背景
- 由于业务的不断增长,企业建立了规模庞大的数据中心,硬件的可靠性一直是影响整个IT基础架构可靠性的关键因素,硬件错误在大型系统里是很普遍,有时候会导致严重的错误,造成经济损失。
Motivation
- 为了理解这些故障模型(failure model),从而帮助企业在软件堆栈复杂性,硬件和运营成本之间取得适当的平衡,从而降低数据中心的总体拥有成本(TCO)
- 现在的数据中心在很多方面都跟以前不一样了
- 比如硬件设计制造得更可靠了,有了更好的故障检测系统,运维人员也积累了更多的经验来操作运行一个大型数据中心
- IT公司变得更加成本敏感,采用更低成本的硬件
- 硬件组件和工作负载的异构性也更高,导致故障模型更加复杂
- 通常认为硬件的不可靠性塑造了故障冗余设计
- 但我们认为不断提高的基于软件的故障冗余设计导致运维人员更少的关心硬件的可靠性
- 基于以上变化,作者认为是时候在现代大型数据中心上做一个故障study了
研究问题
- 对多个拥有成百上千太服务器、服务千万用户的数据中心近4年的故障进行综合分析
- 数据:
- 硬件故障单(hardware failure operation tickets, FOT)
- 数据是通过一个集中式的故障管理系统收集得到的,该系统监控大多数的服务器,并记录每个组件的故障和运维人员的操作
- 研究角度:
- 从故障的时间、空间,该服务器属于哪个产品线,运维人员的反应等角度进行学习
- 首先探索不同组件故障的时间分布,空间分布
- 然后聚焦于相关联的故障(correlated failure),因为人们认为他们最影响软件错误冗余
- 最后,描述运维人员对这些故障的反应
- 本文的观测结果与数据中心里新软件的设计和工作量高度相关,这些故障模式不仅给开发故障管理系统提供了建议,还要求设计故障处理机制的新方法。
方法与数据
- 数据:
- 29万FOT,可分为3大类别
- D_fixing:Issue a repair order 占比70.3%
- D_error:Not repair and set to decommission 占比28%
- D_falsealarm:Mark as a false alarm 占比1.7%
- 我们可以看到,超过1/4的故障是由于保修外的硬件造成的,根本无法解决。操作员将部分故障但可操作的服务器留在生产中,然后将完全损坏的服务器停用。我们还注意到错误警报率极低,显示了硬件故障检测的有效性(高精度)。
- FOT有两个产生来源
- 故障检测程序
- 运维人员
- FOT产生过后会进入一个集中式的故障管理系统(failure management system, FMS)
- FMS记录超过70种类型的故障,涵盖九种类别的组件
- 比如硬盘, SSD, RAID card, flash card, 内存, 主板, CPU, fan, 电源
- 所有人类加入的FOT都会被标为miscellaneous类别
- 故障的定义:
- 本文认为每个D_fixing, D_error都为一个故障
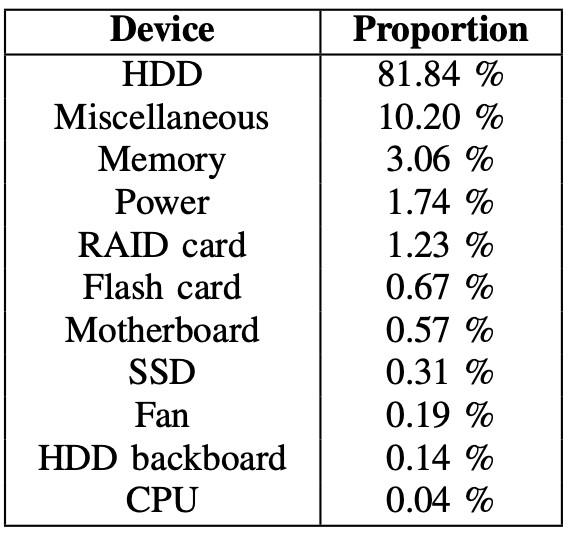
- 29万FOT,可分为3大类别
研究方法:
假设一:组件故障的平均次数在一周的不同日期是一致随机的,否
- 假设二:在一天的每个小时内,组件故障的平均次数是均匀随机的,否
- 对于一些组件来说,故障的数量与负载大小(workload)是相关的,硬盘,内存尤其如是。
- 但作者想强调,这种相关性可能并不意味着低工作负载会减少硬件故障的可能性。实际上,我们认为较高的利用率会导致故障更有可能被异步检测到
- 该观察结果揭示了基于日志的故障检测的局限性-在使用组件之前,它不会检测组件中的故障。另外,仅在工作负载已经很重时才检测故障会增加此类故障对性能的影响。故障管理团队正在研究一种主动的故障探测机制,以解决该问题。
- 如果故障报告需要人员参与,则检测可能会在工作日和正常工作时间进行。对于大多数手动报告的其他故障而言,这都是正确的
- 在短时间内,某些组件可能会大量出现故障
- 对于一些组件来说,故障的数量与负载大小(workload)是相关的,硬盘,内存尤其如是。
B. Time between failures(TBF)
- 假设三:数据中心所有组件的TBF遵循指数分布,否
- 假设四:数据中心单个组件类别的TBF遵循指数分布,否
- 正如先前的study指出,每个组件的故障率会随着时间的推移改变,从而影响TBF,这是指数分布无法捕获的
- 关联故障的影响,有时候故障是大面积同时出现的
C. Failure rate for a single component in its life cycle
- 人们通常认为,组件故障的可能性与其使用寿命有关,之前的study表明,浴缸曲线模型不能很好的描述硬盘故障的概率,本文的study表面,对所有component,这个结论都是对的
- 我们还观察到,对每个组件类别,随着使用时间的增加,故障会变多
D. Repeating failures and the effectiveness of repairs
- repeated failures:当问题被标为解决后,又发生问题的故障
- 超过85%的固定组件永远不会重复相同的故障。我们估计,曾经发生故障的所有服务器(数千台服务器)中约有4.5%遭受重复故障的困扰。
我们观察到曾经发生故障的2%的服务器占所有故障的99%以上。换句话说,故障在各个服务器之间的分布极为不均匀。
问题
study的目的是什么
1
这篇论文study出了几个发现,分别是用什么方法study出来的
- 1
这篇论文的现实意义,如何指导我做empirical study

若有收获,就点个赞吧
0 人点赞
