1.基本内容
1.JVM核心词
2.特点
跨平台:一次偏移、多平台运行,屏蔽了OS底层的差异性
垃圾回收:JVM中提供了一套较为完善的垃圾回收机制
安全性:安全检查、多态实现等。
3.常见JVM
2.JVM体系结构
1.体系图
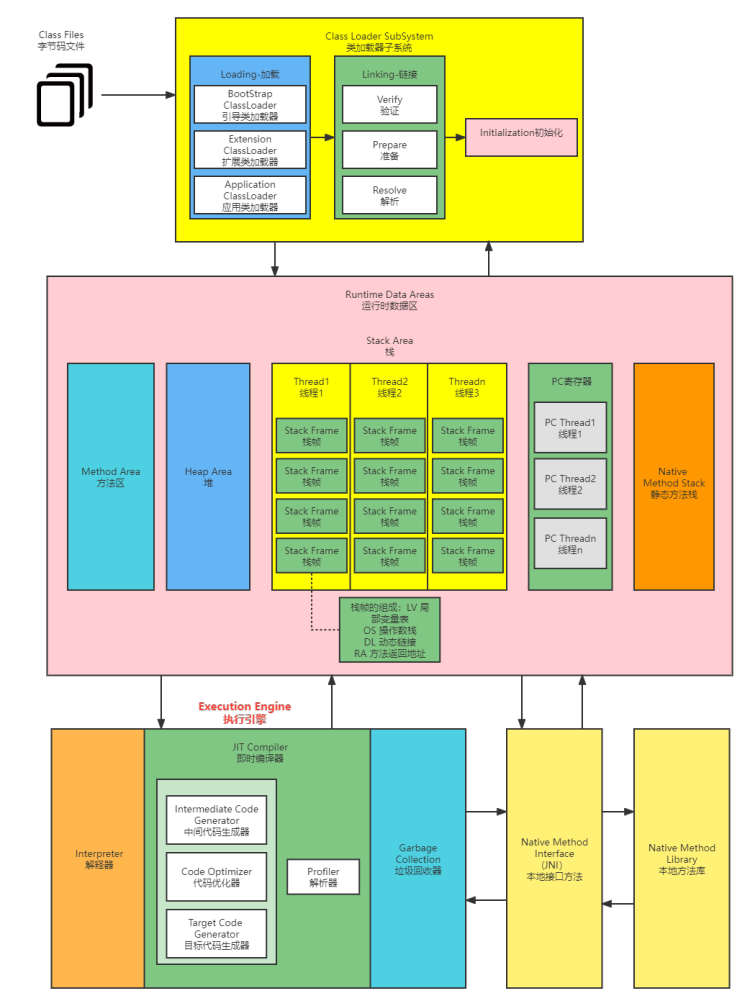
组成:
类加载子系统:加载、链接、初始化
运行时数据区:堆、方法区;PC寄存器、本地方法栈、虚拟机栈
执行引擎:JIT解析器、垃圾回收器
本地接口方法:
本地方法库:
2.生命周期
1、JVM就是一个程序进程、生命周期与进程一致;
2、通常由引导类加载器(Bootstrap class loader)创建的一个初始类(Initial class)完成的。
3.运行时数据区
1.结构组成
运行时数据区:由堆、栈(元空间);程序计数器(PC寄存器)、虚拟机栈、本地方法栈组成。
堆、栈为线程共享;PC寄存器、虚拟机栈、本地方法栈为线程私有。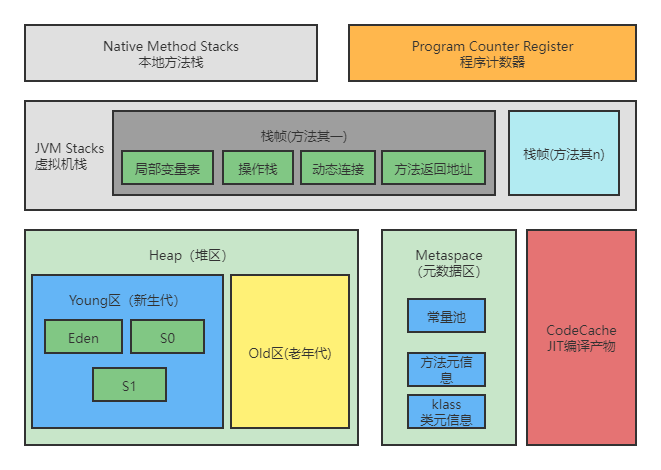
2.系统线程
JVM中的系统线程不包含main线程及main创建的子线程。
1.虚拟机线程:JVM虚拟机到达安全点才会创建
2.周期任务线程:时间周期的体现,用于周期性操作的调度执行
3.GC线程:垃圾回收线程
4.编译线程:将字节码编译成本地代码
5.信号调度线程:接收信号并发送给JVM
3.程序计数器(PC寄存器)
1.作用
程序寄存器是一块很小的内存空间,用于记录当前活动线程的指令执行记录。便于线程在CPU时间片上进行频分上下文切换后再次开始执行。
注意点:
1.PC寄存器线程私有;
2.PC寄存器是 “唯一没有规定OutOfMemoryError异常的区域”;
3.执行Native方法,则计数器值为null值。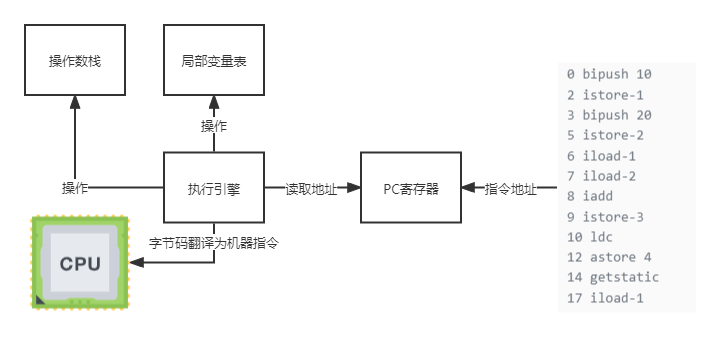
2.私有化
为何需要提供PC寄存器、并将其进行私有化?
