一、介绍
最近JK又有事情交给我做,是的,又要让我爬网页了。。。这次是光明日报。
对于这种网页,我最怕的是反爬机制很厉害,特别是IP限制和验证码识别。。。还好,这次爬取的网页没有防爬机制,直接拿,都不用停歇的那种。。。
首先,2008年~2020年的一级网页链接:http://epaper.gmw.cn/
- 从2008年~2020年所有的一级网页链接:
- 其中,year_month和day控制了日期,分别是“2010-01” 和“01”的格式,block控制版块位置。
然后,1998年~2007年的一级网页的链接比较杂乱。全部的结果从这里进入http://epaper.gmw.cn/gmrbdb/。
- 1998~1999全年的链接
- 2000年全年~2001.04.19
- 2001.04.20~2004.02.28
- 2004.02.29~2007.12.31
那么对应的时间段,使用不同的基本链接即可,然后往里面填充对应的日期、或者版块信息即可。
二、2008~2020年的一级网页的抓取
代码
import requestsfrom lxml import etreeimport pandas as pdfrom sqlalchemy import create_engineimport pymysqlfrom sqlalchemy.types import VARCHARpymysql.install_as_MySQLdb()def df_to_sql(df, root, pw, db, name, idntt):basic_url = 'mysql+mysqldb://{root}:{pw}@localhost:3306/{db}?charset=utf8mb4'.format(root=root, pw=pw, db=db)engine = create_engine(basic_url)conn = engine.connect()df.to_sql(name, conn, if_exists='append', dtype={idntt: VARCHAR(df.index.get_level_values(idntt).str.len().max())})conn.close()passdef get_html(url, decodes='utf-8'):# 第一次获取html,可能存在验证码rsp = requests.get(url)html = rsp.content.decode(decodes, 'ignore').replace('\t', '').replace('\n', '')return htmldef get_dom_1time(html, url, block_tick):# block_tick = '01' '02'等dom = etree.HTML(html)# 二级网页文章的所有链接article_link = dom.xpath(r'.//div[@class="list_l"]//li//a//@href')article_link1 = [url + i for i in article_link]# 二级网页文章的总数量art_len = len(article_link1)# block_tick_list = ['01', '01', '01']block_tick_list = [block_tick] * art_len# 二级网页的版块信息# block_name_list = ['版块1:要闻', '版块2:经济', '版块3:国际'], 一次性block_name_list = dom.xpath(r'.//div[@class="list_r"]//a[@href]//text()')block_total = len(block_name_list)# block_num_list = ['01', '02', '03', '04'], 一次性block_num_list = [str(i).zfill(2) for i in range(1, block_total + 1)]# block_name_tick_list = ['要闻', '要闻', '要闻', '要闻']block_name_tick_list = [block_name_list[0]] * art_lenreturn article_link1, block_tick_list, block_name_tick_list, block_num_list, block_name_listdef get_dom_2time(html, url, block_tick, block_name_tick):# block_tick = '01' '02'等, block_name_tick = '要闻'等dom = etree.HTML(html)article_link = dom.xpath(r'.