一、介绍
师父最近交给了我一个小项目,爬取银保监会网站的“机构退出列表”的信息。
这个网站神奇的地方是,一级页面中的“机构持有列表”、“机构退出列表”等信息,网址全部都是http://xkz.cbirc.gov.cn/jr/。因此一级页面的网址没法使用。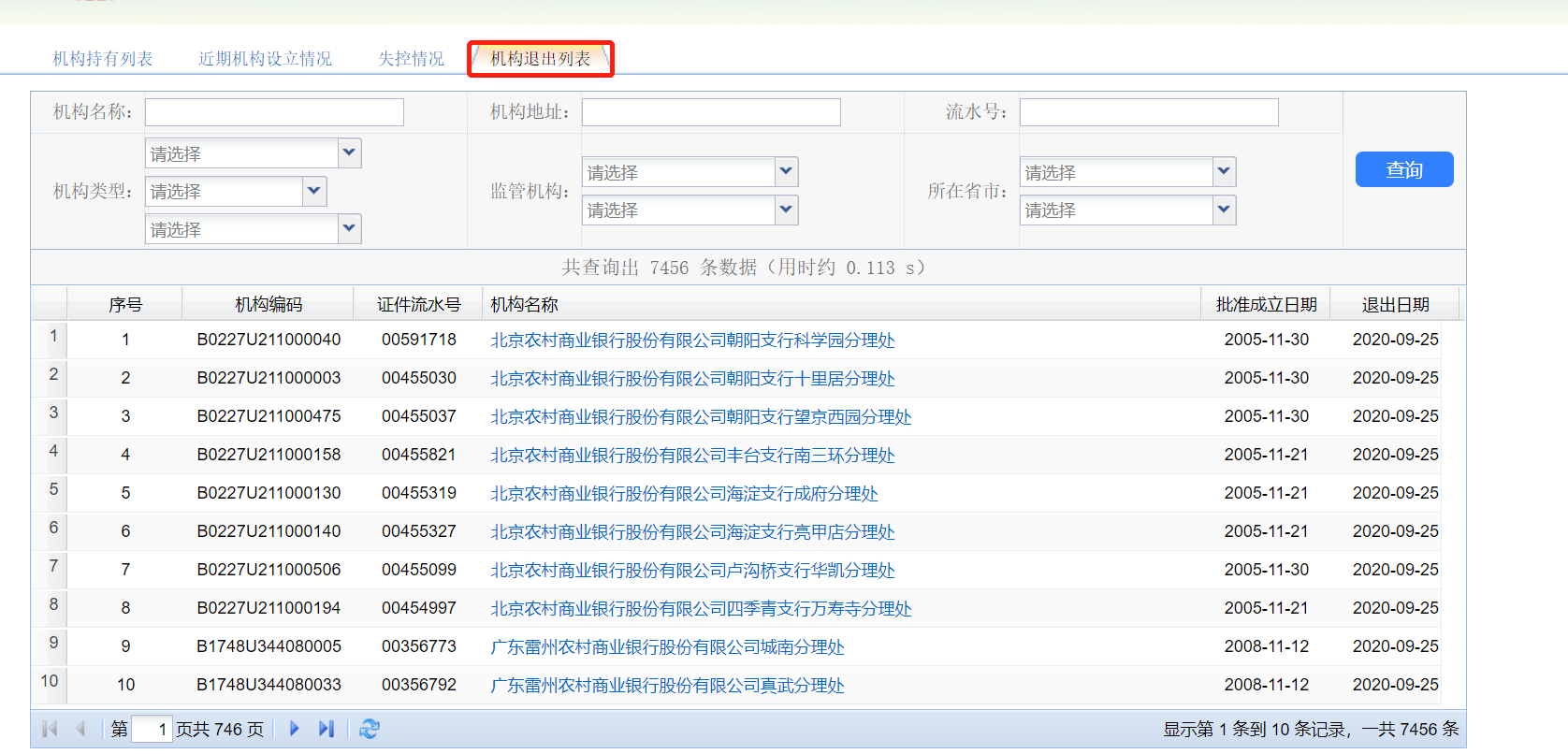
那么如何抓取二级页面的详细信息?
