- 基本介绍
- 简单介绍一下flink
- todo SparkStream 与 Strom,Flink 与什么区别
- flink和spark streaming区别
- Flink 集群有哪些角色?各自有什么作用?
- 公司怎么提交的实时任务,有多少 Job Manager?
- Flink 的并行度了解吗?Flink 的并行度设置是怎样的?
- Checkpoint机制原理剖析与参数配置
- flink on yarn 的任务提交流程?
- todo flink runtime各个图转换
- todo 画出 flink 执行时的流程图。
- todo Flink 的 CBO,物理执行计划和逻辑执行计划
- Flink 的时间语义
- 说说 Flink 中的窗口
- Flink 是如何实现流批统一的?你在项目中用到过吗?
- 容错及精准一次语义
- flink 端到端精准一次的实现过程
- | Flink+Kafka 保证精确一次消费相关问题
- | flink 容错机制
- | barries
- | 讲一讲 Flink 的分界线对齐原理,有什么作用?
- | Exactly-Once 的保证
- | 说一下 Flink 状态机制,flink 如何保证数据不丢失的
- | Flink 分布式快照的原理是什么
- todo 讲一讲 Spark 和 Flink 的 Checkpoint 机制异同
- checkpoint 大小 多少, 怎么监控的
- 如何排查 Checkpoint 异常问题
- todo flink 用 rocksDB 状态后端会有什么 bug()?
- Flink RocksDB 状态后端参数调优实践
- 了解过 Flink 的两阶段提交策略吗?讲讲详细过程。如果第一阶段宕机了会怎么办?第二阶段呢?
- | flink 实现了两段锁协议,保证数据精准性一次性消费,两段锁协议需要细说
- todo Flink 使用过保存点吗?有哪些需要注意的细节
- Flink 中的 Watermark 机制
- todo Flink 是怎么处理迟到数据的?但是实际开发中不能有数据迟到,怎么做?
- todo Flink 延迟和异常的数据怎么处理
- 算子
- todo 多流 Join 水位线怎么确定
- Flink 中的 watermark 除了处理乱序数据还有其他作用吗?
- 介绍一下 Flink 的 CEP 机制
- Flink CEP 编程中当状态没有到达的时候会将数据保存在哪里?
- todo Slot Sharing Group概念
- 数据倾斜
- 说说 Flink 中的 keyState 包含哪些数据结构
- Yarn 调度策略
- 你们的 Flink 怎么提交的?使用的 per-job 模式吗?为什么使用 Yarn-Session 的模式?有什么好处?
- todo flink 中你最常用的算子有哪些
- flink 中的双流 join
- flink 中的双流 join中watermark如何取
- flink 中的双流 join 与 spark 中的双流 join
- Flink 的 Join 类算子有哪些,Flink 流处理怎么实现两个流的 Join 的
- flink 的异步 join 有了解吗?就是例如 kafka 和 mysql 的流进行 join
- flink 的 boardcast join 的原理是什么?
- flink 的双流 join 你们用的时候是 类似数据中的 left join 还是 inner join,双流 join中怎么确定左表还是右表【没太懂,好像应该是 full join】
- flink 的双流 join 有什么问题?写代码实现 interval join 的功能,怎么实现?你设置这个时间不会有数据丢失?
- flink 维表关联怎么做的
- Flink 为什么用 aggregate()不用 process()
- Operator Chains(算子链)这个概念你了解吗?
- 什么情况下才会把Operator chain在一起形成算子链?
- Flink 分区策略
- flink 的广播
- todo flink 写过自定义的一些消息队列,如何写的?
- 运维、优化及其他
- flink 支持的数据类型
- Flink 的序列化
- todo Flink 有没有试过优化
- Flink 内存溢出怎么办
- Flink 的重启策略
- flink主要版本比较
- Flink 监控怎么做的?
- todo Flink 看过哪些源码?
- Flink 关闭后状态端数据恢复得慢怎么办?
- 假设系统 A 实时发送给系统 b 全量的数据,系统 b 需要给系统 c 按照增量更新的方式提供系统 A 发送的数据。如何用 flink 实现该功能。
- flink 每秒数据量多大
- 有没有关注你的 jar 包的处理性能,就是处理 kafka 的 qps 和 tps?
- 你们有用过 flink 的背压吗,怎么做优化还是调整?
- todo 你们 100W 的日活,每天这套体系这套系统能够处理的上限产生延迟最大的支撑时间范围是多少?有没有关注到?