//div[@class="list_l"]//li//a//@href')article_link1 = [url + i for i in article_link]art_len = len(article_link1)block_tick_list = [block_tick] * art_lenblock_name_tick_list = [block_name_tick] * art_lenreturn article_link1, block_tick_list, block_name_tick_listdef get_date_list(start, end):date = pd.DataFrame(pd.date_range(start, end, freq='D'), columns=['date'])date['date'] = date['date'].apply(lambda x: str(x))date['year-month'] = date['date'].apply(lambda x: x[:7])date['day'] = date['date'].apply(lambda x: x[8:10])y_m = list(date['year-month'])d = list(date['day'])return y_m, ddef get_df(first_basic_url, second_basic_url, year_month, day):# 拼出第一页的一级页面,block始终=01,之后更换blockurl1 = first_basic_url.format(year_month=year_month, day=day, block='01')# 拼出二级页面的开头,不再改变。url2 = second_basic_url.format(year_month=year_month, day=day)# 一级网页的第一页信息,block='01'html = get_html(url1)# 需要block_num_list信息,为了下面的信息。article_link, block_tick_list, block_name_tick_list, block_num_list, block_name_list = get_dom_1time(html, url2, '01')length = len(block_name_list)# 一级网页第2页之后的信息for i in range(1, length):block_tick = block_num_list[i]block_name_tick = block_name_list[i]url1 = first_basic_url.format(year_month=year_month, day=day, block=block_tick)html = get_html(url1)try:article_link1, block_tick_list1, block_name_tick_list1 = get_dom_2time(html, url2, block_tick, block_name_tick)article_link.extend(article_link1)block_tick_list.extend(block_tick_list1)block_name_tick_list.extend(block_name_tick_list1)except:print("Error %s "%url1)df = pd.DataFrame([block_tick_list, block_name_tick_list, article_link],index=['block_tick', 'block_name', 'article_link']).Tdf['year_month'] = year_monthdf['day'] = dayreturn dfif __name__ == "__main__":# 得到日期listy_m, d = get_date_list('2008-01-01', '2020-09-29')# 一级网页的基础链接,和二级网页的基础链接,这里仅仅是实验,需要全部的内容爬完整就行。first_basic_url = r'https://epaper.gmw.cn/gmrb/html/{year_month}/{day}/nbs.D110000gmrb_{block}.htm'second_basic_url = r'https://epaper.gmw.cn/gmrb/html/{year_month}/{day}/'for i in range(len(y_m)):year_month = y_m[i]day=d[i]print(year_month, day)df = get_df(first_basic_url, second_basic_url, year_month, day)df = df.set_index(['block_tick'], inplace=False)df_to_sql(df, 'root', 'pw', '光明日报', 'first_link0820', 'block_tick')
三、1997~2007年的网页抓取
import requests
from lxml import etree
import pandas as pd
from sqlalchemy import create_engine
import pymysql
from sqlalchemy.types import VARCHAR
pymysql.install_as_MySQLdb()
def df_to_sql(df, root, pw, db, name, idntt):
basic_url = 'mysql+mysqldb://{root}:{pw}@localhost:3306/{db}?charset=utf8mb4'.format(root=root, pw=pw, db=db)
