1. 逻辑和物理存储结构
1.1. 数据库集簇概念:
在postgresql中,每一个数据库实例叫做数据库集簇,每一个数据库集簇下面有多个数据库,这些数据库使用相同配置文件和监听端口,共用进程和内存结构。
1.2 逻辑存储结构:
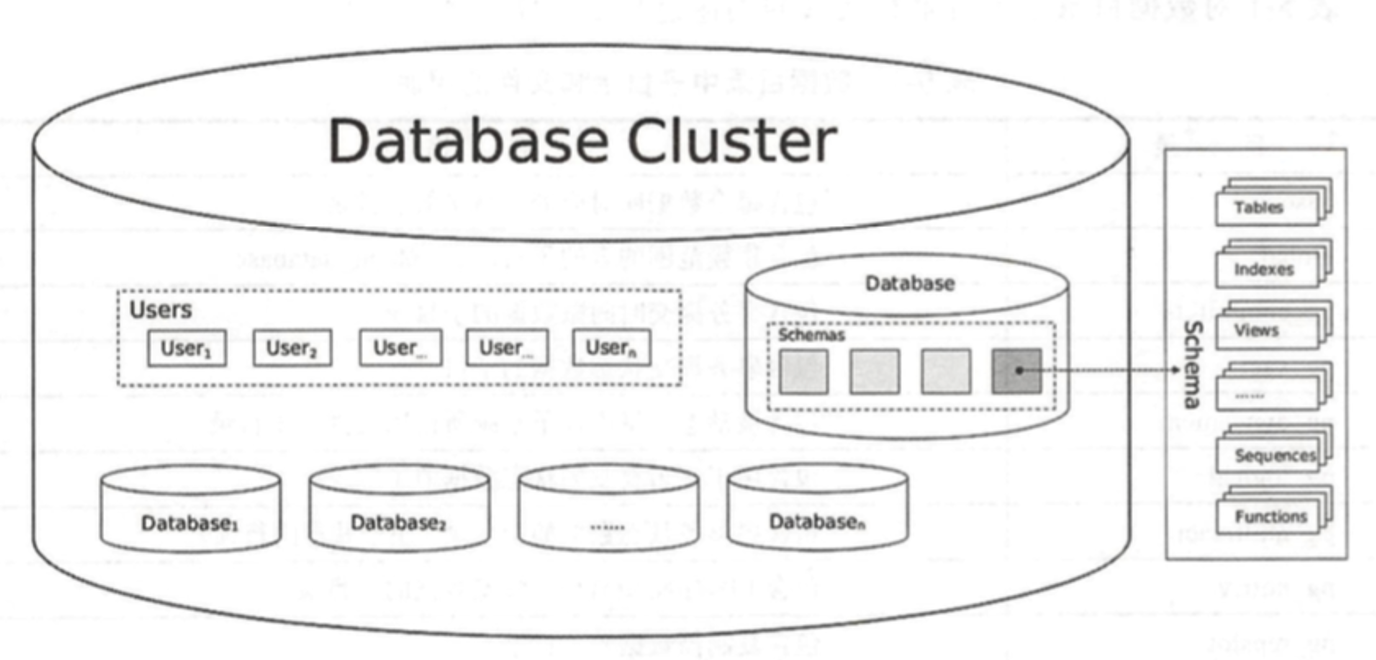
PG数据库集簇逻辑结构图
User:同一个数据库集簇中,每一个数据库都有自己的所有者User,它们之间都是彼此分离的,只能访问自己库下的数据库对象,例如(表、索引、序列、视图、函数等)
DATABASE: 创建数据库database时,如果没有指定schema,就会为其创建为public默认的schema,每个database可以有多个schema,schema可以理解为命名表空间(index、table、squence、view、function),一个用户可以从同一个客户端链接中访问不同的schema,不同schema可以有多个相同名称的index、table、sequece、view、function等数据库对象。
1.3 物理存储结构:
1.3.1 目录信息:
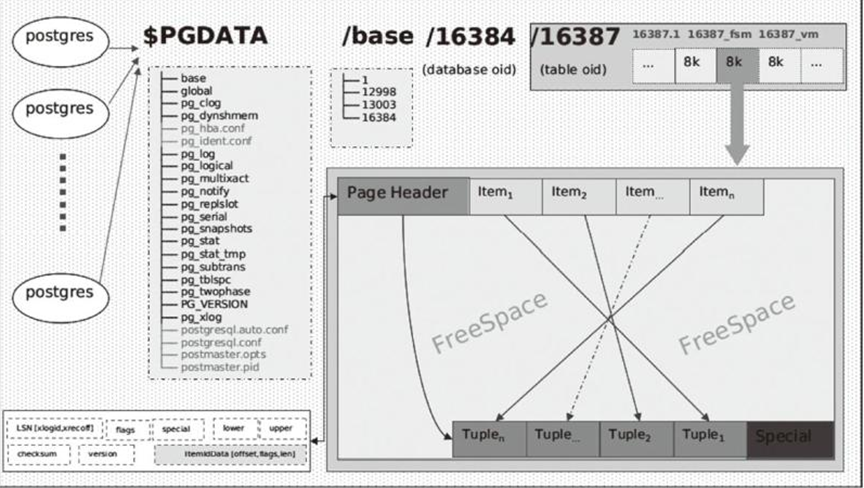
$ tree -FL 1 /var/lib/postgres/data//var/lib/postgres/data/├── base/ # 表和索引文件存放目录├── global/ # 影响全局的系统表存放目录├── pg_clog/ # 事务提交时间戳数据存放目录├── pg_commit_ts/ # 事务提交时间戳数据存放目录├── pg_dynshmem/ # 动态共享内存子系统目录├── pg_hba.conf 配置文件-客户端认证控制文件├── pg_ident.conf 配置文件-控制postgresql用户名映射文件├── pg_logical/ # 用于逻辑复制的状态数据├── pg_multixact/ # 多事务状态的数据├── pg_notify/ # LISTEN/NOTIFY状态的数据├── pg_replslot/ # 复制槽数据存放目录├── pg_serial/ # 已提交的可序列化事务信息存放目录├── pg_snapshots/ # 快照├── pg_stat/ # 统计子系统信息永久文件├── pg_stat_tmp/ # 统计信息子系统临时文件├── pg_subtrans/ # 子事务的一个状态数据信息├── pg_tblspc/ # 表空间链接目录├── pg_twophase/ # 预备事务状态文件├── PG_VERSION 其他文件-版本号文件├── pg_xlog/ #这个日志是记录的Postgresql的WAL信息,也就是一些事务日志信息,高版本叫pg_wal├── postgresql.auto.conf 