1.多线程并发运行过程中,需要进行频繁的资源争夺。
2.多线程并发执行过程中,需要进行频繁的上下文切换,需要一块私有的内存空间进行记录。
4.虚拟机栈
1.核心概念
虚拟机栈与当前活动线程中方法的调用息息相关。随着线程的创建而创建,随着线程的死亡而死亡,生命周期与线程一致,线程私有。
虚拟机栈:对应着Java中方法的调用,每一个栈帧对应一个方法调用。栈帧包含 局部变量表、操作数栈、动态链接、方法返回地址等。
注意点:
1.可能会出现OutOfMemoryError异常、但无GC问题,但是会出现StackOverFlowError异常。
2.局部变量私有且线程安全;静态变量、方法形式参数、局部变量表中有方法返回地址则都非线程安全。
3.栈帧过大、栈帧过多,则都会出现StackOverFlowError异常。
4.如果虚拟机栈动态可扩展,则可能会由于内存申请不够抛出OutOfMemoryError异常。
2.作用
虚拟机栈:栈中由一个个的“栈帧”组成。
栈帧:局部变量表、操作栈、动态链接、方法出口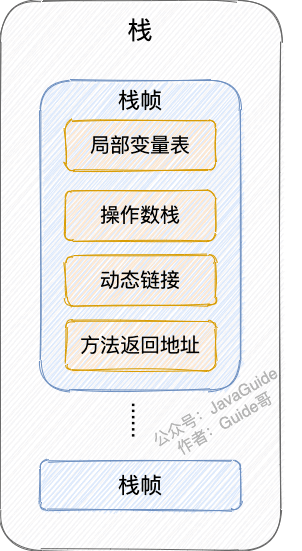
3.栈帧
虚拟机中的栈帧对应着每一次非Native方法的调用。方法入栈,则创建栈帧,方法出栈,则销毁栈帧。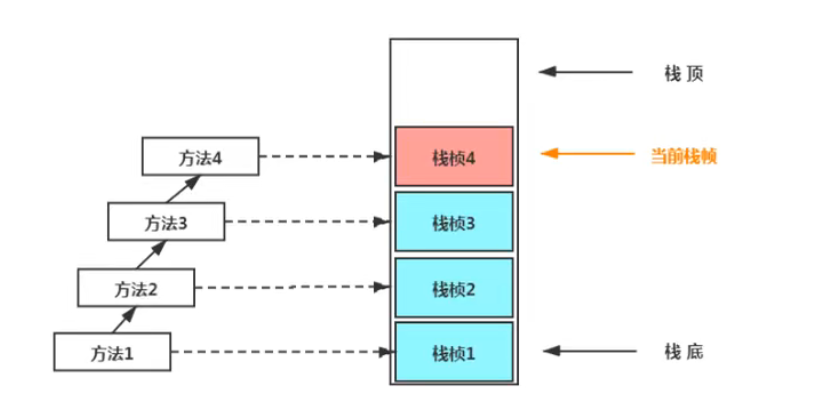
1.局部变量表
局部变量表:存储了编译期可知的各种数据类型(boolean、byte、char、short、int、float、lonog、double)、对象引用(reference类型,不是对象本身,可能是一个指向对象起始地址的引用指针,或者与此对象相关的位置)。
2.操作数栈
主要作为方法调用的中转站使用,用于存储方法执行过程中产生的中间计算结果、临时变量。
3.动态链接
Java源文件编译成字节码后,所有的变量和方法都存储在Class文件中的常量池里。每一个方法调用另一个方法时,都需要将符号信息转换为调用方法的直接引用。
动态链接就是为了将符号引用转换为调用方法的直接引用。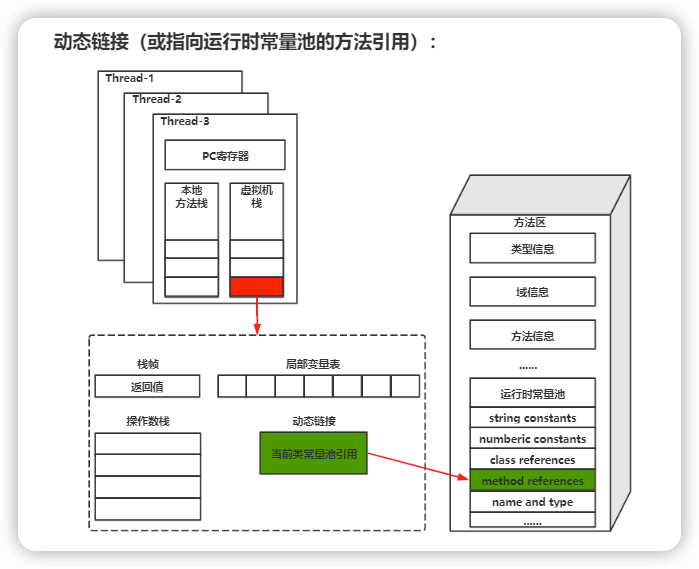
5.本地方法栈
本地方法栈作用和虚拟机栈类似。只不过是为Native方法提供支持。
也会出现OutOffMemoryError、StackOverFlowError异常。且为线程私有。
6.堆(共享)
1.界定
1、Heap堆,是JVM中内存最大的一块,主要用户存放对象实例。
2、几乎所有的对象都存储与堆内存中,从jdk7之后,出现了一些微妙变化
逃逸分析:JDK7中默认开启,如果方法中的对象引用未被返回,或者未被外界使用(未逃逸出去),则可直接在“栈”上分配内存。
3、JVM中进行GC的重点区域、包含Minor GC、Major GC、Full GC(正堆收集)等
2.内存划分
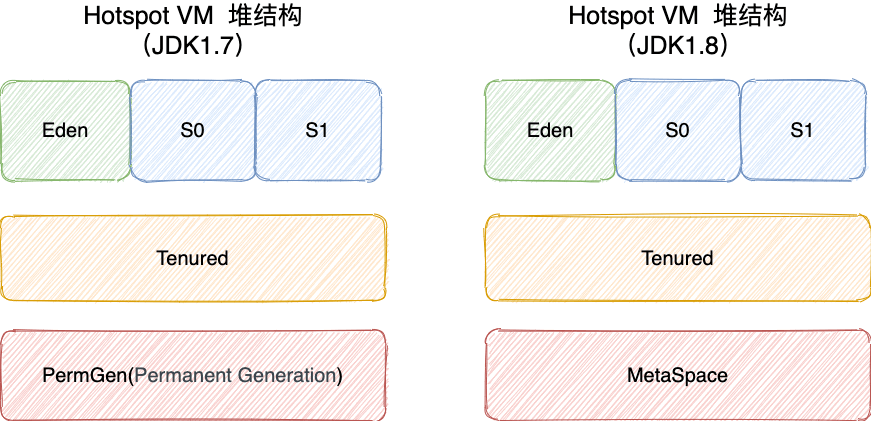
新生代:Eden、S0、S1
老年代:Old
永久代(元空间):PermGen(MetaSpace)
JDK8:将JDK7中的永久代替换为元空间(直接内存)
相关参数:-Xmx(最大堆)、-Xms(最小堆)
3.对象分配过程
