- 一、引言
- 二、数据库和IP供应商
- 在IP的API网站得到的IP格式往往是“addresss:port”的格式,那么我们需要再稍微加工一下,得到下面的固定格式。
- http://117.69.12.224:9999‘, ‘https’:’https://117.69.12.224:9999'}">proxy={‘http’:’http://117.69.12.224:9999‘, ‘https’:’https://117.69.12.224:9999'}
- 我给程序伪装的浏览器是headers,伪装的IP是proxy,网页响应时间是60秒(60秒还开不了就放弃访问)。
- 方法1
- 例如IP = “117.69.12.224:9999”,那么address=117.69.12.224, port=9999
- 通过telnetlib测试
- 方法2:
- 通过访问网站代理,看看是否成功
- http://117.69.12.224:9999‘, ‘https’:’https://117.69.12.224:9999'}">proxy={‘http’:’http://117.69.12.224:9999‘, ‘https’:’https://117.69.12.224:9999'}
一、引言
我们做研究越来越需要“数据库以外”的数据。近期我试图爬取了《人民日报》数据库的一些信息,同时尝试了多线程和IP代理结合的爬虫模式。以下是我的尝试和总结。这里多线程和IP代理是重点,待抓取的内容和IP提供商并不是很重要。
二、数据库和IP供应商
1.《人民日报》数据库
数据库来自淘宝的一个商家,网址是https://www.zhixinglib.com/lib/?s=%E4%BA%BA%E6%B0%91%E6%97%A5%E6%8A%A5。
那么,进入到“人民日报(下载)”的页面中。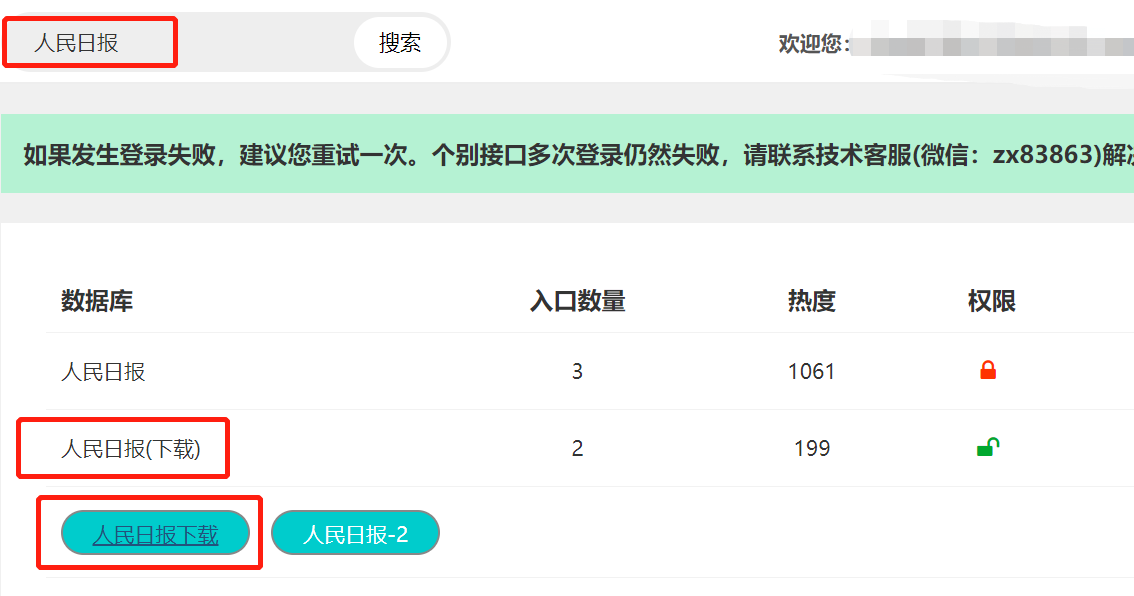
然后,我们进入到了数据库。
这里我需要的信息是每一页的“版块名”,例如2020-08-10第一版是“要闻”,第二版是“要闻”等。有一个问题是,每一天的报纸页码数量都不同,而往往在某日报纸的最后一页能够看到当日一共有多少个版块(我测试过,直接在第1页查看、有时候只能显示前半部分的版块名),例如2020-08-10是20页,而2020-08-09一共只有8页。因此我们还需要抓取每一天的报纸的版面数量。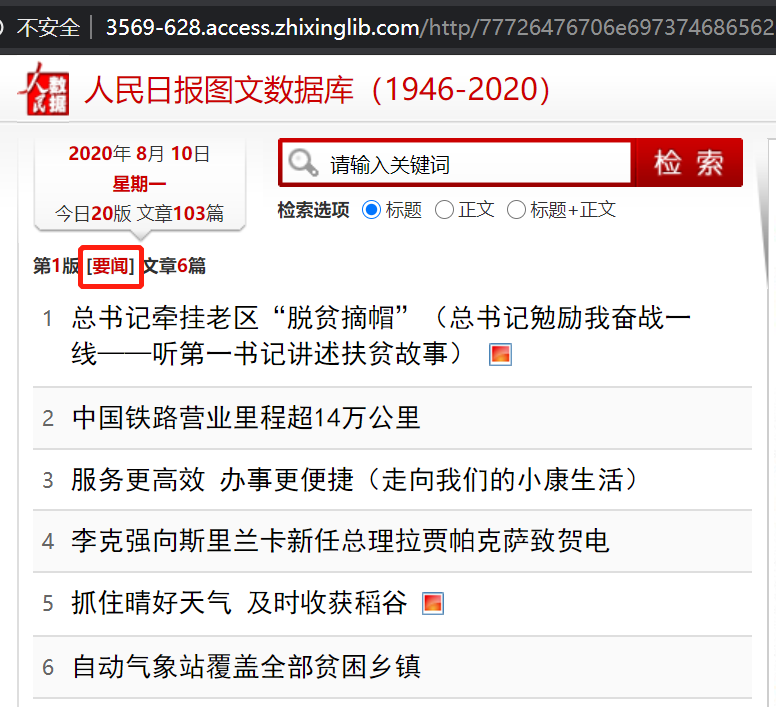

2.《人民日报》的网址分析
