1.异步-流复制
1.1 环境准备:
| 主节点 | pg71 | 10.0.0.71 |
|---|---|---|
| 备节点 | pg72 | 10.0.0.72 |
1.2 主从配置:
1.2.1 以拷贝数据文件方式部署流复制:(了解)
# 在pg01和pg02上创建操作系统用户和相关目录:# 说明:/database/pg10/pg_root目录存储数据库系统数据文件,/database/pg10/pg_tbs存储用户自定义表空间文件:useradd postgrespasswd postgresmkdir -p /database/pg13/pg_rootmkdir -p /database/pg13/pg_tbschown -R postgres:postgres /database/pg13# 在pg01和pg02添加postgres操作系统用户环境变量:su - postgresvim /home/postgres/.bash_profileexport PATHexport PGPORT=5432export PGUSER=postgresexport PGDATA=/database/pg13/pg_rootexport LANG=en_US.utf8export PGHOME=/opt/pgsqlexport LD_LIBRARY_PATH=$PGHOME/lib:/lib64:/usr/lib64:/usr/local/lib64:/lib:/usr/lib:/usr/local/libexport PATH=$PGHOME/bin:$PATHexport MANPATH=$PGHOME/share/man:$MANPATHalias rm='rm -i'alias ll='ls -lh'# 解压并编译postgres软件:yum install -y bison flex readline-devel zlib-deve1 zlib zlib-develtar xf postgresql-13.2.tar.gzcd postgresql-13.2/./configure --prefix=/opt/pgsql_13gmake world && gmake install-worldln -s /opt/pgsql_13 /opt/pgsql# 在pg01上初始化数据库:chown -R postgres. /opt/su - postgresinitdb -D /database/pg13/pg_root -E UTF8 --locale=C -U postgres -W# pg01上修改postgres.conf文件:vim postgresql.conflisten_addresses = '0.0.0.0'wal_level = replicaarchive_mode = onarchive_command = '/bin/date'max_wal_senders = 10hot_standby = on# pg01修改pg_hba.conf文件:vim pg_hba.confhost all all 0.0.0.0/0 trusthost replication repuser 10.0.0.71/24 md5host replication repuser 10.0.0.72/24 md5# pg01启动并创建流复制用户:pg_ctl startpsql -U postgrescreate user repuser replication login connection limit 5 encrypted password '123456';create database repuser;# pg01发起在线备份:select pg_start_backup('francs_bkl');# 打包文件,并发送到从节点cd /database/pg13tar czvf pg_root.tar.gz ./pg_rootscp -rp pg_root.tar.gz postgres@10.0.0.52:/database/pg13# pg02 从节点解包,并修改postgresql.conf配置文件:tar xvf pg_root.tar.gzvim postgresql.confrecovery_target_timeline = 'latest'primary_conninfo = 'host=10.0.0.51 port=5432 user=repuser'touch standby.signalchown -R postgres. standby.signal# pg01关闭在线备份:su - postgrespsql -U postgresselect pg_stop_backup();# pg02 从库配置隐藏文件:su - postgresvim ~/.pgpass10.0.0.51:5432:replication:repuser:12345610.0.0.52:5432:replication:repuser:123456chmod 0600 .pgpass# 从库进行启动:pg_ctl start
1.2.2 以pg_basebakup方式部署流复制:
#pg01及pg02上传解压并授权:useradd postgrestar xf postgresql.tar.gz -C /usr/local/chown -R postgres:postgres /usr/local/postgresql#在pg01和pg02添加postgres操作系统用户环境变量:vim /etc/profileexport PATH=/usr/local/postgresql/bin:$PATHexport PGDATA=/usr/local/postgresql/data./etc/profile#在pg01上初始化数据库:su - postgresinitdb -D $PGDATA# pg71上修改postgres.conf文件cd $PGDATAvim postgresql.conflisten_addresses = '0.0.0.0'wal_level = replicaarchive_mode = onarchive_command = '/bin/date'max_wal_senders = 10hot_standby = on# pg71修改pg_hba.conf文件:vim pg_hba.confhost all all 0.0.0.0/0 trusthost replication repuser 10.0.0.71/24 md5host replication repuser 10.0.0.72/24 md5# pg71启动并创建流复制用户 (切换主备pg72也可提前创建):su - postgrespg_ctl startpsql -U postgrescreate user repuser replication login connection limit 5 encrypted password '123456';create database repuser;\password# pg72 从节点pg_basebackup拉取数据文件,并修改postgresql.conf配置文件:PS: 1. pg12开始不再有Receiver.conf2.使用-R参数可直接拉取数据数据并开启流复制,注意输入密码或申明密码未见pg_basebackup -h 10.0.0.71 -P -p 5432 -D /usr/local/postgresql/data -U repusercd $PGDATAvim postgresql.confrecovery_target_timeline = 'latest'primary_conninfo = 'host=10.0.0.71 port=5432 user=repuser'touch standby.signal #必要# 从库配置隐藏文件:vim ~/.pgpass10.0.0.71:5432:replication:repuser:12345610.0.0.71:5432:replication:repuser:123456chmod 0600 ~/.pgpass# 从库进行启动:pg_ctl start# 主库查看流复制同步方式:psql -U postgrespostgres=# select usename,application_name,client_addr,sync_state from pg_stat_replication;usename | application_name | client_addr | sync_state---------+------------------+-------------+---------repuser | walreceiver | 10.0.0.72 | async(1 row)