二、网页分析
1. 二级网页网址的分析
随便点开一个二级网页。它的链接是http://xkz.cbirc.gov.cn/jr/showLicenceInfo.do?id=1205。
好的,看起来这个二级链接很有规律,因为出现了id=xxx。
多点开几个网页
http://xkz.cbirc.gov.cn/jr/showLicenceInfo.do?id=160572
http://xkz.cbirc.gov.cn/jr/showLicenceInfo.do?id=3463
那么二阶页面的规律是:
http://xkz.cbirc.gov.cn/jr/showLicenceInfo.do?id={}
我们只需要往里面填充id就可以了。
当然,这个页面会碰到验证码。。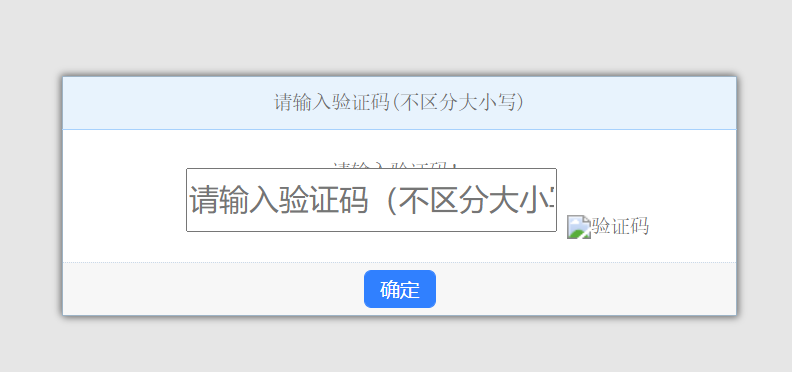
那么碰到这个纸老虎,我们只需要多刷新几次(对应到代码中就是多次运行requests.get(url),直到html中不含有验证码即可),就可以把这个验证码刷掉了。
2. 二级网页的HTML的分析
主要是这句话,控制了整个表格。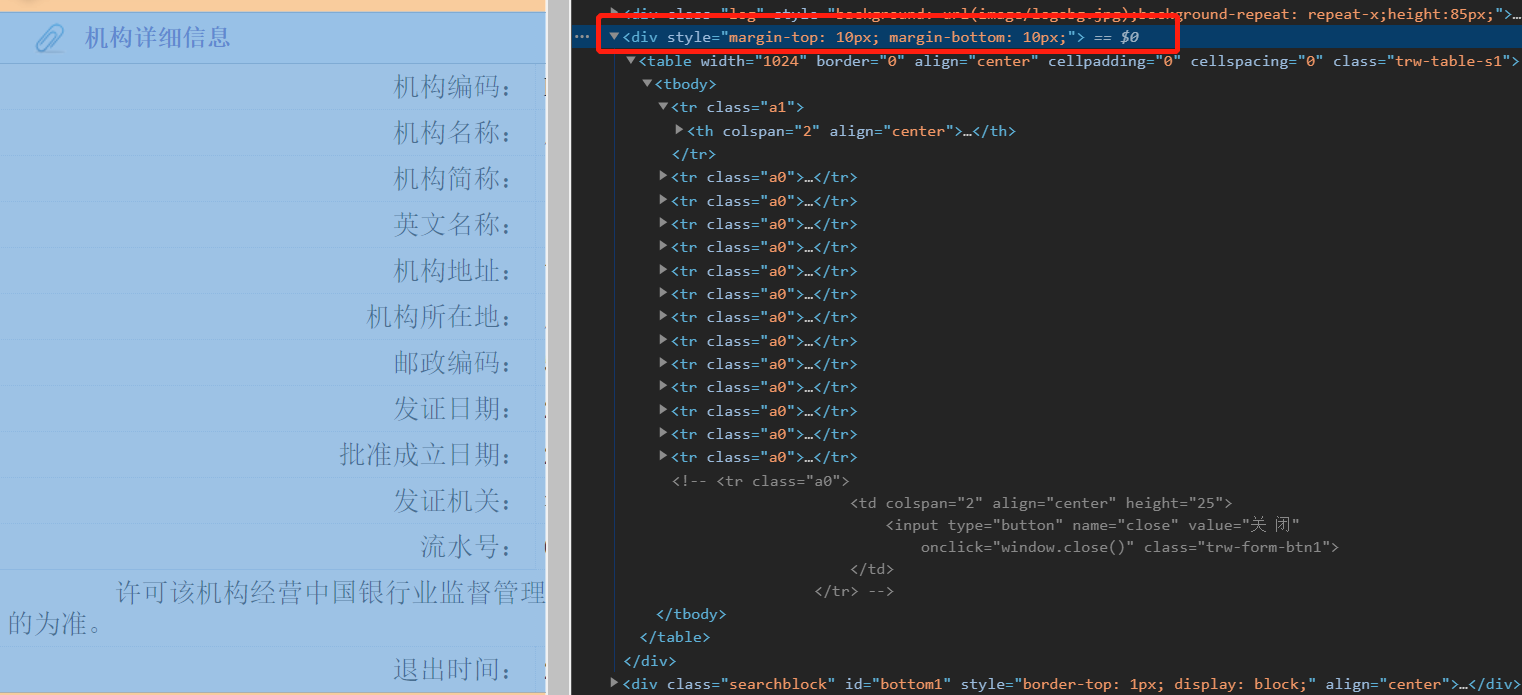
那么在html中(ctrl+u),对应在
那么基本网页已经解析。
表格中的每个元素的定位:.//table[@width=”1024”]//tr[@class=”a0”]//td//text(),从而能够抠出每个class=a0部分的中文字符,再清洗一下,得到了网页中整张表格的信息。
三、爬取流程
这个网页比较特殊,因为它是post获取方式,因此,我采用的笨方法是,把id从1~24万一个一个循环,填充到链接中,然后爬取二级页面的信息;在爬取前首先判断是不是①网页有没有成功打开(至少要含有“机构信息”在网页中)、②有没有验证码(如果html中出现了验证码,那么一直刷到验证码消失)、③是不是我要的“退出机构”的信息(以上两步通过了之后在判断“退出”是不是在HTML中)。
由于网页太多,这里采用了多线程的方式。因此,这里需要使用queue将所有的id装在里面,然后一个一个爬取,同时把失败的id再扔回到queue中,留着以后再处理。
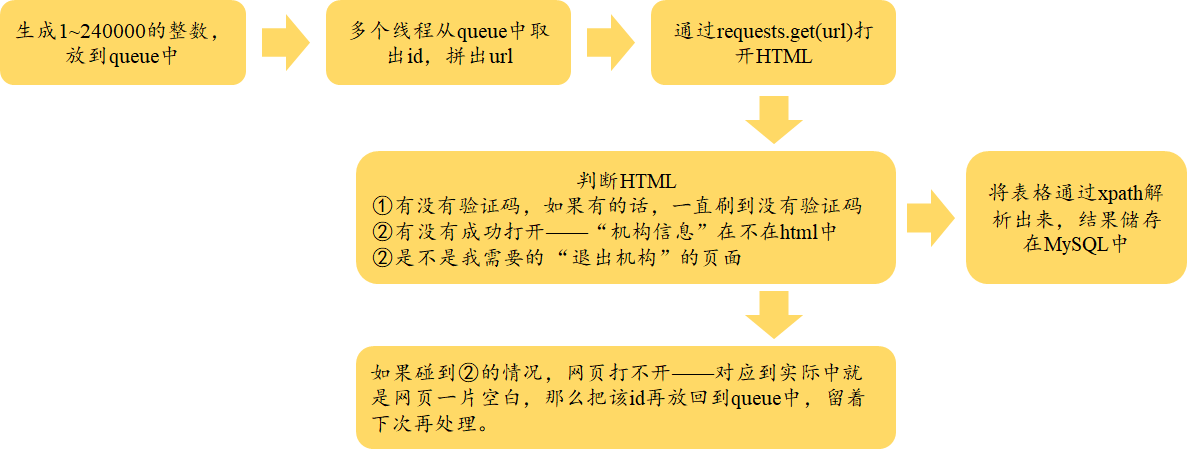
以上就是我处理的方式。
四、具体的代码
