- 1. Redis 持久化
- 是否开启 AOF 功能,默认是 no
- AOF文件的名称
- 表示每执行一次写命令,立即记录到 AOF 文件
- 写命令执行完先放入 AOF 缓冲区,然后表示每隔 1 秒将缓冲区数据写到 AOF 文件,是默认方案
- 写命令执行完先放入 AOF 缓冲区,由操作系统决定何时将缓冲区内容写回磁盘
- AOF 文件比上次文件 增长超过多少百分比则触发重写
- AOF 文件体积最小多大以上才触发重写
- 经过 bgrewriteaof 命令之后会被重写为
- 创建目录
- 拷贝配置文件
- 修改配置(端口号)
- 修改配置(保护模式)
- 修改配置(工作目录), 因为使用 sed 不好更改路径, 所以这里手动修改
- 把上面路径更改成
- 虚拟机本身有多个 IP,为了避免将来混乱,我们需要在 redis.conf 文件中指定每一个实例的绑定 ip 信息
- 3. Redis 哨兵
- 4. Redis 分片集群
1. Redis 持久化
1.1 RDB 持久化
RDB 全称 Redis Database Backup file(Redis 数据备份文件),也被叫做 Redis 数据快照。简单来说就是把内存中的所有数据都记录到磁盘中。当Redis 实例故障重启后,从磁盘读取快照文件,恢复数据。快照文件称为 RDB 文件,默认是保存在当前运行目录
1.1.1 执行时机
1. 执行 save 命令
# 由 Redis 主进程执行 RDB, 会阻塞所有命令127.0.0.1:6379> saveOK
save 命令会导致主进程执行 RDB,这个过程中其它所有命令都会被阻塞。只有在数据迁移时可能用到
2. 执行 bgsave 命令
# 开启子线程执行 RDB,避免主进程受到影响127.0.0.1:6379> bgsaveBackground saving started
这个命令执行后会开启独立进程完成 RDB,主进程可以持续处理用户请求,不受影响
3. Redis 停机时
Redis 停机时会执行一次 save 命令,实现 RDB 持久化
4. 触发 RDB 条件时
Redis 内部有触发 RDB 的机制,可以在 redis.conf 文件中找到,格式如下:
# 900秒内,如果至少有 1 个 key 被修改,则执行 bgsave# 如果是save "" 则表示禁用 RDBsave 900 1save 300 10save 60 10000# 是否压缩 ,建议不开启,压缩也会消耗 cpu,磁盘的话不值钱rdbcompression yes# RDB 文件名称dbfilename dump.rdb# 文件保存的路径目录dir ./
1.1.2 RDB 原理
bgsave 开始时会 fork 主进程得到子进程,子进程共享主进程的内存数据。完成 fork 后读取内存数据并写入 RDB 文件
fork 采用的是 copy-on-write 技术:
- 当主进程执行读操作时,访问共享内存
- 当主进程执行写操作时,则会拷贝一份数据,执行写操作
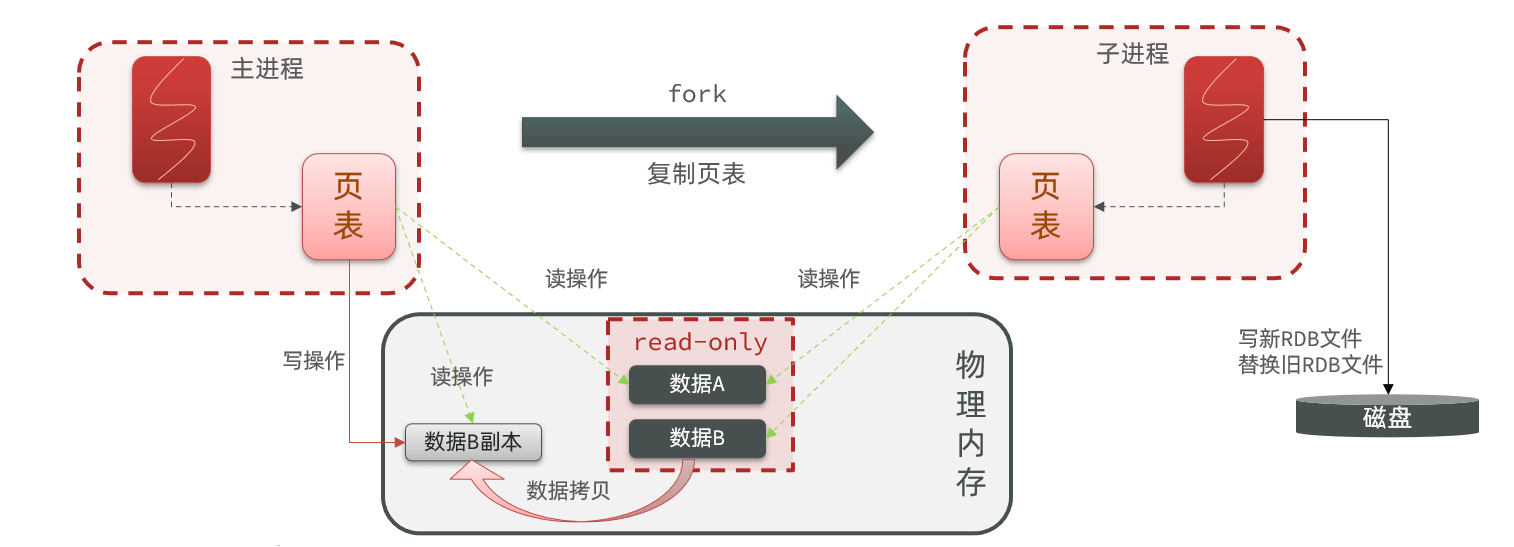
1.1.3 总结
RDB 方式 bgsave 的基本流程?
