Smart DataHub支持高级用户(需具备数据库和SQL知识)低代码方式开发数据集成流程,典型场景包括ELT、ETL、反向ETL(即数据加工处理后推送到业务系统)等场景。
1. 数据流入口
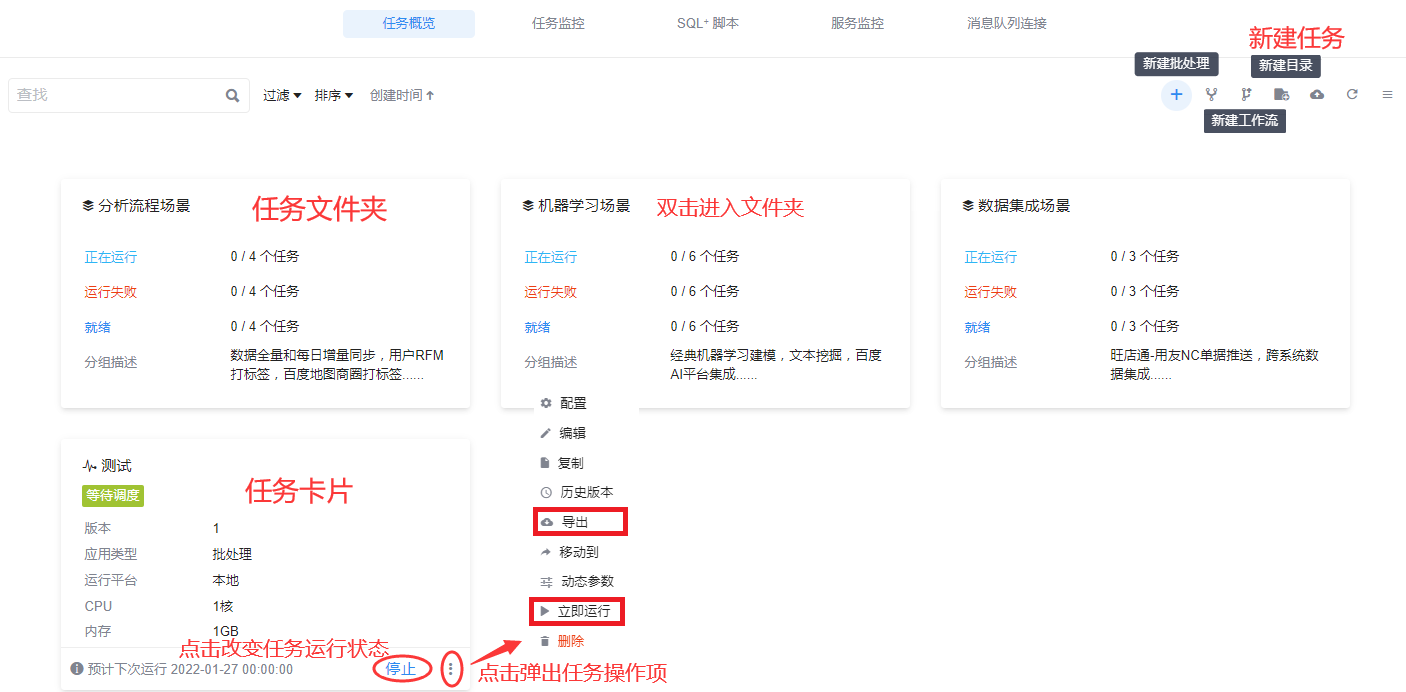
进入菜单“数据流”,默认进入“任务概览”管理页面,点击页面右上方【+】按钮,弹出框选择“批处理”、“流处理”或“工作流”,进入数据流设计页面。用户也可在此管理页面对权限许可的数据流进行分组、运行、编辑、复制、导出、删除等操作。
💡“批处理”即常见的周期性运行任务;“流处理”是实时性任务,资源需要一条永久存在的“管道”,管道前端常接Kafka、Socket等输入;“工作流”是任务流程编排,如执行批处理任务A成功后再执行任务B。
2. 设计批处理任务
2.1 添加输入组件
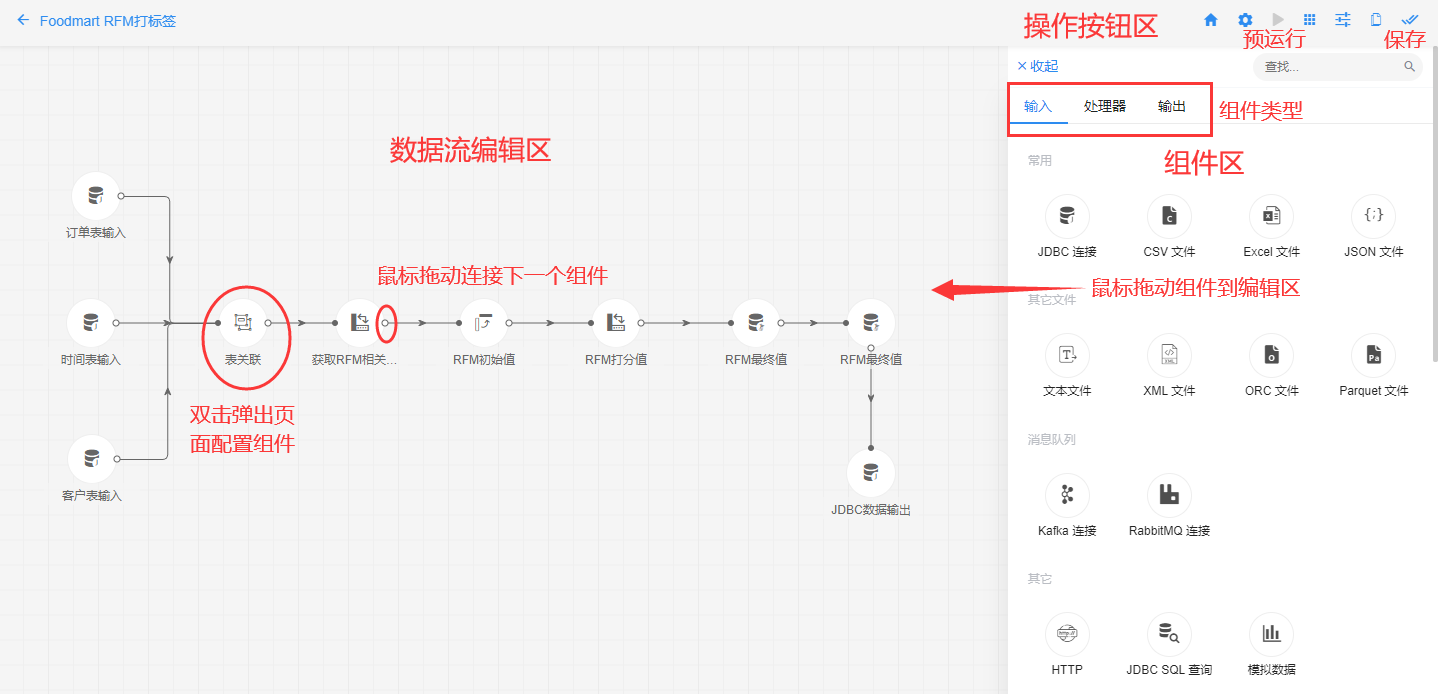
如上图,进入“数据流设计”页面后,左侧是数据流编辑区,右侧是组件区(标签页分为输入、处理器、输出三类组件)。输入组件主要包括数据库、文件、HTTP几种类型。鼠标从组件区拖动1个或多个输入组件到编辑区,完成拖动后双击对应节点,弹出页面设置必要的输入参数即可。
数据库:常见数据库输入如JDBC连接(适用多种数据库),必要配置信息包括“操作名称”(节点名称)、JDBC连接(选择一个已有的连接,配置见“连接您的数据库”)、选择数据库、选择数据表、输出表名(通常采用系统默认值即可),完成点击“下一步”选择需要的字段,完成“保存”或继续“下一步”配置可选项,包括“过滤条件”(where后面带的条件,直接输入表达式即可,如department=A and age>30)、串行或并行读取(串行读取即大量数据时分为几段进行读取)。
