来源
https://zhuanlan.zhihu.com/p/102325190
我们经常需要在一个时间窗口维度上对数据进行聚合,窗口是流处理应用中经常需要解决的问题。Flink的窗口算子为我们提供了方便易用的API,我们可以将数据流切分成一个个窗口,对窗口内的数据进行处理。本文将介绍如何在Flink上进行窗口的计算。
一个Flink窗口应用的大致骨架结构如下所示:
// Keyed Windowstream.keyBy(...) <- 按照一个Key进行分组.window(...) <- 将数据流中的元素分配到相应的窗口中[.trigger(...)] <- 指定触发器Trigger(可选)[.evictor(...)] <- 指定清除器Evictor(可选).reduce/aggregate/process() <- 窗口处理函数Window Function// Non-Keyed Windowstream.windowAll(...) <- 不分组,将数据流中的所有元素分配到相应的窗口中[.trigger(...)] <- 指定触发器Trigger(可选)[.evictor(...)] <- 指定清除器Evictor(可选).reduce/aggregate/process() <- 窗口处理函数Window Function
首先,我们要决定是否对一个DataStream按照Key进行分组,这一步必须在窗口计算之前进行。经过keyBy的数据流将形成多组数据,下游算子的多个实例可以并行计算。windowAll不对数据流进行分组,所有数据将发送到下游算子单个实例上。决定是否分组之后,窗口的后续操作基本相同,本文所涉及内容主要针对经过keyBy的窗口(Keyed Window),经过windowAll的算子是不分组的窗口(Non-Keyed Window),它们的原理和操作与Keyed Window类似,唯一的区别在于所有数据将发送给下游的单个实例,或者说下游算子的并行度为1。
Flink窗口的骨架结构中有两个必须的两个操作:
- 使用窗口分配器(WindowAssigner)将数据流中的元素分配到对应的窗口。
- 当满足窗口触发条件后,对窗口内的数据使用窗口处理函数(Window Function)进行处理,常用的Window Function有reduce、aggregate、process。
其他的trigger、evictor则是窗口的触发和销毁过程中的附加选项,主要面向需要更多自定义的高级编程者,如果不设置则会使用默认的配置。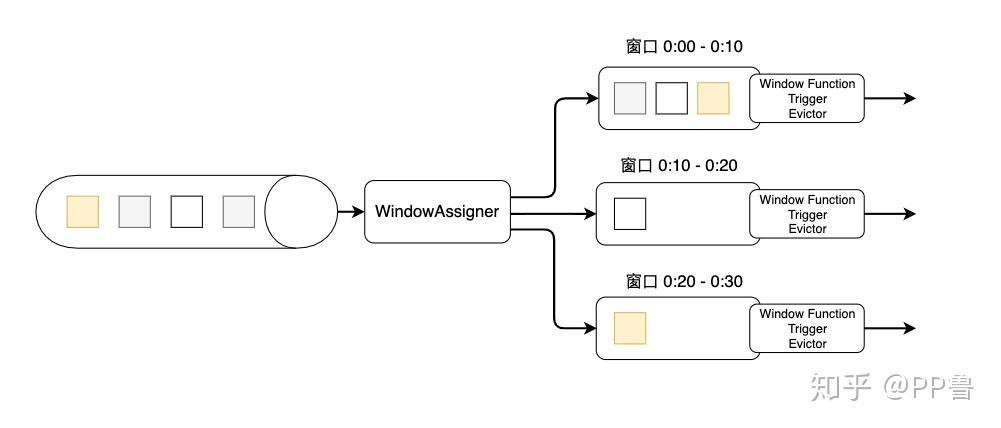
上图是窗口的生命周期示意图,假如我们设置的是一个10分钟的滚动窗口,第一个窗口的起始时间是0:00,结束时间是0:10,后面以此类推。当数据流中的元素流入后,窗口分配器会根据时间(Event Time或Processing Time)分配给相应的窗口。相应窗口满足了触发条件,比如已经到了窗口的结束时间,会触发相应的Window Function进行计算。注意,本图只是一个大致示意图,不同的Window Function的处理方式略有不同。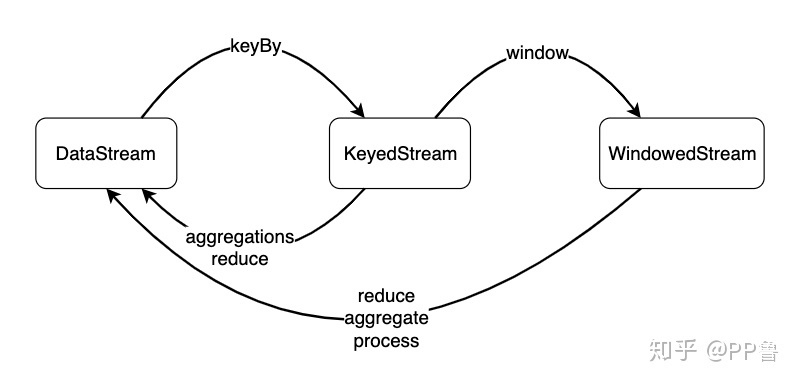
