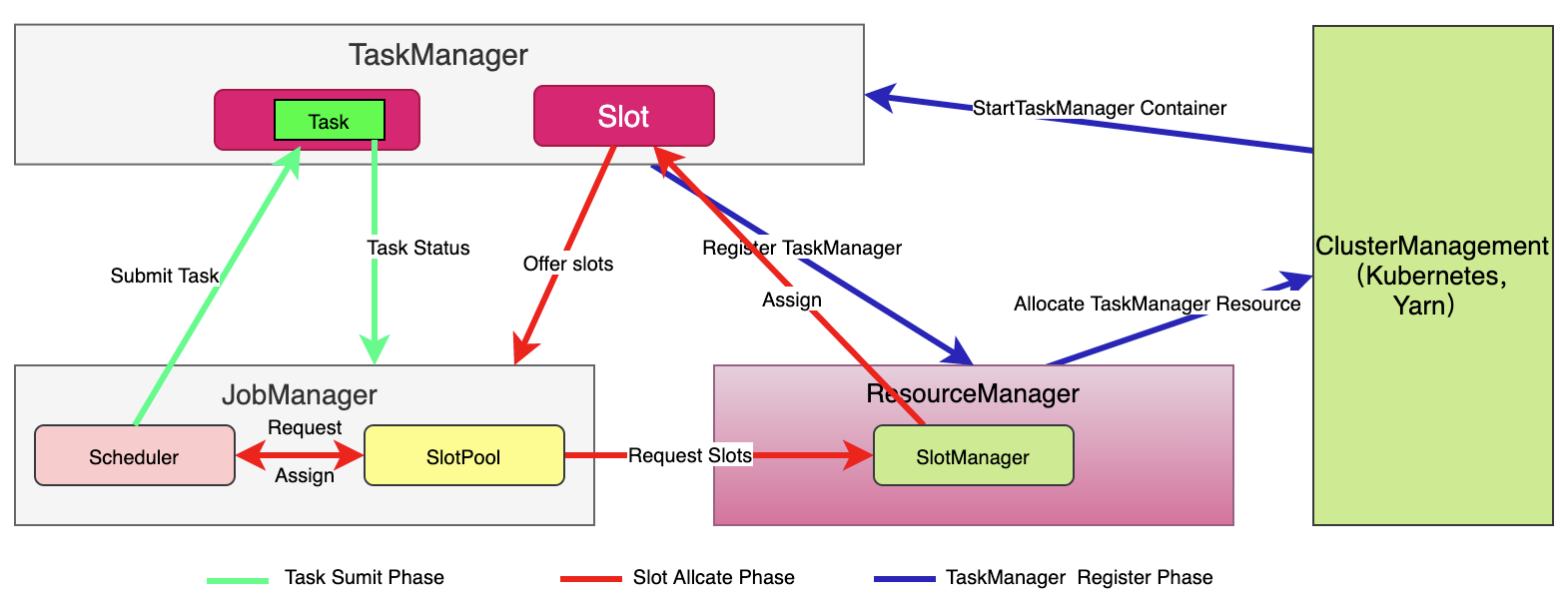
runtime整体架构
整体架构设计
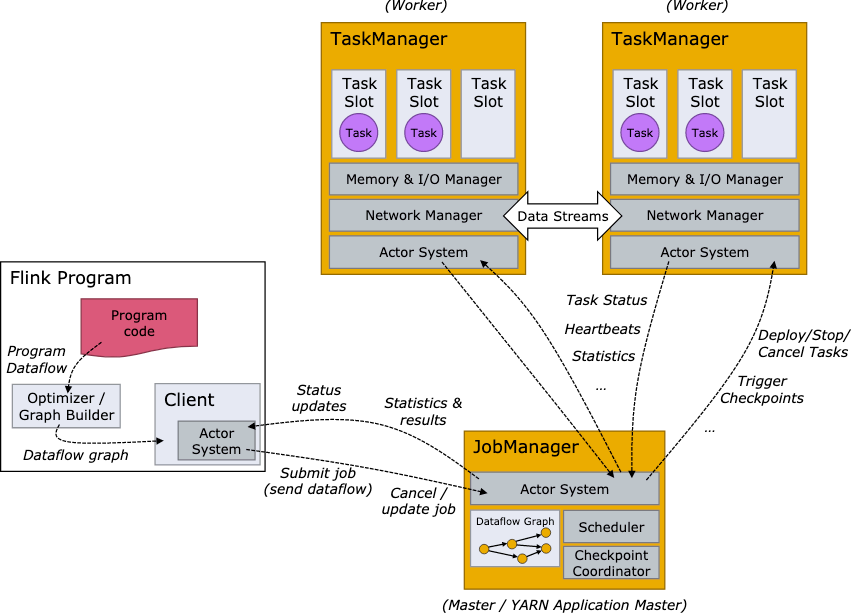
- cluster management:集群资源管理器
- dispatcher:
- 集群job的调度分发
- 接收客户端提交的jobGraph作业,然后实例化出来JobManager
- jobManager(JobMaster类):
- 负责管理一个具体的Job
- scheduler ng,把JobGraph产生的ExecutionGraph里面的Task,能够进行调度执行。发出资源请求。
- Slot Pool ,从ResourceManager申请过来的资源会存在里面,当我们再去跑一些任务的时候,可以优先通过资源池里面的资源进行分配
- 对每一个作业的管理节点,把jobGraph转换成executionGraph,然后再根据executionGraph进行对应的调度(利用本身的scheduler调度器,把executionGraph的Task调到TaskManager运行起来)
- resourceManager:
- 负责整个集群层面的资源管理
- 适配不同的资源管理
- 主要是slot,有slotManager,集中管理所有taskManager的slot资源。
- taskManager:
- Slot计算资源提供者
- 每次启动之后会把自己的资源注册到resourceManager里
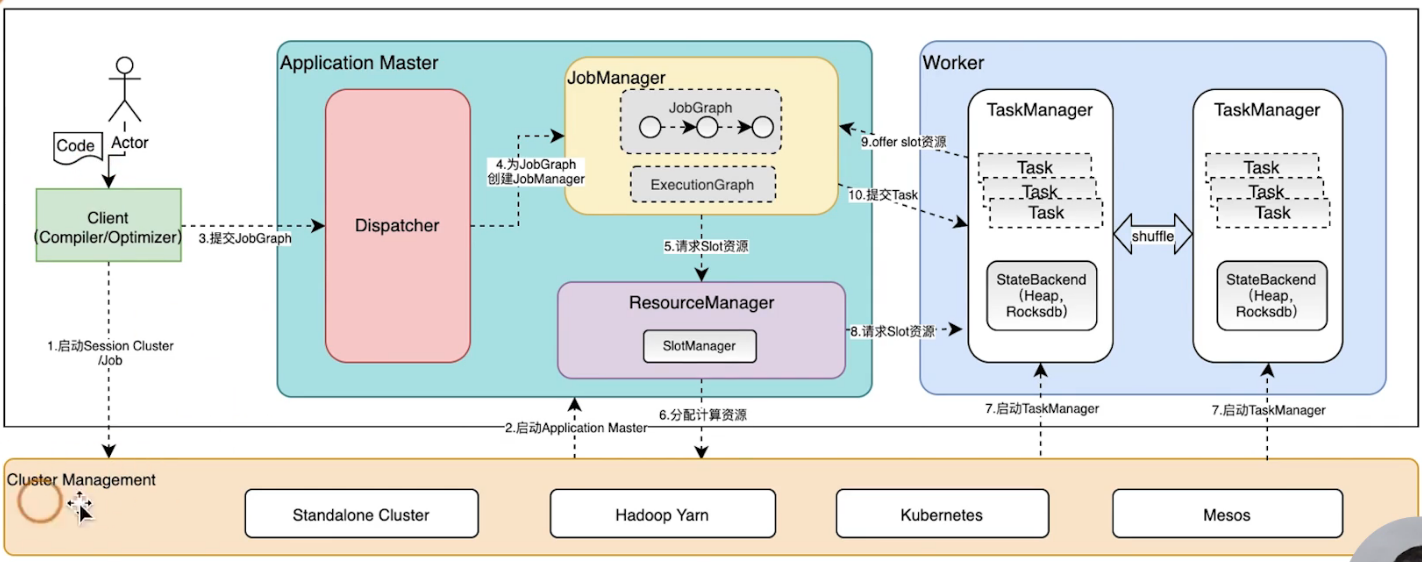
过程:
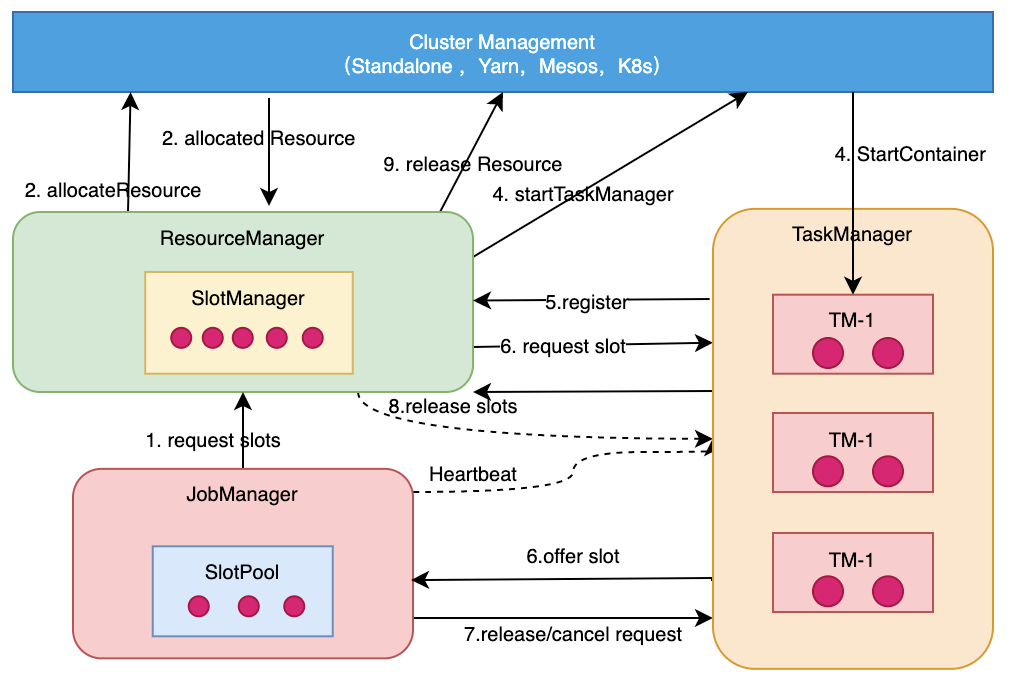
- 用户使用client提交作业
- 事先到Cluster Management启动Session Cluster/job
- client向cluster management申请资源(根据不同模式申请不同资源,yarn的container,k8s的pod),去启动application master
- 启动application master的时候dispatcher、resourceManager就会拉起来
- client提交jobGraph作业到dispatcher
- dispatcher为jobGraph创建JobManager