2020-08-10第1页的页码:http://3569-628.access.zhixinglib.com/http/77726476706e69737468656265737421f4f6559d69206d5f6e048ce29b5a2e7b74a4/rmrb/20200810/1
2020-08-10第2页的页码:http://3569-628.access.zhixinglib.com/http/77726476706e69737468656265737421f4f6559d69206d5f6e048ce29b5a2e7b74a4/rmrb/20200810/2
那么可以推断出,基本的网址是:
http://3569-628.access.zhixinglib.com/http/77726476706e69737468656265737421f4f6559d69206d5f6e048ce29b5a2e7b74a4/rmrb/{date}/{page},我们只要往里面填充具体的日期date和页码page即可。
3.《人民日报》网页结构分析
Ctrl+U进入到HTML中。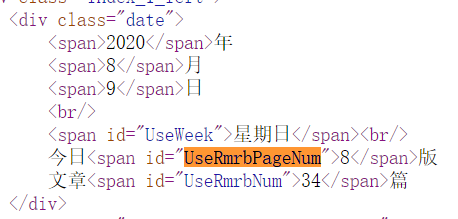
可以看到,当日总页码信息就在“.//span[@id=”UseRmrbPageNum”]//text()”结构中。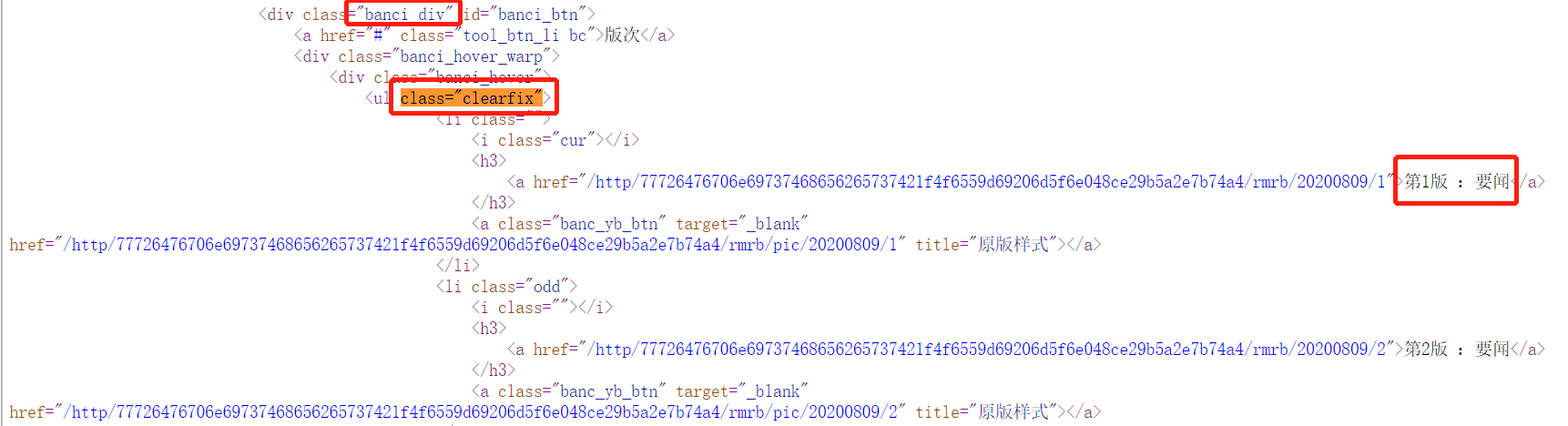
可以看到,版块信息就在“.//div[@class=”banci_div”]//div[@class=”banci_hover”]//ul[@class=”clearfix”]//text()”的结构中。
那么我们能够抓取到具体的版块名。
逻辑:通过第一页的网页HTML,获取到当日一共有多少版面,然后把最大的页码拼到url中,翻到当日最后一页,就能够看到当日具体的板块名。
4.IP提供商
这里我选择是http://119.45.8.232/GetApi代理。然后付费之后能够得到secret_key,从而能够生成便于提取出动态的IP的API接口,有效的IP占比很高。http://119.45.8.232/Api/?k=5H1NY6EBHEDD3Q0KYVI0DR&num=100&type=1&expire=&repeat=1&respone=1&ptn=1这个即为动态API接口,通过json格式获取IP,每次能够获取100个IP。当然,我的这个已经失效了。这里仅供参考。
5.IP用在哪里?
通常情况下,程序访问网站url,采用的代码一般是
import requestsrsp = requests.get(url)html = rsp.content
