1.常见的关系型数据库
1.MySQL架构(如何设计?)
MySQL主要包含两大部分:存储模块、服务模块。
存储模块:负责数据的存储与提取、MySQL中提供了多种存储引擎机制来进行存储。
服务模块:包含连接器、分析器、优化器、执行器、缓存层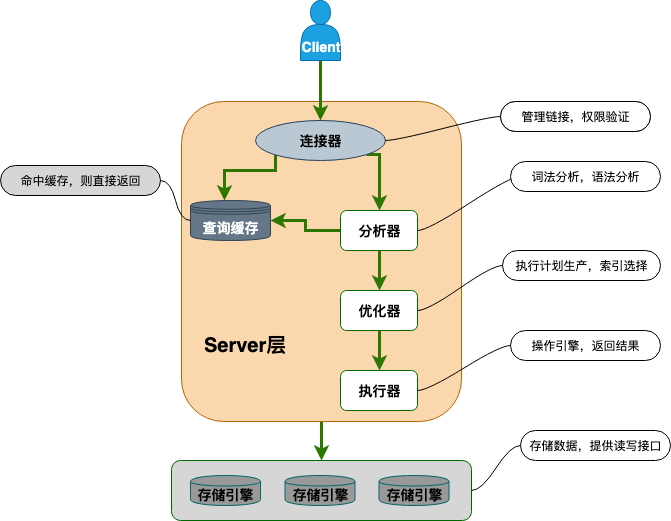
1、连接器:进行身份的认证和权限相关(登录MySQL)
2、缓存器:执行SQL语句、先查询缓存中是否存在(8.0之后废除)
3、分析器:没有命中缓存,则对SQL进行分析、检查SQL的合法性
4、优化器:按照MySQL最优方案进行执行
5、知心器:执行SQL语句、执行前会再次判断是否具有响应的权限信息。
2.MySQL存储引擎
MySQL中提供了多种(InnoDB、MyISAM、MEMORY等)存储引擎,最常用的是InnoDB、MyISAM。可以通过show engines命令来进行查看。
1.MySQL存储引擎架构?
MySQL存储引擎采用的是插件式架构,支持多种数据库存储引擎、甚至可以为不同的数据库设置不同的存储引擎。
与此同时、也提供了第三方的一个接口来供开发者进行自行实现。
2.InnoDB&MyISAM
MySQL5.5之前,主要的存储引擎为MyISAM、之后、InnoDB成为了MySQL主要的存储引擎
主要区别:
1、外键:InnoDB支持外键、MyISAM不支持外键设置
2、事务:InnoDB支持事务、MyISAM不支持事务
3、锁:InnoDB支持行锁和表锁、MyISAM只支持表锁。
4、索引:InnoDB支持聚集索引、MyISAM不支持
5、MVCC:InnoDB支持MVCC、MyISAM不支持
4.MySQL三大范式
