Kibana的HTTP操作类似,可以看四、Kibana安装部署及使用 5. 查询语句
1. 查看ES各种信息
1.1 检查ES是否可用
GET IP:9200

1.2 查看有多少节点
GET IP:9200/_cat/nodes

1.3 查看集群健康状态
GET IP:9200/_cluster/health?pretty
**status**字段只是这当前集群在总体上是否工作正常,他的三种颜色含义如下: |
|
|---|---|
green |
所有的主分片和副本分片都正常运行 |
yellow |
所有的主分片都运行正常,但不是所有的副本分片都正常运行 |
red |
有主分片没能正常运行 |

1.4 查看所有索引及索引状态
GET IP:9200/_cat/indices?v

1.5 使用分词器分析词条
GET /_analyze{"analyzer": "standard","text": "hello world"}# "analyzer": "standard":# 是指定使用哪个分词器,standard是自带分词器# 如果装了ik分词器# 1. 可以使用ik_max_word --- 会将文本做最细粒度的拆分# 2. 还可以使用ik_smart --- 会将文本做最粗粒度的拆分# "text": "hello world"是指定文本
2. 索引
对比关系型数据库,索引就等同于数据库
2.1 创建
PUT http://hadoop101:9200/shopping# 无body
2.2 创建索引同时创建映射、设置分片和副本
PUT http://hadoop101:9200/student1# body如下:{"settings" : {"number_of_shards" : 3, // 3个主分片"number_of_replicas" : 1 // 每个分片1个副本},"mapping":{"properties":{"name":{"type":"text", // 文本类型,会分词"index":true // 索引,该字段可以搜索,默认true},"sex":{"type":"keyword", // 关键字类型,不分词,必须整条记录搜索才能搜到"index":true // 索引,该字段可以搜索,默认true},"tel":{"type":"text", // 文本类型,会分词"store":true // 是否单独存储,默认数据会存储到_source中,如果配置store为true,会将该字段单独存储,查询会非常快,但会占用更多的空间}}}}
2.3 修改副本分片数
PUT http://hadoop101:9200/person1/_settings{"number_of_replicas" : 2}
2.4 查询所有
GET http://hadoop101:9200/_cat/indices?v# 结果如下:health status index uuid pri rep docs.count docs.deleted store.size pri.store.sizegreen open student1 fgI0uB9zTZGXVo3geDtn9w 1 1 0 0 416b 208bgreen open user gQAHQT92Q7mbLC394fHtDw 1 1 1 0 7.6kb 3.8kbgreen open shopping LsvqKvmSTo6yhllrQL-oEw 1 1 3 0 22.8kb 11.4kb

