1.何为Kafka
Kafka是一个基于发布订阅模式的、分布式事件流消息处理平台。具有高吞吐量、持久化、高扩展的流式处理特点。
2.应用场景
Kafka和其他的消息系统一样,都具有服务解耦、流量控制、异步处理等功能。
通常用于:信息系统、网站活动追踪、日志收集、监控等
异步处理:
订单服务链路中:首先要扣减库存——>下单——>积分。
上述过程中随着后续服务的不断增加,使得链路越来越长。比如后续增加短信服务、数据统计服务等
这时候,就需要使用异步处理:内部异步处理多种服务、外部快速响应用户体验。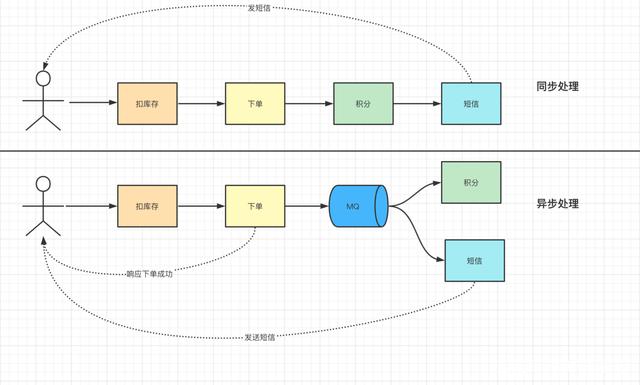
系统解耦:
上述链路中,如果单单集成在一个服务中,则需要随着服务的增加,不断的更改订单模块代码。
这时候就需要系统解耦:订单产生后,只需要将消息推入到消息队列中,下游服务订阅即可。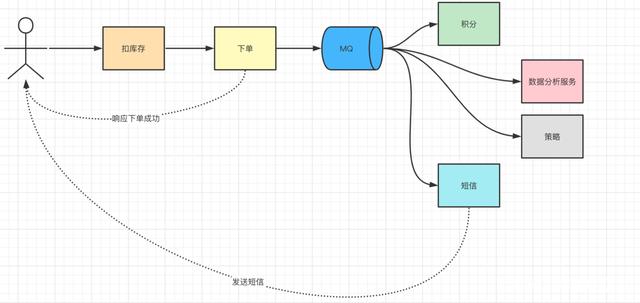
流量控制:
ES搜索数据同步过程中,如何采用同步写入ES、则会导致大量数据压垮服务。
这时候就需要流量控制:通过增加kafka缓冲层,缓冲同步数据,下游尽最大努力消费同步。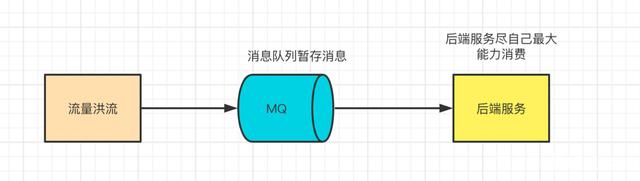
3.Kafka组件
1.Kafka架构
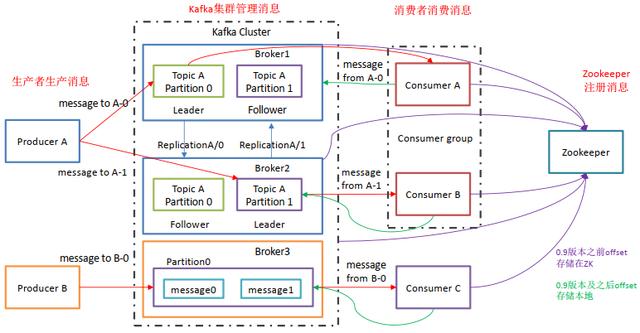
Producer(消费者):消息的产出者、将消息推送到Broker中
Broker(经纪人):Kafka实例、一台Kafka服务为一个实例,也就是一个经纪人,用于管理话题
Topic(话题):Kafka中消息的类别表示,通过不同的Topic来区分不同的消息队列。为了实现扩展:一个Topic可
以跨越多个Broker。
Partition(分区):Topic中的逻辑区分,每一个Partition又是一个有序队列,为了实现扩展:一个Topic中可以存
在多个Partition。
Consumer(消费者):消息的消费者、通过拉取消息进行消费。
2.Kafka副本机制
Kafka为了保证Kafka集群中的单节点故障、确保Partition分区中的消息不丢失,提供了一个Partition多副本机制。
单个Partition中,存在多个follower(副本)、一个leader。接收消息的过程中,实际上是在通过leader进行交互。推送消息给leader、follower主动拉取同步。
4.队列模型
1.早期队列模型
早期队列模型中,Producer生产消费到队列中,多个消费者消费时尽量均分消费。这种模式的缺点就是难以指定消费发送给需要的消费者。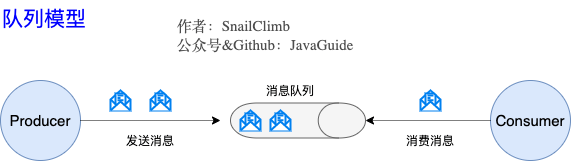
2.Kafka-发布/订阅模型
为了解决上述传统消费模型问题,Kafka提出了发布-订阅模式。多个Producer生成各种类型的Topic存入到消息队列中,下游服务(Consumer)通过订阅感兴趣的Topic来消费指定类型的消息。
发布-订阅模式中,如果只存在单个Consumer,则这种模式就和传统的消息队列没有区别。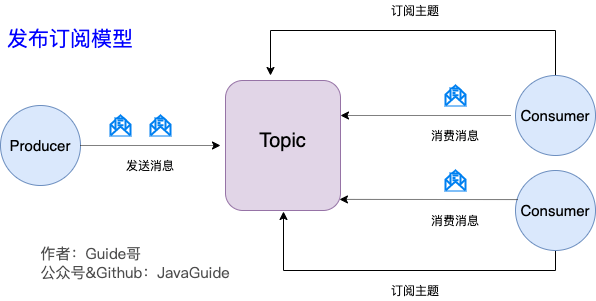
5.核心问题
1.文件存储
Kafka中采用“尾部追加”写入数据到log日志中的末端、消费消息时,按照顺序进行消费。