第一范式:所有的字段都是原子性的、不可拆分的
第二范式:所有的字段全部依赖于主键、不存在部分依赖
第三范式:所有的字段直接依赖主键、不存在间接依赖
5.MySQL执行过程
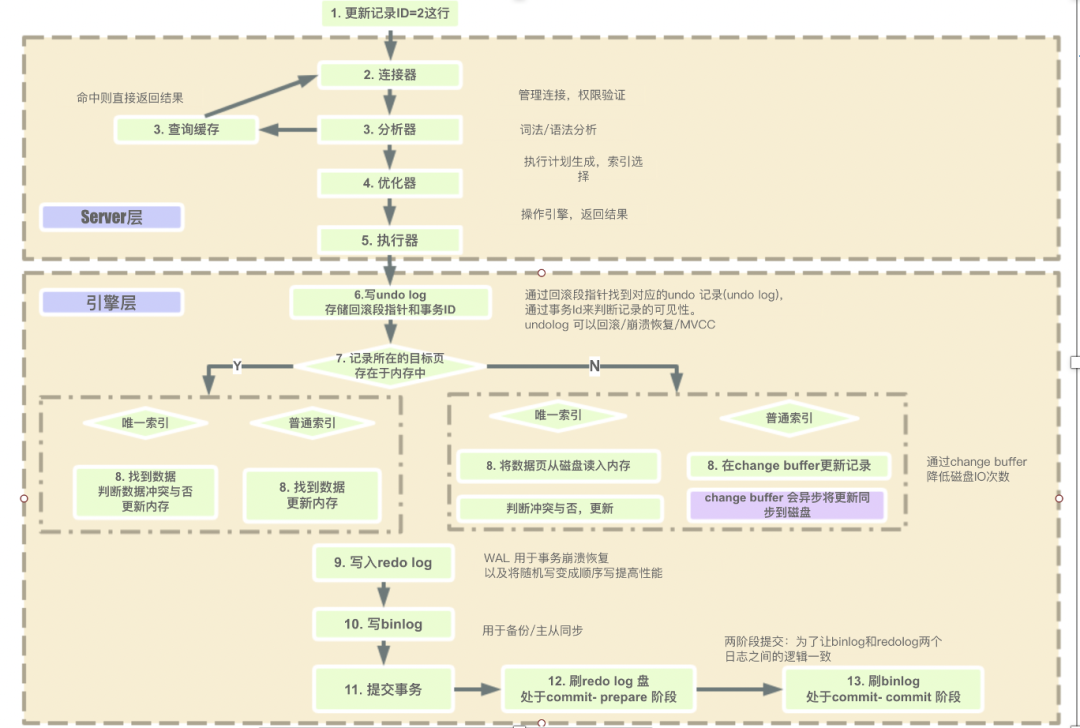
2.MySQL事务
1.ACID特性
MySQL事务中包含ACID四种事务特性、也就是指原子性、一致性、隔离性、持久性
1、A-原子性:事务作为一个整体执行、要么全部成功、要么全部失败。
2、C-一致性:事务执行成功与失败、数据都是完整的、不会出现数据不一致问题
3、I-隔离性:并发事务访问期间、事务之间是相互隔离的、不会相互造成干扰
4、D-持久性:事务完成后,对数据的更改将会持久化到数据库中
2.并发问题
事务并发访问会导致脏读、不可重复读、幻读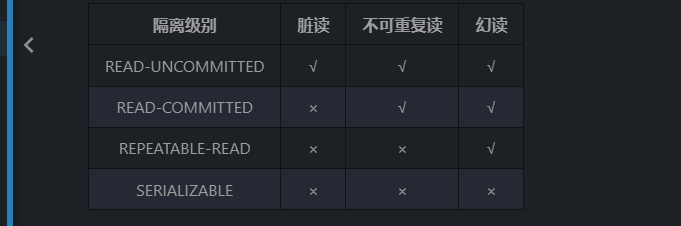
1、脏读:事务A读取了事务B还未提交的数据,造成了脏读。
2、不可重复读:事务A读取了一定条件返回内的数据后,事务B对该范围内的数据进行了修改。此时事务A再次重复读取相同条件范围的数据,造成数据不一致问题。
3、幻读:事务A读取了一定条件返回内的数据后,事务B对该范围内的数据进行了增、删操作。此时事务A再次读取相同条件范围内的数据,造成数据不一致问题。
3.隔离级别
MySQL中提供了四种隔离级别机制:读未提交、读已提交、可重复读、序列化。MySQL中默认为可重复读。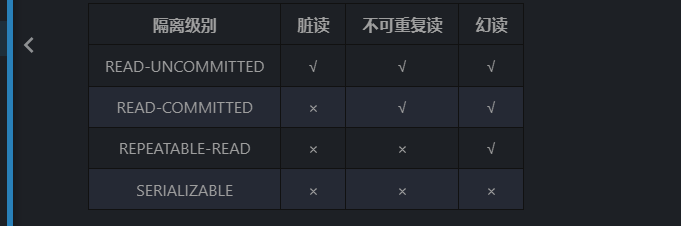
串行化指的是所有事务都是按照顺序执行的、不会出现任何并发事务问题、隔离级别最高、但耗性能。
4.如何保证事务隔离性?