- 非native(standalone):job提交完成后JobManager会向ResourceManager请求slot资源,ResourceManager会直接返回slot资源到JobManager,这时候TaskManager会把相应的资源offer到JobManager,JobManager拿到slot资源(包含slot位置,位置本身包含TaskManager信息)后,会和Task一起提交到TaskManager上运行起来,这时候Task线程就会按照Slot的资源去启动,去创建相应的内存资源和CPU Core 的一些资源,这时候Task就可以运行起来
native:资源是按需分配的,TaskManager不用时候不启动,用的时候ResourceManager会到SlotManager找,没有就会到ClusterManagement申请,yarn的是container,k8s的是container即pod,申请完成后调用相应的脚本去启动相应的TaskManager,TaskManager会在相应的资源管理器(yarn、k8s)上启动相应的TaskManager实例,启动完成后会向ResourceManager注册,完成之后slot就在SlotManager里了,接下来就进行slot分配给JobManager的过程,最终作业就可以运行起来
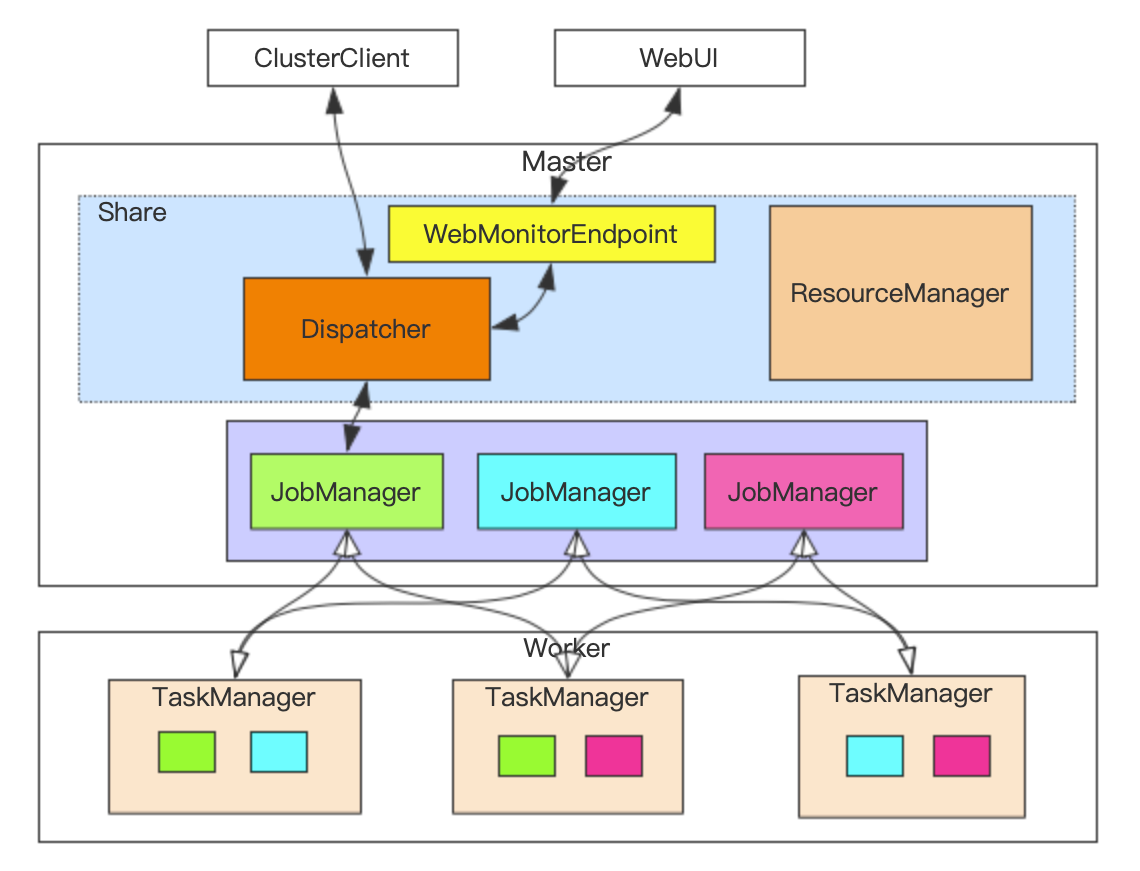
- runtime集群组件共享(主要有dispatcher、ResourceManager、WebMonitorEndpoint类似后台)
- 资源复用
-
per-job模式
runtime集群组件仅为单个Job服务
- 资源相对独立
-
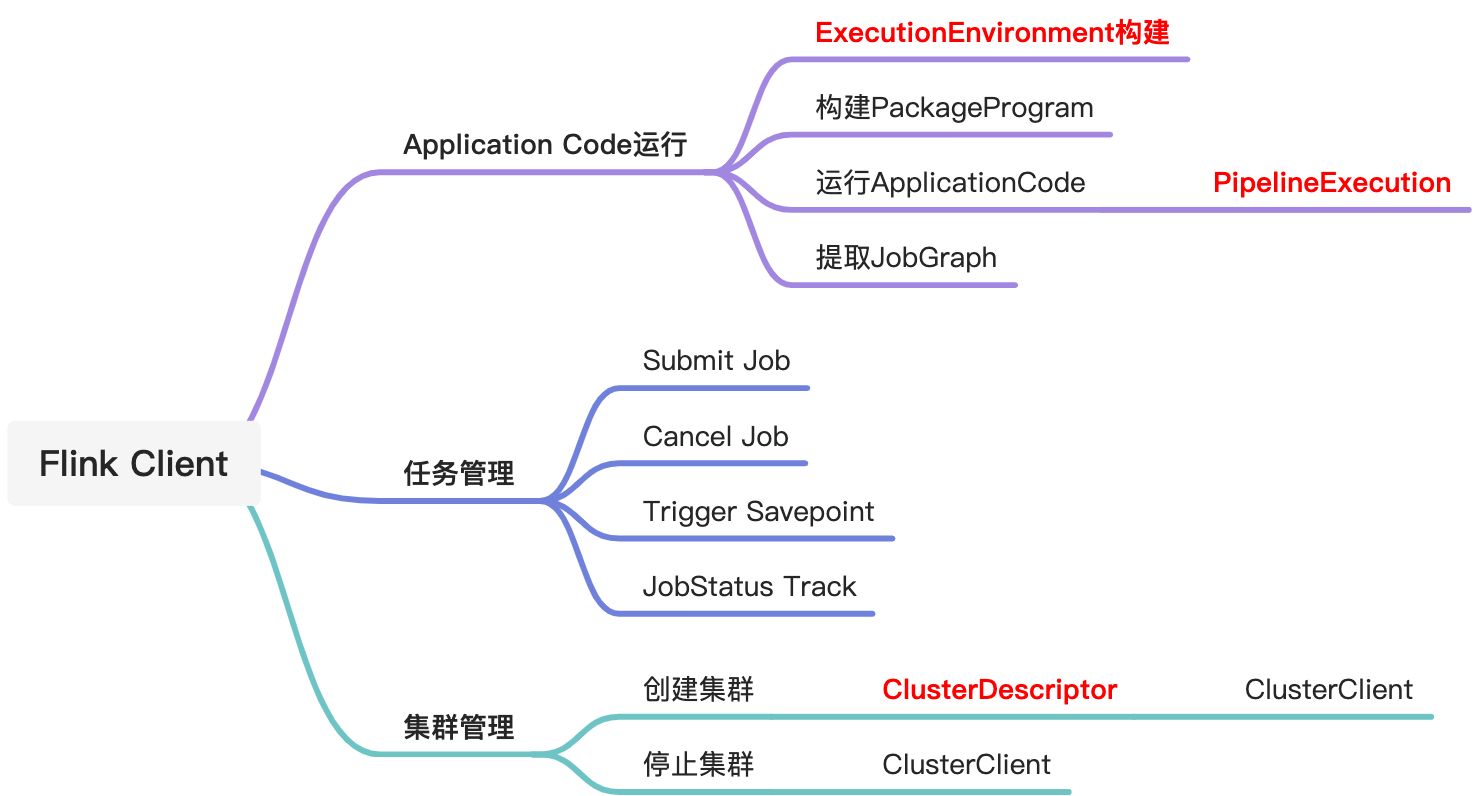
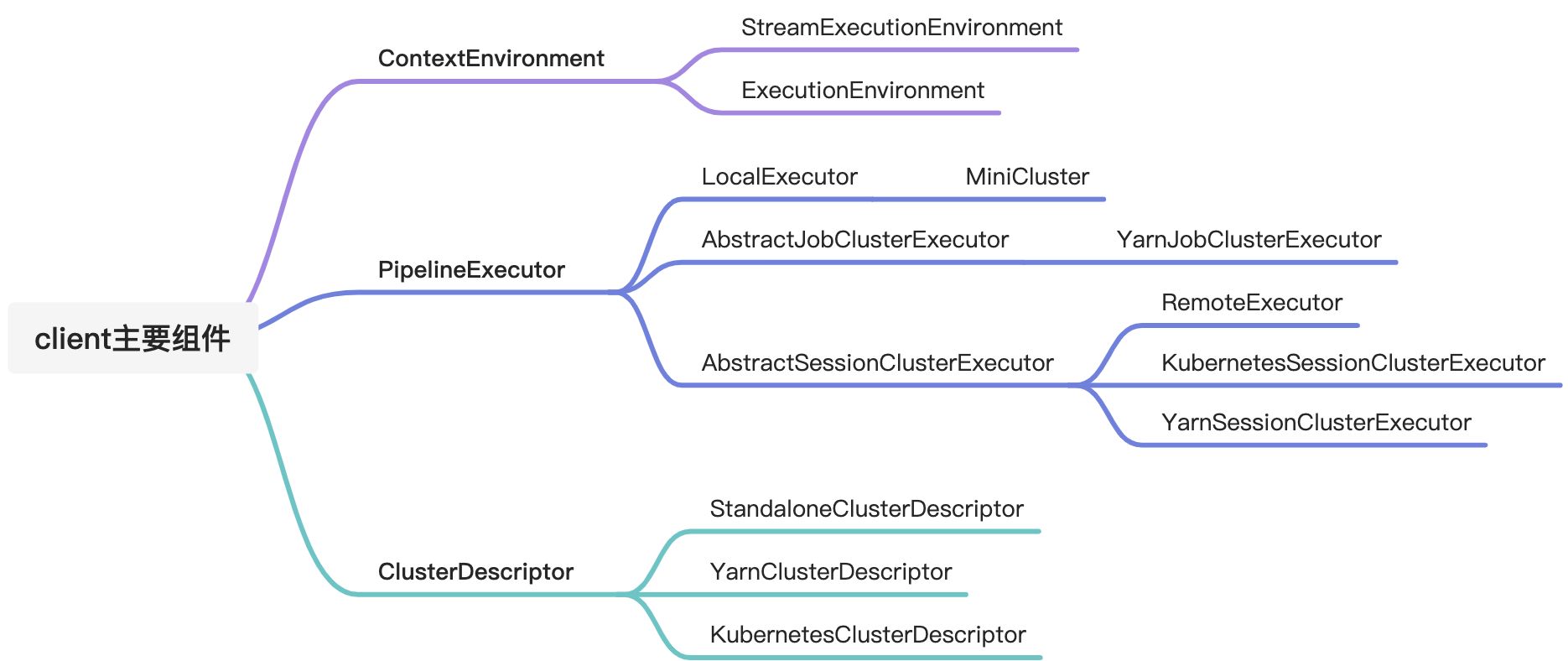
client实现原理
主要功能
主要组件
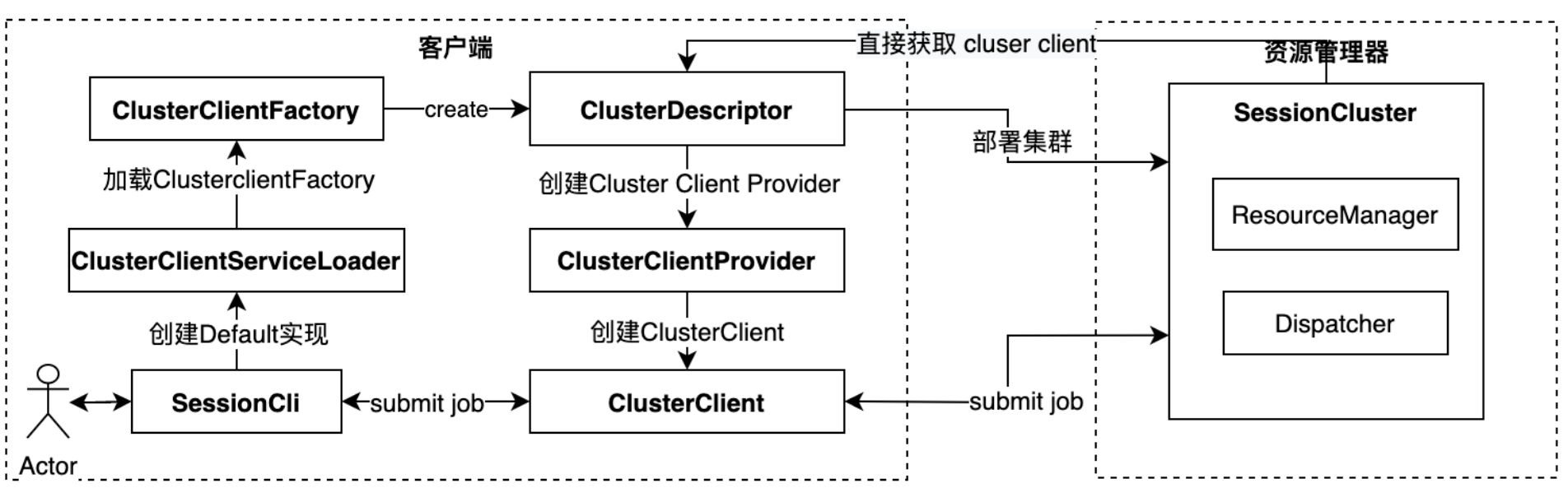
Session集群创建流程
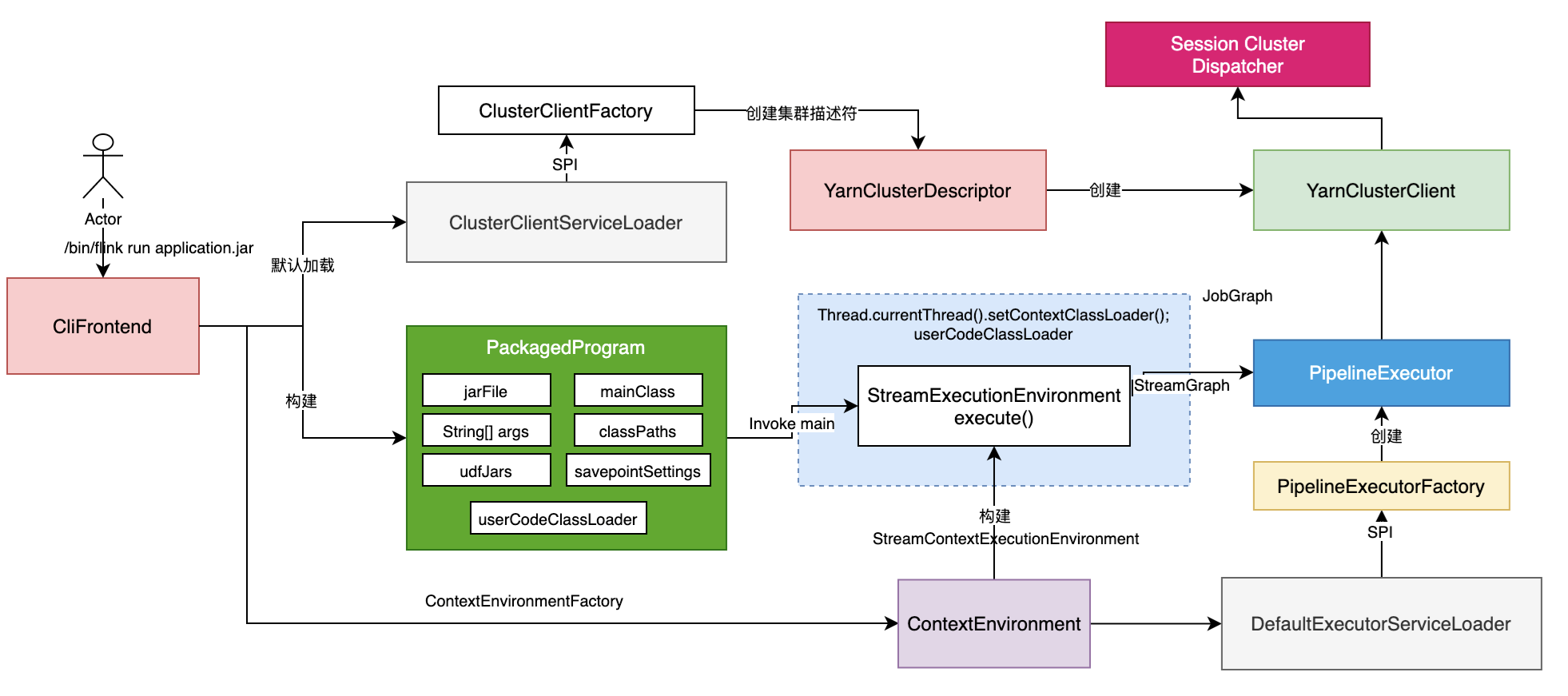
ApplicationCode运行
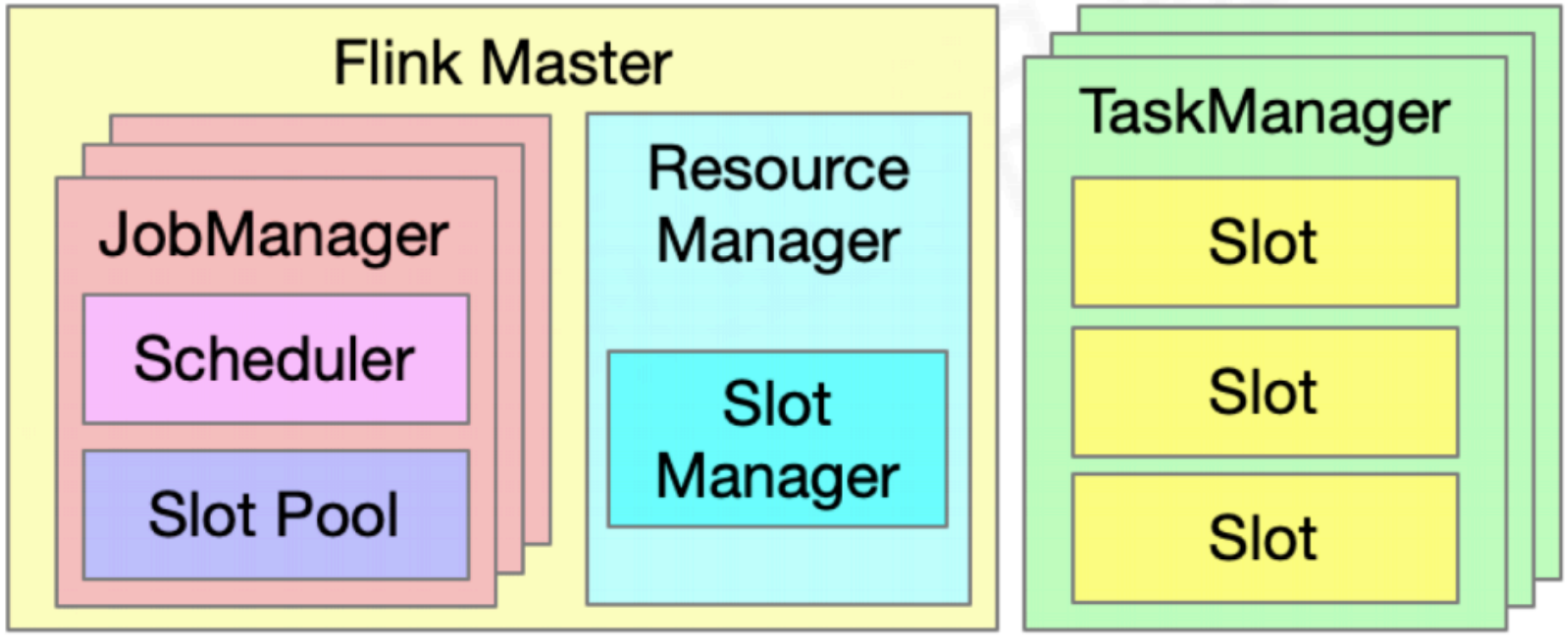
ResourceManager资源管理