Postgresql12 recovery.conf 并入postgresql.conf 说明
1.2.3 主库参数说明:
listen_addresses = '0.0.0.0'wal_level = replicaarchive_mode = onarchive_command = '/bin/date'max_wal_senders = 10hot_standby = on1. wal_leval控制WAL日志级别,分别有minimal、replica、logical· minimal记录wal最少,记录数据库异常关闭需要恢复的wal外,其它操作都不记录。· replica在wal_leval的基础上还支持wal归档、复制和备库中启用只读查询等操作所需的wal信息。· logical记录wal日志信息最多,包含了支持逻辑解析(10版本的新特性,逻辑复制使用这种模式)所需的wal,此参数包含了minimal和replica所有的记录。2. archive_mode参数控制是否启动归档:· off表示不启用。· on表示启用。3. archive_command指定wal目录所在位置。4. max_wal_senders参数控制主库上的最大wal发送进程数,通过pg_basebackup命令在主库上做基准备份时也会消耗wal进程,pg_basebackup命令也会消耗一个wal进程,此参数不能超过max_connections最大连接数,默认值为10,一个流复制备库通常只消耗1个wal发送进程。5. wal_keep_segments参数设置pg_wal最小wal日志的文件数(每个wal默认为16MB)。6. hot_standby参数控制数据库恢复过程中是否启用读操作。
1.2.4从库参数说明
recovery_target_timelineprimary_conninfo1. recovery_target_timeline参数设置恢复时间线,默认时恢复到基准备份生成时的时间线,设置为latest表示从备份中恢复到最近的时间线。2. primary_conninfo设置主库的连接信息,例如IP、端口、用户名等。
1.3 如何判断那个为主库:
1. 通过进程的方式,如果有walsender就是主库:ps -ef|grep "walsender" |grep -v "grep"2. 数据库上查看WAL发送进程或WAL接收进程:select usename,application_name,client_addr,sync_state from pg_stat_replication;3. 通过系统函数查看,返回t为备库,返回f为主库:select pg_is_in_recovery();4. 通过pg_controldata命令判断 in production 主pg_controldata | grep 'Database cluster state'
2.同步-流复制
2.1 同步流复制:
# pg71 postgres.conf文件添加:vim postgresql.confsynchronous_commit = onsynchronous_standby_names = '*'# pg72 postgresql.conf配置文件添加:vim postgresql.confprimary_conninfo = 'host=10.0.0.71 port=5432 user=repuser application_name=node2'# 从库进行启动:pg_ctl start# 主库查看流复制同步方式:psql -U postgrespostgres=# select usename,application_name,client_addr,sync_state from pg_stat_replication;usename | application_name | client_addr | sync_state---------+------------------+-------------+------------repuser | node2 | 10.0.0.72 | sync
2.2 主库参数说明:
