背景
信也科技(拍拍贷)在2016年前大部分使用的技术都是微软.net平台的技术栈,这个时期部署的都是那些巨大而且笨重的单体应用。这些应用通常都没有明确的业务领域划分、系统耦合太严重。随着公司规模和业务体量的快速增长,那些笨重的单体应用由于结构复杂、迭代周期长、部署缓慢、无法进行回滚以及灰度发布等问题,已经无法满足业务的高速迭代的要求。
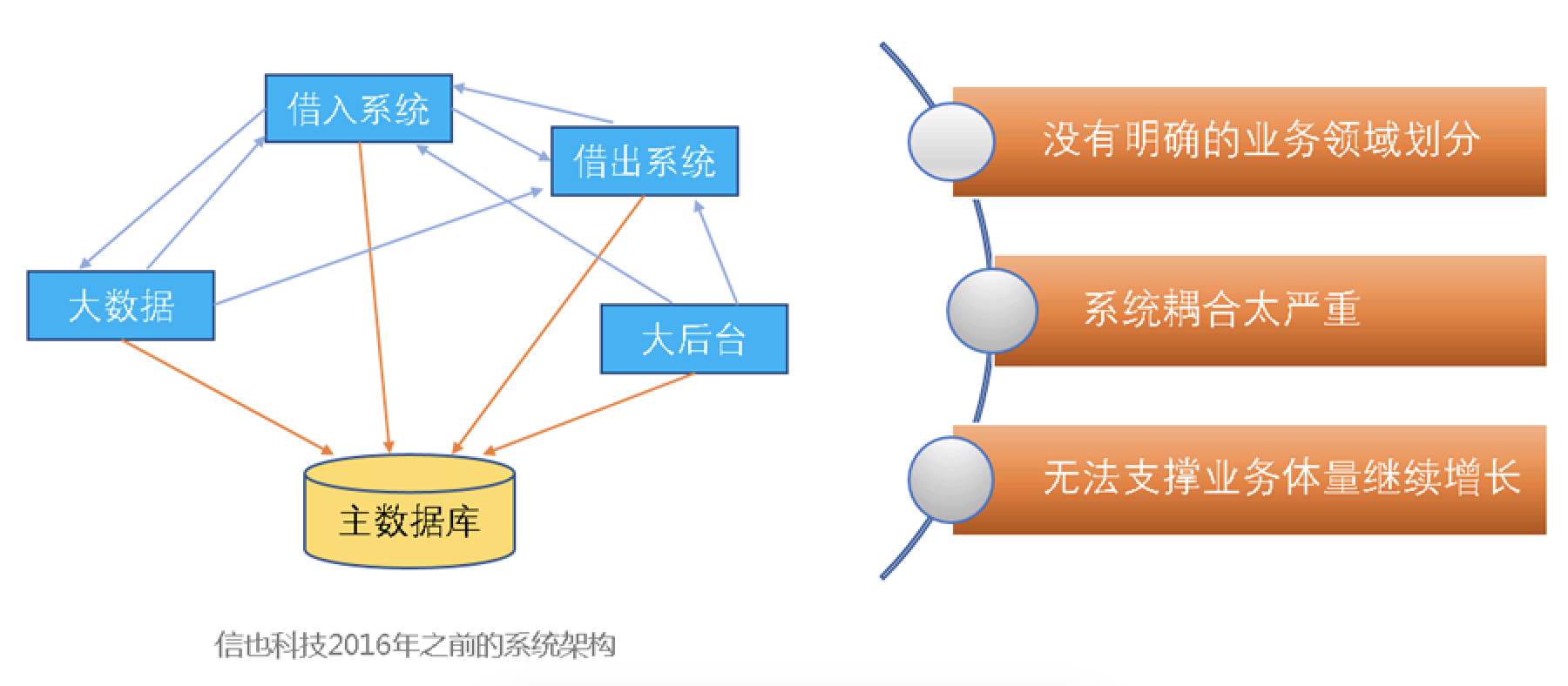
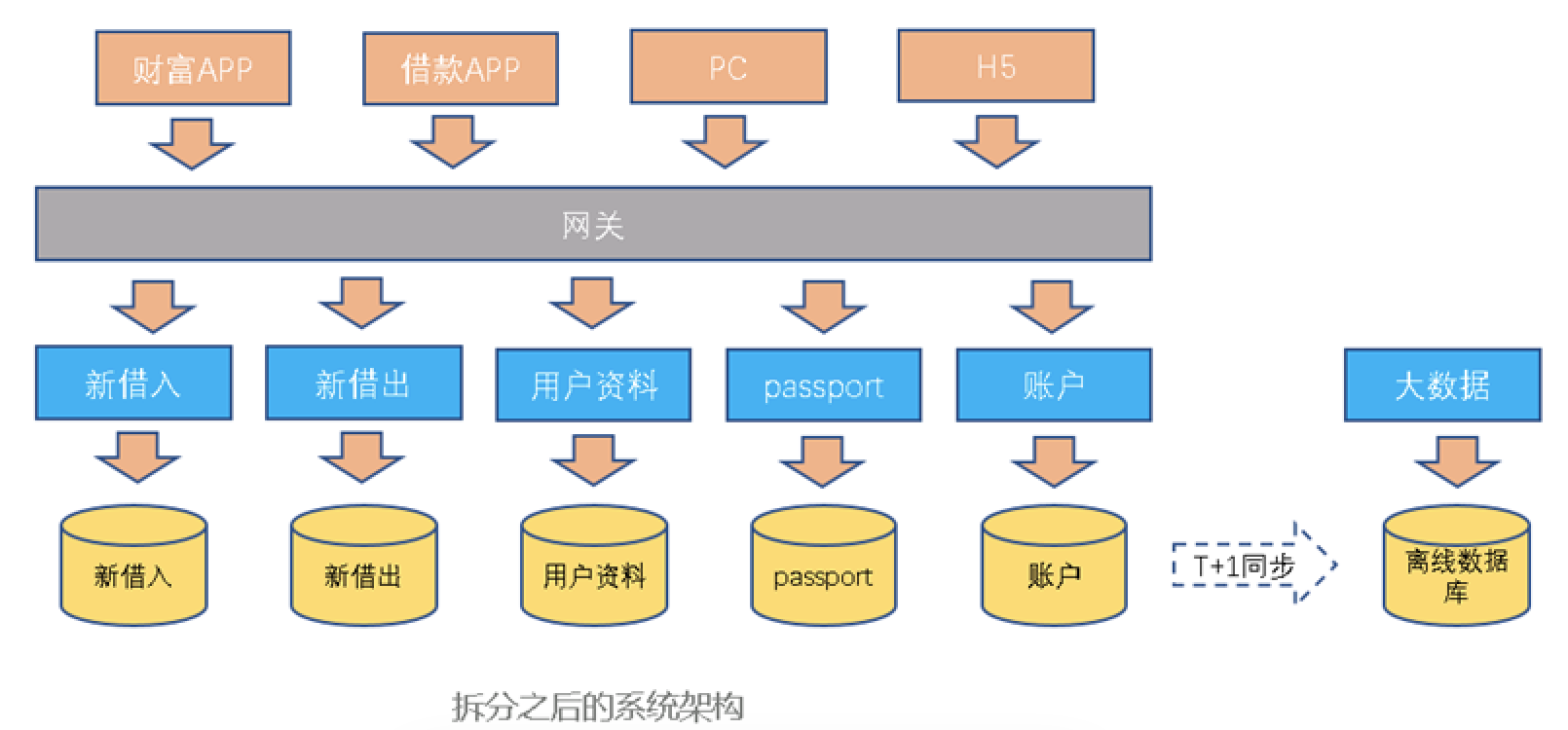
所以从2016年开始,信也科技内部开始做系统拆分,同时开始进行.net转java的技术栈转型。系统拆分之后,各应用的业务领域划分更加明确,应用也更加的瘦身。各个应用通过明确的接口定义进行交互。每次业务的迭代只需更新部分应用,迭代周期可以控制在周甚至是天。
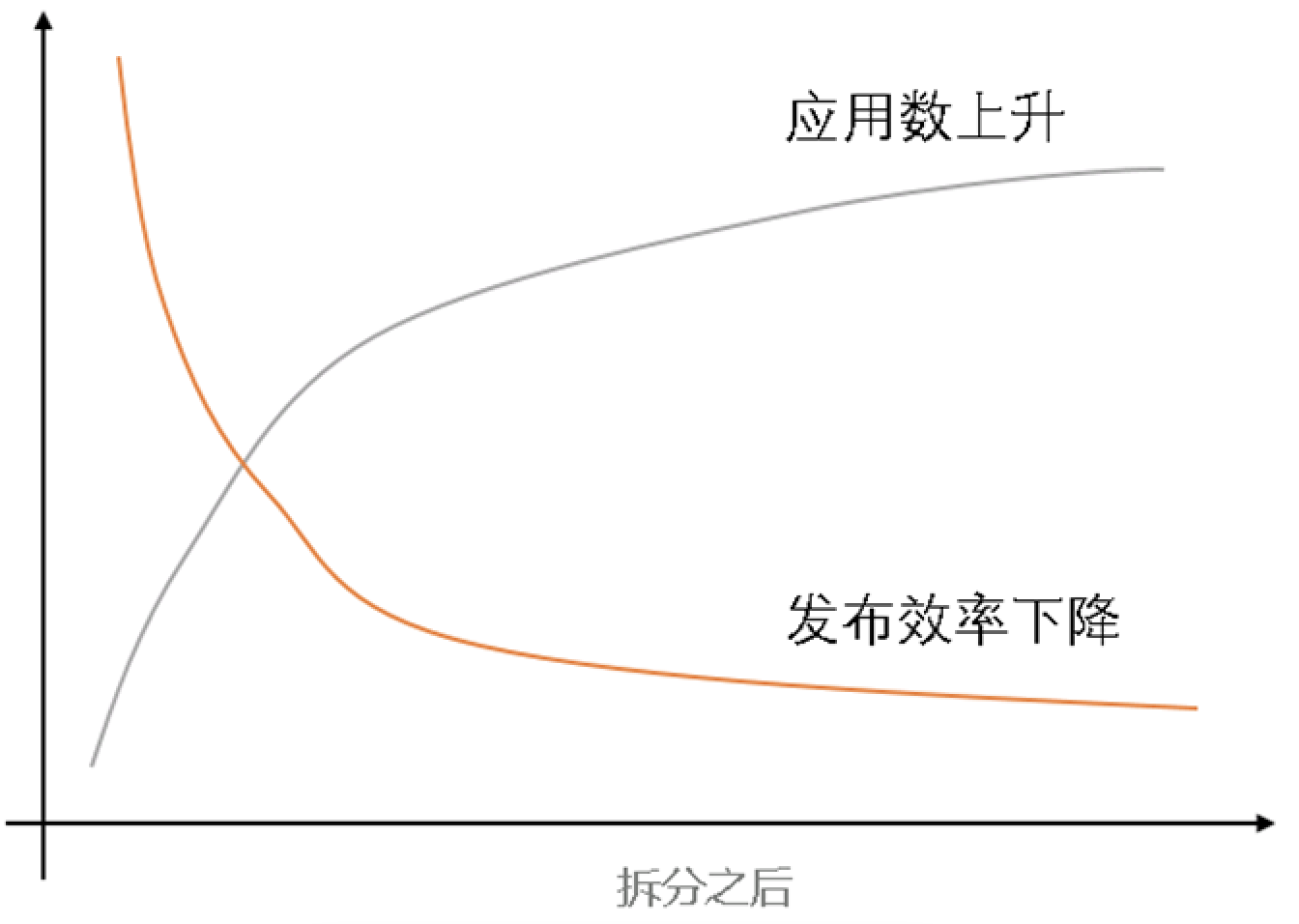
但是系统拆分也不是银弹。拆分之后,应用数都会有个显著的上升。有时甚至每周都会有创建新应用和销毁旧应用。在应用数上升到一定规模后,发布效率开始下降。