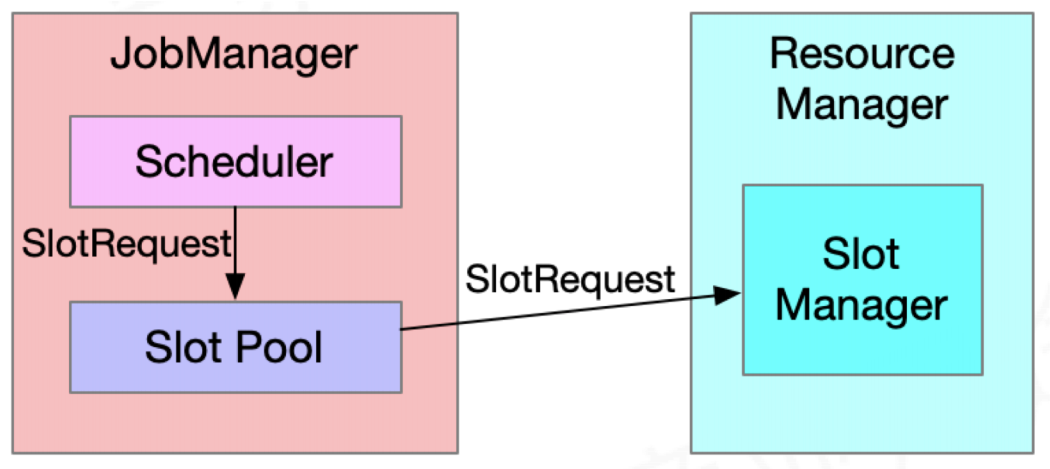
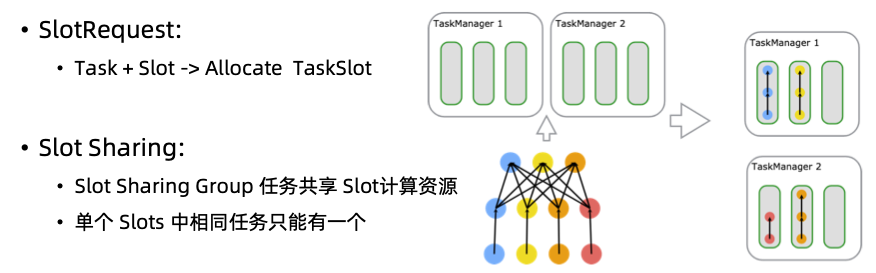
双层资源调度 Cluster->Job
- Job的申请会携带作业需要的资源
- SlotManager给申请的Job进行一次性资源分配
Job->Task
TM有固定数量的Slot资源
- Slot数量由配置决定
- Slot资源由TM资源及Slot数量决定
- 同一TM上的Slot之间无差别
-
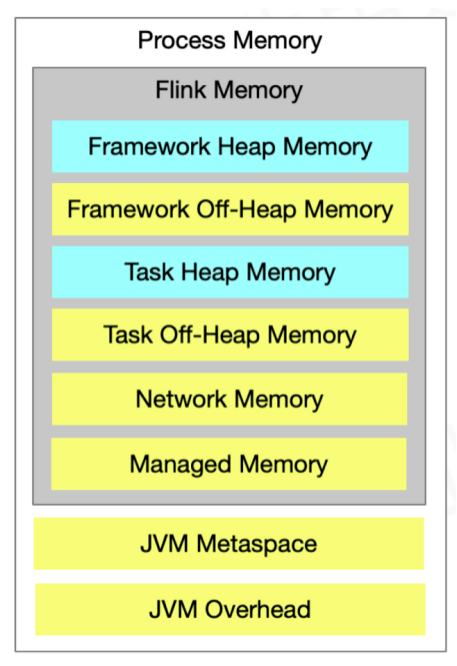
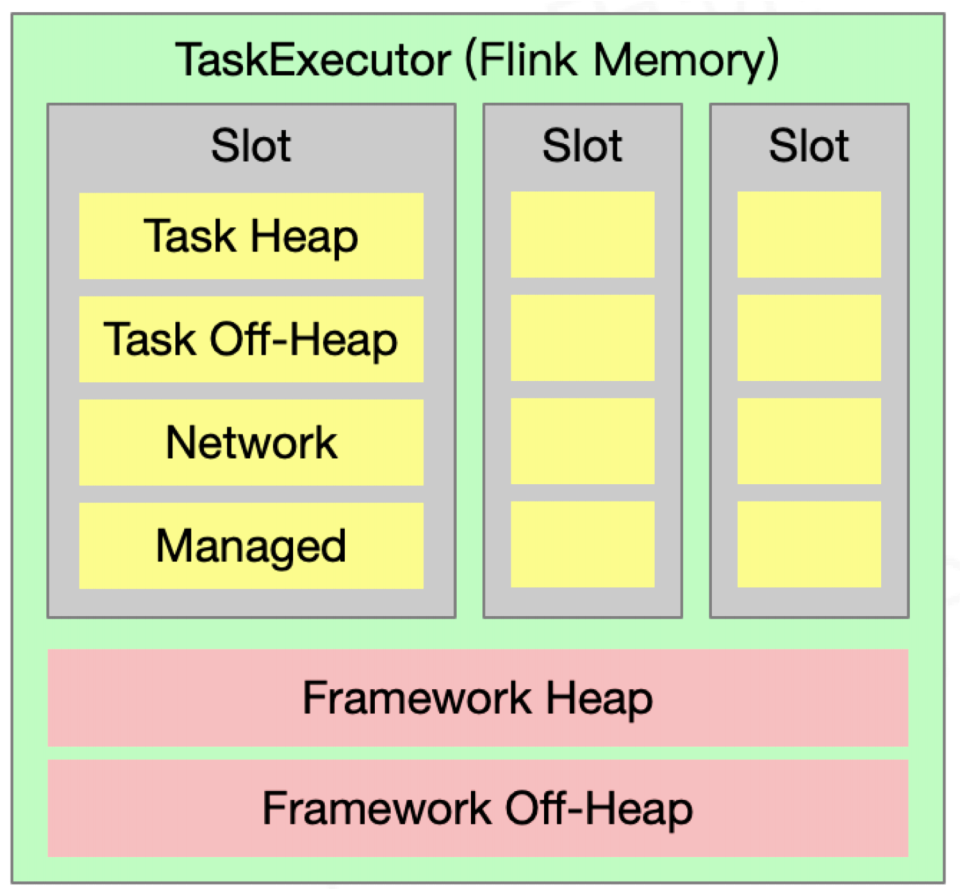
TaskManager资源管理
资源类型:内存、CPU、GPU(待支持)
On-Heap:堆内存
Off-Heap:堆外内存
ResourceManager分类

资源分类分两种: Standalone模式
Native模式(资源按需申请,利用率高,如k8s,yarn)
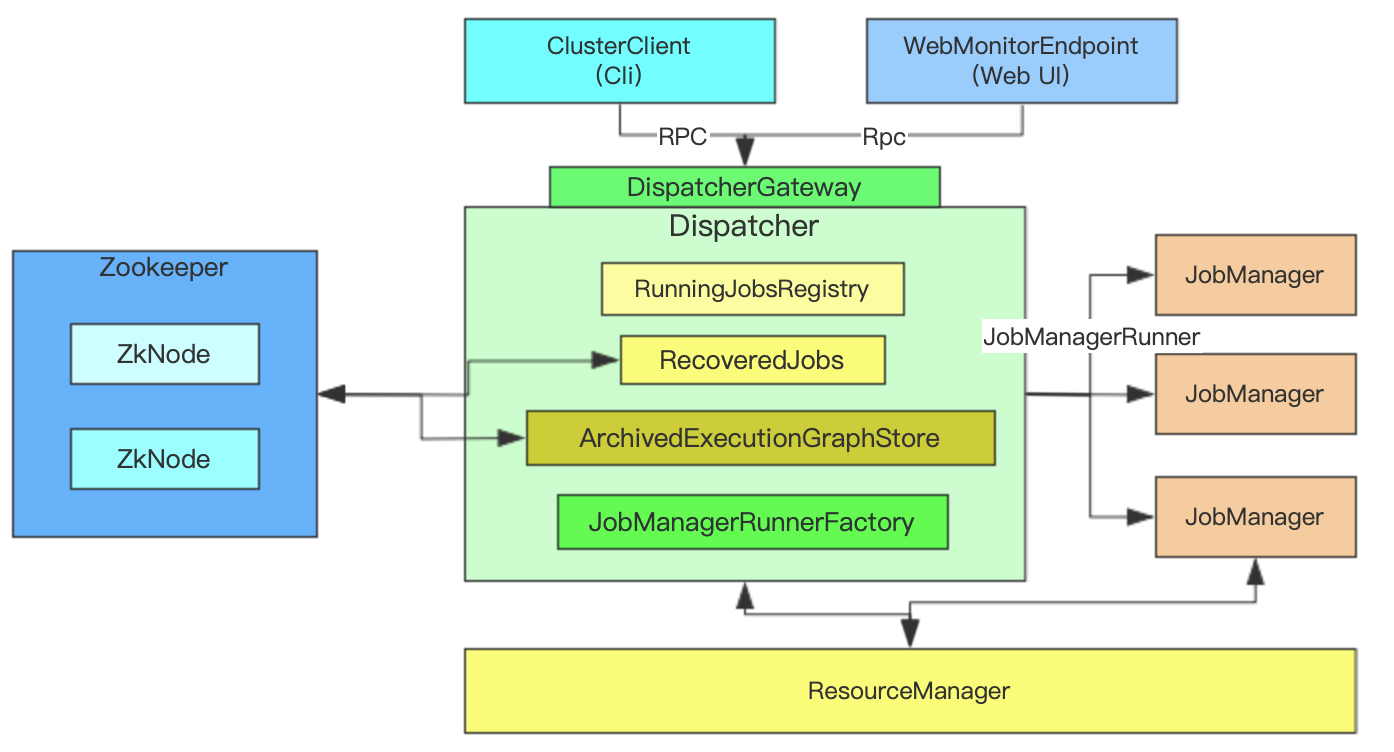
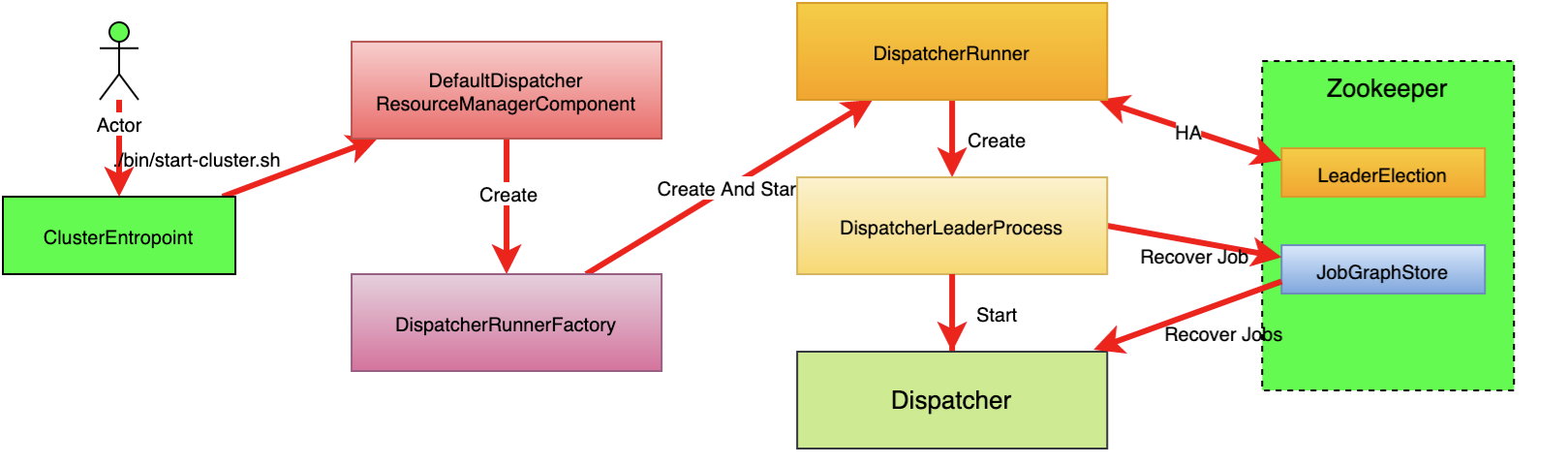
集群重要组件之一,主要负责JobGraph接收
- 根据JobGraph启动JobManager
- RPCEndpoint服务
- 通过DispatcherGateway RPC对外提供服务
- 从ZK中恢复JobGraph(HA模式)
-
核心成员
RunningJobsRegistry
- 处于Running的Job都会注册在这里
- RecoveredJobs
- 恢复HA集群中从ZK或外部介质恢复出来的JobGraph对象即Jobs,然后由Dispatcher重新启动JM分发Jobs启动运行
- ArchivedExecutionGraphStore
- 会把已经产生的ExecutionGraph进行压缩或归档,一旦出现问题可以通过ExecutionGraph进行恢复
- JobManagerRunnerFactory
- 创建JobManagerRunner使用的,JobManager会通过JobManagerRunner启动
- JobManagerSharedServices
- JobManager之间共享数据或服务
- BlobServer