2.5 查询单个
GET http://hadoop101:9200/shopping
2.6 删除
DELETE http://hadoop101:9200/shopping
2.7 刷新索引
慎用 ES默认1s刷新一次 在索引构建时,可以先关闭自动刷新,让索引构建更快,待开始使用索引时再打开 如果不需要近实时搜索,可以调大刷新间隔,提高索引效率
PUT /users/_settings # 关闭自动刷新{"refresh_interval": -1}PUT /users/_settings # 每一秒刷新{"refresh_interval": "1s"}PUT /users/_refresh # 手动刷新
3. 映射
对比关系型数据库,映射就等同于表结构
映射数据说明:
| 映射 | 类型 | 描述 |
|---|---|---|
| type | text(String类型) | 可分词 |
| keyword(String类型) | 不可分词,数据会作为完整字段进行匹配 | |
| long、integer、short、byte、double、float、half_float | 基本数据类型 | |
| scaled_float | 浮点数的高精度类型 | |
| Date | 日期类型 | |
| Array | 数组类型 | |
| Object | 对象 | |
| index | true/false | true:默认,字段会被索引,则可以用来进行搜索 false:字段不会被索引,不能用来搜索 |
| store | true/false | 原始的文本会存储在_source 里面,默认情况下其他提取出来的字段都不是独立存储的,是从_source 里面提取出来的。当然你也可以独立的存储某个字段,只要设置”store”: true 即可,获取独立存储的字段要比从_source 中解析快得多,但是也会占用更多的空间,所以要根据实际业务需求来设置。 |
| analyzer | ik | 分词器 |
3.1 创建
PUT http://hadoop101:9200/shopping/_mapping# body如下:{"properties":{"name":{ // 字段名,任意填写"type":"text", // 文本类型,会分词"index":true // 索引,该字段可以搜索,默认true},"sex":{"type":"keyword", // 关键字类型,不分词,必须整条记录搜索才能搜到"index":true // 索引,该字段可以搜索,默认true},"tel":{"type":"text", // 文本类型,会分词"store":true // 是否单独存储,默认数据会存储到_source中,如果配置store为true,会将该字段单独存储,查询会非常快,但会占用更多的空间}}}
3.2 创建索引同时创建映射
3.3 查看映射
GET http://hadoop101:9200/user/_mapping
4. 文档
对比关系型数据库,文档就等同于数据
4.1 新增
4.1.1 随机_id
POST http://hadoop101:9200/shopping/_doc# body如下:{"title":"小米手机","category":"小米","images":"http://www.gulixueyuan.com/xm.jpg","price":3999.00}
4.1.2 自定义_id
POST http://hadoop101:9200/shopping/_doc/1001# body如下:{"title":"小米手机","category":"小米","images":"http://www.gulixueyuan.com/xm.jpg","price":3999.00}
4.2 查询
4.2.1 主键查询
GET http://hadoop101:9200/shopping/_doc/1001
4.2.2 全部查询
GET http://hadoop101:9200/shopping/_doc/_search
4.2.3 高级查询
参考:4. 高级查询
4.3 修改
4.3.1 某条记录某个字段
POST http://hadoop101:9200/shopping/_update/1001{"doc":{"title":"华为手机"}}
4.3.2 某条记录全字段
POST http://hadoop101:9200/shopping/_doc/1001# body如下:{"title":"小米手机","category":"小米","images":"http://www.gulixueyuan.com/xm.jpg","price":4999.00}
4.4 删除
4.4.1 主键删除
DELETE http://hadoop101:9200/shopping/_doc/1002
4.4.2 条件删除
POST http://hadoop101:9200/shopping/_delete_by_query# body如下;{"query":{"match":{"price":3999.00}}}
5. 高级查询
5.1 查询所有—-match_all
GET http://hadoop101:9200/shopping/_search# body如下:{"query": {"match_all": {}}}
5.2 分词词条匹配查询
5.2.1 单字段分词词条匹配查询—-match
将查询条件先分词,根据分词后的每一个词条去匹配,词条之间是or的关系,结果取并集
match查询keyword字段,match会被分词,而keyword不会被分词,match的条件需要跟keyword的完全匹配才可以。 match查询text字段,match分词,text也分词,只要match的分词结果和text的分词结果有相同的就匹配。
GET http://hadoop101:9200/shopping/_search# body如下:{"query":{"match":{"title":"华为手机"}}}
5.2.2 多字段分词词条匹配查询—-multi_match
将查询条件先分词,根据分词后的每一个词条在多个字段中去匹配(text类似于多词条like,keyword需要词条完全匹配),词条之间是or的关系,结果取并集
GET http://hadoop101:9200/shopping/_search# body如下:{"query":{"multi_match":{"query":"华为","fields":["catgory","title"]}}}
5.3 短语匹配查询—-match_phrase
match_phrase匹配keyword字段。match_phrase会被分词,而keyword不会被分词,match_phrase需要跟keyword的完全匹配才可以。 match_phrase匹配text字段。match_phrase是分词的,text也是分词的。match_phrase的分词结果必须在text字段分词中都包含,而且顺序必须相同,而且必须都是连续的。类似于like
GET http://hadoop101:9200/shopping/_search# body如下:{"query":{"match_phrase":{"title":"华为手机"}}}
5.4 关键字精确查询
5.4.1 单关键词精确查询—-term
term查询keyword字段,term不会分词。而keyword字段也不分词。需要完全匹配才可以。 term查询text字段,因为text字段会分词,而term不分词,所以term查询的条件必须是text字段分词后的某一个词条。
GET http://hadoop101:9200/shopping/_search# body如下:{"query":{"term":{"title":{"value":"华"}}}}
5.4.2 多关键字精确查询—-terms
GET http://hadoop101:9200/shopping/_search# body如下:{"query":{"terms":{"title":["华","为"]}}}
5.5 (不)返回指定字段查询—-includes、excludes
GET http://hadoop101:9200/shopping/_search# includes的body如下:{"_source":{"includes":["title"]}}# excludes的body如下:{"_source":{"excludes":["title"]}}
5.6 组合查询—-bool
bool 把各种其它查询通过
**must**(必须 )、**must_not**(必须不)、**should**(应该)的方式进行组合
GET http://hadoop101:9200/shopping/_search# body如下:{"query":{"bool":{"must":[{"match":{"title":"手机"}},{"match":{"price":3999}}]}}}
5.7 范围查询—-range
GET http://hadoop101:9200/shopping/_search# body如下:{"query":{"bool":{"must":[{"match":{"title":"手机"}}],"filter":{"range":{"price":{"gt":4000}}}}}}
5.8 通配符查询—-wildcard
wildcard查询text字段,wildcard不分词,text分词,需要通配符匹配text分词后的词条 wildcard查询keyword字段,wildcard不分词,keyword不分词,通配符匹配,完全like模式
GET http://hadoop101:9200/user/_search# body如下:{"query":{"wildcard":{"sex":"*的"}}}
5.9 纠错查询—-fuzzy
例:输入个“吴疫烦”,也能把“吴亦凡”查出来,有一定的纠错能力 通过 fuzziness 修改编辑距离。一般使用默认值 AUTO,根据术语的长度生成编辑距离。实际就是能容忍 错/少 几个字符,比如“吴疫烦”和“吴亦凡”fuzziness就是2

