- Simple Sentiment Analysis">实验1 - Simple Sentiment Analysis
- Upgraded Sentiment Analysis">实验2 - Upgraded Sentiment Analysis
- Faster Sentiment Analysis">实验3 - Faster Sentiment Analysis
- Multi-class Sentiment Analysis">实验5 - Multi-class Sentiment Analysis
- Convolutional Sentiment Analysis">实验4 - Convolutional Sentiment Analysis
- Colab
- Pre-train Word Vectors
实验1 - Simple Sentiment Analysis
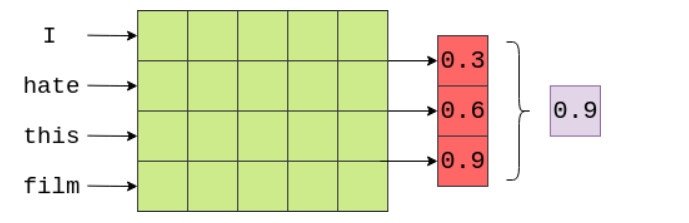
网络结构大致是:one-hot encoder => embedding => rnn => fullly-connection => sigmod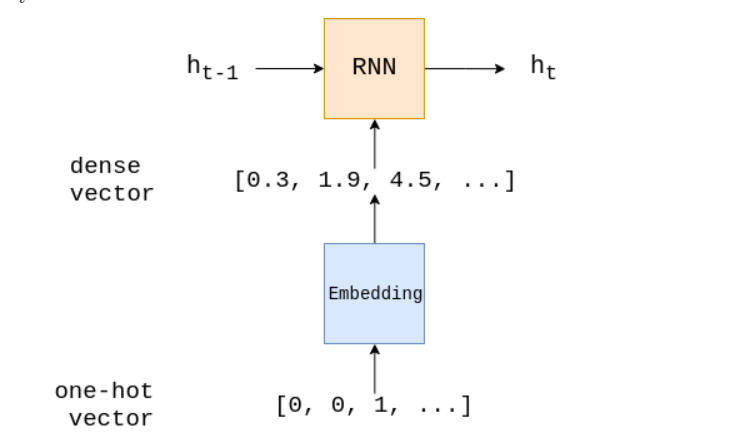
实验结果:效果一般,Test Loss: 0.676 | Test Acc: 60.82%
实验2 - Upgraded Sentiment Analysis
Preparing Data
为了告诉RNN实际的句子有多长,我们通过设置
include_lengths = True给TEXT fieldTEXT = data.Field(tokenize = 'spacy', include_lengths = True)
使用预训练的词向量
一般来说,TorchText对在在词表但是不在预训练词向量中的未登录词汇初始化为0,我们可以给他初始化为一个标准正态分布。
TEXT.build_vocab(train_data,max_size = MAX_VOCAB_SIZE,vectors = "glove.6B.100d",unk_init = torch.Tensor.normal_)
另一件事就是对于所有packed padded sequences,都需要根据其长度排序。
train_iterator, valid_iterator, test_iterator = data.BucketIterator.splits((train_data, valid_data, test_data),batch_size = BATCH_SIZE,sort_within_batch = True,device = device)
Build the Model
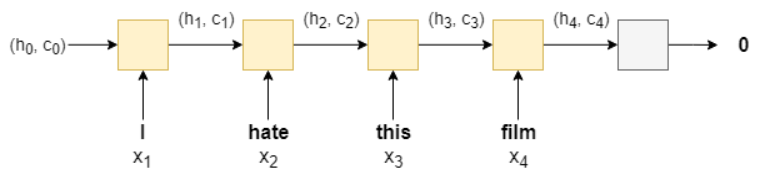
LSTM
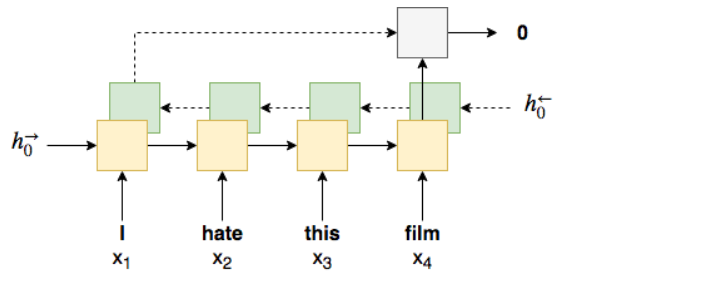
Bidirectional RNN
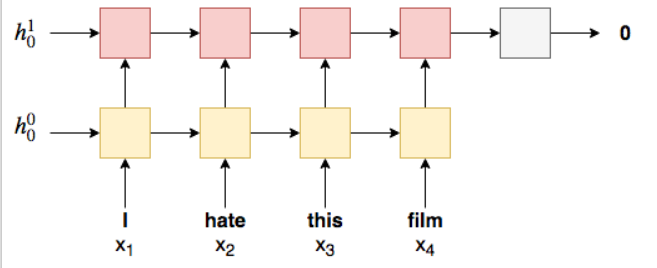
Deep RNNs
Regularization
一般来讲,参数越多,过拟合的可能性越大,使用Dropout来进行正则化,Dropout的思想就是随机drop一些神经单元,用一个超参数来控制dropout rate。为什么Dropout会work?一个解释是经过dropout后的model可以看作一个弱学习器weaker,此时预测的过程就是从这些弱学习器中集成获得较好的performance。
Implementation Details
- Dropout在forward方法中使用,但是dropout不能用在input或者output层,即只能在中间层使用;
- 将embeddings送入RNN的之前,需要先将其用其nn.utils.rnn.packed_padded_sequence处理,然后送入RNN,这样就可以让RNN只处理真实的sequence
- 接下来继续unpack output sequence,通过使用nn.utils.rnn.pad_packed_sequence
Result
实验3 - Faster Sentiment Analysis
def generate_bigrams(x):n_grams = set(zip(*[x[i:] for i in range(2)]))for n_gram in n_grams:x.append(' '.join(n_gram))return x