- 你们之前有没有遇到过 flink 数据丢失的情况
- 你们 flink 输出的目标数据库是什么,答看需求到 es 或者 mysql 需要自定义mysqlsink,他问自定义 mysqlsink 里面实际上是 jdbc 做的?你们有没有发现用 jdbc 并发的写mysql 他的性能很差,怎么处理的?
- todo 聊聊 flink 的了解 用过 cep 吗 cep 连续事件的可选项有什么 讲讲你用 cep 做过的业务逻辑
- cep 底层如何工作
- todo cep 怎么老化 cep 性能调优 过期数据怎么处理
- acid,acp,base
- todo 实例
- 有三个 map,一个 reduce 来做 top10,哪种方法最优。数据量特别大。
- 怎么从10亿条数据中计算 TOPN?
- 如何做实时 TopN
- 如何将实时数据与一张大表 join
- todo 如何通过 flink 实现 uv 的
- 实时 GMV 统计,中间状态(状态计算)怎么存储的?
- 如何通过 flink 的 CEP 来实现支付延迟提醒
- todo Flink 上有多少个指标,一个指标一个 jar 包吗?Flink 亲自负责的有几个 jar 包产出?
- flink 的 source 端断了,比如 kafka 出故障,没有数据发过来,怎么处理?用 flink 实时流实现了什么功能?
- flink代码实现日活
- Flink 项目遇到过什么难题,怎么解决的
- 你用 Flink 开发做过最复杂的场景是什么。
- todo flink10s 做一次缓存会不会有影响
- Flink 怎么删掉数据(数据太多了要删掉一些)?
- Flink 怎么实时增加表字段(好像是说形成一个数仓那样的宽表必须是实时的)?
- Flink调优法则
基本介绍
Flink面试题大全(建议收藏):https://blog.csdn.net/a934079371/article/details/108250658
Flink面试题整理,全是干货,自己整理的:https://blog.csdn.net/qq_31866793/article/details/102393050
Flink面试题:https://zhuanlan.zhihu.com/p/138101642
尚硅谷大数据高频面试题文件。
简单介绍一下flink
Flink 是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。并且 Flink 提供了数据分布、容错机制以及资源管理等核心功能。 Flink 提供了诸多高抽象层的 API 以便用户编写分布式任务:
DataSet API, 对静态数据进行批处理操作,将静态数据抽象成分布式的数据集,用户可以方便地使用 Flink 提供的各种操作符对分布式数据集进行处理,支持 Java、 Scala 和 Python。
DataStream API,对数据流进行流处理操作,将流式的数据抽象成分布式的数据流,用户可以方便地对分布式数据流进行各种操作,支持 Java 和 Scala。
Table API,对结构化数据进行查询操作,将结构化数据抽象成关系表,并通过类 SQL 的 DSL 对关系表进行各种查询操作,支持 Java 和 Scala。
此外, Flink 还针对特定的应用领域提供了领域库,例如: Flink ML, Flink 的机器学习库,提供了机器学习Pipelines API 并实现了多种机器学习算法。 Gelly, Flink 的图计算库,提供了图计算的相关 API 及多种图计算算法实现。
todo SparkStream 与 Strom,Flink 与什么区别
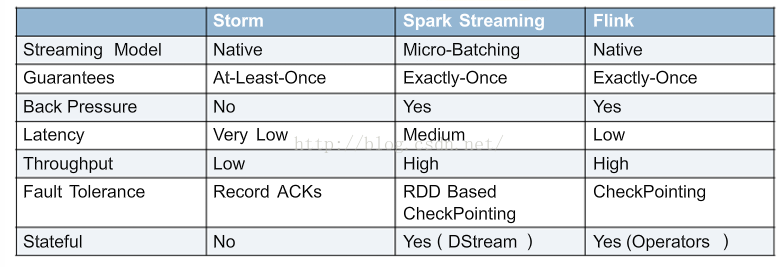
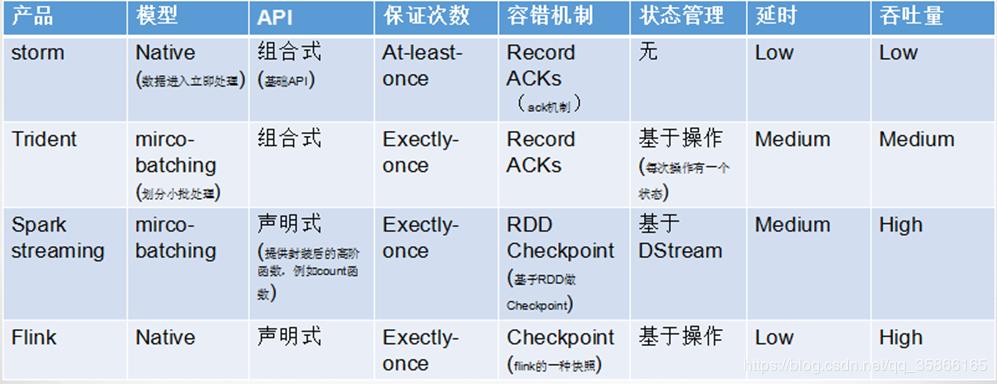
flink和spark streaming区别
这个问题是一个非常宏观的问题,因为两个框架的不同点非常之多。但是在面试时有非常重要的一点一定要回答出来: Flink 是标准的实时处理引擎,基于事件驱动。而 Spark Streaming 是微批(Micro-Batch)的模型。
下面我们就分几个方面介绍两个框架的主要区别:
1)架构模型 Spark Streaming 在运行时的主要角色包括:Master、Worker、Driver、Executor,Flink 在运行时主要包含:Jobmanager、Taskmanager 和 Slot。
2)任务调度 Spark Streaming 连续不断的生成微小的数据批次,构建有向无环图 DAG,Spark Streaming 会依次创建 DStreamGraph、JobGenerator、JobScheduler。Flink 根据用户提交的代码生成 StreamGraph,经过优化生成JobGraph,然后提交给 JobManager 进行处理,JobManager 会根据 JobGraph 生成 ExecutionGraph,ExecutionGraph 是 Flink 调度最核心的数据结构,JobManager 根据 ExecutionGraph 对 Job 进行调度。
3)时间机制 Spark Streaming 支持的时间机制有限,只支持处理时间。 Flink 支持了流处理程序在时间上的三个定义:处理时间、事件时间、注入时间。同时也支持 watermark 机制来处理滞后数据。
4)容错机制对于 Spark Streaming 任务,我们可以设置 checkpoint,然后假如发生故障并重启,我们可以从上次 checkpoint 之处恢复,但是这个行为只能使得数据不丢失,可能会重复处理,不能做到恰好一次处理语义。Flink 则使用两阶段提交协议来解决这个问题。
Flink 集群有哪些角色?各自有什么作用?
Flink 程序在运行时主要有 TaskManager,JobManager,Client、cluster management、dispatcher、resourceManager等。
- JobManager 扮演着集群中的管理者 Master 的角色,它是整个集群的协调者,负责接收 Flink Job,协调检查点,Failover 故障恢复等,同时管理 Flink 集群中从节点 TaskManager。
- TaskManager 是实际负责执行计算的 Worker,在其上执行 Flink Job 的一组 Task,每个 TaskManager 负责管理其所在节点上的资源信息,如内存、磁盘、网络,在启动的时候将资源的状态向 JobManager 汇报。
Client 是 Flink 程序提交的客户端,当用户提交一个 Flink 程序时,会首先创建一个 Client,该 Client 首先会对用户提交的 Flink 程序进行预处理,并提交到 Flink 集群中处理,所以 Client 需要从用户提交的 Flink 程序配置中获取 JobManager 的地址,并建立到 JobManager 的连接,将 Flink Job 提交给 JobManager。
cluster management:集群资源管理器
- dispatcher:
- 集群job的调度分发
- 接收客户端提交的jobGraph作业,然后实例化出来JobManager
- resourceManager:
- 负责整个集群层面的资源管理
- 适配不同的资源管理
- 主要是slot,有slotManager,集中管理所有taskManager的slot资源。
公司怎么提交的实时任务,有多少 Job Manager?
1)我们使用 yarn session 模式提交任务;另一种方式是每次提交都会创建一个新的 Flink 集群,为每一个 job 提供资源,任务之间互相独立,互不影响,方便管理。任务执行完成之后创建的集群也会消失。线上命令脚本如下:
bin/yarn-session.sh -n 7 -s 8 -jm 3072 -tm 32768 -qu root.. -nm - -d
其中申请 7 个 taskManager,每个 8 核,每个 taskmanager 有 32768M 内存。
2)集群默认只有一个 Job Manager。但为了防止单点故障,我们配置了高可用。对于 standlone 模式,我们公司一般配置一个主 Job Manager,两个备用 Job Manager,然后结合 ZooKeeper 的使用,来达到高可用;对于 yarn模式,yarn 在 Job Mananger 故障会自动进行重启,所以只需要一个,我们配置的最大重启次数是 10 次。Flink 的并行度了解吗?Flink 的并行度设置是怎样的?
