操作数栈概述
- 每一个独立的栈帧除了包含局部变量表以外,还包含一个操作数栈,也可以称之为表达式栈(Expression Stack),栈结构
- 操作数栈,在方法执行过程中,根据字节码指令,往栈中写入数据或提取数据,即入栈(push)和 出栈(pop)
- 某些字节码指令将值压入操作数栈,其余的字节码指令将操作数取出栈。使用它们后再把结果压入栈,
- 比如:执行复制、交换、求和等操作
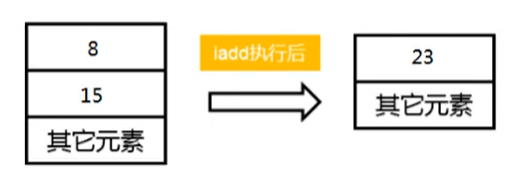
操作数栈的作用
- 操作数栈,主要用于保存计算过程的中间结果,同时作为计算过程中变量临时的存储空间。
- 操作数栈是基于数组实现的,但是不能用索引访问,只能通过出栈入栈操作。
- 操作数栈就是JVM执行引擎的一个工作区,当一个方法刚开始执行的时候,一个新的栈帧也会随之被创建出来,这时方法的操作数栈是空的(这个时候数组是创建好并且是长度固定的,但数组的内容为空)
- 每一个操作数栈都会拥有一个明确的栈深度用于存储数值,其所需的最大深度在编译期就定义好了,保存在方法的Code属性中,为maxstack的值。
- 栈中的任何一个元素都是可以任意的Java数据类型
- 32bit的类型占用一个栈单位深度
- 64bit的类型占用两个栈单位深度
- 如果被调用的方法带有返回值的话,其返回值将会被压入当前栈帧的操作数栈中,并更新PC寄存器中下一条需要执行的字节码指令。
- 操作数栈中元素的数据类型必须与字节码指令的序列严格匹配,这由编译器在编译期间进行验证,同时在类加载过程中的类检验阶段的数据流分析阶段要再次验证。
另外,我们说Java虚拟机的解释引擎是基于栈的执行引擎,其中的栈指的就是操作数栈。
操作数栈代码追踪
分析
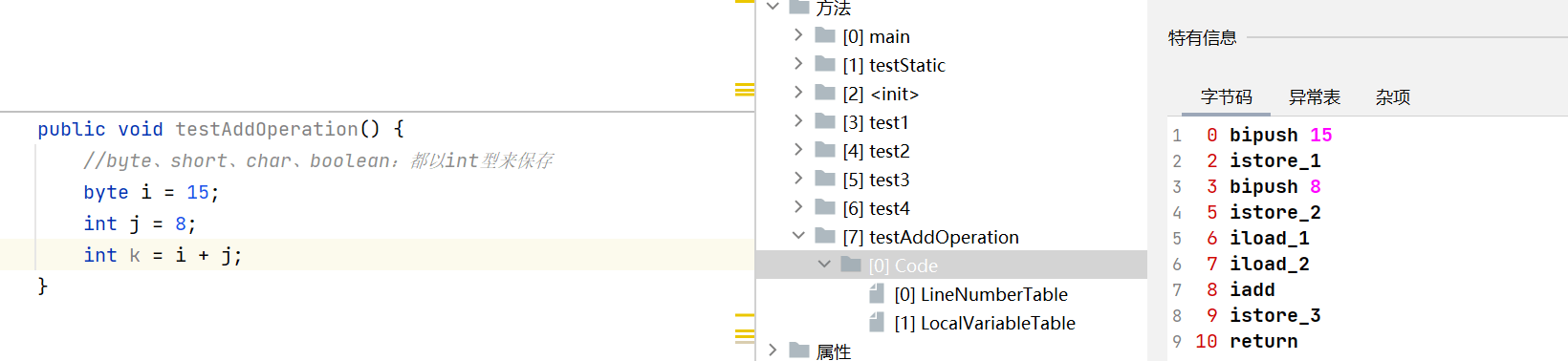
首先执行第一条语句,PC寄存器指向0,也就是指令地址为0,然后使用
bipush让操作数15入操作数栈,这时候局部变量表什么都没有。每一行执行完了,PC寄存器都会更新指向下一行指令的位置,后面就不重复写这句话了istore_1,把15放入索引1的局部变量表,操作数栈15出栈,索引0是thisbipush 8,8入操作数栈istore_2,把8放入索引2的局部变量表,操作数栈8出栈iload_1,局部变量表索引1的变量入操作数栈iload_2,局部变量表索引2的变量入操作数栈iadd,操作数栈都出栈,进行加法运算,这里是通过执行引擎编译成机器语言,CPU进行的四则运算,得到结果,结果入操作数栈istore_3,把算出的结果放入到索引3的局部变量表中,操作数栈结果出栈return,方法结束,void默认有一个return入栈和存储的数据类型转换

- 因为 8 可以存放在 byte 类型中,所以压入操作数栈的类型为 byte ,而不是 int ,所以执行的字节码指令为
bipush 8 - 但是存储在局部变量的时候,会转成 int 类型的变量:
istore_2栈顶缓存技术
栈顶缓存技术:Top Of Stack Cashing
- 前面提过,基于栈式架构的虚拟机所使用的零地址指令更加紧凑,但完成一项操作的时候必然需要使用更多的入栈和出栈指令,这同时也就意味着将需要更多的指令分派(instruction dispatch)次数(也就是你会发现指令很多)和导致内存读/写次数多,效率不高。
- 由于操作数是存储在内存中的,因此频繁地执行内存读/写操作必然会影响执行速度。为了解决这个问题,HotSpot JVM的设计者们提出了栈顶缓存(Tos,Top-of-Stack Cashing)技术,将栈顶元素全部缓存在物理CPU的寄存器中,以此降低对内存的读/写次数,提升执行引擎的执行效率。
- 寄存器的主要优点:指令更少,执行速度快,但是指令集(也就是指令种类)很多

若有收获,就点个赞吧
0 人点赞
