1. 操作系统优化
1.1 top命令:
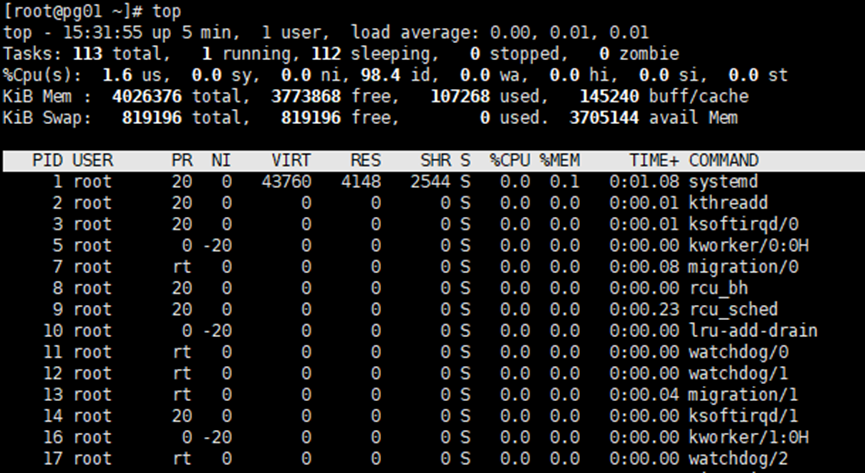
当前时间为15:31:55,系统运行5分钟,当前有1个用户登录操作系统,最近1分钟、5分钟、15分钟的系统负载分别是:0.00、0.01、0.01。当前一共有113个进程,1个正在运行,112个正在睡眠,0个进程停止,0个僵尸进程。用户cpu占用1.6%,内核cpu占用0.0%,特定优先级的进程cpu占用0.0%,空闲cpu 98.4%,因为IO等待的cpu占用0.0%,硬中断cpu占用0.0%,软中断cpu占用0.0%,虚拟机盗取占用0.0%。内存共有4026376k,可用3771756k,使用109328k,buffers使用145292k。swp共有819196,可用819196k,使用0k,cache使用了3703036k。PID:进程idUSER:进程所有者PR:进程优先级:NI:进程优先级的修正值。VIRT:进程使用虚拟内存的总量。RES:进程使用物理内存的总量。SHR:共享内存大小。%CPU:进程使用CPU百分比。%MEM:进程使用物理内存百分比。TIME+:进程使用CPU的时间总计。COMMAND:进程运行的命令名。
1.2 free命令:

MEM:服务器共有3GB(used+free),已分配内存0GB,未分配内存3GB,共享内存0GB,buffer/cache使用0GB,剩余3GB。
1.3 iostat 命令:

# yum install -y sysstat每隔5秒采集一次,共采集5次:# iostat -dx /dev/sda 5 5rrqm/s,wrqm/s:每秒读写请求的合并数量(OS会尽量读取和写入临近扇区)r/s,w/s:每秒读写请求次数rkB/s,wkB/s:每秒读写请求字节数avgrq-sz:每秒请求的队列大小avgqu-sz:每秒请求的队列长度await:从服务器发起到返回信息共花费的平均服务时间%util:磁盘IO的利用率:如果 %util 接近 100%,说明产生的I/O请求太多,I/O系统已经满负荷,该磁盘可能存在瓶颈。如果 svctm 比较接近 await,说明 I/O 几乎没有等待时间;如果 await 远大于 svctm,说明I/O 队列太长,io响应太慢,则需要进行必要优化。如果avgqu-sz比较大,也表示有当量io在等待。
1.4 sar命令:


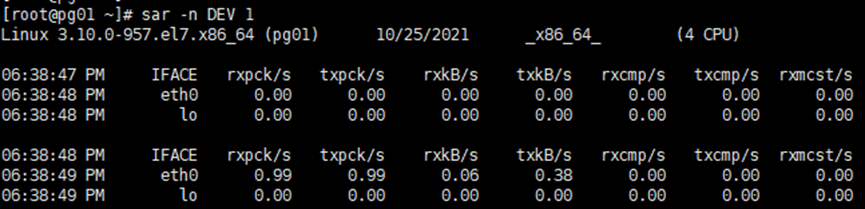
1. 汇总CPU状况:sar -qrunq-sz:运行队列平均长度plist-sz:进程列数ldavg-1,ldavg-5,ldavg-15:每1、5、15分钟系统负载2. 汇总IO情况:sar -btps,rtps,wtps:每秒处理的事务数量bread/s,bwrtn/s:每秒读写block的大小,这里的block为512字节,不要与数据库中的混淆3. 网卡信息:sar -n DEV 1IFACE LAN接口rxpck/s 每秒钟接收的数据包txpck/s 每秒钟发送的数据包rxbyt/s 每秒钟接收的字节数txbyt/s 每秒钟发送的字节数rxcmp/s 每秒钟接收的压缩数据包txcmp/s 每秒钟发送的压缩数据包rxmcst/s 每秒钟接收的多播数据包
1.5 linux系统的优化:


cfq公平调度算法:为每个进程和线程单独创建一个队列来管理该进程的I/O请求,为这些进程和线程均匀分配I/O带宽,适合通用服务器,是linux系统中默认的调度算法。noop电梯调度算法:它基于FIFO队列实现,所有I/O请求先进先出,适合SSD。deadline保障算法:它为读和写分别创建FIFO队列,当内核收到请求时,先尝试合并,不能合并则尝试排序放入队列中,并且尽量保证在请求达到最终期限时进行调度,避免有一些请求长时间不能得到处理。适合虚拟机或I/O压力比较重的场景,例如数据库服务器。1. 查看调度算法:cat /sys/block/sda/queue/scheduler括号中则是当前的调度算法2. 修改调度算法:echo noop >/sys/block/sda/queue/schedulergrubby --update-kernel=ALL --args="elevator=noop"
1.6 预读参数调整:
在内存中读取数据比从磁盘中读取要快很多,增加Linux内核预读,对于大量顺序读取的操作,可以减少I/O的等待时间。如果应用场景中有大量的小文件,过多的预读会造成资源的让费。所以该值应该在实际环境中多次测试。1. 查看磁盘预读扇区:blockdev --getra /dev/sda2. 通过命令设置磁盘预读扇区(可以设置到16384或者更大)方法一:blockdev --setra 16384 /dev/sda方法二:echo 16384 /sys/block/sda/queue/read_ahead_kb永久生效可以将此命令添加到/etc/rc.local
1.7 内存优化:
swap由于是借用磁盘的空间,所以会使数据库的性能急促降低,如果关闭swap当内存不够用时就会发生oom的现象,可以使用free命令查看有没有使用到swap,如果有,请在物理内存充裕的情况下执行如下操作:1. 关闭swap:swapoff -a2. 开启swap:swapon -a
1.8 透明大页:
# 透明大页在运行时动态分配内存,而运行的内存分配会有延误,对于数据库管理员来讲这并不友好,所以建议关闭透明大页:1. 查看透明大页是否开启(never关闭)cat /sys/kernel/mm/transparent_hugepage/enabled2. 关闭透明大页:echo never > /sys/kernel/mm/transparent_hugepage/enabledecho never > /sys/kernel/mm/transparent_hugepage/defrag3. 永久关闭:chmod +x /etc/rc.d/rc.localvi /etc/rc.d/rc.localif test -f /sys/kernel/mm/transparent_hugepage/enabled; thenecho never > /sys/kernel/mm/transparent_hugepage/enabledfiif test -f /sys/kernel/mm/transparent_hugepage/defrag; thenecho never > /sys/kernel/mm/transparent_hugepage/defragfi
1.9 NUMA:
# MUMA架构会优先在请求线程所在的CPU的local内存上分配空间,如果local内存不足,优先淘汰local内存中无用的页面, 这样就会导致每个cpu内存分配不均匀,虽然可以通过配置NUMA的轮询机制缓解,但对于数据库管理员仍然不友好,建议关闭numa:
2. 数据库优化
2.1 系统信息和查询计划
2.1.1 pg_stat_database:

# select numbackends,blks_read,blks_hit,xact_commit,xact_rollback,deadlocks from pg_stat_database;numbackends:当前有多少个并发连接,理论上控制在cpu核数的1.5倍可以获得更高的性能blks_read,blks_hit:读取磁盘块的次数与这些块的缓存命中数xact_commit,xact_rollback:提交和回滚的事务数deadlocks:从上次执行pg_stat_reset以来的死锁数量1. 计算缓存命中率:select blks_hit::float/(blks_read + blks_hit) as cache_hit_raito from pg_stat_database where datname=current_database();此值应当接近1(如果命中率低于99%),否则应当调大shared_buffers2. 计算事务提交率:select xact_commit::float/(xact_commit+xact_rollback)as successful_xact_ratio from pg_stat_database where datname=current_database();事务提交率应该等于或接近1,否则检查是否死锁或其它超时太多在pg_stat_database系统视图的字段中,除numbackends字段和stats_reset字段外,其它字段值是从stats_reset字段记录的时间点执行pg_stat_reset()命令以来的统计信息。优化和参数调整之后执行pg_stat_reset()命令,方便对比优化和调整前后的各项指标。
2.1.1 pg_stat_statements:

1. 开启pg_stat_statements:vi postgresql.confshared_preload_libraries = 'pg_stat_statements'pg_stat_statements.track=all2. 启动pg_stat_statements:create extension pg_stat_statements;pg_stat_statements提供了很多维度的统计信息,最常用的是统计运行的所有查询的总的调用次数和平均的CPU时间,对于分析慢查询非常有帮助。例如查询平均执行时间最长的3条查询:SELECT calls,total_exec_time/calls AS avg_time,left(query,80) FROM pg_stat_statements ORDER BY 2 DESC LIMIT 3;执行pg_stat_statements_reset可以重置pg_stat_statements的统计信息。

若有收获,就点个赞吧
0 人点赞