1.加锁保证隔离
MySQL中不同的隔离级别有不同的实现方式。
序列化采用的加锁实现、其余的均采用MVCC实现。
2.MVCC
3.MySQL锁
1.行锁&表锁
MySQL中的InnoDB引擎默认采用的是行锁、同时也支持表锁。但MyISAM只支持表锁。且行锁性能更高、锁冲突更小。
行锁:针对索引字段加锁、WHERE中的字段未命中索引、或者索引失效,都会导致升级为表锁。
不过、很多时候即使走了索引、也还是会进行全表搜索、这是由于MySQL优化器的原因
2.共享锁&排它锁
无论是行锁,还是表锁。都存在共享锁和排它锁机制。
共享锁:也称为读锁、事务并发读取数据时、允许多个事务同时持有锁。
排他锁:也称为写锁、事务并发写如数据时、只能有单个事务占用锁。
注意:只要读锁之间不存在锁冲突问题。
3.意向锁作用
意向锁也是一种表锁,由引擎自动维护、开发者不能操作。意向锁主要用来快速判断添加表锁时、是否存在行锁。
4.MySQL索引
含义:索引是一种用来提高访问速度的、有序的数据结构。
特点:检索快速、但占用内存、维护成本高。
1.索引结构
索引底层具有多种数据结构实现、常见的有B树、B+树、Hash。
1.Hash结构
Hash是一种 数组 + 链表 的键值对集合存储结构。主要通过散列函数来控制数据的存储与读取。
为何不用Hash做索引?
Hash结构中,采用散列函数来计算数据的存储位置,不能作为索引结构的原因主要有:
1、哈希冲突:Hash表中主要采用Hash函数来计算数据的存储位置,存在哈希冲突问题。