import pandas as pdimport requestsfrom lxml import etreefrom itertools import compressimport threadingimport timefrom queue import Queuefrom sqlalchemy import create_engineimport pymysqlfrom sqlalchemy.types import VARCHARpymysql.install_as_MySQLdb()# 用于多线程中存储idtotal_queue = Queue()numbers = 0# 用于多线程存储爬取结果————MySQL支持多线程的存结果。def df_to_sql(df, root, pw, db, name, idntt):basic_url = 'mysql+mysqldb://{root}:{pw}@localhost:3306/{db}?charset=utf8mb4'.format(root=root, pw=pw, db=db)engine = create_engine(basic_url)conn = engine.connect()df.to_sql(name, conn, if_exists='append', dtype={idntt: VARCHAR(df.index.get_level_values(idntt).str.len().max())})conn.close()passdef get_html(url, decodes='utf-8'):rsp = requests.get(url)html = rsp.content.decode(decodes, 'ignore').replace('\t', '').replace('\n', '')return html# 解析网页def get_dom(html):dom = etree.HTML(html)list1 = dom.xpath(r'.//table[@width="1024"]//tr[@class="a0"]//td//text()')list2 = [item.replace('\r', '').replace('\xa0', '') for item in list1]return list2# 将结果整理为dfdef get_info(list_info, id_num, index):# 通过compress,将指定位置的元素储存起来,放到list1中。