engine = create_engine(basic_url)
conn = engine.connect()
df.to_sql(name, conn, if_exists='append',
dtype={idntt: VARCHAR(df.index.get_level_values(idntt).str.len().max())})
conn.close()
pass
def sql_to_df(one_sql, root, pw, db):
basic_url = 'mysql+mysqldb://{root}:{pw}@localhost:3306/{db}?charset=utf8'.format(
root=root, pw=pw, db=db)
engine = create_engine(basic_url)
conn = engine.connect()
df = pd.read_sql(one_sql, conn)
conn.close()
return df
def get_date_list(start, end):
date = pd.DataFrame(pd.date_range(start, end, freq='D'), columns=['date'])
date['date'] = date['date'].apply(lambda x: str(x)[:10])
date['year'] = date['date'].apply(lambda x: x[:4])
date['month'] = date['date'].apply(lambda x: x[5:7])
date['day'] = date['date'].apply(lambda x: x[8:10])
y = list(date['year'])
m = list(date['month'])
d = list(date['day'])
dt = list(date['date'])
return y, m, d, dt
def get_html(url, decodes='utf-8'):
rsp = requests.get(url)
html = rsp.content.decode(decodes, 'ignore').replace('\t', '').replace('\n', '')
return html
def get_dom(html, basic_url, year, month, day):
dom = etree.HTML(html)
# blocks = dom.xpath(r'.//div[@class="channelLeftPart"]//b//text()')
every_url = dom.xpath(r'.//div[@class="channelLeftPart"]//ul[@class="channel-newsGroup"]//li//span//a//@href')
every_titile = dom.xpath(r'.//div[@class="channelLeftPart"]//ul[@class="channel-newsGroup"]//li//span//a//@title')
every_url1 = [basic_url.format(year=year, month=month, day=day, item=u) for u in every_url]
return every_titile, every_url1
def get_df(title_list, url_list, date):
df = pd.DataFrame([title_list, url_list], index=['title', 'url']).T
df['date'] = date
df = df.set_index(['date'], inplace=False)
return df
### 1998~1999全年的链接
basic_url1 = r'http://www.gmw.cn/01gmrb/{year}-{month}/{day}/GB/{item}'
y, m, d, dt = get_date_list('1998-01-01', '1999-12-31')
ymddt = zip(y, m, d, dt)
# ymddt = zip(y[:10], m[:10], d[:10], dt[:10])
for y1, m1, d1, dt1 in ymddt:
print(dt1)
url1 = basic_url1.format(year=y1, month=m1, day=d1, item='DEFAULT.HTM')
try:
html = get_html(url1)
every_titile, every_url = get_dom(html, basic_url1, y1, m1, d1)
df = get_df(every_titile, every_url, dt1)
df_to_sql(df, 'root', 'pw', '光明日报', 'first_link9807', 'date')
except:
print("Error : %s"%url1)