2、查询缺点:Hash表中不能进行排序、范围查询。
2.B树*B+树
B树也称为B-树(多路平衡查找树)。B+树是B树的一种变体。目前大多数数据库都采用B树&B+树做为索引。
3.B&B+树区别
数据存储结构不同:B树所有结点都存储数据、B+树只有叶子结点存储数据(非叶子结点存储索引)。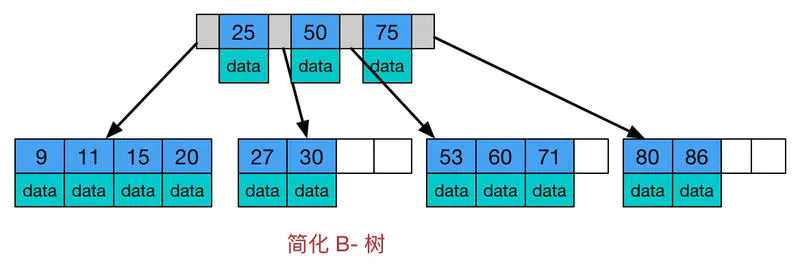
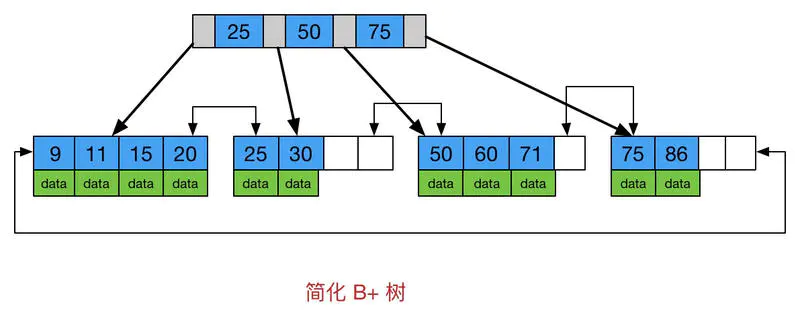
数据检索效率不同:B树相当于二分查找、B+树只能从根结点开始向叶子结点遍历。
叶子结点不同:B树叶子结点之间无关联关系、B+树叶子结点之间存在引用链指向相邻叶子结点。
2.索引类型
1.主键索引
数据库中的主键使用的就是主键索引。唯一且不能重复、不能为null。没有显示指定主键、则会先判断有无唯一索引、否则会创建一个6Byte的自增索引。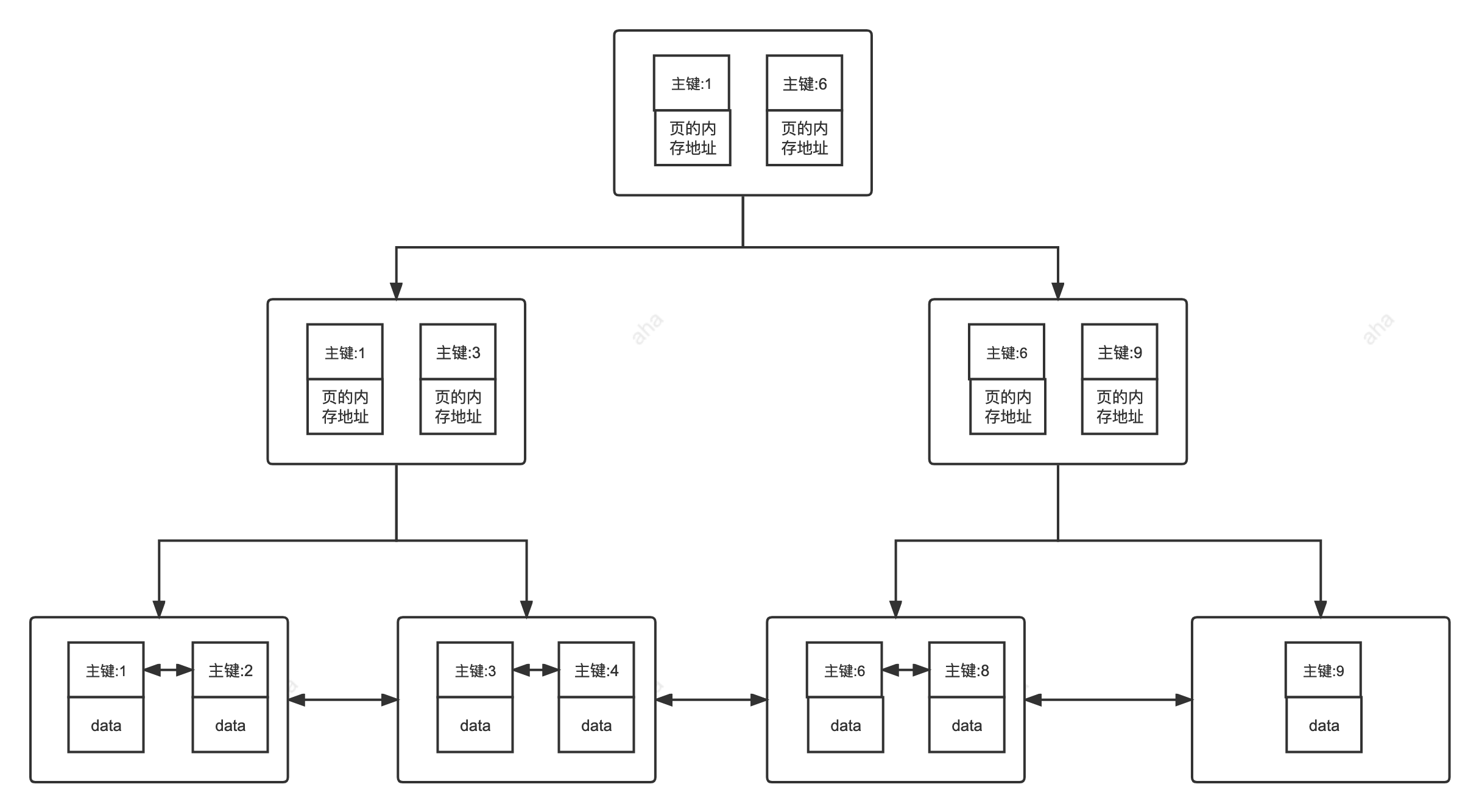
2.二级索引
二级索引又称为辅助索引、是二级索引的叶子结点存储的数据时主键、通过二级索引可以确定主键的位置
唯一索引、普通索引、前缀索引等都属于二级索引。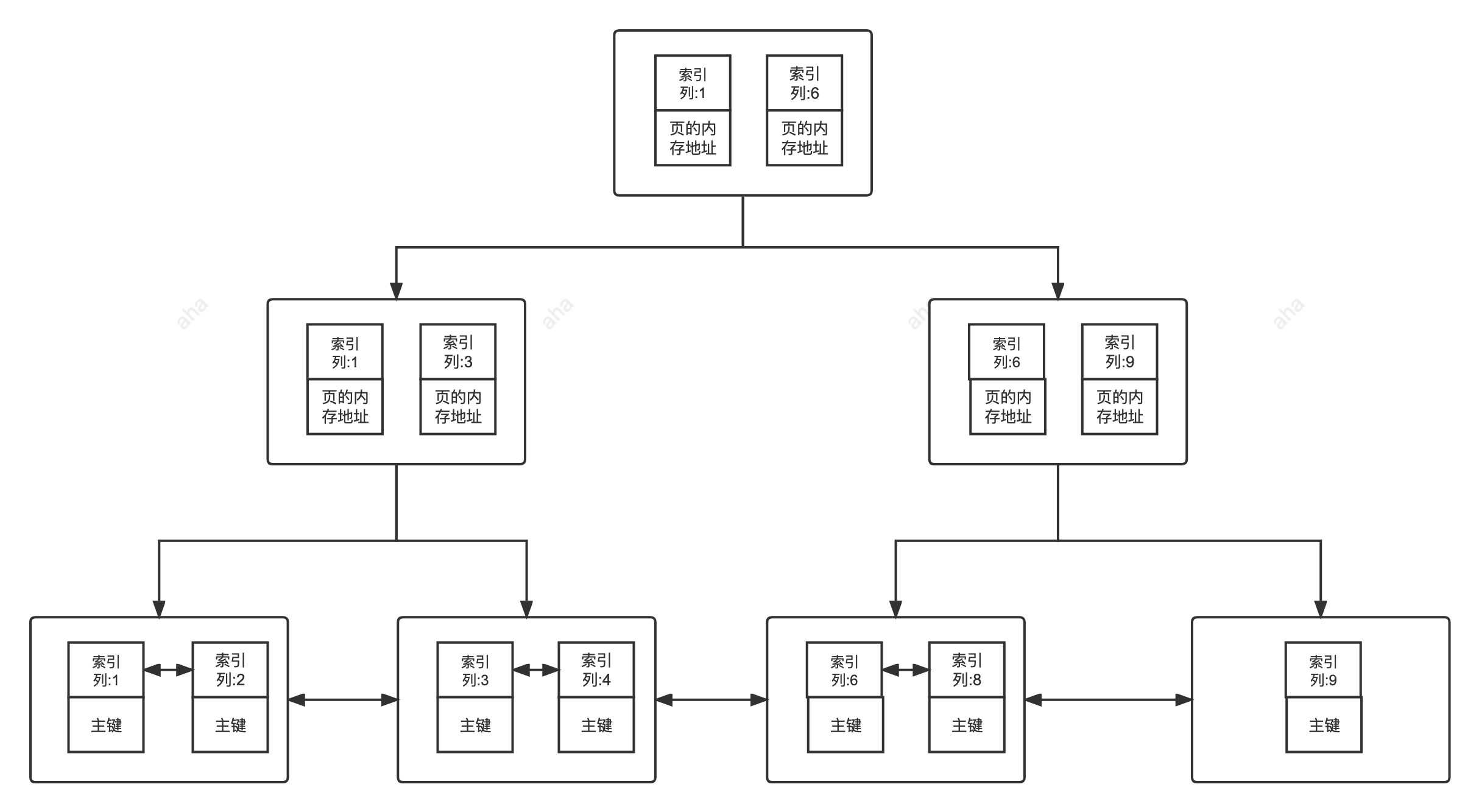
唯一索引:唯一索引不允许出现重复的值、但可以存在NULL。单表允许创建多个唯一索引。
普通索引:普通索引单纯为了提高查询速度,可以存在重复值&NULL值。
