分享摘要
伴随 Kubernetes 的兴起,越来越多的公司开始实践 Service Mesh,以应对规模越来越大的微服务间通信问题。本次分享主要介绍了 Service Mesh 演进的常见形式,扇贝 Service Mesh 选型落地 Envoy 的过程,以及如何基于 go-control-plane 搭建自己的 Envoy xDS 服务端。希望能对在大家落地 Service Mesh 的过程中提供一点思路。
主要内容
- 扇贝业务现状
- 几种 Service Mesh 的演进模式
- 扇贝 Service Mesh 选型Envoy的过程
- Envoy xDS 协议介绍
- 基于 go-control-plane 实现 xDS 服务端
分享嘉宾
李有才,扇贝基础服务工程师
提问链接
https://shimo.im/docs/C9xJT8Hj66cg8Chc
正文
扇贝业务情况
扇贝三年前就开始实行docker化和微服务化来应对需求的快速变更。随着公司规模扩大,组织结构也相应的调整拆分,业务团队之间变得独立,微服务数量开始快速上升,因此2018年初我们的技术架构也开始转向k8s来应对挑战,service mesh的落地便是伴随着转型k8s开始的。
目前扇贝的微服务有五百多个,整个k8s集群有七十多个节点,运行了五千多pod,承担每天数十亿次的内外部API调用, 峰值QPS过万。
Service Mesh
Service Mesh一词出现的时间虽然较晚(2016年9月 https://www.infoq.cn/article/kHBVYZIf2V3VpHGkCkkL),但宽泛的来讲,他所追求的通信与业务解耦的理念却有很长的发展的历程,通常会有下面几种演进形式。
较原始的时候,开发者需要在业务代码中实现服务发现、负载均衡、熔断重试等功能,这些都是脏活累活,本不属于业务的核心功能,却需要开发者花费大量的心血。
第二阶段,自然而然的我们就会想到把这部分功能剥离出来,抽象成可复用的类库,比如Java世界中的Spring Cloud/Nestflix OSS。但是这些框架从进程角度来看,还是跟业务是耦合的,而且还存在着跨语言困难,版本升级难以推进,框架庞大业务同学学习成本高等问题。
第三阶段,服务通信的技术栈进一步下沉,通过Nginx,HAProxy,Apache等反向代理的使用引入 Proxy 层,分离业务与服务通信。Proxy层的引入是一个承上启下的阶段。
有了proxy层,服务注册发现、负载均衡、重试熔断等机制得以脱离业务语言和框架,开始热闹起来。但是以传统反向代理为核心的,服务变化需要重启进程甚至更改配置文件的proxy层,在面对k8s时代微服务频繁重启、漂移的状况时就显得力不从心了。