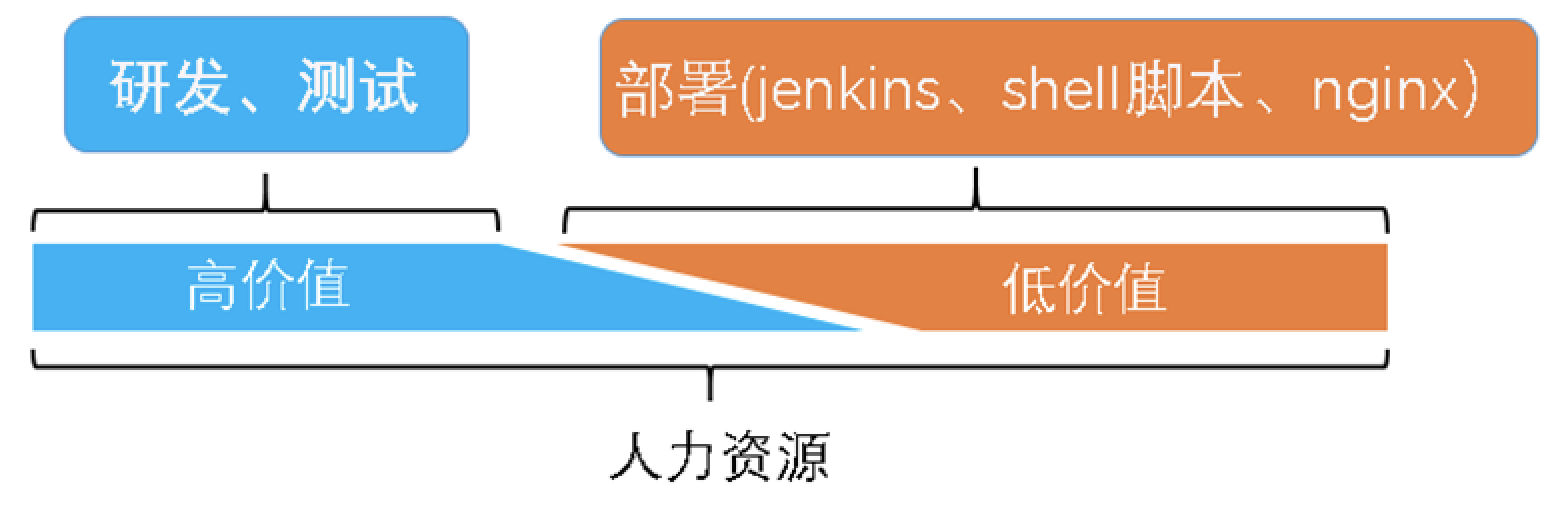
信也科技之前如果有新应用上线,需要在测试环境、预发环境和生产环境各配置一套jenkins发布脚本。发布脚本里面都是些繁琐复杂的shell指令。同时在测试和预发环境,每个团队都要维护自己的一套nginx,供自己的服务给其他人访问。研发和测试人员的大量时间花在了应用部署上面,而且这些都是低价值的事情,给公司造成人力资源的浪费。
为此,一个好的应用交付系统迫在眉睫。在2018年,容器技术已经发展了5年多,技术日趋成熟。同时kubernetes在容器调度领域有一统江湖之势。公司决定使用kubernetes和docker技术构建基于容器的下一代交付系统。
网络选型
Kubernetes落地首先要解决的就是网络的选型。k8s支持的网络插件有很多,比如:flannel、calico、weavenet等。刚入门的人可能无从下手。选择哪种网络需要考虑到现有应用的部署构架以及应用的使用网络的方式。比如:容器部署的应用如何和现有的应用进行网络互访?网络是否可以满足每个应用实例使用需求?