generate_bigrams(['This', 'film', 'is', 'terrible'])output:['This', 'film', 'is', 'terrible', 'film is', 'is terrible', 'This film']
FastText
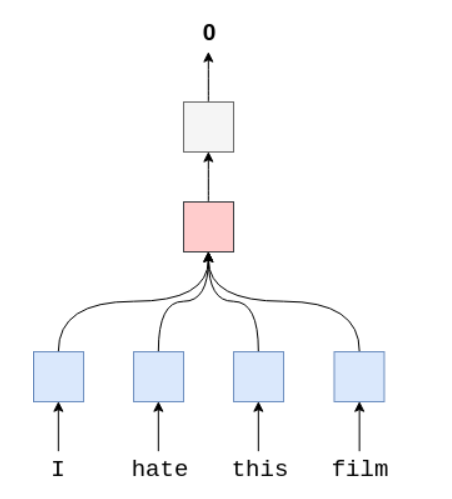
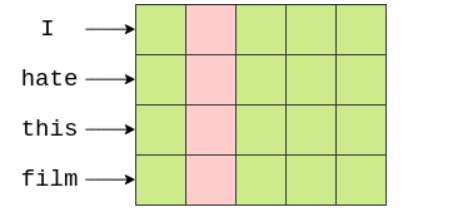
改变数据的shape,然后将其做平均,来表示整个句子…
class FastText(nn.Module):def __init__(self, vocab_size, embedding_dim, output_dim, pad_idx):super().__init__()self.embedding = nn.Embedding(vocab_size, embedding_dim, padding_idx=pad_idx)self.fc = nn.Linear(embedding_dim, output_dim)def forward(self, text):#text = [sent len, batch size]embedded = self.embedding(text)#embedded = [sent len, batch size, emb dim]embedded = embedded.permute(1, 0, 2)#embedded = [batch size, sent len, emb dim]pooled = F.avg_pool2d(embedded, (embedded.shape[1], 1)).squeeze(1)#pooled = [batch size, embedding_dim]return self.fc(pooled)
Result
- epoch:15 Train Acc:93% Val. Acc:89% Test Loss: 0.394 | Test Acc: 86.45%
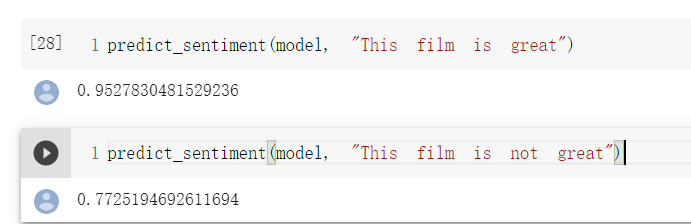
“This film is great” 这个case没问题,加个not就坏掉了。。。
实验5 - Multi-class Sentiment Analysis
同实验4,更换了数据集,6分类任务,使用softmax,而非BCEWithLogitsLoss+sigmoid
References
- Enriching Word Vectors with Subword Information
- Bag of Tricks for Efficient Text Classification
- Pytorch中的cat、stack、tranpose、permute、unsqeeze
- Pytorch文本情感分析
实验4 - Convolutional Sentiment Analysis
TextCNN
经典的TextCNN:https://arxiv.org/abs/1408.5882
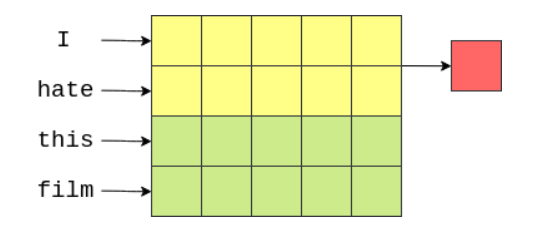
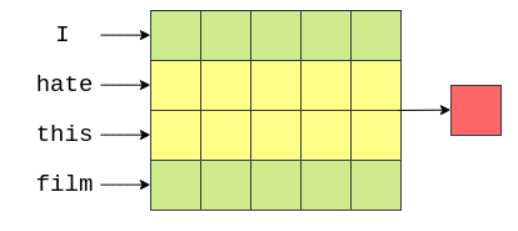
import torch.nn as nnimport torch.nn.functional as Fclass CNN(nn.Module):def __init__(self, vocab_size, embedding_dim, n_filters, filter_sizes, output_dim,dropout, pad_idx):super().