但是,连续不断的访问会触发IP被封(一段时间打不开这个网页)的情况。那么我们需要给程序访问网站的时候、装上伪装。那么这里使用的就是IP代理+headers的更换。最重要的是IP代理,headers没有IP重要。
- 装上代理IP
```python
在IP的API网站得到的IP格式往往是“addresss:port”的格式,那么我们需要再稍微加工一下,得到下面的固定格式。
proxy={‘http’:’http://117.69.12.224:9999‘, ‘https’:’https://117.69.12.224:9999'}
proxy = {‘http’: http_proxy, ‘https’: http_proxy} headers = {‘User-Agent’: “Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36”}
我给程序伪装的浏览器是headers,伪装的IP是proxy,网页响应时间是60秒(60秒还开不了就放弃访问)。
rsp = requests.get(url, headers=headers, proxies=proxy, timeout=60) html = rsp.content
那么,通过给访问装上proxy,就能够很好地伪装起来。- **我购买的数据库的IP代理商的使用方法如下**```pythonimport randomimport requestsdef get_proxy(api_url):rsp = requests.get(api_url).json()rsp2 = [i['Ip'] + ':' + str(i['Port']) for i in rsp]http_proxy = random.choice(rsp2)if "http" not in http_proxy:http_proxy = "http://" + http_proxyhttp_proxy.replace("\r", "").replace("\n", "").replace(" ", "")proxy = {'http': http_proxy, 'https': http_proxy}return proxy
首先,通过request访问api接口,从而每次都能够返回json格式的IP,然后我们解析之后、从中随机抽取一个出来。
注意,proxy的固定格式,否则即便抽出了有效的IP也无法使用。
proxy = {'http': 'http://117.69.12.224:9999', 'https': 'http://117.69.12.224:9999'}
6.IP失效了怎么办?