### 2000年全年~2001.04.19
basic_url2 = r'http://www.gmw.cn/01gmrb/{year}-{month}/{day}/GB/{item}'
y, m, d, dt = get_date_list('2000-01-01', '2000-04-19')
ymddt = zip(y, m, d, dt)
# ymddt = zip(y[:10], m[:10], d[:10], dt[:10])
for y1, m1, d1, dt1 in ymddt:
print(dt1)
url1 = basic_url2.format(year=y1, month=m1, day=d1, item='default.htm')
try:
html = get_html(url1)
every_titile, every_url = get_dom(html, basic_url2, y1, m1, d1)
df = get_df(every_titile, every_url, dt1)
df_to_sql(df, 'root', 'pw', '光明日报', 'first_link9807', 'date')
except:
print("Error : %s"%url1)
### 2001.04.20~2004.02.28
basic_url3 = r'http://www.gmw.cn/01gmrb/{year}-{month}/{day}/{item}'
item = '{year}-{month}-{day}-Homepage.htm'
y, m, d, dt = get_date_list('2001-04-20', '2004-02-28')
ymddt = zip(y, m, d, dt)
# ymddt = zip(y[:10], m[:10], d[:10], dt[:10])
for y1, m1, d1, dt1 in ymddt:
print(dt1)
item1 = item.format(year=y1, month=m1, day=d1)
url1 = basic_url3.format(year=y1, month=m1, day=d1, item=item1)
try:
html = get_html(url1)
every_titile, every_url = get_dom(html, basic_url3, y1, m1, d1)
df = get_df(every_titile, every_url, dt1)
df_to_sql(df, 'root', 'pw', '光明日报', 'first_link9807', 'date')
except:
print("Error : %s"%url1)
### 2004.02.29~2007.12.31
basic_url4 = r'http://www.gmw.cn/01gmrb/{year}-{month}/{day}/{item}'
y, m, d, dt = get_date_list('2004-02-29', '2007-12-31')
# ymddt = zip(y, m, d, dt)
ymddt = zip(y[:10], m[:10], d[:10], dt[:10])
for y1, m1, d1, dt1 in ymddt:
print(dt1)
url1 = basic_url4.format(year=y1, month=m1, day=d1, item='default.htm')
try:
html = get_html(url1)
every_titile, every_url = get_dom(html, basic_url4, y1, m1, d1)
df = get_df(every_titile, every_url, dt1)
df_to_sql(df, 'root', 'pw', '光明日报', 'first_link9807', 'date')
except:
print("Error : %s"%url1)
四、2008~2020二级网页的爬取
再爬取二级网页的内容。在爬取的时候,注意需要使用headers信息,每台机器都不一样。
使用google浏览器打开2008年的一个网址,https://epaper.gmw.cn/gmrb/html/2008-01/01/nw.D110000gmrb_20080101_1-01.htm?div=-1
然后通过Ctrl+Shift+I查看headers。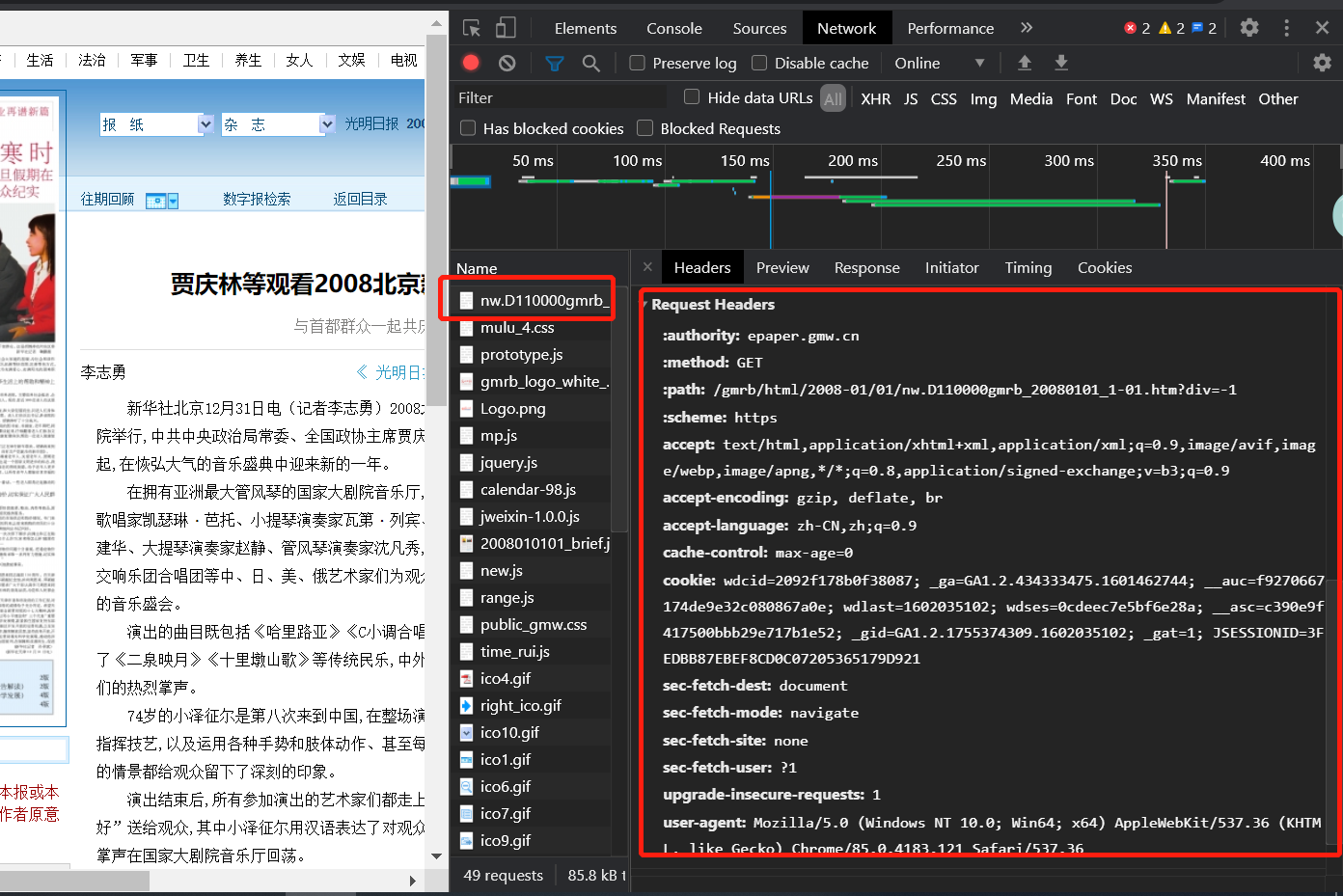
那么把headers中的信息全部取出来,放到requests.get中。
from sqlalchemy import create_engine
import pymysql
import pandas as pd
import requests
from lxml import etree
import time
from sqlalchemy.types import VARCHAR
pymysql.install_as_MySQLdb()
def get_headers():
h = {}
h['accept'] = 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9'
h['accept-encoding'] = 'gzip, deflate, br'