Flink 中的任务被分为多个并行任务来执行,其中每个并行的实例处理一部分数据。这些并行实例的数量被称为并行度。我们在实际生产环境中可以从四个不同层面设置并行度:
操作算子层面(Operator Level)
执行环境层面(Execution Environment Level)
客户端层面(Client Level)
系统层面(System Level)
需要注意的优先级:算子层面>环境层面>客户端层面>系统层面。Checkpoint机制原理剖析与参数配置
https://zhuanlan.zhihu.com/p/104601440flink on yarn 的任务提交流程?
https://www.yuque.com/shawndanger/bigdata/npwupm#tW5cjtodo flink runtime各个图转换
todo 画出 flink 执行时的流程图。
todo Flink 的 CBO,物理执行计划和逻辑执行计划
Flink的优化执行其实是借鉴的数据库的优化器来生成的执行计划。
CBO,成本优化器,代价最小的执行计划就是最好的执行计划。传统的数据库,成本优化器做出最优化的执行计划是依据统计信息来计算的。Flink 的成本优化器也一样。Flink 在提供最终执行前,优化每个查询的执行逻辑和物理执行计划。这些优化工作是交给底层来完成的。根据查询成本执行进一步的优化,从而产生潜在的不同决策:如何排序连接,执行哪种类型的连接,并行度等等。
Flink 的时间语义
Event Time:是事件创建的时间。它通常由事件中的时间戳描述,例如采集的日志数据中,每一条日志都会记录自己的生成时间,Flink 通过时间戳分配器访问事件时间戳。
Ingestion Time:是数据进入 Flink 的时间。
Processing Time:是每一个执行基于时间操作的算子的本地系统时间,与机器相关,默认的时间属性就是Processing Time。
说说 Flink 中的窗口
Flink 支持三种划分窗口的方式,按照 time 和 count。如果根据时间划分窗口,那么它就是一个 time-window 如果根据数据划分窗口,那么它就是一个 count-window。flink 支持窗口的两个重要属性(size 和 interval)如果size=interval,那么就会形成 tumbling-window(无重叠数据) 如果 size>interval,那么就会形成 sliding-window(有重叠数据) 如果 size< interval, 那么这种窗口将会丢失数据。比如每 5 秒钟,统计过去 3 秒的通过路口汽车的数据,将会漏掉 2 秒钟的数据。通过组合可以得出四种基本窗口:
time-tumbling-window 无重叠数据的时间窗口,设置方式举例:timeWindow(Time.seconds(5))
time-sliding-window 有重叠数据的时间窗口,设置方式举例:timeWindow(Time.seconds(5), Time.seconds(3))
count-tumbling-window 无重叠数据的数量窗口,设置方式举例:countWindow(5)
count-sliding-window 有重叠数据的数量窗口,设置方式举例:countWindow(5,3)
还有一种根据时间划分的窗口是session window,根据是否再一次会话内区分窗口,即多久没有活动即可通过session gap(缺口)分割窗口
Flink 是如何实现流批统一的?你在项目中用到过吗?
容错及精准一次语义
flink 端到端精准一次的实现过程
https://zhuanlan.zhihu.com/p/108570573
| Flink+Kafka 保证精确一次消费相关问题
| flink 容错机制
| barries
| 讲一讲 Flink 的分界线对齐原理,有什么作用?
