flink sql是什么
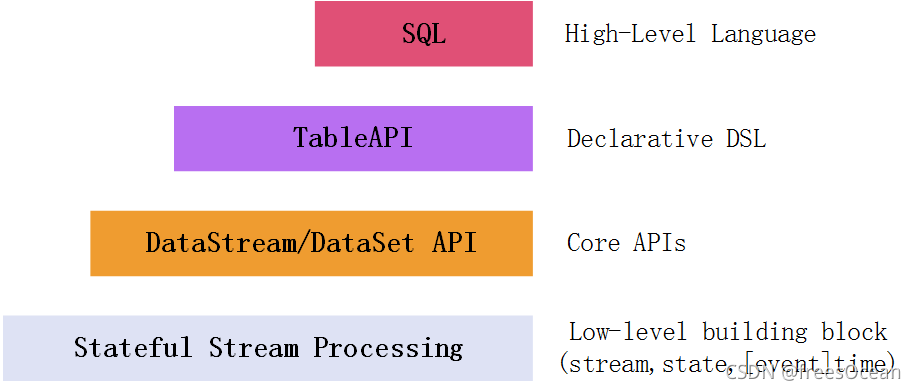
Flink针对流处理和批处理,为我们提供了多种操作API。从图中可知,越上层的API抽象程度越高,门槛越低(大家都熟悉SQL),但也丧失了灵活性。
Table API 是一系列集成在Java或Scala语言中的查询API,它允许通过一些关系运算符操作进行很直观的操作。
FlinkSQL 则是基于Apache Calcite实现了标准的SQL,可以通过编写SQL的方式进行Flink数据处理。
总结:flinksql 就是封装底层实现细节。在上层统一的实现。方便扩展。实现调用sql实现很多底层的操作。table api flink sql 底层原理架构是一样的。在使用的时候是两套api table api 是java scala 的查询api 以直观的方式组合关系关系运算符的查询
[
](https://blog.csdn.net/gexiaoyizhimei/article/details/120183213)
table api 的基础结构

表的概念

跟mysql的概念是一样的。 一组字段的集合,catalog 目录,下面又是数据库名。下面是对象名(表名)
如果api不指定catalog 和database 默认为default
表可以是常规的(实际存在的表),虚拟的(视图的概念) 在flink中数据都在内存中。
表可以连接外部数据源,文件,数据库表,消息队列,从流转换来的。这种表可以称为常规表,
视图一般是在flink 做数据转换中临时创建的表,可以从现有的表创建,通常是table api 或者sql的查询的结果集。
table api 创建表

//connect默认提供了es kafka 文件,可以自定义实现
//创建环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);// 2. 表的创建:连接外部系统,读取数据// 2.1 读取文件String filePath = "D:\\FlinkTutorial\\src\\main\\resources\\sensor.txt";tableEnv.connect( new FileSystem().path(filePath)).withFormat( new Csv()).withSchema( new Schema().field("id", DataTypes.STRING()).field("timestamp", DataTypes.BIGINT()).field("temp", DataTypes.DOUBLE())).createTemporaryTable("inputTable");Table inputTable = tableEnv.from("inputTable");// inputTable.printSchema();// tableEnv.toAppendStream(inputTable, Row.class).print();// 3. 查询转换// 3.1 Table API// 简单转换Table resultTable = inputTable.select("id, temp").filter("id === 'sensor_6'");// 聚合统计Table aggTable = inputTable.groupBy("id").select("id, id.count as count, temp.avg as avgTemp");// 3.2 SQLtableEnv.sqlQuery("select id, temp from inputTable where id = 'senosr_6'");Table sqlAggTable = tableEnv.sqlQuery("select id, count(id) as cnt, avg(temp) as avgTemp from inputTable group by id");// 打印输出 追加流 需要源源不断的数据。否则报错tableEnv.toAppendStream(resultTable, Row.class).print("result");//缩进流 使用追加流会报错,因为sql查询已经限制了条数 具体区别 https://www.cnblogs.com/wynjauu/articles/11654838.htmltableEnv.toRetractStream(aggTable, Row.class).print("agg");tableEnv.toRetractStream(sqlAggTable, Row.class).print("sqlagg");env.execute();
表跟环境的关系