从网络本身来讲主要分为underlay网络和overlay网络。这2种网络有如下特点:

信也科技在网络选型的时候考虑到之前的应用都是部署在虚拟机上面,大多数的应用都要从虚拟机迁到容器。网络需要兼容应用在虚机的使用方式以及支持虚拟机和容器的互访。同时考虑到信也科技在k8s项目投入的人力资源只有3人,简单和高效也是我们考虑的因素。为此我们决定使用macvlan作为k8s的网络模式。macvlan最大的特点就是每个容器都有自己独立的IP和MAC地址,这样可以很好的兼容应用在虚拟机里面对网络的使用方式。
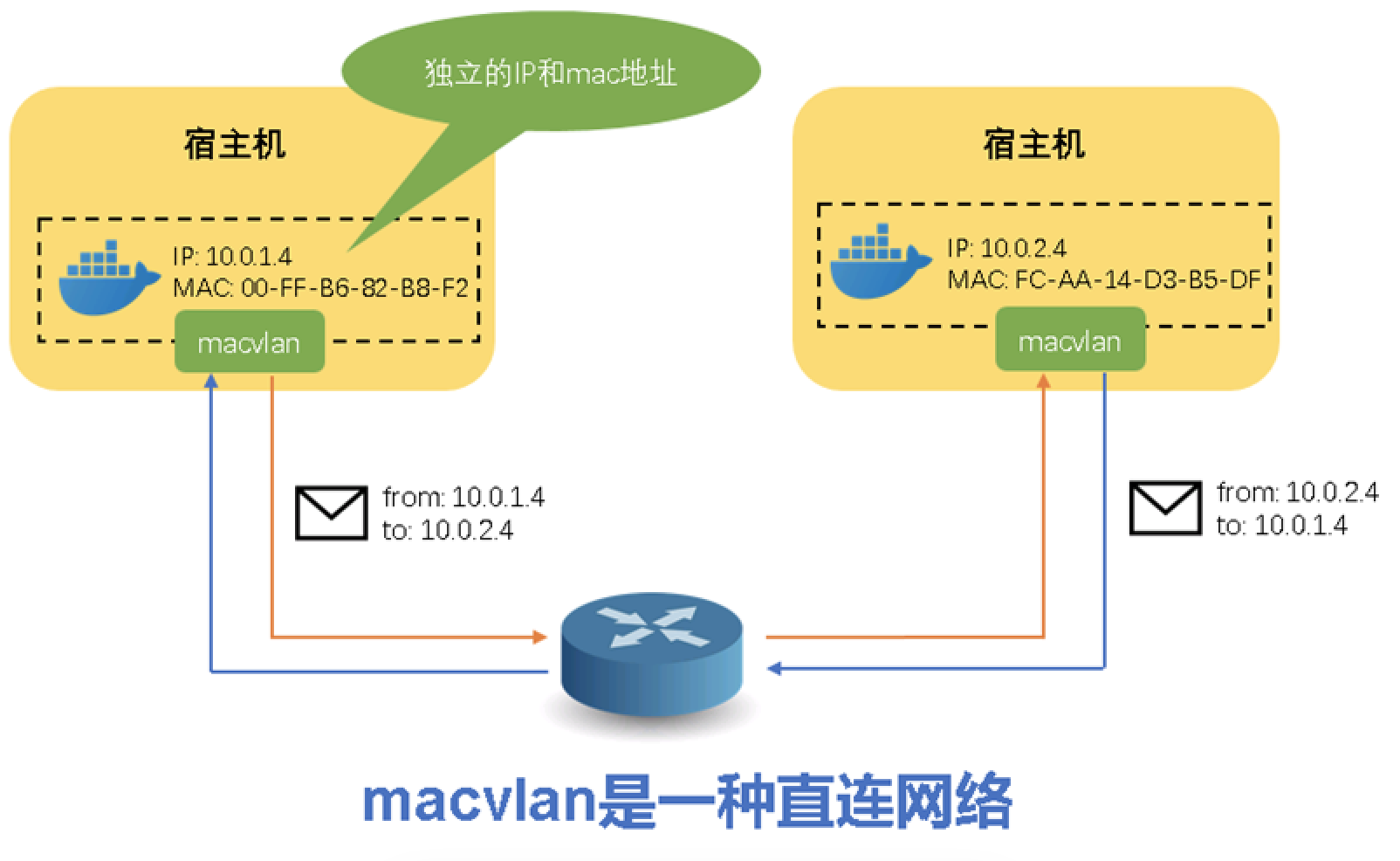
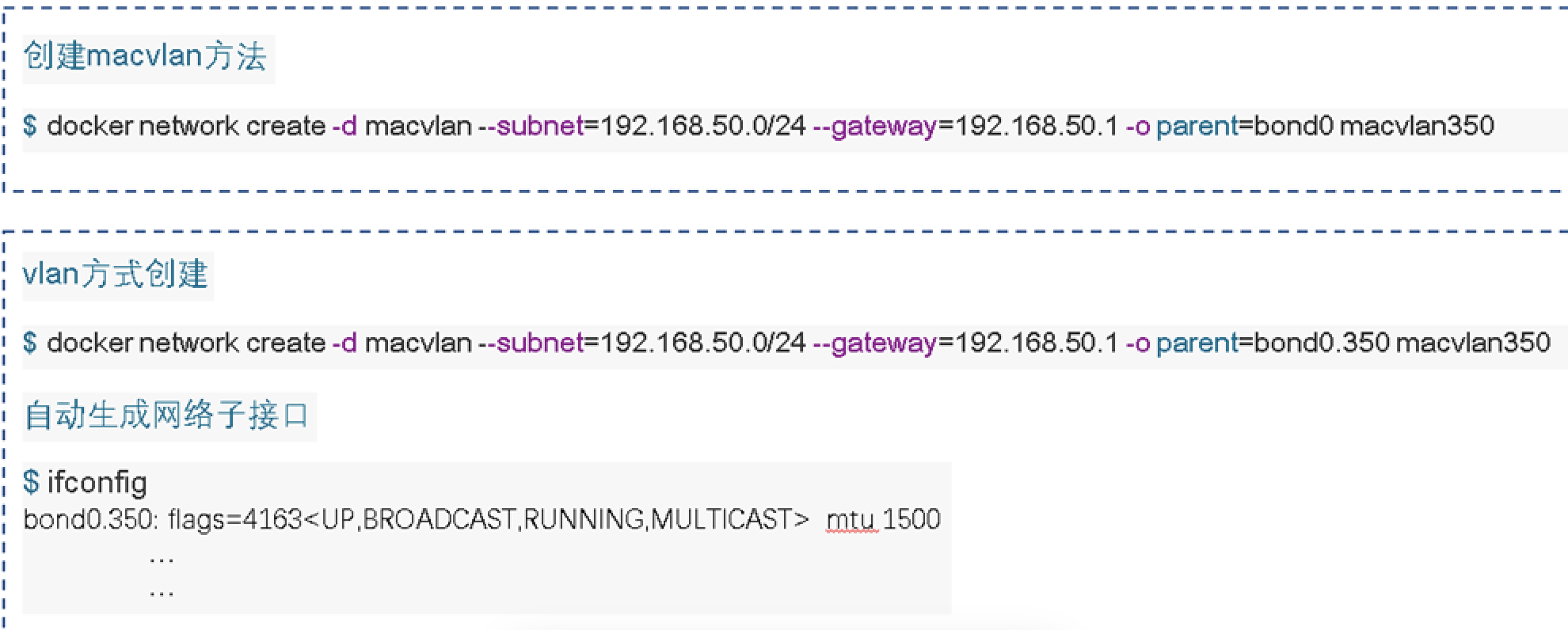
而且macvlan的设置简单,使用一行命令即可完成创建。采用vlan方式创建之后,一台宿主机可同时支持多个网段。如果使用了vlan的话,宿主机一定要接到交换机的trunk端口。
镜像仓库