| Exactly-Once 的保证
下级存储支持事务:Flink 可以通过实现两阶段提交和状态保存来实现端到端的一致性语义。 分为以下几个步
1)开始事务(beginTransaction)创建一个临时文件夹,来写把数据写入到这个文件夹里面
2)预提交(preCommit)将内存中缓存的数据写入文件并关闭
3)正式提交(commit)将之前写完的临时文件放入目标目录下。这代表着最终的数据会有一些延迟
4)丢弃(abort)丢弃临时文件
5)若失败发生在预提交成功后,正式提交前。可以根据状态来提交预提交的数据,也可删除预提交的数据。
下级存储不支持事务:
具体实现是幂等写入,需要下级存储具有幂等性写入特性。
| 说一下 Flink 状态机制,flink 如何保证数据不丢失的
Flink 在做计算的过程中经常需要存储中间状态,来避免数据丢失和状态恢复。选择的状态存储策略不同,会影响状态持久化如何和 checkpoint 交互。
Flink 提供了三种状态存储方式:MemoryStateBackend、FsStateBackend、RocksDBStateBackend。
| Flink 分布式快照的原理是什么
Flink 的容错机制的核心部分是制作分布式数据流和操作算子状态的一致性快照。 这些快照充当一致性checkpoint,系统可以在发生故障时回滚。 Flink 用于制作这些快照的机制在“分布式数据流的轻量级异步快照”中进行了描述。 它受到分布式快照的标准 Chandy-Lamport 算法的启发,专门针对 Flink 的执行模型而定制。
barriers 在数据流源处被注入并行数据流中。快照 n 的 barriers 被插入的位置(我们称之为 Sn)是快照所包含的数据在数据源中最大位置。
例如,在 Apache Kafka 中,此位置将是分区中最后一条记录的偏移量。 将该位置 Sn 报告给 checkpoint 协调器(Flink 的 JobManager)。
然后 barriers 向下游流动。当一个中间操作算子从其所有输入流中收到快照 n 的 barriers 时,它会为快照 n 发出barriers 进入其所有输出流中。
一旦 sink 操作算子(流式 DAG 的末端)从其所有输入流接收到 barriers n,它就向 checkpoint 协调器确认快照n 完成。
在所有 sink 确认快照后,意味快照着已完成。一旦完成快照 n,job 将永远不再向数据源请求 Sn 之前的记录,因为此时这些记录(及其后续记录)将已经通过整个数据流拓扑,也即是已经被处理结束。
todo 讲一讲 Spark 和 Flink 的 Checkpoint 机制异同
checkpoint 大小 多少, 怎么监控的
kb或mb,在flink web页面上的checkpoints
如何排查 Checkpoint 异常问题
https://www.jianshu.com/p/5ed18ab7fe3d
todo flink 用 rocksDB 状态后端会有什么 bug()?
Flink RocksDB 状态后端参数调优实践
https://zhuanlan.zhihu.com/p/256351671
了解过 Flink 的两阶段提交策略吗?讲讲详细过程。如果第一阶段宕机了会怎么办?第二阶段呢?
Flink两阶段提交:https://blog.csdn.net/lisenyeahyeah/article/details/90288231
| flink 实现了两段锁协议,保证数据精准性一次性消费,两段锁协议需要细说
todo Flink 使用过保存点吗?有哪些需要注意的细节
Flink 中的 Watermark 机制
Watermark 是一种衡量 Event Time 进展的机制,可以设定延迟触发
Watermark 是用于处理乱序事件的,而正确的处理乱序事件,通常用 Watermark 机制结合 window 来实现;
数据流中的 Watermark 用于表示 timestamp 小于 Watermark 的数据,都已经到达了,因此,window 的执行也是由 Watermark 触发的。
todo Flink 是怎么处理迟到数据的?但是实际开发中不能有数据迟到,怎么做?
todo Flink 延迟和异常的数据怎么处理
算子
todo 多流 Join 水位线怎么确定
Flink 中的 watermark 除了处理乱序数据还有其他作用吗?
介绍一下 Flink 的 CEP 机制
CEP 全称为 Complex Event Processing,复杂事件处理
Flink CEP 是在 Flink 中实现的复杂事件处理(CEP)库
CEP 允许在无休止的事件流中检测事件模式,让我们有机会掌握数据中重要的部分
一个或多个由简单事件构成的事件流通过一定的规则匹配,然后输出用户想得到的数据 —— 满足规则的复杂事件
Flink CEP 编程中当状态没有到达的时候会将数据保存在哪里?
在流式处理中,CEP 当然是要支持 EventTime 的,那么相对应的也要支持数据的迟到现象,也就是 watermark的处理逻辑。CEP 对未匹配成功的事件序列的处理,和迟到数据是类似的。在 Flink CEP 的处理逻辑中,状态没有满足的和迟到的数据,都会存储在一个 Map 数据结构中,也就是说,如果我们限定判断事件序列的时长为 5 分钟,那么内存中就会存储 5 分钟的数据,这在我看来,也是对内存的极大损伤之一。
todo Slot Sharing Group概念
Slot Sharing Group
Set the slot sharing group of an operation. Flink will put operations with the same slot sharing group into the same slot while keeping operations that don’t have the slot sharing group in other slots. This can be used to isolate slots. The slot sharing group is inherited from input operations if all input operations are in the same slot sharing group. The name of the default slot sharing group is “default”, operations can explicitly be put into this group by calling slotSharingGroup(“default”).
