序列比对
基本介绍
北京大学生物信息学网课
两条序列比对,:表示比较相似,.表示不太相思,|表示一致,空表示有gap,也称indel(insert/deltion,因为一个是插入另一个就是删除)

左右两边数字是这一段所处的序列位置,不是分数。最后分数=blosum62的分数相加+空位罚分,第一个空位罚10,延申0.5。
这里给的是最后的比对结果,并没有说过程
动态规划
全局比对 Needleman-Wunsch算法
如果采用枚举法来进行比对,两条n长的序列。最极端的align就是都比对到空位,全长2n,那么可能数就是2n长里面找n个空位,最好的就是n个里面找0个空位。总共可能性就非常多,1088,不能枚举

动态规划就是局部最优解加当前最优解,一直下去就能得到最后全局的最优解。横向走就意味着要加空位罚分,斜向就是比对的分,每个空里面其实会有三种结果(从左上角三个格来的)但是取最好的写上去,并且带上箭头表示从哪来,要是最好的有多种来源就会有多个箭头,然后算到最后的最大值回溯回去得到了比对结果。所以也可能同样分有多种比对结果。

局部比对 Smith-Waterman算法
相比于全局比对,局部比对就是在三种可能上再加一种,0,也就是之前三种要是分数小于0了就算终止,从这开始新一次局部比对。


仿射空位罚分
之前横向纵向都直接+d,也就是所有gap一视同仁,但不应该。所以需要区分gap的状态是open还是extension。用MXY三种状态表示:M表示非gap,X表示序列X对上了gap,Y表示序列Y对上了gap。也就是将原来的三种情况多标注了一个状态。



时间复杂度
穷举法是指数时间,动态规划是平方级,即两条序列长度相乘,因为有这么多个空格需要填,O(mn)。
FASTA算法
原理
youtube链接 ppt链接
开始有了k-tuple的概念,需要exact match,通常蛋白选2aa,DNA选6nt。
BLAST
原理
动态规划将需要填充的格子数变成了mn,blast就是将需要填充的格子数变得更少,猜出最优解的大致区域,填周围格子。
用k-mer先匹配,再延申。如下图,每个点代表k-mer对上了,最优的应该大致平行于主对角线,于是非主对角线的匹配就不要了,只允许沿主对角线的有两个及以上的hits的hits cluster,而后对他们进行延伸,延申靠smith-waterman算法,低于某个值就不再延申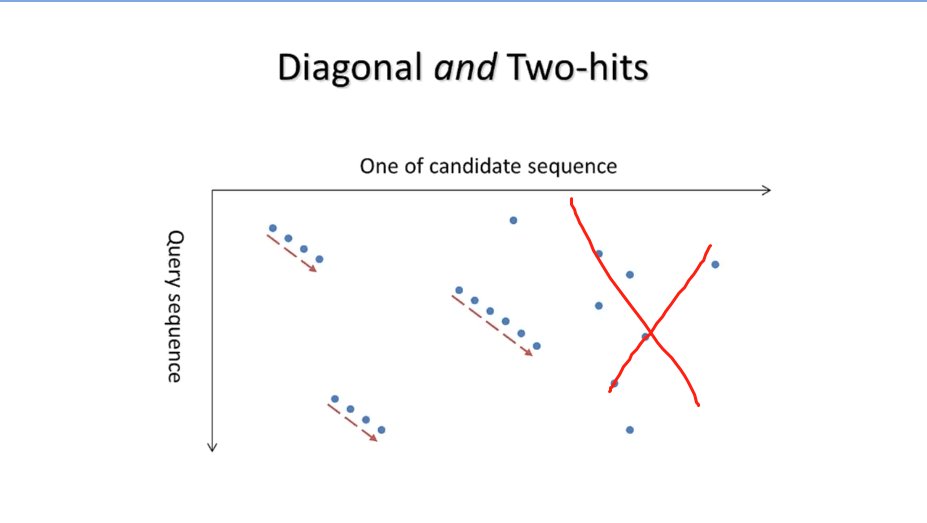
看youtube视频的总结
如何快速匹配到kmer?