synchronous_commitsynchronous_standby_names1. synchronous_commit参数控制是否同步,它有几种场景:场景一:单实例环境· on或local当数据库提交事务时,wal先写入到wal buffer在写入到wal日志文件,当写入到wal日志文件后才向客户端返回成功。· off表示不等待本地wal buffer写入到wal日志就向客户端返回成功,设置此参数可以提升数据库性能。场景二:流复制环境· remote_write当流复制主库提交数据时,需等待wal写入备节点缓存才向客户端返回成功,此模式下当即后会有丢失wal的风险,因为是在缓存中。· on表示主库提交事务时,需等待备库接收主库的wal写入到文件后,才向客户端返回成功,此时还没有将接收到的wal进行回放。· remote_apply表示备库接收到wal并写入到日志文件中之后,并完成wal回放,才向客户端返回成功。2. synchronous_standby_names参数配置同步复制的备库列表。· synchronous_standby_names='node1,node2',其中node1为同步节点,node2为同步节点的备节点。· synchronous_standby_names='FIRST 2(node1,node2,node3)',2表示两个同步备库,其中node1和node2为同步备库,node3为同步节点的备节点。· synchronous_standby_names='ANY 2(node1,node2,node3)',ANY 2表示设置列表中的任意两个为同步备库,剩余的一个为同步节点的备节点。
2.3 主从复制的监控:
2.3.1 查看wal详细信息:
postgres=# \x — 类似mysql \G 转换列显示
select * from pg_stat_replication;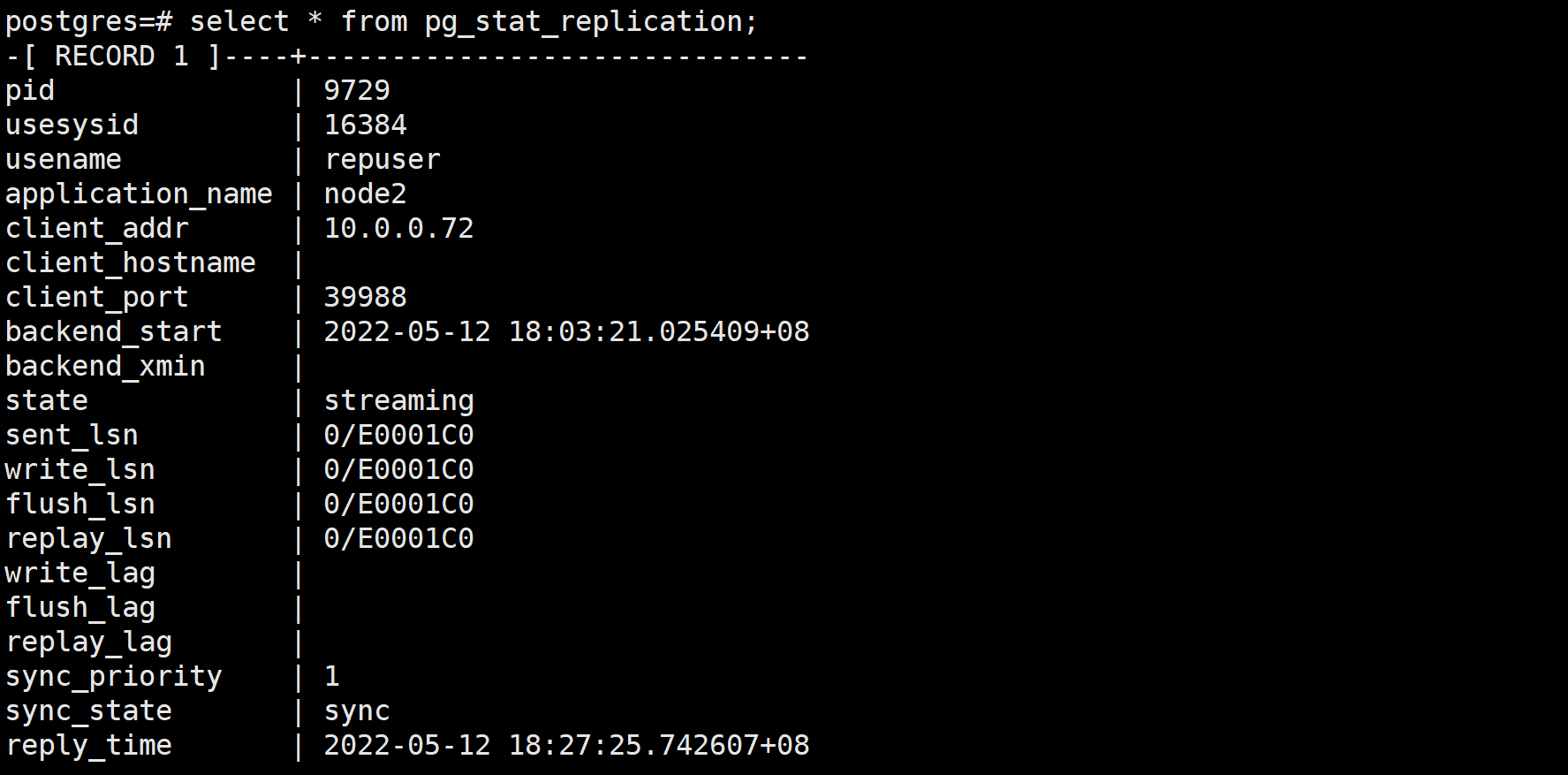
| pid | WAL发送进程的进程号 |
|---|---|
| usename | WAL发送进程的数据库用户名 |
| application_name | 连接WAL发送进程的应用别名,此参数显示值为备库primary_conninfo参数选项的值。 |
| client_addr | 从库的IP地址 |
| backend_start | WAL发送进程的启动时间 |
| state | 显示WAL发送进程的状态: startup表示WAL进程在启动过程;catchup表示备库正在追赶主库;streaming表示从库已追赶上主库;backup表示通过pg_basebackup正在进行备份;stopping表示WAL发送进程正在关闭。 |
| sent_lsn | WAL发送进程最近发送的WAL日志位置 |
| write_lsn | 备库最近写入到操作系统缓存的WAL日志位置 |
| flush_lsn | 备库已写入到WAL日志文件的lsn位置 |
| replay_lsn | 备库回放到的WAL位置 |
| write_lag | 备库接收到主库WAL日志后,已经写入到操作系统缓存,并返回确认的时间 |
| flush_log | 备库接收到主库WAL日志后,已经写入到日志,并返回确认的时间 |
| replay_log | 备库接收到主库WAL日志后,已经回放到的WAL日志,并返回确认的时间 |
| sync_priority | 选中同步备库的优先级 |
| sync_state | 同步状态: async异步同步模式,potential同步节点宕机后的备选节点,sync同步模式。 |
2.3.2 监控主备延迟:
1. 通过WAL延迟时间衡量,通过write_lag、flush_lag、replay_lag字段来判断主备延迟:select pid,usename,client_addr,state,write_lag,flush_lag,replay_lag from pg_stat_replication;2. 通过WAL日志应用延迟衡量:select pid,usename,client_addr,state,pg_wal_lsn_diff(pg_current_wal_lsn(),write_lsn) write_delay,pg_wal_lsn_diff(pg_current_wal_lsn(),flush_lsn) flush_delay,pg_wal_lsn_diff(pg_current_wal_lsn(),replay_lsn) replay_delyfrom pg_stat_replication;PS: pg_current_wal_lsn函数显示流复制主库当前WAL日志文件写入的位置,pg_wal_lsn_diff函数计算两个WAL日志位置之间的偏移量,返回单位为字节数。
2.3.3 查看WAL发送进程的详细信息:
select * from pg_stat_wal_receiver;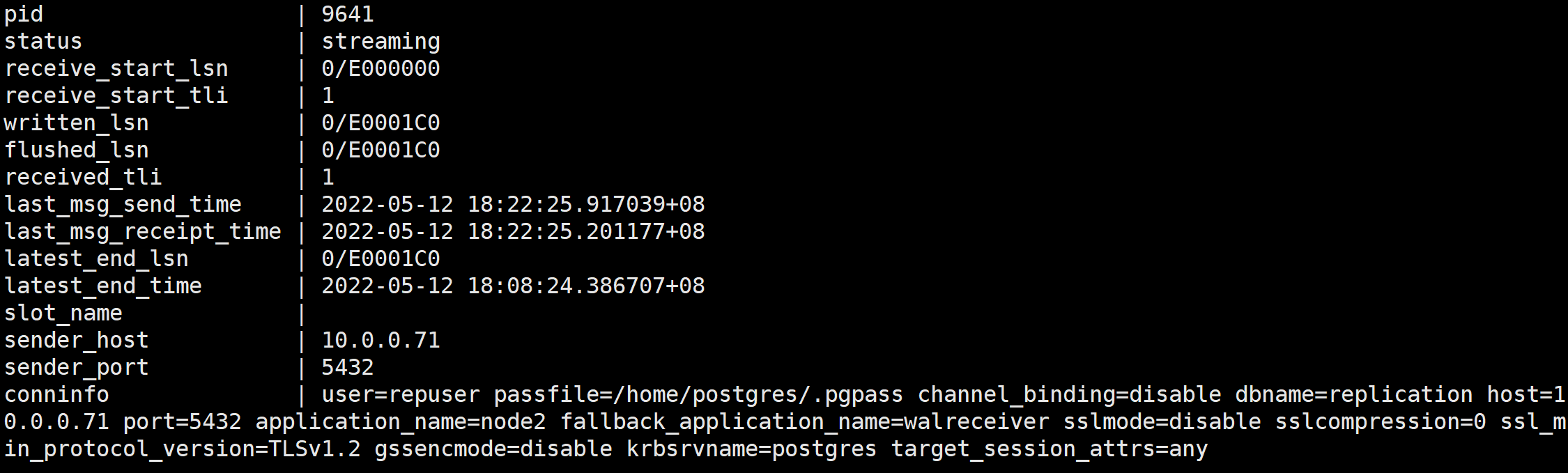
| pid | WAL接收进程的进程号。 |
|---|---|
| status | WAL接收进程的状态 |
| receive_start_lsn | WAL接收进程启动后使用的第一个WAL日志位置。 |
| receive_lsn | 最近接收并写入WAL日志文件的WAL位置 |
| last_msg_send_time | 备库接收到发送进程最后一个消息后,向主库发回确认消息的发送时间。 |
| last_msg_receipt_time | 备库接收到发送进程最后一个消息的接收时间。 |
| conninfo | 显示primary_conninfo设置主库的连接信息,例如IP、端口、用户名等。 |
2.4 相关系统函数:
1. 通过系统函数查看,返回t为备库,返回f为主库:select pg_is_in_recovery();2. 显示备库最近接收的WAL日志位置:select pg_last_wal_receive_lsn();3. 显示备库最近应用WAL日志的位置:select pg_last_wal_replay_lsn();4. 显示备库最近事务的应用时间:select pg_last_xact_replay_timestamp();5. 显示主库WAL当前写入位置:select pg_current_wal_lsn();6. 计算两个WAL日志的偏移量:select pg_wal_lsn_diff('3/940001B0','3/940001A0');
3.流复制-主备切换
3.1 主备切换之文件触发方式:
1. 修改备库文件:rm -rf standby.signalvim postgresql.conf删除如下两行:recovery_target_timeline = 'latest'primary_conninfo = 'host=10.0.0.71 port=5432 user=repuser application_name=node2'增加如下两行:synchronous_commit = onsynchronous_standby_names = 'node1'2. 修改主库文件:touch standby.signalvim postgresql.conf# 删除如下两行:synchronous_commit = onsynchronous_standby_names = 'node2'# 增添如下两行:recovery_target_timeline = 'latest'primary_conninfo = 'host=10.0.0.72 port=5432 user=repuser application_name=node1'# postgre用户创建如下文件:cd ~vim .pgpass10.0.0.71:5432:replication:repuser:12345610.0.0.72:5432:replication:repuser:123456chmod 0600 .pgpass# 使用postgres用户重启原来主库/从库:pg_ctl restart
3.2 ? ? ? 主备切换之使用pg_ctl promote方式:
目前主备状态:
| 主节点 | pg72 | 10.0.0.72 |
|---|---|---|
| 备节点 | pg71 | 10.0.0.71 |
4.级联复制 ???