①IP本身未必有效,因为劣质供应商提供的IP大概50%都是无效的IP;②某个IP在经过了多次的抓取之后,就被网站自动拉黑;③每个IP的存活时间不长,到了一定的时间IP就会失效。这3种情况都需要我们更新IP。
- 对于我们个人来说,我们检测IP的方法如下。
```python
方法1
import telnetlib例如IP = “117.69.12.224:9999”,那么address=117.69.12.224, port=9999
通过telnetlib测试
address, port = ip.split(‘:’) #分割address和port try: telnetlib.Telnet(address, port, timeout=0.4) #检测代理ip是否有效,0.4秒超时 print(“yes”) except: print(“No”)
方法2:
通过访问网站代理,看看是否成功
proxy={‘http’:’http://117.69.12.224:9999‘, ‘https’:’https://117.69.12.224:9999'}
try: r = requests.get(“http://ip-api.com/json/?lang=zh-CN“, proxies=proxy, headers=headers, timeout=10) print(‘yes’) except Exception as e: print(‘No’)
- 对于连续不断的程序来讲,需要的是“如果某一个爬取失败了、那么立刻换下一个IP”的机制。
```python
# get_proxy(api_url)是通过api_url随机获取新的IP。
proxy = get_proxy(api_url)
retry = 3
while retry > 0: # 0
try: # 1
rsp = requests.get(url, proxies=proxy, headers=headers, timeout=60)
except: # 2
proxy = get_proxy(api_url)
rsp = requests.get(url, proxies=proxy, headers=headers, timeout=60)
if rsp.status_code != 200: # 3
proxy = get_proxy(api_url)
rsp = requests.get(url, proxies=proxy, headers=headers, timeout=60)
retry -= 1
continue
# 4
html = rsp.content.decode('utf-8').replace('\t', '').replace('\n', '')
html = ""
以上代码的解读:
首先,我们通过get_proxy函数,访问API接口,然后得到新的proxy。retry=3次机会;超过了3次尝试,那么html=””空字符。
最好的流程是#0——#1——#4,一开始生成的IP有效、并且得到了HTML。
如果流程是#0——#1——#3,那么表示IP已经被禁了,那么更换3次IP,3次以内通过就会运行#4;如果3次更换都失败了,说明该网站已经崩了或者设置了验证码没法抓取,那么返回的是””的html。
如果是#0——#2,即为初始的proxy已经失效,那么更换了新的IP再次访问,接下来依然会运行#3,同样3次机会尝试,通过就跳到#4,;没有通过就返回””。
注意:try…except是一次性的运行,要么try要么except,运行结束后,运行下一句if判断。
那么总代码如下:
import pandas as pd
import random
import time
import requests
from lxml import etree
from sqlalchemy import create_engine
from sqlalchemy.types import VARCHAR
import pymysql
pymysql.install_as_MySQLdb()
# 将proxy初始值设置为空字符,且为全局变量。
proxy = ""
class SingleThreadWebCrawler:
def __init__(self, basic_url, api_url, root, host, db, pw):
self.basic_url = basic_url
self.api_url = api_url
self.root = root
self.host = host
self.db = db
self.pw = pw
def df_to_sql(self, df, name, idntt):
"""将DataFrame存在MySQL中"""
pass
def get_dom_info(self, html, types):
"""如果我们要获取的是总页码,那么输入PAGES;如果我们要获取的是总的版块名字,那么输入的是BLOCKS。"""
dom = etree.HTML(html)
if types == 'PAGES':
result = dom.xpath(r'.//span[@id="UseRmrbPageNum"]//text()')[0]
else:
result = dom.xpath(r'.//div[@class="banci_div"]//div[@class="banci_hover"]//ul[@class="clearfix"]//text()')
result = [item.split(' :')[1] for item in result]
return result
def processdata(self, blocks, date):
"""处理lists,把存储了blocks信息的lists变为dataframe"""
date = pd.to_datetime(date)
df = pd.DataFrame(blocks, columns=['BLOCKS'])
df['DATE'] = date
df['DATE'] = df['DATE'].apply(lambda x: str(x)[:10])
df['PAGES'] = range(1, len(df) + 1)
return df
def get_proxy(self):