__init__()self.embedding = nn.Embedding(vocab_size, embedding_dim, padding_idx = pad_idx)self.conv_0 = nn.Conv2d(in_channels = 1,out_channels = n_filters,kernel_size = (filter_sizes[0], embedding_dim))self.conv_1 = nn.Conv2d(in_channels = 1,out_channels = n_filters,kernel_size = (filter_sizes[1], embedding_dim))self.conv_2 = nn.Conv2d(in_channels = 1,out_channels = n_filters,kernel_size = (filter_sizes[2], embedding_dim))self.fc = nn.Linear(len(filter_sizes) * n_filters, output_dim)self.dropout = nn.Dropout(dropout)def forward(self, text):#text = [batch size, sent len]embedded = self.embedding(text)#embedded = [batch size, sent len, emb dim]embedded = embedded.unsqueeze(1)#embedded = [batch size, 1, sent len, emb dim]conved_0 = F.relu(self.conv_0(embedded).squeeze(3))conved_1 = F.relu(self.conv_1(embedded).squeeze(3))conved_2 = F.relu(self.conv_2(embedded).squeeze(3))#conved_n = [batch size, n_filters, sent len - filter_sizes[n] + 1]pooled_0 = F.max_pool1d(conved_0, conved_0.shape[2]).squeeze(2)pooled_1 = F.max_pool1d(conved_1, conved_1.shape[2]).squeeze(2)pooled_2 = F.max_pool1d(conved_2, conved_2.shape[2]).squeeze(2)#pooled_n = [batch size, n_filters]cat = self.dropout(torch.cat((pooled_0, pooled_1, pooled_2), dim = 1))#cat = [batch size, n_filters * len(filter_sizes)]return self.fc(cat)
Result
- Epoch: 5 Train Acc: 87.80% Val. Acc: 85.92% Test Loss: 0.341 Test Acc: 85.20%
说明还是有明显效果的。
References
- https://cs231n.github.io/convolutional-networks/
- https://ujjwalkarn.me/2016/08/11/intuitive-explanation-convnets/
Colab
由于不可抗拒的因素,我们必须会用到一些外力才可以正常访问Google等网站,如果你的工具不是很稳定,那么使用Colab的时候就不会那么愉快。有时候本想着安安稳稳挂机一夜,第二天早上一看电脑才发现真的是“挂”了一夜:电脑开着,Colab却挂了。其实问题也很简单,只需要一段小小的代码就可以解决这个问题:
function ClickConnect(){console.log("Working");document.querySelector("colab-toolbar-button#connect").click()}setInterval(ClickConnect,60000)
打开你的浏览器,执行F12或者Ctrl + Shift + i , 将上面代码复制粘贴到Console框里按回车即可。
Pre-train Word Vectors
- charngram.100d
- fasttext.en.300d
- fasttext.simple.300d
- glove.42B.300d
- glove.840B.300d
- glove.twitter.27B.25d
- glove.twitter.27B.50d
- glove.twitter.27B.100d
- glove.twitter.27B.200d
- glove.6B.50d
- glove.6B.100d
- glove.6B.200d
- glove.6B.300d

若有收获,就点个赞吧
0 人点赞