以query对database的其中一条序列做align举例。
将db的序列也切kmer,并且将kmer的字母独一无二的数字,每种kmer都有对应数字,例如ATCG分别为0123,那么“GTAC”的kmer的数字可以为34^3+14^2+04^1+24^0。然后将target的kmer按大小排序,建立一个二分的树,在对query的每一个kmer进行检索的时候就可以快很多。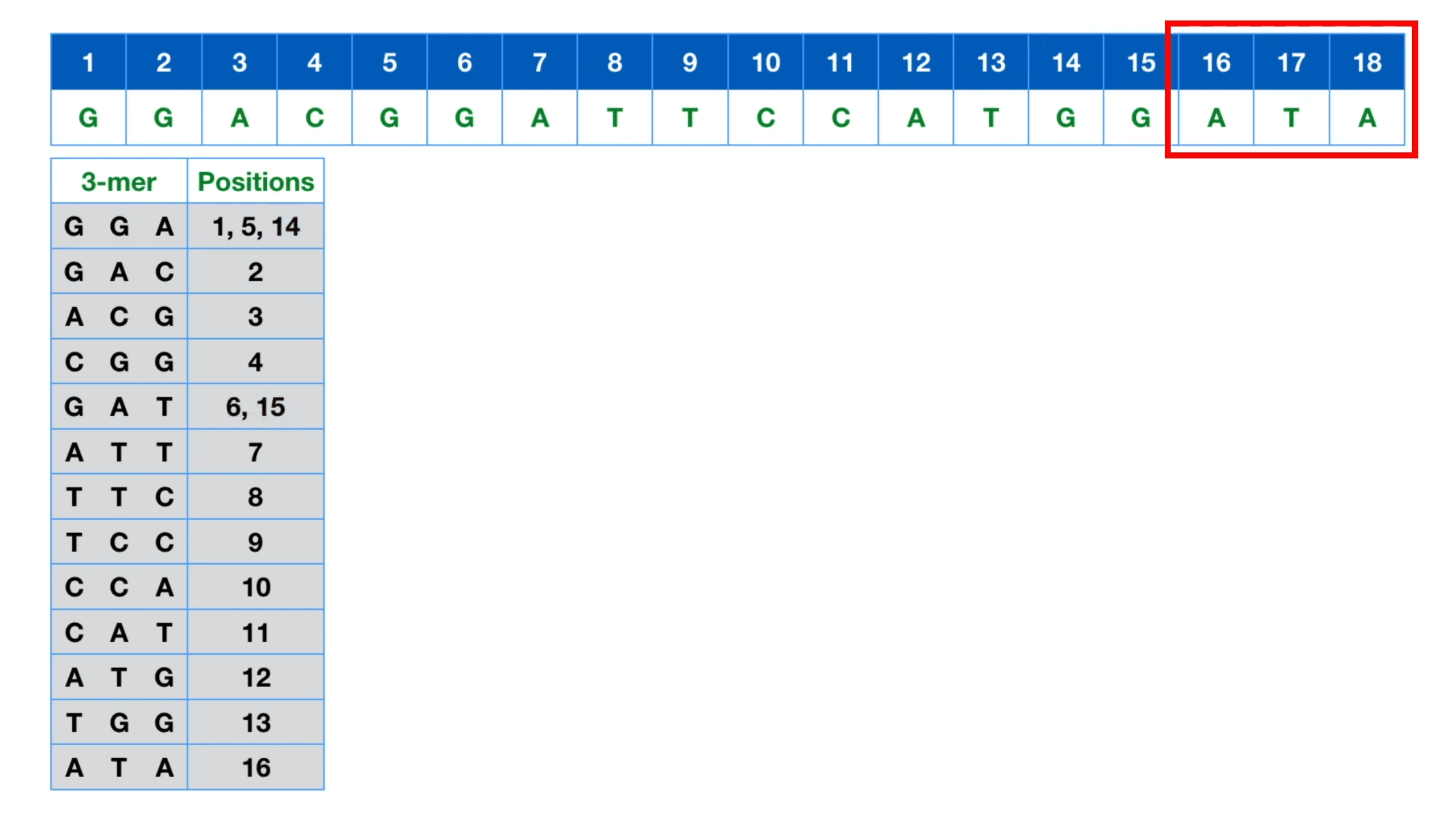
建立target的kmer索引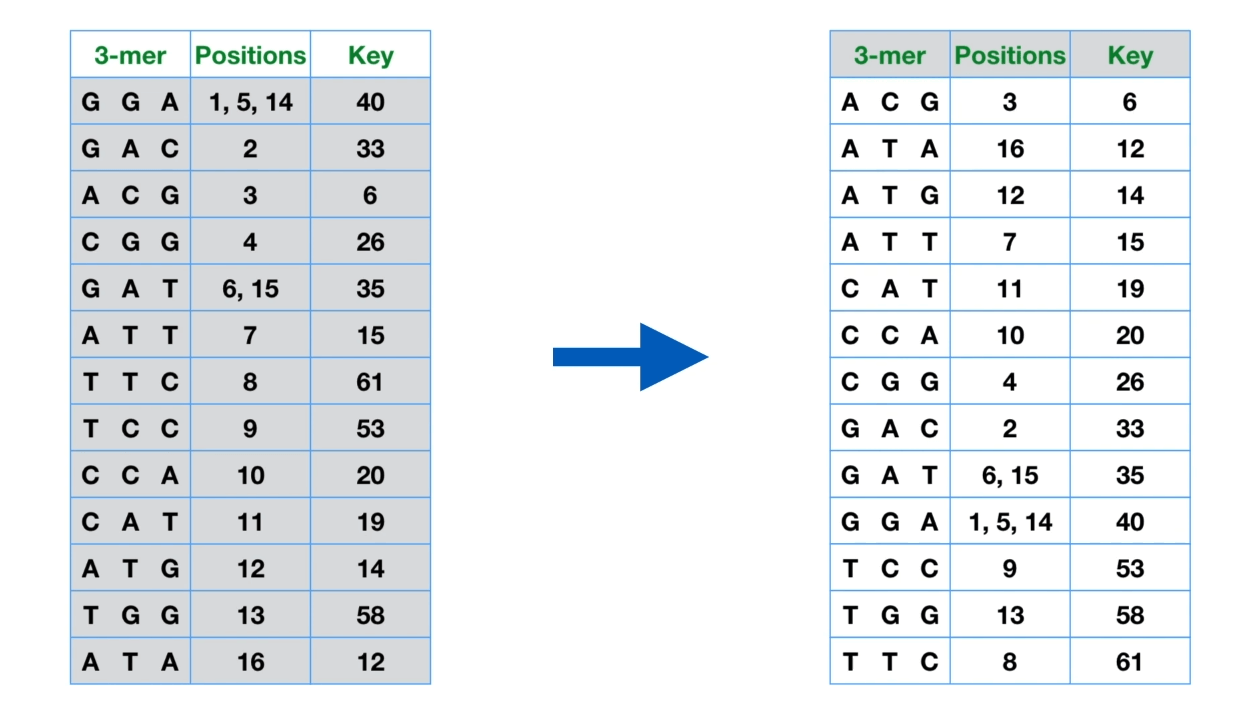
将kmer变成数字并排序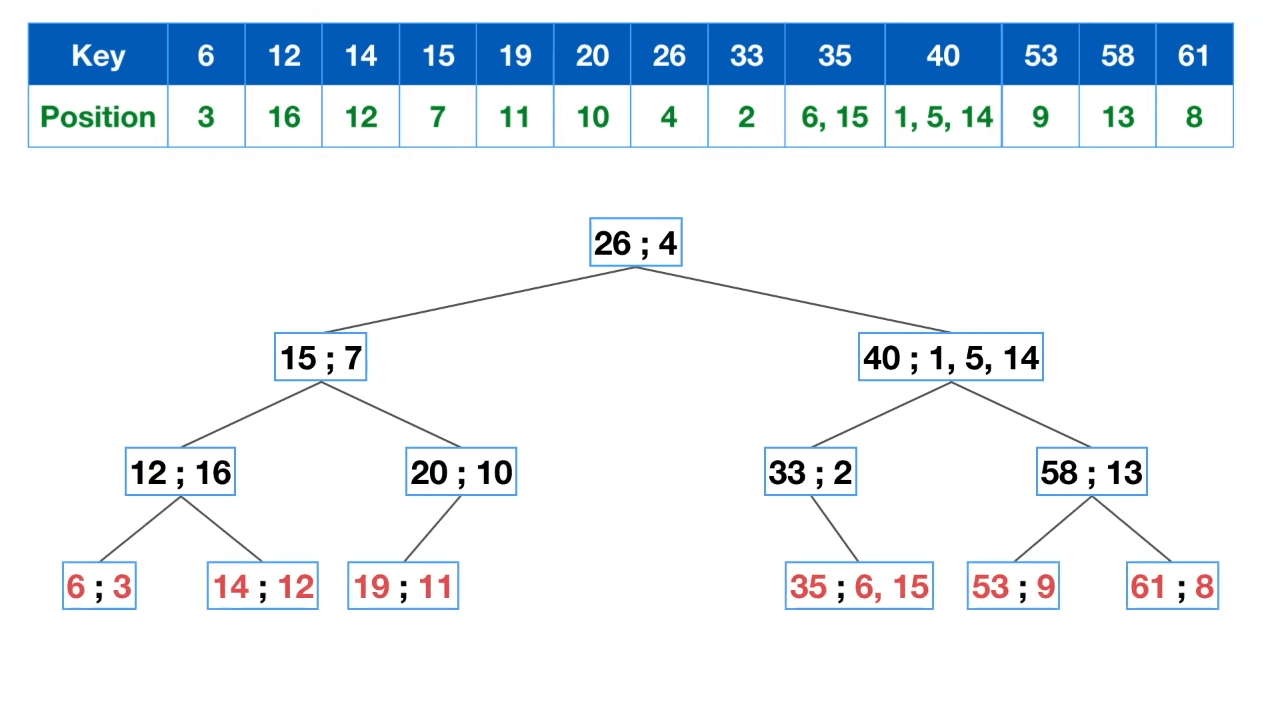
建树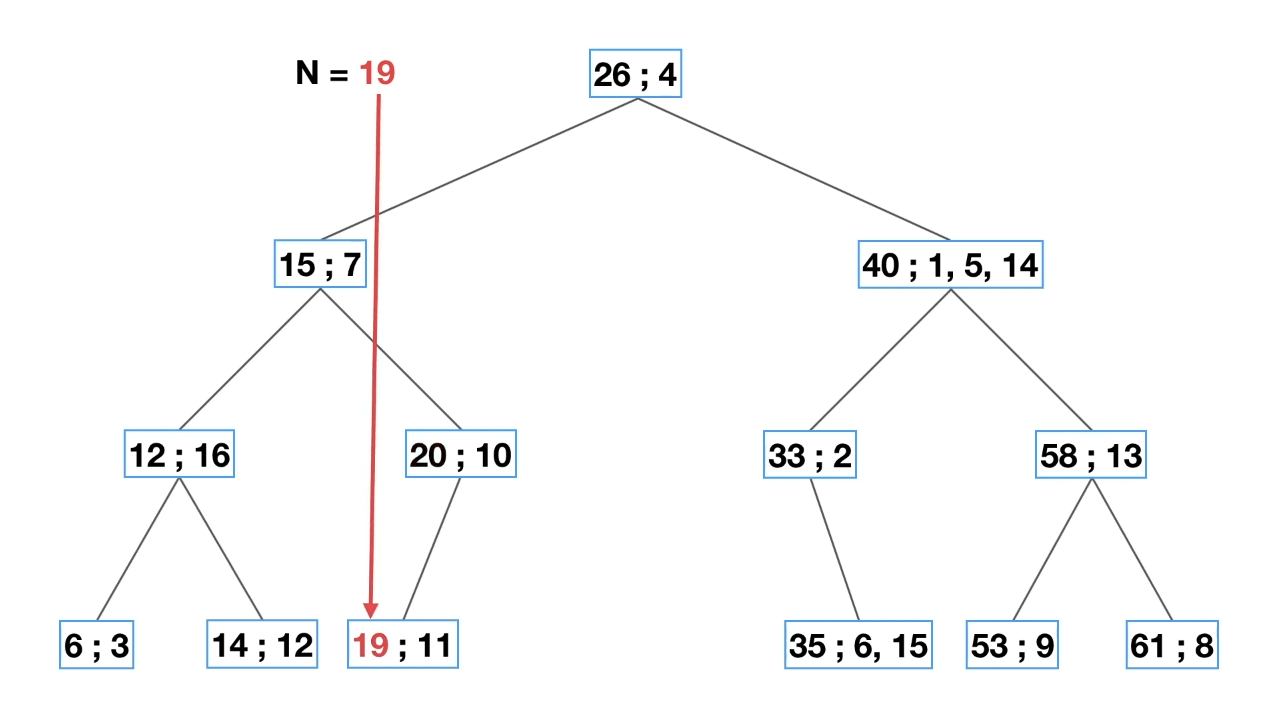
对于query的一个值为19的kmer,只需判断三步就找到index
加速
- 屏蔽掉了低复杂度的序列,例如CACACA。因为这种的种子搜出来也不太能用?k=6时如下计算出K为0.36,太小从而屏蔽掉