position_list = [0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 0, 1]list1 = []for item in compress(list_info, position_list):list1.append(item)list1.append(str(id_num))df = pd.DataFrame(list1, index=index).Tdf = df.set_index(['退出时间'], inplace=False)return df# 多线程的爬取def process(basic_url, df_name, index):# 将total_queue全局化global total_queueprint("thread start...\n")# 不为空则一直跑,while True不可以省略,否则只运行一次。while True:# 再次判断如果total_queue空了,那么停止。if total_queue.qsize() == 0:print('The end. \n')return# 从queue中取出id_num,然后拼出urlid_num = total_queue.get()# print('get id %d. \n' % id_num)url = basic_url.format(id_num)try:# 如果能够成功打开网页,那么检测:有没有验证码html = get_html(url)# print('1st html.\n')# 如果真的有验证码,那么刷到验证码消失为止while '验证码' in html:try:# print('出现验证码.\n')html = get_html(url)# 如果在刷验证码的过程中,遇到了网页问题,那么把id放回到queue中,并且睡眠10秒。except:total_queue.put(id_num)# 验证成功# print("开网页失败,id=%d.\n" % id_num)# print('time sleep 10s.\n')time.sleep(10)# print("跳出了while,已获得html.\n")# 只有退出机构才参与分析页面结构+储存到mysql,其他不用管了if '退出时间' in html:# print('退出机构: %d. \n' % id_num)list_info = get_dom(html)df1 = get_info(list_info, id_num, index)df_to_sql(df1, root, pw, db, df_name, '退出时间')elif '机构信息' not in html:total_queue.put(id_num)# 验证成功# print("开网页失败,id=%d.