https://arxiv.org/abs/1301.3781
著名的word2vec
Previous Work
Feedforward Neural Net Language Model (NNLM)
网络结构:input,projection,hidden,output
复杂度:
其中N是选择的N个单词,D是一个单词的projection结果,D维的,H是Hidden层的大小,V是vocabulary的大小,使用one-of-encoding。
优化:分类时使用二叉树,可以将最后一项的复杂度V降到  ,所以整个复杂度绝大多数还是由
,所以整个复杂度绝大多数还是由 决定的,在本论文中的模型使用分层的Softmax(hierarchicalsoftmax),此时vocabulary通过哈夫曼二叉树来表示,复杂度可以优化到
决定的,在本论文中的模型使用分层的Softmax(hierarchicalsoftmax),此时vocabulary通过哈夫曼二叉树来表示,复杂度可以优化到 ;
;
Recurrent Neural Net Language Model (RNNLM)
就是RNN的model,提到了LSTM。
复杂度:
优化:还是使用分层的Softmax可以将最后一项的复杂度降为 ,整个的复杂度还是由
,整个的复杂度还是由 决定的。
决定的。
New Log-linear Models
模型结构是:input、projection、output三层,没有hidden layer
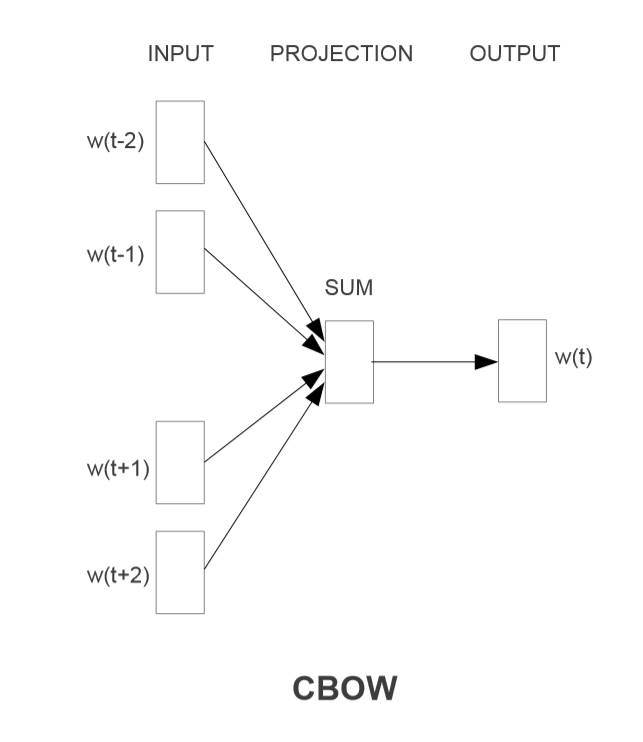
ContinuousBag-of-WordsModel
根据上下文,预测中心词汇;
经过同样的分层softmax优化之后,复杂度为:
Continuous Skip-gram Model
根据中心词,预测上下文
经过同样的分层softmax优化之后,复杂度为:
其中C是单词之间的最大距离,我认为是半径?可以这么理解,对于每个训练词汇,每次从中1到C的范围中随机选一个数字R,R个单词作为历史词汇,R个单词作为未来的词汇,就是上下文,最后R+R个单词作为输出。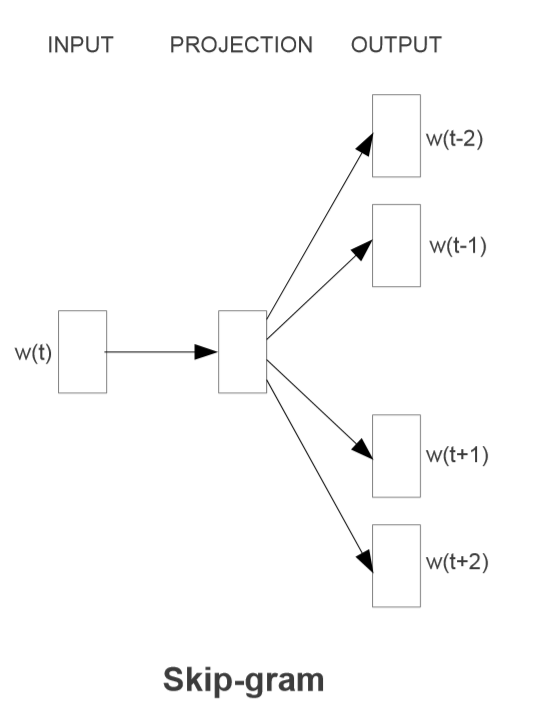
Result
略
更多详情请参考:

若有收获,就点个赞吧
0 人点赞