一般过程: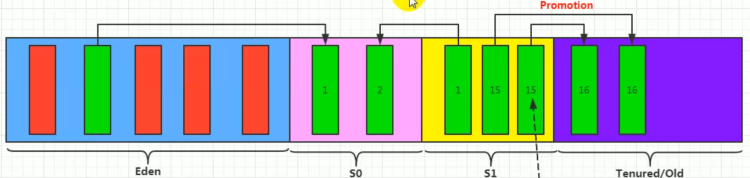
1、new对象,存储在Eden区。如果Eden区内存空间已满,则新生代会发生一次Minor GC(Young GC)。新生代Minor GC中,会将未被其他对象引用的对象进行回收,将存活对象复制移动到空闲S0(To)区域,年龄+1。
2、第一次Minor GC后,将空闲S1(From)区与非空闲区S0(To)区进行互换。空区域S0(To)一直在Eden后面。
3、后续Minor GC中,重复上述步骤,如果年龄达到15,则会晋升Old区。
4、Old区域内存也不够,则会在Old进行一次Major GC(Full GC)。将老年代中的未引用对象清除掉,如果内存还不够,则抛出OutOfMemoryError异常。
特殊情况:
1、如果Eden区Minor GC后,内存不够用,则直接将对象存储在Eden区域。
2、如果S区域Minor GC后,空S区不够用,则将部分对象存储在Eden区、部分仍旧在S区。
4.内存分配担保
确保Minor GC之前,晋升到老年代中对象是否大于老年代剩余空间。
不够,则进行Full GC;
足够,再次通过Handle Promotion判断是否满足,允许满足则进行Full GC。
7.方法区(共享)
1.界定
用于存储被JVM加载的类的信息,包含类信息、变量、方法、常量、即时编译器编译后产生的代码缓存信息、运行时常量池信息等。
2.方法区&永久代&元空间
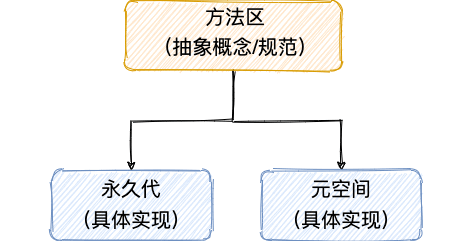
JVM中,永久代、元空间都是方法区的两种实现方式。
JDK7中,通过永久代来实现方法区;但在JDK8中将永久代替换为了元空间。
3.元空间替换永久代
方法区本身就是堆空间中的一块逻辑区域。在《深入理解JVM虚拟机中》说道:
主要原因有以下几点:
1、永久代本身就是堆内存中的一块逻辑地址,难以进行内存空间的动态调整。但在元空间中,使用的是直接内存,大小受制于本地内存的限制,虽然可能会出现内存溢出,但是几率会非常小。
2、永久代内存难以动态扩展、加载的类的信息很少;而元空间内存受限于本地内存的限制,可以同时加载更多的类信息。
4.运行时常量池
Class文件中不仅包含类信息、字段信息、方法信息、以及常量信息之外,在编译期间会产生字面量、符号引用信息,这部分信息存储在“Class文件常量池中”,在类加载后,这部分信息将会被加载到“运行时常量(Constant Pool Table)中”。
字面量:通常指的是类中定义的变量、常量名称等符号表示。
符号引用:符号引用指的是为变量、常量等字面量赋的值信息。
5.字符串常量池
JVM中为了提高性能、减少内存消耗开辟的一块专门避免“字符串重复创建”的区域。
字符串常量池位置移动?
JDK7之前存储在永久代,JDK7及之后存储代堆内存中。
1、JDk6中,运行时常量池、字符串常量池、静态变量均存在与方法区中的“永久代实现中”。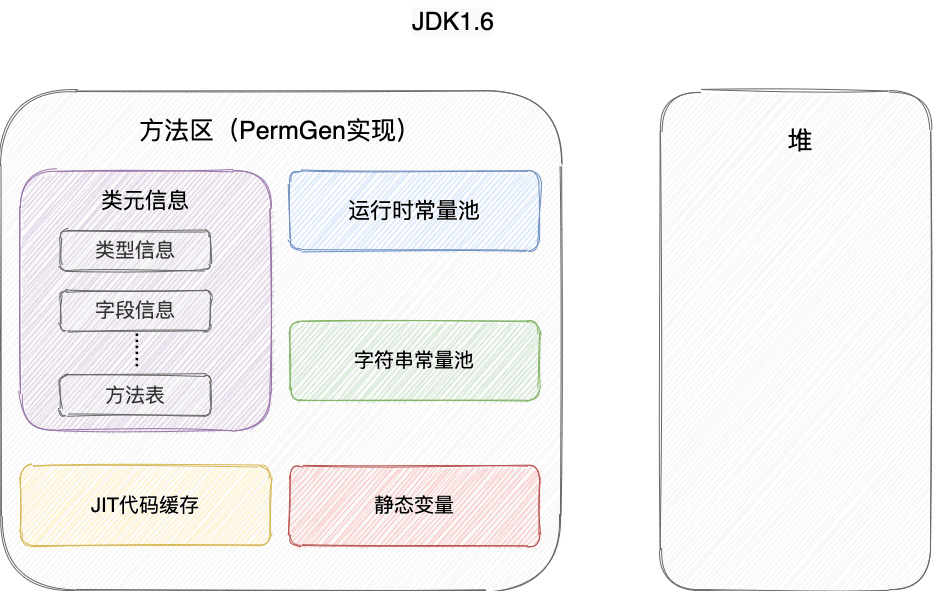
2、JDK7以及JDK8之后,将字符串常量池、静态变量移动到了堆内存中。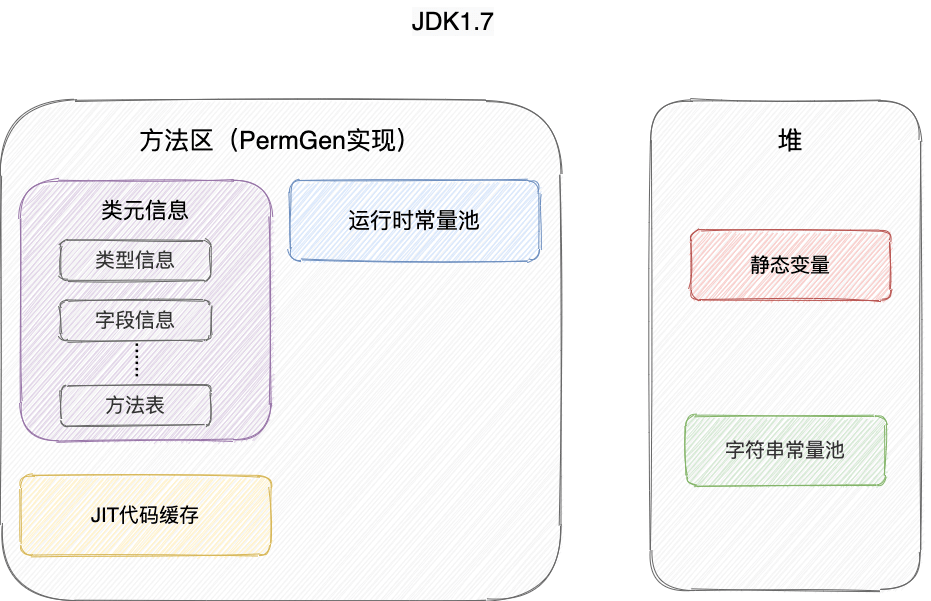
StringTable位置移动?