镜像仓库我们使用的是docker官方提供的镜像仓库,镜像存储用的是ceph。我们额外开发了一个代理服务,拦截了镜像仓库的所有API请求。在代理服务里面我们做了用户认证以及对上传和拉取镜像做了权限的控制和操作审计。 同时记录了各个应用每次上传镜像的名称和版本。用户可以使用docker login登入镜像仓库后手动docker push进行镜像的推送。也可以使用token集成到CI系统里面进行推送。
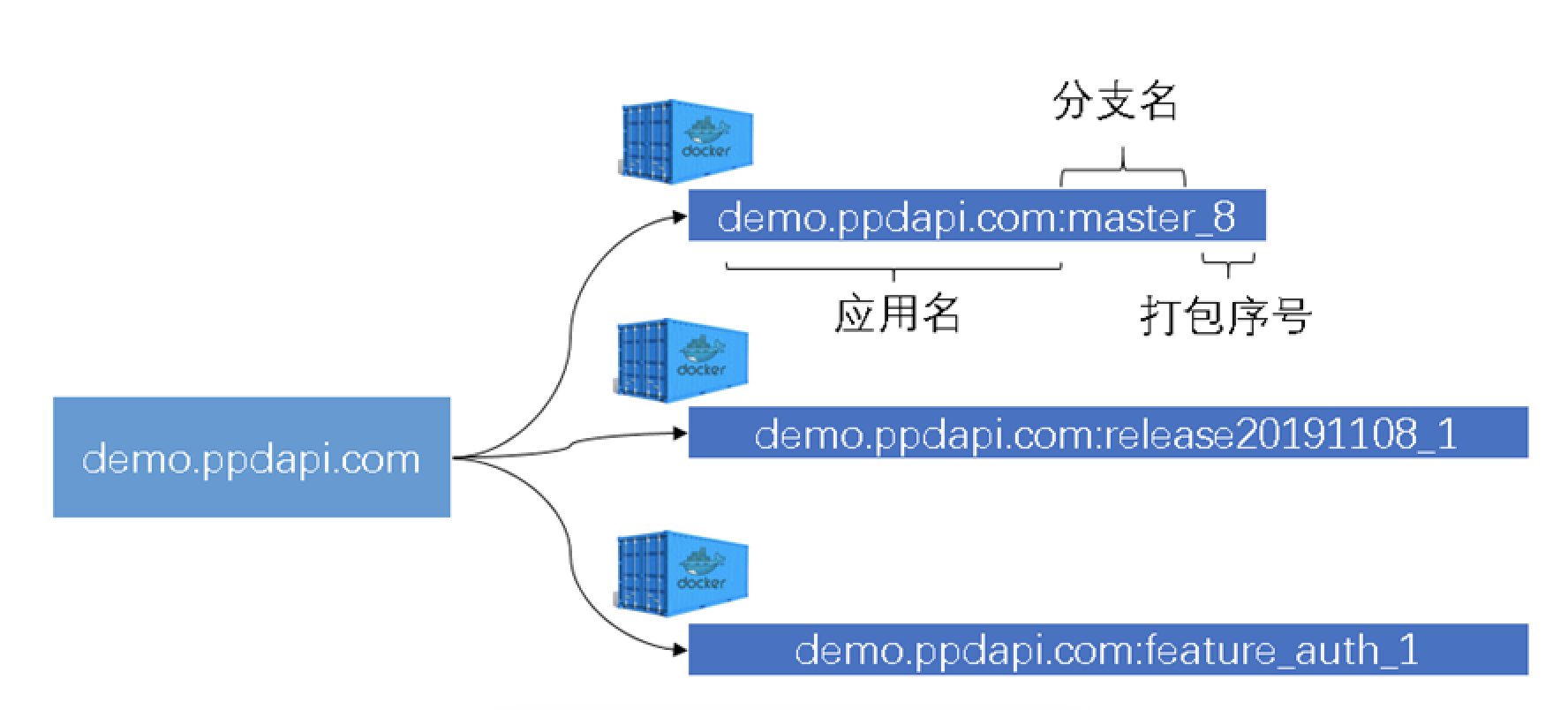
我们对镜像的命名采用的是应用名+代码分支名+打包自增ID,可以很方便的选择哪个分支、哪次构建的镜像进行部署。

CD的话我们在k8s上面开发了一个容器发布平台,对用户封装了所有的k8s使用细节。我们的容器发布平台支持从开发、测试、预发和生产的全环境部署。支持按应用维度进行容器的创建、重启、销毁,以及实例维度的上下线操作。用户在测试环境打包镜像并且测试通过之后在预发和生产就可以使用该镜像进行发布。
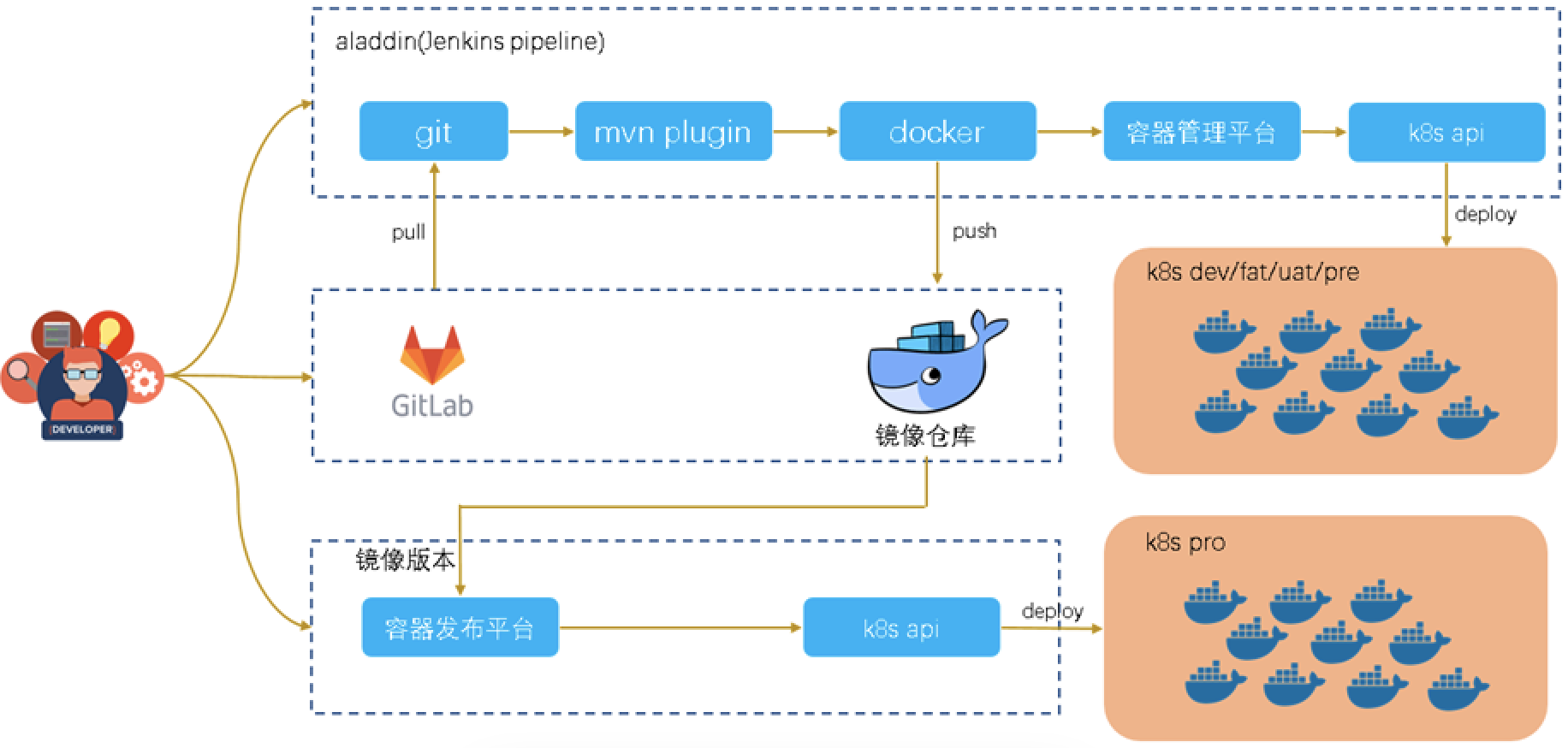