💡这里每个节点都会输出为一张内存表作为下一步骤的输入,如下一步骤是手动编写SQL语句,则在select … from中需要引用这里的“输出表名”。
文件:常见文件输入如Excel、CSV、Json输入组件,必要配置信息包括“操作名称”(节点名称)、输入文件(点击“上传”或点击“自定义”填写文件路径)、输出表名(通常采用系统默认值即可),Excel还需选择工作表(Sheet)。高级配置(通常默认即可)还可以配置字符编码、字符处理规则、CSV分隔符等。
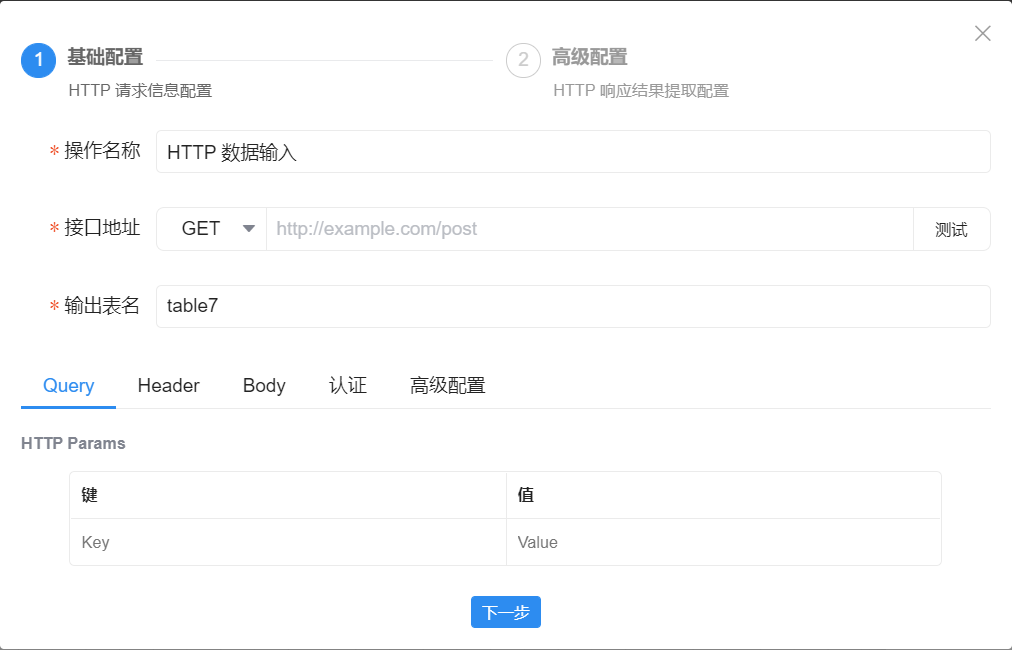
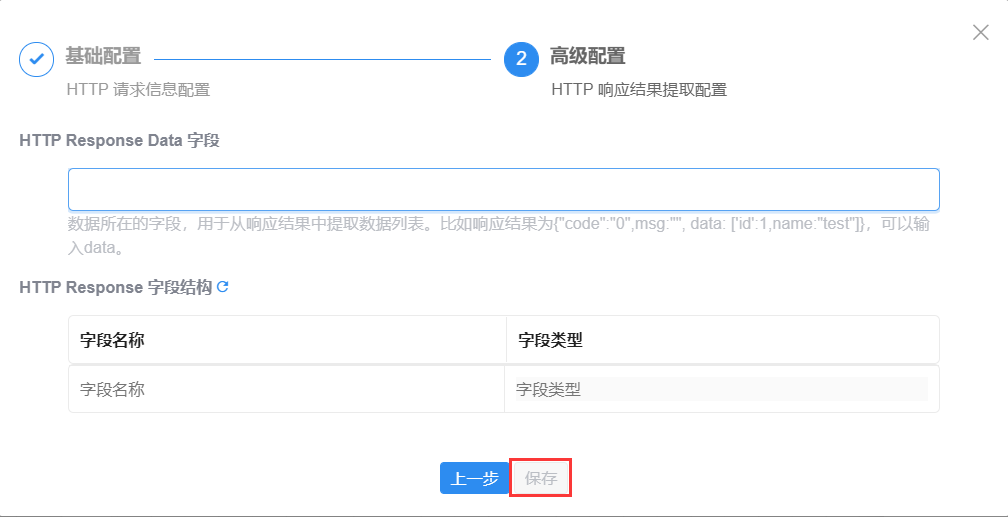
- HTTP:必要配置信息包括“操作名称”(节点名称)、接口地址(选择GET或POST方法并输入具体地址)、输出表名(通常采用系统默认值即可),视对接API要求按“键”和“值”方式填写Qeury或Header参数、并配置认证信息;完成后点击“接口地址”右侧的“测试”按钮,测试成功则点击“下一步”配置HTTP响应结果提取(按提示在“HTTP Response Data字段”中填入返回Json的某个Key名称),最后“保存”即可。
2.2 添加处理器组件
处理器组件主要包括SQL、数据转换、表关联、表合并、表透视、列操作(列选择/列名小写等)、删除重复值、正则处理等。鼠标从组件区拖动1个或多个处理器组件到编辑区,与输入组件进行连线,完成连线后双击处理器组件对应节点,弹出页面设置必要的参数即可。