从数据类型上来看,一个DataStream经过keyBy转换成KeyedStream,再经过window转换成WindowedStream,我们要在之上进行reduce、aggregate或process等Window Function,对数据进行必要的聚合操作。
WindowAssigner
窗口主要有两种,一种基于时间(Time-based Window),一种基于数量(Count-based Window)。本文主要讨论Time-based Window,在Flink源码中,用TimeWindow表示。每个TimeWindow都有一个开始时间和结束时间,表示一个左闭右开的时间段。Flink为我们提供了一些内置的WindowAssigner,即滚动窗口、滑动窗口和会话窗口,接下来将一一介绍如何使用。
Count-based Window根据事件到达窗口的先后顺序管理窗口,到达窗口的先后顺序和Event Time并不一致,因此Count-based Window的结果具有不确定性。
滚动窗口
滚动窗口下窗口之间之间不重叠,且窗口长度是固定的。我们可以用TumblingEventTimeWindows和TumblingProcessingTimeWindows创建一个基于Event Time或Processing Time的滚动时间窗口。窗口的长度可以用org.apache.flink.streaming.api.windowing.time.Time中的seconds、minutes、hours和days来设置。
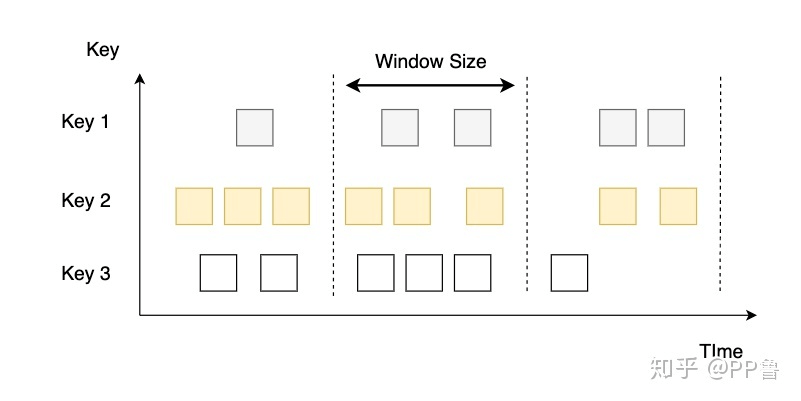
下面的代码展示了如何使用滚动窗口。代码中最后一个例子,我们在固定长度的基础上设置了偏移(offset)。默认情况下,时间窗口会做一个对齐,比如设置一个一小时的窗口,那么窗口的起止时间是[0:00:00.000 - 0:59:59.999)。如果设置了offset,那么窗口的起止时间将变为[0:15:00.000 - 1:14:59.999)。offset可以用在全球不同时区设置上,如果系统时间基于格林威治标准时间(UTC-0),中国的当地时间要设置offset为Time.hours(-8)。
al input: DataStream[T] = ...// tumbling event-time windowsinput.keyBy(...).window(TumblingEventTimeWindows.of(Time.seconds(5))).<window function>(...)// tumbling processing-time windowsinput.keyBy(...).window(TumblingProcessingTimeWindows.of(Time.seconds(5))).<window function>(...)// 1 hour tumbling event-time windows offset by 15 minutes.input.keyBy(...).window(TumblingEventTimeWindows.of(Time.hours(1), Time.minutes(15))).<window function>(...)