Java中经常需要使用字符串信息,而在方法区中的StringTable回收很低效、一般只在Full GC的时候进行回收。移动到堆内存中,对于这部分的回收会更加方便、高效。
public class Demo{public static void main(String[] args){String s1 = "a";String s2 = "b";String s3 = "ab";/**此处实际调用的是StringBuilder中的append()方法进行的拼接拼接之后创建一个新对象s4存入*/String s4 = s1 + s2;s3 == s4 ? // 此时,对象不相等,s4为StringBuilder调用append()拼接后创建的新对象,存在于堆内存中,s3存在于串池中String s5 = "a" + "b"; // 此时,直接从串池中查询,s3 == s5}}
6.直接内存
JDK4中新添加了一种基于通道与缓存区的NIO类、可以通过Native函数库直接分配堆外内存,通过直接内存可
以显著的提升性能,避免了Java堆和Native堆之间来回复制数据。
该区域中也会出现OutOfMemoryError异常,但不会受到JVM的GC影响。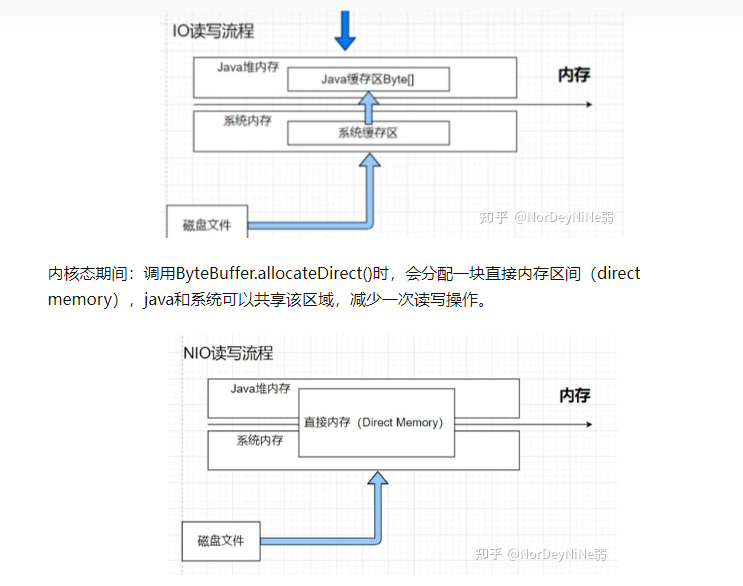
4.垃圾回收-标记阶段
1.任务&区域
2.垃圾标记算法
1.标记阶段-引用计数算法
JVM中为每一个对象创建了一个“整型引用计数器”,每个对象被引用一次、则引用计数器就会+1;失去引用一次,则引用计数器就会—1。如果引用计数器数值 = 0,则该对象将会被回收。
特点:
优点:对象标识简单、高效无延迟性;
缺点:无法解决“循环引用问题”。
2.标记阶段-可达性分析
可达性分析是对“引用计数算法”的一个优化,目的是解决“循环引用问题”。会出现STW(用户线程阻塞)。
从GC Roots(根对象)为起点,从上之下对目标对象进行搜索,如果是不可达的,则将会被进行“标记”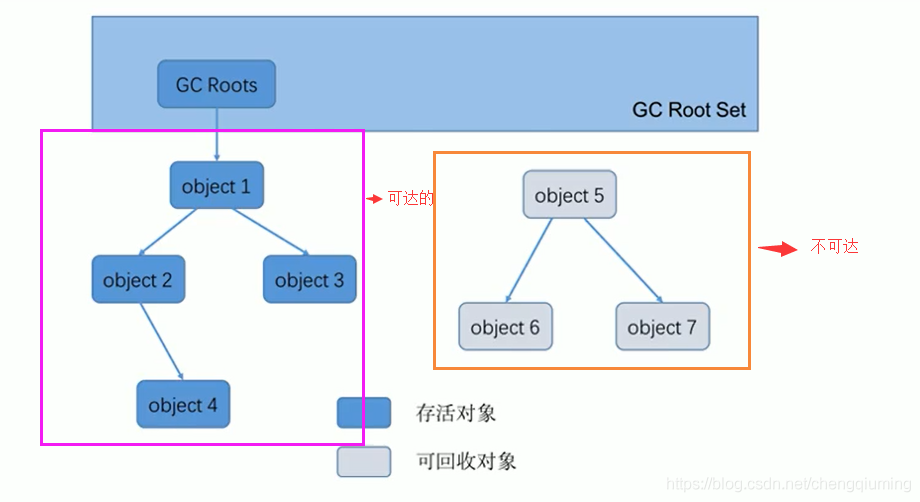
GC Root:
1、虚拟机栈(栈帧的局部变量表)中引用的对象;
2、方法区中常量、本地变量引用的对象;
3、本地方法区中Native引用的对象;
4、所有被同步锁持有的对象。
3.finalize&二次标记&引用
1.对象finalization终止机制?
Java语言中提供了finalization机制来供开发者在对象被回收之前自定义处理逻辑,对象被回收前则会调用该方法,允许重写,用于对对象被回收时释放资源。
注意点:
1、调度权应该交给垃圾回收机制、主动调用finalize()可能会导致对象复活。
2、JDK9中逐渐淡化掉了finalize()方法。
2.标记一次就可回收?
标记阶段-可达性分析过程中,一个对象被标记为“不可达”时,并不会立刻宣布该对象死亡。需要两次标记。
1·、初次从GC Root扫描、不可达则进行一次标记;
2、进入筛选、看有无必要执行finalize()方法。
1·、对象没有覆盖finalize()方法、或者已被虚拟机调用,则再次“标记”。
2、有必要执行,则放入F-Queue队列中,该队列中对象可将自己加入引用链进行逃逸。
3.对象引用
引用:如果reference类型中的内存区域中存储的数值是另一块内存的起始地址,则该内存地址就叫做引用。
强引用:强引用是代码中非常常见的类型,如“Object obj = new Object()”类型。
只要强引用对象存在,则垃圾回收器就不会对被引用对象进行回收。
软引用:指一些还存在、但非必需的独对象,通过SoftReference实现。
在内存溢出之前,会被列入安全范围进行二次回收。
弱引用:描述的也是非必需对象,只能存活到下一次垃圾回收之前,一定会进行垃圾回收。
虚引用:最弱的一种引用,通常不会到生命造成影响。
5.垃圾回收-清除阶段(清除?)