- fork 主进程得到一个子进程,共享内存空间
- 子进程读取内存数据并写入新的 RDB 文件
- 用新 RDB 文件替换旧的 RDB 文件
RDB 的缺点
- RDB 执行间隔时间长,两次 RDB 之间写入数据有丢失的风险
- fork子进程、压缩、写出 RDB 文件都比较耗时
1.2 AOF 持久化
1.2.1 AOF 原理
AOF 全称为 Append Only File(追加文件)。Redis 处理的每一个写命令都会记录在 AOF 文件,可以看做是命令日志文件1.2.2 AOF 配置
AOF 默认是关闭的,需要修改 redis.conf 配置文件来开启 AOF ```是否开启 AOF 功能,默认是 no
appendonly yes
AOF文件的名称
appendfilename “appendonly.aof”
表示每执行一次写命令,立即记录到 AOF 文件
appendfsync always
写命令执行完先放入 AOF 缓冲区,然后表示每隔 1 秒将缓冲区数据写到 AOF 文件,是默认方案
appendfsync everysec
写命令执行完先放入 AOF 缓冲区,由操作系统决定何时将缓冲区内容写回磁盘
appendfsync no
AOF 文件比上次文件 增长超过多少百分比则触发重写
auto-aof-rewrite-percentage 100
AOF 文件体积最小多大以上才触发重写
auto-aof-rewrite-min-size 64mb
| 配置项 | 刷盘时机 | 优点 | 缺点 || --- | --- | --- | --- || always | 同步刷盘 | 可靠性高,几乎不丢数据 | 性能影响大 || everysec | 每秒刷盘 | 性能适中 | 最多丢失 1s 数据 || no | 操作系统控制 | 性能最好 | 可靠性查,可能丢失大量数据 |<a name="fgxtf"></a>### 1.2.3 AOF 文件重写因为是记录命令,AOF 文件会比 RDB 文件大的多。而且 AOF 会记录对同一个 key 的多次写操作,但只有最后一次写操作才有意义。通过执行`bgrewriteaof` 命令,可以让 AOF 文件执行重写功能,用最少的命令达到相同效果
set num 123 set name jack set num 666
经过 bgrewriteaof 命令之后会被重写为
mset name jack num 666