"""注意:每个IP代理商的get_proxy函数不尽相同,这个适用我租用的IP代理商的IP获取"""
rsp = requests.get(self.api_url).json()
rsp2 = [i['Ip'] + ':' + str(i['Port']) for i in rsp]
http_proxy = random.choice(rsp2)
if "http" not in http_proxy:
http_proxy = "http://" + http_proxy
http_proxy.replace("\r", "").replace("\n", "").replace(" ", "")
proxy = {'http': http_proxy, 'https': http_proxy}
return proxy
def get_html_proxy(url, headers, timeout, retry=3):
"""这里,proxy无效的原因有两种。(A)被网站封了该ip,(B)proxy本身无效。"""
"""技巧①:将proxy设为全局变量"""
global proxy
if not proxy:
proxy = get_proxy()
print("START: ", proxy)
"""技巧②:试错系统,万一url是错误的,那么经过3次尝试依然失败,那么返回的html=""
"""
while retry > 0:
"""技巧③:防止proxy本身无效,情况(B),采用try和except,休息3s,再换proxy"""
try:
rsp = requests.get(url, headers=headers, timeout=timeout, proxies=proxy)
except:
print('(B) Invalid proxy itself.')
proxy = get_proxy()
rsp = requests.get(url, headers=headers, timeout=timeout, proxies=proxy)
print('Valid proxy now.')
"""技巧④:防止proxy被网站封,情况(A),再次更换proxy。"""
if rsp.status_code != 200:
# 切换ip重试
proxy = get_proxy()
print("(A) Proxy is banned.")
retry -= 1
continue
html = rsp.content.decode('utf-8').replace('\t', '').replace('\n', '')
return html
"""技巧⑤:链接无效,对应retry次数失效。"""
return ""
def get_date_range(self, start, end):
"""得到时间区间lists"""
date_range = list(pd.date_range(start, end))
date_range2 = [str(i)[:10] for i in date_range]
date_range3 = [i[:4] + i[5:7] + i[8:10] for i in date_range2]
return date_range3
def master(self, start, end, name, idntt):
# 得到日期的范围的list。
date_range = self.get_date_range(self, start, end)
for date in date_range:
# 第一次是为了得到总页数
headers1 = {'User-Agent': random.choice(user_agent)}
url1 = self.basic_url.format(date=date, page=1)
html1 = self.get_html_proxy(url1, headers1, 60, retry=3)
if html1 == "":
continue
# 第二次是为了得到总的版块名。
pages = self.get_dom_info(html1, 'PAGES')
headers2 = {'User-Agent': random.choice(user_agent)}
url2 = basic_url.format(date=date, page=pages)
html2 = self.get_html_proxy(url2, headers2, 60, retry=3)
if html2 == "":
continue
blocks = self.get_dom_info(html2, 'BLOCK')
blocks = self.processdata(blocks, date)
blocks = blocks.set_index([idntt], inplace=False)
self.df_to_sql(blocks, name, idntt)
if __name__ == "__main__":
basic_url = 'http://3569-628.access.zhixinglib.com/http/77726476706e69737468656265737421f4f6559d69206d5f6e048ce29b5a2e7b74a4/rmrb/{date}/{page}'
api_url = 'http://119.45.8.232/Api/?k=5H1NY6EBHEDD3Q0KYVI0DR&num=100&type=1&expire=&repeat=1&respone=1&ptn=1'
user_agent = [
"Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
"Mozilla/5.0 (Windows NT 10.0; WOW64; rv:38.0) Gecko/20100101 Firefox/38.0",
"Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; .NET4.0C; .NET4.0E; .NET CLR 2.0.50727; .NET CLR 3.0.30729; .NET CLR 3.5.30729; InfoPath.3; rv:11.0) like Gecko"]
root, host, db, pw = ...