- Flink内部对象存储服务,如Jar包、文件都存在这里
- RunningJobsRegistry
- 运行中Job集合
- JobManagerRunnerFutures
- 异步启动JobManagerRunner集合
- HistoryServerArchivist
- 历史服务
- HighAvaiabilityServices
- 高可用服务
- ResourceManagerGatewayRetriever
- ResourceManager交互
- HeartbeatService
- 心跳服务
- FatalErrorHandler
- 错误处理
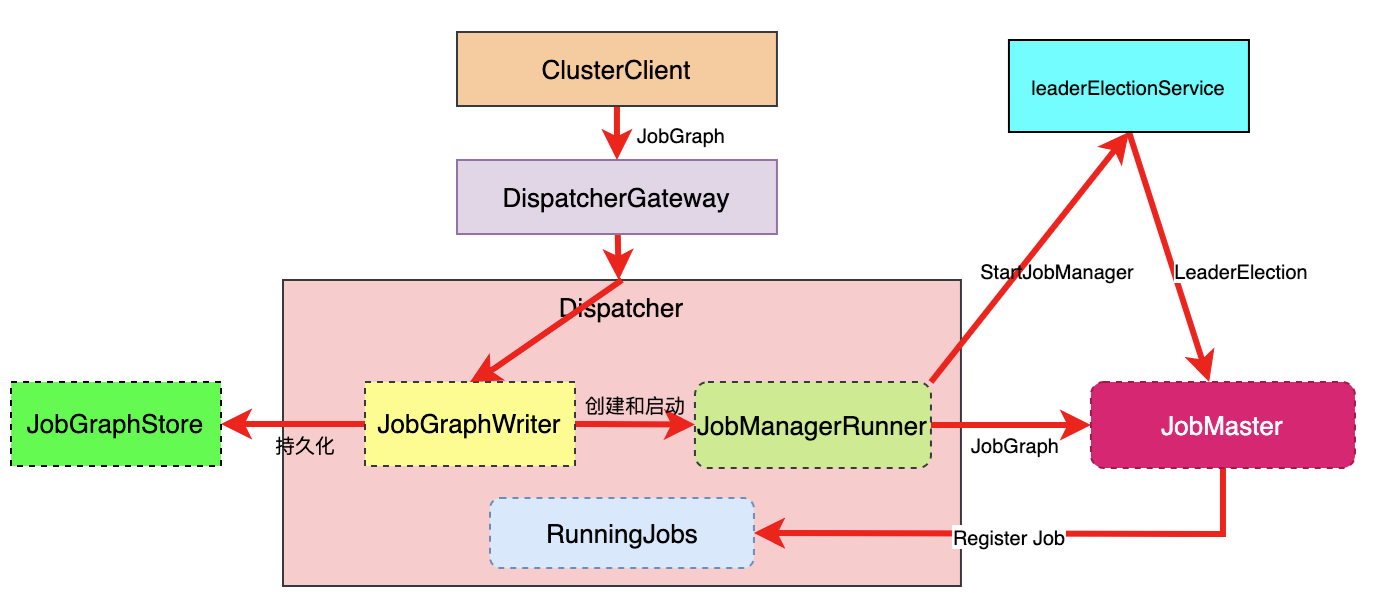
- JobGraphWriter
- 向ZK中写入JobGraph信息
- JobManagerMetricGroup
- JobManager统计信息
MetricServiceQueryAddress
Dispatcher拿到JobGraph后先通过JobGraphWriter持久化到JobGraphStore
JobManagerRunner启动后会先启动leaderElectionService选举
JobGraph提交与运行
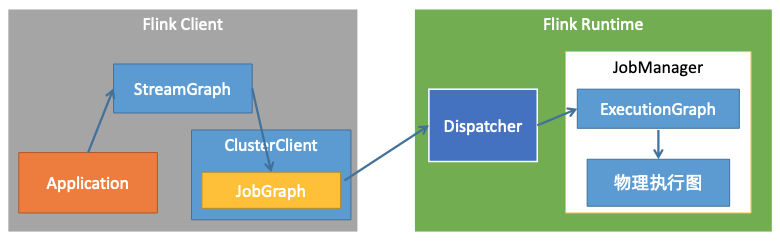
Flink作业提交流程
Flink四种Graph转换
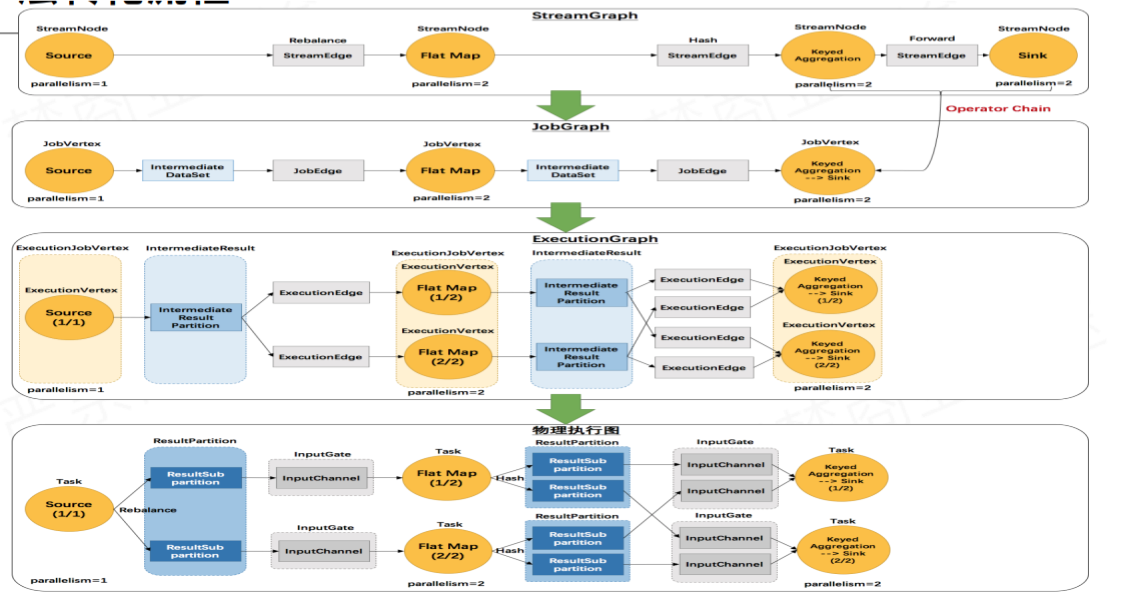
第一层: Program -> StreamGraph
- 第二层:StreamGraph -> JobGraph
- 第三层:JobGraph -> ExecutionGraph
- 第四层:Execution -> 物理执行计划
注:
Forward即算子到算子数据输出,不涉及类似shuffle等物理层面的数据交互(如多个TaskManager之间数据交互的时候),可以合并到同一个OperatorChain里面,最终会执行在同一个Task里面,不同OperatorChain会在不同Task里运行
Program->StreamGraph
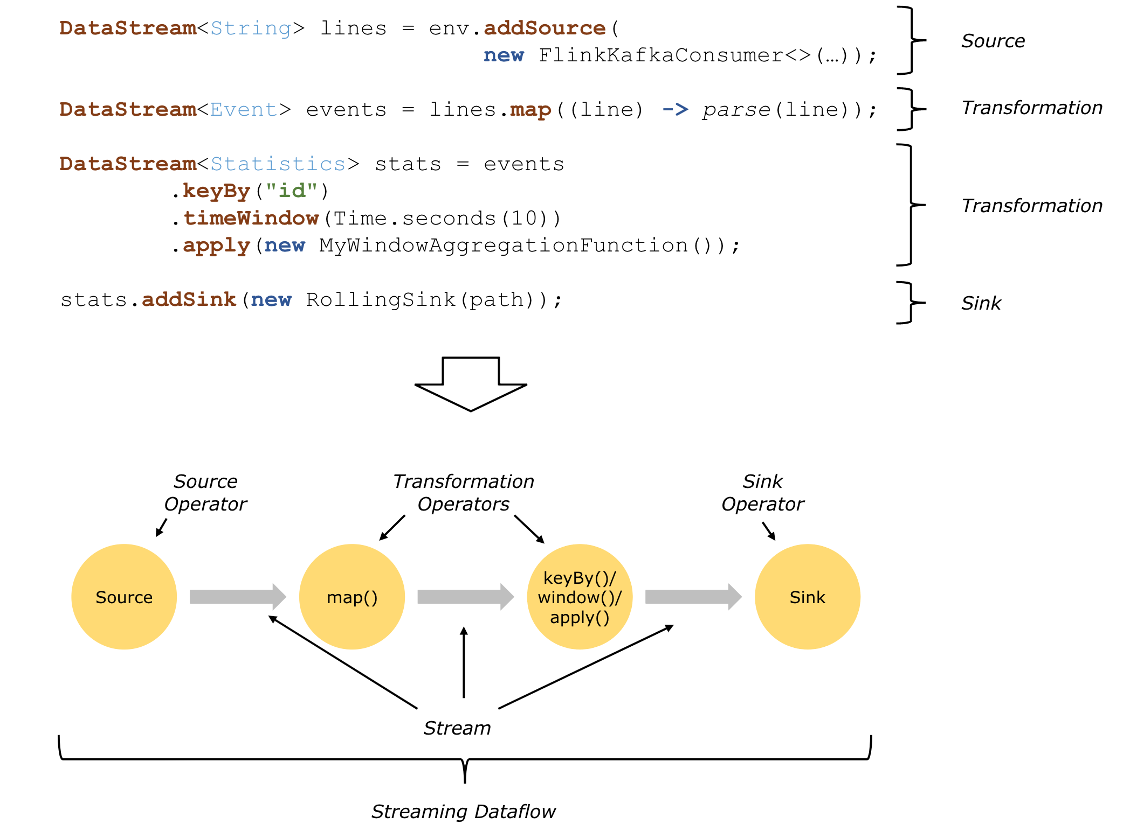
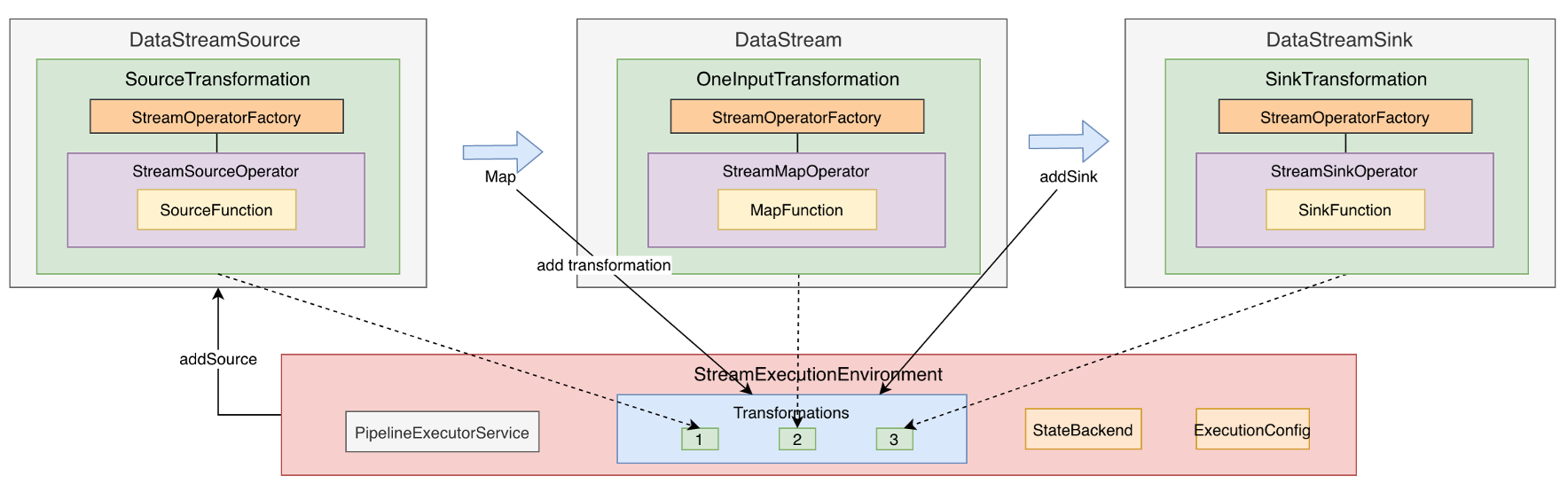