配置文件-参数文件,只保存ALTER SYSTEM命令修改的参数├── postgresql.conf 配置文件-参数文件├── postmaster.opts 配置文件-记录服务器最后一次启动时使用的命令行参数└── postmaster.pid 配置文件-记录数据库进程编号、PGDATA、端口等17 directories, 7 files备注:从PG 10.0开始,目录的名称已经更改pg_xlog ---- pg_wal (WAL 日志,即重做日志) 强制开启pg_clog ---- pg_xact (事务提交日志,记录的是事务的元数据) 内容一般不具有可读性 强制开启pg_log ---- log pg_log(数据库运行日志) 内容可读 默认关闭的,需要设置参数启动
1.3.2 数据文件部署:
I.OID说明:- 所有数据库对象都有各自的对象标识符OID进行内部管理,它们是无符号的4字节整数。数据库对象和各个OID之间的关系存储在适当的系统目录中。select oid,datname from pg_database where datname='mydb';oid | datname-------+---------16384 | mydb- 查看数据库中的表、索引、序列等对象的OID:select oid,relname,relkind from pg_class where relname='t1';II.表空间说明:数据库中创建的所有对象如果不指定,都保存在默认的表空间中,初始化数据库目录时会自动创建pg_default和pg_global两个表空间,可以用\db进行查看:· pg_global表空间的物理文件默认存储在global目录,它用来保存系统表。· pg_default表空间的物理文件默认存储在base目录中,时template0和template1数据库据默认的表空间, 当创建数据库时,如果不指定表空间,默认使用template1进行克隆,也就是pg_default。III. 自定义表空间:· 创建表空间:mkdir /usr/local/postgresql/mytablespacecreate tablespace myspc location '/usr/local/postgresql/mytablespace';· 创建数据库或者表时可以指定表空间:create table student (id int not null) tablespace myspc;IV 数据文件命名:创建的表文件以OID命名,当大小超过1GB的表数据文件,postgresql会自动切分为多个文件来存储,切分的文件用OID顺序号来命名。实际上真正管理表文件的是pg_class表中的relfilenode字段值,当经过几次valcuum、truncate操作之后,relfilenode的值就会发生变化。