容器发布平台支持蓝绿部署和滚动更新的方式进行版本升级。蓝绿部署可以在我们平台里面可以创建2个发布组作为蓝绿组,流量在2组间切换可以方便的进行版本更新和回滚。滚动更新就跟deployment的更新方式一样,按批次对实例进行升级。
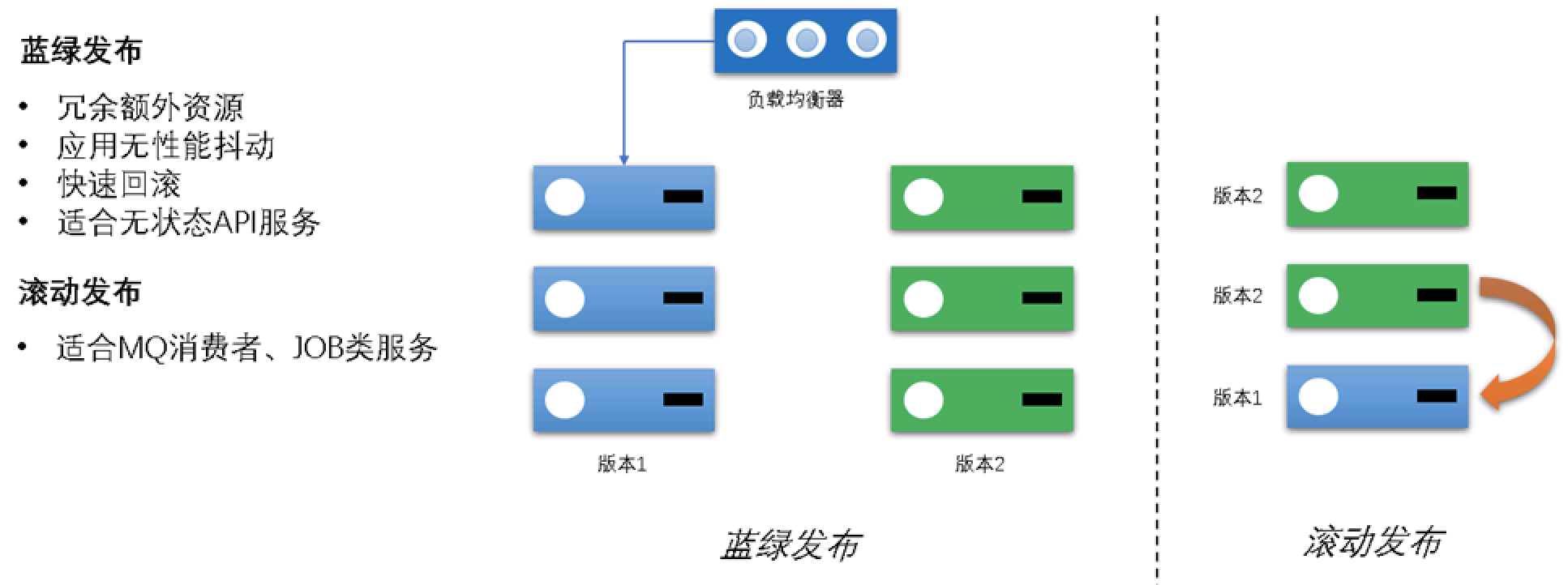
容器发布平台都是基于k8s中的pod进行部署的。各个pod通过发布组或应用进行分组。我们之所以没有使用deployment进行部署是因为deployment的控制逻辑过于复杂和限制。因为我们需要经常针对单个pod进行重启、上下线、销毁以及版本更新等操作。如果使用deployment的话这些就无法做到了。Pod也是k8s中最简单的部署单位,并且也足够静态,不用担心k8s在有些情况自动对pod进行操作,这些操作有些可能不是我们所期望的,甚至会带来生产的故障。
使用java自研高可用组件
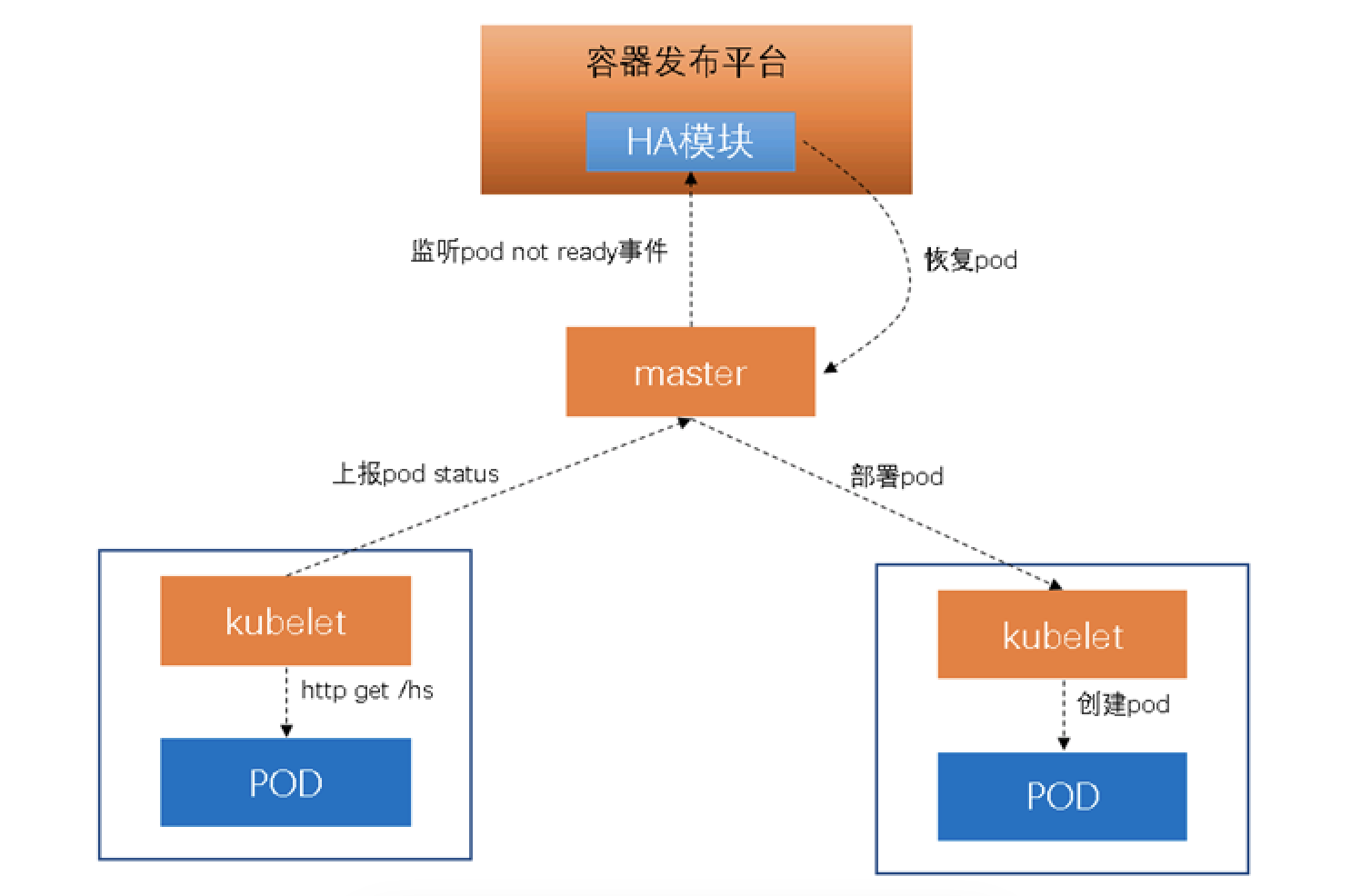
