面试:一个Object对象在JVM内存中占用多大
想要知道一个java对象占用内存大小,一般用一个JOL工具来计算。
JOL(Java Object Layout)是OpenJDK官方提供的Java对象内存查看工具。
只要加入依赖包即可
<dependency><groupId>org.openjdk.jol</groupId><artifactId>jol-core</artifactId><version>0.10</version></dependency>
查看以下的代码:
@Testpublic void test1() {Layouter l;//64位vm对象分布,未启动指针压缩l = new HotSpotLayouter(new X86_64_DataModel());System.out.println(ClassLayout.parseInstance(new MyObject(),l).toPrintable());System.out.println("==============================================");//64位vm对象分布,启动指针压缩l = new HotSpotLayouter(new X86_64_COOPS_DataModel());System.out.println(ClassLayout.parseInstance(new MyObject(),l).toPrintable());}
运行的结果
com.oyb.jvm.test03.lesson07.MyObject object internals:OFFSET SIZE TYPE DESCRIPTION VALUE0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)8 4 (object header) 43 23 01 f8 (01000011 00100011 00000001 11111000) (-134143165)12 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)Instance size: 16 bytesSpace losses: 0 bytes internal + 0 bytes external = 0 bytes total==============================================com.oyb.jvm.test03.lesson07.MyObject object internals:OFFSET SIZE TYPE DESCRIPTION VALUE0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)8 4 (object header) 43 23 01 f8 (01000011 00100011 00000001 11111000) (-134143165)12 4 (loss due to the next object alignment)Instance size: 16 bytesSpace losses: 0 bytes internal + 4 bytes external = 4 bytes totalProcess finished with exit code 0
未启动指针压缩 16个字节16bytes 16字节对象头(8字节的markwork,8字节的class指针)
启动指针压缩 16字节 12字节对象头(8字节的markwork 4字节的class指针)+ 4字节对齐填充
可以看到有 OFFSET、SIZE、TYPE DESCRIPTION、VALUE 这几个名词头,它们的含义分别是
OFFSET:偏移地址,单位字节;
SIZE:占用的内存大小,单位为字节;
TYPE DESCRIPTION:类型描述,其中object header为对象头;
VALUE:对应内存中当前存储的值,二进制32位;
面试:Object对象以什么格式,在内存中存储?
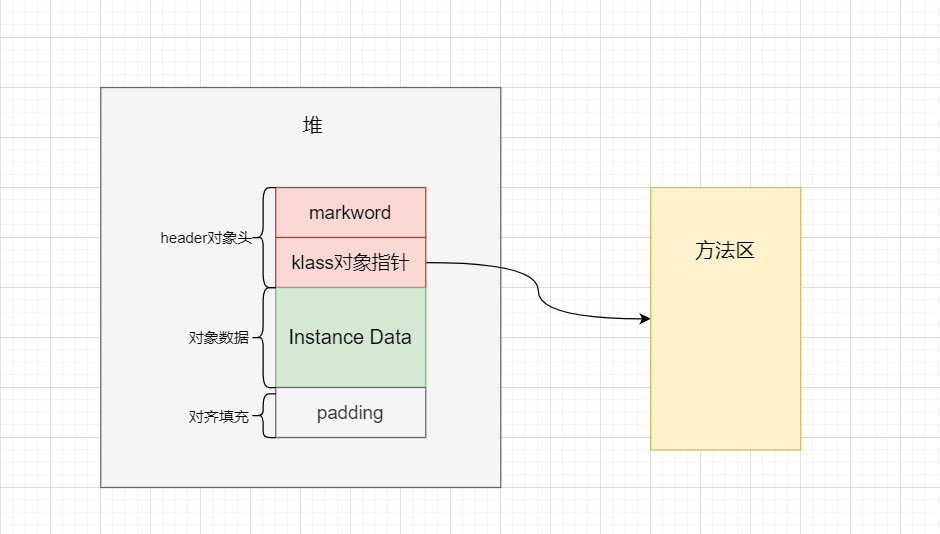
Mark Word
用于存储对象自身的运行时数据,如哈希码(HashCode)、GC分代年龄、锁状态标志、线程持有的锁、偏向线程ID、偏向时间戳等等。
Mark Word在32位JVM中的长度是32bit,在64位JVM中长度是64bit。
Kclass指针
一个class文件被JVM加载之后,就会被解析成一个Klass对象存储在方法区中。
什么是压缩指针呢?