1. 级联复制就是将以下参数的IP地址修改一下即可:vim postgresql.confrecovery_target_timeline = 'latest'primary_conninfo = 'host=10.0.0.72 port=5432 user=repuser application_name=node2'touch standby.signal2. 查看级联复制状态:# 在主库查看:select pid,usename,application_name,client_addr,state,sync_state,sync_priority from pg_stat_replication;# 在从库查看:select pid,usename,application_name,client_addr,state,sync_state,sync_priority from pg_stat_replication;
5.延迟备库
1. 搭建1主1备异步流复制:略2. 备库修改参数,并重启:# 此参数默认为毫秒,支持的时间单位如下:ms(毫秒) s(秒) min(分钟) h(小时) d(天)例如将主从延时为1分钟:vim postgresql.confrecovery_min_apply_delay = 1minpg_ctl restart# 在主库创建test_delay测试表:create table test_delay(id int4,create_time timestamp(0) without time zone);insert into test_delay(id,create_time) values (1,now());# 从库进行查看,从时间可以看出正好相差一分钟。3. 通过备库找回数据:# 主库删除此表,模拟数据误删:drop table test_delay;# 在从库导出此表:pg_dump -t test_delay postgres >dump.sql# 将导出的此表恢复到主库:psql -U postgres < dump.sql4. 配置延时从注意事项:# 延时从不能与同步复制中的synchronous_commit参数的remote_apply同时使用,因为remote_apply表示备库接收到wal并写入到日志文件中,并完成wal回放后才向客户端返回成功,由于这里延时从1分钟,所以主库就会夯住一分钟,这样就会严重影响业务。
6.流复制维护生产案例
6.1. 主库创建表空间时备库宕机:
1. 说明:# 例如创建一个新项目,就需要创建新的表空间,或者添加一块新硬盘,需要创建新表空间指向新的硬盘。此时如果只在主库创建表空间目录,此时创建表空间时,从库就会发生宕机。2. 主从创建表空间:# 主从创建表空间目录:mkdir -p /usr/local/postgresql/data/test# 登录主库创建表空间:create tablespace test owner postgres location '/usr/local/postgresql/data/test';# 创建数据库,并指定表空间:create database test tablespace test;
6.2 备库查询被中止:
6.3 备库查询被中止:
1. 说明:# 当时一个异步流复制备库主机由于硬件故障宕机,需要做一次停机硬件检查,由于备库上没有业务在跑,因为白天就关闭了数据库进行硬件检测,停机检测花了大概花了两个小时,之后再次启动备库,备库启动后报了如下错误:could not receive data from WAL stream: ERROR: requested WAL segment 0000000100000001000000F2 has already been removed以上错误是0000000100000001000000F2的WAL日志已被清除,因为WAL日志是循环覆盖使用的。由于异步流复制备库关闭了2小时,在这两小时主库的WAL日志无法同步给从库,所以此日志才会被移除。2. 解决方法:· 方法一:如果是在postgresql13之前的版本,可以将主备库的wal_keep_segments参数设置为较大值,从而保证pg_wal目录下留存较多的WAL日志。· 方法二:将主库开启归档,如果所需的WAL被循环清理掉,我们还可以使用归档中的WAL日志将从库进行数据的恢复。(前面章节有)· 方法三:开启复制槽。(以下会详细介绍)3. 复制槽的使用:# 修改主库配置文件,并重启主库:vim postgresql.confmax_replication_slots = 10pg_ctl restart# 主库创建复制槽:select * from pg_create_physical_replication_slot('test');# 查看主库pg_replication_slots视图,可以列出数据库所有复制槽:select * from pg_replication_slots;# slot_name指复制槽名称。# plugin如果是物理复制槽显示为空。# slot_type复制槽类型,physical或logical。# database复制槽对应的数据库名称,如果是物理复制槽,此字段显示为空,如果是逻辑复制槽则显示数据库名称。# active当前复制槽如果在使用显示为t。# active_pid使用复制槽会话的进程号。# xmin数据库需要保留的最老事务。# 修改从库配置文件,是从库使用此复制槽:vim postgresql.confprimary_slot_name = 'test'pg_ctl restart# 此时再从主库查看pg_replication_slots视图:select * from pg_replication_slots;
7.逻辑复制
7.1 逻辑复制解析:
# 逻辑解析是逻辑复制的核心,理解逻辑解析有助于理解逻辑复制原理,逻辑解析读取数据库WAL并将数据变化解析成目标格式。1. 修改参数:wal_level=logicalmax_replication_slots=82. 创建并查看逻辑槽位:# 如果是yum安装需要下载如下包:postgresql15postgresql15-contribpostgresql15-libspostgresql15-serverhttps://yum.postgresql.org/testing/15/redhat/rhel-7-x86_64/repoview/postgresqldbserver15.group.html# 如果是编译可以直接创建:select pg_create_logical_replication_slot('logical_slot1','test_decoding');select slot_name,plugin,slot_type,database,active,restart_lsn from pg_replication_slots;3. 查看指定逻辑复制槽所解析的数据变化:# 每执行一次会被消耗掉,只能查看一次:select * from pg_logical_slot_get_changes('logical_slot1',null,null);# 可以查看多次:select * from pg_logical_slot_peek_changes('logical_slot1',null,null);# 也可以使用命令进行查看变化的数据:pg_recvlogical -d postgres --slot logical_slot1 --start -f -# 如果逻辑复制槽不需要使用了,需要及时删除:select pg_drop_replication_slot('logical_slot1');4. 创建一张表,并插入数据,并使用如下进程进行监控:窗口一:并创建表插入数据:# 创建逻辑复制槽select pg_create_logical_replication_slot('logical_slot1','test_decoding');# 也可以这样创建逻辑复制槽:pg_recvlogical --create-slot -S test_slot -d postgres -p 5432create table t1 (id int);insert into t1 values (1);窗口二:使用如下进程进行查看:pg_recvlogical --start -S logical_slot1 -d postgres -p 5432 -f –BEGIN 749table public.t1: INSERT: id[integer]:5COMMIT 7495. 删除复制槽:# 方法一:pg_recvlogical --drop-slot -S test_slot -d postgres -p 5432# 方法二:select pg_drop_replication_slot('test_slot');
7.2 逻辑架构:
7.2.1 逻辑架构说明:
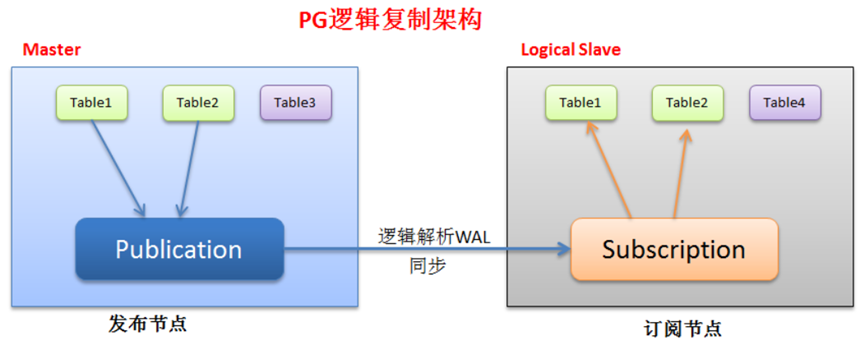
1. 参数说明:wal_level=logicalmax_replication_slots=8max_wal_senders=10max_logical_replication_workers=8max_worker_processes=20- WAL_level参数控制WAL日志信息的级别,有minimal、replica、logical三种模式,在这里需要设置成logical级别。- max_replication_slots参数指允许的最大复制槽数,应当大于订阅节点数量。# max_wal_senders进程之和。由于每个订阅节点和流复制备库上都会占用一个WAL发送进程,因此此参数的值要大于max_replication_slots参数值加上物理备库数量。- max_logical_replication_workers设置逻辑复制进程数,应大于订阅节点数量。- max_worker_processes最多可以fork多少进程。max_logical_replication_workers会消耗后台进程数,并且从max_worker_processes参数设置的后台进程数中消耗,因此max_worker_processes参数需设置较大。2. 逻辑复制架构:图中逻辑主库table1和table2加入到了Publication,备库上Subscription能够实施同步主库的table1和table2表。逻辑复制核心原理是逻辑主库将Publication中表的WAL日志解析成一定格式并发送给逻辑备库,逻辑备库Subscription接收到解析后的WAL日志后进行重做,从而实现同步。对于以创建publication的数据库称为发布节点,一个数据库可以创建多个发布,目前加入发布的对象只有表(可以加入多个)。加入对象的表必须有复制表示(主键、唯一索引、full)- subscription(订阅节点)实时同步指定发布者表的数据,订阅节点也可以创建发布。发布节点发布的表DDL不会备复制,所以发布节点如果表结构收到了更改,订阅节点也需手工进行DDL操作,订阅节点通过逻辑复制槽获取发布节点发布的WAL数据变化。
 [
[
7.2.2 逻辑架构的部署: ](https://blog.csdn.net/fengbohello/article/details/115115162)