table api 创建表并输出到文件
// 1. 创建环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);// 2. 表的创建:连接外部系统,读取数据// 读取文件String filePath = "D:\\迅雷下载\\4.代码\\FlinkTutorial\\src\\main\\resources\\sensor.txt";tableEnv.connect( new FileSystem().path(filePath)).withFormat( new Csv()).withSchema( new Schema().field("id", DataTypes.STRING()).field("timestamp", DataTypes.BIGINT()).field("temp", DataTypes.DOUBLE())).createTemporaryTable("inputTable");Table inputTable = tableEnv.from("inputTable");// inputTable.printSchema();// tableEnv.toAppendStream(inputTable, Row.class).print();// 3. 查询转换// 3.1 Table API// 简单转换Table resultTable = inputTable.select("id, temp").filter("id === 'sensor_6'");// 聚合统计Table aggTable = inputTable.groupBy("id").select("id, id.count as count, temp.avg as avgTemp");// 3.2 SQLtableEnv.sqlQuery("select id, temp from inputTable where id = 'senosr_6'");Table sqlAggTable = tableEnv.sqlQuery("select id, count(id) as cnt, avg(temp) as avgTemp from inputTable group by id");// 4. 输出到文件// 连接外部文件注册输出表String outputPath = "D:\\Projects\\BigData\\FlinkTutorial\\src\\main\\resources\\out.txt";tableEnv.connect( new FileSystem().path(outputPath)).withFormat( new Csv()).withSchema( new Schema().field("id", DataTypes.STRING())// .field("cnt", DataTypes.BIGINT()).field("temperature", DataTypes.DOUBLE())).createTemporaryTable("outputTable");resultTable.insertInto("outputTable");// aggTable.insertInto("outputTable");env.execute();
table api 从kafka读取数据 输出到kafka
// 1. 创建环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);// 2. 连接Kafka,读取数据tableEnv.connect(new Kafka().version("0.11").topic("sensor").property("zookeeper.connect", "localhost:2181").property("bootstrap.servers", "localhost:9092")).withFormat(new Csv()).withSchema(new Schema().field("id", DataTypes.STRING()).field("timestamp", DataTypes.BIGINT()).field("temp", DataTypes.DOUBLE())).createTemporaryTable("inputTable");// 3. 查询转换// 简单转换Table sensorTable = tableEnv.from("inputTable");Table resultTable = sensorTable.select("id, temp").filter("id === 'sensor_6'");// 聚合统计Table aggTable = sensorTable.groupBy("id").select("id, id.count as count, temp.avg as avgTemp");// 4. 建立kafka连接,输出到不同的topic下tableEnv.connect(new Kafka().version("0.11").topic("sinktest").property("zookeeper.connect", "localhost:2181").property("bootstrap.servers", "localhost:9092")).withFormat(new Csv()).withSchema(new Schema().field("id", DataTypes.STRING())// .field("timestamp", DataTypes.BIGINT()).field("temp", DataTypes.DOUBLE())).createTemporaryTable("outputTable");resultTable.insertInto("outputTable");env.execute();
简单查询 一条id =sensor_6 的数据 注意文件 和 kafka sink 只实现了append数据, 做不到更改之前的数据。
只做添加操作适合此模式 具体分析如下图
更新模式 (重点)
sink到外部数据源的数据类型。

追加 (append) 一直接收数据。所有的外部数据源都支持一直追加数据。
撤回模式(retract) 如果输出表是数据库。需要crud同步。比较适合撤回模式。一张表发生变化。在新增时,发送一条add ,删除时 一条撤回消息。,修改时发送两条消息。一条是数据的撤回删除。一条是插入新数据
支持append 的官方插件 api
有csv kafka
支持更新数据的 api
提供的es连接器

