出发点:
- 现代大数据中心,非常庞大,复杂,由分布式系统构成,出现错误是很常见的的,但传统的依赖于人和人定的规则来定位错误不够有效率,且容易出错
- 为了更好的选择这个问题该由哪个团队解决(分锅)
使用机器学习来自动分析这些复杂的关系,定位问题
- 挑战:
- 故障,组件,监控数据一直在变
- 数据维度很多,来源各种各样
- 监控数据不全或者不规范
- 数据不是对所有团队可见
- 设计目标:
- 找到正确的团队来寻找根因(任务派发正确)
- 故障派发要自动且稳健
- 这个系统不能很大
- 团队可以给出专家经验,但不决定派给谁
- 系统必须在不常见的部署组件上很稳健
- AutoML为啥不行:
- 对输入数据格式敏感,不好用
- 如果训练集数据变化很微小,就表现不好
- 黑盒
- 训练代价很大
Scout架构
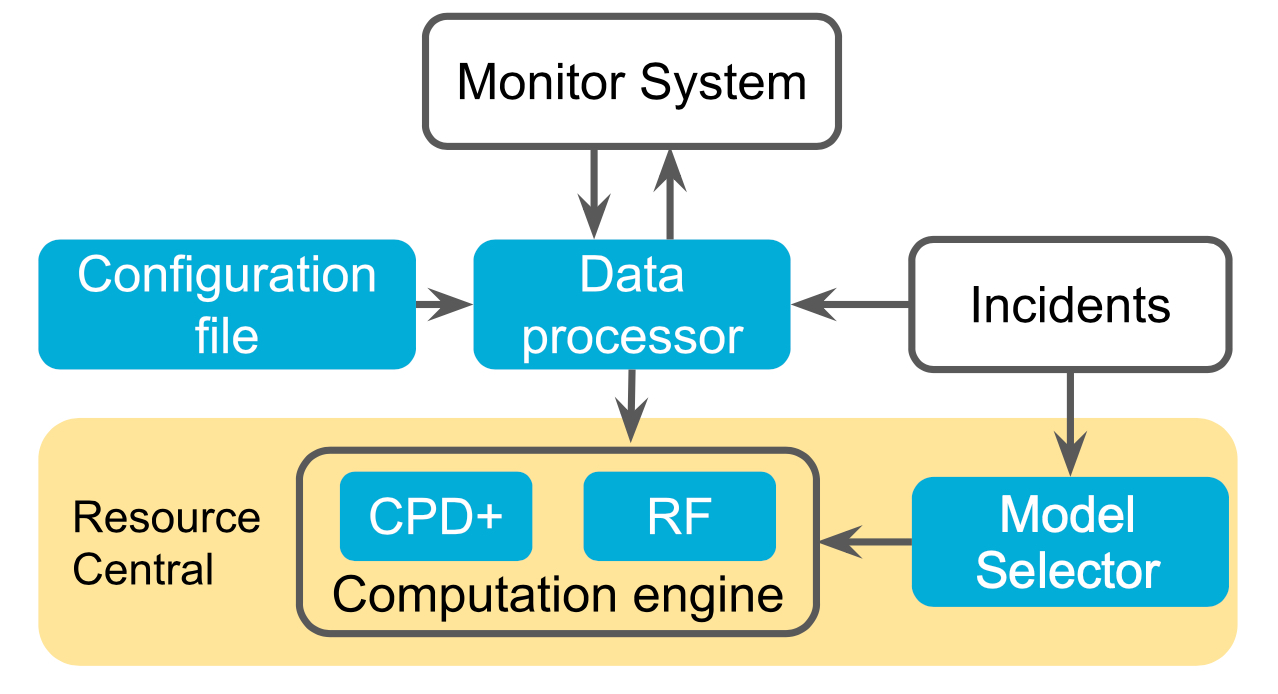
监控要求:
- 决定哪份监控的数据与异常事件相关
- 用数据之前预处理
- 一些起到帮助的方法:
- 给监控数据打标签
- 从异常事件里提取组件(可以用组件之间的拓扑关系)
特征构建与预测
- 有监督模型与无监督模型并用(有监督模型来判断常见事件,无监督模型来判断不常见事件)
- 特征构建:
- 随机森林
- 每个组件的特征:
- 事件/告警:统计在过去T时间内的数量
- 时间序列数据:统计过去T时间内的统计特征:均值,标准差,最大最小值,K分位点
- 合并多个组件的特征:适配组件采集出的数据
- 每个组件的特征:
- Modified Change Point Detection(CPD+)
- 一个假设:当一个团队需要为某个异常事件负责时,这些组件的数据通常会发生偏移,从一个分布变到另一个分布
- 虽然没法通过点的变化来判断哪个团队该为此负责,但是可以通过点的变化,来学习这些变化是不是真正的异常
- 随机森林
模型选择:
- 决定异常事件是不是范围内的
- 决定用RF还是CPD+,通过元学习来判断事件是不是新事件(重要关键词和出现频率)
pipeline:
- 发生异常事件
- 提取相关组件,如果不成功,转交传统的派发系统
- 选择模型
- 提取特征
- 分离
数据集:
- Azure上9个月的数据
- precision和recall都能做到97%

若有收获,就点个赞吧
0 人点赞