<a name="NbXG5"></a>## 1.3 RDB 和 AOF 对比RDB 和 AOF 各有自己的优缺点,如果对数据安全性要求较高,在实际开发中往往会**结合**两者来使用| | RDB | AOF || --- | --- | --- || 持久化方式 | 定时对整个内存做快照 | 记录每一次执行的命令 || 数据完整性 | 不完整,两次备份之间会丢失 | 相对完整,取决于刷盘策略 || 文件大小 | 会有压缩,文件体积小 | 记录命令,文件体积大 || 宕机恢复速度 | 很快 | 慢 || 数据恢复优先级 | 低,因为数据完整性不如 AOF | 高,因为数据完整性更高 || 系统资源占用 | 高<br />大量 CPU 和内存消耗 | 低<br />主要是磁盘 IO 资源,但 AOF 重写时会占用大量的 CPU 和内存资源 || 使用场景 | 可以容忍数分钟的数据丢失,追求更快的启动速度 | 对数据安全性要求较高常见 |<a name="nYpgw"></a># 2. Redis 主从单节点 Redis 的并发能力是有上限的,要进一步提高 Redis 的并发能力,就需要搭建主从集群,实现读写分离<br />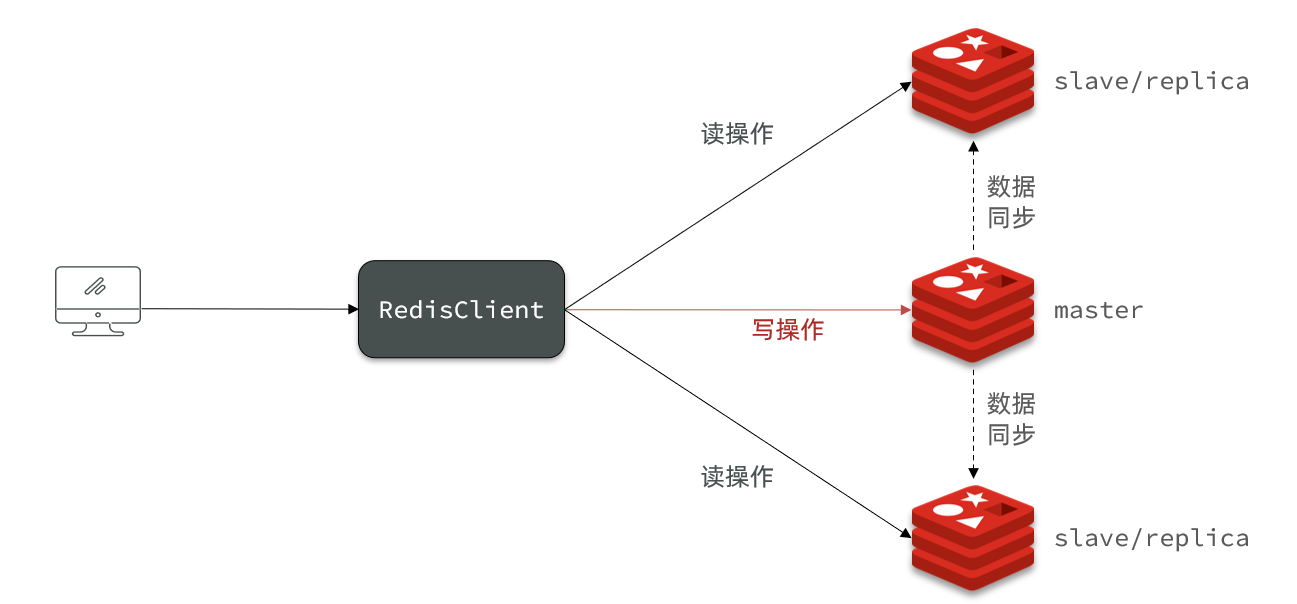<a name="Wb109"></a>## 2.1 主从集群搭建<a name="Rh7Kc"></a>### 2.1.1 集群架构| ip | port | 角色 || --- | --- | --- || 192.168.0.118 | 7001 | master || 192.168.0.118 | 7002 | slave || 192.168.0.118 | 7003 | slave |<a name="j9vb5"></a>### 2.1.2 环境搭建
创建目录
mkdir 7001 7002 7003
拷贝配置文件
cp redis.conf ./7001/ cp redis.conf ./7002/ cp redis.conf ./7003/
修改配置(端口号)
sed -i -e ‘s/6379/7001/g’ ./7001/redis.conf sed -i -e ‘s/6379/7002/g’ ./7002/redis.conf sed -i -e ‘s/6379/7003/g’ ./7003/redis.conf
修改配置(保护模式)
sed -i -e ‘s/protected-mode yes/protected-mode no/g’ ./7001/redis.conf sed -i -e ‘s/protected-mode yes/protected-mode no/g’ ./7002/redis.conf sed -i -e ‘s/protected-mode yes/protected-mode no/g’ ./7003/redis.conf
修改配置(工作目录), 因为使用 sed 不好更改路径, 所以这里手动修改
dir .
