面试:为什么会出现CMS垃圾回收器
由于历代垃圾回收器都是串行或者独占式回收的,例如前面3个年轻代回收器 + 2个老年代回收器。都是必须停止工作线程后,gc线程才开始垃圾清除。
在这样的大背景下,于2002年JDK1.4.2.发布CMS,它是哪个时代第一次实现并发收集器(相对来说),即实现了让垃圾收集线程与用户线程同时工作。
CMS的特色就是停顿时间短(低延迟),停顿时间越短就越适合用户交互的程序,越能提升用户体验。
在G1收集器面世之前,CMS基本都是JVM的标配,甚至是现在市面都是很多系统在使用CMS。
7步图解CMS
第一阶段:初始标记
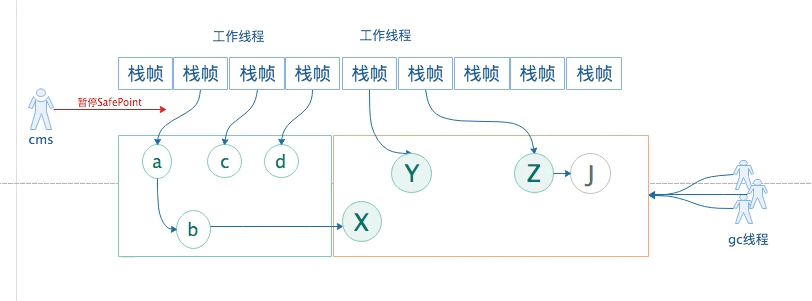
- 先把工作线程挂起,所有工作线程进入安全点SafePoint后,当前处于STW状态。
- gc线程,采用多线程,从gc root标记直接可达的对象(XYZ)。CMS标记的,年轻代有ps垃圾收集器去标记
什么是直接可达?
从栈帧、方法区(静态变量、常量)、本地方法栈等,查找第一个引用对象。,
例如 直接引用的对象都是abcdyz就被标记为直接可达。
其他对象不标记
第二阶段:并发标记
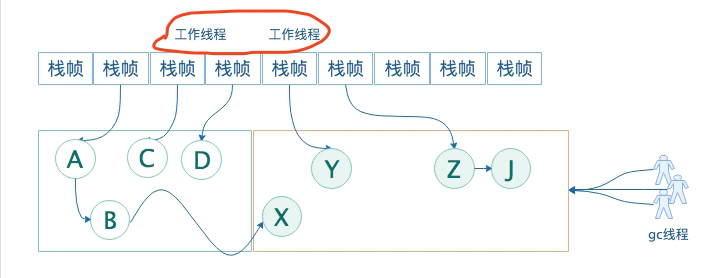
并发标记最大的特点:工作线程不再是STW状态,它处于running状态,并且工作线程和gc线程同时工作。
gc线程本阶段在干嘛?
通过遍历第一个阶段《初始标记》标记出来的存活对象,继续递归遍历老年代,并标记可直接或间接到达的所有老年代存活对象(J)。
工作线程在本阶段干嘛?
- 工作线程的栈帧,继续生产新的对象,继续往eden区填对象。
- 工作线程继续运行,旧的栈帧就出栈,出栈后老对象就死亡,即存活对象转变为垃圾对象。
由于该阶段工作线程还一直在生产新对象和老对象编程垃圾对象。
那这阶段新产生的对象和垃圾对象,如何处理?
不处理?不处理的话就会遗漏,导致垃圾回收不干净
处理?处理的话,就非常复杂,要对整个老年代再重新gc roots重新标记,即费时又费力。
哪有什么好的算法能快速解决呢?
