在80年代中后期,有一种思潮,“一切皆对象”。但是后面大家发现,这不现实
- 一个int、一个double这样的类型不需要抽象成对象
- 在业务场景中,一些很小的东西,看起来细粒度的东西,你可能也会考虑抽象成对象
但一旦你用的多了,就有倍乘效应,带来非常大的开销。
那怎么办了?那就不用面向对象了吗?
- 常见的优化方法,就是用共享的方式。
比如说字符串这件事情:字符串常量所占内存的比重都是比较大的
- 常见的系统,比如STL中,都对字符串用了共享技术
- 有些语言,比如Java、C#,它们在编译器层面,都不是类库层面,去用一些共享技术。这些编译器层面的技术虽然和享元模式不同,但思想都是相通的,都是用“共享技术”来共享大量细粒度对象
比如线程,线程也是开销很大的
- 通常我们会用线程池来实现一些共享
但到什么量才算大
- 这个是需要评估的
- 去测量,量多大的情况下会带来内存层面上的负担、资源层面上的负担
附:共享技术,是面向对象中经常用来解决性能问题的一个手段
动机
在软件系统采用纯粹对象方案的问题在于大量细粒度的对象会很快充斥在系统中,从而带来很高的运行时代价——主要指内存需求方面的代价。
如何在避免大量细粒度对象问题的同时,让外部客户程序仍然能够透明地使用面向对象的方式来进行操作?
模式定义
运行共享技术有效地支持大量细粒度的对象——《设计模式》GoF。
结构
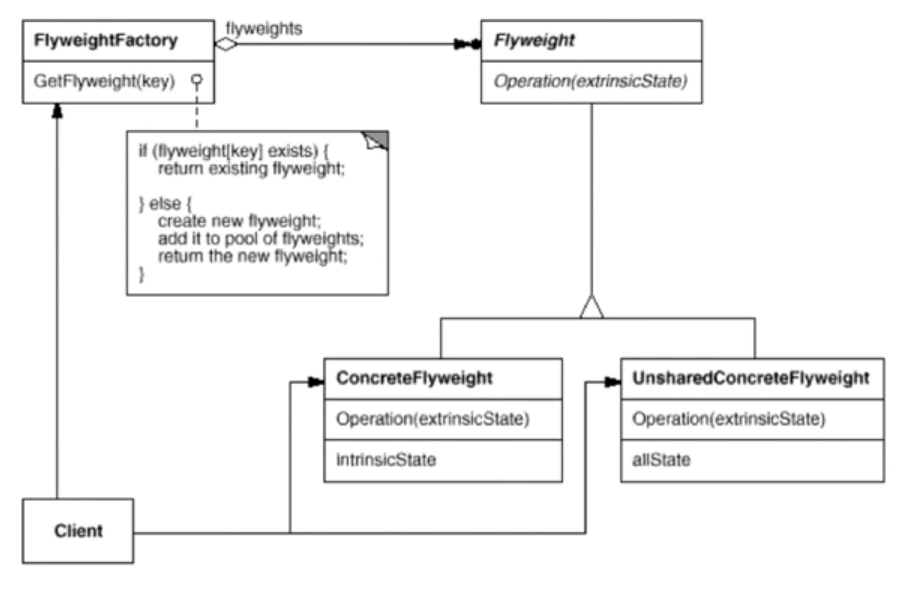
享元工厂,用于创建享元
//根据key来创建对象FlyweightFactory::GetFlyweight(key) {if( flyweight[key] exists ) { //存在就返回return existing flyweight;} else { //不存在则创建create new flyweight;add it to pool of flyweights;return the new flyweight;}}
还有一些别的类
- ConcreteFlyweight支持享元的对象
- UnsharedConcreteFlyweight不支持享元的对象
代码
把字体抽象成一个对象(一切皆对象)
字体对象的量很大
- 严格意义上讲,每个字符都有一个字体对象
- 但实际上,绝大多数字符的字体对象是相同的
- 如果不加区分的,为每个字符都创建一个字体对象。比如你有一万个字符,为每一个字符都创建一个字体对象,那就有1万个字体对象
这时候,就需要用享元的方式来设计
- 对于一个Key,就创建了一个字体对象
- 比如你的系统只用到了10种字体,那你的系统就维护10个字体对象即可
```cpp
class Font {
private:
//字体唯一的key
string key;
//object state
//….
public:
Font(const string& key){
} };//根据字体的Key,可以获得该字体的相关资源//...
//字体工厂(即flyweightfactory)
class FontFactory{
private:
//对象池
map
public: //根据key去查找 Font GetFont(const string& key){ map<string,Font>::iterator item=fontPool.find(key);
//共享的思想:有就返回,没有就创建if(item!=footPool.end()){return fontPool[key];}else{Font* font = new Font(key);fontPool[key]= font;return font;}}void clear(){//...}
}; ```
要点总结
面向对象很好地解决了抽象性的问题,但是作为一个运行在机器中的程序实体,我们需要考虑对象的代价问题。
Flyweight主要解决面向对象的代价问题,一般不触及面向对象的抽象问题。
Flyweight采用对象共享的做法来降低系统中对象的个数,从而降低细粒度对象给系统带来的内存压力。在具体实现方面,要注意对象状态的处理。
- 一般享元模式创建出来的对象都是只读的
- 但是例子字符串,它通过copy on write的方式来解决这个只读问题,可以实现读写
对象的数量太大从而导致对象内存开销加大——什么样的数量才算大?这需要我们仔细的根据具体应用情况进行评估,而不能凭空臆断。
比如:
- 先看一个对象占用多少空间
- 再考虑峰值的时候,某一类对象在内存中一共有多少个
- 享元模式内部的数据结构也是需要评估的。比如上面的对象池(
map<string, Font*>)

若有收获,就点个赞吧
0 人点赞