设置操作的槽位共享组。Flink将把具有相同槽共享组的操作放在相同槽中,而将没有槽共享组的操作放在其他槽中。这可以用来隔离槽。如果所有的输入操作都在同一个槽位共享组中,则从输入操作继承槽位共享组。默认槽位共享组的名称为“default”,可以通过调用slotSharingGroup(“default”)显式地将操作放入该组。
数据倾斜
flink 数据倾斜问题解决方案:https://zhuanlan.zhihu.com/p/365136566
说说 Flink 中的 keyState 包含哪些数据结构
flink的六大keyState:https://blog.csdn.net/qq_44962429/article/details/104428236
Flink 的 Keyed State 支持以下数据类型:
ValueState[T]保存单个的值,值的类型为 T。
get 操作: ValueState.value()
set 操作: ValueState.update(value: T)
ListState[T]保存一个列表,列表里的元素的数据类型为 T基本操作如下:
ListState.add(value: T)
ListState.addAll(values: java.util.List[T])
ListState.get()返回 Iterable[T]
ListState.update(values: java.util.List[T])
MapState[K, V]保存 Key-Value 对。
MapState.get(key: K)
MapState.put(key: K, value: V)
MapState.contains(key: K)
MapState.remove(key: K)
ReducingState[T]
AggregatingState[I, O]
FoldingState
State.clear()是清空操作。
Yarn 调度策略
FIFO Scheduler、Capacity Scheduler、Fair Scheduler
https://www.yuque.com/shawndanger/bigdata/iqyd80#EbQCZ
你们的 Flink 怎么提交的?使用的 per-job 模式吗?为什么使用 Yarn-Session 的模式?有什么好处?
小任务用yarn-session,节省资源;大任务用per-job,资源充足且隔离。
todo flink 中你最常用的算子有哪些
map、
flatmap、
Filter、
Reduce、
window、windowAll、window Apply、windowReduce、
union、
window join、interval join、
connect、
官网:https://nightlies.apache.org/flink/flink-docs-release-1.14/zh/docs/dev/datastream/operators/overview/
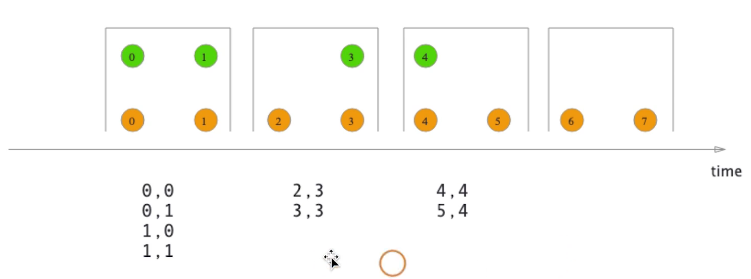
flink 中的双流 join
- window join
- 窗口类型一样(每个窗口进行全连接)
left 、right、inner可以通过不同的join function去实现
- tumbling window join
- sliding window join
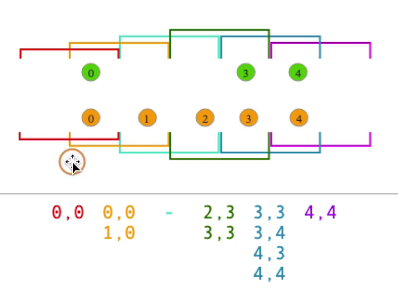
- session window join
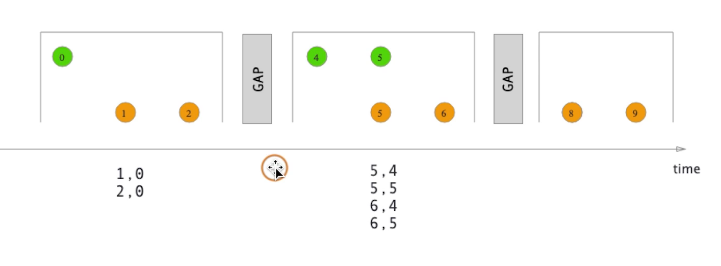
- interval join
目前只提供event time
每个window会同时缓存两股流里的元素,然后在两股数据流的元素上面做join,比较消耗存储空间,记得删除不用的数据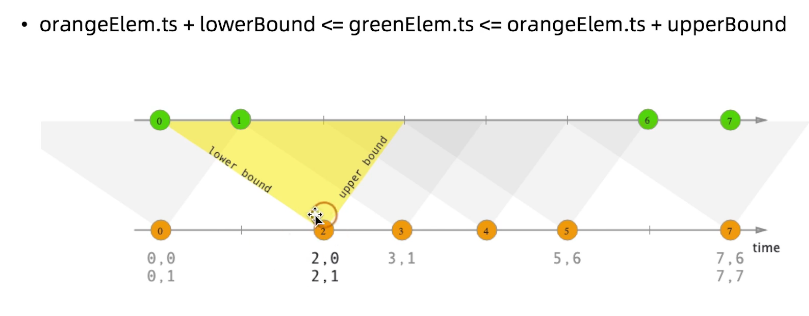
flink 中的双流 join中watermark如何取
flink 中的双流 join 与 spark 中的双流 join
Flink 的 Join 类算子有哪些,Flink 流处理怎么实现两个流的 Join 的
flink 的异步 join 有了解吗?就是例如 kafka 和 mysql 的流进行 join
异步join如何保证有序:https://www.jianshu.com/p/2543ee8c1fa4
会有一个队列维护顺序,使用hascomplete确保出队的完成才会进行下一个。
flink 的 boardcast join 的原理是什么?