进入k8s时代,Service Mesh概念开始出现,通信网络分为了控制平面和数据平面,Linked、Envoy、Istio 等产品登上历史舞台。并由第一代的 proxy per node(Linked v1 ) 模式快速进化到 sidecar 形式,使得通信层离真实业务足够进,控制力度足够细,同时又做到了业务的完全无感知。
实践
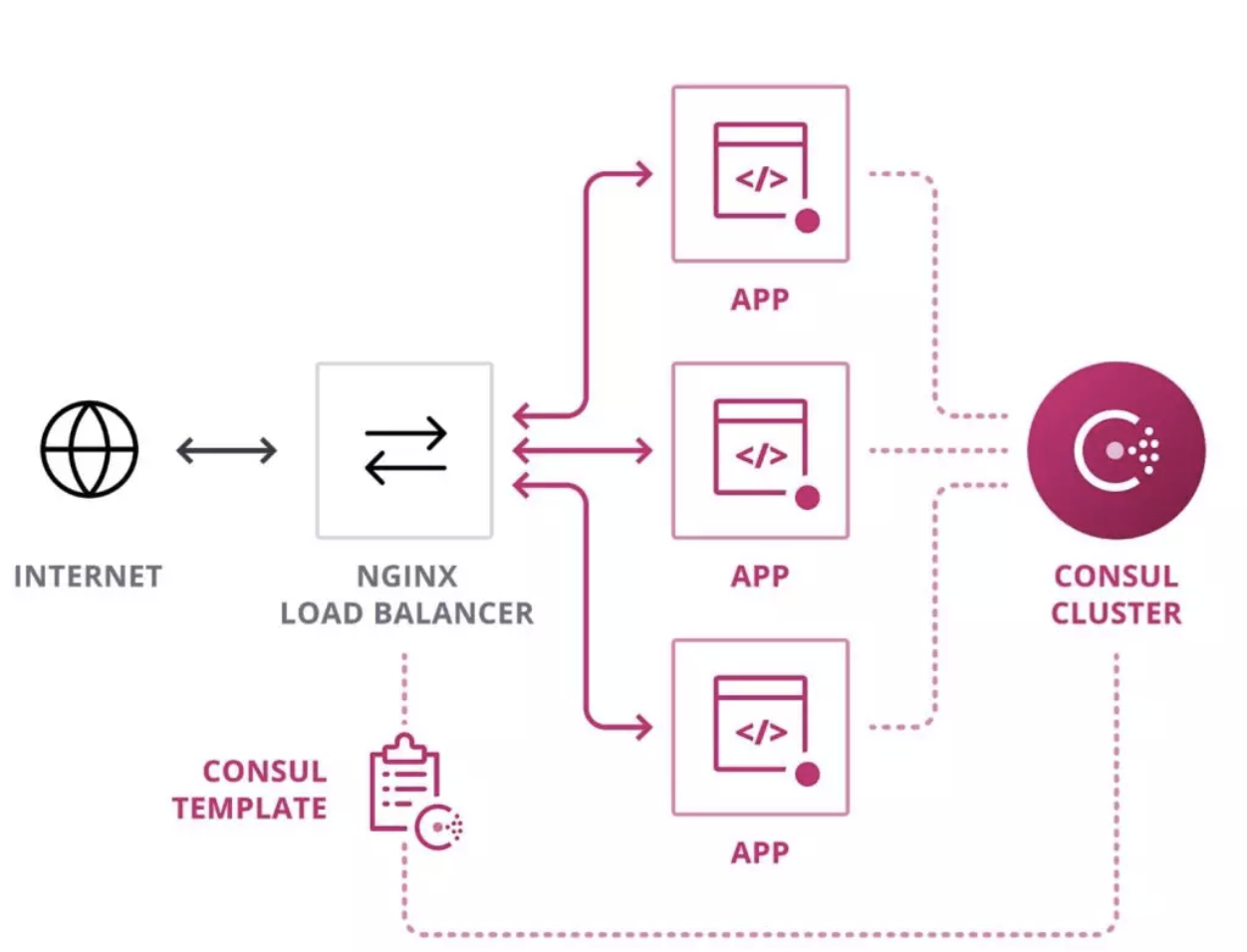
扇贝早期的微服务架构采用的是传统的Proxy层方式,由nginx+consul+consul-template来实现。微服务启动时向Consul进行注册,同时提供健康检查入口。
然后Consul会进行主动健康检测,consul template通过长链接到consul监测服务变化,渲染nginx的配置模板,在监测到发生变动时根据模板生成新的配置文件,发送signal热重启nginx。
这种架构在服务变动较少时还是挺好用的。但是当我们需要蓝绿部署、灰度测试、流量镜像等高级一点的功能和更详细的统计指标时就比较难办了。
从早期的微服务模式演进到 k8s 时,公司的技术方案是比较开放激进的,想要k8s和Service Mesh同时推进。当时可选的方案有Linked和Istio两种,考虑到Istio背后的google和社区繁荣程度,我们认为Istio会成为主流,所以在技术预研和测试的时候部署了Istio。
令人尴尬的是,当时Istio太早期了,版本还是0点几,我们发现服务非常不稳定,各种莫名其妙的5xx错误。但是我们又实在不想放弃这种符合未来趋势的服务通信层方式,所以我们做了折衷选择——只使用它的数据平面组件Envoy。
一方面我们获得的Envoy技术积累待Istio稳定后在切换过去也还是有用的,另一方面保留Envoy也使我们拥有了更先进的Proxy层,能够应对 k8s 架构下服务快速变化的状况。
之所以说Envoy是现代化的代理,是因为相比于比于传统的Nginx代理,Envoy有原生的GRPC/HTTP2(我们内部服务调用是基于grpc的)支持,能够提供非常丰富的统计指标(比如基础的请求延时,重试次数等),以及我们后面会提到的能够运行时动态更新配置的xDS协议。
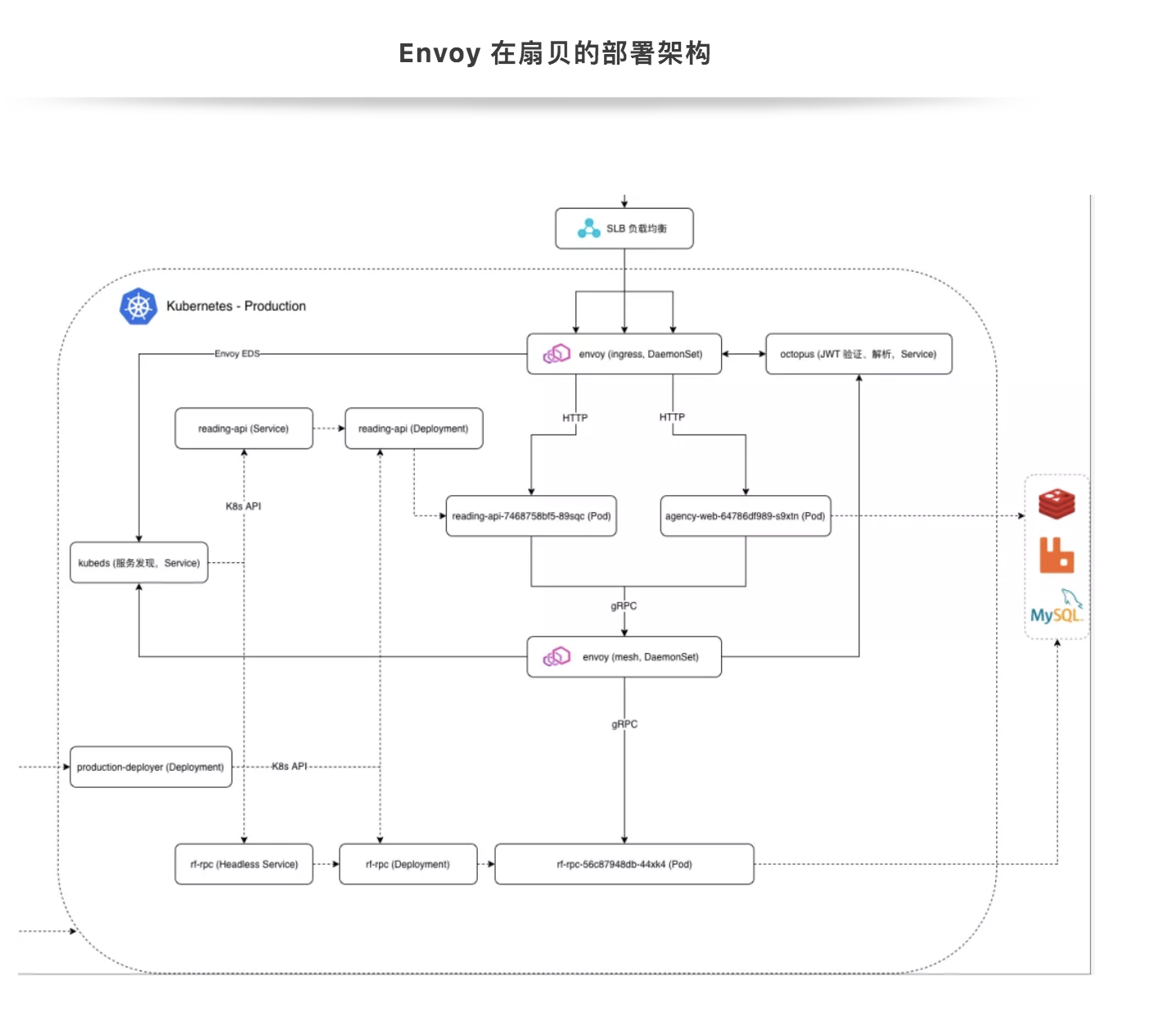
由上图可以看出,扇贝使用的并不是严格意义上ServiceMesh所定义的Sidecar模式,而是以daemonset的形式部署的Envoy,这是考虑到我们脱离了Istio控制平面,自己做sidecar模式对技术团队来说难度过大。