JVM设计了一个cardtable来记录并发阶段老年代对象变更后的存储。
具体技术实现如下:
- 先把内存划分为大小相同的Card(卡片),每个card的大小为512Byte,每个card可以装1个或多个对象
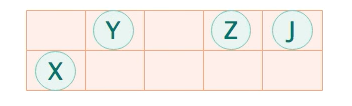
- 整个老年代的card连起来就成了一张card table,记录可能存在的老年代中有新生代的引用的对象地址,来避免扫描整个老年代。
例如:工作线程在此阶段,
老年代对象的引用关系变更:Y的栈帧出栈了,Y就没人引用了,故把Y的card对应的card_table的value设置为1(dirty)
直接在老年代分配对象,survivor空间不足,直接分配K L M对象,对应的card也设置为dirty
新生代的对象晋升到老年代:D从新生代晋升到老年代,对应的card也设置为dirty。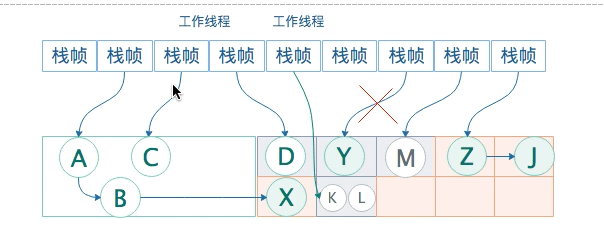
并发标记阶段只负责将引用发生改变的Card标记为Dirty状态,不负责处理;、
第三阶段:预清除阶段
此阶段工作线程也是不停地,它和gc线程同时工作。
在并发预清洗阶段,将会重新扫描《并发标记》阶段被标记为Dirty的card,并标记直接或间接引用的对象,然后清除Card标识。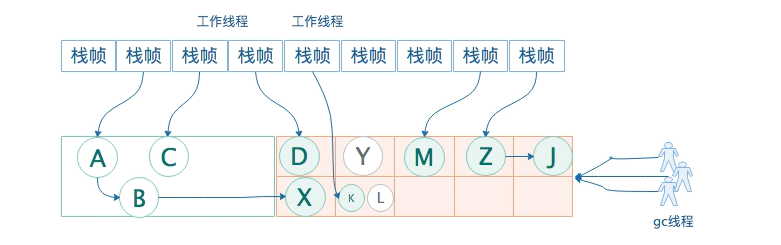
gc线程,扫描cardtable,把标记为dirty的card找出来,把card里面的对象,重新gc roots标记可直接或间接到达的对象。
例如经过此轮的整理,老年代存活对象新增D M K。
第四阶段:可中断的预清理
此阶段工作线程也是不停的,它和gc线程同时工作
此阶段触发的前提是,eden区的内存使用量大于参数CMSScheduleRemarkEdenSizeThreshold默认是2M。
如果eden区对象太少,就没必要执行,直接跳下一阶段《重新标记》。
应该有很多同学有疑问,为什么会设计这个阶段,它有什么作用?
因为下一阶段《重新标记阶段》会出现STW,为了使暂停时间最短,CMS设计了《预清理阶段》和《可中断的预清理》,目的就是为了给《重新标记阶段》降低压力,保障STW暂停时间最短。
在该阶段,主要循环的做两件事:
- 处理survivor区的对象,标记可达的老年代对象
- 和上一个阶段《预清理阶段》一样,处理cardtable的对象。
该阶段还为了控制执行时间,设置了3个中断的条件:
- 设置最多循环的次数 CMSMaxAbortablePrecleanLoops,默认是0,表示没有循环次数的限制。
- 如果这个阶段的时间达到了阈值CMSMaxAbortablePrecleanTime,默认是5s,会退出循环。
- 如果Eden的内存使用率达到了阈值CMSScheduleRemarkEdenPenetration,默认50%,会退出循环。
总之一句话:设计该阶段的目的就是为了给下一阶段《重新标记阶段》降低压力,保障STW暂停时间最短。
第五阶段:重新标记
《预清理阶段》和《可中断的预清理》都是为重新标记阶段做准备。
由于重新标志阶段会发生(STW),所以要保证尽可能的停顿时间短,不然会影响应用程序的用户体验。
干3件事:
第一件事:扫描整个年轻代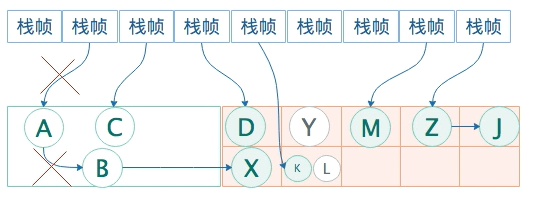
为什么要扫描新生代呢?
因为对于老年代中的对象,如果被新生代中的对象引用,那么就会被视为存活对象,即使新生代的对象已经不可达了,也会使用这些不可达的对象当做cms的“gc root”,来扫描老年代;(例如A的栈帧出栈或 A断开B的引用,导致X一直被误认为是gc root,像这种为了判断X死亡,只能扫描新生代了)
扫描整个新生代,耗时会比较长,如何优化?
