所需软件
- Wind
- Python的运行终端,例如Anaconda中的Jupyter
一. Wind获取批量的年报链接EXCEL
打开Wind之后,通过“新闻-公司公告-沪深股票”进入。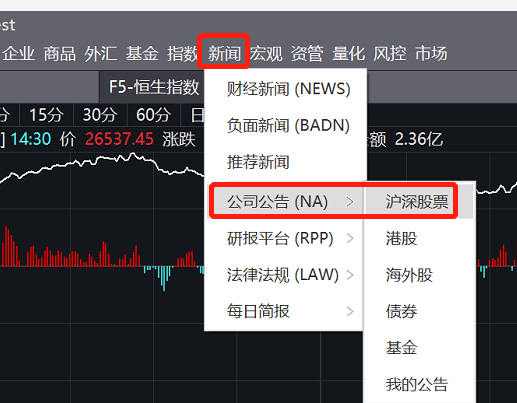
然后,通过“高级搜索”,设置搜索内容,自定义时间“2020-01-01~2020-12-09”,公告类型选择“年度报告”,所属市场选择“全部A股”。然后把进度条往下拉,点击搜索。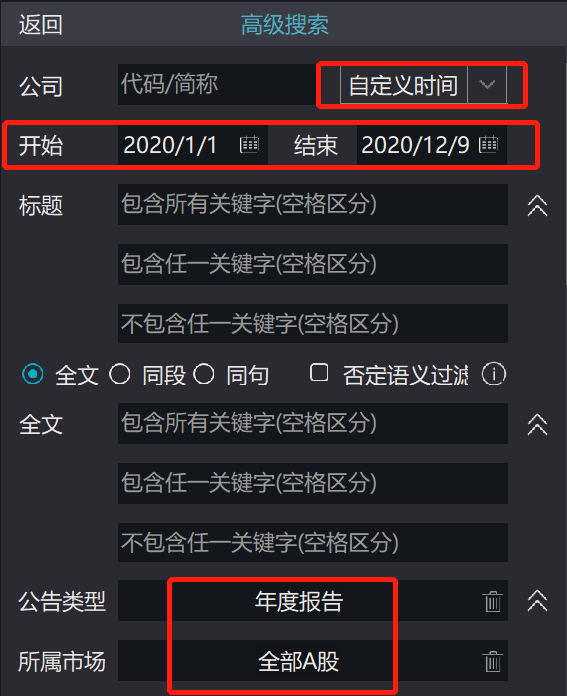
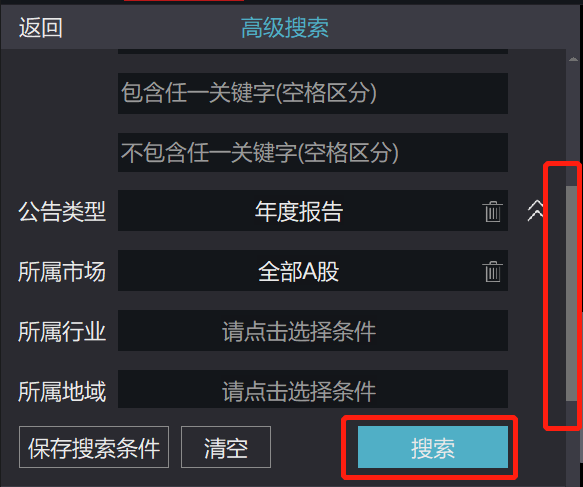
搜索结果在右边出现。那么一共有8370个结果。注意,虽然A股上市公司没有8370家,但是有些公司重复提交了年报,导致结果有这么多。然后我们点击“导出列表”,可以选择存放路径,最多能够一次性提取9999条数据。因此,每次酌情提取。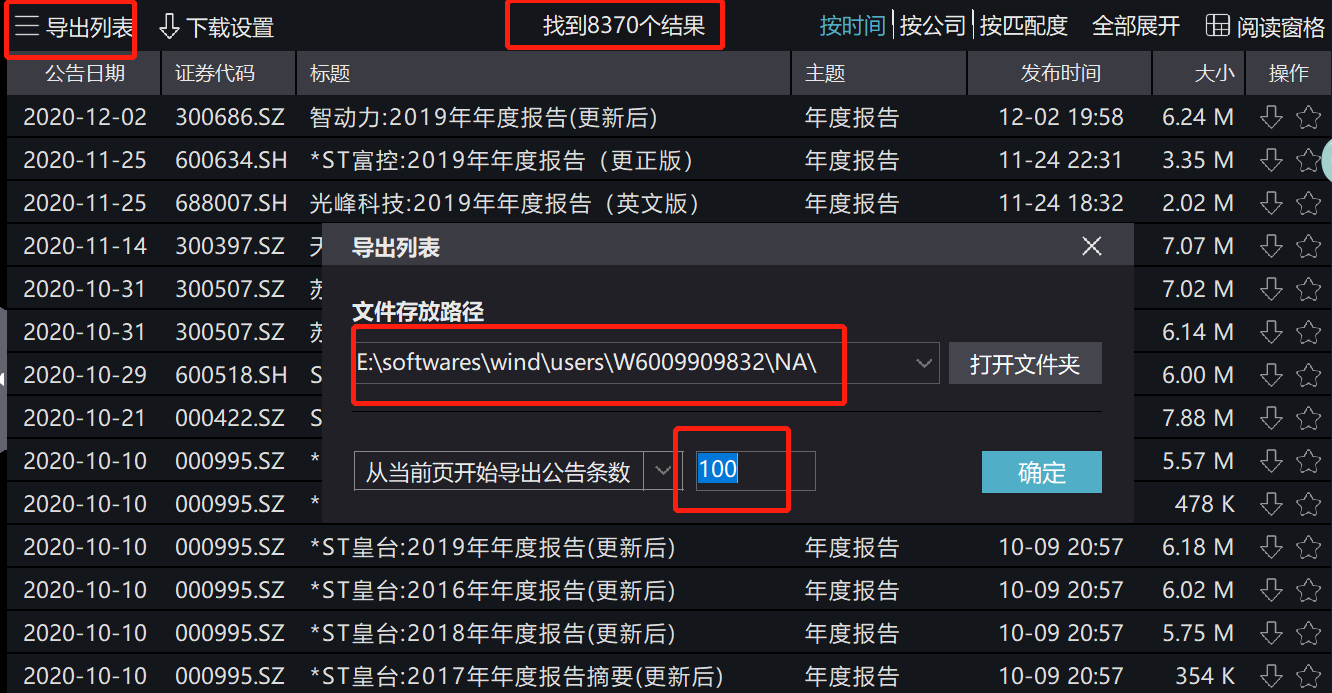
然后,点击“确定”。会提示我们正在下载。
然后,在相应的路径下,得到了存放结果的EXCEL。打开EXCEL,看到存放结果的内容。“公告标题”背后对应了超链接。我们把超链接通过EXCEL自带的函数“=FORMULATEXT”解析为文本,设置为“地址”,那么“地址”列就是解析出来的超链接文本。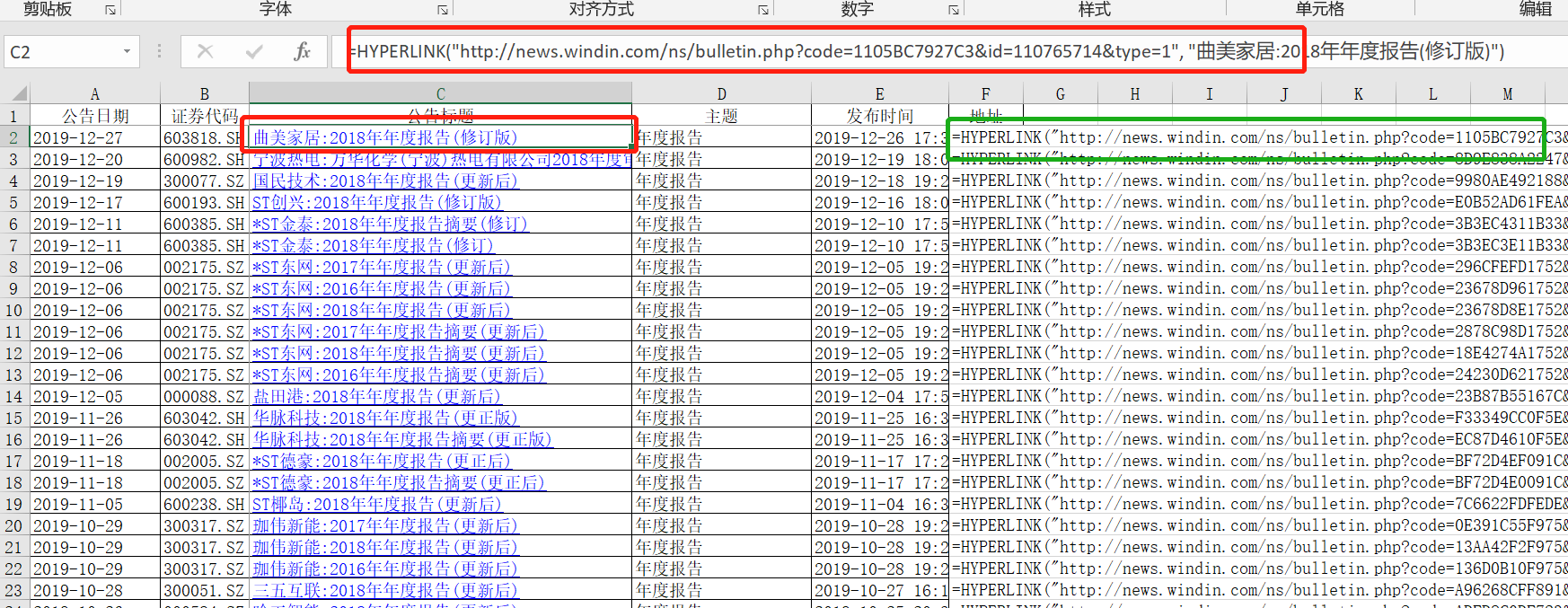
二. Python抓取PDF
在得到了超链接之后,我们使用Python读取EXCEL。
import pandas as pd# 读取Excel,抛弃最后一行没有内容。link = pd.read_excel(r'E:\softwares\wind\users\W6009909832\NA\公司公告2020-12-09.xlsx').iloc[:-1]# 定义函数,提取链接字符def address(str):return str.split('"')[1]link['地址'] = link['地址'].apply(address)