把上面路径更改成
dir /Users/ruanrenzhao/environment/redis/7001 dir /Users/ruanrenzhao/environment/redis/7002 dir /Users/ruanrenzhao/environment/redis/7003
虚拟机本身有多个 IP,为了避免将来混乱,我们需要在 redis.conf 文件中指定每一个实例的绑定 ip 信息
replica-announce-ip 192.168.0.118 replica-announce-ip 192.168.0.118 replica-announce-ip 192.168.0.118
<a name="jLcJy"></a>### 2.1.3 开启主从关系现在三个实例还没有任何关系,要配置主从可以使用 `replicaof` 或者 `slaveof`(5.0以前)命令永久生效,修改 redis.conf 配置文件,添加配置 `slaveof <masterip> <masterport>`<br />临时生效,在命令行中执行 `slaveof <masterip> <masterport>`
redis-server 7001/redis.conf redis-server 7002/redis.conf redis-server 7003/redis.conf
```MacBook-Pro:~ ruanrenzhao$ redis-cli -p 7002127.0.0.1:7002> slaveof 192.168.0.118 7001OKMacBook-Pro:~ ruanrenzhao$ redis-cli -p 7003127.0.0.1:7003> slaveof 192.168.0.118 7001OK
127.0.0.1:7001> info replication# Replicationrole:masterconnected_slaves:2slave0:ip=192.168.0.118,port=7002,state=online,offset=154,lag=1slave1:ip=192.168.0.118,port=7003,state=online,offset=154,lag=1master_failover_state:no-failovermaster_replid:c9d81f33671aec2d907d2dbee7a59c01fafcae4emaster_replid2:0000000000000000000000000000000000000000master_repl_offset:154second_repl_offset:-1repl_backlog_active:1repl_backlog_size:1048576repl_backlog_first_byte_offset:1repl_backlog_histlen:154
127.0.0.1:7002> info replication# Replicationrole:slavemaster_host:192.168.0.118master_port:7001master_link_status:upmaster_last_io_seconds_ago:1master_sync_in_progress:0slave_read_repl_offset:112slave_repl_offset:112slave_priority:100slave_read_only:1replica_announced:1connected_slaves:0master_failover_state:no-failovermaster_replid:c9d81f33671aec2d907d2dbee7a59c01fafcae4emaster_replid2:0000000000000000000000000000000000000000master_repl_offset:112second_repl_offset:-1repl_backlog_active:1repl_backlog_size:1048576repl_backlog_first_byte_offset:1repl_backlog_histlen:112
127.0.0.1:7003> info replication# Replicationrole:slavemaster_host:192.168.0.118master_port:7001master_link_status:upmaster_last_io_seconds_ago:2master_sync_in_progress:0slave_read_repl_offset:70slave_repl_offset:70slave_priority:100slave_read_only:1replica_announced:1connected_slaves:0master_failover_state:no-failovermaster_replid:c9d81f33671aec2d907d2dbee7a59c01fafcae4emaster_replid2:0000000000000000000000000000000000000000master_repl_offset:70second_repl_offset:-1repl_backlog_active:1repl_backlog_size:1048576repl_backlog_first_byte_offset:15repl_backlog_histlen:56
2.2 主从数据同步原理
2.2.1 全量同步
主从第一次建立连接时,会执行全量同步,将 master 节点的所有数据都拷贝给 slave 节点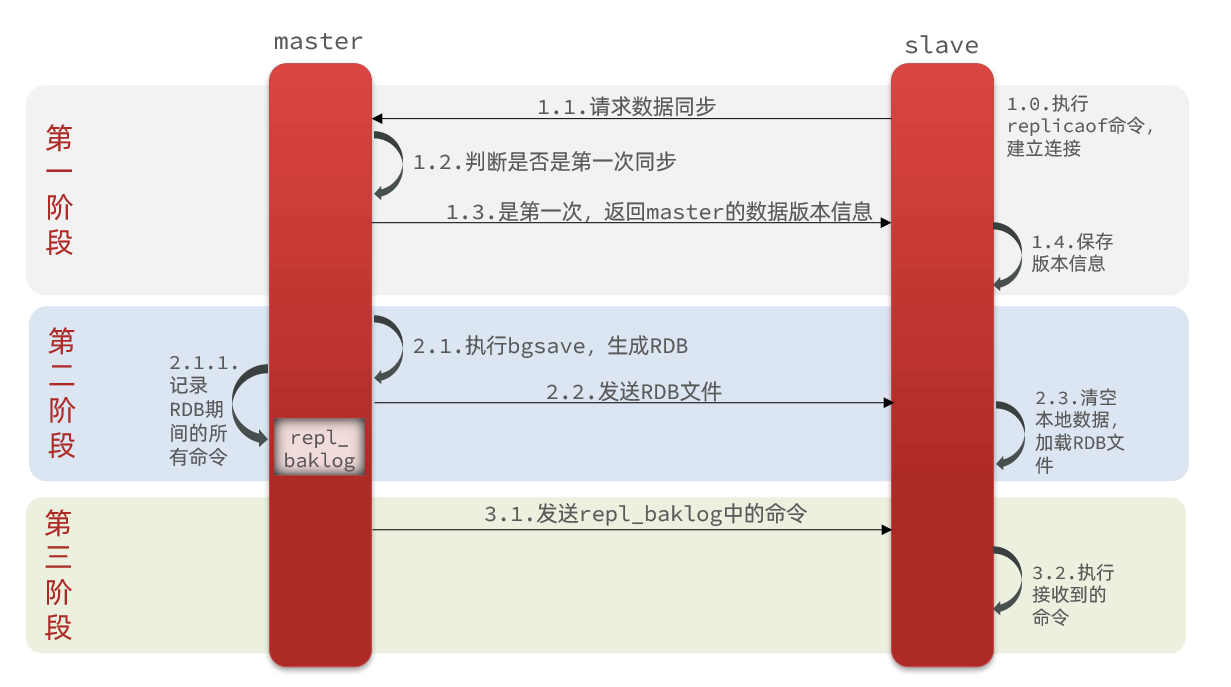
master 如何判断 slave 是不是第一次来同步数据?