1.标记-清除(Mark-Sweep)
1.界定
最基础的垃圾清除算法,后续算法均是在此基础之上进行的。包含标记、清除两阶段。
2.特点
低效率:GC执行时,用户线程全部阻塞(STW);
内存碎片:清除阶段不会对空闲内存进行整理,通过一个空闲列表来维护空余内存。
3.标记阶段
可达性标记算法:从GC Root触发、采用三色标记法标记。
黑色:被完全扫描过、是完全存活对象;
灰色:未被完全扫描、至少还有其他引用等待扫描;
白色:未被标记的垃圾对象,需要进行回收。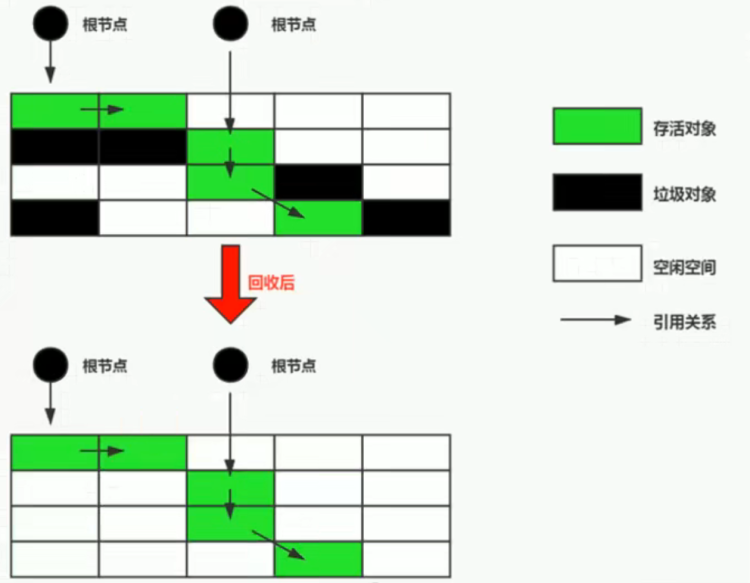
4.清除阶段
标记阶段过后,将可回收内存标记为空闲内存,并不会进行内存移动,通过空闲表维护。容易产生内存碎片。
2.复制(Copy)
1.界定
对标记-清算算法的一项优化。
可达性分析算法:将内存容量划分为大小相等的两块,每次只使用一块内存。当其中一块内存满时,则将其存活对象通过复制的方式移动到另一块空闲的区域。
2.特点
高效:无需标记-清除过程,每次只需要移动堆顶指针,然后按照顺序重新分配内存即可。
无碎片:整体复制移动,不会产生垃圾碎片。
缺点:需要两倍的内存空间进行复制移动。
场景:垃圾对象多、存活对象少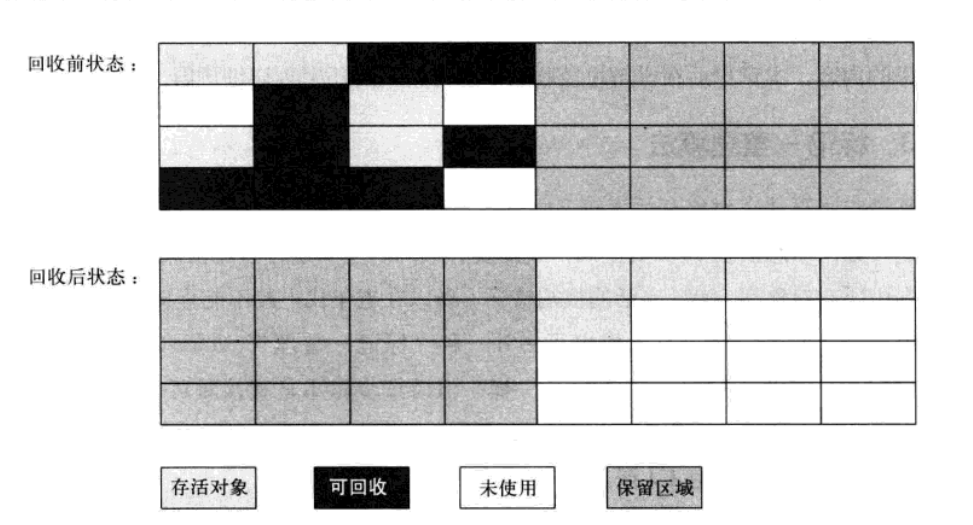
3.实际引用
堆区中的新生代就采用了这种“复制(Copy)”算法进行回收。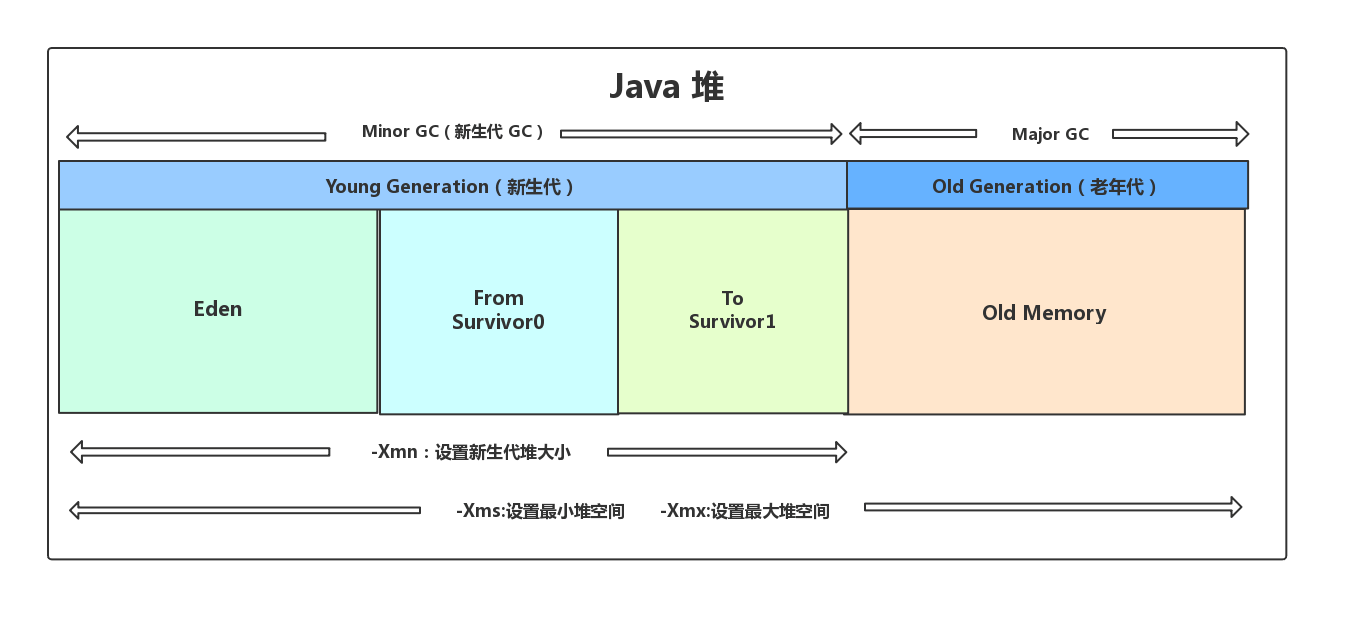
每次只使用Eden、S区中空闲的一块;
内存慢时,则将Eden、S区中已使用的一块中存活对象一次性复制到S区中另一块中。
3.标记-整理(Mark-Compact)
1.界定
可达性分析算法:适用于垃圾对象少、存活对象多的情况,是对标记-清除算法中内存无法整理的优化,存活对象向一端移动,不会产生碎片问题。
2.特点
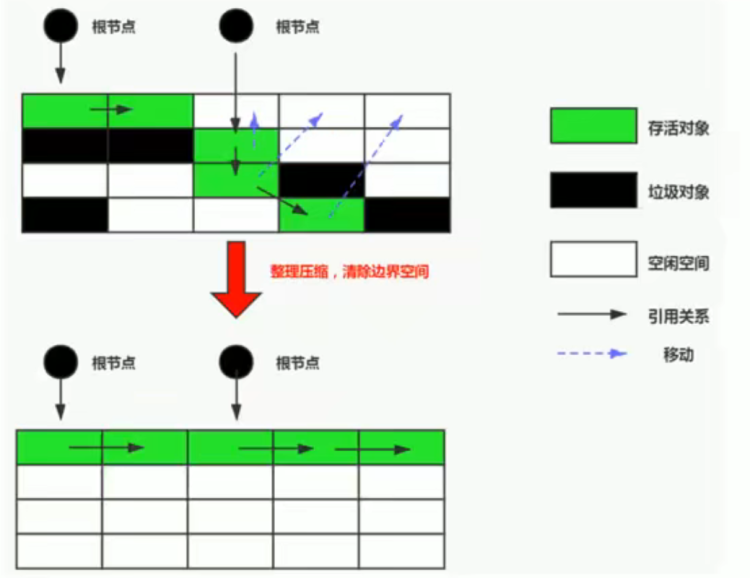
4.分代收集
Java堆划分为了新生代和老年代、分代收集的思想就是按照不同对象的生命周期进行划分,然后按照不同的分代内存采取不同的垃圾回收策略。
新生代中,垃圾对象多、存活对象少、则采用复制算法进行清除,To和Form区之间的移动。
老年代中,垃圾对象少、存活对象多、则采用标记-清除、标记-整理算法进行清除。
6.垃圾回收-垃圾回收器
1.Serial-串行
Serial-串行回收器是最基础、最古老的一种回收器,最早应用于JDK3中。
最早使用于新生代中,“单线程”回收,这种单线程指的是 Serial-串行 GC执行期间、用户线程全部进入阻塞状态(STW),直至GC执行完毕、用户线程才会正常运行。
高效、但用户体验度差
新生代:复制算法
老年代:标记-整理算法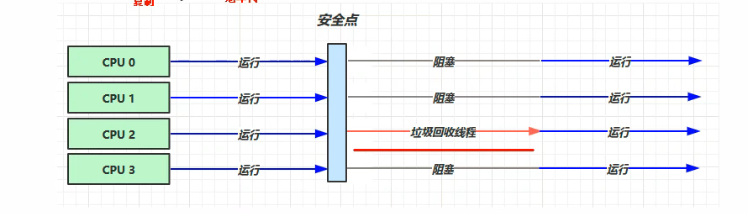
2.ParNew-串行多线程
ParNew收集器是对Serial-串行回收器的一种多线程机制实现,只是增加了GC多线程回收机制,其余行为和Serial一致(包含垃圾回收算法、执行过程等)。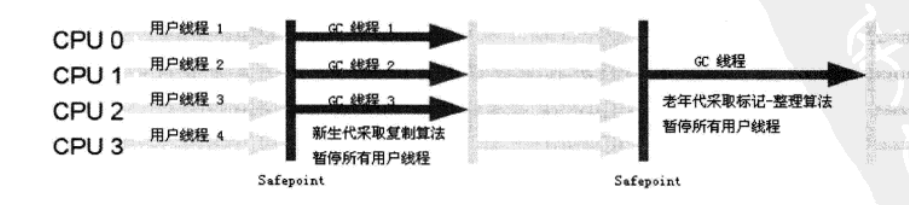
3.Parallel-吞吐量优先
Parallel回收器也是“新生代”中的一种收集器、通常采用吞吐量优先(CPU执行代码时间 / CPU总消耗时间)来进行垃圾回收。
多线程并发执行、GC期间也需要STW。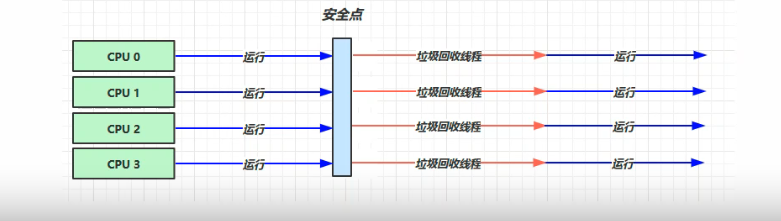
4.CMS-响应时间优先
Concurrent Mark Sweep,是一种STW时间最短的回收器。对于重在缩短服务停顿时间的需求来说,是一个非常不错的选择。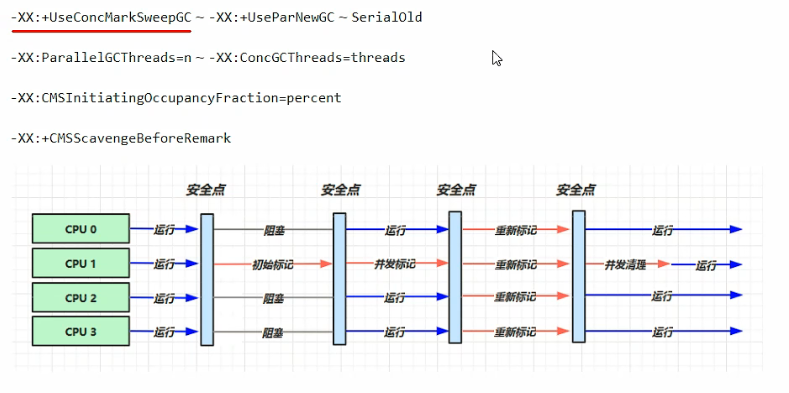