然后,通过requests访问地址,并且把pdf的链接从HTML中提取出来。
import requestsfrom lxml import etreedef get_pdf_url(url):html = requests.get(url).texttree = etree.HTML(html) #解析网页url = tree.xpath('//div[2]/a/@href') #获取PDF链接return 'http://news.windin.com/ns/' + url[0]# 将地址提取出来放到list中,等会儿循环这个listlink_list = list(link['地址'])# 存放pdf的listpdf_link_list = []# 循环list,抓取pdf的链接# 这里可以先试一试enumerate(link_list),因为几千个网页翻一遍时间还挺久的。for i, lk in enumerate(link_list):if i % 100 == 0:print(i)try:pdf_link_list.append(get_pdf_url(lk))except:print('Error: {i}, {link}'.format(i=i, link=lk))
先运行。等到结果跑完之后,再运行下面的代码。
# 如果中间没有报错(我没有发现报错),那么把pdf_link_list合并到link这个dataframe中;# 万一存在链接没有访问成功,得把它从dataframe中drop(可以通过打印出来的位置i将其剔除),然后再运行下面的代码。link['PDF地址'] = pdf_link_list
到目前为止,link看起来是这样的。“地址”是网页版链接,“PDF地址”是下载年报的链接,只要点进去、就会自动下载一个PDF。建议先把这个link保存到本地。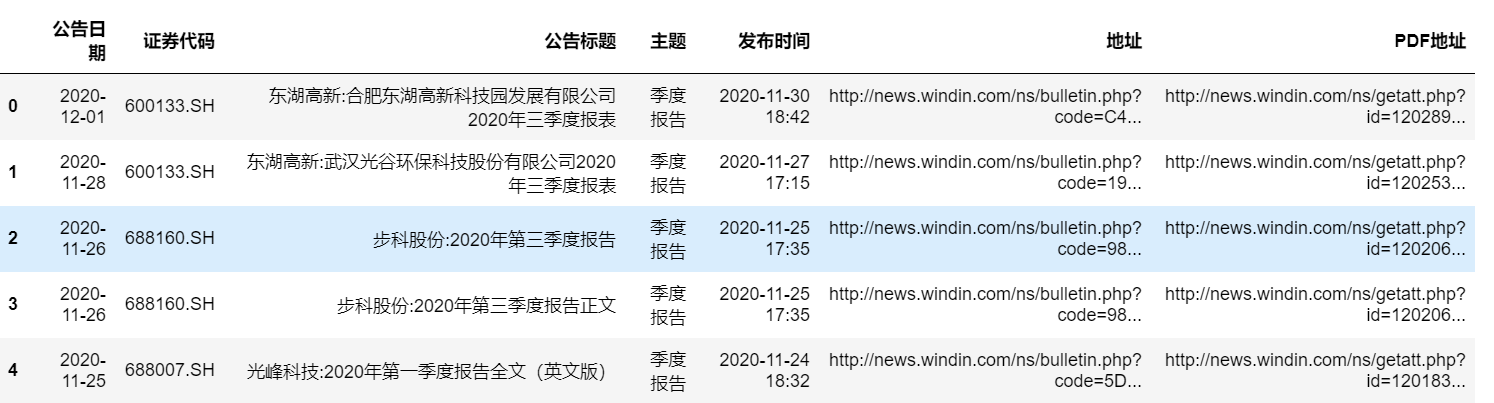