有些代码中,设置时间使用的是timeWindow而非window,比如,input.keyBy(…).timeWindow(Time.seconds(1))。timeWindow是一种简写。当我们在执行环境设置了TimeCharacteristic.EventTime时,Flink对应调用TumblingEventTimeWindows;如果我们基于TimeCharacteristic.ProcessingTime,Flink使用TumblingProcessingTimeWindows。
滑动窗口
滑动窗口以一个步长(Slide)不断向前滑动,窗口的长度固定。使用时,我们要设置Slide和Size。Slide的大小决定了Flink以多大的频率来创建新的窗口,Slide较小,窗口的个数会很多。Slide小于窗口的Size时,相邻窗口会重叠,一个事件会被分配到多个窗口;Slide大于Size,有些事件可能被丢掉。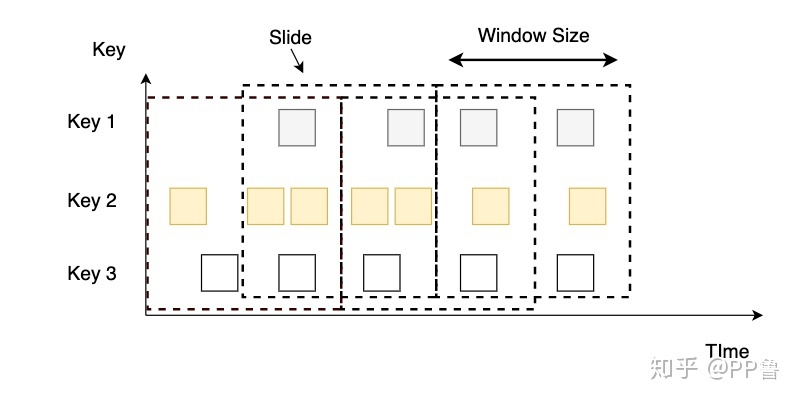
跟前面介绍的一样,我们使用Time类中的时间单位来定义Slide和Size,也可以设置offset。同样,timeWindow是一种缩写,根据执行环境中设置的时间语义来选择相应的方法初始化窗口。
al input: DataStream[T] = ...// sliding event-time windowsinput.keyBy(...).window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5))).<window function>(...)// sliding processing-time windowsinput.keyBy(<...>).window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5))).<window function>(...)// sliding processing-time windows offset by -8 hoursinput.keyBy(<...>).window(SlidingProcessingTimeWindows.of(Time.hours(12), Time.hours(1), Time.hours(-8))).<window function>(...)