这里会用到两个很重要的概念可以作为判断依据
- Replication Id:简称 replid,是数据集的标记,id 一致则说明是同一数据集。每一个 master 都有唯一的 replid,slave 则会继承 master 节点的replid
- offset:偏移量,随着记录在 repl_baklog 中的数据增多而逐渐增大。slave 完成同步时也会记录当前同步的 offset。如果 slave 的 offset 小于master 的 offset,说明 slave 数据落后于 master,需要更新
因此 slave 做数据同步,必须向 master 声明自己的 replication id 和 offset,master 才可以判断到底需要同步哪些数据
因为 slave 原本也是一个 master,有自己的 replid 和 offset,当第一次变成 slave 与 master 建立连接时,发送的 replid 和 offset 是自己的 replid 和 offset,master 判断发现 slave 发送来的 replid 与自己的不一致,说明这是一个全新的 slave,就知道要做全量同步了。master 会将自己的 replid 和 offset 都发送给这个 slave,slave 保存这些信息。以后 slave 的 replid 就与 master 一致了
因此 master 判断一个节点是否是第一次同步的依据,就是看 replid 是否一致
完整流程描述
- slave节点请求增量同步
- master 节点判断 replid,发现不一致,拒绝增量同步
- master 将完整内存数据生成 RDB,发送 RDB 到 slave
- slave 清空本地数据,加载 master 的 RDB
- master 将 RDB 期间的命令记录在 repl_baklog,并持续将 log 中的命令发送给 slave
- slave 执行接收到的命令,保持与 master 之间的同步
2.2.2 增量同步
全量同步需要先做 RDB,然后将 RDB 文件通过网络传输个 slave,成本太高了。因此除了第一次做全量同步,其它大多数时候 slave 与 master 都是做增量同步。
什么是增量同步?就是只更新 slave 与 master 存在差异的部分数据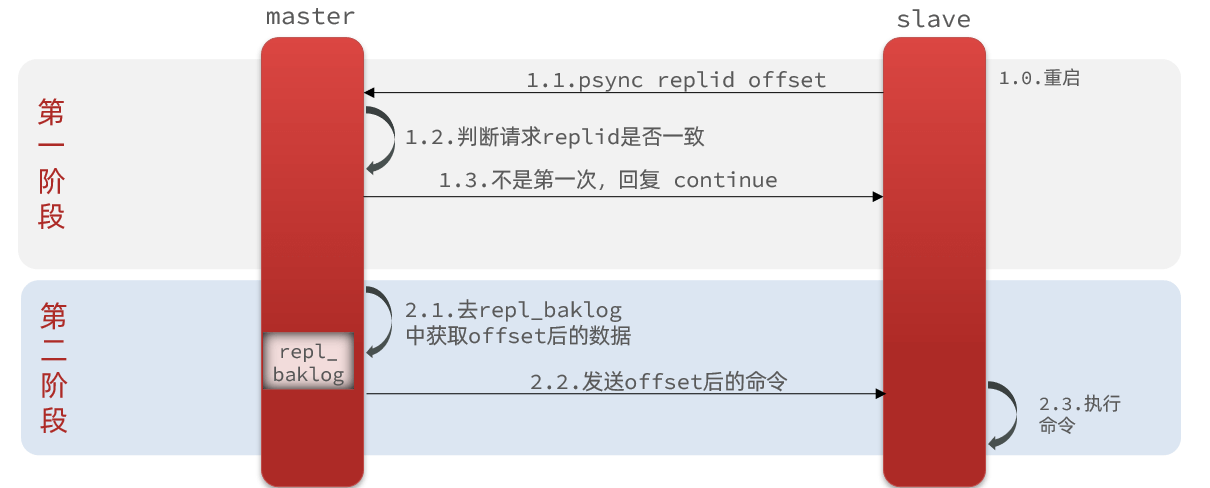
2.2.3 repl_baklog 原理
master 怎么知道 slave 与自己的数据差异在哪里?