上文中已提到我们只使用了k8s中的pod进行部署,虽然简单但是也无法享有k8s带来的自动恢复特性。同时我们需要定制化符合我们操作习惯的自动恢复逻辑。由于团队成员都是JAVA出身,我们就使用了JAVA语言实现了一个高可用组件,支持容器的宕机恢复和物理机的宕机迁移。该组件集成在了我们的容器发布平台中。
高可用组件使用fabric8提供的kubernetes-client去向apiserver监听endpoints事件。信也科技要求所有的应用都必须实现一个健康检测接口,这样我们可以在pod上面添加一个readiness探针。kubelet就会不断地调用健康检测接口并上报结果到apiserver。我们根据endpoints中的NotReady实例状态,去触发一个删除pod和重新部署pod的任务。我们使用了推拉结合的方式获取endpoints事件的方式,这样就保证事件不会丢失。同时如果用户正在操作实例的话,那我们就对该实例忽略高可用的处理。目前该组件已经在生产完成了实例宕机和物理机宕机的考验,表现良好。
虚拟环境的支持
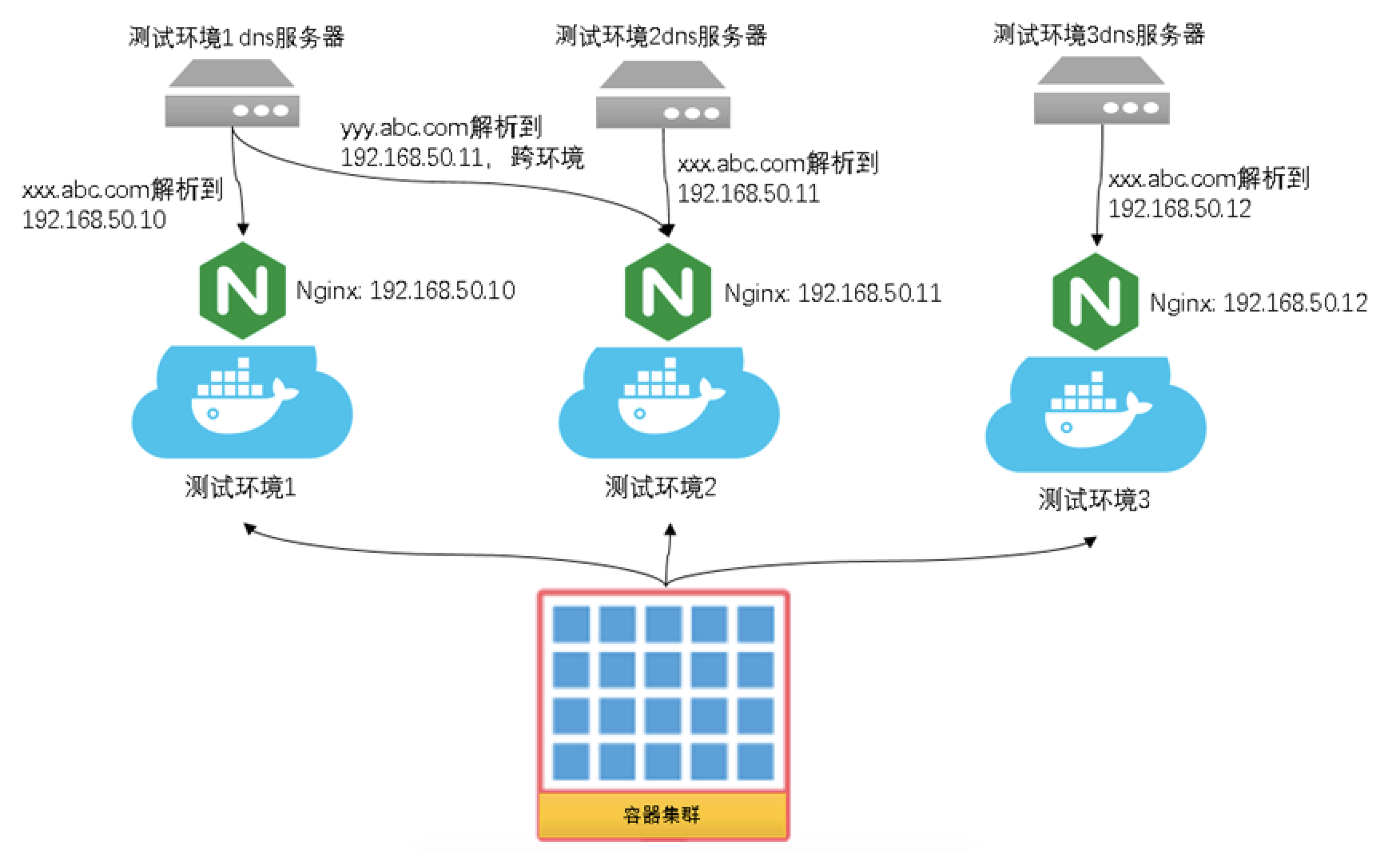
