout(900000)env.getCheckpointConfig.setFailOnCheckpointingErrors(false)env.setParallelism(10)/*** 设置状态后端为rocksDB** 线上环境建议不要使用memory 作为状态后端* TIMER分为HEAP(默认,性能更好)和RocksDB(扩展好)*/val checkpointDataUri ="hdfs:///flink/checkpoints-data"val tmpDir = "file:///tmp/rocksdb/data/"val fsStateBackend: StateBackend = new FsStateBackend(checkpointDataUri)val rocksDBBackend: RocksDBStateBackend = new RocksDBStateBackend(fsStateBackend, TernaryBoolean.TRUE)val config = new Configuration()config.setString(RocksDBOptions.TIMER_SERVICE_FACTORY,RocksDBStateBackend.PriorityQueueStateType.ROCKSDB.toString)rocksDBBackend.configure(config)rocksDBBackend.setDbStoragePath(tmpDir)env.setStateBackend(rocksDBBackend.asInstanceOf[StateBackend])/*** 获取source*/val SOURCE = new sourceval gpsSource = SOURCE.getGpsSource(env,3)/***过滤掉不是车辆GPS的报文数据* gps数据的命令字为41*/val GpsFilterMapStream = gpsSource.filter(x => {var out = falseif (x.length >= 12 ){/*** length从报文中截取出报文长度的编码* command为报文的命令字* dataLen报文长度*/val length = x.substring(4 , 8)val command = x.substring(10 , 12)val dataLen = Integer.parseInt(length , 16)if("41".equals(command) & x.length > 8 + dataLen*2){out = true}else{out = false}}else{out = false}out}).name("过滤非gps报文").setParallelism(3)/*** 报文字段拆分*/.map(x =>{(x.substring(42 , 58),x.substring(160 , 162),x.substring(110 , 120),x.substring(120 , 128),x.substring(144 , 148),x.substring(164 , 172),x.substring(156 , 158),x.substring(128 , 140),x.substring(58 , 74),x.substring(92 , 94))}).name("拆分报文").setParallelism(3)/***将拆分出来的报文 转化成 具体的字段值*/val messageSplitStream = GpsFilterMapStream.map(x =>{var speed = "0.0"var mileage = "0.0"try{speed = (x._5.toDouble/10).toStringmileage = (x._6.toDouble/100).toString}catch{case e:Exception => log.error(e.getMessage)}gps(asciiToString(stringToDecimal(x._1)),if(!"1".equals(bytes2BinaryStr(hexStringToByte(x._7)).substring(6,7))) "营运中" else operationStatus2(x._2),DfToDd("lon" , x._3).toString,DfToDd("lat" , x._4).toString,speed,mileage,"20" + x._8,bytes2BinaryStr(hexStringToByte(x._7)).substring(3,4),asciiToString(stringToDecimal(x._9)).replaceAll("\u0000" , ""),Integer.parseInt(x._10 , 16).toString)}).name("根据深标协议对字段解码").setParallelism(6).filter(x =>{(x.lat != "0.0" || x.lng != "0.0") && x.line_code != null && x.line_code != "" && x.station_num != null && x.station_num != "" && x.busId != null && x.busId != ""}).name("过滤无效gps").setParallelism(6)val gps_join_stop = AsyncDataStream.unorderedWait(messageSplitStream , new gpsJoinStop , 2 , duration.MINUTES).name("gps数据join线路站点信息").setParallelism(10)val gpsNextStream = gps_join_stop.map(x =>{val next_Station = nextStation(x.station_num,x.up_end_order,x.down_end_order,x.stop_list)val comfort = Random.shuffle(seq).take(1)(0)gpsSink.apply(x.busId,x.runType,x.lng,x.lat,x.speed,x.mileage,x.direction,next_Station,x.dataTime,x.bus_type,if(x.station_num== x.up_end_order || x.station_num== x.down_end_order) 100 else comfort)}).name("计算车辆下一站").setParallelism(10)gpsNextStream.addSink(new gpsSinkToMySql).name("gpsSinkToMySql").setParallelism(10)env.execute("GPS实时任务")}/*** 计算车辆实时下一站* @param current_order 车辆当前站点序号(上下行合在一起的序号)* @param up_end_order 上行终点站序号* @param down_end_order 下行终点站序号* @param stop_list 线路站点列表,jsonString格式* @return 返回车辆前站点序号对应的下一站,当车辆到达上行或者下行终点站时返回 “--”*/def nextStation (current_order:String , up_end_order:String , down_end_order:String , stop_list:String): String = {var next_station = "--"if(stop_list == null || current_order == null){next_station}else{if(up_end_order == current_order || down_end_order == current_order){next_station}else{next_station = JSON.parseObject(stop_list).getString((current_order.toInt + 1).toString)if(next_station == null){"--"}else{next_station}}}}}

若有收获,就点个赞吧
0 人点赞