h['accept-language'] = 'zh-CN,zh;q=0.9'
h['cache-control'] = 'max-age=0'
h['cookie'] = 'wdcid=2092f178b0f38087; _ga=GA1.2.434333475.1601462744; __auc=f9270667174de9e32c080867a0e; JSESSIONID=38DBDBA2673365EC3BBD12B822D079D0; wdses=590ee4d1d7c5eb0b; __asc=b92e75d6174f7ac22b1fcd6e6a7; _gid=GA1.2.2141714287.1601883088; wdlast=1601883189'
h['sec-fetch-dest'] = 'document'
h['sec-fetch-mode'] = 'navigate'
h['sec-fetch-user'] = '?1'
h['upgrade-insecure-requests'] = '1'
h['user-agent'] = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36'
return h
def df_to_sql(df, root, pw, db, name, idntt):
basic_url = 'mysql+mysqldb://{root}:{pw}@localhost:3306/{db}?charset=utf8mb4'.format(root=root, pw=pw, db=db)
engine = create_engine(basic_url)
conn = engine.connect()
df.to_sql(name, conn, if_exists='append',
dtype={idntt: VARCHAR(df.index.get_level_values(idntt).str.len().max())})
conn.close()
pass
def sql_to_df(one_sql, root, pw, db):
basic_url = 'mysql+mysqldb://{root}:{pw}@localhost:3306/{db}?charset=utf8'.format(
root=root, pw=pw, db=db)
engine = create_engine(basic_url)
conn = engine.connect()
df = pd.read_sql(one_sql, conn)
conn.close()
return df
def get_html(url, decodes='utf-8'):
# 第一次获取html,可能存在验证码
rsp = requests.get(url, headers = get_headers())
html = rsp.content.decode(decodes, 'ignore').replace('\t', '').replace('\n', '')
return html
def get_article(html):
dom = etree.HTML(html)
title = dom.xpath(r'.//div[@class="text_c"]//h1//text()')
title1 = ''
for item in title:
title1 += item.replace(' ', '').replace('\xa0', '').replace('\r', '')
article = dom.xpath(r'.//div[@id="articleContent"]//text()')
article1 = ''
for item in article:
item = item.replace(' ', '').replace('\xa0', '').replace('\r', '')
article1 += item
return title1, article1
def get_df(title, article, url):
df = pd.DataFrame([url, title, article], index=['url', 'title', 'article']).T
df = df.set_index(['url'], inplace=False)
return df
### first_link即为我刚刚爬取的存在MySQL中的链接。
first_link = sql_to_df("""select * from first_link0820""", 'root', 'pw', '光明日报')
for url in list(first_link['article_link'])
try:
html = get_html(url)
title, article = get_article(html)
one_link = get_df(title, article, url)
df_to_sql(one_link, 'root', 'pw', '光明日报', 'second_page1', 'url')
except:
print('Error url %s'%url)
五、1998~2007年的二级网页
同样,这里需要加入headers。