访问pdf的链接,并且保存到本地。
#下载网络文件到本地from urllib.request import urlretrieve# 先把pdf要存的名字拼出来,放到name变量中。link['date'] = link['公告日期'].apply(lambda x: x.replace('-', ''))link['title'] = link['公告标题'].apply(lambda x: x.replace(':', ':'))link['stock'] = link['证券代码'].apply(lambda x: str(x)[:6])# 这样拼写名字的好处是方便我们把出错的链接迅速找出来link['name'] = link.apply(lambda x: '\\' + x['date'] + '_' + x['stock'] + '_' + x['title'] + '.pdf', axis=1)def process(link, home_url):# 我们循环的变量是pdf的链接,pdf的名字,和它在dataframe中的位置。pdf_url_list = list(link['PDF地址'])pdf_name_list = list(link['name'])length = list(range(len(link)))zipps = zip(pdf_url_list, pdf_name_list, length)for url, name, i in zipps:if i % 100 == 0:print(i)try:urlretrieve(url, filename = home_url + name)except:print('Error : {i}, {name}'.format(i=i, name=name))# 开始爬取并储存process(link, r'...\TXT\18')
PS:有一些爬取失败了。可以把运行错误的链接捞出来再爬一次。
import glob
import re
# 到储存所有pdf的路径下,已经抓到的链接是has_been。
pdf_path = r'...\TXT\18'
has_been = glob.glob(r"{}/*.pdf".format(pdf_path))
# 从所有的数据total_df中,剔除已经抓取的链接has_been,即为没有抓取的是has_not,pattern根据链接自己写。
def get_left_df(has_been, total_df, pattern):
has_been_df = []
for url in has_been:
has_been_df.extend(re.findall(pattern, url))
has_been_df = pd.DataFrame(has_been_df, columns=['date', 'stock', 'title'])
has_been_df['tick'] = 1
merge_df = total_df.merge(has_been_df, on=['date', 'stock', 'title'], how='outer')
has_not = merge_df[merge_df['tick']!=1]
return has_not
has_not = get_left_df(has_been, link, r'.*\\18\\(.*?)_(.*?)_(.*?).pdf')
# 再爬一遍
process(has_not, r'...\TXT\18')
以上~

若有收获,就点个赞吧
0 人点赞