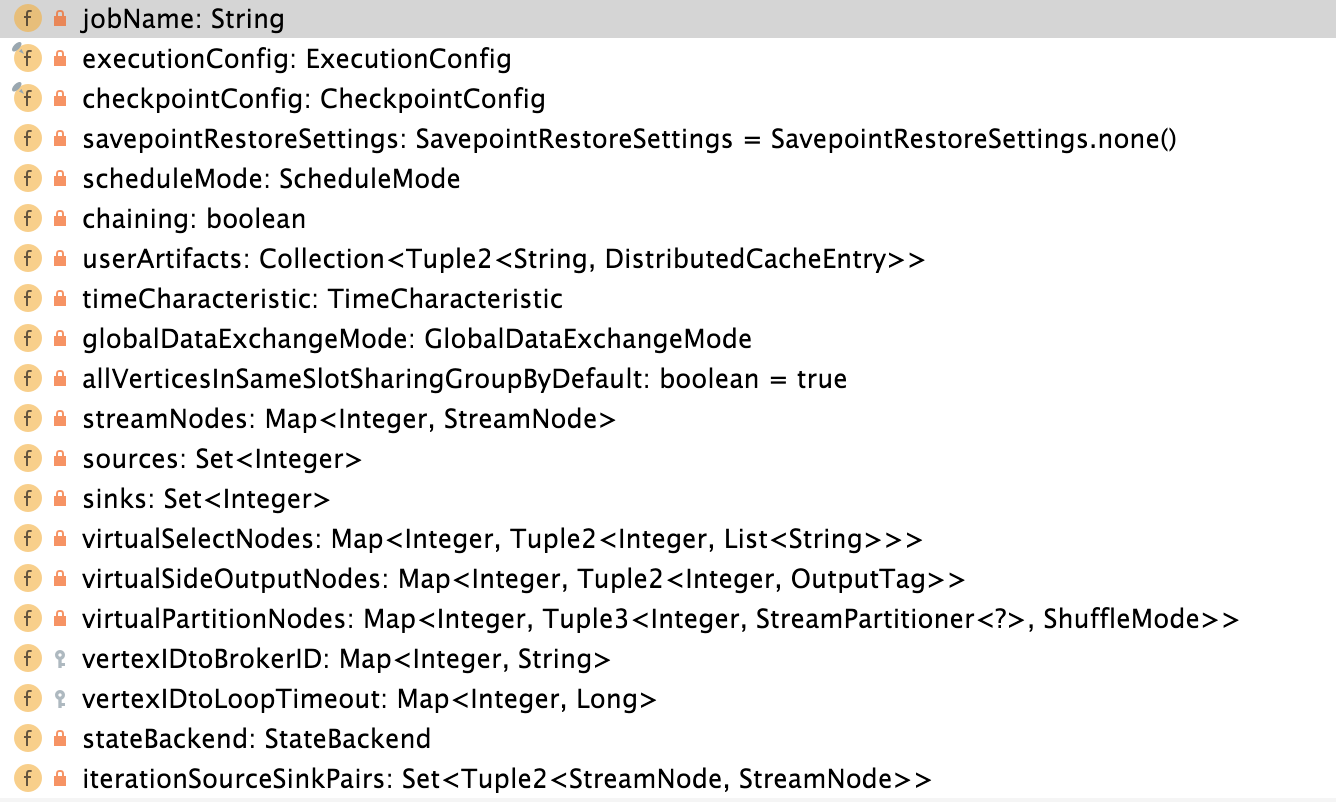
StreamGraph组成
- StateBackend
- 状态的管理
- 选择不同实现的StateBackend(Memory、RocksDB、FS)
- 用户的StateBackend配置
- userArtifacts
- 用户涉及到的文件或包
- 配置信息
- checkPoint的配置等
- TimeCharacteristic
- 时间概念(Event、Process)
拓扑关系
DataStream可以强制合并节点,默认边是Forward就会合并,如keyd,然后sink,就是Forward类型
JobGraph会生成Intermediate DateSet数据集,作用是在执行过程中生成ResultPartition的组件,ResultPartition是中间数据的一个缓冲,是在network数据交换都是通过Intermediate DateSet以及job的边的连接信息
JobGraph组成
基本配置
- JobConfiguration
- JobId
- JobName
- scheduleMode
- SerializedExecutionConfig
- JobCheckpointSettings
- SavepointRestoreSettings
- 拓扑配置
- todo 拓扑配置脑图(JobGraph类)
- 环境配置
- UserJars
- userArtifacts
- userJarBlobKeys
- classpaths
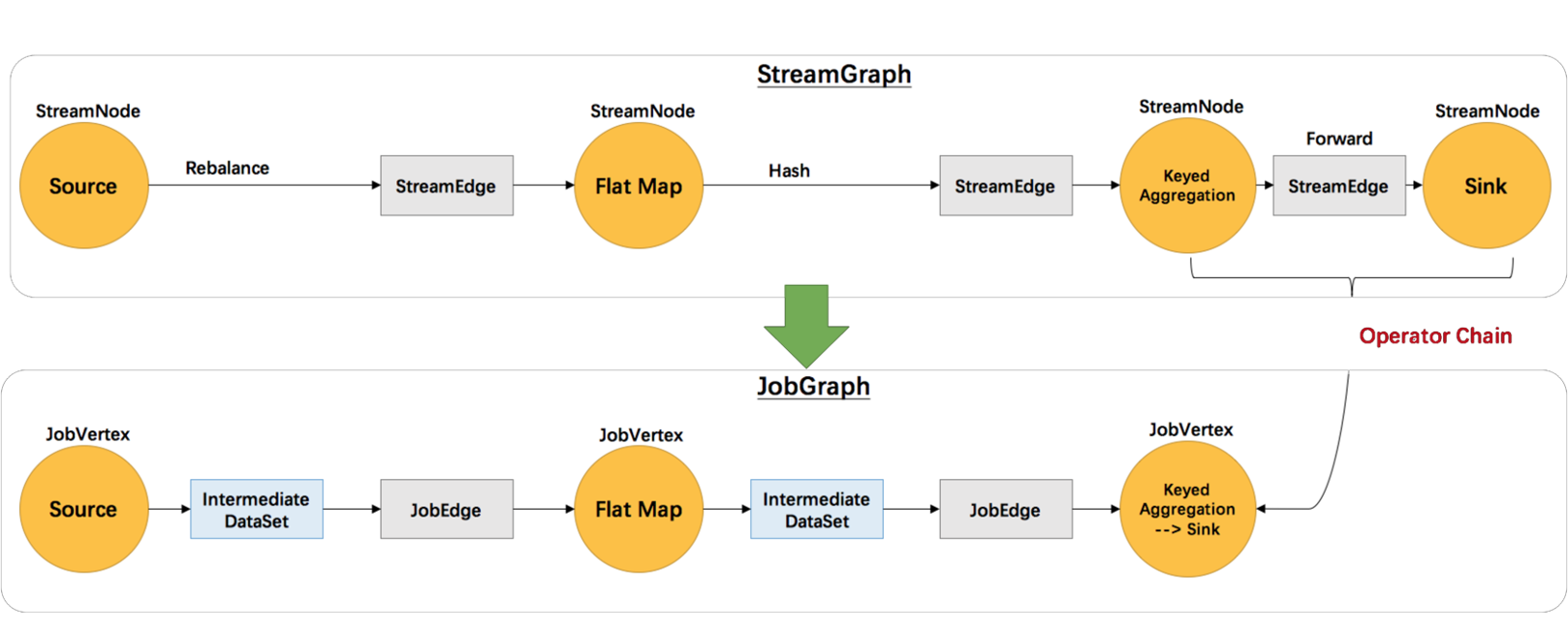
JobGraph->ExecutionGraph
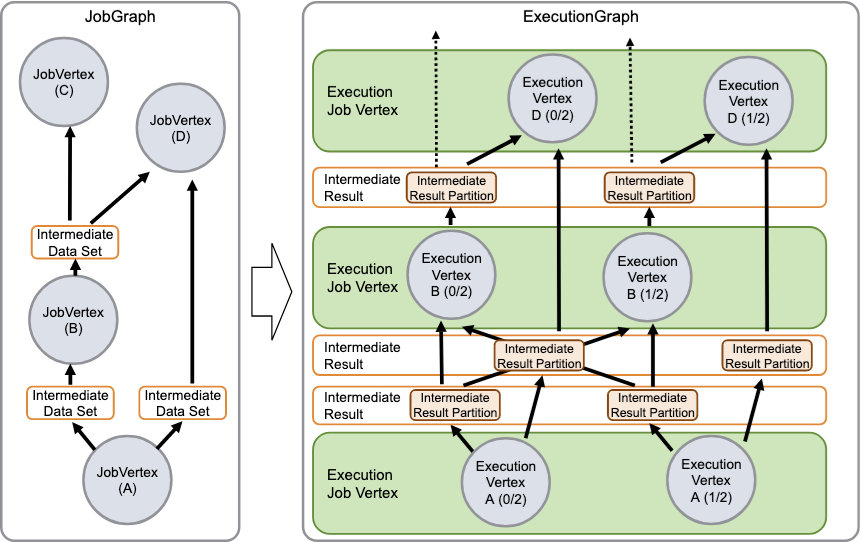
ExecutionGraph组成
- 基本配置
- 环境配置
- 容错配置
- 主要组件
- 拓扑配置
Task执行与调度
ExecutionGraph->物理执行计划
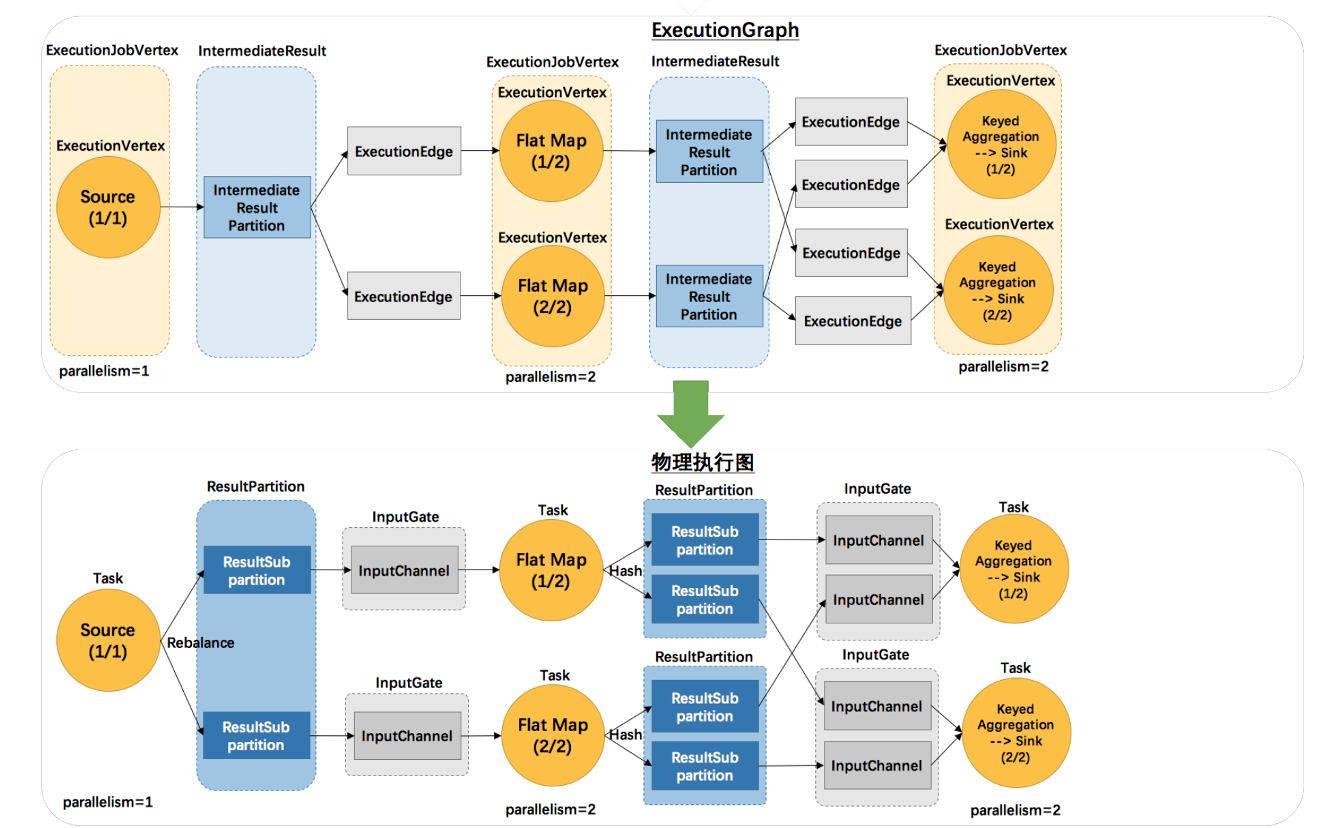
ExecutionGraph调度器

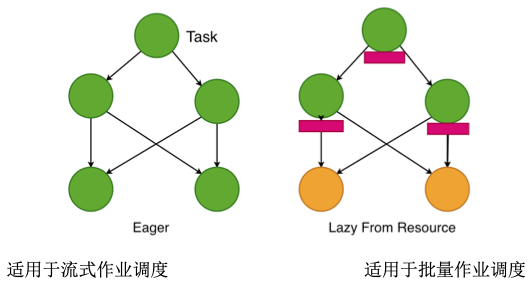
Task调度策略
Task结构组成
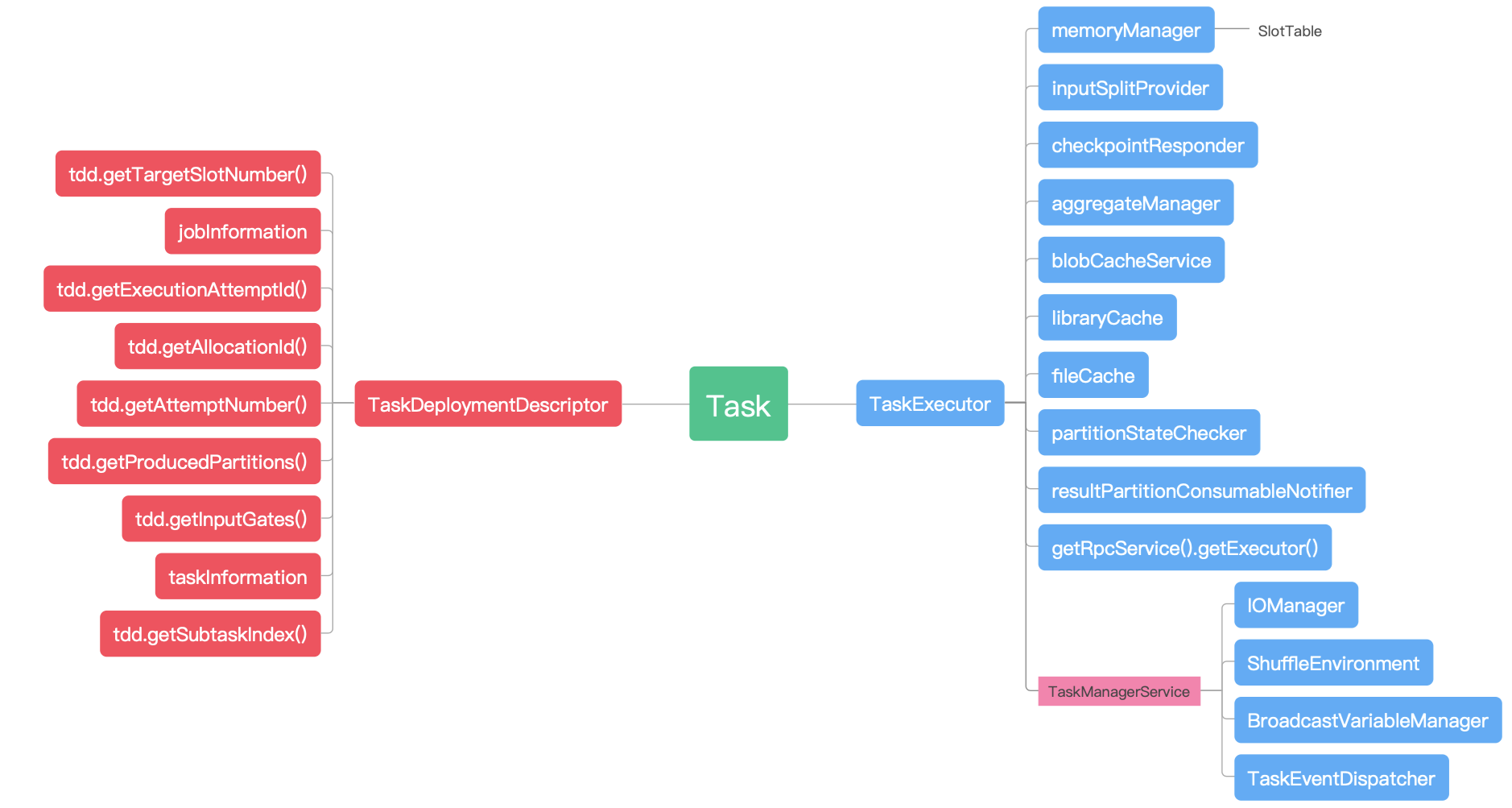