· 举例说明,首先查看当前表的OID,此时发现此表的OID为:postgres=# select oid,relfilenode from pg_class where relname = 'test';oid | relfilenode-------+-------------16384 | 16384[postgres@pg01 ~]$ ls /usr/local/postgresql/data/base/13580/16384/usr/local/postgresql/data/base/13580/16384当多次执行truncate之后,发现其存储目录发生了改变,其存储目录与relfilenode相同:postgres=# truncate test;postgres=# select oid,relfilenode from pg_class where relname = 'test';oid | relfilenode-------+-------------16384 | 16392[postgres@pg01 ~]$ ls /usr/local/postgresql/data/base/13580/16392/usr/local/postgresql/data/base/13580/16392· 可以通过pg_relation_filepath函数查询表在物理结构的路径:postgres=# select pg_relation_filepath('test');pg_relation_filepath----------------------base/13580/16392· 插入多行数据,将其大小超过1GB,此时发现其命名规则为relfilenode的顺序号:insert into test select generate_series(1,99999999);postgres=# select pg_size_pretty(pg_relation_size('test'::regclass));pg_size_pretty----------------3457 MB[postgres@pg01 ~]$ ls /usr/local/postgresql/data/base/13580/16394*/usr/local/postgresql/data/base/13580/16392/usr/local/postgresql/data/base/13580/16392.1/usr/local/postgresql/data/base/13580/16392.2/usr/local/postgresql/data/base/13580/16392.3/usr/local/postgresql/data/base/13580/16394_fsm/usr/local/postgresql/data/base/13580/16394_vm_fsm(空闲空间映射表文件):用来映射表文件中可用空间,也就是每个页面上的空闲空间信息。