使用daemonset的部署形式降低了我们要管理的代理数量,能减少资源占用,升级Envoy也相对容易些。当然,缺点也是显而易见的,无法做到sidecar那样细粒度的流量管控,好在目前我们的架构还能接受这一点。
另外一个可以从图中看出的点是,我们的 Envoy 其实是分成两组的。一组承担了 API Gateway 的功能,代理集群南北流量。另一组则代理了集群内的东西流量。API Gateway 启用了 jwt 解析,ratelimit 等功能。内部服务代理则实现了服务鉴权功能。
xDS 协议介绍
基于 go-control-plane 实现xDS服务
Q && A
Q:为啥自己实现 xds 服务器?有现成的为啥不用?例如istio-pilot/rotor,istio-pilot可以单独使用的。
A:其实是早期遗留问题,一开始我们用的 Istio 不稳定,后续的选择就趋于保守了。当时 rotor 应该还没有 release 版本。
Q:如何保证 Envoy 对业务性能影响最小?
A:Envoy 本身性能没什么问题,要注意的是配置的 filter 这些跟外部服务交互的地方,比如 ratelimit 之类的,要配置好超时时间以及失败后的策略。
Q:你们的服务是基于 gRPC 还是 REST/http1.1 的?gRPC 要求至少 http2,如果需要把 gRPC 服务暴露给外部,对于 Ingress Controller 你有什么推荐?你们服务部署的是阿里云吗?Edge Proxy 用的阿里的服务?
A:我们对外的 rest,内部服务是 gRPC。Envoy 也是有做 Ingress Controller 的产品的,比如 Contour,不过我们没有实践过,谈不上推荐。Edge Proxy 用的是阿里云,最外面有一层阿里云的 slb。
Q:Istio 不好用,为什么不考虑 Sofa Mesh 来代替?
A:早期 0 点几版本的时候不稳定哈。现在不是特别在意大集群性能问题的话,Istio 是可用的。
Q:请问如何实现的灰度发布和蓝绿部署?
A:灰度发布也是基于配置不同 Endpoints 权重这个思路来的,也可以部署不同的 Deployment,基于 Pod 比例来做。蓝绿部署实践不多哈。
Q:你们服务 tracing 和流量监控是怎么做的呢?
A:traceing 目前还是原始的日志方式,在研究替代方案,后续有进展可以再分享一下。流量监控我们有做 Pod 的进出流量统计,也有从 Envoy metrics 获取的请求统计。
原文链接

若有收获,就点个赞吧
0 人点赞
