常量池
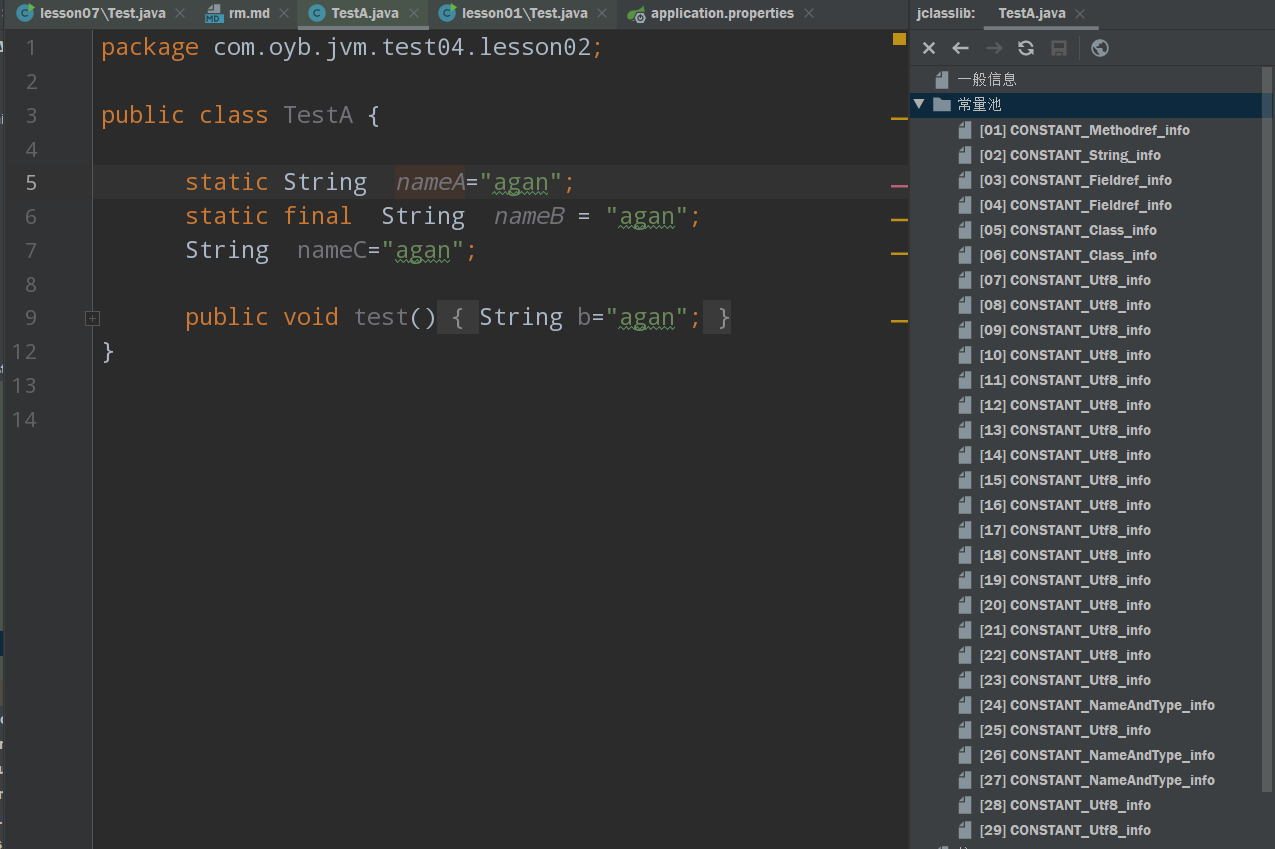
常量池(constant pool table),用于存放编译器生成的各种字面量(Literal)和符号引用(Symbolic Reference)。
字面量就是我们所说的常量概念,如文本字符串String、被声明为final的常量值等。
符号引用是一组符号来描述所引用的目标,符号可以是任何形式的字面量,只要使用时能无歧义地定位到目标即可。
一般包括下面三类常量:
类和接口名
类成员变量名
方法的名称
面试:class常量池有什么好处?有什么作用?