空闲空间映射文件是表和索引数据文件的第一个分支。_vm(可见性映射表文件):用来映射表文件跟踪哪些页面只包含已知对所有活动事务可见的元组。可见性映射文件是数据文件的第二个分支。
V 表文件内存结构:· page 磁盘中的块· buffer 内存中的块· relation 表和索引· Tuple 行· 数据库的读写以page为最小单元,如果不指定大小,默认为8kb· 表文件=多个page=多个Tupe· pd_lsn:这个lsn称之为pagelsn,它记录了最后更改此页的xlog记录lsn,把数据也和wal进行关联,用于恢复数据是校验日志文件和数据文件的一致性。· pg_flags:标识页面的存储情况。· pg_checksum:如果一个块不可用,该页面的校验和就会错误。· pg_special:指向索引相关数据的开始位置,该项在数据文件中为空,主要针对不同的索引。· pd_lower:指向空闲空间的起始位置。· pd_upper:指向空闲空间的结束位置。· pd_pagesize_version:不同的postgresql版本的页的格式可能会不同。· pd_linp[1]:行指针数组,item1、item2……这些地址指向tuple的存储位置。· 如果一个表由一个堆元组的页面组成,该页面的pd_lower指向第一行指针,并且指针和pd_upper都指向第一个堆元组。· 当第二个元组被插入时,第二行指针指向第二个元组,pd_lower更改为指向第二行指针,pd_upper更改为第二个堆元组,此页面的其它头数据,例如pd_lsn、pg_checksum、pg_flag也被重写为适当的值。· 当从数据库中检索数据时有两种典型的访问方法,顺序扫描和B树索引扫描。顺序扫描通过扫描每个页面中的所有行指针顺序读取所有页面中的所有元组。B树索引扫描时,索引文件包含索引元组,每个元组由索引键和指向目标堆元组的TID组成。如果找到了正在查找的键的索引元组,postgresql使用获取的TID值读取所需的堆元组。
- page:
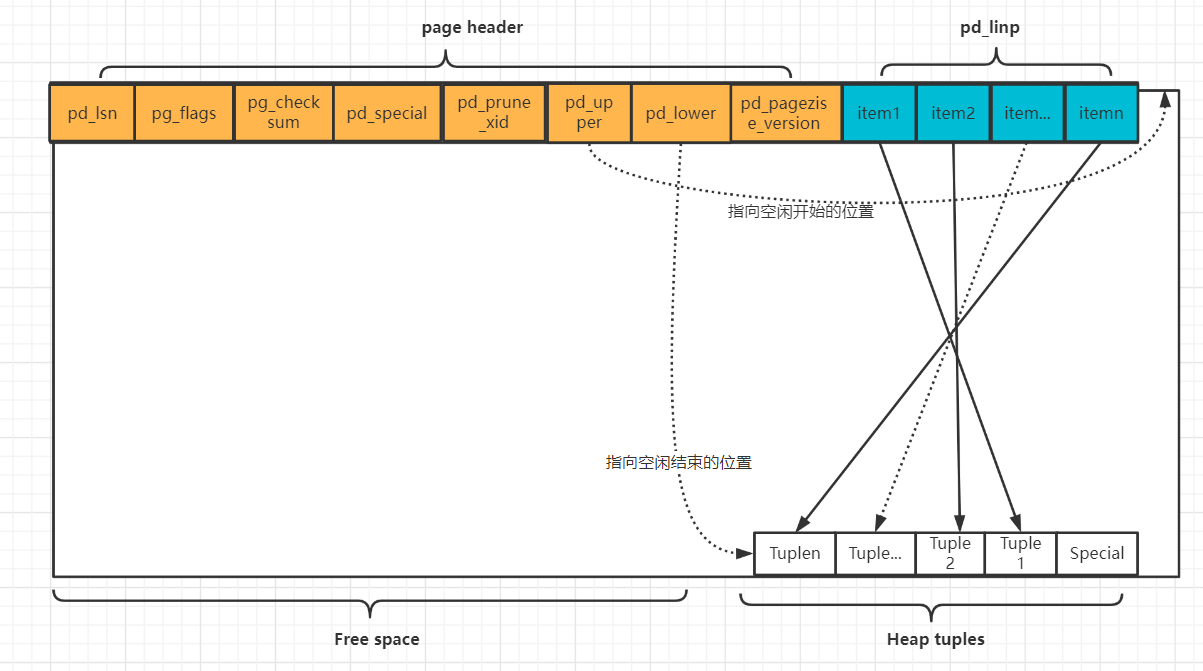
每个Tuple包含两部分内容,一部分为HeapTupleHeader,用来保存Tuple的元信息,包含该Tuple的OID、xmin、cmin等,如图:

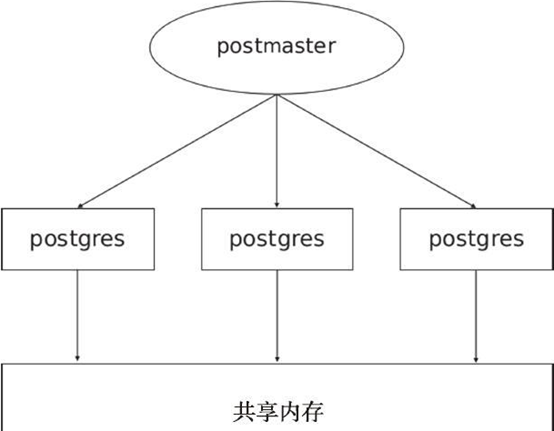
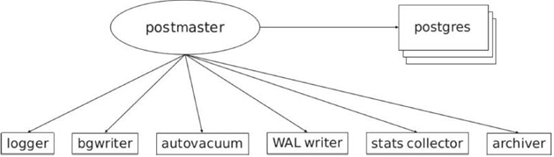
2. 进程结构
2.2 进程结构说明:
#数据库启动后由若干个进程:postmaster(守护进程)postgres(服务进程)syslogger、checkpointer、bgwriter、walwriter等辅助进程。
2.2.1 守护进程 & 服务进程:
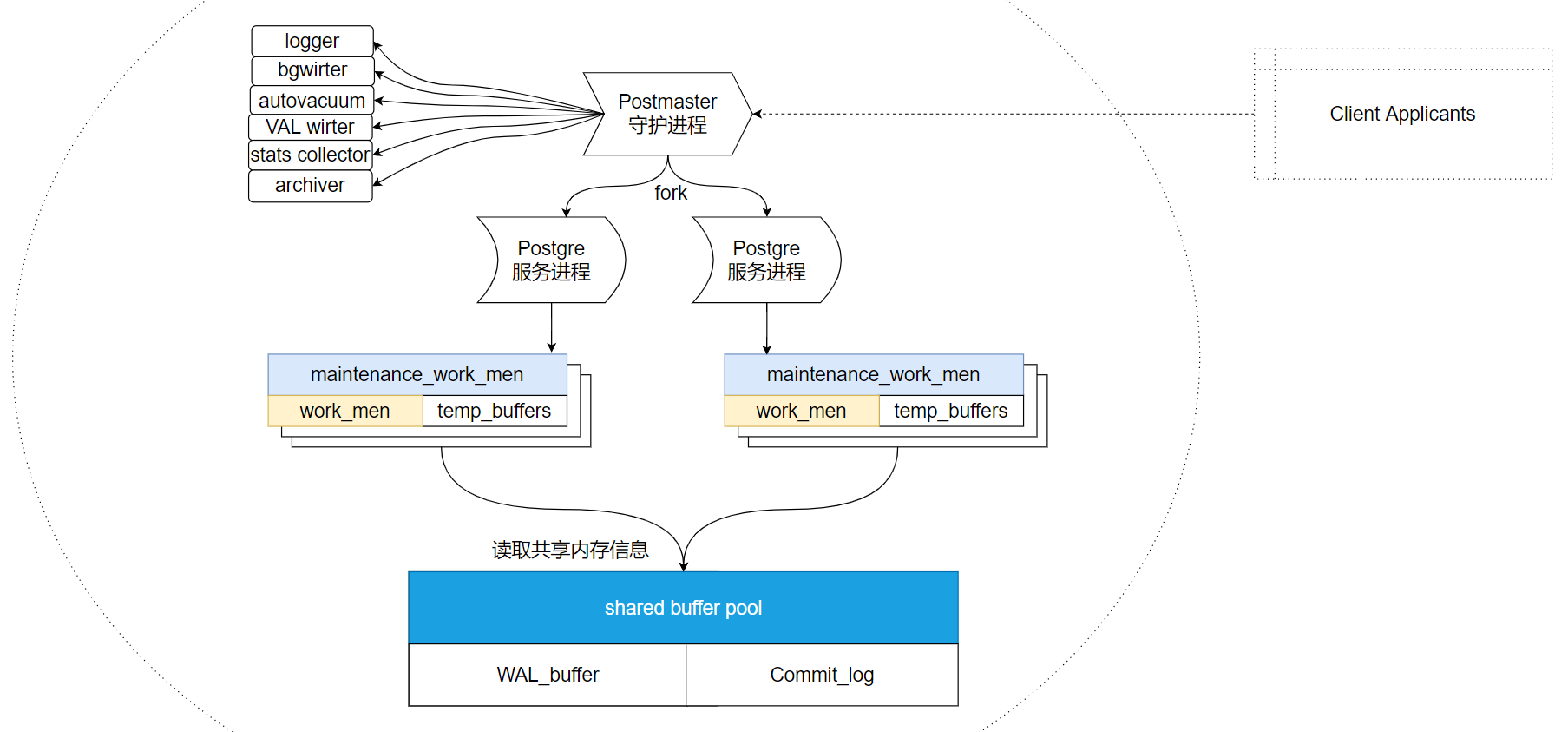
一,postmaster守护进程作用:· 数据库启停· 监听客户端连接· 为每个客户端连接frok单独的postgres服务进程· 当服务进程出错时进行修复· 管理数据文件· 管理与数据库运行相关的辅助进程二,守护进程与服务进程的相互作用:1. 当客户端发起连接时,守护进程会fork服务进程为客户端提供服务,此后将由服务进程执行各种命令,而不需要守护进程中转,直到客户端断开连接为止。2. postgresql使用基于消息协议的消息流进行服务器和客户端通讯,消息的第一个字节标识消息类型,后面的四个字节声明消息剩下部分的长度,该协议在TCP/IP和Unix域上实现。服务器作业之间通过信号和共享内存通信,以保证并发访问时的数据完整性。

2.2.2 辅助进程:
除了守护进程和服务进程外,postgresql运行期间还需要一些辅助进程才能工作:① background writer:· bgwriter很多时候都是在休眠状态,每次唤醒后他会搜索共享缓冲池找到被修改的页,并将他们从共享缓冲池刷出。① autovacuum launcher:· 自动清理回收垃圾进程。② WAL writer:· 定期将WAL缓冲区上的WAL数据写入磁盘。③ logging collector:· 日志进程,将消息或错误信息写入日志。④ archiver:· WAL归档进程。⑤ checkpointer· 检查点进程。
3. 内存结构
3.1 本地内存:
当后端服务进程被fork时,每个后端进程都会分配一个本地内存区域本地内存由三部分组成:#1. work_mem:· 当使用order by或distinct操作对元组仅从排序时会使用这部分内存。#2. maintenance_work_mem:· 维护操作,例如vacuum、reindex、create index等操作使用这部分内存。#3. temp_buffer:· 临时表相关操作使用这部分内存。
3.2 共享内存:
共享内存在postgresql服务器启动时分配,由所有后端进程共同使用。共享内存主要由三部分组成:#1. shared buffer poll:· postgresql将表和索引中的页面从持久存储装载到这里,并且直接操作它们。#2. WAL buffer:· WAL文件持久化之前的缓冲区。#3. CommitLog buffer:· PostgreSQL在commit log中保存事务状态,并将这些状态保留在共享内存缓冲区中,在整个事务处理过程中使用。

若有收获,就点个赞吧
0 人点赞