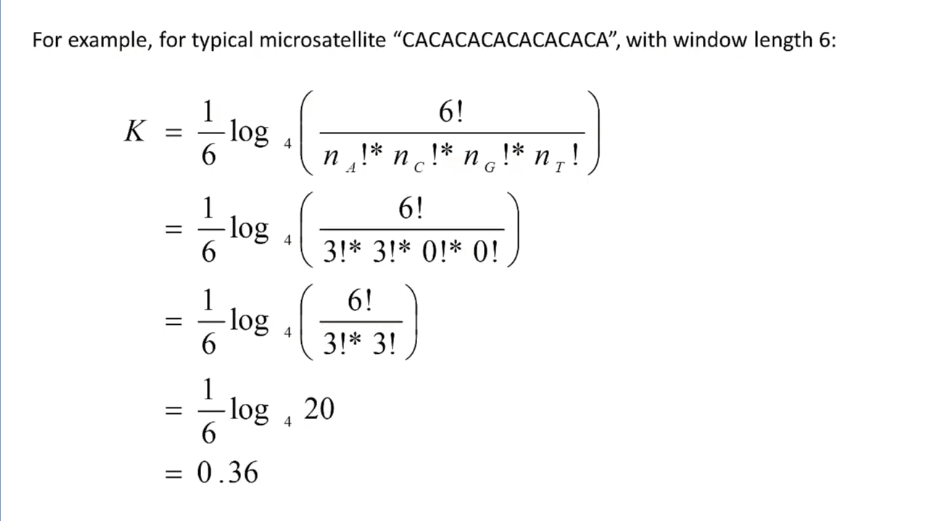
- E-value就是指随机碰上match的数目,所以越小越好。不是概率,可以大于1。例如E可以等于10,说明有十条是随机碰上的。式中S表示匹配的分数,m是query长度,n是数据库大小,k和λ是个factor可以先不管,也就是如果S越大越不可能是随即碰上的。

总结
BLAST是一种启发式的算法, 也就是说,它并不确保能找到最优解,但尽力在更短时间内找到足够好的解。
具体来说,BLAST通过应用Seeding-and-extending策略,只在有限区域应用动态规划算法, 从而有效地降低了计算量、提高了计算速度。
filter
blast的filter是过滤query,把CACACA这种过滤掉,而不是过滤targetdb
seed
就是k-mer的概念,取多少相似的种子算匹配上取决于t值,一个threshold。
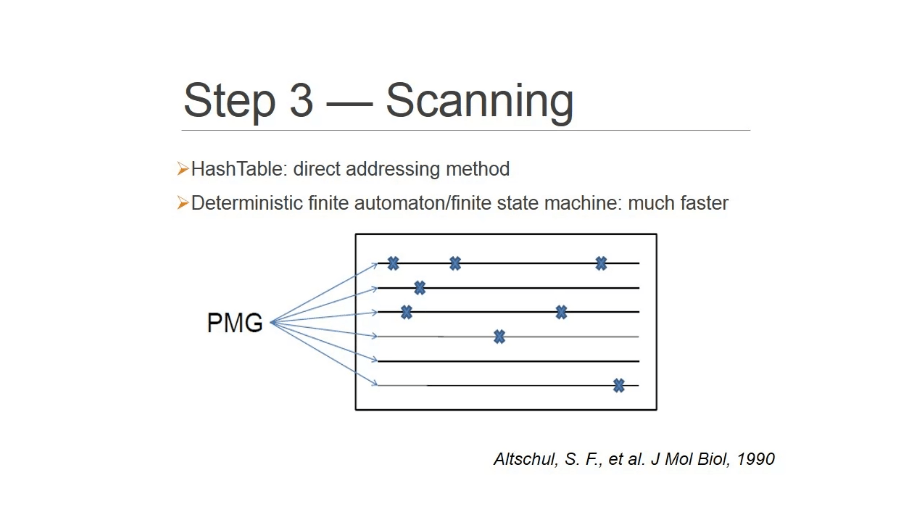
scaning
两种方法
- 哈希表,设定键值
- 有限自动机:记录状态?这个是提升速度的关键,不懂
extension