这就要说到全量同步时的 repl_baklog 文件了。这个文件是一个固定大小的数组,只不过数组是环形,也就是说角标到达数组末尾后,会再次从 0 开始读写,这样数组头部的数据就会被覆盖。
repl_baklog 中会记录 Redis 处理过的命令日志及 offset,包括 master 当前的 offset,和 slave 已经拷贝到的 offset
注意 repl_baklog 大小有上限,写满后会覆盖最早的数据,如果 slave 断开时间过久,导致尚未备份的数据被覆盖,则无法基于 log 做增量同步,只能再次全量同步
2.2.4 主从同步优化
可以从以下几个方面来优化 Redis 主从就集群
- 在 master 中配置
repl-diskless-sync yes启用无磁盘复制,避免全量同步时的磁盘 IO - Redis 单节点上的内存占用不要太大,减少 RDB 导致的过多磁盘 IO
- 适当提高 repl_baklog 的大小,发现 slave 宕机时尽快实现故障恢复,尽可能避免全量同步
- 限制一个 master 上的 slave 节点数量,如果实在是太多 slave,则可以采用 主-从-从 链式结构,减少 master 压力
3. Redis 哨兵
3.1 哨兵集群搭建
3.1.1 集群架构
| ip | port | 角色 | | —- | —- | —- | | 192.168.0.118 | 27001 | s1 | | 192.168.0.118 | 27002 | s2 | | 192.168.0.118 | 27003 | s3 |
3.1.2 环境搭建
# 创建目录mkdir s1 s2 s3# 创建 sentinel.conf 文件, 内容见下方cp sentinel.conf ./s1/cp sentinel.conf ./s2/cp sentinel.conf ./s3/# 修改配置(端口号)sed -i -e 's/27001/27002/g' s2/sentinel.confsed -i -e 's/27001/27003/g' s3/sentinel.conf# 修改配置(工作目录)sed -i -e 's/s1/s3/g' s2/sentinel.confsed -i -e 's/s1/s3/g' s3/sentinel.conf
# 当前 sentinel 实例的端口port 27001sentinel announce-ip 192.168.0.118# 指定主节点信息# mymaster: 主节点名称,自定义,任意写# 192.168.0.118 7001 主节点的 ip 和端口号# 2: 选举 master 时的 quorum 值sentinel monitor mymaster 192.168.0.118 7001 2sentinel down-after-milliseconds mymaster 5000sentinel failover-timeout mymaster 60000dir "/Users/ruanrenzhao/environment/redis/s1"
3.1.3 哨兵集群实验
redis-sentinel s1/sentinel.confredis-sentinel s2/sentinel.confredis-sentinel s3/sentinel.conf
尝试让 master 节点 7001 宕机
# 主观认为 192.168.0.118 7001 节点下线6908:X 09 Jun 2022 16:02:41.167 # +sdown master mymaster 192.168.0.118 7001# quorum 达标(超过 2 个节点认为下线),触发 odown(客观认为下线)6908:X 09 Jun 2022 16:02:41.234 # +odown master mymaster 192.168.0.118 7001 #quorum 3/26908:X 09 Jun 2022 16:02:43.629 # +new-epoch 36908:X 09 Jun 2022 16:02:43.629 # +try-failover master mymaster 192.168.0.118 70016908:X 09 Jun 2022 16:02:43.633 * Sentinel new configuration saved on disk# sentienl 内部选举一个 leader,选中的 sentinel 实例去执行故障切换6908:X 09 Jun 2022 16:02:43.633 # +vote-for-leader 407bb952fa8bbbef2cd4ca9f131fd8dedc1e7afe 3# 其它两个节点选举 sentinel leader 实例为 407bb952fa8bbbef2cd4ca9f131fd8dedc1e7afe6908:X 09 Jun 2022 16:02:43.637 # b4d6dde06d1ed38f04e9a37cd64e26b0571f6fe7 voted for 407bb952fa8bbbef2cd4ca9f131fd8dedc1e7afe 36908:X 09 Jun 2022 16:02:43.637 # 21cd54f88e8a0a897037507e528a6d0081804537 voted for 407bb952fa8bbbef2cd4ca9f131fd8dedc1e7afe 36908:X 09 Jun 2022 