现有方法的局限
- 大多数根因定位的工作都是基于建立一个依赖图(Dependency Graph, DG)或者网络结构,拓扑关系。
- 但是,软件服务的DG很难获得,切在软件服务突变的情况下,很难维护这些图
直接使用监控数据训练一个机器学习模型不work
- 问题定义的不够好
- 信息不完整
- 错误case不够多
- 缺乏解释性
因此提出想法,使用领域知识(domain knowledge)
- 领域知识主要是指从数据里面很难学到的,但在手工定位的时候总结出来的信息
- 基于领域知识提出新的架构
由手工定位的5步启发
- 在后台,运维人员可以用一些统计算法来检测大批KPI是否发生异常(问题:效率不高,准确度不高)
- 在出问题后,运维人员手动的扫描KPI,,找出在异常发生时间周围检测出一场的KPI(问题:手工)
- 手工对这些KPI进行排序(问题:手工)
- 对高排名的KPI,一条条核对
- 找到根因后,修复bug
提出FLUXRANK

挑战
- 怎么快速量化KPI的异常程度
- 怎么对KPI进行聚类
-
贡献
提出了一个基于和密度估计(Kernel Density Estimation, KDE)的非参数的轻量算法来量化和比较大量KPI
- 提出一个新方法聚类,基于DBSCAN
- 提出一个新方法排序
Change Quantification
- change degree & change start time
- change start time:
- 寻找一个kpi开始发生变化的时间可以转变为一个经典的变化点检测问题
- 由于我们的问题是已经给定了故障时间,因此我们只需要检测故障时间周围kpi的变化
- 使用Abs_Dev来寻找开始时间Tc,即绝对微分值最大的地方(突增突降)
- change degree
- 根据历史数据,计算条件概率
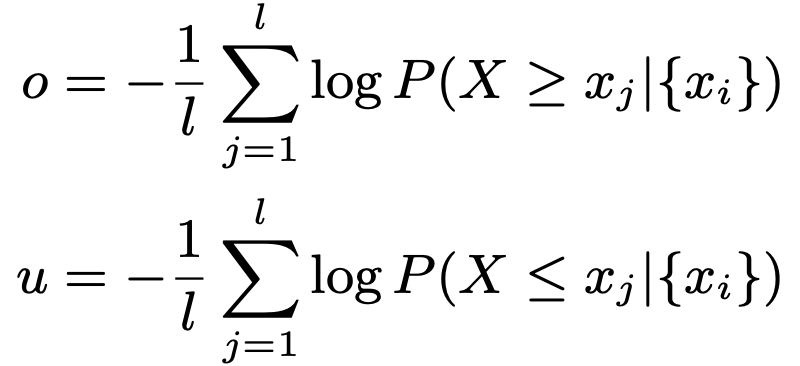
- 其中P可为beta分布,poisson分布,gaussian分布,不同的指标服从不同的分布,作者在文中列出
- 根据公式计算突增程度o,和突降程度u
- 这样我们就获得了三个参数Tc,o,u
Digest Distillation
- 对于大型服务系统来说,一般会有多台机器部署,其中每台机器有很多KPI,可以构造向量
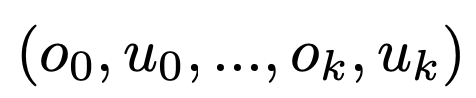 ,其中oi跟ui表示KPIi的突增突降程度
,其中oi跟ui表示KPIi的突增突降程度- 衡量距离,pearson相似系数或其他的统计指标
- 使用DBSCAN进行聚类,每一个聚类结果称作一个digest
Digest Ranking
最后,就是对聚类结果的排序工作。通过观察会发现:
- 变化开始时间(change start time)
 会在失败发生时间
会在失败发生时间  之前;
之前; - 不同的故障机器 KPIs 的 change start time 是非常接近的;
- 故障机器的一些 KPIs 的 change degree 是非常大的;
- 故障机器的占比是与故障原因相关的,故障机器越多说明故障越大;

若有收获,就点个赞吧
0 人点赞