使用google浏览器打开1998年的一个网址,http://www.gmw.cn/01gmrb/1998-01/01/GB/17560^GM1-0104.HTM 然后通过Ctrl+Shift+I查看headers。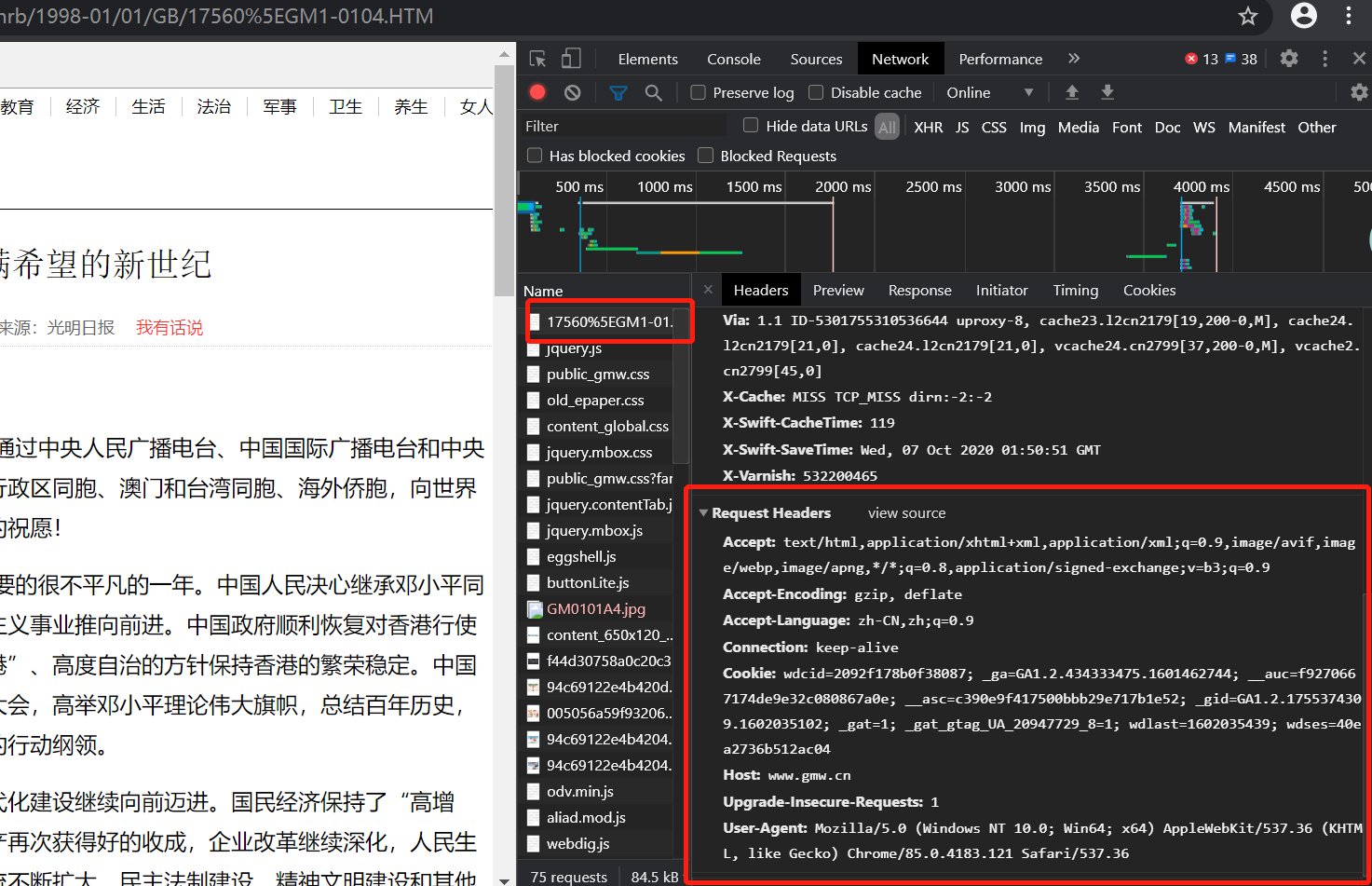
from sqlalchemy import create_engine
import pymysql
import pandas as pd
import requests
from lxml import etree
import time
from sqlalchemy.types import VARCHAR
pymysql.install_as_MySQLdb()
def get_headers():
h = {}
h['Accept'] = 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9'
h['Accept-Encoding'] = 'gzip, deflate'
h['Accept-Language'] = 'zh-CN,zh;q=0.9'
h['Connection'] = 'keep-alive'
h['Cookie'] = 'wdcid=2092f178b0f38087; _ga=GA1.2.434333475.1601462744; __auc=f9270667174de9e32c080867a0e; wdlast=1601695399; __asc=b92e75d6174f7ac22b1fcd6e6a7; _gid=GA1.2.2141714287.1601883088'
h['Host'] = 'www.gmw.cn'
h['Upgrade-Insecure-Requests'] = '1'
h['User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36'
return h
def df_to_sql(df, root, pw, db, name, idntt):
basic_url = 'mysql+mysqldb://{root}:{pw}@localhost:3306/{db}?charset=utf8mb4'.format(root=root, pw=pw, db=db)
engine = create_engine(basic_url)
conn = engine.connect()
df.to_sql(name, conn, if_exists='append',
dtype={idntt: VARCHAR(df.index.get_level_values(idntt).str.len().max())})
conn.close()
pass
def sql_to_df(one_sql, root, pw, db):
basic_url = 'mysql+mysqldb://{root}:{pw}@localhost:3306/{db}?charset=utf8'.format(
root=root, pw=pw, db=db)
engine = create_engine(basic_url)
conn = engine.connect()
df = pd.read_sql(one_sql, conn)
conn.close()
return df
def get_html(url, decodes='utf-8'):
# 第一次获取html,可能存在验证码
rsp = requests.get(url, headers = get_headers())
html = rsp.content.decode(decodes, 'ignore').replace('\t', '').replace('\n', '')
return html
def get_article(html):
dom = etree.HTML(html)
article = dom.xpath(r'.//div[@id="contentMain"]//text()')
article1 = ''
for item in article:
item = item.replace(' ', '').replace('\xa0', '')
article1 += item
return article1
def get_df(article, url):
df = pd.DataFrame([article, url], index=['art', 'url']).T
df = df.set_index(['url'], inplace=False)
return df
first_link = sql_to_df("""select * from first_link9807""", 'root', 'pw', '光明日报')
link_list =list(first_link['url'])
for url in link_list[:10]:
try:
html = get_html(url)
article = get_article(html)
one_link = get_df(article, url)
df_to_sql(one_link, 'root', 'pw', '光明日报', 'second_page2', 'url')
except:
print('Error url %s'%url)
以上

若有收获,就点个赞吧
0 人点赞