类型指针(Class Pointer)记录的是该对象类型在MetaSpace的地址引用,
指向方法区中Class信息的指针,意味着该对象可随时知道自己是哪个Class的实例。
比如new JavaObject()这个对象,类型指针记录的就是JavaObject.class的地址引用
类型指针占用的内存大小分两种情况,当开启对象压缩时占用4个字节(JVM默认开启),关闭时占用8字节
关闭压缩指针参数:-XX:-UseCompressedOops
压缩指针不仅可以作用于对象头的类型指针,还可以作用于引用类型的字段,以及引用类型的数组。
在64位操作系统中,对象头中的类型指针占用64位(8字节),开启压缩指针后占用32位(4字节),压缩指针的目的即节省内存空间。
对齐填充(Padding)
这个部分存在的目的是为了保持对象的大小与8字节的倍数对齐
假如一个对象占用12字节,12不是8的倍数,则需要填充4字节,16刚好是8的倍数,那么这块区域就会用0进行填充;
如果对象大小刚好等于8的倍数,如16、32等,则该区域大小为0。
疑问:为什么要进行8字节内存对齐?
原因一,在默认的情况下,JVM堆中的对象默认要对齐8字节倍数,可以通过参数-XX:ObjectAlignmentlnBytes修改
原因二,是由于CPU进行内存访问时,一次寻址的指针大小是8字节,正好也是L1缓存行的大小;
如果不进行内存对齐,则可能出现跨缓存行的情况,这叫做缓存污染,如图所示:
之所以叫做“污染”,是由于obj1对象的字段被修改后,那么CPU在访问obj2对象时,必须将其重新加载到缓存行,因此影响了程序执行效率。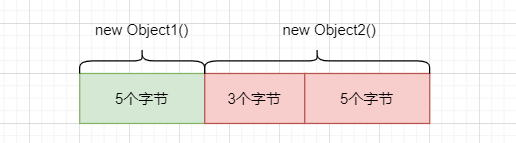
对象中的属性是如何在内存中分配的
如下面这个类
public class MyObjectData {private int i=66;private long l=6L;private String string=new String("aaaa");}
@Testpublic void test1() {Layouter l;//64位vm对象分布,未启动指针压缩l = new HotSpotLayouter(new X86_64_DataModel());System.out.println("***** " + l);System.out.println(ClassLayout.parseInstance(new MyObjectData(),l).toPrintable());System.out.println("==============================================");//64位vm对象分布,启动指针压缩l = new HotSpotLayouter(new X86_64_COOPS_DataModel());System.out.println("***** " + l);System.out.println(ClassLayout.parseInstance(new MyObjectData(),l).toPrintable());}
com.oyb.jvm.test05.lesson03.MyObjectData object internals://16字节的header(8字节markword、8字节klass指针)//8字节的long字段 值为6//4字节的int字段 值为66//4字节的对齐填充(不够8的倍数)//8字节的string字段//-8字节内存对齐 (64位vm未启动指针压缩,会出现-8的内存对齐,这个我查了很多资料,还没找到原因,有小伙伴知道原因的也告诉我一下)OFFSET SIZE TYPE DESCRIPTION VALUE0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)8 4 (object header) c5 23 01 f8 (11000101 00100011 00000001 11111000) (-134143035)12 4 (object header) 42 00 00 00 (01000010 00000000 00000000 00000000) (66)16 8 long MyObjectData.l 624 4 int MyObjectData.i 6628 4 (alignment/padding gap)32 8 java.lang.String MyObjectData.string (object)40 -8 (loss due to the next object alignment)Instance size: 32 bytesSpace losses: 4 bytes internal + -8 bytes external = -4 bytes