flink 的双流 join 你们用的时候是 类似数据中的 left join 还是 inner join,双流 join中怎么确定左表还是右表【没太懂,好像应该是 full join】
flink 的双流 join 有什么问题?写代码实现 interval join 的功能,怎么实现?你设置这个时间不会有数据丢失?
会有数据join不上,watermask时间调大或者对迟到的数据单独去接受或者使用interval join
谈谈Flink DataStream API中的三种双流join操作,以及interval join的原理:https://www.jianshu.com/p/45ec888332df
清除的是mapState状态命名空间,然后根据状态的时间戳去清除状态(存在不同状态容器则清除不同的数据)
flink 维表关联怎么做的
https://blog.csdn.net/u012554509/article/details/100533749
Flink 为什么用 aggregate()不用 process()
aggregate: 增量聚合
process: 全量聚合
当计算累加操作时候可以使用aggregate操作。
当计算窗口内全量数据的时候使用process,例如排序等操作。
Operator Chains(算子链)这个概念你了解吗?
为了更高效地分布式执行,Flink会尽可能地将operator的subtask链接(chain)在一起形成task。每个task在一个线程中执行。将operators链接成task是非常有效的优化:它能减少线程之间的切换,减少消息的序列化/反序列化,减少数据在缓冲区的交换,减少了延迟的同时提高整体的吞吐量。这就是我们所说的算子链。
什么情况下才会把Operator chain在一起形成算子链?
- 上下游的并行度一致
- 下游节点的入度为1 (也就是说下游节点没有来自其他节点的输入)
- 上下游节点都在同一个 slot group 中(下面会解释 slot group)
- 下游节点的 chain 策略为 ALWAYS(可以与上下游链接,map、flatmap、filter等默认是ALWAYS)
- 上游节点的 chain 策略为 ALWAYS 或 HEAD(只能与下游链接,不能与上游链接,Source默认是HEAD)
- 两个节点间数据分区方式是 forward(参考理解数据流的分区)
-
Flink 分区策略
Flink分区策略:你可以不会,但不能不懂:https://zhuanlan.zhihu.com/p/399759920
flink 的广播
Flink使用广播实现配置动态更新:https://www.jianshu.com/p/c8c99f613f10
todo flink 写过自定义的一些消息队列,如何写的?
运维、优化及其他
flink 支持的数据类型
Java Tuples and Scala Case Classes
Java POJOs 实体类
Primitive Types 原始类型
Regular Classes 通用类
Values
Hadoop Writables
Special Types
Apache Flink 进阶(五):数据类型和序列化:https://blog.csdn.net/weixin_44904816/article/details/102694099Flink 的序列化
Apache Flink 进阶(五):数据类型和序列化:https://blog.csdn.net/weixin_44904816/article/details/102694099
todo Flink 有没有试过优化
Flink 内存溢出怎么办
看ui,哪部分内存占用太大,哪部分小,看日志。用top或jemalloc分析dump文件
Flink 的重启策略
https://www.jianshu.com/p/4be0fa07f29d
flink主要版本比较
https://zhuanlan.zhihu.com/p/427596069
Flink 监控怎么做的?
https://www.zhihu.com/question/490670208
todo Flink 看过哪些源码?
Flink 关闭后状态端数据恢复得慢怎么办?
https://www.cnblogs.com/bianqi/p/12183571.html
假设系统 A 实时发送给系统 b 全量的数据,系统 b 需要给系统 c 按照增量更新的方式提供系统 A 发送的数据。如何用 flink 实现该功能。
https://www.jianshu.com/p/02187f84f9a1
https://blog.csdn.net/weixin_43970890/article/details/109571650flink 每秒数据量多大
有没有关注你的 jar 包的处理性能,就是处理 kafka 的 qps 和 tps?
https://www.zhihu.com/question/421237964
你们有用过 flink 的背压吗,怎么做优化还是调整?
flink的背压问题产生原因和解决方法:https://www.jianshu.com/p/74c031b1ec29
todo 你们 100W 的日活,每天这套体系这套系统能够处理的上限产生延迟最大的支撑时间范围是多少?有没有关注到?