s1 = SingleThreadWebCrawler(basic_url, api_url, root, host, db, pw)
s1.master(start, end, 'BLOCKS', 'DATE')
这里需要注意的是,proxy一开始是空的字符串;但是在类中运行get_html_proxy函数的时候,将它全局化,并且给它初始值;同时在爬取的时候,不停地判断proxy处于哪一个情况、或者更换proxy。当然,万一html=””,那么跳出该次循环,继续下一个循环——continue。
三、多线程Threading的使用
1.简介
事实上,我们需要抓取的网页很多很多,一个线程不够用,这里使用了多线程,从而极大地提高效率。
2.如何和多个IP结合
当我们把线程变成多线程的时候,那么IP也要为多线程服务,也就是一个线程至少有一个IP使用。同时,检测和更换也要满足多线程的方式。
流程:①把总链接拆成N个部分(即为N个线程);②每个线程负责该部分的链接的抓取工作;③N个线程对应了N个IP代理组成的list,每个thread_id对应list[thread_id]的IP,时刻准备更换失效的IP。
代码如下
import threading
# 多线程锁
lock = threading.Lock()
# 多线程的IP list,一个线程thread_id对应一个IP=proxy_list[thread_id],从而里面存着N个线程的IP。
# 更换的时候,也是通过proxy_list[thread_id]进行更换。
# 一开始是空的list,在使用的时候再进行初始化。
proxy_list = []
# 下面的函数中,多线程的“多”只体现在“proxy_list”它的初始化和定义;
# 在真正使用的时候,本质上我们通过thread_id从proxy_list中抽取出对应位置的IPproxy_list[thread_id],用在各自的线程上。
# 同样,在使用try...except的时候,那么运行对应的情况,然后就运行下一句,不存在重复运行。
def get_html_proxy(url, user_agent, timeout, thread_id, retry=3):
# ① 将proxy_list全局化,“多”的体现。
global proxy_list
# ② 初始化,将proxy_list填满,“多”的体现。
while len(proxy_list) < thread_id + 1:
proxy_list.append(get_proxy(api_url))
print("thread_id:%d has no proxy fixing... done" % thread_id)
time.sleep(3)
headers = {'User-Agent': random.choice(user_agent)}
# 以下:本质上是单线程
# 技巧:试错系统,万一url是错误的,那么经过3次尝试依然失败,那么返回的html=""
while retry > 0:
try:
# 从list 中抽出对应位置的IP使用,“多”的体现。
proxy = proxy_list[thread_id]
# 这种报错是因为我们通过多线程访问、但是每次IP都不一样,网站无法封具体的IP,只能够直接“HTTP ERROR 429”。
# ConnectionResetError: [WinError 10054] 远程主机强迫关闭了一个现有的连接
# urllib3.exceptions.MaxRetryError: HTTPConnectionPool(host='58.218.200.247', port=23742): Max retries exceeded with url
try:
rsp = requests.get(url, headers=headers, proxies=proxy, timeout=60)
print("Thread %d OK: IP %s."%(thread_id, proxy))
except:
# 一旦砍断我网线,直接放弃。
print("Thread %d WinError 10054."%(thread_id))
time.sleep(30)
proxy = get_proxy(api_url)
proxy_list[thread_id] = proxy
return ""
except:
# 预防情形: ip自身无效
print("Thread %d : invalid proxy."%(thread_id))
proxy = get_proxy(api_url)
proxy_list[thread_id] = proxy
try:
rsp = requests.get(url, headers=headers, proxies=proxy, timeout=60)
print("Thread %d OK : IP %s." % (thread_id, proxy))
except:
print("Thread %d WinError 10054."%(thread_id))
time.sleep(30)
proxy = get_proxy(api_url)
proxy_list[thread_id] = proxy
return ""
# 预防情形:IP被禁
if rsp.status_code != 200:
print("Thread %d : proxy banned."%(thread_id))
time.sleep(30)
proxy = get_proxy(api_url)
# 换了新proxy,list对应位置也要换,“多”的体现。
proxy_list[thread_id] = proxy
retry -= 1
continue
html = rsp.content.decode('utf-8').replace('\t', '').replace('\n', '')
rsp.close()
return html
return ""
# 一个线程的操作:获取它的date_range的list以及它的thread_id,然后操作抓+存。
def process(date_range, user_agent, name, thread_id):