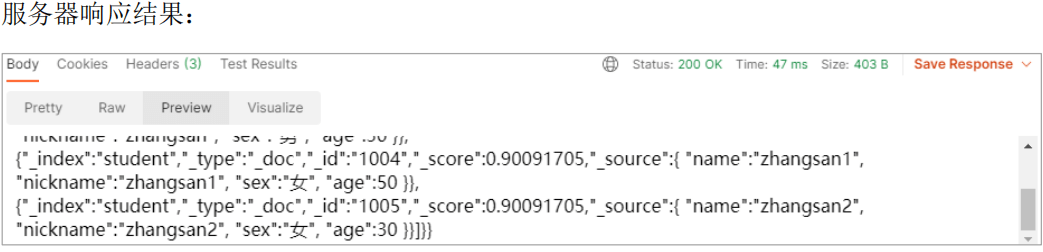

5.10 排序查询—-sort、order
text字段不支持聚合和排序
5.10.1 单字段排序查询
GET http://hadoop101:9200/shopping/_search# body如下:{"query":{"match_all":{}},"sort":{"price":{"order":"desc"}}}
5.10.2 多字段排序查询
GET http://hadoop101:9200/shopping/_search# body如下:{"query":{"match_all":{}},"sort":[{"price":{"order":"desc"}},{"_score":{"order":"desc"}}]}
5.11 高亮查询—-highlight
GET http://hadoop101:9200/shopping/_search# body如下:{"query":{"match":{"title":"华为"}},"highlight": {"pre_tags": "<font color='red'>", // 前缀"post_tags": "</font>", // 后缀"fields": {"title": {} //高亮字段}}}
5.12 分页查询—-from、size
GET http://hadoop101:9200/shopping/_search# body如下:{"query":{"match_all":{}},"from":0, // 从第几条开始,from=(页数-1)*size"size":1 // 每页多少量}
5.13 聚合查询—-aggs
text字段不支持聚合和排序
GET http://hadoop101:9200/shopping/_search// 分组(桶聚合查询){"aggs":{ // 分组查询"price_group":{ // 名称,随意起名"terms":{ // 分组"field":"price" // 分组字段}}},"size": 0 // 如果不想查询结果中带有原始数据,可以设置size为0}// 平均值{"aggs":{ // 分组查询"price_avg":{ // 名称,随意起名"avg":{ // 平均值"field":"price" // 分组字段}}},"size":0 // 如果不想查询结果中带有原始数据,可以设置size为0}// 最大值{"aggs":{ // 分组查询"price_max":{ // 名称,随意起名"max":{ // 最大值"field":"price" // 分组字段}}},"size":0 // 如果不想查询结果中带有原始数据,可以设置size为0}// 最小值{"aggs":{ // 分组查询"price_min":{ // 名称,随意起名"min":{ // 最小值"field":"price" // 分组字段}}},"size":0 // 如果不想查询结果中带有原始数据,可以设置size为0}// 去重后取总数{"aggs":{ // 分组查询"distinct_price":{ // 名称,随意起名"cardinality":{ // 去重取总数"field":"price" // 去重字段}}},"size":0}// state聚合,对某个字段一次性返回 count,max,min,avg 和 sum 五个指标{"aggs":{ // 分组查询"stats_age":{ // 名称,随意起名"stats":{ // state聚合"field":"age" // 聚合字段}}},"size":0}
5.14 桶聚合查询—-aggs、terms
桶聚和相当于 sql 中的 group by 语句 text字段不支持聚合和排序
GET http://hadoop101:9200/shopping/_search# terms聚合,分组统计,body如下:{"aggs":{"price_groupby":{"terms":{"field":"price"}}},"size":0}# 在terms分组下再进行聚合,body如下:{"aggs":{"price_groupby":{"terms":{"field":"price"},"aggs":{"sum_price":{"sum":{"field":"price"}}}}},"size":0}

若有收获,就点个赞吧
0 人点赞