前缀索引:适合于字符串类型的前几个字符创建索引。
全文索引:全文索引为了检索打文本数据的索引。
3.聚集索引&非聚集索引
1.聚集索引
聚集索引:数据和索引存储在一起。主键索引就是聚集索引。
特点:查询快速、B+树中叶子结点有序、很容易定位到数据
缺点:
依赖于有序数据:索引无序时、插入数据前要进行排序。
更新成本高:索引和数据同时存在,数据更新时,维护成本高。
2.非聚集索引
非聚集索引:数据和索引分开存储。二级索引就是非聚集索引。
特点:易维护
缺点:
依赖于有序数据、可能需要二次回表查询
3.非聚集索引回表问题
非聚集索引不一定需要二次回表查询。如果需要查询的字段正好是创建的索引、则会直接返回。也就是指索引覆盖。
4.覆盖索引&联合索引
1.覆盖索引
2.联合索引
5.索引创建原则
建立索引:
主键、频繁查询字段、读取占比高的表、尽可能创建组合索引避免冗余索引
不建索引:
可为null的不建、where用不到的不建、频繁修改的不建
6.最左匹配原则
组合索引中、MySQL会根据从左到右的字段顺序依次匹配查询条件。当遇见范围查询时会停止匹配(< > between %开头的like查询等)
7.索引失效
范围查询失效
不符合最左匹配原则失效
字段类型不一致(隐式转换)
索引字段使用函数失效
符号运算失效
or、null、not in like等失效
5.MySQL慢查询日志
1.基本设置
MySQL中默认不开启慢查询日志、需要手动设置参数及其阙值。
然后设置将慢查询日志输出到文件/表结构中。