1. 参数相关配置:# 发布节点参数配置:vim postgresql.confwal_level=logicalmax_replication_slots=20max_wal_senders=12max_logical_replication_workers = 20max_worker_processes = 20listen_addresses = '*'vim pg_hba.confhost all all 0.0.0.0/0 trusthost replication logical_user 10.0.0.72/24 md5host replication logical_user 10.0.0.71/24 md5vim ~/.pgpass10.0.0.71:5432:postgres:logical_user:123456chmod 600 ~/.pgpass# 订阅节点参数配置:vim postgresql.confwal_level=logicalmax_replication_slots=10max_wal_senders=12max_logical_replication_workers = 10max_worker_processes = 10listen_addresses = '*'vim pg_hba.confhost all all 0.0.0.0/0 trusthost replication logical_user 10.0.0.72/24 md5host replication logical_user 10.0.0.71/24 md5vim ~/.pgpass10.0.0.71:5432:postgres:logical_user:123456chmod 600 ~/.pgpass② 创建用户以及测试表:# 发布节点配置:# 创建复制用户,该用户需具备replication权限:create user logical_user replication login connection limit 8 encrypted password '123456';# 创建测试表:create table t_lrl(id int4,name text);insert into t_lrl values (1,'zhang3');# 赋予给此用户读权限:grant usage on schema public to logical_user;grant select on t_lrl to logical_user;# 为t_lrl添加主键:alter table t_lrl add primary key(id);# 发布t_lrl表:(也可以发布for all table当前库下所有的表)create publication pub1 for table t_lrl;# 查看发布信息:select * from pg_publication;# pubname:指定发布信息# pubowner:指发布的属主,和pg_user视图的usesysid字段关联。# pubinsert:t表示发布表上的insert操作。# pubupdate:t表示仅发布表上的update操作。# pubdelete:t表示仅发布表上的delete操作。# 订阅节点配置:# 创建测试表:create table t_lrl(id int4,name text);# 为t_lrl添加主键:alter table t_lrl add primary key(id);# 创建订阅(此操作成功创建了订阅,并且在发布节点创建了sub1的复制槽)。create subscription sub1 connection 'host=10.0.0.71 port=5432 dbname=postgres user=logical_user' publication pub1;③ 查看相关:# 在发布节点查看复制槽:select slot_name,plugin,slot_type,database,active,restart_lsn from pg_replication_slots where slot_name='sub1';# 在订阅节点查看订阅信息:\xselect * from pg_subscription;# subdbid:数据库的OID,和pg_database.oid关联。# subname:订阅的名称。# subowner:订阅的属主。# subenabled:是否启用订阅。# subconninfo:订阅的连接串信息,显示发布节点连接串信息。# subslotname:复制槽名称。# subpublications:订阅节点订阅的发布列表。
7.3 逻辑复制添加表,删除表:
1. 发布节点:# 创建一张大表t_big:create table t_big(id int4 primary key,create_time timestamp(0) without time zone default clock_timestamp(),name character varying(32));insert into t_big(id,name) select n,n*random()*1000 from generate_series(1,10)n;# 将t_big的select的权限赋予logical_user用户:grant select on t_big to logical_user;# 将t_big加入到发布pub1:alter publication pub1 add table t_big;# 查看发布中的列表:# 方法一:\dRp+# 方法二:select * from pg_publication_tables;2. 订阅节点:# 创建表:create table t_big(id int4 primary key,create_time timestamp(0) without time zone default clock_timestamp(),name character varying(32));# 将新创建的表刷新到sub1订阅:alter subscription sub1 refresh publication;# 如果不需要同步t_big表,也可以进行删除:alter publication pub1 drop table t_big;
7.3.1 逻辑复制的启动及停止:
1. 逻辑复制启动、停止订阅实现逻辑复制的启动和停止:# 订阅节点停止订阅:alter subscription sub1 disable;2. 订阅节点开启订阅:alter subscription sub1 enable;3. 查看订阅是否为启动(f代表停止):select subname,subenabled,subpublications from pg_subscription;

若有收获,就点个赞吧
0 人点赞