你们之前有没有遇到过 flink 数据丢失的情况
Flink写500亿/天数据到远端Kafka排错、Flink优化记录。:https://uzshare.com/view/835847
你们 flink 输出的目标数据库是什么,答看需求到 es 或者 mysql 需要自定义mysqlsink,他问自定义 mysqlsink 里面实际上是 jdbc 做的?你们有没有发现用 jdbc 并发的写mysql 他的性能很差,怎么处理的?
mysql 确保没有其他读写业务方的干扰
- 读写分离模式
- 其它业务排除
flink如果Job的数据量不大可以尝试单并发写入。但是在高QPS/TPS、高并发情况下,写入性能会降低。
mysql 根据业务特点做分库分表分区,尽可能避免单表写入,实施细节请联系对应的DBA。
- 尽可能不使用UniqueKey, 带UniqueKey(唯一主键)表的写入可能会导致死锁。如果业务要求表必须包含UniqueKey,请按照字段区分能力从大到小排列来定义UniqueKey,可大幅降低死锁出现概率。如一个md5值的区分能力大于day_time(20171010)。
mysql group批量提交
- flink批量大些写入
- mysql 连接池、长连接
- 减少大事务:insert、update提交频率稍快即可
[
](https://blog.csdn.net/weixin_34101914/article/details/113300002)
todo 聊聊 flink 的了解 用过 cep 吗 cep 连续事件的可选项有什么 讲讲你用 cep 做过的业务逻辑
cep 底层如何工作
FlinkCEP的底层理论:NFA-b Automaton原理介绍:https://blog.csdn.net/penriver/article/details/121824479
todo cep 怎么老化 cep 性能调优 过期数据怎么处理
acid,acp,base
https://baike.baidu.com/item/CAP%E5%8E%9F%E5%88%99/5712863?fr=aladdin
todo 实例
有三个 map,一个 reduce 来做 top10,哪种方法最优。数据量特别大。
怎么从10亿条数据中计算 TOPN?
海量数据处理 - 10亿个数中找出最大的10000个数(top K问题):https://blog.csdn.net/zyq522376829/article/details/47686867
如何做实时 TopN
Flink实时计算topN热榜
:https://www.cnblogs.com/data-magnifier/p/14520843.html
Flink 实现 实时TOPN 需求:https://www.cnblogs.com/yangxusun9/p/13170340.html
如何将实时数据与一张大表 join
flink实战—双流join之原理解析:http://www.360doc.com/content/19/0904/17/14808334_859110520.shtml
todo 如何通过 flink 实现 uv 的
实时 GMV 统计,中间状态(状态计算)怎么存储的?
Flink实战 - 统计每个店铺每日GMV:https://blog.csdn.net/m0_49826240/article/details/109704393
如何通过 flink 的 CEP 来实现支付延迟提醒
CEP监控下单付款超时通知:https://www.jianshu.com/p/4aef81468b6d
todo Flink 上有多少个指标,一个指标一个 jar 包吗?Flink 亲自负责的有几个 jar 包产出?
flink 的 source 端断了,比如 kafka 出故障,没有数据发过来,怎么处理?用 flink 实时流实现了什么功能?
会有报警、而且flink记录有kafka消费offset,最多故障重启任务,重新消费。,监控的kafka偏移量也就是LAG。
Flink 如何管理 Kafka 的消费偏移量:http://smartsi.club/how-flink-manages-kafka-consumer-offsets.html
flink代码实现日活
https://www.cnblogs.com/weijiqian/p/14034205.html
Flink 项目遇到过什么难题,怎么解决的
你用 Flink 开发做过最复杂的场景是什么。
todo flink10s 做一次缓存会不会有影响
Flink分布式缓存:https://www.cnblogs.com/linkmust/p/10902050.html
Flink 怎么删掉数据(数据太多了要删掉一些)?
Flink笔记-Evictors数据剔除:https://blog.csdn.net/yangxiaobo118/article/details/100056371
Flink 怎么实时增加表字段(好像是说形成一个数仓那样的宽表必须是实时的)?
Flink调优法则
https://zhuanlan.zhihu.com/p/306289347

若有收获,就点个赞吧
0 人点赞