2.执行计划
explain sql语句
关键字段解析:
id:SQL语句的执行顺序
select_type:SQL语句的执行类型
table:表名
type:SQL语句查询连接类型,性能逐渐提高
possible_keys:显示表中可能使用的索引
key:显示SQL执行过程中实际使用的索引
key_len:使用的SQL索引长度、长度越短越好
ref:表示索引的那一列被引用,最好为const
6.MySQL优化
1.MySQL执行过程
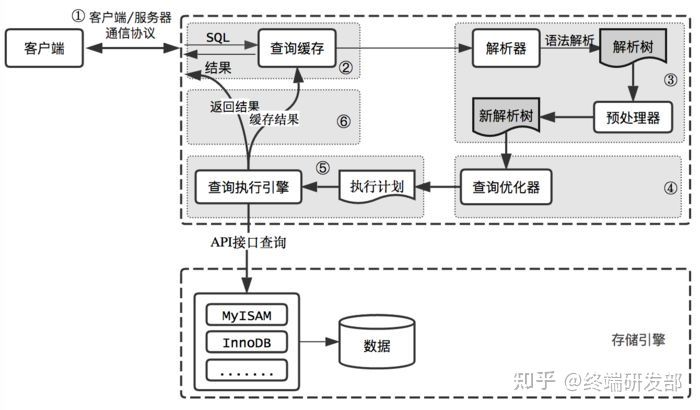
2.优化方面
MySQL优化包含四部分:结构优化、SQL及索引优化、系统配置优化、硬件优化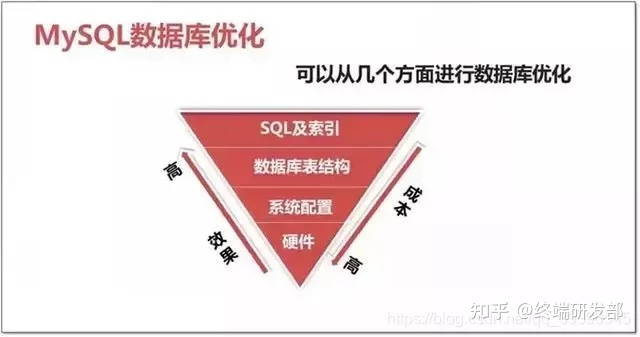
3.优化-SQL及索引
1.原则
1、合理建立索引
2、尽量避免全表扫描
3、尽量避免检索无效数据
2.索引
3.SELECT查询优化
1、尽量避免使用in、not in、or、null、<、>、!=等连接词查询,会造成全表扫描
2、尽量避免对索引字段使用函数、隐式转换,造成全表扫描
3、大数据量时,尽量避免使用1=1恒等条件连接
4、避免使用select 查询,以列名代替
5、多表联查时,小表驱动大表
4.优化-结构优化
1、建立索引:优先考虑where条件后的字段
2、数据类型:合理选用数据类型,避免造成空间等的浪费。
3、合理进行分库分表

若有收获,就点个赞吧
0 人点赞