会话窗口
会话窗口根据Session gap切分不同的窗口,当一个窗口在大于Session gap的时间内没有接收到新数据时,窗口将关闭。在这种模式下,窗口的长度是可变的,每个窗口的开始和结束时间并不是确定的。我们可以设置定长的Session gap,也可以使用SessionWindowTimeGapExtractor动态地确定Session gap的长度。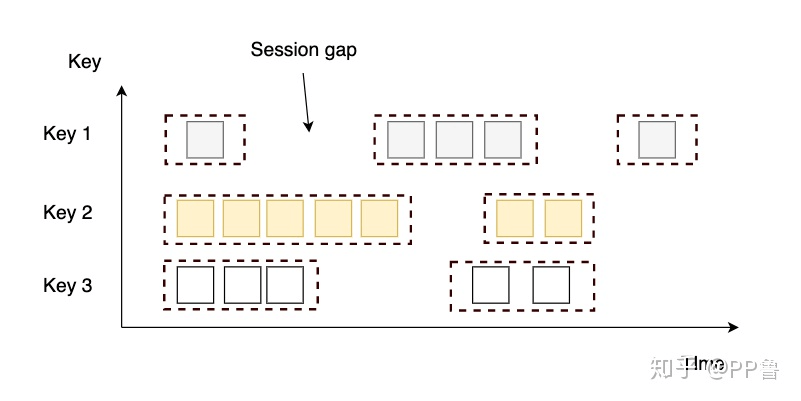
下面的代码展示了如何使用定长和可变的Session gap来建立会话窗口,其中SessionWindowTimeGapExtractor[T]的泛型T为数据流的类型,我们可以根据数据流中的元素来生成Session gap。
val input: DataStream[T] = ...// event-time session windows with static gapinput.keyBy(...).window(EventTimeSessionWindows.withGap(Time.minutes(10))).<window function>(...)// event-time session windows with dynamic gapinput.keyBy(...).window(EventTimeSessionWindows.withDynamicGap(new SessionWindowTimeGapExtractor[T] {override def extract(element: T): Long = {// determine and return session gap}})).<window function>(...)// processing-time session windows with static gapinput.keyBy(...).window(ProcessingTimeSessionWindows.withGap(Time.minutes(10))).<window function>(...)// processing-time session windows with dynamic gapinput.keyBy(...).window(DynamicProcessingTimeSessionWindows.withDynamicGap(new SessionWindowTimeGapExtractor[T] {override def extract(element: T): Long = {// determine and return session gap}})).<window function>(...)
数据经过了window和WindowAssigner之后,已经被分配到不同的窗口里,接下来,我们要通过窗口函数,在每个窗口上对窗口内的数据进行处理。窗口函数主要分为两种,一种是增量计算,如reduce和aggregate,一种是全量计算,如process。增量计算指的是窗口保存一份中间数据,每流入一个新元素,新元素与中间数据两两合一,生成新的中间数据,再保存到窗口中。全量计算指的是窗口先缓存该窗口所有元素,等到触发条件后对窗口内的全量元素执行计算。
ReduceFunction
使用reduce算子时,我们要重写一个ReduceFunction。ReduceFunction在DataStream API: keyBy、reduce和aggregations一文中已经介绍,它接受两个相同类型的输入,生成一个输出,即两两合一地进行汇总操作,生成一个同类型的新元素。在窗口上进行reduce的原理与之类似,只不过多了一个窗口状态数据,这个状态数据的数据类型和输入的数据类型是一致的,是之前两两计算的中间结果数据。当数据流中的新元素流入后,ReduceFunction将中间结果和新流入数据两两合一,生成新的数据替换之前的状态数据。
case class StockPrice(symbol: String, price: Double)val input: DataStream[StockPrice] = ...senv.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime)// reduce的返回类型必须和输入类型StockPrice一致val sum = input.keyBy(s => s.symbol).timeWindow(Time.seconds(10)).reduce((s1, s2) => StockPrice(s1.symbol, s1.price + s2.price))
上面的代码使用Lambda表达式对两个元组进行操作,由于对symbol字段进行了keyBy,相同symbol的数据都分组到了一起,接着我们将price加和,返回的结果必须也是StockPrice类型,否则会报错。
使用reduce的好处是窗口的状态数据量非常小,实现一个ReduceFunction也相对比较简单,可以使用Lambda表达式,也可以重写函数。缺点是能实现的功能非常有限,因为中间状态数据的数据类型、输入类型以及输出类型三者必须一致,而且只保存了一个中间状态数据,当我们想对整个窗口内的数据进行操作时,仅仅一个中间状态数据是远远不够的。
AggregateFunction
AggregateFunction也是一种增量计算窗口函数,也只保存了一个中间状态数据,但AggregateFunction使用起来更复杂一些。我们看一下它的源码定义:

若有收获,就点个赞吧
0 人点赞