包含四个步骤:
1、初始标记:该阶段只标记被GC Root能够直接关联对象;期间会出现短暂STW、快速标记。
2、并发标记:该阶段对GC Root关联对象进行详细标记;期间无STW时间、并发标记。
3、重新标记:该阶段负责并发阶段中出现关联变动的标记;期间会出现较长STW、并发标记。
4、并发清除:该阶段采用“标记-清除”算法进行垃圾回收;期间无STW时间、并发清除。
问题;
老年代中进行CMS、如果并发标记阶段出现错误,则会触发一次Full GC。
采用“标记-清除”算法会出现大量的空间碎片。
5.G1-面向服务器
G1也是一个并行回收器、将整堆内存划分为多个大小相同的Region(分区)。通过不同的Region来表示Eden、To、Form、Old区,根据不同Region的堆积程度以及维护一个优先列表,回收最大价值的对象垃圾。
1.回收特点
1、并发与并行:(并行)G1进行GC期间、会出现用户线程STW阻塞。(并发)G1执行过程中,允许部分用户线程与GC线程交替执行。
2、分代收集:G1回收器将整堆进行同大小Region划分、不会明确的标识Eden、To、Form、Old区域,通过Region中对象是否超过了50%来进行大小对象区分。
3、空间整合:G1回收器在同等Region之间采用“复制”算法,但在整体上采用的是“标记-整理”算法,不会出现内存空间碎片问题。
4、精确控制:G1回收器允许使用者指定一个长度为M毫秒的时间片段内,垃圾清除的时间不会超过N毫秒。
2.回收过程
总体包含三总回收过程: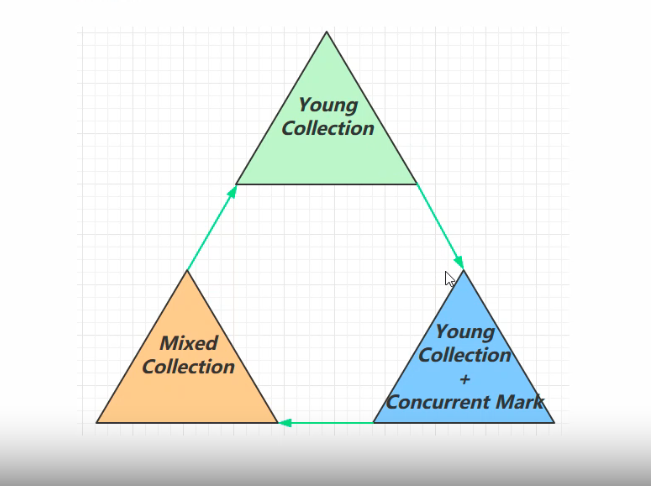
详细回收过程: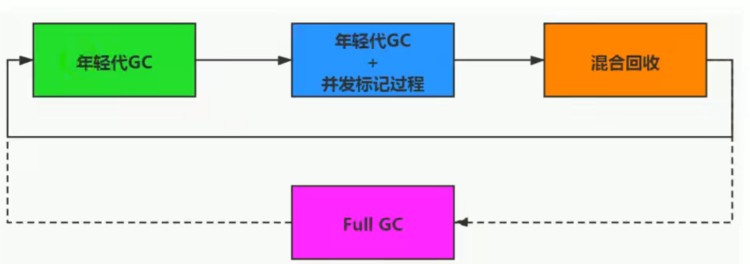
1、新生代-Young Collection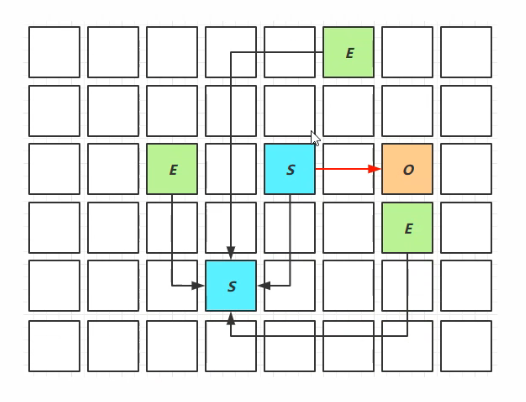
新生代中的Eden区内存不足、则通过“复制算法”进行垃圾回收,晋升到S区;(有STW时间)
晋升到S区后,内存仍然不足,则晋升到Old老年代。
2、新生代-Young Collection & Concurrent Mark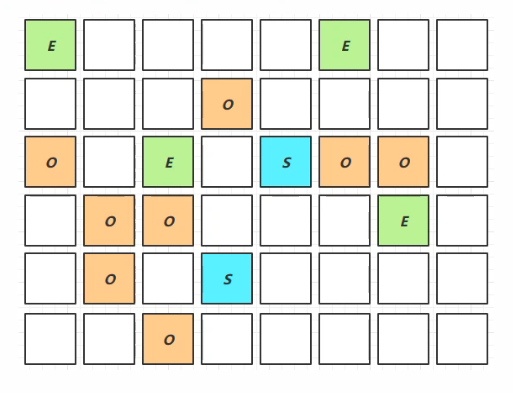
Young GC时,对GC Root进行初始标记。
老年代达到内存阈值,则进行并发标记(无STW时间)
CMS并发过程中,出现错误则进行Full GC
3、Mixed Collection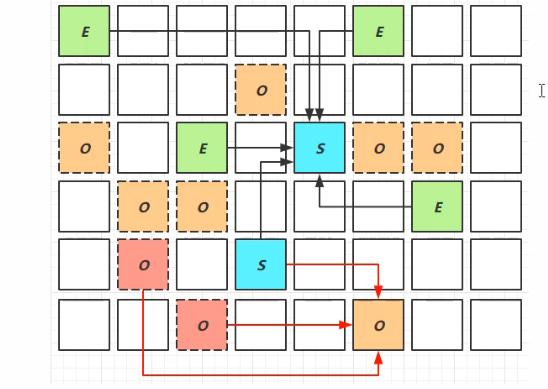
混合回收阶段看会对整堆进行全面回收:
第一阶段:Eden区内存不足、采用“复制算法”复制到S空闲区;
第二阶段:S区内存不足,则晋升到老年代;
第三阶段:老年代内存不足,则有选择的进行老年代回收;
最终标记:会出现STW、拷贝存活;会出现STW;当整堆内存不足时,则进行Full GC。
3.Full GC
G1的设计初衷就是减少Full GC的产生。但如果上述回收过程中未能正常执行,则G1会进行STW并进入单线程垃圾回收算法进行垃圾回收。
触发条件:堆内存耗尽、清除垃圾时内存无法存储晋升对象、并发处理过程中空间耗尽。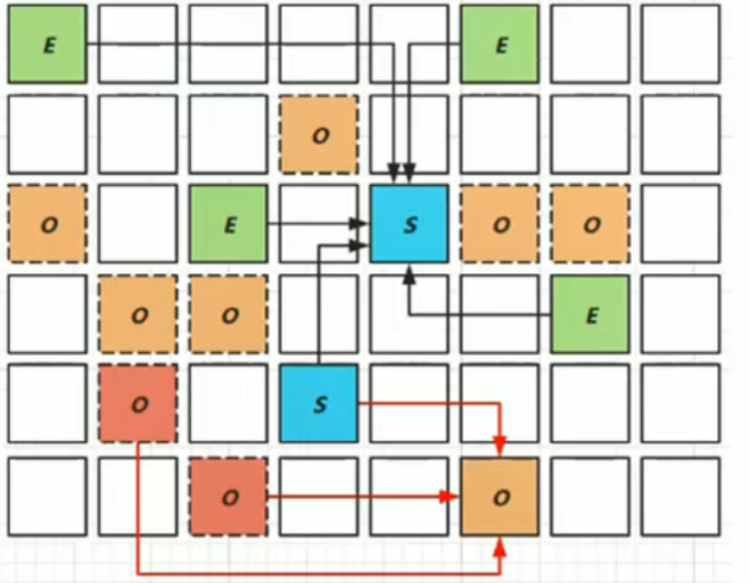
6.垃圾回收器总结
| 垃圾回收器 | 类型 | 作用位置 | 算法 | 特点 | 使用场景 |
|---|---|---|---|---|---|
| Serial | 串行 | 新生代 | 复制 | 响应速度优先 | 单CPU Client |