代码实现 es的动态更新。把聚合条件插入进去并接受动态更新

创建动态表。执行改变该表数据就可以看到聚合数据动态在es更新了。
动态数据输出到mysql


将表转换成流

关键代码实现



流和关系型表的区别
sql 查出来是有固定数据的。总的来说还是批处理
流处理是无界的。处理起来奇奇怪怪问题需要处理。就是跟有界不一样的地方
动态表
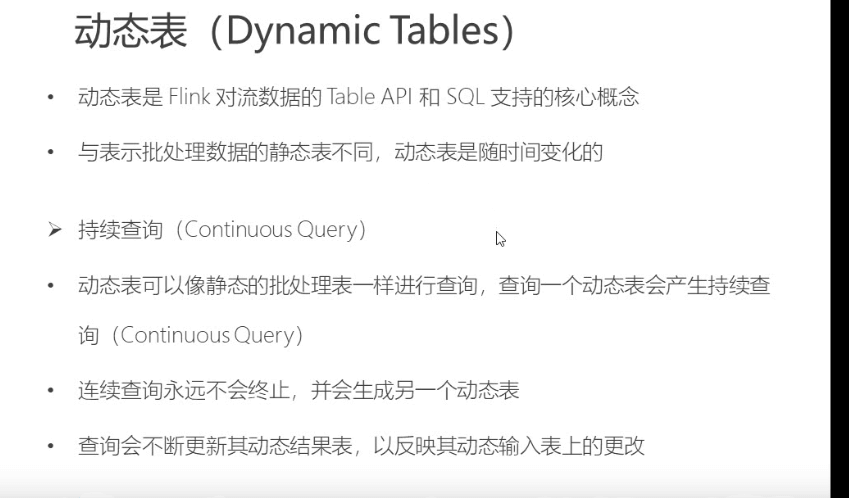
动态表是随时间变化。持续查询是不会停止的。操作api得到的结果也是动态表
动态表的流式处理过程
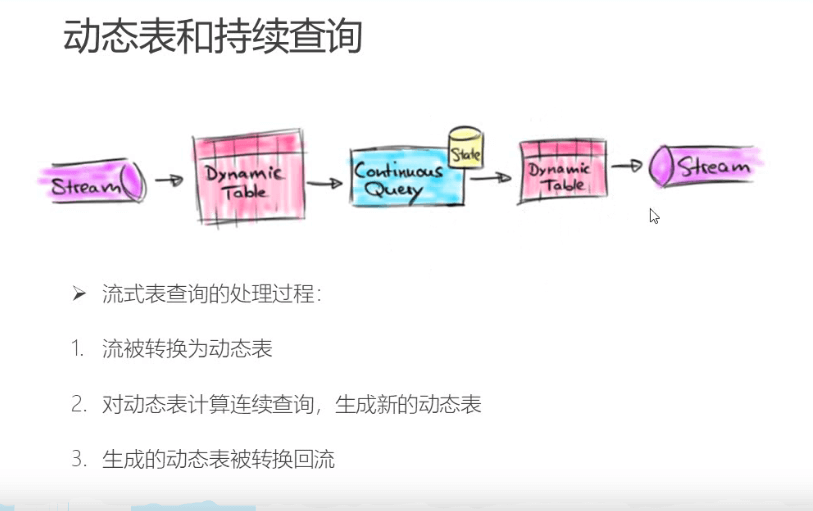
动态表在流程中会更新。生成新的动态表 最后流式输出
例子
日志数据,用户访问数据的日志,
从kafka 到flink 的表中。
类型下面的样子,来一条数据加一条数据到表中。
追加模式。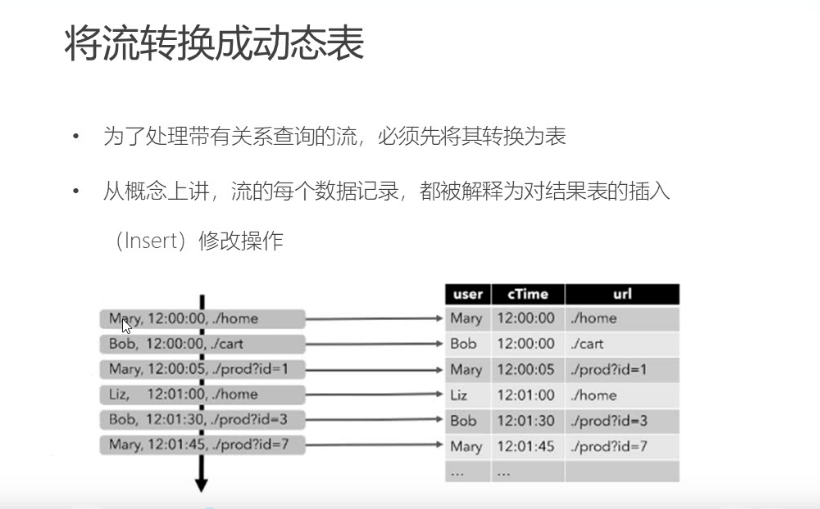