\n" % id_num)else:pass# 如果第一次都没有成功打开网页,那么把id放回到queue中,并且睡眠10秒。except:# print('第一次网页都没有打开。\n')total_queue.put(id_num)# 验证成功# print("开网页失败,id=%d.\n" % id_num)# print('time sleep 60s.\n')time.sleep(10)# 监听程序def listen_thread():while True:l = total_queue.qsize()print('current size : %d. \n' % l)time.sleep(20)# 调度程序def schedule(thread_num, df_name, index, basic_url):global numbersthreading.Thread(target=listen_thread).start()for i in range(thread_num):threading.Thread(target=process, args=(basic_url, df_name, index,)).start()if __name__ == '__main__':basic_url = r'http://xkz.cbirc.gov.cn/jr/showLicenceInfo.do?id={}'index = ['机构编码', '机构名称', '机构简称', '英文名称', '机构地址', '机构所在地','邮政编码', '发证日期', '批准成立日期', '发证机关', '流水号', '退出时间', 'ID']root = 'root'pw = 'pw'host = 'localhost'db = '银保监会'df_name = '退出机构'# 把标签全部放到total_queue中,等待取出。for i in range(1, 240000):total_queue.put(i)# 如果total_queue空了,但是有线程没有结束,那么等待60秒。# 直接主线程等待1s就行time.sleep(1)schedule(20, df_name, index, basic_url)
那么最后成功的结果在mysql中的显示如下: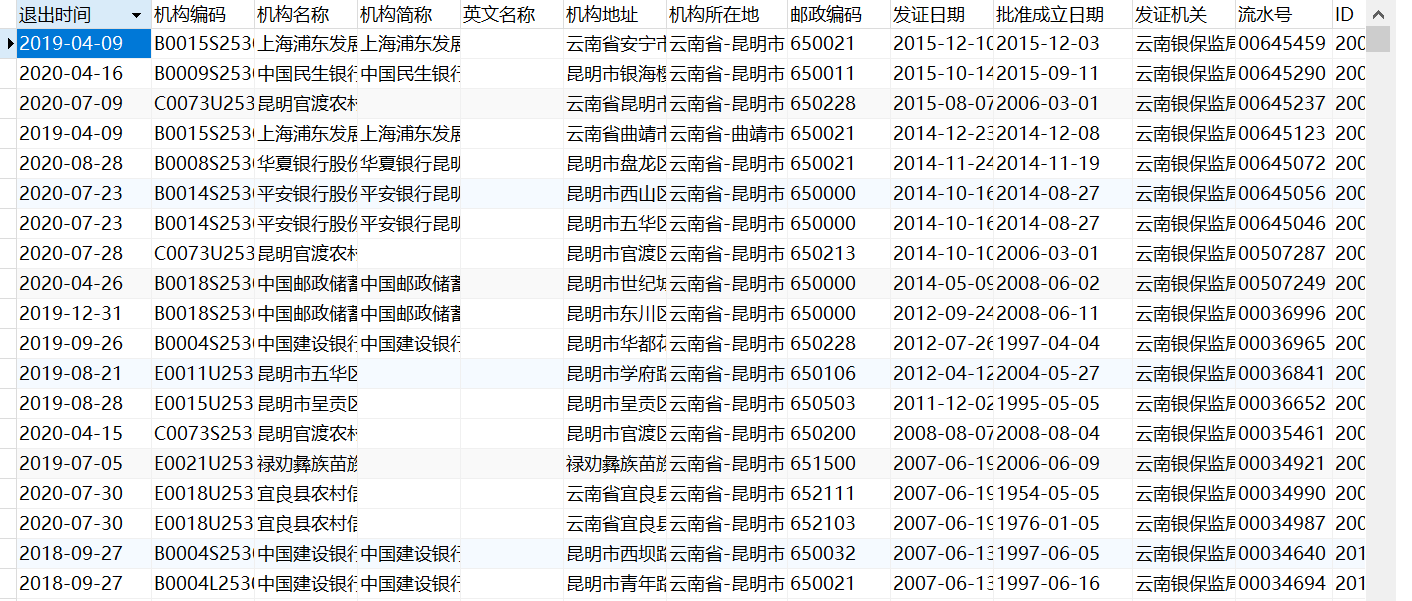
以上~

若有收获,就点个赞吧
0 人点赞