16:02:43.691 # +elected-leader master mymaster 192.168.0.118 7001# 准备选举一个 slave 作为 master6908:X 09 Jun 2022 16:02:43.691 # +failover-state-select-slave master mymaster 192.168.0.118 7001# 投票选中了 192.168.0.118:7002 节点6908:X 09 Jun 2022 16:02:43.760 # +selected-slave slave 192.168.0.118:7002 192.168.0.118 7002 @ mymaster 192.168.0.118 7001# 让 192.168.0.118:7002 节点执行 slaveof noone, 即成为新的 master 节点6908:X 09 Jun 2022 16:02:43.760 * +failover-state-send-slaveof-noone slave 192.168.0.118:7002 192.168.0.118 7002 @ mymaster 192.168.0.118 7001# 192.168.0.118:7002 节点等待提升,其实就是让其它节点执行 slaveof 192.168.0.118 70026908:X 09 Jun 2022 16:02:43.865 * +failover-state-wait-promotion slave 192.168.0.118:7002 192.168.0.118 7002 @ mymaster 192.168.0.118 70016908:X 09 Jun 2022 16:02:44.323 * Sentinel new configuration saved on disk# 192.168.0.118:7002 正式提升为 master 节点6908:X 09 Jun 2022 16:02:44.324 # +promoted-slave slave 192.168.0.118:7002 192.168.0.118 7002 @ mymaster 192.168.0.118 7001# 修改下线的 7001 实例,让它标记为 7002 的 slave6908:X 09 Jun 2022 16:02:44.324 # +failover-state-reconf-slaves master mymaster 192.168.0.118 7001# 修改 7003 实例的配置,标记为 7002 的 slave6908:X 09 Jun 2022 16:02:44.410 * +slave-reconf-sent slave 192.168.0.118:7003 192.168.0.118 7003 @ mymaster 192.168.0.118 7001# 事件处理结束6908:X 09 Jun 2022 16:02:44.744 # -odown master mymaster 192.168.0.118 70016908:X 09 Jun 2022 16:02:45.186 * +slave-reconf-inprog slave 192.168.0.118:7003 192.168.0.118 7003 @ mymaster 192.168.0.118 70016908:X 09 Jun 2022 16:02:45.186 * +slave-reconf-done slave 192.168.0.118:7003 192.168.0.118 7003 @ mymaster 192.168.0.118 70016908:X 09 Jun 2022 16:02:45.238 # +failover-end master mymaster 192.168.0.118 7001# 主节点切换完成6908:X 09 Jun 2022 16:02:45.238 # +switch-master mymaster 192.168.0.118 7001 192.168.0.118 70026908:X 09 Jun 2022 16:02:45.238 * +slave slave 192.168.0.118:7003 192.168.0.118 7003 @ mymaster 192.168.0.118 70026908:X 09 Jun 2022 16:02:45.238 * +slave slave 192.168.0.118:7001 192.168.0.118 7001 @ mymaster 192.168.0.118 70026908:X 09 Jun 2022 16:02:45.240 * Sentinel new configuration saved on disk6908:X 09 Jun 2022 16:02:50.313 # +sdown slave 192.168.0.118:7001 192.168.0.118 7001 @ mymaster 192.168.0.118 7002
MacBook-Pro:redis ruanrenzhao$ redis-cli -p 7001127.0.0.1:7001> info