total==============================================***** VM Layout Simulation (X64 model (compressed oops), 8-byte aligned, compact fields, field allocation style: 1)com.oyb.jvm.test05.lesson03.MyObjectData object internals:OFFSET SIZE TYPE DESCRIPTION VALUE0 4 (object header) 05 00 00 00 (00000101 00000000 00000000 00000000) (5)4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)8 4 (object header) c5 23 01 f8 (11000101 00100011 00000001 11111000) (-134143035)12 4 int MyObjectData.i 6616 8 long MyObjectData.l 624 4 java.lang.String MyObjectData.string (object)28 4 (loss due to the next object alignment)Instance size: 32 bytesSpace losses: 0 bytes internal + 4 bytes external = 4 bytes totalProcess finished with exit code 0
未开启压缩的情况:
16字节的header(8字节markword、8字节klass指针)
8字节的long字段 值为6
4字节的int字段 值为66
4字节的对齐填充(不够8的倍数)
8字节的string字段
-8字节内存对齐 (64位vm未启动指针压缩,会出现-8的内存对齐,这个我查了很多资料,还没找到原因,有小伙伴知道原因的也告诉我一下)
开启压缩的情况
12字节的header(8字节markword、4字节klass指针)
8字节的long字段 值为6
4字节的int字段 值为66
4字节的string字段(启动指针压缩,把原本8字节压缩为4个字节)
4字节的对齐填充(不够8的倍数)
来看数组的情况
@Testpublic void test2() {int[] a = {1};Layouter l;l = new HotSpotLayouter(new X86_64_COOPS_DataModel());System.out.println("***** " + l);System.out.println(ClassLayout.parseInstance(a,l).toPrintable());}
***** VM Layout Simulation (X64 model (compressed oops), 8-byte aligned, compact fields, field allocation style: 1)[I object internals:OFFSET SIZE TYPE DESCRIPTION VALUE0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)8 4 (object header) 6d 01 00 f8 (01101101 00000001 00000000 11111000) (-134217363)12 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)16 4 int [I.<elements> N/A20 4 (loss due to the next object alignment)Instance size: 24 bytesSpace losses: 0 bytes internal + 4 bytes external = 4 bytes total
12字节的header(8字节markword、4字节klass指针)
4字节的header(存储数组的长度)
4字节 数组的实例数据
4字节的对齐填充(不够8的倍数)
对象数据总结:
- 对象数据
如果对象有属性字段,则这里会有数据信息。如果对象无属性字段,则这里就不会有数据。
根据字段类型的不同占不同的字节,如boolean类型占1个字节,int类型占4个字节等等;
- 指针压缩
jdk8版本是默认开启指针压缩的,可以通过配置vm参数开启关闭指针压缩,-XX:-UseCompressedOops。
MarWord
演示下面的代码:
public class MarkWordTest {@Testpublic void test1() {MyObject obj=new MyObject();out.println(obj + " 十六进制哈希:" + Integer.toHexString(obj.hashCode()));out.println(ClassLayout.parseInstance(obj).toPrintable());}}
com.oyb.jvm.test03.lesson07.MyObject@e2d56bf 十六进制哈希:e2d56bfcom.oyb.jvm.test03.lesson07.MyObject object internals:OFFSET SIZE TYPE DESCRIPTION VALUE0 4 (object header) 01 bf 56 2d (00000001 10111111 01010110 00101101) (760659713)4 4 (object header) 0e 00 00 00 (00001110 00000000 00000000 00000000) (14)8 4 (object header) 73 00 01 f8 (01110011 00000000 00000001 11111000) (-134152077)12 4 (loss due to the next object alignment)Instance size: 16 bytesSpace losses: 0 bytes internal + 4 bytes external = 4 bytes total
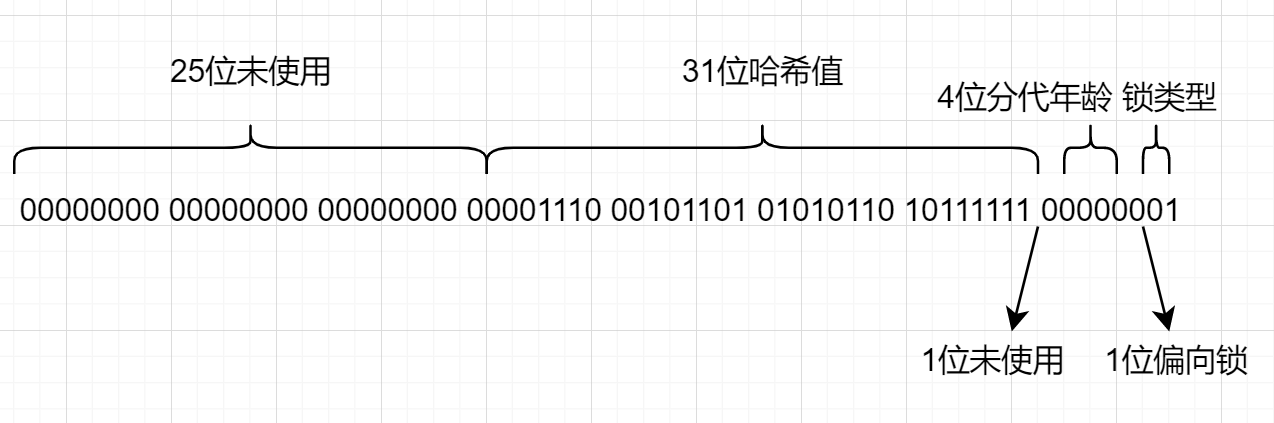
value的值格式:
—16进制—— —————————2进制—————————- ——10进制——-
01 bf 56 2d (00000001 10111111 01010110 00101101) (760659713)
com.oyb.jvm.test03.lesson07.MyObject@e2d56bf 十六进制哈希:e2d56bf
e2d56bf是16进制,我们在value中也能找到对应的值
00 00 00 0e 2d56bf
为什么这么排列存储?
小端:较高的有效字节存储在较高的存储器地址,较低的有效字节存储在较低的存储器地址。(小存小)
大端:较高的有效字节存储在较低的存储器地址,较低的有效字节存储在较高的存储器地址。
这里涉及到大端小端的知识。
2进制
com.oyb.jvm.test03.lesson07.MyObject object internals:OFFSET SIZE TYPE DESCRIPTION VALUE0 4 (object header) 01 bf 56 2d (00000001 10111111 01010110 00101101) (760659713)4 4 (object header) 0e 00 00 00 (00001110 00000000 00000000 00000000) (14)8 4 (object header) 73 00 01 f8 (01110011 00000000 00000001 11111000) (-134152077)12 4 (loss due to the next object alignment)
说到这里,我们来回顾一道经典的面试题:
为什么晋升到老年代的年龄设置(XX:MaxTenuringThreshold)不能超过15?
因为就给了age四个bit空间,最大就是1111(二进制)也就是15,多了没地方存。
面试:为什么Java对象头要存储锁信息?
先来看个案例:代码如下:
synchronized(obj){//锁内容处理System.out.println("锁住......");}
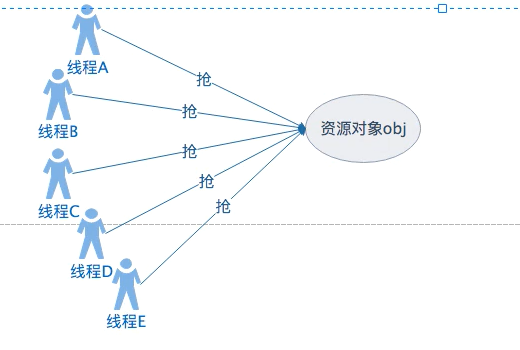
现在问题来了,高并发多线程抢obj,那如果是线程B抢到,线程B就锁住了obj,其他线程就不能抢。
问题:谁来记录线程B抢到obj,并告诉其他线程等待?
如果是你,你会怎么做?一般就2种方案,
A方案:开辟一个空间来存储,obj=B,当B解锁时把obj=null。其他线程每次检查obj是否为null,不是为null就能继续抢obj。
B方案:在obj的对象头开辟一块锁空间把B设置进去,当B解锁时,obj的对象头锁空间清空,其他线程只要对象头锁空间为空,都可以继续抢。
这2种方案中,A方案有个致命性的缺陷,就是新开辟的空间有线程安全问题,还要继续加锁,麻烦。
而B方案就没有线程安全的问题了,obj本身就是被锁住的,谁拿到锁谁在obj身上设置自己。
这个就是我们之前讲过的对象头Mark Word空间。
Mar Word空间存储了4种锁
无锁 —> 001
偏向锁 —> 101
轻量级锁 —> 000
重量级锁 —> 010
随着锁的竞争,锁可以从偏向锁升级到轻量级锁,再升级到重量级锁。

若有收获,就点个赞吧
0 人点赞