# do its own things.
pass
# 将大列表lists分成小列表,每个列表含n个元素
def chunks(lists, n):
return [lists[i:i + n] for i in range(0, len(lists), n)]
def multi_process(date_range, user_agent, name, ele_number):
# 同样需要把proxy_list全局化,“多”的体现
global proxy_list
range_lists = chunks(date_range, ele_number)
# 新建列表,用于存放所有线程
ts = []
# 线程总数 = num_thread
num_thread = len(range_lists)
# 为每一个thread分配一个proxy id
for i in range(num_thread):
proxy_list.append(get_proxy(api_url))
# 遍历N个子线程的range_lists
for i, range_list in enumerate(range_lists):
t = threading.Thread(target=process, args=(range_list, user_agent, name, i,)) # 创建线程
t.start() # 线程运行
ts.append(t) # 将线程添加到ts
# 等待线程结束
for t in ts: # 遍历每个线程
t.join() # 等待线程结束
print('Done')
拔掉网线是什么样子呢?就是下图的样子。
以上即为核心代码。我们把它封装到多线程中。
import pandas as pd
import random
import time
import threading
import requests
from lxml import etree
from sqlalchemy import create_engine
from sqlalchemy.types import VARCHAR
import pymysql
pymysql.install_as_MySQLdb()
# 多线程锁
lock = threading.Lock()
# 全局变量,用于多线程中,放入等数量的proxy ip,每个线程对应它的位置的proxy。
proxy_list = []
class BLOCKS:
def __init__(self, date_range, basic_url, api_url, root, host, db, pw):
self.date_range = date_range
self.basic_url = basic_url
self.api_url = api_url
# 以下的参数用于存储MySQL的信息。
self.root = root
self.host = host
self.db = db
self.pw = pw
def df_to_sql(self, df, name, idntt):
# dataframe to sql
pass
def get_dom_info(self, html, types):
dom = etree.HTML(html)
if types == 'PAGES':
result = dom.xpath(r'.//span[@id="UseRmrbPageNum"]//text()')[0]
else:
result = dom.xpath(r'.//div[@class="banci_div"]//div[@class="banci_hover"]//ul[@class="clearfix"]//text()')
result = [item.split(' :')[1] for item in result]
return result
def processdata(self, blocks, date):
date = pd.to_datetime(date)
df = pd.DataFrame(blocks, columns=['BLOCKS'])
df['DATE'] = date
df['DATE'] = df['DATE'].apply(lambda x: str(x)[:10])
df['PAGES'] = range(1, len(df) + 1)
return df
def get_proxy(self):
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50"}
rsp = requests.get(api_url).json()
rsp2 = [i['Ip'] + ':' + str(i['Port']) for i in rsp]
http_proxy = random.choice(rsp2)
if "http" not in http_proxy:
http_proxy = "http://" + http_proxy
http_proxy.replace("\r", "").replace("\n", "").replace(" ", "")
proxy = {'http': http_proxy, 'https': http_proxy}
return proxy
def get_html(self, url, user_agent, thread_id, retry=3):
global proxy_list
if len(proxy_list) < thread_id + 1:
proxy_list.append(self.get_proxy())
headers = {'User-Agent': random.choice(user_agent)}
# 3次尝试机会,如果没有通过,那么返回html=""
while retry > 0:
try:
proxy = proxy_list[thread_id]
try:
rsp = requests.get(url, headers=headers, proxies=proxy, timeout=60)
print("Thread %d OK: IP %s."%(thread_id, proxy))
except:
# 万一网线都拔了,那么直接返回空。
print("Thread %d WinError 10054."%(thread_id))
time.sleep(30)
proxy = self.get_proxy()
proxy_list[thread_id] = proxy
return ""
except:
# 失效的ip
print("Thread %d : invalid proxy."%(thread_id))
proxy = self.get_proxy()
proxy_list[thread_id] = proxy
try:
rsp = requests.get(url, headers=headers, proxies=proxy, timeout=60)