当大量引用老年代的新生代对象死亡时,耗时较长的时候,可以加入参数-XX:+CMSScavengeBeforeRemark,在重新标记之前,先执行一次ygc,回收掉年轻代的对象无用的对象,并将对象放入幸存者区或者晋升到老年代,这样再进行年轻代扫描的时候,只需要扫描幸存者区的对象即可,一般幸存者区非常小,这大大减少了扫描时间。
第二件事:扫描gc roots
扫描的目的是,例如J 是在《并发标记阶段》扫描出来的,如果后面Z断开了J的引用关系,是不是害得继续扫描一遍。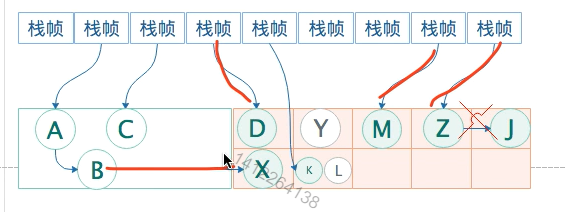
第三件事:扫描cardtable
和《预清理阶段》一样,gc线程,扫描cardtable,把标记为dirty的card找出来,把card里面的对象,重新gc roots标记可以直接或间接到达的对象。
所以可以看出,在整个过程中,该过程《重新标志》是最慢的,做的事情太多了。
第六阶段:并发清理
并发清理阶段,主要工作是 清理所有未被标记的死亡对象,回收被占用的空间,例如清理YLJ对象。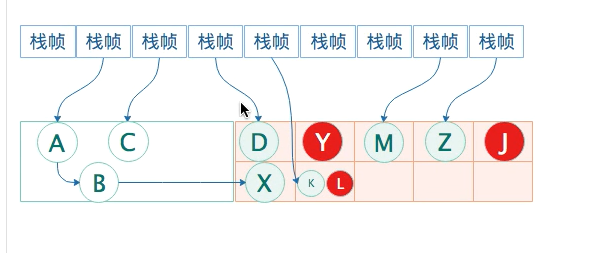
第七阶段:并发重置
图解分析:为什么CMS会出现内存碎片?如何解决?
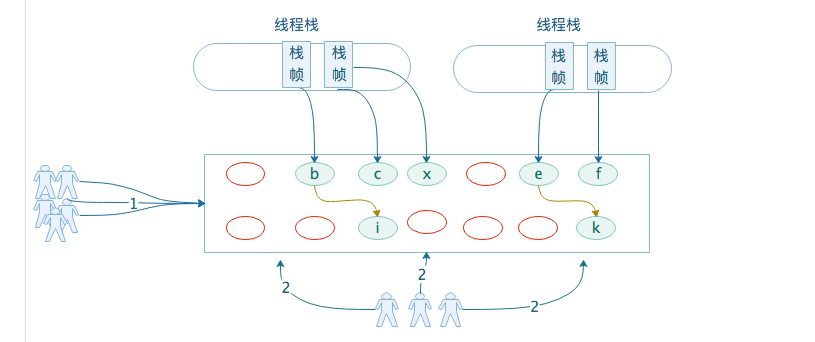
经理了【并发清理】阶段后,垃圾对象都被清除了,剩下内存碎片,碎片化导致内存空间不连续,内存空间白白被占用但没数据。
如果碎片化太多时,会有什么后果?
会给大对象分配带来很大麻烦,往往会 出现老年代还有很大空间剩余,但是无法找到足够大的连续空间来分配当前对象,不得不提前触发一次Full GC。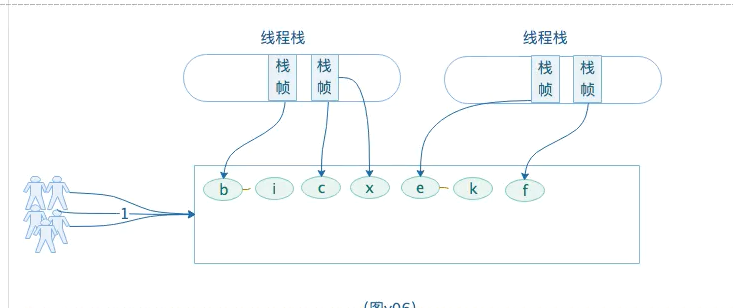
答案是整理
为了解决这个问题,CMS收集器提供了一个-XX: +UseCMSCompactAtFullCollection开关参数(默认是开启的),用于在CMS收集器顶不住要进行FullGC开启内存碎片的合并整理过程,内存整理的过程是无法并发的,空间碎片问题没有了,但停顿时间不得不边长。
虚拟机设计者还提供了另外一个参数-XX: CMSFullCGsBeforeCompaction,这参数是用于设置执行多少次不压缩的Full GC后
默认值为0,表示每次进入Full GC时都进行碎片整理,
把CMSFullGCsBeforeCompaction配置为10,就会让上面说的第一个条件变成每隔10次真正的full GC做一次压缩(而不是每10次CMS并发GC就做一次压缩,目前VM里没有这样的参数)
这会使Full gc更少做压缩,也就更容易使CMS的old gen受碎片化问题的困扰
总结CMS
特点:
- 分代:老年代
- 工作方式:多线程并发回收
- 算法:标记-清除
- 性能设计:停顿时间短
优点:
并发收集
低延迟
缺点:
垃圾收集结束后残余大量空间碎片

若有收获,就点个赞吧
0 人点赞