延申,也有阈值,是s,high score segment pair(HSP/HSSP)。
相似度高其实不代表同源性。
打分矩阵

PAM

BLOSUM
也是构建出MSA,可以直接数出mismatch(Pab)和本底频率,比一下取合适log能够变整就ok。
E值和S分


PSI_BLAST
基本原理
多轮搜索,第一轮就是普通的blast搜索,匹配出来的东西产生MSA后,根据每个位置aa出现的频率等因素构建出一个position-specific-score-matrix(PSSM,或者叫profile),将这个shape为L×20的矩阵替换掉原来20×20的成为新的打分矩阵,再进行blast。那么也就是依旧是这个序列去blast只不过打分矩阵换了。
如何构建PSSM
构建MSA
其实就和之前构建BLOSUM62等东西类似,只不过那时候用的alignment固定了,现在用的alignment会根据第一遍blast的结果(使用gapped blast)而生成称为M,且做了98%去冗余以及把那些需要向query插入gap的target seq删了,保证alignment长度和query一致。且每一列的alignment不一样,称为MC(M column),需要所有序列在那一列不为gap,但是在其他地方可能是有gap的。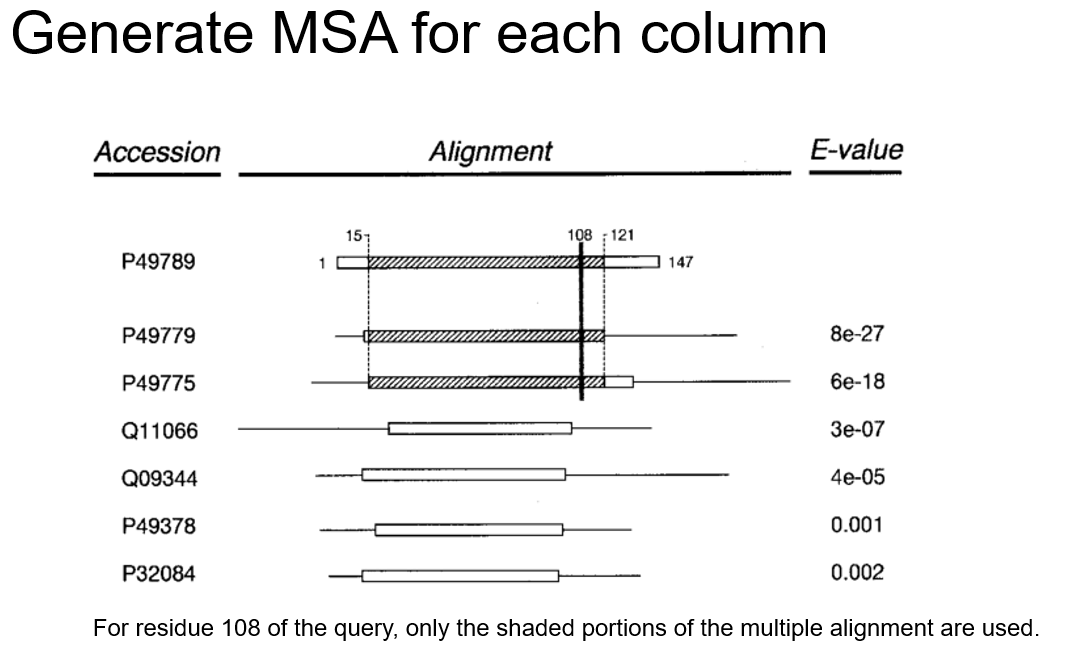
PSSM里面的分数由来
组合了两个部分,一个是两残基间本质上容不容易被替换(gi),另一个是在这个sub alignment里面出现的概率(fi)。
fi
observed residue frequencies,是在这个sub alignment里面出现的概率,且是加权重后的。(我猜测fi就是只算在那一列出现的概率,乘以权重。构建Mc只是为了算每条序列的权重以及NC)文章对如何算observed residue frequencies没有做过多解释,只有一句加权重的描述。
In speaking of a column’s observed residue frequencies fi, we shall henceforth mean its weighted rather its raw frequencies
qij