| ParNew | 并行(Serial) | 新生代 | 复制 | 响应速度优先 | 多CPU Server |
| Parallel | 并行 | 新生代 | 复制 | 吞吐量优先 | 后台运算 |
| Serial-Old | 串行 | 老年代 | 标记-整理 | 响应速度优先 | 单CPU Client |
| Parallel-Old | 并行 | 老年代 | 标记-整理 | 吞吐量优先 | 后台运算 |
| CMS | 并发 | 老年代 | 标记-清除 | 响应速度优先 | C/S |
| G1 | 并发、并行 | 整堆 | 复制、标记-整理 | 响应速度优先 | 服务端 |
7.类加载子系统
1.编译动作
1.解析
解析:包含了词法分析和语法分析。
词法分析:词法分析是将源文件中的字符流拆分成标记(Token)集合。单个字符为编译过程中最小元素。
实例:int a = b + 2; 拆分为:int、a、=、b、+、2这6个Token标记。
语法分析:语法分析是基于词法分析产生的Token序列,来构建抽象语法树(描述代码程序结构)的过程。
2.填充符号表
符号地址~符号信息的映射表格。通过符号表来进行符号地址分配。
3.注解处理器
4.语义分析&字节码生成
语义分析:语法分析构建抽象语法树后,无法保证逻辑的正确性,语义分析就是对该问题的一个审查。
字节码生成:字节码生成是javac编译的最后阶段,将前面的全部信息转换为字节码写到磁盘中。
2.Java语法糖
1.泛型&泛型擦除
泛型:是为了打破对类型的约束,能够使得一些容器等更加兼容多种Object的存储使用。
泛型擦除:泛型只在编译期有效、编译过会会将其进行擦除,也就是说转型成第一个边界类型。
2.自动装、拆箱&遍历
public static void main(String[] args){// 泛型List<Integer> list = Arrays.asList(new Integer[]{// 自动装箱Integer.valueOf(1);Integer.valueOf(2);});// 循环遍历int sum = 0;for(Iterator it = list.iterator(); it.hasNext()){// 自动拆箱int i = (Integer) it.next().intValue();sum += i;}}
1.类文件结构
.java文件经过JVM编译器——>编译为.class文件;
*.class文件经过JIT解析器——>解析为机器码。
ClassFile {u4 magic; //Class 文件的标志u2 minor_version;//Class 的小版本号u2 major_version;//Class 的大版本号u2 constant_pool_count;//常量池的数量cp_info constant_pool[constant_pool_count-1];//常量池u2 access_flags;//Class 的访问标记u2 this_class;//当前类u2 super_class;//父类u2 interfaces_count;//接口u2 interfaces[interfaces_count];//一个类可以实现多个接口u2 fields_count;//Class 文件的字段属性field_info fields[fields_count];//一个类可以有多个字段u2 methods_count;//Class 文件的方法数量method_info methods[methods_count];//一个类可以有个多个方法u2 attributes_count;//此类的属性表中的属性数attribute_info attributes[attributes_count];//属性表集合}
