问题定义
- 在大型分布式系统中,使用分层的因果关系图,自动定位性能问题
- 由于很难找到一个通用的方法来诊断所有类型的性能问题,作者将问题限定在一个运行环境改变这个子集上
- 因为在review了一些开源系统的bug过后,作者发现bug可以导致性能问题
- 仅考虑与物理资源或逻辑资源异常消耗相关的错误
- 选择这些指标的原因是,这些指标可以在运行时很容易的收集,无需检测源代码,且软件中存在大量此类错误
- 作者的目标是将导致性能问题的根因归结于上述提到的性能指标上
- 为了达成上述目标,作者建立了一个自动、黑盒的线上性能诊断系统—CauseInfer
- CauseInfer的基本思想是,通过捕获因果关系来建立一个因果关系图,然后通过因果关系图中的原因路径来推断根因
- 要建立两层 层级因果关系图
- 一个粗粒度的图,目的是在服务级别定位根因
- 一个细粒度的图,目的是找出性能问题的真正原因
贡献
- 提出了Bayesian Change Point(BCP)算法来寻在突变点
- 提出了一个轻量级的服务依赖发现方法
- 提出了一个基于PC算法的新的因果关系图建立方法
- 设计并实现了CauseInfer系统
系统总览
- CauseInfer的核心模块包括一个因果图构造器和一个推断引擎
- 因果图构造器自动的构建一个两层的层级因果关系图
- 推断引擎通过因果关系图,找出问题的根因
- 在目标系统上,CauseInfer部署在每一个节点,分布式部署
系统设计
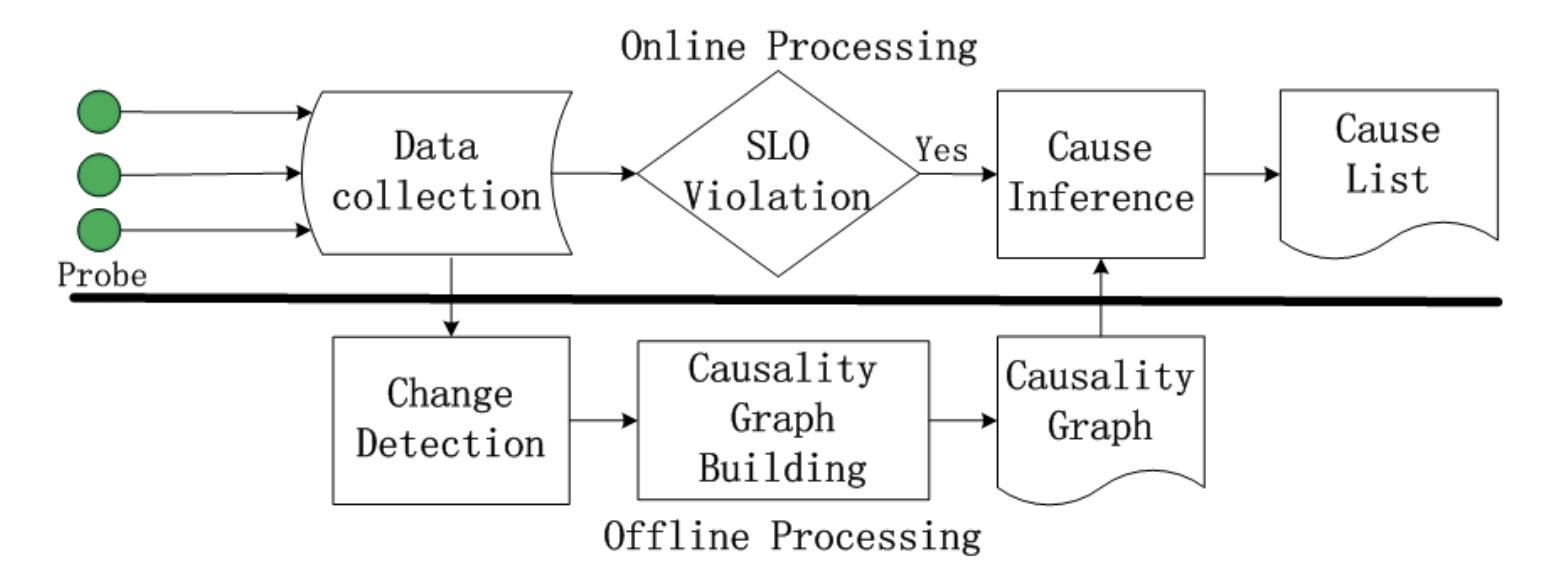
数据收集
- 收集高维的,运行时数据
突变点检测
- BGP算法
构建因果图
- 两个变量X,Y,如果X变化能导致Y的分布变化,且Y不能导致X,则有X->Y
- 不准两个变量相互影响,因此可以因果图是一个DAG
服务依赖图
- 基于一个假设,如果两个服务一件有提供服务或者使用服务关系,则相关服务之间的流量延迟通常表现出“典型”峰值
- 通过netstat的信息,建立(ip,protocol)->(ip,protocol)的映射,流量延迟关系用来确定箭头指向
指标因果图
- 使用PC算法来建立一个DAG
- 激进的算法:不使用任何先验知识来构建因果关系图
- 保守的算法:使用一些先验知识来构建因果关系图,包括某个变量在图中没有父亲节点,或某个变量在图中没有依赖
检测
根据指标因果图,DFS到最深的异常节点

若有收获,就点个赞吧
0 人点赞