这是两个残基间能被比对上的一个概率值,其物理意义就是两个残基本质上像不像,公式如下。Pi和Pj是两个残基出现的本底频率,λu其实就是ungapped下的λ,sij就是替代矩阵里的分数。由于λ的理论基础就是用的ungapped,所以针对gapped其实没有一个理论值,但是作者认为只要the gap costs used are sufficiently large,gap和ungap的λ就差不多。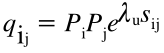
1. gi
其实被称作pseudocount frequencies,作用大概就是保持一个基础值?它是根据上面从替代矩阵里的来的qij,然后对每种ij组合加上一个权重,j出现频率比自然出现的本底频率要高的权重就更大。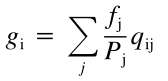
2. Qi
Qi就是残基i在这一列出现的概率。α为NC-1,也就是MC去重后的的条数。β就看你想让两残基间的本质关系占比多大了,他们认为是10的值比较合理。NC就是个0-21的值,感觉基本上如果是比较相像的就会小于10,比较多不像的就大于十,权重差距没有太大。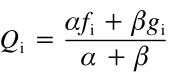
3. score
算分数就是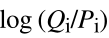 ,后面又补充到是
,后面又补充到是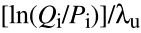 ,这其实就是做一个相对不同打分矩阵的标准化。其中这个λu取决于算qij时用哪个替代矩阵的sij,比如用的BLOSUM62就用那个的。
,这其实就是做一个相对不同打分矩阵的标准化。其中这个λu取决于算qij时用哪个替代矩阵的sij,比如用的BLOSUM62就用那个的。
如何去重
对所有序列一视同仁显然不合理,大量相似序列会掩盖那些更不一样的序列所带来的信息。那么如何进行去重,就是如何算一个sub alignment里究竟有多少条即NC,单纯数条数不行。最开始一个简单的想法就是,算出MC的每一列有多少种残基,然后取均值得到NC,但是这样就最大值是21(加上gap),但实践发现大部分都不到21,所以其实这样是ok的。NC的绝对值没有那么重要,重要的是不同column之间的NC的差距。
为什么打分矩阵换成PSSM会使blast更敏感?