常量池是为了避免频繁地创建和销毁对象而影响系统性能,其实现了对象的共享。
例如字符串常量池,在编译阶段就把所有的字符串文字放到一个常量池中。
- 节省内存空间:常量池中所有相同的字符串常量被合并,只占用一个空间。
- 节省运行时间:比较字符串时,==比equals()快。对于两个引用变量,只用==判断引用是否相等,也就可以判断实际值是否相等。
代码浅析
public class TestA {static String nameA="agan";static final String nameB = "agan";String nameC="agan";public void test(){String b="agan";}}
查看构造方法的字节码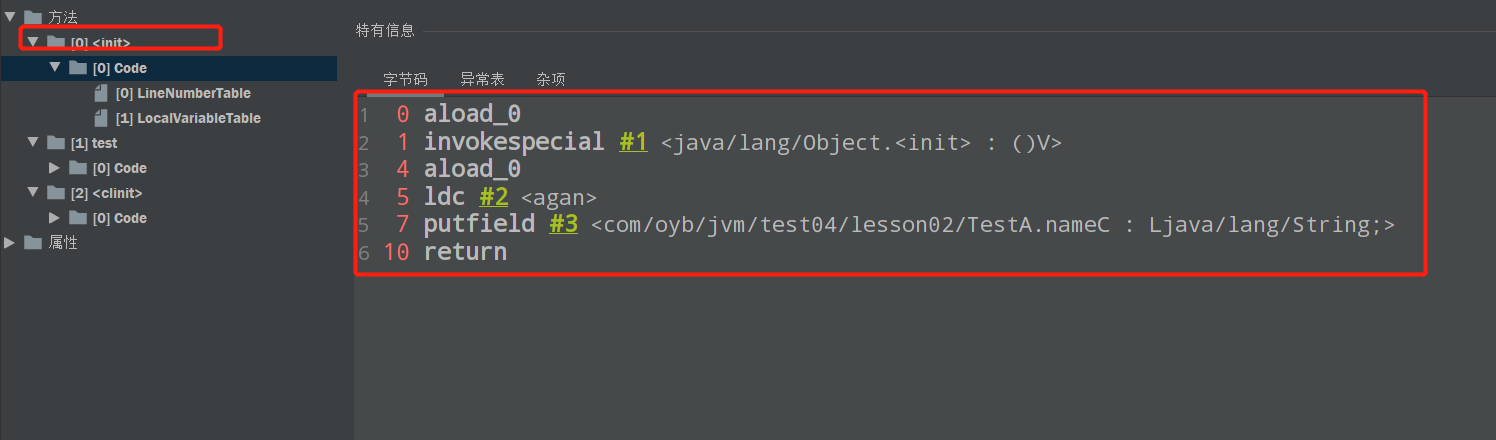
可以看到有个指令是ldc,也就是load Constant,就是从常量池中加载”agan”这个常量,后面有个指令,就是putfield,就是说,在构造方法的时候初始化了nameC这个变量,赋值为”agan”。
我们再看下test方法的字节码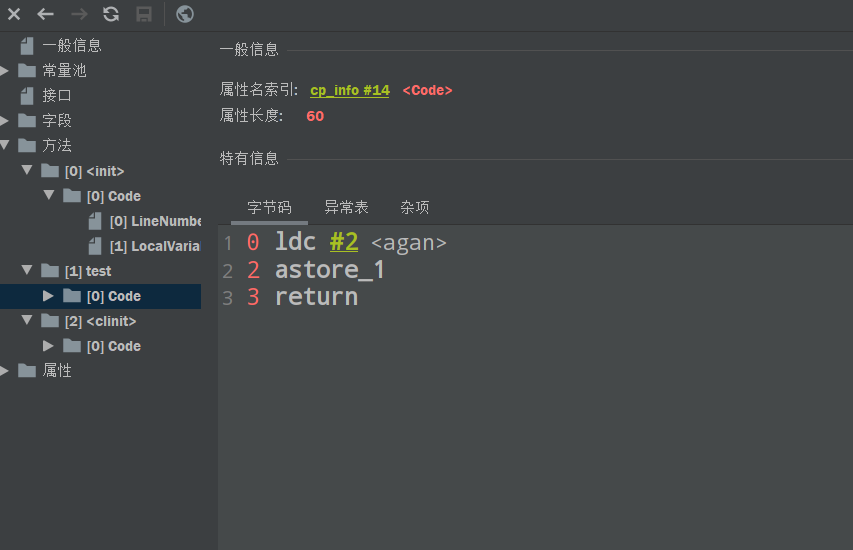
可以看到有一个ldc指令,然后执行指令astore存储了这个局部变量