在信也科技,我们有多个测试环境用来支持同时多个业务的并行迭代测试。如果对每个测试环境都单独部署一套k8s集群,这样成本太大。为此我们在一个k8s集群上构建出了多个虚拟环境,每个虚拟环境包含了部分或所有应用。由于信也科技中的大多数应用都是通过域名和nginx的方式对外提供服务的,为此我们基于coredns,实现了一个mysql的dns记录维护插件。每个虚拟环境启动一个coredns服务和nginx服务,在这个环境下的所有pod启动时都会绑定这个dns服务器的IP。本环境下所有的域名都会解析到该环境下的nginx的IP,从而达到环境隔离访问的效果。
其他
在实践的过程中我们还是遇到了蛮多问题,给大家依次分享下:
一
Java程序无法正确识别到容器内存和cpu数量。如果没有手动设置堆大小的话,默认会使用宿主机内存的四分之一,超过容器内存规格大小的会直接造成容器宕机。同时jvm获取到的cpu核数也是宿主机的,这样如果有根据cpu核数创建线程的代码都会根据错误的数量来创建,造成程序运行的不稳定。这2个问题可以通过使用lxcfs文件系统和把jdk的版本升级到8u212以上版本解决。
有些应用使用短连接去请求,如果调用量很大的话会造成端口的不够用,需要在容器里面调下tcp的内核参数扩大可用端口数量。
使用lxcfs和修改内核参数可以在pod上面添加如下设置:

二 k8s证书过期问题。
我们当时安装k8s的时候证书的过期时间设置成了1年,造成1年之后因为证书过期造成整个集群的不可用。需要重新生成证书,在master和node节点上依次更新证书。证书更新过程会中会造成集群的不可用,但不会影响已运行的实例。信也科技已经在生产更新过证书。
三 宿主机高负载运行触发了docker1.13的bug
由于对测试环境开启了资源超配,一台宿主机经常会运行超过200的实例,由于测试环境需要不断地发版测试,操作频率也比较频繁。所以就触发了docker1.13的各种奇怪的问题,比如:containerd挂了无法自动恢复、容器进程停止但是docker ps容器实例还在等问题。 目前我们是通过把测试环境docker版本升级最新版本解决的。
Q && A

若有收获,就点个赞吧
0 人点赞