Kafka中采用Partition-log来存储文件,单个Partition只对应一个log文件。为了防止单个log文件过大问题,又在log文件中划分了多个segment片段来进行区间划分。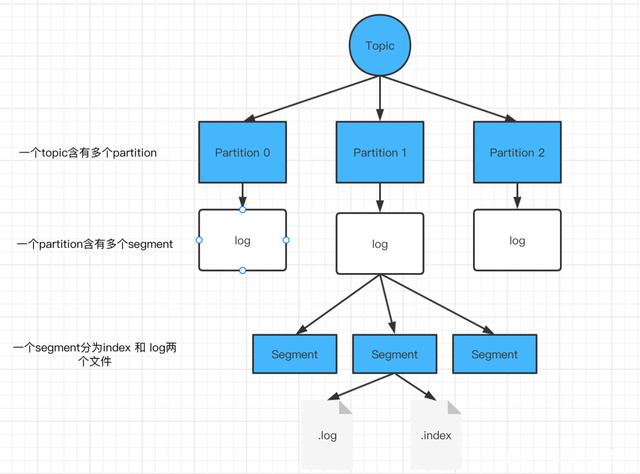
2.消息不丢失
Kafka中主要面临三种数据丢失区间,分别是生成消息过程、Broker存储消息过程、消费消息过程
Producer生产端:
可能由于网络不可用、消息不合格则会导致消息根本无法写入Broker中。
因此、Kafka中提供了ACK确认机制来保证消息的稳定生成:
ack=0:producer不需要等待broker的回应、极大可能存在消息丢失。
ack=1:producer需要等待指定的分区中的leader返回相应的确认消息。当leader同步消息到follower之前发生故障,则仍然会导致消息丢失。
ack=-1:producer需要等待指定的所有分区中leader与follower全部落实完毕。当leader同步消息之后、如果当前leader宕机、则kafka会认为消息发送失败、重新发送消息给新的leader。
// 此处采用消息发送回调进行判断ListenableFuture<SendResult<String, Object>> future = kafkaTemplate.send(topic, o);future.addCallback(result -> logger.info("生产者成功发送消息到topic:{} partition:{}的消息", result.getRecordMetadata().topic(),result.getRecordMetadata().partition()),ex -> logger.error("生产者发送消失败,原因:{}", ex.getMessage()));
Broker存储端:
Kafka中的Broker接收到消息后,需要将消息持久化到磁盘中,这个过程主要依赖于多个Replica(冗余副本)机制来保证数据的可靠存储。
Consumer消费端:
Kafka消费端可以通过其他业务逻辑进行判断,正常执行完业务逻辑则为消息消费成功。
Kafka中也可以通过手动提交offset进行判断,但这种机制也会出现消息重复消费问题。
3.消息有序性
Kafka中的Topic可以对应多个Partition分区,每个分区中采用尾加法进行消息推送。只能保证单个Partition分
区中的消息有序(局部有序)。
解决方案:
1.减少分区数,单个Topic对应单个Partition分区。
2.指定key/partition,Kafka中发送消息时,可以指定topic/key/partition/data四个部分,通过指定key就可以向指定分区推送消息。
4.消息不重复
原因:
Produce发送消息,写入了Broker,但是由于网络原因没有被消费,导致Producer进行了重发;
Consumer消费消息后,需要更新offset、但此时Consumer宕机,新的Consumer启动,重新消费消息;
解决方案:
1.幂等性:Kafka中为每个Producer分配了一个唯一PID、发往同一个Broker的消息会携带一个Sequence Number,Kafka中会对
Redis中的set、MySQL中的主键都可以进行幂等性处理。
2.Offset:关闭自动提交、通过手动提交offset保障消息不重复性。但这种方式会还是可能会出现重复问题。
执行完业务在提交,和自动提交无区别;拉取到消息就提交,这需要进行消息延迟。

若有收获,就点个赞吧
0 人点赞