print("Thread %d OK : IP %s." % (thread_id, proxy))
except:
# 万一拔了网线
print("Thread %d WinError 10054."%(thread_id))
time.sleep(30)
proxy = self.get_proxy()
proxy_list[thread_id] = proxy
return ""
if rsp.status_code != 200:
# 万一IP被禁
print("Thread %d : proxy banned."%(thread_id))
time.sleep(30)
proxy = self.get_proxy()
proxy_list[thread_id] = proxy
retry -= 1
continue
html = rsp.content.decode('utf-8').replace('\t', '').replace('\n', '')
rsp.close()
return html
return ""
def process(self, date_range, user_agent, name, thread_id):
# 遍历每个ip
for i, date in enumerate(date_range):
if i % 20 == 0:
print(i)
time.sleep(60)
url1 = self.basic_url.format(date=date, page=1)
html1 = self.get_html(url1, user_agent, thread_id, retry=3)
time.sleep(5)
if html1 == "":
continue
pages = self.get_dom_info(html1, 'PAGES')
url2 = self.basic_url.format(date=date, page=pages)
html2 = self.get_html(url2, user_agent, thread_id, retry=3)
if html2 == "":
continue
blocks = self.get_dom_info(html2, 'BLOCKS')
blocks = self.processdata(blocks, date)
blocks = blocks.set_index(['DATE'], inplace=False)
self.df_to_sql(blocks, name, 'DATE')
# 将大列表分成小列表,每个列表含n个元素
def chunks(self, lists, n):
return [lists[i:i + n] for i in range(0, len(lists), n)]
def multi_process(self, user_agent, name, ele_number):
global proxy_list
range_lists = self.chunks(self.date_range, ele_number)
ts = [] # 新建列表,用于存放所有线程
# 线程总数
num_thread = len(range_lists)
# 为每一个thread分配一个proxy id
for i in range(num_thread):
proxy_list.append(self.get_proxy())
for i, range_list in enumerate(range_lists): # 遍历每个ip列表
t = threading.Thread(target=self.process, args=(range_list, user_agent, name, i,)) # 创建线程
t.start() # 线程运行
ts.append(t) # 将线程添加到ts
# 等待线程结束
for t in ts: # 遍历每个线程
t.join() # 等待线程结束
print('Done')
def get_date_range(start, end):
date_range = list(pd.date_range(start, end))
date_range2 = [str(i)[:10] for i in date_range]
date_range3 = [i[:4] + i[5:7] + i[8:10] for i in date_range2]
return date_range3
if __name__ == "__main__":
user_agent = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362",
"Mozilla/5.0 (Windows NT 10.0; WOW64; rv:38.0) Gecko/20100101 Firefox/38.0",
"Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; .NET4.0C; .NET4.0E; .NET CLR 2.0.50727; .NET CLR 3.0.30729; .NET CLR 3.5.30729; InfoPath.3; rv:11.0) like Gecko",
"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
"Mozilla/5.0 (Windows NT 10.0; WOW64; rv:38.0) Gecko/20100101 Firefox/38.0",
"Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; .NET4.0C; .NET4.0E; .NET CLR 2.0.50727; .NET CLR 3.0.30729; .NET CLR 3.5.30729; InfoPath.3; rv:11.0) like Gecko"
]
basic_url = 'http://2522-602.access.zhixinglib.com/rwt/235/http/MSRYIZJPPBTX86DMMVYGG55NF3SXP/rmrb/{date}/{page}'
api_url = "http://119.45.8.232/Api/?k=5H1NY6EBHEDD3Q0KYVI0DR&num=100&type=1&expire=&repeat=1&respone=1&ptn=1"
date_range = get_date_range('1994-01-01', '2020-07-31')
b1 = BLOCKS(date_range, basic_url, api_url, root, host, db, pw)
b1.multi_process(user_agent, 'block1', 500)
以上就是多线程+IP代理用于爬虫的实例。欢迎点赞收藏。

若有收获,就点个赞吧
0 人点赞