这个时候写一个sql select user,count(url) as cnt from clicks group by 按照用户分组 统计点击次数
这个sql会动态执行
动态表就会持续变化
因为出现了聚合操作。实现了修改动态的操作。。(外部连接器需要支持更新模式) 如果是简单map则不会
这样可以实现输出表的变化更新
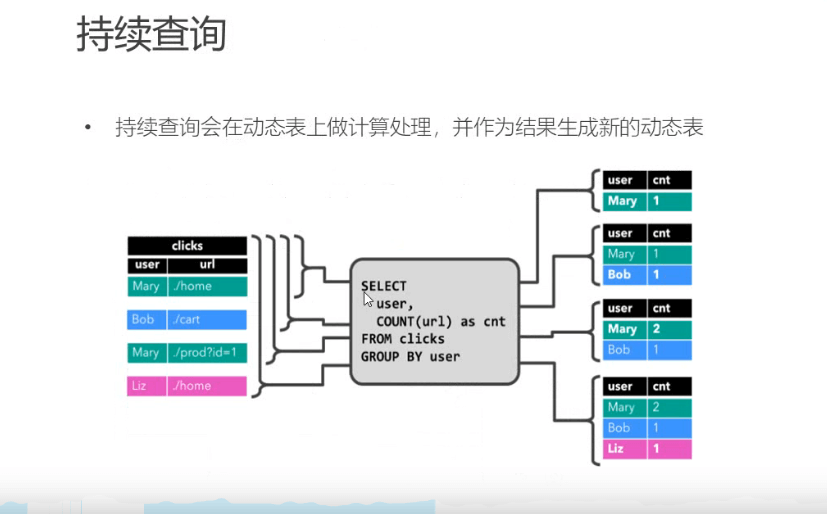
输出三种流模式
然后外部连接器可以消费这些信息。保证动态插入, 动态更新
需要外部连接器支持
两个更新模式的区别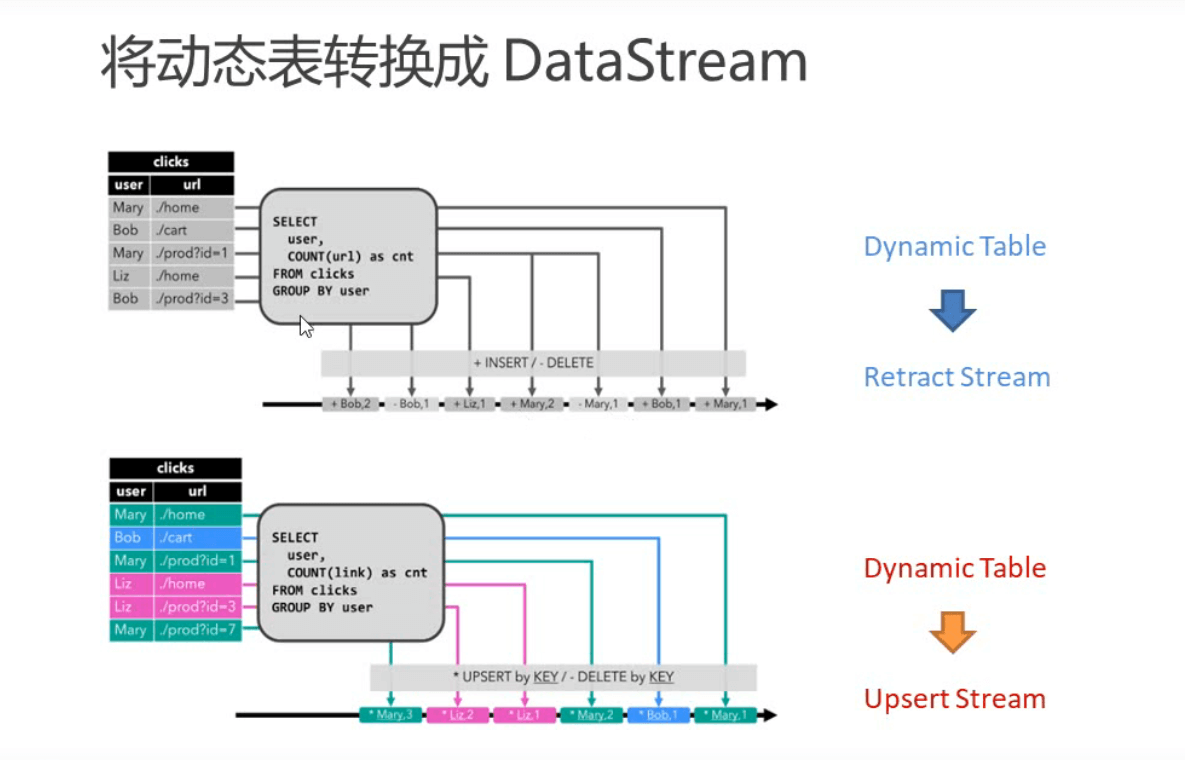
retract 只有两条消息。简单。缺点,发两条消息都要处理。外部连接器可能不愿意解释这种麻烦操作。
upsert 发送更新数据。比较好解释有点。
时间特性 (重要)
flink 支持多种时间语意