Task设计和实现

StreamTask触发与执行
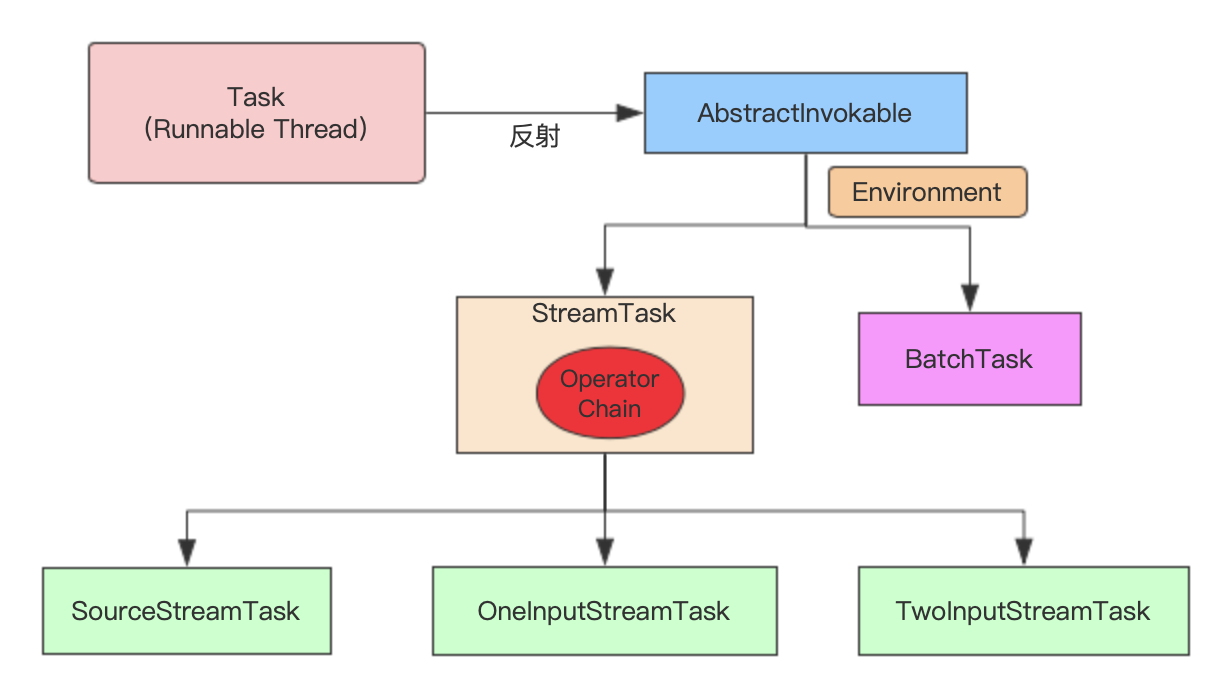
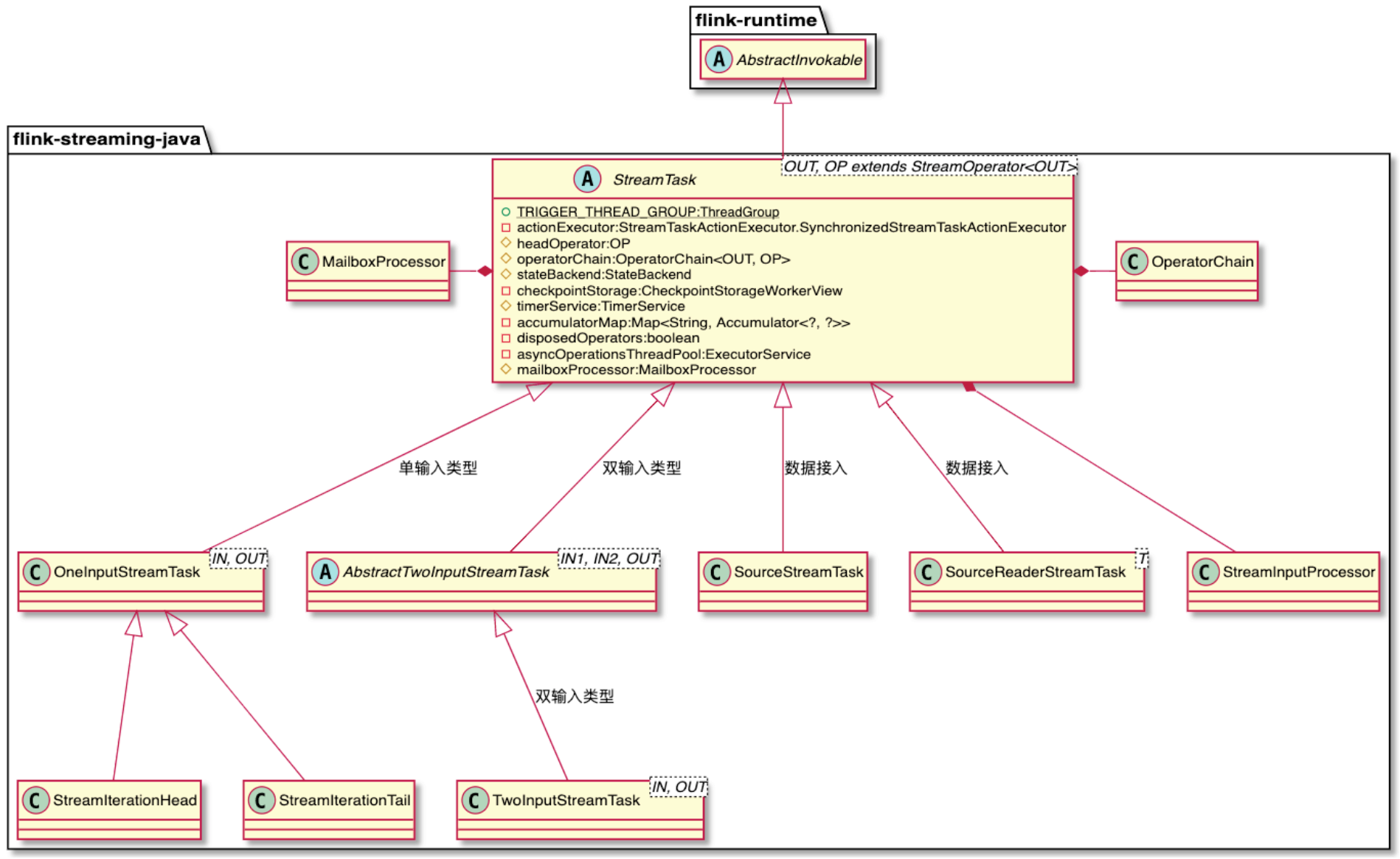
Task运行状态
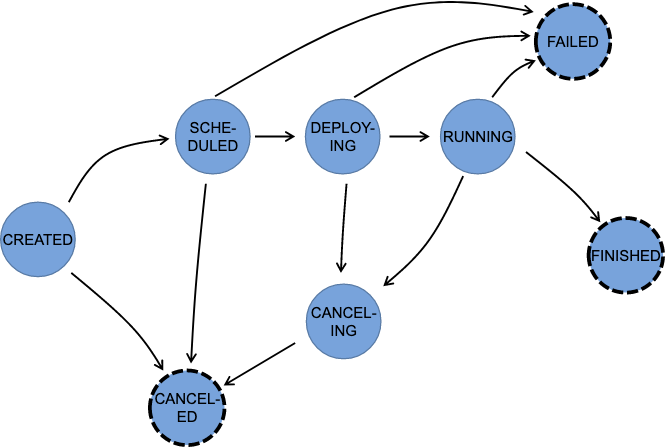
Task重启和容错策略
TaskFailover情况
- 单个Task执行失败
- TaskManager出错退出
-
Task容错恢复策略
Task Restart策略(重启频率和方式)
- Fixed Delay Restart Strategy:指定固定延时重启策略

- Failure Rate Restart Strategy:根据容错率区间重启策略

- No Restart Strategy:不重启
- Fixed Delay Restart Strategy:指定固定延时重启策略

- Failover Strategies(重启范围:起哪些Task)
- Restart all:所有

- Restart pipelined region:仅去将相关联的Task重启
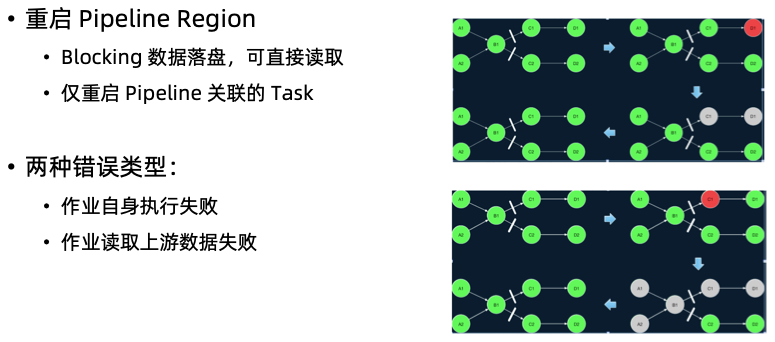
- 需要重启的 Region 的判断逻辑如下:
- 出错 Task 所在 Region 需要重启。
- 如果要重启的 Region 需要消费的数据有部分无法访问(丢失或损坏),产出该部分数 据的 Region 也需要重启。
- 需要重启的 Region 的下游 Region 也需要重启。这是出于保障数据一致性的考虑,因 为一些非确定性的计算或者分发会导致同一个 Result Partition 每次产生时包含的数据 都不相同。
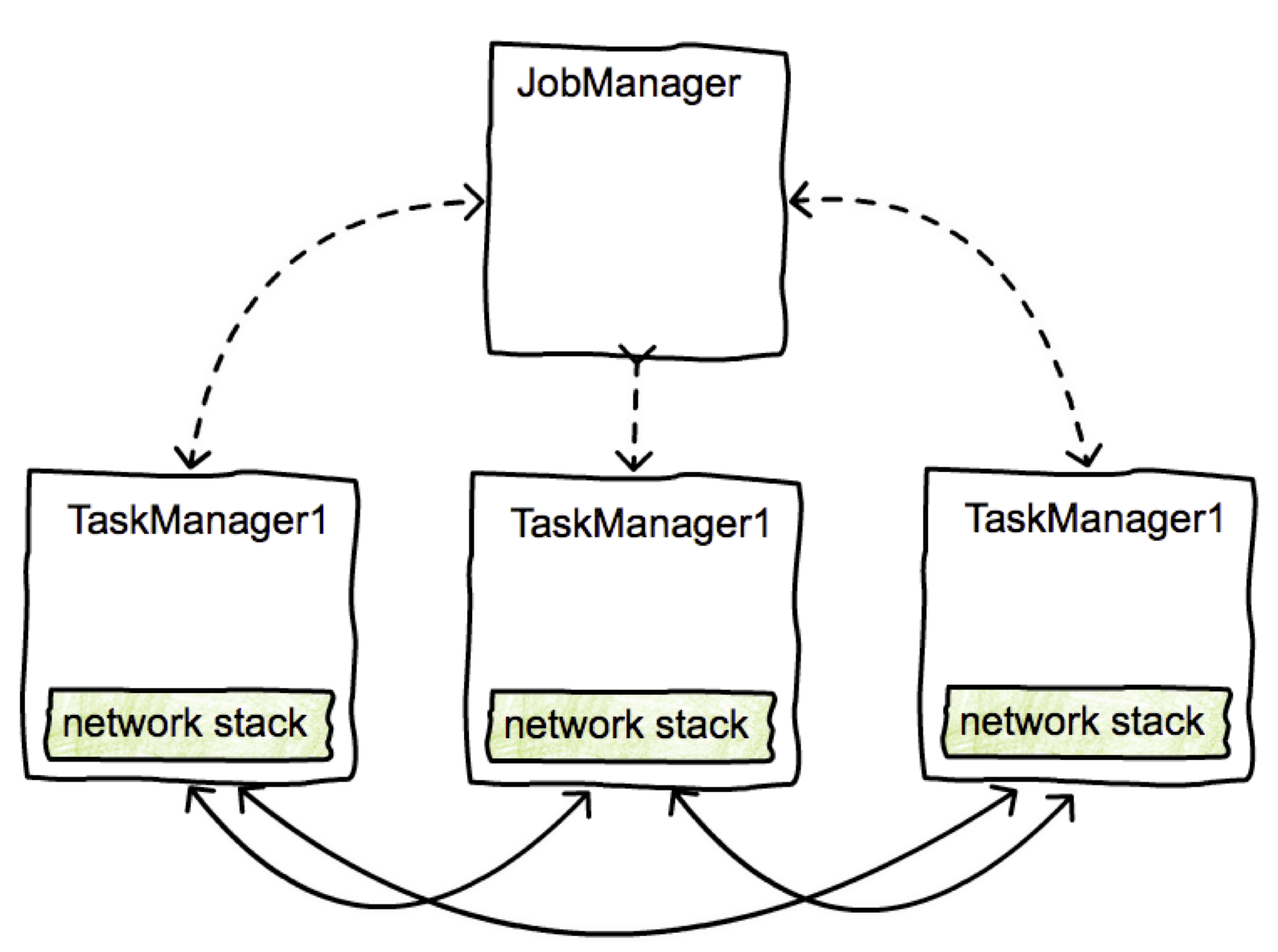
集群组件RPC通信机制
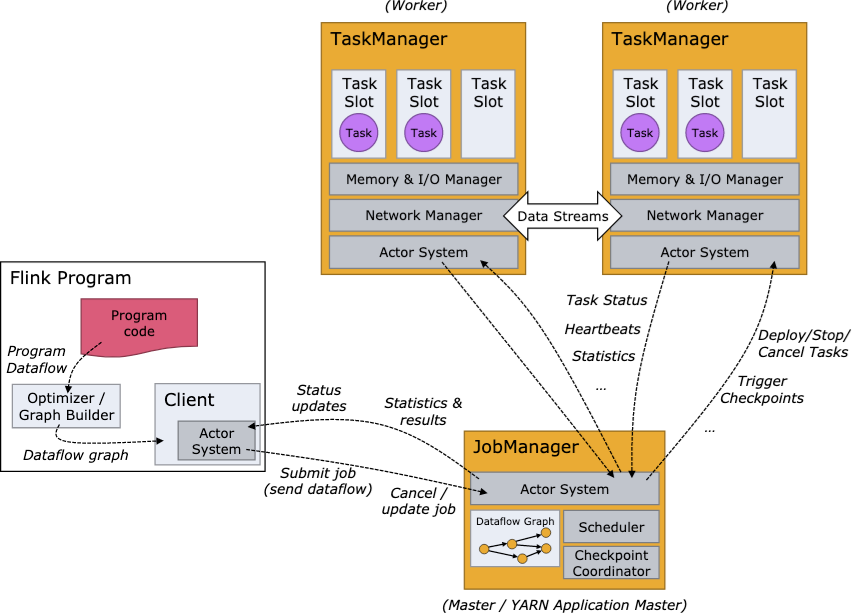
节点与节点通信:akka通信框架
数据交互:NetworkManager,netty实现的tcp管道,即flink里面的network stack(网络栈)Akka通信框架介绍
scala编写的库,在jvm平台上,简化编写具有可容错的、高可伸缩性的Java和Scala的Actor应用模型。