再看clinit方法的字节码,也就是加载类的时候,类初始化执行的方法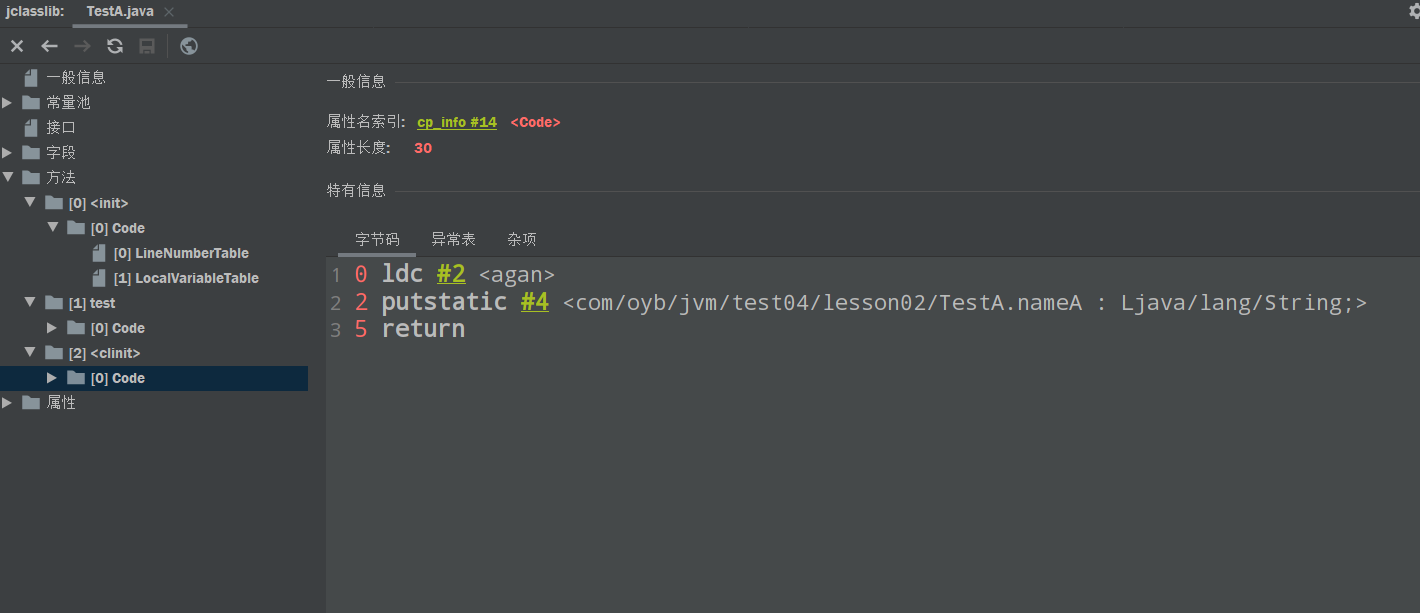
可以看到同样的,有ldc加载常量的指令,后来执行了putstatic,初始化了nameA这个类变量,这一步就是类加载的时候,对类变量进行的初始化,可以参考之前讲过的类加载的步骤。
这时候就会问了,不是还有个nameB吗?不错,但是nameB本身是常量,在编译阶段的时候就被初始化了。
个人的理解,就是编译阶段会初始化所有的常量到常量池中,字符串”agan”被放入常量池,然后nameB也被放入常量池,并且执行了类似 “ldc”和”put”指令(注意,这里说的是类似,真实的情况我也不知道,大概就这样吧),相当于nameB的指针指向了常量池中”agan”字符串。
所以,我的理解是:
在编译阶段中,先把”agan”放入常量池,然后初始化nameB,并且指向”agan”这个字符串
然后在类加载的时候,初始化了nameA这个类变量,并指向了常量池中的”agan”这个字符串
之后在对象初始化的时候,初始化了nameC这个实例变量,并指向了常量池中的”agan”这个字符串
在调用test()方法的时候,局部变量b就会指向常量池中”agan”

若有收获,就点个赞吧
0 人点赞