suwen:原来的打分矩阵如果要满足大于T值基本上等于要三个里面要两个aa完全match,那么有可能会失去一部分同源的。换成PSSM之后会有那种打分特别高的position完全对应,可能就可以突破这种限制。
我补充:换成PSSM后打分矩阵的分数通常更高的权重给了你得到的MSA里面两个残基可以替换的频率,那么也就是赋予了第一轮找出的那些MSA一些充当query的功能,就可以一拖二二拖四这样。
GAPPED BLAST
首先注意gapped 和 two-hits是两个可以并行的trick,gapped是指在延伸时允许有gap。
起源
原版的blast最开始是会分别找到一条数据库序列里面的好几段局部alignment,这几个没有gap的HSP合在一起的分数加起来达到了被报告出来的要求。那么问题就在于万一少了任何一个HSP这条序列都会遗失掉。
所以这一版的gapped blast就是对HSP再进一步做gapped延申,从而只要找到一个HSP就不会遗失掉这个序列。由于现在只需要找到一个HSP就足够,原来需要找到可能三个才行,那么自然我们可以容忍T值变得更高,例如从11到13。但是不是对所有的HSP都延伸,需要HSP的分数超过一个适中的分数Sg,使得大概每五十条序列里面会有一个HSP被延申。
四个阶段
(针对一条seq,之后就是for循环)
- database scanning。生成hit list,然后去找database的那一条序列有多少hits。
- Calculating whether hits qualify for ungapped extension。two-hit有的部分,需要同一对角线(通过算index相减);hits间距小于A,然后才达标。
- Ungapped extensions。我认为是对第二个hit进行延申,延申出HSP。
- Gapped extensions。在HSP里面找到那个合适的residue pair作为seed,再用动态规划进行延伸。一旦掉落比目前为止的最高分超过Xg就停止延伸,相比之前规定好一个bandwidth这个更因地制宜一点。
two-hits
找hit阶段
two hits。降低T值使similar list变长,然后去扫hit,但是有一个hit并不延伸,需要在对角线上距离A以内有另一个hit才延申,距离是计算hit的头部间距。找hits的过程中可能在同一条对角线上会不止找到一个2个hits,那么当第三个hit出现的时候就会替换掉第二个hit的坐标。延申阶段
one-hit很简单就是无空位延伸成高于Sg的HSP,然后去做gapped延申。
two-hit,赵认为是两个hit中间可以直连,然后向两边无空位延申成HSP,高于Sg就gapped延申。
我认为是不直连,对第二个hit先无空位延申成HSP,高于Sg就gapped延申。
原因是因为看到97年原文有这样一句话的描述。In summary, the new gapped BLAST algorithm requires two non-overlapping hits of score at least T, within a distance A of one another, to invoke an ungapped extension of the second hit.
两个要点
- two hits。降低T值使similar list变长,然后去扫hit,但是有一个hit并不延伸,需要在对角线上距离A以内有另一个hit才延申,距离是计算hit的头部间距。问题是两个hit的话从哪开始延伸?新的那一个的中间?还是两者连线中间,还是直接把两者连起来后往两边延伸。文章里有说The new gapped alignment algorithm uses dynamic programming to extend a central pair of aligned residues in both directions.
-
问题
Sg的选择为什么要选择1/50这样一个概率,这个数值是高还是低?
一些概念
λ and K
这两个常数在计算标准化后的S分数会用到,λ是有关打分函数特性的一个常数,K是有关被搜索的数据库的一个常数。
sensitivity
敏感度。数据库里有1w个应该匹配到的序列,你找到了1000还是5000。也就是找到某一真阳性序列的概率
specificity
特异性,找到的5000条里面,有多少是真阳性 百度文库

哈希函数
定义
哈希函数可以将无限不一定等长的元素的集合,转成有限的固定长度集合,并且通常长度较短,完成这样的转化的函数就可以称为哈希函数。也就相当于提取一个数字指纹的感觉。
那么这样的函数肯定就不是单射的,将原元素称为value,转化后的称为key(也称哈希值,散列值),也就是会有一个key对应多个value,这种现象称为“碰撞”,那么好的哈希函数应该做到尽量少出现这种现象。
值得注意的是安全的哈希函数应当是单向不可逆的,从value可以简单的算key,但是从key到value应当就会花费很大的算力。
哈希表
也称散列表,对于哈希函数,提前建立一个value和key的对应关系的表就成为哈希表
用途
登录系统,人为设置的密码就可以先转为哈希值存到系统中,那么在登录时,也将你输入的字符串转为哈希,去匹配系统中存储的哈希值,错误就登不上。这样可以避免密码泄露等
- 快速查找。也是将target都有一个哈希值,query也生成一个,比对就好了,可以避免转化前直接比对发现比对到最后一个字符才发现不对,白白浪费算力
- 均衡分配

若有收获,就点个赞吧
0 人点赞