- SQL组件:必要配置信息包括“操作名称”(节点名称)、输出表名(通常采用系统默认值即可)、SQL语句输入,完成点击“下一步”选择需要的字段,继续“下一步”进行是否有重复字段检查,“保存”即可。
- 数据转换组件:支持用户无需手写SQL语句进行字段选择、过滤排序、列变换、分组聚合等操作和预览。
- 表关联和表合并:支持用户无需手写SQL语句进行跨数据源的join和union操作;其中表关联需要配置1个或多个关联字段,并在“下一步”选择结果表字段,继续“下一步”系统进行重复字段检查。
- 正则处理:支持用户指定输入列和选择正则表达式(内置不满足则手写表达式)对符合内容进行抽取、替换、拆分为或列等操作;其他必要配置信息建议采用默认值即可。
2.3 添加输出组件
输出组件与输入组件类型和操作基本一致,主要区别在于需要指定“输出模式”,如JDBC输出支持“追加数据”、“重写数据”等模式。另外注意JDBC输出支持“表不存在时自动建表”功能,用户仅需输入新的表名即可;若表已存在且输出模式不是“重写数据”,则需要输出字段和表字段一一匹配。💡用户修改“输出模式”为“重写数据”时,务必确认“输出表名”确实是需要覆盖重写的表。
2.4 (可选)节点预运行
点击流程“编辑区”某个组件节点,再点击界面右上方第三方操作按钮【预运行】,输出该步骤的结果预览数据,可用于检查上一步骤的输出或根据预览结果设计下一操作步骤。预运行默认加载1000条预览数据,有特殊需求可点击右上方第二个操作按钮【预运行配置】选择数据采样或全量加载(非必要不推荐)。
2.5 (可选)动态参数设置
SQL组件手写SQL语句或HTTP输入组件的Qeury/Header参数,支持“@参数名”引用动态参数,点击界面右上方第五个操作按钮【动态参数】,弹出框中可查看系统内置的时间参数,或在“自定义”中填入参数名称、选择类型为“常量”或“JDBC查询结果”、填写参数值(JDBC查询则点击旁边输入按钮打开SQL编辑器)。