他其实本身是一个并行计算的模型,他把Actor作为并行计算的基本元素来对待,可以去响应接收到的消息,然后一个Actor可以作出一些决策,比如创建一些新的Actor,或者发送更多的消息。
Flink使用的Akka Actor就是每个RPC endpoint。TaskManager、JobManager、Dispatcher等本身就是Actor节点,可以与其他节点进行通信,每个Actor都有地址。ActorSystem创建

Flink RPC通信
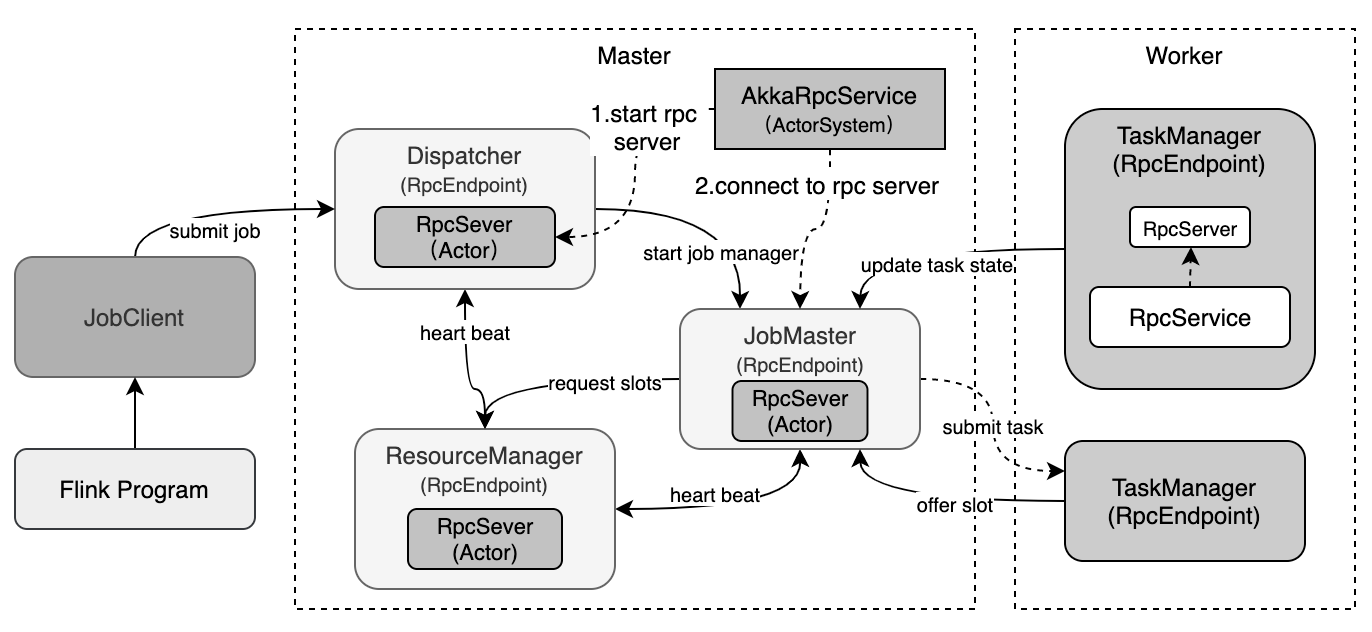
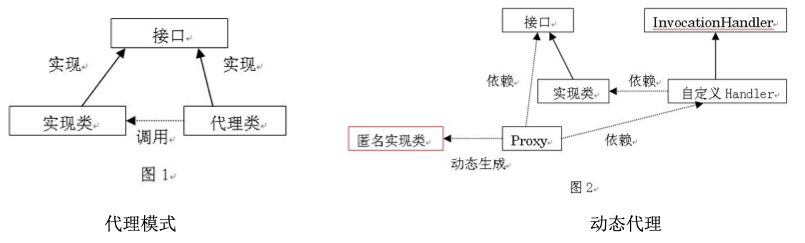
Java动态代理
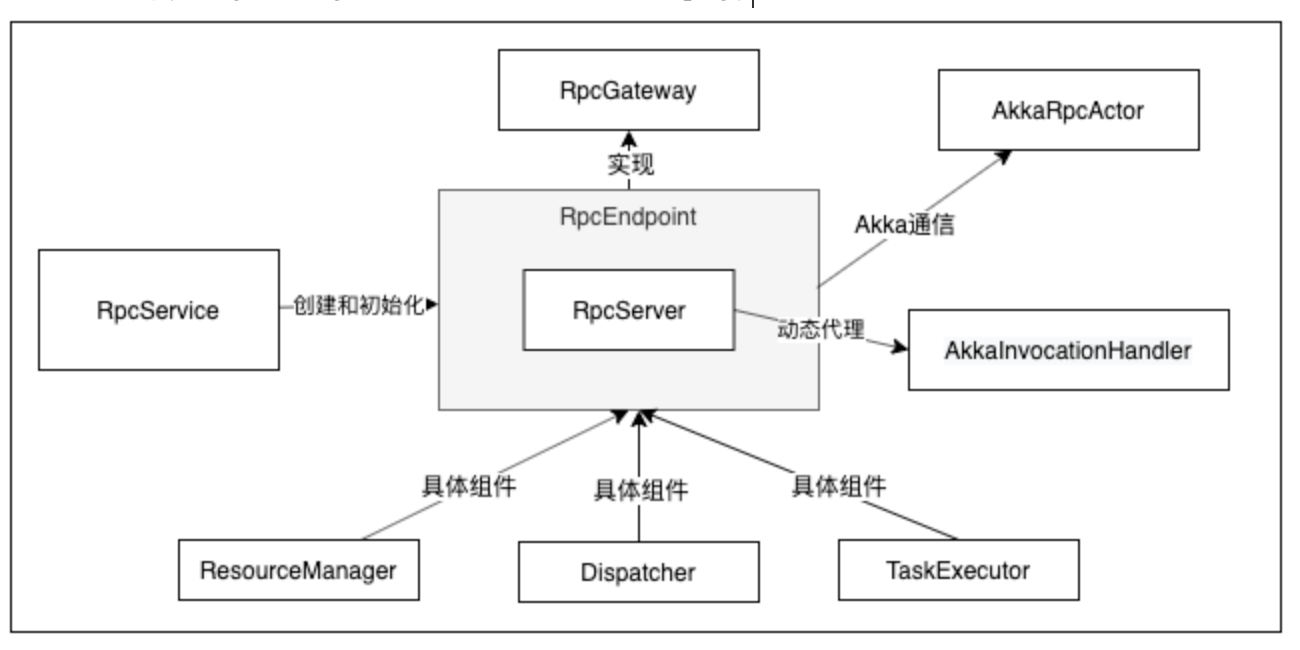
Flink RPC Server设计
NetworkStack实现原理
Data exchange between tasks
Transfer of a byte buffer between two tasks
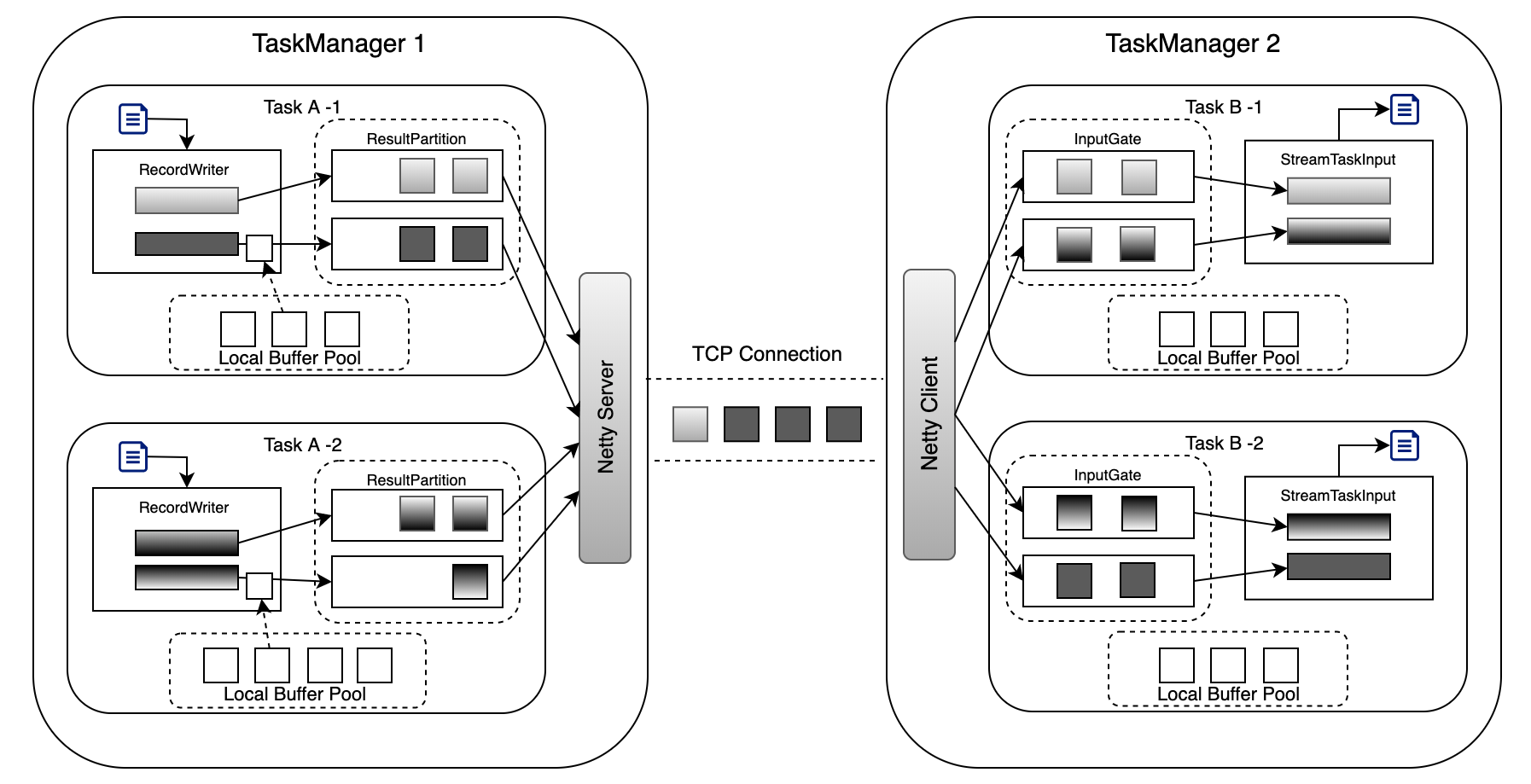
主要依赖netty的tcp连接实现网络数据交互
过程:
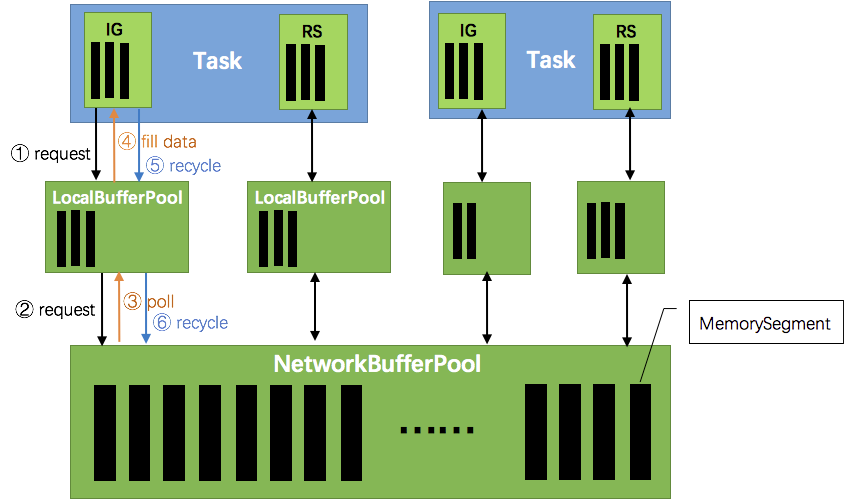
- 数据经过算子处理完成之后通过RecordWriter写入到ResultPartition里,ResultPartition里有对应的ResultSubPartition,ResultSubPartition里面有BufferPool队列,BufferPool去Local BufferPool(内存的资源)申请MemorySegment资源,然后将数据存储到Buffer里面,然后在存到ResultPartition队列里面
- 下游一旦可以继续消费,上游就会有Reader读取和消费Buffer里的数据,Buffer数据经过Netty Server去经过Tcp传输到下游Netty Client里
Netty Clinet会把数据通过Input Channel发送给InputGate,会把响应的数据存储在基于内存的Local Buffer Pool里,接着会发送到对应的Task里去处理
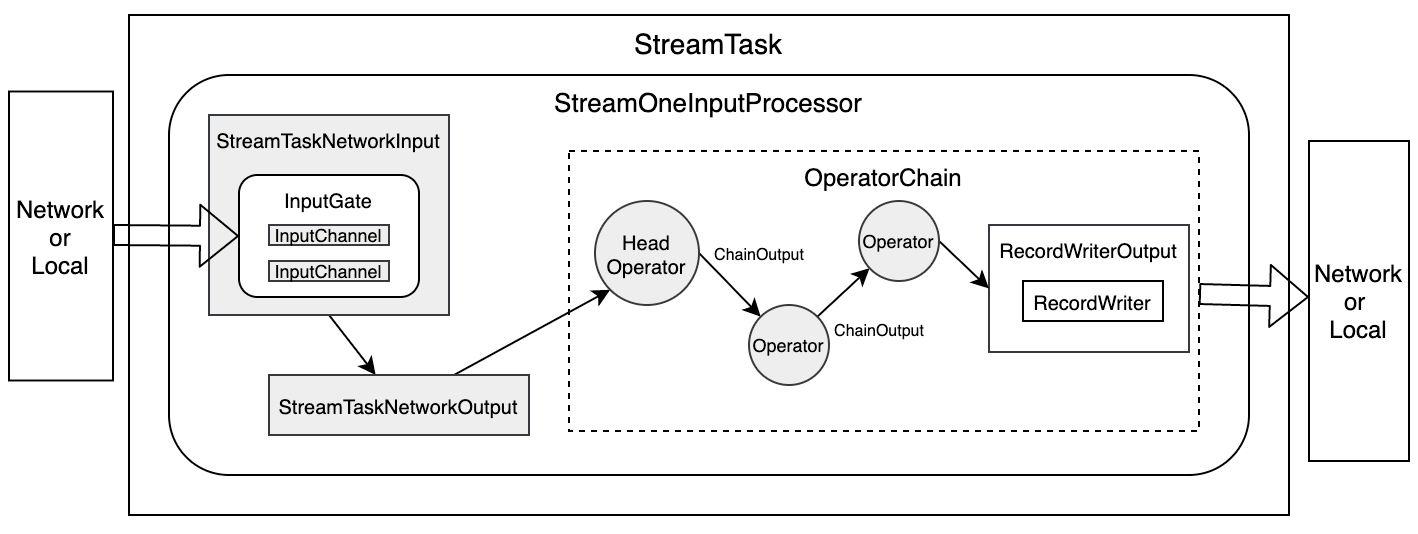
StreamTask 内部数据流转