table 可以提供一个时间字段用于访问数据。
定义完成就可以作为表字段使用

FAQ 常见问题
1.怎么判断flink sql 中with的外部数据是输入还是输出?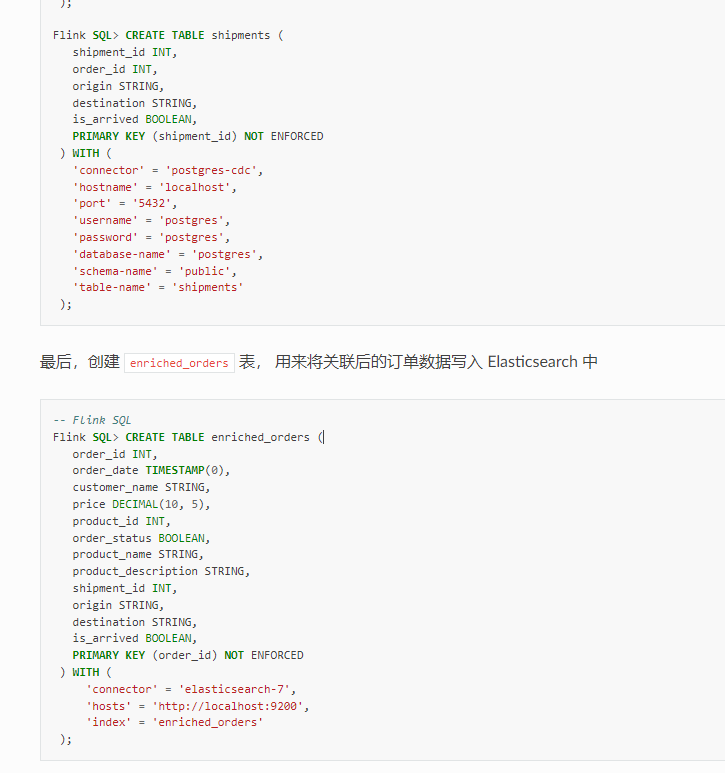
答:create是在flink 环境里注册一张表。 定义输入输出是业务的概念。取决于你后续的操作。 这里定义了es的外部数据源,那么你insert into 插入数据到es。那es就是输出表。
table api 同理

若有收获,就点个赞吧
0 人点赞