💡另外输出组件中的“变量输出”组件也是动态参数功能的范畴,可作为后续流程的输入。
2.6 任务保存和运行设置
数据流程设计完成,点击界面右上方【保存】按钮,弹出框中填入任务名称,选择日志级别,并按需要配置调度参数、运行参数和消息通知。
- 调度参数:设置任务运行开始时间、结束时间(通常留空)、调度模式(时间驱动或Cron调度,时间驱动填写调度间隙,Cron调度手写Cron表达式),并按需设置任务运行失败重试规则。
- 运行参数:设置该任务最大运行资源(不等于实际占用),默认为1个CPU核和1G内存(注意任务加载数据量较大时需要调大最大内存配置,处理数百万条记录时建议设置至少4G内存)。
- 消息通知:设置任务运行成功或失败时推送消息到企业微信群或钉钉群。
3. 设计任务流程编排
任务流程编排即对有依赖关系的任务进行流程编排,对应创建任务时的“工作流”任务类型。
任务编排与“数据流设计”界面和操作类似,左侧是编辑区,右侧是组件区(标签页分为控制、任务、功能三类组件)。鼠标从组件区拖动组件到编辑区,进行组件参数配置和连线即可。
- 控制组件:包括开始和结束组件,这两个组件必选。
- 任务组件:该组件用于调用批处理任务,通常需要多个有依赖关系的任务组件进行连线,必要配置包括选择对应的批处理任务、设置触发规则(任务依赖关系如“所有依赖任务运行成功才触发”)、按需配置超时和重试规则。
- 功能组件:包括休眠组件(设置休眠时间)、Bash脚本、Python脚本等。

若有收获,就点个赞吧
0 人点赞