replication# Replicationrole:slavemaster_host:192.168.0.118master_port:7002master_link_status:downmaster_last_io_seconds_ago:-1master_sync_in_progress:1slave_read_repl_offset:47718slave_repl_offset:47718master_sync_total_bytes:-1master_sync_read_bytes:0master_sync_left_bytes:-1master_sync_perc:-0.00master_sync_last_io_seconds_ago:1master_link_down_since_seconds:-1slave_priority:100slave_read_only:1replica_announced:1connected_slaves:0master_failover_state:no-failovermaster_replid:38bf6d7234541ad873aadf293700d06e8cc377d0master_replid2:816bc3d68ac2b7dd8f74d8238dbb82ecc4304d49master_repl_offset:47718second_repl_offset:45581repl_backlog_active:1repl_backlog_size:1048576repl_backlog_first_byte_offset:45581repl_backlog_histlen:2138
3.2 哨兵原理
3.2.1 集群结构和作用
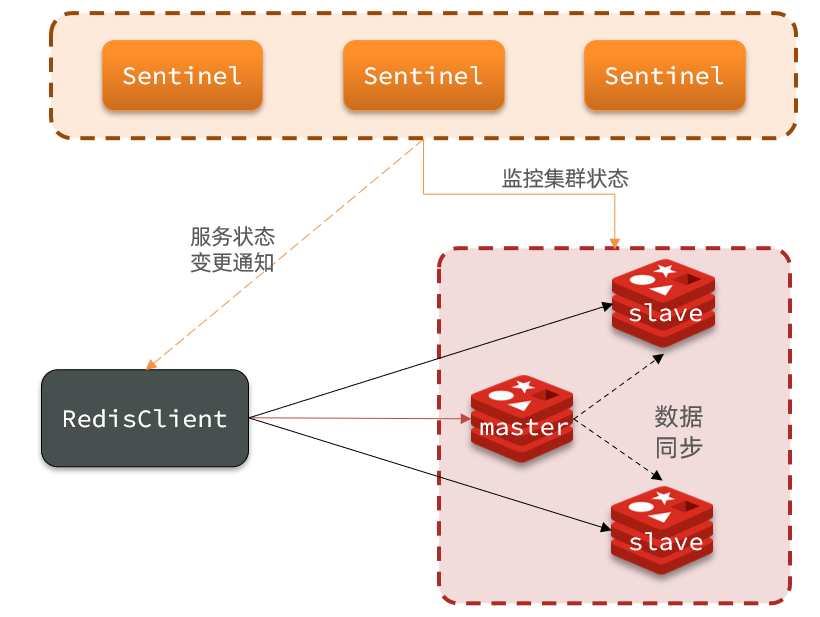
哨兵的作用如下:
- 监控:Sentinel 会不断检查您的master和slave是否按预期工作
- 自动故障恢复:如果 master 故障,Sentinel 会将一个 slave 提升为 master。当故障实例恢复后也以新的 master 为主
通知:Sentinel 充当 Redis 客户端的服务发现来源,当集群发生故障转移时,会将最新信息推送给 Redis 的客户端
3.2.2 集群监控原理
Sentinel 基于心跳机制监测服务状态,每隔 1 秒向集群的每个实例发送 ping 命令:
主观下线:如果某 sentinel 节点发现某实例未在规定时间响应,则认为该实例主观下线
客观下线:若超过指定数量(quorum)的 sentinel 都认为该实例主观下线,则该实例客观下线。quorum 值最好超过 Sentinel 实例数量的一半
3.2.3 集群恢复原理
一旦发现 master 故障,sentinel 需要在 slave 中选择一个作为新的 master,选择依据是这样的:
首先会判断 slave 节点与 master 节点断开时间长短,如果超过指定值(down-after-milliseconds * 10)则会排除该 slave 节点
- 然后判断 slave 节点的 slave-priority 值,越小优先级越高,如果是 0 则永不参与选举
- 如果 slave-prority 一样,则判断 slave 节点的 offset 值,越大说明数据越新,优先级越高
- 最后是判断 slave 节点的运行 id 大小,越小优先级越高
当选出一个新的master后,该如何实现切换。流程如下:
- sentinel 给备选的 slave1 节点发送
slaveof no one命令,让该节点成为 master - sentinel 给所有其它 slave 发送
slaveof 192.168.0.118 7002命令,让这些 slave 成为新 master 的从节点,开始从新的 master 上同步数据。 最后,sentinel 将故障节点标记为 slave,当故障节点恢复后会自动成为新的 master 的 slave 节点
3.3 RestTemplate 访问哨兵集群
在 Sentinel 集群监管下的 Redis 主从集群,其节点会因为自动故障转移而发生变化,Redis 的客户端必须感知这种变化,及时更新连接信息
Spring 的 RedisTemplate 底层利用 lettuce 实现了节点的感知和自动切换 ```java @Configuration public class RedisConfig {/**
- MASTER:从主节点读取
- MASTER_PREFERRED:优先从 master 节点读取,master 不可用才读取 replica
- REPLICA:从 slave(replica)节点读取
- REPLICA _PREFERRED:优先从 slave(replica)节点读取,所有的 slave 都不可用才读取 master
*/
@Bean
public LettuceClientConfigurationBuilderCustomizer clientConfigurationBuilderCustomizer() {
return new LettuceClientConfigurationBuilderCustomizer() {
}; }@Overridepublic void customize(LettuceClientConfiguration.LettuceClientConfigurationBuilder clientConfigurationBuilder) {clientConfigurationBuilder.readFrom(ReadFrom.REPLICA_PREFERRED);}
4. Redis 分片集群

若有收获,就点个赞吧
0 人点赞