1.魔数
1 u4 magic;
每个Class文件的头四个字节称为魔数,唯一做勇敢是确定这个文件是否为一个能被虚拟机接收的class文件。
2.版本号
1 u2 minor_version;1 u2 major_version;
魔数后面的四个字节存储的Class文件的版本号。5、6位为次版本号、7、8位为主版本号。
3.常量池
1 u2 constant_pool_count; // 常量池数量2 cp_info 从上探探_pool; // 常量池
主次版本后的是常量池,常量池数量是constant_pool_count - 1(从1开始计数、0不做计数)。
4.访问标志
常量池结束之后的两个字节代表访问标志,用于识别一些类或者接口层次的访问信息。
5.当前类、父类、接口索引集合
6.字段、方法、属性表集合
2.类加载时机
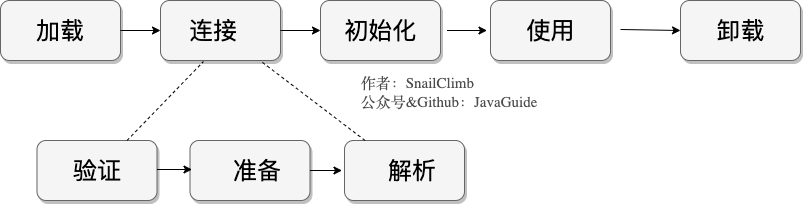
3.类加载过程
类的加载过程主要包含:加载、链接、初始化。链接阶段又包含(验证、准备、解析)。
1.加载
1、通过一个类的全限定名来获取定义此类的二进制字节流;
2、将字节流中的静态存储结构转换为方法区中的运行时数据结构;
3、内存中生成Class对象,作为方法区数据的入口。
类的来源:JVM中没有做明显的规定、来源于ZIP、网络读取、其他文件JSP、数据库等。
2.链接-验证
这一阶段主要用于确保类中的信息时安全的,符合JVM虚拟机规范的,不会对JVM虚拟机造成危害。
包含:文件格式、元数据、字节码、符号引用验证。
3.链接-准备
这一阶段主要用于进行类变量(静态变量)在方法区中进行内存分配与初始化赋值的阶段。
public static int num = 123; // static修改的非final类型初始化Wie0public static final int nu, = 123; // static final修饰的常量则初始化为123
4.链接-解析
这一阶段主要用于将Class文件中常量池中的符号引用转换为直接引用,并通过运行时常量池进行缓存,防止重复解析动作执行。
5.初始化
这一阶段主要用于执行字节码,也就是执行
注意:
1.类中无静态变量 或 静态代码块时,不会执行clinit方法;
2.
3.
4.如果有父类,则会先执行父类的
5.JVM中必须保证
4.类加载器分类
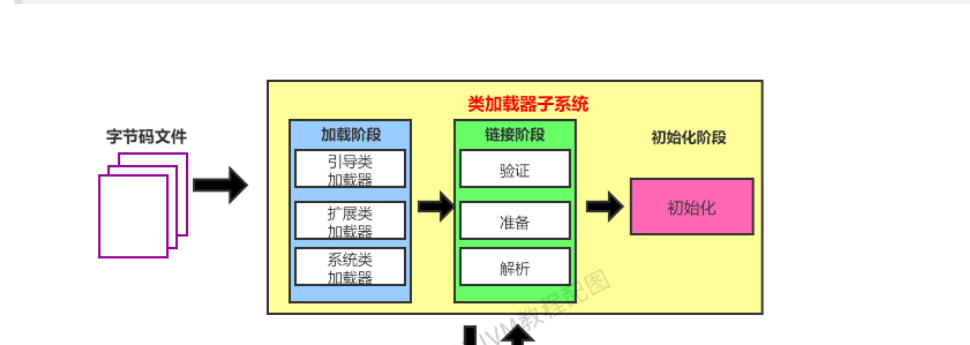
1.系统自带的类加载器
BootStrap Class Loader引导类:加载核心库,加载lib目录中下的jar包和类;
Extension Class Loader扩展类:加载lib/ext目录下的jar包和类;
System Class Loader系统类:负责加载classpath下的类库。
2.自定义类加载器
为何需要自定义?
隔离加载类;
修改类加载方式;
防止加载源;
防止源码泄露。
如何实现?
继承ClassLoader、继承URLClassLoader
5.双亲委派机制
JVM中采用按需加载的方式,通过向上委托进行加载,如果父类无法完成加载任务,则子类才会进行亲自加载。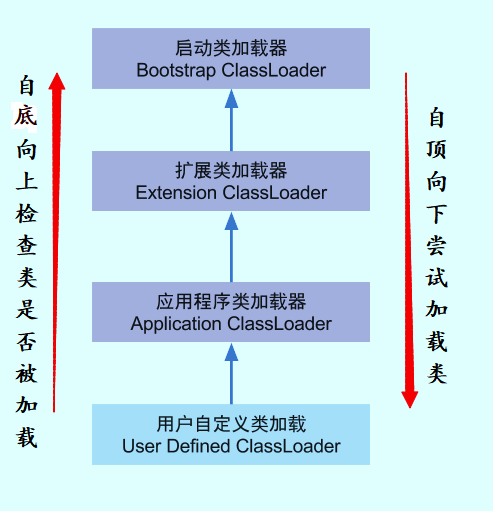
1.优势
2.破坏
不想使用双亲委派机制时,则可以重写ClassLoader类中的findClass()方法即可。
想要打破双亲委派机制时,则需要重写loadClass()方法。

若有收获,就点个赞吧
0 人点赞