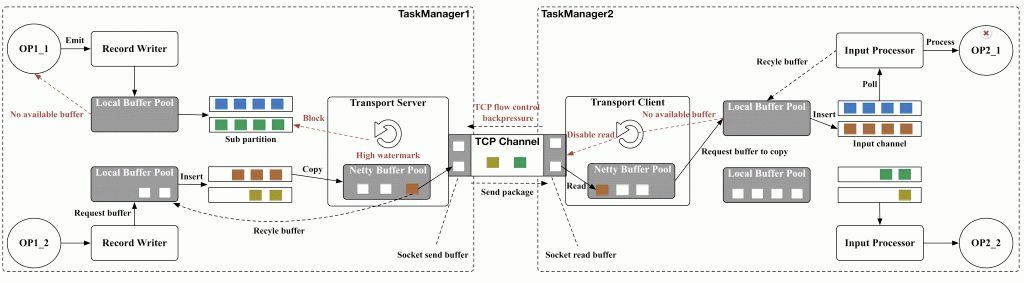
TaskManager之间的数据交互
网络传输中的内存管理
Flink内存管理
JVM内存管理带来的问题
Java对象存储密度低:一个只包含 boolean 属性的对象占用了16个字节内存:对象头占了8个,
boolean 属性占了1个,对齐填充占了7个。而实际上只需要一个 bit(1/8字节)就够了。
- FullGC会极大地影响性能,尤其是为了处理更大数据而开了很大内存空间的JVM来说,GC会达到秒 级甚至分钟级。
OOM问题影响稳定性:OutOfMemoryError是分布式计算框架经常会遇到的问题,当JVM中所有对 象大小超过分配给 JVM 的内存大小时,就会发生 OutOfMemoryError 错误,导致 JVM 崩溃,分布式 框架的健壮性和性能都会受到影响。
Flink内存模型
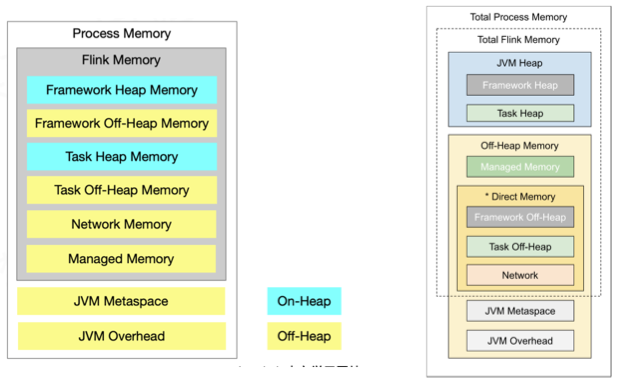
内存吃紧时会将数据写入到磁盘,不会导致oom问题
- 所有数据基于二进制,节省内存空间,不像Java会补位
Network Memory可以进行零拷贝技术,提高数据处理性能
TypeInformation支持

除了支持类型定义,还支持非常紧凑的序列化方式,极大降低内存消耗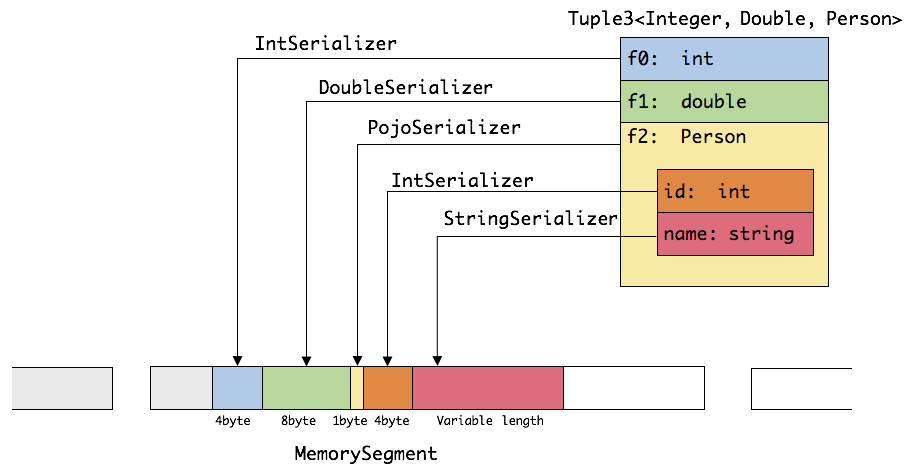
MemorySegment内存块
分两种:HybridMemorySegment、HeapMemorySegment
启动超大内存(上百GB)的JVM需要很长时间,GC停留时间也会很长(分钟级)。使用堆外 内存的话,可以极大地减小堆内存(只需要分配Remaining Heap那一块),使得 TaskManager 扩展到上百GB内存不是问题。
- 高效的 IO 操作。堆外内存在写磁盘或网络传输时是 zero-copy,而堆内存的话,至少需要 copy 一次。
- 堆外内存是进程间共享的。也就是说,即使JVM进程崩溃也不会丢失数据。这可以用来做故 障恢复(Flink暂时没有利用起这个,不过未来很可能会去做)。
- Flink用通过ByteBuffer.allocateDirect(numBytes)来申请堆外内存,用 sun.misc.Unsafe 来操作堆外内存。

若有收获,就点个赞吧
0 人点赞
